the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Mar 2023
| 02 Mar 2023
Empirical tsunami fragility modelling for hierarchical damage levels
Hossein Ebrahimian
Konstantinos Trevlopoulos
Brendon Bradley
The present work proposes a simulation-based Bayesian method for parameter estimation and fragility model selection for mutually exclusive and collectively exhaustive (MECE) damage states. This method uses an adaptive Markov chain Monte Carlo simulation (MCMC) based on likelihood estimation using point-wise intensity values. It identifies the simplest model that fits the data best, among the set of viable fragility models considered. The proposed methodology is demonstrated for empirical fragility assessments for two different tsunami events and different classes of buildings with varying numbers of observed damage and flow depth data pairs. As case studies, observed pairs of data for flow depth and the corresponding damage level from the South Pacific tsunami on 29 September 2009 and the Sulawesi–Palu tsunami on 28 September 2018 are used. Damage data related to a total of five different building classes are analysed. It is shown that the proposed methodology is stable and efficient for data sets with a very low number of damage versus intensity data pairs and cases in which observed data are missing for some of the damage levels.
- Article
(6342 KB) - Full-text XML
- BibTeX
- EndNote





Fragility models express the probability of exceeding certain damage thresholds for a given level of intensity for a specific class of buildings or infrastructure. Empirical fragility curves are models derived from observed pairs of damage and intensity data for buildings and infrastructure usually collected, acquired and even partially simulated in the aftermath of disastrous events. Some examples of empirical fragility models are seismic fragility (Rota et al., 2009; Rosti et al., 2021), tsunami fragility (Koshimura et al., 2009a; Reese et al., 2011; a comprehensive review can be found in Charvet et al., 2017), flooding fragility (Wing et al., 2020) and debris flow fragility curves (Eidsvig et al., 2014). Empirical fragility modelling is greatly affected by how the damage and intensity parameters are defined. Mutually exclusive and collectively exhaustive (MECE, see next section for the definition) damage states are quite common in the literature as discrete physical damage states. The MECE condition is necessary for damage states in most probabilistic risk formulations, leading to the mean rate of exceeding loss (e.g. Behrens et al., 2021).
Tsunami fragility curves usually employ the tsunami flow depth as the measure of intensity; although different studies also use other measures like current velocity (e.g. De Risi et al., 2017b; Charvet et al., 2015). Charvet et al. (2015) demonstrate that the flow depth may cease to be an appropriate measure of intensity for higher damage states, and other parameters such as the current velocity, debris impact and scour can become increasingly more important. De Risi et al. (2017b) developed bivariate tsunami fragilities, which account for the interaction between the two intensity measures of tsunami flow depth and current velocity.
Early procedures for empirical tsunami fragility curves used data binning to represent the intensity. For example, Koshimura et al. (2009b) binned the observations by the intensity measure, i.e. the flow depth; however, the latest procedures have mostly used point-wise intensity estimates instead.
Fragility curves for MECE damage states are distinguished by their nicely “laminar” shape; in other words, the curves should not intersect. When fitting empirical fragility curves to observed damage data, this condition is not satisfied automatically. For example, fragility curves are usually fitted for individual damage states separately, and they are filtered afterwards to remove the crossing fragility curves (e.g. Miano et al., 2020), or ordered (“parallel”) fragility models are used from the start (Charvet et al., 2014; Lahcene et al., 2021). Charvet et al. (2014) and De Risi (2017a) also used partially ordered models to derive fragility curves for MECE damage states. They used the multinomial probability distribution to model the probability of being in any of MECE damage states based on binned intensity representation. De Risi et al. (2017a) used Bayesian inference to derive the model parameters for an ensemble of fragility curves.
Empirical tsunami fragility curves are usually constructed using generalised linear models based on probit, logit or the complementary loglog link functions (Charvet et al., 2014; Lahcene et al., 2021). As far as the assessment of the goodness of fit, model comparison and selection are concerned, approaches based on the likelihood ratio and Akaike information criterion, (e.g. Charvet et al., 2014; Lahcene et al., 2021) and on k-fold cross validation have also been used (Chua et al., 2021). For estimating confidence intervals for empirical tsunami fragility curves, bootstrap resampling has been commonly used (Charvet et al., 2014; Lahcene et al., 2021; Chua et al., 2021).
The present paper presents a simulation-based Bayesian method for inference and model class selection for the ensemble modelling of the tsunami fragility curves for MECE damage states for a given class of buildings. By fitting the (positive definite) fragility link function to the conditional probability of being in a certain damage state, given that building is not in any of the preceding states, the method ensures that the fragility curves do not cross (i.e. they are “hierarchical” as in De Risi et al., 2017a). The method uses adaptive Markov chain Monte Carlo simulation (MCMC, Beck and Au, 2002), based on likelihood estimation using point-wise intensity values, to infer the ensemble of the fragility model parameters. Alternative link functions are compared based on log evidence, which considers both the average goodness of fit (based on log likelihood) and the model parsimony (based on relative entropy). This way, among the set of viable models considered, it identifies the simplest model that fits the data best. By “simplest model”, we mean the model having maximum relative entropy (measured using the Kullback–Leibler distance; Kullback and Leibler, 1951) with respect to the data. This usually means the model has a small number of parameters.
2.1 Definitions of intensity and damage parameters
The intensity measure, IM, (or simply “intensity”, e.g. the tsunami flow depth) refers to a parameter used to convey information about an event from the hazard level to the fragility level – it is an intermediate variable. The damage parameter, D, is a discrete random variable, and the vector of damage levels is expressed as , where Dj as the jth damage level (threshold) and NDS as the total number of damage levels considered (depending on the damage scale being used and on the type of hazard, e.g. earthquake, tsunami, debris flow). Normally, D0 denotes the no-damage threshold, while defines the total collapse or being totally washed away. Let us assume that DSj is the jth damage state defined by the logical statement that the damage D is between the two damage thresholds Dj and Dj+1; i.e. D is equal to or greater than Dj and smaller than Dj+1 as follows (see also Fig. 1 for a graphical representation of the above expressions):
where (⋅) denotes the logical product and is read as “AND”. Obviously, for the last damage state, we have DS.

Damage states are mutually exclusive and collectively exhaustive (MECE) if and only if (if i≠j, ) and ; (⋅) denotes the logical product and is read as “AND”. In simple words, the damage states are MECE if being in one damage state excludes all others and if all the damage states together cover the entire range of possibilities in terms of damage. The ensemble of MECE damage states DSj, is usually referred to as the damage scale (e.g. the EMS98; Grünthal, 1998).
The proposed methodology herein is also applicable to fragility assessment in cases where observed damage data are not available for some of the damage levels. Let index be the vector of j values (), indicating damage levels Nj for which observed data are available (j values are in ascending order). The new damage scale formed as , where N is the length of vector index, is also MECE. It is noteworthy that the number of fragility curves derived in this case is going to be equal to N−1. In the following, for simplicity and without loss of generality, we have assumed that observed data are available for all damage levels, i.e. , that is, . However, the proposed methodology is also applicable to the modified damage scale formed by damage level indices in vector index(1:N). We will later see examples of such applications in the case studies.
2.2 Fragility modelling using generalised regression models
The generalised regression models (GLMs) are more suitable for empirical fragility assessment with respect to the standard regression models. This is mainly because the dependent variable in the case of the generalised regression models is a Bernoulli binary variable (i.e. only two possible values: 0 or 1). Bernoulli variables are particularly useful in order to detect whether a specific damage level is exceeded or not (only two possibilities). In the following, fragility assessment based on GLMs is briefly described.
The term P(DSj | IM) denotes the probability of being in damage state DSj for a given intensity level IM. Based on NDS damage thresholds, this conditional probability P(DSj | IM) can be read (see Eq. 1) as the probability that (D≥Dj) and and can be estimated as follows (see Appendix A for the derivation):
where is the fragility function for damage level Dj.
For each damage threshold, fragility can be obtained for a desired building class considering that the damage data provide Bernoulli variables (binary values) of whether the considered damage level was exceeded or not for given IM levels. For damage threshold Dj, all buildings with an observed damage level D<Dj will have a probability equal to zero, while those with D≥Dj will have an assigned probability equal to one. In other words, for building i and damage state j, the Bernoulli variable Yij indicates whether building i is in damage state j
where IMi is the intensity evaluated at the location of building i. A Bernoulli variable is defined by one parameter, which is herein. This latter is usually linked to a linear logarithmic predictor in the form
where α0,j and α1,j are regression constants for damage level j. We have employed generalised linear regression (e.g. Agresti, 2012) with different link functions “logit”, “probit” and “cloglog” to define probability function πij as the following:
The logit link function is equivalent to presenting πj(IM) with a logistic regression function. The probit link function is equivalent to a lognormal cumulative distribution function for πj(IM). In the cloglog (complementary log–log) transformation, the link function at the location of building i can be expressed as . It is noted that the generalised linear regression based on maximum likelihood estimation (MLE) is available in many statistical software packages (e.g. MathWorks, Python, R).
In the following, we have referred to the general methodology of fitting fragility model to data – one damage state at a time – the “Basic method”. In the Basic method, the probability of exceeding damage level j is equal to the probability function defined in Eq. (5); that is, . This method for empirical fragility curve parameter estimation is addressed in detail in the section “Results”, under the “MLE-Basic” method. The fragility curves obtained under the “MLE-Basic” method could potentially cross, leading to the ill condition that . To overcome this, a hierarchical fragility modelling approach has been adopted like that in De Risi et al. (2017a).
2.3 Hierarchical fragility modelling
Equation (2) for , and given IMi, can also be written as follows using the product rule in probability:
The term embedded in Eq. (6) denotes the conditional probability that the damage exceeds the damage threshold Dj+1 knowing that it has already exceeded the previous damage level Dj given IMi. By making (see Eq. 5, which is positive definite), we ensure that the fragility curve of a lower damage level will not fall below the fragility curve of the subsequent damage threshold (the ill condition of does not take place). Hence, Eq. (6) can be expanded as follows (see Appendix B for derivation):
In this way, the fragility curves are constructed in a hierarchical manner by first constructing the “fragility increments” P(DSj | IMi). Note that for the last damage state , the probability , which is also equal to the fragility of the ultimate damage threshold , i.e. (see Eq, 2), can be estimated by satisfying the collectively exhaustive (CE) condition
Accordingly, the fragility of other damage levels , where , can be obtained from Eq. (2) by starting from the fragility of the higher threshold and adding successively P(DSj | IM) (see Eq. 7) as follows:
As a result, the set of hierarchical fragility models based on Eq. (9) has 2×NDS model parameters with the vector . Obviously, with reference to Eq. (8), no model parameter is required for the last damage level, which is derived by satisfying the CE condition. The vector θ of the proposed hierarchical fragility models can be defined by two different approaches
- 1.
MLE method. A generalised linear regression model (as explained in previous the section) is used for the conditional fragility term for the jth damage state DSj (see Eq. 7, ). Herein, we need to work with partial damage data so that all buildings in DSj (with an observed damage ) will be assigned a probability equal to 0, while those in higher damage states (with ) will be assigned a probability equal to 1 (i.e. in order to model the conditioning on D≥Dj, the domain of possible damage levels is reduced to D≥Dj).
- 2.
Bayesian model class selection (BMCS). The Bayesian inference for model updating is employed to obtain the joint distribution of the model parameters.
Detailed discussion about these two approaches, namely “MLE” and “BMCS”, for parameter estimation of empirical fragility curves are provided in Sect. 3.
2.4 Bayesian model class selection (BMCS) and parameter inference using adaptive MCMC
We use the Bayesian model class selection (BMCS) herein to identify the best link model to use in the generalised linear regression scheme. However, the procedure is general and can be applied to a more diverse pool of candidate fragility models. BMCS (or model comparison) is essentially Bayesian updating at the model class level to make comparisons among candidate model classes given the observed data (e.g. Beck and Yuen, 2004; Muto and Beck, 2008). Given a set of N𝕄 candidate model classes , and in the presence of the data D, the posterior probability of the kth model class, denoted as P(𝕄k | D) can be written as follows:
In lieu of any initial preferences about the prior P(𝕄k), one can assign equal weights to each model; thus, P(𝕄k)=1/N𝕄. Hence, the probability of a model class is dominated by the likelihood of p(D|𝕄k) (a.k.a. evidence). It is important to note that p herein stands for the probability density function (PDF). Here, data vector defines the observed intensity and damage data for NCL buildings surveyed for class CL. Let us define the vector of model parameters θk for model class 𝕄k as . We use the Bayes theorem to write the “evidence” p(D | 𝕄k) provided by data D for model 𝕄k as follows:
It can be shown (see Appendix C; Muto and Beck, 2008) that the logarithm of the evidence (called log-evidence) ln [p(D | 𝕄k)] can be written as
where is the domain of θk, and is the likelihood function conditioned on model class 𝕄k. “Term 1” denotes the posterior mean of the log likelihood, which is a measure of the average data fit to model 𝕄k. “Term 2” is the relative entropy (Kullback and Leibler, 1951; Cover and Thomas, 1991) between the prior p(θk | 𝕄k) and the posterior of θk given model 𝕄k, which is a measure of the distance between the two PDFs. The latter Term 2 measures quantitatively the amount of information (on average) that is “gained” about θk from the observed data D. It is interesting that Term 2 in the log-evidence expression penalises for model complexity; i.e. if the model extracts more information from data (which is a sign of being a complex model with more model parameters), the log-evidence reduces. The exponential of the log-evidence, p(D | 𝕄k), is going to be implemented directly in Eq. (10) to provide the probability attributed to the model class 𝕄k. More details on how to estimate the two terms in Eq. (12) are provided in Sect. 3.
The likelihood can be derived, based on point-wise intensity information, as the likelihood of nCL,j buildings being in damage state DSj (considering that ), according to data D defined before
The posterior distribution can be found based on Bayesian inference
where C−1 is a normalising constant. In lieu of additional information (or preferences), the prior distribution, p(θk | 𝕄k), can be estimated as the product of marginal normal PDFs for each model parameter, i.e. a multivariate normal distribution with zero correlation between the pairs of model parameters θk (see Appendix D). More detail about an efficient prior joint PDF is provided in Sect. 3. To sample from the posterior distribution in Eq. (14), an adaptive MCMC simulation routine (see Appendix E) is employed. MCMC is particularly useful for drawing samples from the target posterior, while it is known up to a scaling constant C−1 (see Beck and Au, 2002); thus, in Eq. (14), we only need un-normalised PDFs to feed the MCMC procedure. The MCMC routine herein employs the Metropolis–Hastings (MH) algorithm (Metropolis et al., 1953; Hasting, 1970) to generate samples from the target joint posterior PDF .
2.5 Calculating the hierarchical fragilities and the corresponding confidence intervals based on the vector of model parameters θk
For each realisation of the vector of model parameters θk, the corresponding set of hierarchical fragility curves can be derived based on the procedure described in the previous sections. Since we have realisations of the model parameters drawn from the joint PDF (based on samples drawn from adaptive MCMC procedure, see also Appendix E), we can use the concept of robust fragility (RF) proposed in Jalayer et al. (2017) (see also Jalayer et al., 2015; Jalayer and Erahimian, 2020) to derive confidence intervals for the fragility curves. RF is defined as the expected value for a prescribed fragility model considering the joint probability distribution for the fragility model parameters θk. The RF herein can be expressed as
where is the fragility given the model parameters θk associated with the model 𝕄k (it has been assumed that once conditioned on fragility model parameters θk, the fragility becomes independent of data D); is the expected value over the vector of fragility parameters θk for model 𝕄k. The integral in Eq. (15) can be solved numerically by employing Monte Carlo simulation with Nd generated samples from the vector θk as follows:
where is the fragility given the lth realisation () of the model parameters θk for model 𝕄k. Based on the definition represented in Eqs. (15) and (16), the variance , which can be used to estimate a confidence interval for the fragility considering the uncertainty in the estimation of θk, is calculated as follows:
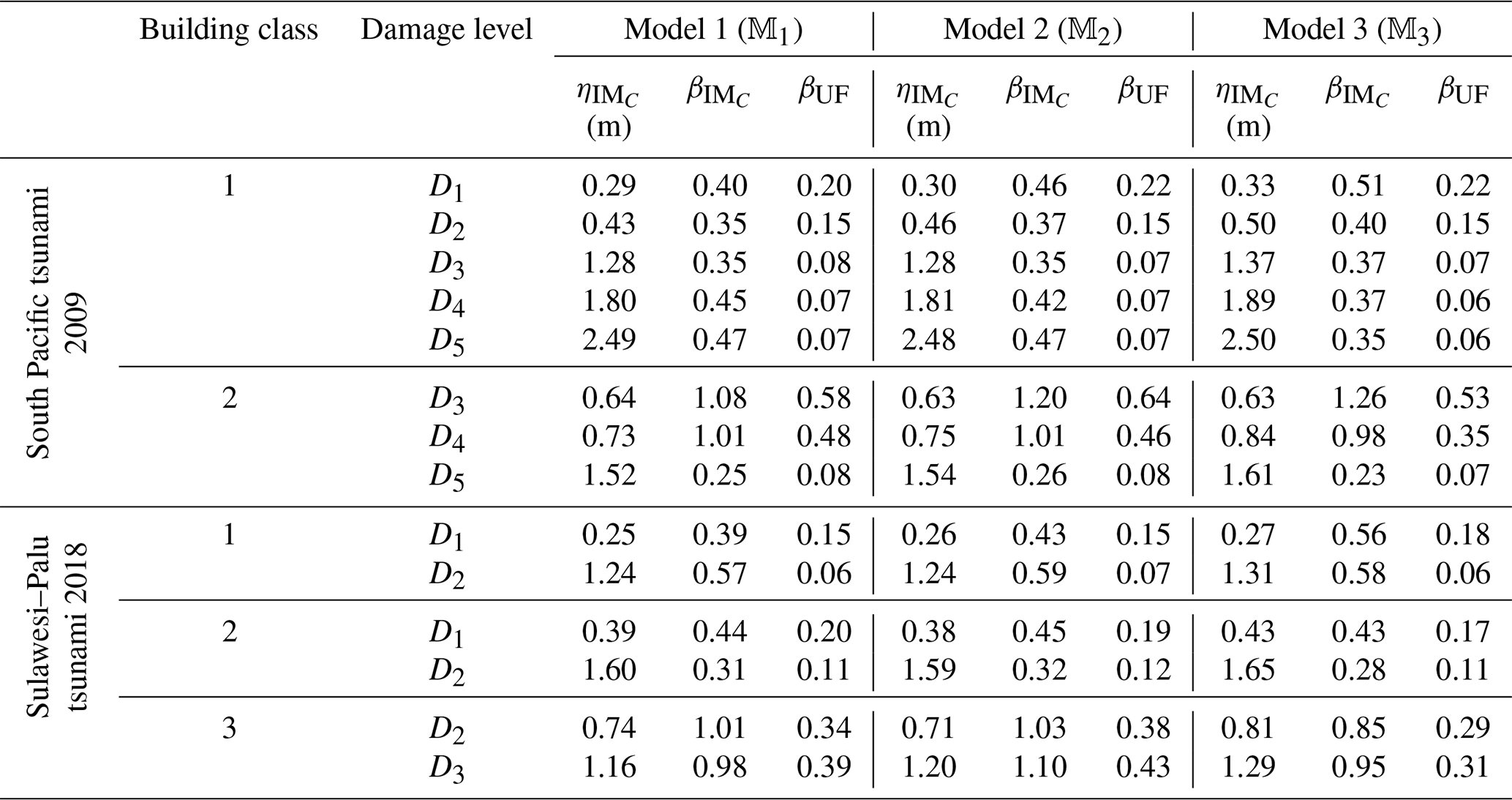
The empirical fragilities derived through the hierarchical fragility procedure are not necessarily attributed to a lognormal distribution. Hence, we have derived equivalent lognormal statistics (i.e. the median and dispersion) for the resulting fragility curves. The median intensity, , for a given damage level is calculated as the IM corresponding to 50 % probability on the fragility curve. The logarithmic standard deviation (dispersion) of the equivalent lognormal fragility curve at the onset of damage threshold, , is estimated as half of the logarithmic distance between the IMs corresponding to the probabilities of 16 % () and the 84 % () on the fragility curve; thus, the dispersion can be estimated as . The overall effect of epistemic uncertainties (due to the uncertainty in the fragility model parameters and reflecting the effect of limited sample size) on the median of the empirical fragility curve is considered through (logarithmic) intensity-based standard deviation denoted as βUF (see Jalayer et al., 2020). βUF can be estimated as half of the (natural) logarithmic distance (along the IM axis) between the median intensities (i.e. 50 % probability) of the RF's derived with 16 % (denoted as IM84) and 84 % (IM16) confidence levels, respectively; i.e. . The RF and its confidence band, the sample fragilities θk,l (where ), the equivalent lognormal parameters and of the RF, the epistemic uncertainty βUF, and finally the intensities IM16 and IM84 are shown in Figs. 2d to 6d in the following Sect. 3.
3.1 Case study 1: the 2009 South Pacific tsunami
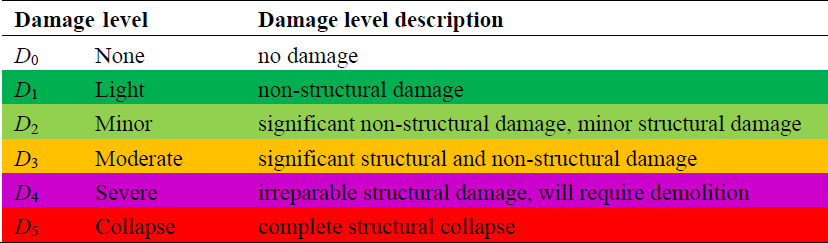
The central South Pacific region-wide tsunami was triggered by an unprecedented earthquake doublet (Mw 8.1 and Mw 8.0) on 29 September 2009, between about 17:48 and 17:50 UTC (Goff and Dominey-Howes, 2011). The tsunami seriously impacted numerous locations in the central South Pacific. Herein, the damage data related to the brick masonry residential (1 storey) and Timber residential buildings associated with the reconnaissance survey sites of American Samoa and the Samoan Islands were utilised. Based on the observed damage regarding different indicators (see Reese et al., 2011 for more details on damage observation), each structure was assigned a damage state between (DS0 and DS5). The original data documented in Reese et al. (2011) reporting the tsunami flow depth and the attributed damage state to each surveyed building can be found on the site of the European Tsunami Risk Service (https://eurotsunamirisk.org/datasets/, last access: 30 November 2022). The five damage levels (NDS=5) and a description of the indicators leading to the classification of the damage states are given in Table 1 based on Reese et al. (2011).
Table 1The classification of damage thresholds (the damage scale) used for the 2009 South Pacific tsunami (from Reese et al., 2011).
3.2 Case study 2: the 2018 Sulawesi–Palu tsunami
On Friday 28 September 2018, at 18:02 local time, a shallow strike-slip earthquake of moment magnitude Mw 7.5 occurred near Palu City, Central Sulawesi, Indonesia followed by submarine landslides, a tsunami, and massive liquefaction caused substantial damage (Muhari et al., 2018; Rafliana et al., 2022). In Sulawesi, more than 3300 fatalities and missing people, 4400 serious injuries and 170 000 people were displaced by earthquake, tsunami, landslides, liquefaction or building collapse, or combinations of these hazards (Paulik et al., 2019; Mas et al., 2020). Herein, the damage data related to the non-engineered unreinforced clay brick masonry (1 and 2 storey) and non-engineered light timber buildings located in Palu City were utilised. Based on the observed damage (see Paulik et al., 2018 for details on damage observation), each structure was assigned a damage state between (DS0 and DS3). The original data reporting the tsunami flow depth and the attributed damage state to each surveyed building can be found as the Supplement to Paulik et al. (2018). The three damage levels (NDS=3) and a description of the indicators leading to the classification of the damage state are given in Table 2.
Table 2The classification of damage thresholds (the damage scale) used for the 2018 Sulawesi–Palu tsunami (from Paulik et al., 2019).

3.3 The building classes
Table 3 illustrates the building classes, for which fragility curves are obtained based on the proposed procedure and based on the databases related to the two tsunami events described above. The taxonomy used for describing the building class matches the original description used in the raw databases. The number of data points available for different building classes showcases both classes with large number of data available, e.g. brick masonry 1 storey (South Pacific) and non-engineered brick masonry 1 storey (Sulawesi), and classes with few data points available, e.g. timber residential (South Pacific) and non-engineered masonry 2 storeys and timber (Sulawesi). The fifth column in the table shows the proportion of the number of damage levels for which observed data are available N (see Sect. 2.1) to the total number of damage levels in the corresponding damage scales, namely for South Pacific and for Sulawesi tsunami events (to include level 0). If the ratio is equal to unity, it indicates that data are available for all the damage levels from 0 to NDS. Note that the number of fragility curves derived is going to be equal to N−1, that is, equal to the number of damage levels for which observed damage data are available minus one.

3.4 The different model classes
For each building class considered, we have considered the set of candidate models consisting of the fragility models resulting from the three alternative link functions used in the generalised linear regression in Eq. (5). That is, 𝕄1 refers to hierarchical fragility modelling based on “logit”, 𝕄2 refers to hierarchical fragility modelling based on “probit”, and 𝕄3 refers to hierarchical fragility modelling based on “cloglog”. For each model, both the MLE method using the MATLAB generalised regression toolbox and the BMCS using the procedure described in the previous section are implemented.
3.5 Fragility modelling using MLE
The first step towards fragility assessment by employing the MLE method (see Sect. 2.3) is to define the vector of model parameters , where and where vector index is defined in Sect. 2.1 as the vector of damage level indices (in ascending order) for which observed damage data are available and N is the length of index. To accomplish this, the model parameters are obtained by fitting the link functions in Eq. (5) to conditional fragility according to Eq. (6). Herein, we have used MATLAB as a statistical software package (developed by MathWorks) to estimate the maximum likelihood of model parameters using the following MATLAB command: glmfit. The `model' will be either `logit', `probit', or `comploglog'. For each damage level Dj+1, , the vector xj is the IM's for which the condition D≥Dj is satisfied; yj is the column vector containing one-to-one probability assignment to the IM data in xj, with zero (=0.0) assigned to those data corresponding to DSj () and one (=1.0) to those related to higher damage states (with ).
The vectors defining the MLE of the model parameters, θMLE, are presented in Table 4 for each of the building classes listed in Table 3 and for each of the three models 𝕄1, 𝕄2, and 𝕄3 defined in Sect. 3.4. Given the model parameter θMLE, the damage state probability P(DSj|IM) can be estimated based on the recursive Eqs. (7) and (8). Then, the fragility for the ultimate damage level is calculated first based on Eq. (8). For the lower damage thresholds, the empirical fragility is derived based on Eq. (9). The resulting hierarchical fragility curves by employing the direct fragility assessment given θMLE, i.e. for , are shown later in the next section by comparison with those obtained from the BMCS method.
3.6 Fragility modelling using BMCS
In the first step, the model parameters are estimated for each model class separately. For each model class 𝕄k, the model parameters θk are estimated through the adaptive MCMC method described in detail in Appendix E, which yields the posterior distribution in Eq. (14). With reference to Eq. (14), the prior joint PDF p(θk|𝕄k) is a multivariate normal PDF with zero correlation between the pairs of model parameters (see Appendix D). The vector of the mean values, μθ is set to be the MLE tabulated in Table 4 (=θMLE related to 𝕄k). We have attributed a high value for the coefficient of variation (more than 3.20 herein) for each of the model parameters. Appendix F illustrates the histograms representing the drawn samples from the joint posterior PDF p(θk|D,𝕄k) for a selected building class.
The RF curves derived from the hierarchical fragility curves (see Sect. 2.5) and the corresponding plus/minus 1 standard deviation (±1σ) intervals from Eqs. (16) and (17) are also plotted in Figs. 2a to 6a corresponding to Classes 1–2 South Pacific tsunami and Classes 1–3 Sulawesi–Palu for one of the model classes 𝕄k and for the damage thresholds Dj, . The colours of the hierarchical robust fragility curves, labelled as Dj-BMCS, match closely with those shown in Tables 1 and 2. The corresponding ±1σ confidence interval curve, which reflects the uncertainty in the model parameters, is shown as a light grey area with different colour intensities. Figures 2b to 6b compare the hierarchical robust fragility and its confidence interval with the result of hierarchical fragility assessment based on maximum likelihood estimation (see previous Sect. 3.5) labelled as Dj-MLE. The fragility curves are shown with similar colours (and darker intensity) and with the same line type (and half of the thickness) of the corresponding robust fragility curves. The first observation is that the results of MLE-based fragilities and the BMCS-based fragilities are quite close in all damage thresholds (as expected, see Jalayer and Erahimian, 2020). Moreover, the BMCS provides also the confidence bands for the fragility curves, which cannot be directly provided by the MLE method. To showcase an individual fragility curve, Figs. 2c to 6c illustrate the empirical fragility curves associated with the lth realisation of the vector of model parameters θk,l for model class 𝕄k (where l is defined on each figure separately), i.e. (see Sect. 2.5). Figures 2d to 6d illustrate the robust fragility curve associated with the ultimate damage threshold Dindex(N), together with all the sample fragilities. The intensity values for which the damage level is not exceeded are shown with blue circles having the probability equal to zero. Other IMs that lead to the exceedance of the damage level are shown with red circles with a probability equal to one. Figures 2d to 6d also illustrate all the fragility parameters described in Sect. 2.5 including the equivalent lognormal parameters and ; the epistemic uncertainty in the empirical fragility assessment βUF; and also the intensities , , IM84, and IM16 (the latter two are IMs at the median, i.e. 50 % probability, from the RF ±1 standard deviation, respectively. For all five building classes considered (see Table 3), , , and βUF are tabulated in Table 5 for all damage thresholds associated to model classes 𝕄1 to 𝕄3.
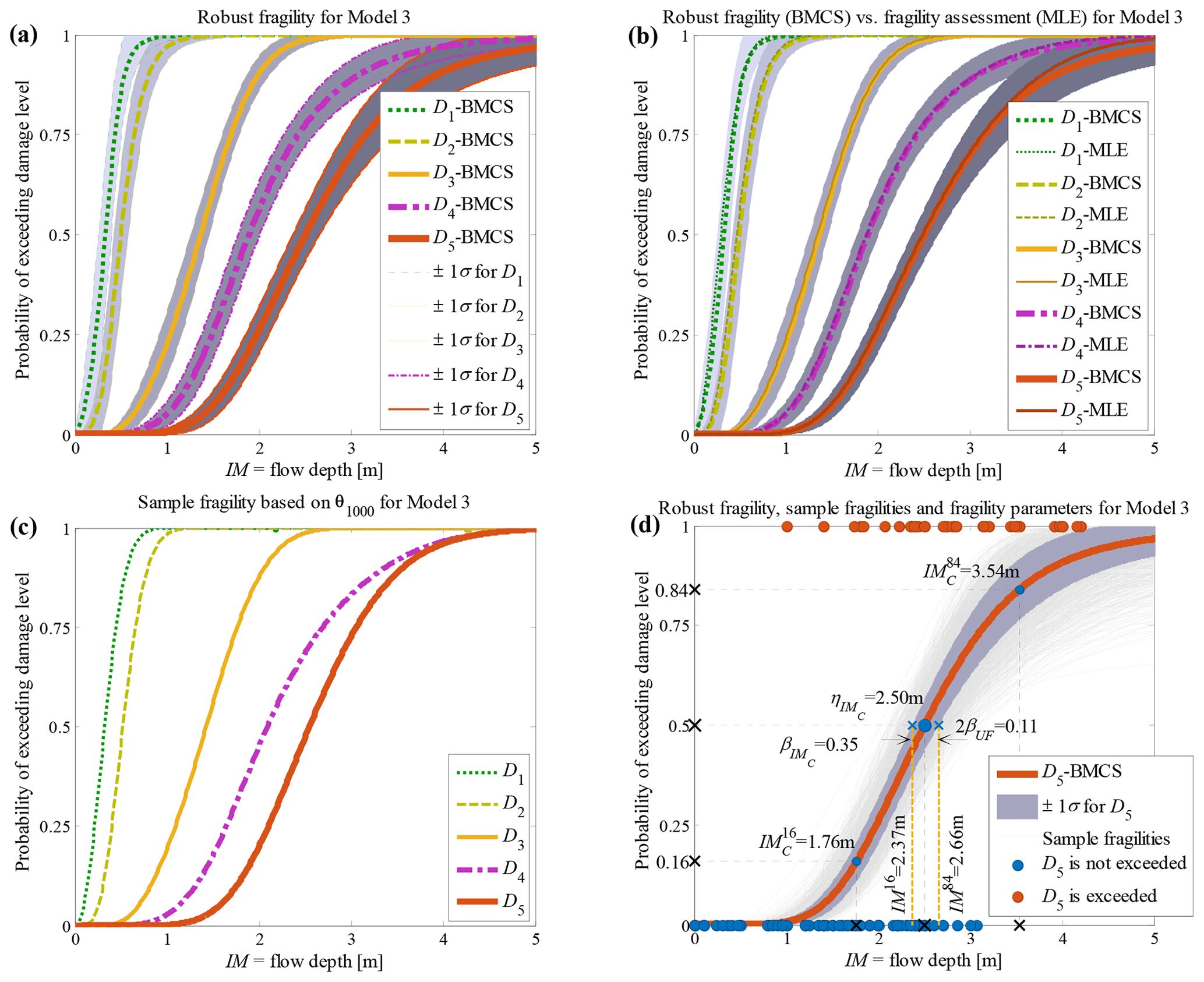
Figure 2Building class 1 (brick masonry residential, 1 storey) of the South Pacific 2009 tsunami considering fragility model class 𝕄3 (a) hierarchical robust fragility curves and their ±1 standard deviation confidence intervals; (b) comparison between hierarchical robust fragility curves and their confidence band (based on BMCS method) and fragility assessment based on MLE method; (c) the fragility curves , where associated with the 1000th realisation of the model parameters, θ3,1000 (k=3 associated to model 𝕄3, l=1000); and (d) RF associated with the damage threshold D5, together with all the sample fragilities and the equivalent lognormal fragility parameters.
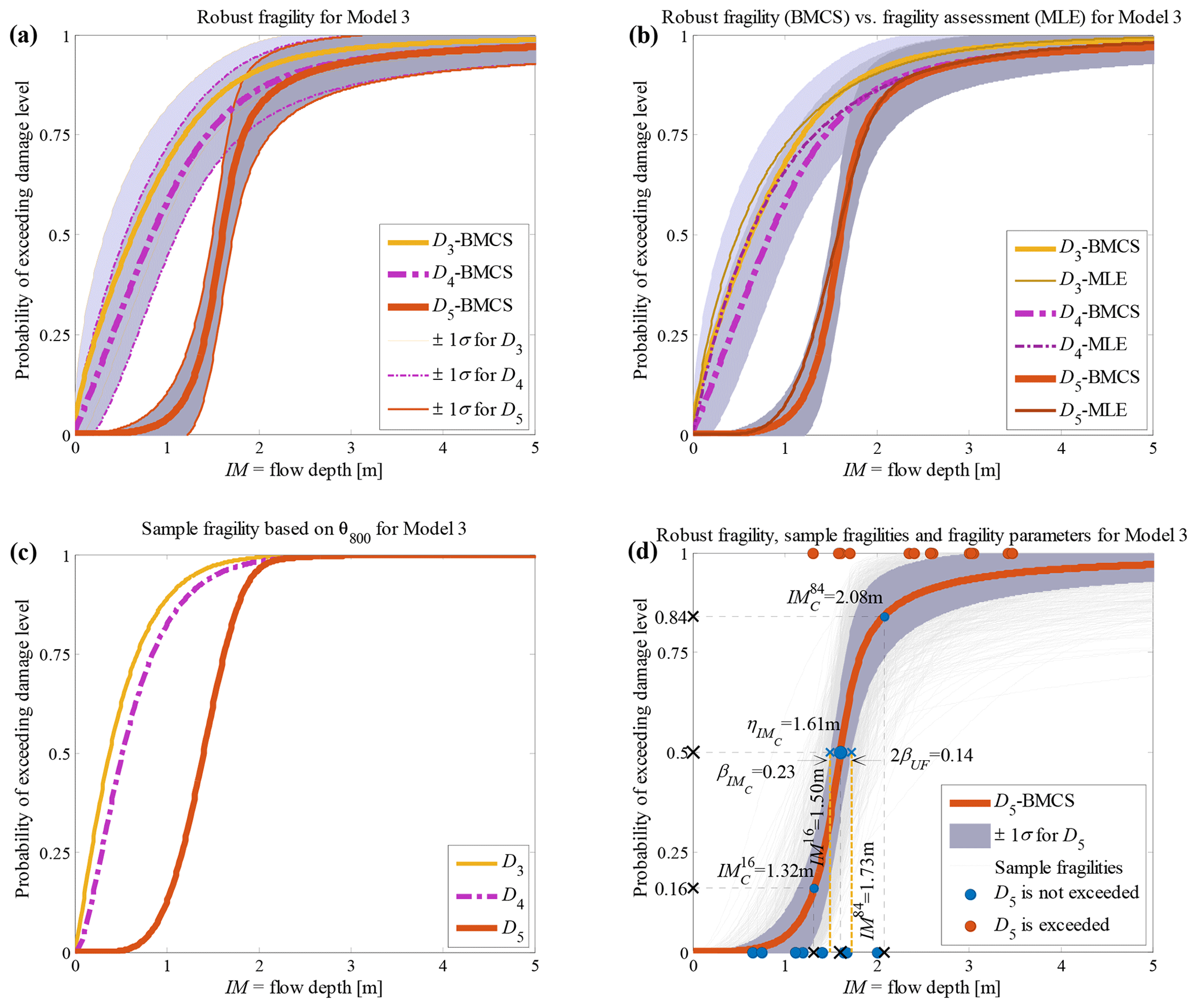
Figure 3Building class 2 (timber residential) of the South Pacific 2009 tsunami considering fragility model class 𝕄3 (a) hierarchical robust fragility curves and their ±1 standard deviation confidence intervals; (b) comparison between hierarchical robust fragility curves and their confidence band (based on BMCS method) and fragility assessment (based on MLE method); (c) the fragility curves where associated with the 800th realisation of the model parameters, θ3,800 (k=3 associated to model 𝕄3, l=800); and (d) robust fragility associated with the damage threshold D5, together with all the sample fragilities and the equivalent lognormal fragility parameters.
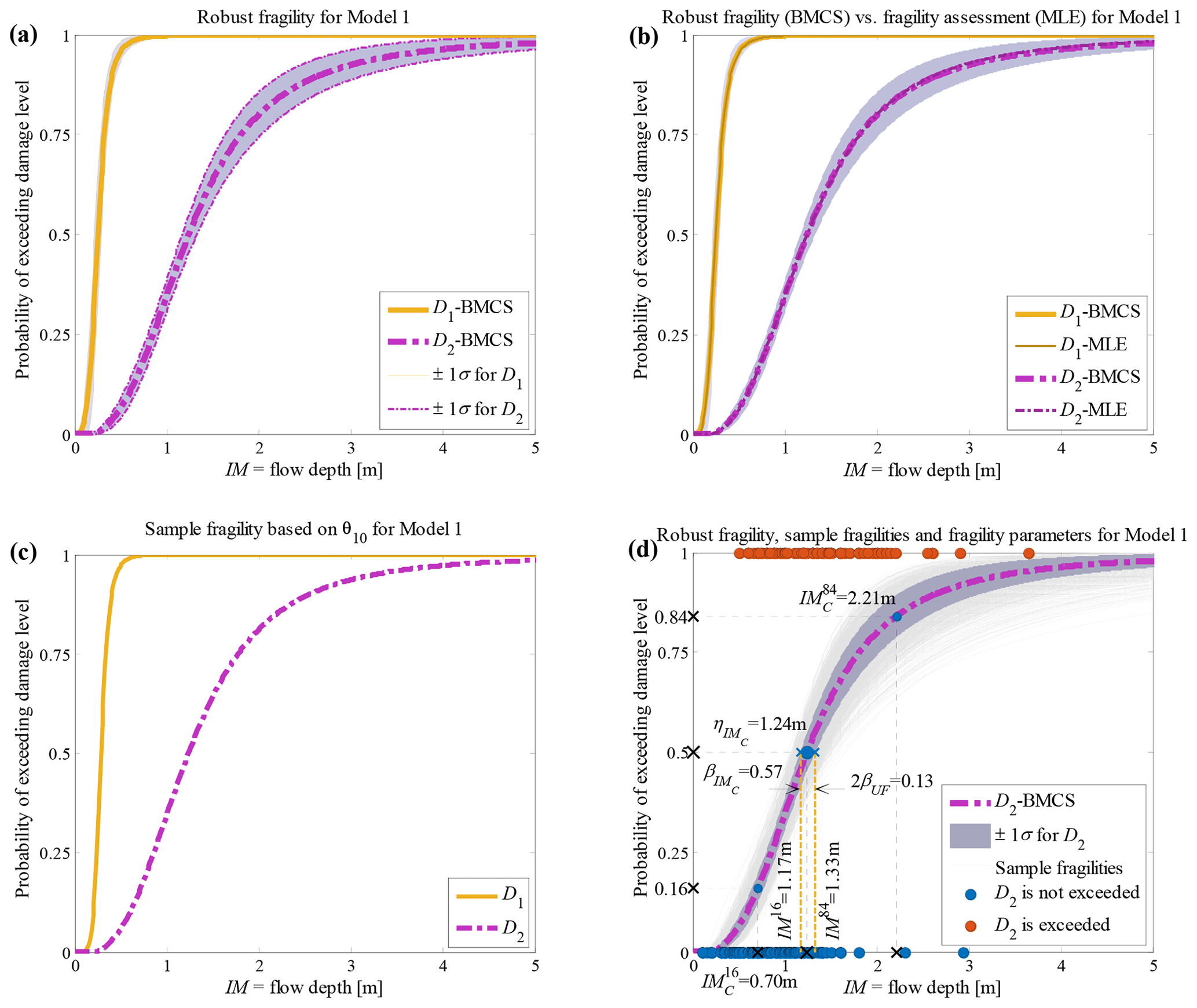
Figure 4Building class 1 (non-engineered masonry, unreinforced with clay brick, 1 storey) of the Sulawesi–Palu 2018 tsunami considering fragility model class 𝕄1 (a) robust fragility curves (RF) and their ±1 standard deviation confidence intervals; (b) comparison between hierarchical robust fragility and its confidence band (based on BMCS method) and fragility assessment based on MLE method; (c) the fragility curves , where associated with the 10th realisation of the model parameters, θ1,10 (k=1 associated to model 𝕄1, l=10); and (d) robust fragility curve associated with the damage threshold D2, together with all the sample fragilities and the equivalent lognormal fragility parameters.
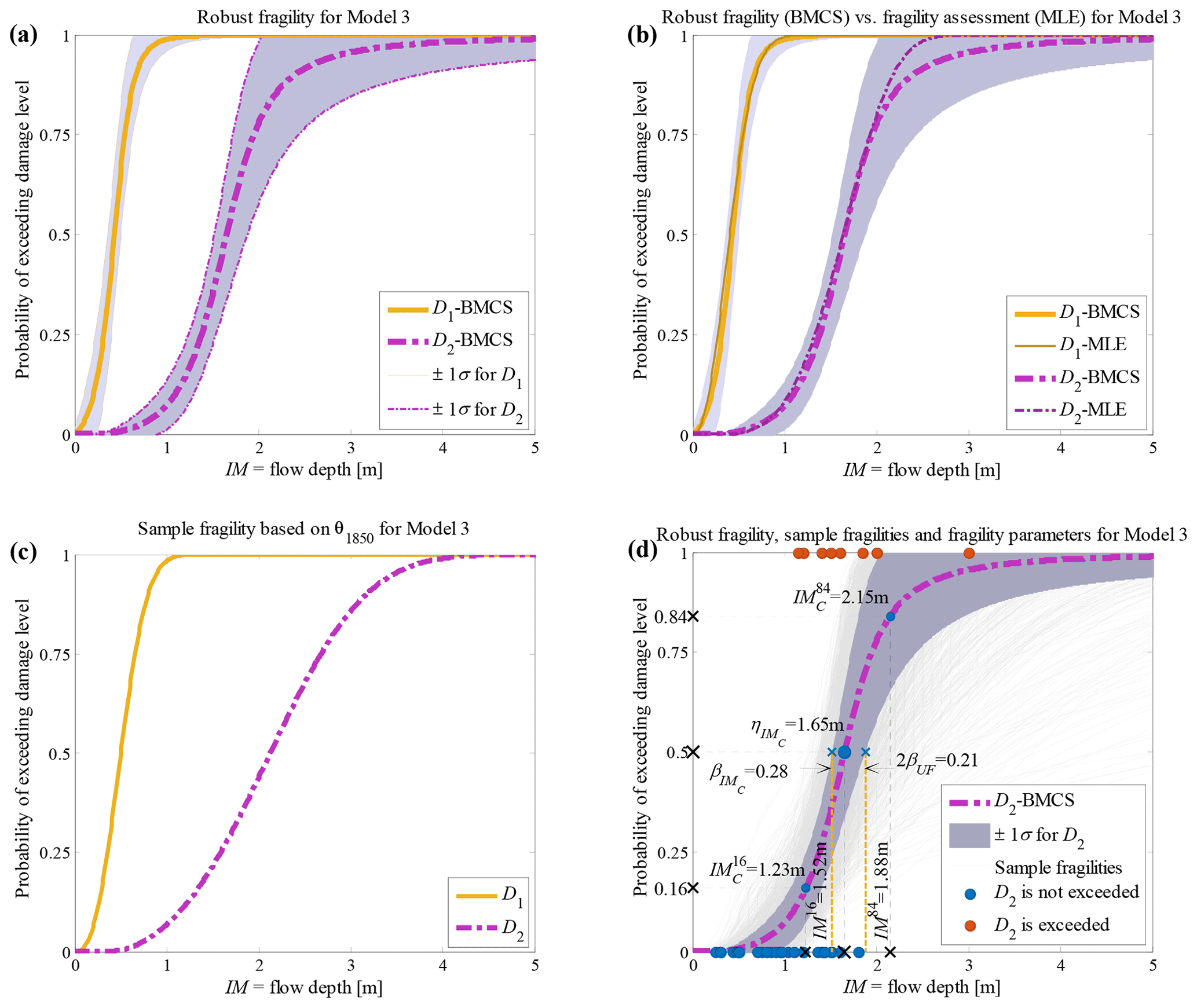
Figure 5Building class 2 (non-engineered masonry, unreinforced with clay brick, 2 storey) of the Sulawesi–Palu 2018 tsunami considering fragility model class 𝕄3 (a) hierarchical robust fragility curves and their ±1 standard deviation confidence intervals; (b) comparison between robust fragility and its confidence band (based on BMCS method) and fragility assessment based on MLE method; (c) the fragility curves , where associated with the 1850th realisation of the model parameters, θ3,1850 (k=3 associated to model 𝕄3, l=1850); and (d) robust fragility curve associated with the damage threshold D2, together with all the sample fragilities and the equivalent lognormal fragility parameters.
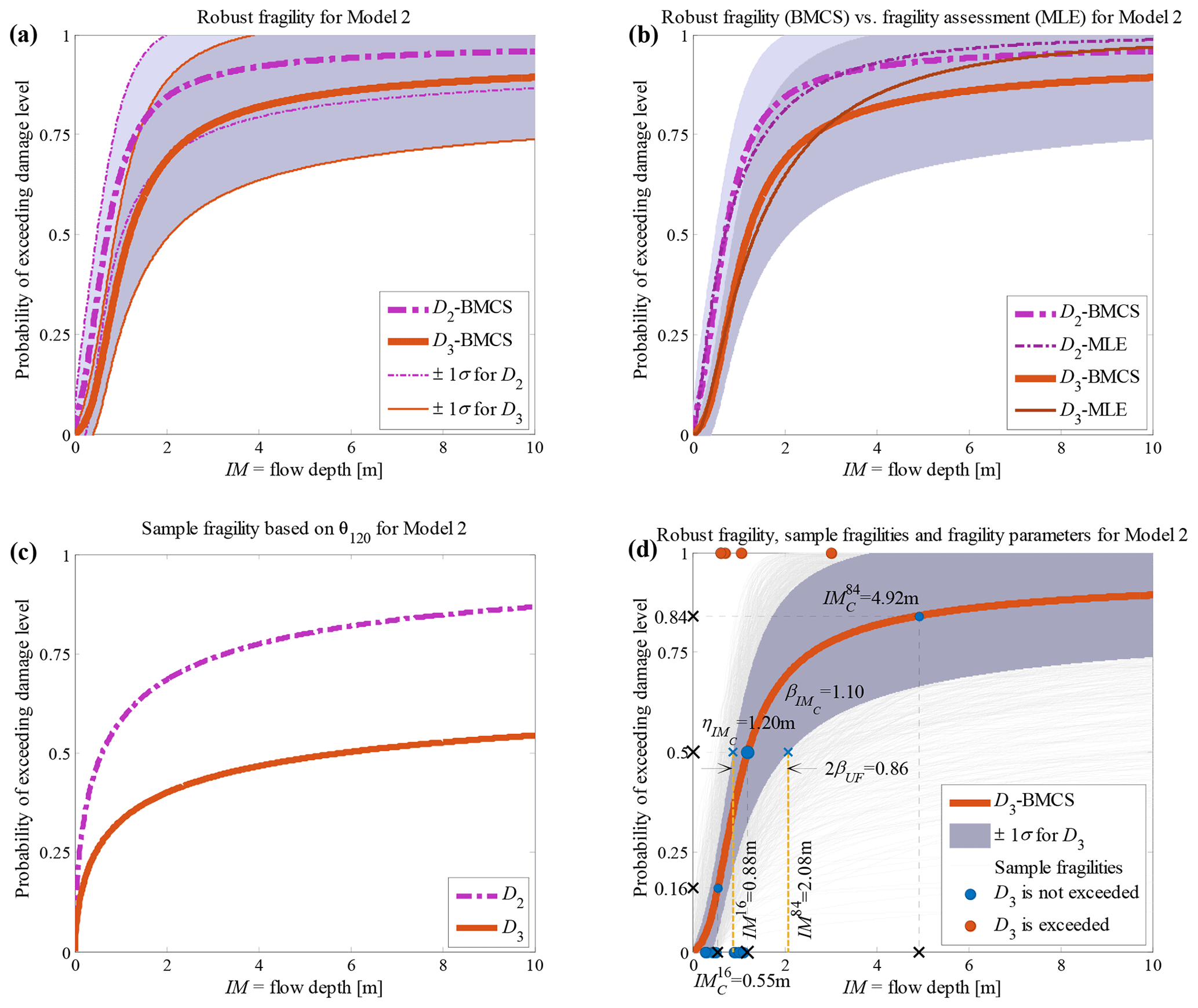
Figure 6Building class 3 (non-engineered light timber) of the Sulawesi–Palu 2018 tsunami considering fragility model class 𝕄2 (a) hierarchical robust fragility curves and their ±1 standard deviation confidence intervals; (b) comparison between robust fragility and its confidence band (based on BMCS method) and fragility assessment based on MLE method; (c) the fragility curves , where associated with the 120th realisation of the model parameters, θ2,120 (k=2 associated to model 𝕄2, l=120); and (d) robust fragility curve associated with the damage threshold D3, together with all the sample fragilities and the equivalent lognormal fragility parameters.
Table 5The equivalent lognormal parameters and the epistemic uncertainty in the RF assessment for all the building classes, damage thresholds, and model classes 𝕄1 to 𝕄3.
3.7 Model selection
With reference to Eq. (12), the log-evidence ln [p(D|𝕄k)] can be estimated by subtracting Term 2 from Term 1. Term 1 denotes the posterior mean of the log likelihood, and Term 2 is the relative entropy between the prior and the posterior. Within the BMCS method, these two terms are readily computable.
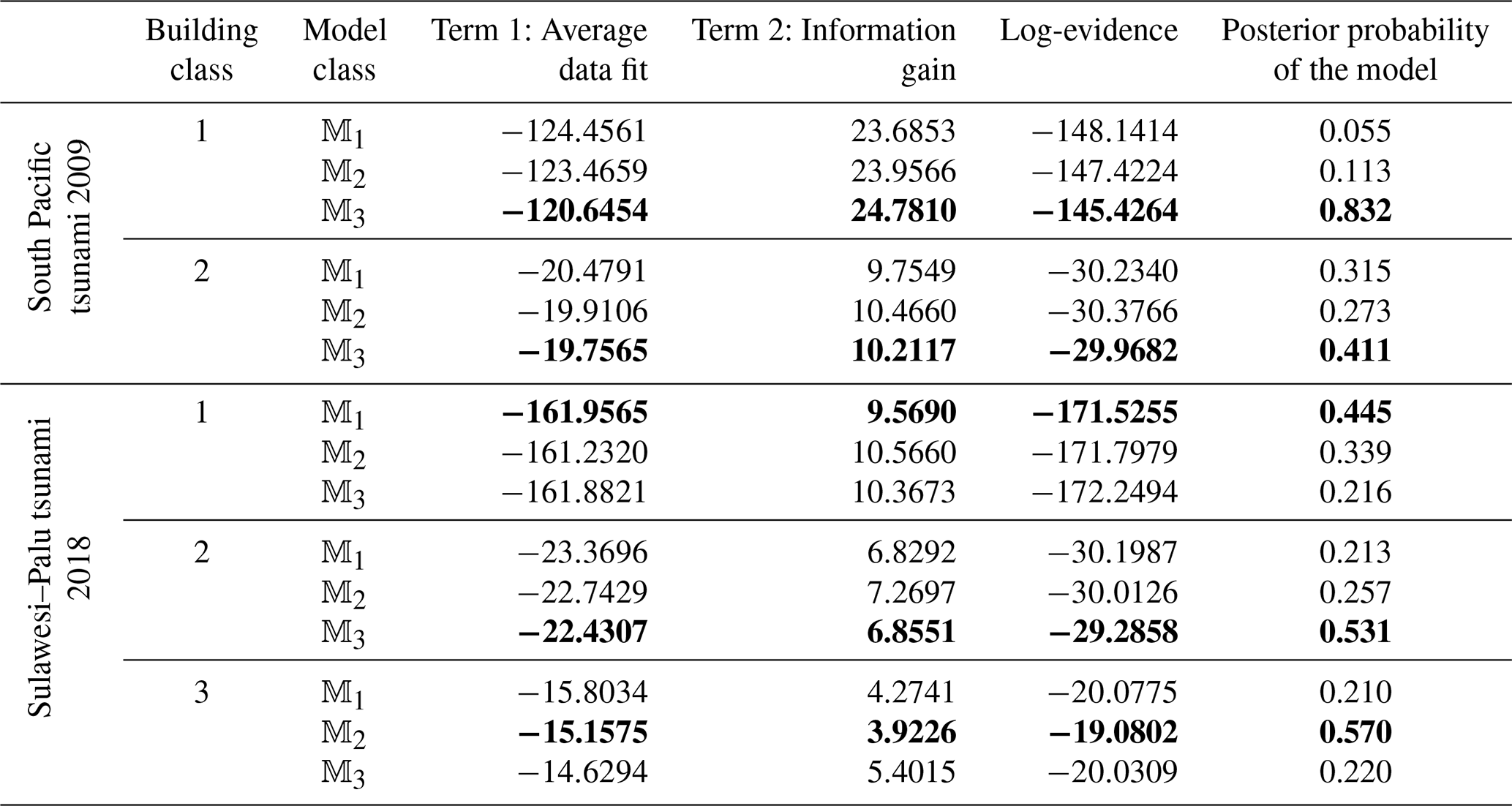
Given the samples generated from the joint posterior PDFs θk, Term 1 (the average data fit) can be seen as the expected value of the log likelihood over the vector of fragility parameters θk given the model 𝕄k, i.e. . Term 2 (the relative entropy) is calculated as the expected value of information gain or entropy between the two PDFs posterior and prior over the vector θ given the model 𝕄k, i.e. . It is noted that based on Jensen's inequality, the mean information gain (relative entropy) of the posterior compared to the prior is always non-negative (see e.g. Jalayer et al., 2012; Ebrahimian and Jalayer, 2021). Hence, Term 2 should always be positive. Herein, p(θk|D,𝕄k) is constructed by an adaptive kernel density function (see Eq. E5, Appendix E) as the weighted sum (average) of Gaussian PDFs centred among the samples θk given model 𝕄k (). The prior p(θk|𝕄k) is a multivariate normal PDF, respectively, with the mean and covariance described previously for each model (see Eq. D1 in Appendix D). Table 6 shows the results for model class selection for all five building classes considered. The last column illustrates the posterior probability (weight) of the model P(𝕄k|D) according to Eq. (10) assuming that the prior (where ). The best model for each building class is shown in bold.
For instance, for Class 1 (masonry residential) for the South Pacific tsunami, model class 𝕄3 (using a complementary log–log “cloglog” transformation of πij to the linear logarithmic space, see Eq. 5) is preferred, since it has an overall larger difference between data fit and mean information gain, which leads to a higher log-evidence. The posterior weights (last column of Table 6, see also Eq. 10) of 6 %, 11 % and 83 % are stabilised through different runs of the BMCS method. It should be noted that in Figs. 2 to 6 we reported directly the fragility results for the “best” fragility model class (i.e. the one that maximises log evidence) identified based on the procedure described here.
Table 6Bayesian model class selection results for empirical fragility models. The best model for each building class is shown in bold.
3.8 The “basic” (MLE-Basic) method: fitting data to one damage state at a time
In the basic method (see Sect. 2.2), the fragility P(D≥Dj|IM) is obtained by using a generalised linear regression model according to Eq. (5) with logit, probit or cloglog link function fitted to the damage data (𝕄k where ). With reference to the MLE method described previously, the vector xj herein is the IM associated with all damage data (and not partial, as in the hierarchical fragility method described in Sect. 3.3), and yj is the column vector of one-to-one probability assignment to the IM data in xj, with zero (=0) assigned to those data with an observed damage threshold D<Dj and one (=1) to those with D≥Dj. Thus, for the empirical fragility associated with the damage threshold Dj, and based on the model 𝕄k, there are two model parameters to be defined, namely . As noted previously, there might be conditions (depending on the quantity of the observed damage data) where a part of the fragility of damage threshold Dj lies below the fragility of the higher damage level Dj+1, indicating that This is due to the fact that in the traditional method there is no explicit requirement to satisfy P(DSj|IM)>0 as compared to the proposed method. The MLE of model parameters {α0,α1} for the damage levels Dj, associated with the building classes in Table 3 are presented in Table 7.
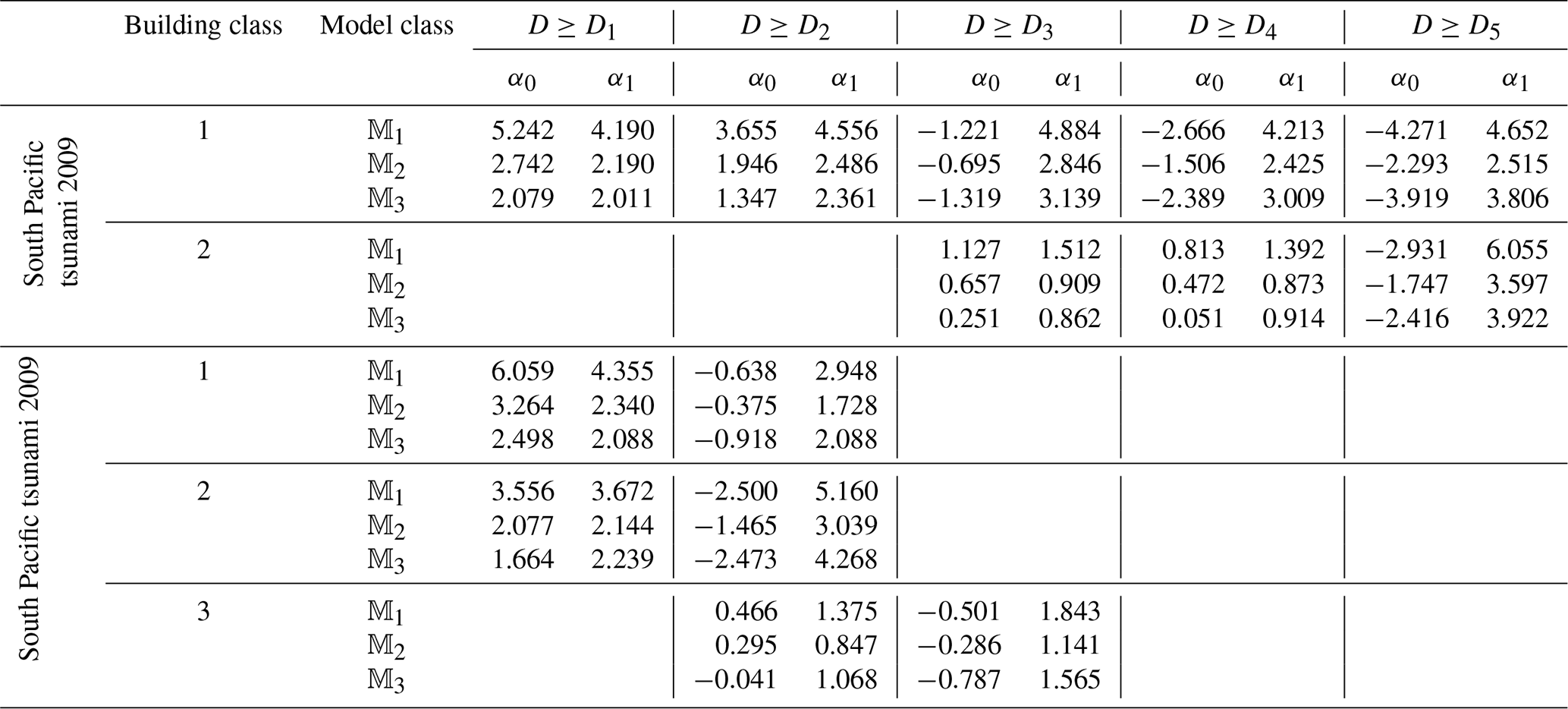
Figure 7 compares the fragility assessment obtained based on MLE-based hierarchical fragility modelling (see also the MLE-based curves in Figs. 2b to 6b) with the result of the fragility assessment by employing the MLE-Basic method for the “best” model class 𝕄k identified according to the procedure outlined in the previous section. It is noted that the fragility functional form is different between the two methods. MLE-based fragility assessment given 𝕄k uses Eqs. (7) to (9) to construct a hierarchical fragility curve given that the conditional fragility term , has one of the functional forms in Eq. (5). However, the fragility assessment using the MLE-Basic method employs directly one of the expressions in Eq. (5) (corresponding to 𝕄k, ) to derive the fragility curve (based on the whole damage data) and . This difference manifests itself in Fig. 7a (for brick masonry residential, Class 1, South Pacific tsunami) as the deviation between the two fragility models for higher damage thresholds D4 and D5. The deviations between the fragility curves are particularly noticeable at higher IM values (with exceedance probability >50 %); however, their medians are quite similar. In Fig. 7b for (timber residential buildings, Class 2, South Pacific tsunami) and 7e (light informal timber buildings, Class 3, Sulawesi–Palu tsunami), we can observe that fragility curves intersect in the case of the MLE-Basic fragility assessment. However, they do not intersect for hierarchical fragility curves. The intersection points of the consequent damage states Dj+1 with Dj when using the MLE-Basic fragility estimation method are shown with colour stars on each figure.
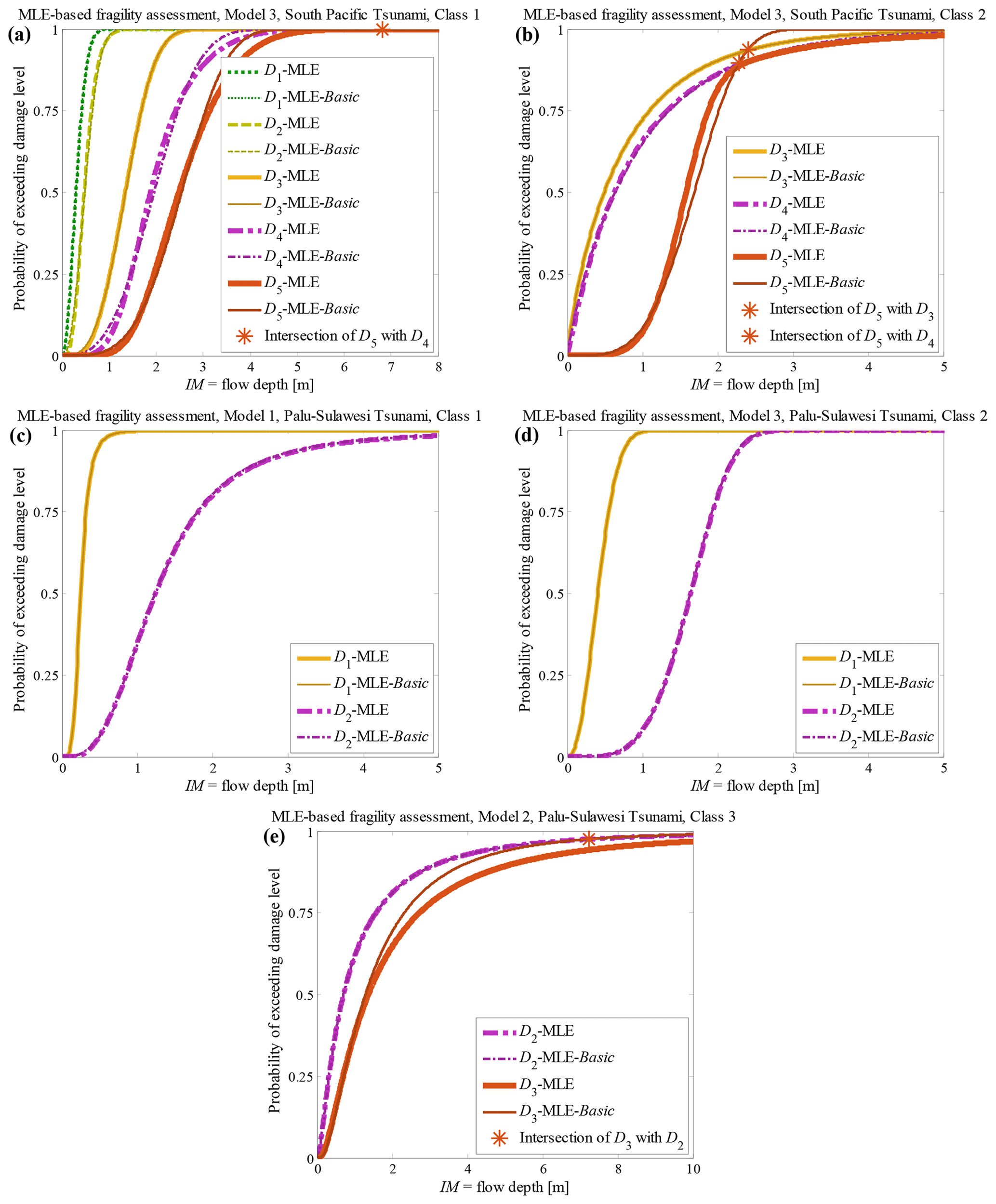
Figure 7Comparison between the fragility assessment by MLE-based hierarchical fragility modelling and MLE-Basic fragility assessment given (a) South Pacific 2009 tsunami, Class 1, 𝕄3; (b) South Pacific 2009 tsunami, Class 2, 𝕄3; (c) Sulawesi–Palu 2018 tsunami, Class 1, 𝕄1; (d) Sulawesi–Palu 2018 tsunami Class 2, 𝕄3; and (e) Sulawesi–Palu 2018 tsunami Class 3, 𝕄2.
Table 8 reports the fragility assessment parameters of the MLE and MLE-Basic methods for the damage thresholds Dindex(2) to Dindex(N) with the equivalent lognormal parameters and (explained in Sect. 2.5) for 𝕄1 to 𝕄3 for all five classes considered. The medians are almost identical among the four models while there are higher dispersion estimates for the MLE method derived by hierarchical fragility modelling.
Table 8Comparison between fragility assessment based on MLE method (by hierarchical fragility modelling) and the MLE-Basic method for damage thresholds Dindex(2) to Dindex(N).

The results outlined in this section show a fragility assessment for two different data sets corresponding to observed damaged in the aftermath of South Pacific and Sulawesi–Palu tsunami events. We have demonstrated the versatility of the proposed workflow and tool for hierarchical fragility assessment both for cases in which a large number of data points are available (e.g. Class 1, brick masonry residential, South Pacific tsunami; Class 1, one-storey non-engineered masonry, Sulawesi–Palu tsunami) and cases where very few data points are available (e.g. Class 2, timber residential, South Pacific tsunami; Class 3, non-engineered light timber, Sulawesi–Palu tsunami). Moreover, we demonstrated how the proposed workflow avoids crossing fragility curves (e.g. Class 2, timber residential, South Pacific tsunami; Class 3, non-engineered light timber, Sulawesi–Palu tsunami). The results illustrated for the five building classes demonstrate that the proposed workflow for hierarchical fragility assessment can be applied in cases in which data points are not available for all the damage levels within the damage scale.
An integrated procedure based on Bayesian model class selection (BMCS) for empirical hierarchical fragility modelling for a class of buildings or infrastructure is presented. This procedure is applicable to fragility modelling for any type of hazard as long as the damage scale consists of mutually exclusive and collectively exhaustive (MECE) damage states, and the observed damage data points are independent. This simulation-based procedure can (1) perform hierarchical fragility modelling for MECE damage states, (2) estimate the confidence interval for the resulting fragility curves, and (3) select the simplest model that fits the data best (i.e. maximises log evidence) amongst a suite of candidate fragility models (herein, alternative link functions for generalised linear regression are considered). The proposed procedure is demonstrated for empirical fragility assessment based on observed damage data to masonry residential (1 storey) and timber residential buildings due to the 2009 South Pacific tsunami in American Samoa and the Samoan Islands and non-engineered masonry buildings (1 and 2 storeys) and non-engineered light timber buildings due to the 2018 Sulawesi–Palu tsunami. It is observed that
-
For each model class, the same set of simulation realisations is used to estimate the fragility parameters, the confidence band and the log evidence. The latter, which consists of two terms depicting the goodness of fit and the information gain between posterior distribution resulting from the observed data and the prior distribution, is used to compare the candidate fragility models to identify the model that maximises the evidence.
-
Hierarchical fragility assessment can be done also based the maximum likelihood estimation (MLE) and the available statistical toolboxes (e.g. MATLAB's generalised linear model). For each damage level, the reference domain should be the subset of data that exceeds the consecutive lower damage level, instead of taking the entire set of data points as reference domain. Note that the basic fragility estimation (“MLE-Basic”, non-hierarchical fragility model) fits the damage data for each damage level at a time. In other words, the reference domain is set to all damage data.
-
The procedure is also applicable to cases in which observed data are available only for a subset of the damage levels within the damage scale. The number of fragility curves is going to be equal to the total number of damage levels for which data are available minus one. This means, in order to have at least one fragility curve, one needs to have data available for at least two damage levels.
-
Although the resulting fragility curves are not lognormal (strictly speaking), equivalent statistics work quite well in showing the fragility curves (median and logarithmic dispersion) and the corresponding epistemic uncertainty (logarithmic dispersion).
-
The proposed BMCS method and the one based on MLE lead to essentially the same set of parameter estimates for hierarchical fragility estimation. However, the latter does not readily lead to the confidence band and log evidence.
-
Using the basic method for fragility estimation (MLE-Basic) leads to results that are slightly different from the hierarchical fragility curves. The difference grows for higher damage levels. It is important to note that following the basic method MLE-Basic led to ill-conditioned results (i.e. fragility curves crossing) in some of the cases (Class 2 for the South Pacific tsunami and Class 3 for the Sulawesi–Palu tsunami, both Timber constructions) studied in this work.
The major improvement offered by this method is in providing a tool that can fit fragility curves to a set of hierarchical levels of damage or loss in an ensemble manner. This method, which starts from prescribed fragility models and explicitly ensures the hierarchical relation between the damage levels, is very robust in cases where few data points are available and/or where data are missing for some of the damage levels. This tool provides confidence bands for the fragility curves and performs model selection among a set of viable link functions for generalised regression. It is important to note that the proposed method is in general applicable to hierarchical vulnerability modelling for human or economic loss levels and to different types of hazards if (1) the defined levels are mutually exclusive and collectively exhaustive, and (2) a suitable intensity measure (IM) can be identified.
The probability of being in damage state DSj for a given intensity measure IM can be estimated as follows:
where the upper-bar sign stands for the logical negation and is read as “NOT”, and (+) defines the logical sum and is read as “OR”. The above derivation is based on the rule of sum in probability and considers the fact that the two statements D<Dj and are mutually exclusive (ME); thus, the probability of their logical sum is the sum of their probabilities.
The probability of being in damage state DSj (where j≥1) given the intensity measure evaluated at the location of building i, denoted as IMi, based on Eq. (6) can be expanded in a recursive format as follows:
where (+) defines the logical sum and is read as “OR”. The above derivation is based on the rule of sum in probability and considers the fact that the recursive statements in the second term expressed generally as , where , are ME; hence, the probability of their logical sum is the sum of their probabilities. It is important to note that in case where j=0, the above equation can be written as
From an information-based point of view, the logarithm of the evidence (log-evidence), denoted as ln [p(D|𝕄k)], can provide a quantitative measure of the amount of information as evidence of model 𝕄k. Moreover, the posterior PDF p(θk|D,𝕄k) (see Eq. 14) over the domain of the model parameters Ωθ given the kth model is equal to unity. Thus, ln [p(D|𝕄k)] can be written as follows:
Since the log-evidence is independent of θ, we can bring it inside the integral and do some simple manipulation (also using the relation in Eq. 11) as follows:
Let us assume that the vector of parameters for the kth model is set to θ; i.e. θ=θk. A multivariate normal PDF can be expressed as follows:
where n is the number of components (uncertain parameters) of vector ; μθ is the vector of the mean value of θ; and S is the covariance matrix. The positive definite matrix Sn×n can be factorised based on Cholesky decomposition as S=LLT, where Ln×n is a lower triangular matrix (i.e. for all j>i, Lij=0 where Lij denotes the (i, j)-entry of the matrix L). A Gaussian vector θn×1 with mean μθ and covariance S can be generated as follows:
where Zn×1 is a vector of standard Gaussian random variables with zero mean 0n×n and a covariance equal to the identity matrix In×n. To verify the properties of θ, we know that with reference to Eq. (D2), it should have a mean equal to μθ and a covariance matrix equal to S. The expectation of θ, denoted as E(θ), can be estimated as
The covariance matrix of θ can be written as
Thus, the vector θ can be written according to Eq. (D2).
E1 MCMC procedure
The MCMC simulation scheme has a Markovian nature where the transition from the current state to a new state is done by using a conditional transition function that is conditioned on the current (last) state. Let us assume that the vector of parameters for the kth model is set to θ; i.e. θ=θk. To generate (i+1)th sample θi+1 from the current ith sample θi based on MH routine, the following procedure is adopted herein
-
Simulate a candidate sample θ* from a proposal distribution q(θ|θi). It is important to note that there are no specific restrictions about the choice of q(⋅) apart from the fact that it should be possible to calculate both and .
-
Calculate the acceptance probability , where r is defined as follows (it is to note that the following Eq. (E1) is written in the general format for brevity compared to Eq. (14) of the paper, and we have used θ instead of θk and dropped the conditioning on 𝕄k; hence, when we write the ith sample θi it is actually the ith sample drawn from θk and “k” is dropped for brevity):
-
Generate u from a uniform distribution between (0,1), u∼ uniform (0,1).
-
If set (accept the candidate state to be taken as the next state of the Markov chain); else set (the current state is taken as the next state).
Estimating the likelihood in the arithmetic scale based on Eq. (E1) may encounter instability as p(D|θ) may become very small; thus, the likelihood ratio becomes indeterminate. To avoid this numerical instability, it is desirable to substitute the likelihood ratio in Eq. (E1) with if the ratio becomes indeterminate or zero.
With reference to Eq. (E1), samples from the posterior can be drawn based on MH algorithm without any need to define the normalising C−1 coefficient according to Eq. (14). Equation (E1) always accepts a candidate if the new proposal is more likely under the target posterior distribution than the old state. Therefore, the sampler will move towards the regions of the state space where the target posterior function has high density.
The choice of the proposal distribution q is very important. The ratio corrects for any asymmetries in the proposal distribution. Intuitively, if , the candidate state is always accepted (with r=1); thus, the closer q is to the target posterior PDF, the better the acceptance rate and the faster the convergence. This is not a trivial task as information about the important region p(θ|D) is not available. If the proposal distribution q is non-adaptive, it means that the information of the current sample θi is not used to explore the important region of the target posterior distribution p(θ|D); thus, we can say that . Therefore, it is more desirable to choose an adaptive proposal distribution which depends on the current sample (Beck and Au, 2002). Having the proposal PDF q centred around the current sample renders the MH algorithm like a local random walk that adaptively leads to the generation of the target PDF. However, if the Markov chain starts from a point that is not close to the region of the significant probability density of p(θ|D), the chance of generating a candidate state θ* will become extremely small (and we will face high rejection of candidate samples). Therefore, most of the samples will be repeated. To solve this problem, Beck and Au (2002) introduce a sequence of PDFs that bridge the gap between the prior PDF and the target posterior PDF. This issue will be further explored hereafter under the adaptive MCMC. Finally, it can mathematically be shown that (see Beck and Au, 2002) if the current sample θi is distributed as , the next sample θi+1 is also distributed as .
E2 Adaptive Metropolis–Hastings algorithm (adaptive MCMC)
The adaptive MH algorithm (Beck and Au, 2002) introduces a sequence of intermediate candidate evolutionary PDF's that resemble more and more the target PDF. Let be the sequence (chain) of PDFs leading to , where Nchain is the number of chains and each chain contains Nd samples (as indicated subsequently). The following adaptive simulation-based procedure is employed:
Step 1. Simulate Nd samples , where the superscript (1) denotes the first simulation level or the first chain (nc =1, where nc denotes the chain number/simulation level), with the target PDF p1 as the first sequence of samples. Instead of accepting or rejecting a proposal for θ involving all its components simultaneously (called block-wise updating scheme), it might be computationally simpler and more efficient for the first chain to make proposals for individual components of θ one at a time (called component-wise updating approach). In the block-wise updating, the proposal distribution has the same dimension as the target distribution. For instance, if the model parameters involve n uncertain parameters (e.g. the vector of model parameters θn×1 in this paper has variables for each of the three models 𝕄1, 𝕄2, and 𝕄3), we design an n-dimensional proposal distribution and either accept or reject the candidate state (with all n variables) as a block. The block-wise updating approach can be associated with high rejection rates. This may cause problem when we want to generate the first sequence of samples (first chain). Therefore, we have utilised the more stable component-wise updating for the first chain. We start from the first variable and generate a candidate state based on a proposal distribution for this individual component and finally accept or reject it based on MH algorithm. Note that in this stage we have varied the current component and kept the other variables in vector θ constant. Then, we move to the next components one by one and do the same procedure while taking into account the previous (updated) components. Therefore, what happens in the current step is conditional on the updated parameters in the previous steps.
Step 2. Construct a kernel density function κ(1) as the weighted sum (average) of n-dimensional Gaussian PDFs centred among the samples , with the covariance matrix S(1) of the samples and the weights associated to each sample as wi, where as follows (see Ang et al., 1992; Au and Beck, 1999):
The kernel density κ(1) constructed in Eq. (E2) approximates p1. The kernel function κ can be viewed as a PDF consisting of bumps at θi, where width wi controls the common size of the bumps. Therefore, a large value of wi tends to over-smooth the kernel density, while a small value may cause noise-shaped bumps. In view of this, wi can be assumed to have a fixed width (=w), or alternatively the adaptive kernel estimate can be employed (Ang et al., 1992; Au and Beck, 1999) that is defined for each sample θi, . The adaptive kernel has better convergence and smoothing properties over the fixed-width kernel estimate. The fixed width w is estimated as follows (Epanechnikov, 1969):
where Ndist is the number of samples (Ndist≤Nd). For one-dimensional problems (n=1), this leads to the well-known fixed-width value of . In the adaptive kernel method, the idea is to vary the shape of each bump so that a larger width (flatter bump) is used in regions of lower probability density. Following the general strategy used in the past (see Ang et al., 1992; Au and Beck, 1999), the adaptive band width wi for the ith sample θi can be written as wi=wλi, where the local bandwidth factor λi can be estimated as follows:
where is the sensitivity factor, and κ(θi) is calculated based on Eq. (E2) where θ=θi, with the choice of fixed-width w in Eq. (E3). The denominator in Eq. (E4) is a geometric mean of the kernel estimator at all Nd points. The value of ω=0.50 is employed herein as also suggested by other research endeavours (Abramson, 1982; Ang et al., 1992; Au and Beck, 1999). It is numerically more stable to estimate the denominator in Eq. (E4) as .
Step 3. Simulate Nd Markov chain samples with the target PDF p2 as the second simulation level (nc =2). We use κ(1) as the proposal distribution q(⋅) in Eq. (E1) in this stage to generate the second chain of samples. To generally simulate sample θ from the kernel κ(nc) (where nc ), we generate a discrete random index from the vector with the corresponding weights using an inverse transformation sampling; if index =j, then generate θ from the Gaussian PDF κj, where
where , where S(nc) is the covariance matrix of the samples . Appendix D shows how a sample θ can be drawn from the Gaussian PDF κi. From this sequence on, the MCMC updating is done in a block-wise manner as we generate a candidate θ and accept/reject it as a block. The second chain of samples are then used to construct the kernel density κ(2) based on Eq. (E2).
Step 4. In general, κ(nc) is used as the proposal distribution in order to move from the ncth simulation level (which approximates pnc) into (nc+1)th chain (with target PDF pnc+1). This will continue until the Nchainth simulation level where Markov chain samples are simulated for the target updated .
The adaptive MCMC procedure for drawing samples from the model parameters from the joint posterior PDF p(θk|D𝕄k) is carried out by considering Nchain=6 chains (simulation levels) and Nd=2000 samples per each chain (see Appendix E). In the first simulation level (first chain, nc=1), for which a component-wise updating approach is employed (see Appendix E, Step 1 for the description of component-wise and block-wise updating), the first 20 samples are not considered in order to reduce the initial transient effect of the Markov chain. The proposal distribution (see Eq. E1) for each component is assumed to be a normal distribution with a coefficient of variation COV =0.30 herein. In addition, the prior ratio according to Eq. (E1) will become the ratio of two normal distributions for each component one at a time. In the next simulation levels (i.e. ), the adaptive kernel estimate (Eq. E2) is employed; i.e. the MCMC updating is performed in a block-wise manner. There will be Nd Markov chain samples generated within the each chain, denoted as , where . The Nd samples of the last chain (nc=6) will be used as the fragility model parameters, as discussed in Sect. 3.6. It is important to note that the likelihood p(D|θk,𝕄k) (used in calculating the acceptance probability within the MCMC procedure in Eq. E1) is estimated according to Eq. (13).
Figure F1 illustrates the histograms representing the drawn samples from the joint posterior PDFs corresponding to the sampled model parameters corresponding to the brick masonry residential, Class 1 South Pacific tsunami classes 𝕄k () shown in Fig. 2. The marginal normal prior PDFs are also shown with dashed orange-coloured lines. The statistics of the samples, mean and confidence interval (CI) between 2nd and 98th percentiles for the posterior of model parameters θk are shown on the figures associated to each parameter. It is expected to have the mean values of the marginal posterior samples close to and comparable with those obtained by the MLE in Table 4.
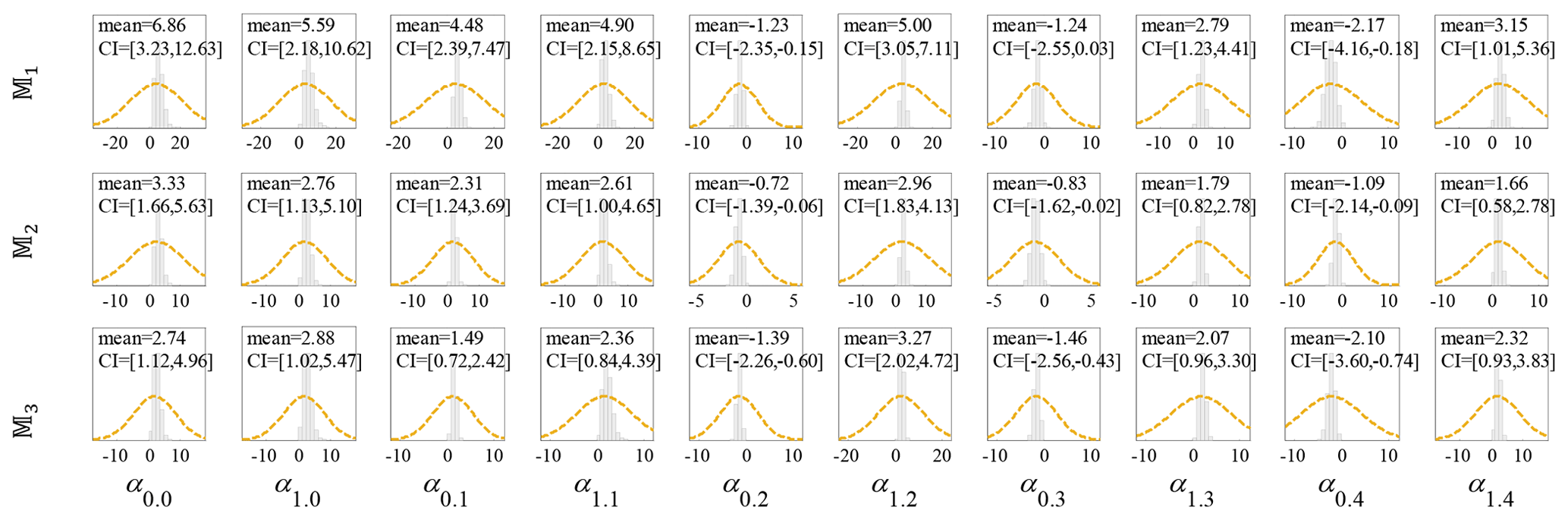
Figure F1Distribution of the fragility model parameters based on model class 𝕄k (where ) for Class 1, brick masonry residential, South Pacific tsunami, by employing an adaptive MCMC procedure including samples drawn from the joint posterior PDF with their statistics (mean and COV) and the marginal normal priors (subfigures show the posterior statistics).
The code implementing the methodology and data used to produce the results in this article are available at the following URL: https://github.com/eurotsunamirisk/computeFrag/tree/main/Code_ver2 (last access: 30 November 2022; Ebrahimian and Jalayer, 2022).
FJ designed and coordinated this research. HE performed the simulations and developed the fragility functions. KT cured the availability of codes and software on the European Tsunami Risk Service (ETRiS). BB provided precious insights on the damage data gathered for American Samoa and the Samoan Islands in the aftermath of the 2009 South Pacific tsunami (documented in Reese et al., 2011). All authors have contributed to the drafting of the paper. The first two authors contributed in an equal manner to the drafting of the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “Tsunamis: from source processes to coastal hazard and warning”. It is not associated with a conference.
The authors would like to acknowledge partial support from Horizon Europe Project Geo-INQUIRE. Geo-INQUIRE is funded by the European Commission under project no. 101058518 within the HORIZON-INFRA-2021-SERV-01 call. The authors are grateful to the anonymous reviewer and Carmine Galasso for their insightful and constructive comments.
The authors gratefully acknowledge partial support by PRIN-2017 MATISSE (Methodologies for the AssessmenT of anthropogenic environmental hazard: Induced Seismicity by Sub-surface geo-resources Exploitation) project no. 20177EPPN2 funded by the Italian Ministry of Education and Research.
This research has been partially supported by PRIN-2017 MATISSE (Methodologies for the AssessmenT of anthropogenic environmental hazard: Induced Seismicity by Sub-surface geo-resources Exploitation) project no. 20177EPPN2 funded by the Italian Ministry of Education and Research.
This paper was edited by Animesh Gain and reviewed by Carmine Galasso and one anonymous referee.
Abramson, I. S.: On bandwidth variation in kernel estimates–a square root law, Ann. Stat., 10, 1217–1223, 1982.
Agresti, A.: Categorical Data Analysis, 3rd edn., Wiley, New Jersy, ISBN: 978-0-470-46363-5, 2012.
Ang, G. L., Ang, A. H.-S., and Tang, W. H.: Optimal importance sampling density estimator, J. Eng. Mech., 118, 1146–1163, 1992.
Au, S. K. and Beck, J. L.: A new adaptive importance sampling scheme, Struct. Saf., 21, 135–158, 1999.
Beck, J. L. and Au, S. K.: Bayesian updating of structural models and reliability using Markov Chain Monte Carlo simulation, J. Eng. Mech., 128, 380–391, 2002.
Beck, J. L. and Yuen, K.-V.: Model selection using response measurements: Bayesian probabilistic approach, J. Eng. Mech., 130, 192–203, 2004.
Behrens, J., Løvholt, F., Jalayer, F., Lorito, S., Salgado-Gálvez, M. A., Sørensen, M., Abadie, S., Aguirre-Ayerbe, I., Aniel-Quiroga, I., Babeyko, A., Baiguera, M., Basili, R., Belliazzi, S., Grezio, A., Johnson, K., Murphy, S., Paris, R., Rafliana, I., De Risi, R., Rossetto, T., Selva, J., Taroni, M., Del Zoppo, M., Armigliato, A., Bureš, V., Cech, P., Cecioni, C., Christodoulides, P., Davies, G., Dias, F., Bayraktar, H. B., González, M., Gritsevich, M., Guillas, S., Harbitz, C. B., Kânoğlu, U., Macías, J., Papadopoulos, G. A., Polet, J., Romano, F., Salamon, A., Scala, A., Stepinac, M., Tappin, D. R., Thio, H. K., Tonini, R., Triantafyllou, I., Ulrich, T., Varini, E., Volpe, M., and Vyhmeister, E.: Probabilistic Tsunami Hazard and Risk Analysis: A Review of Research Gaps, Front. Earth Sci., 9, 628772, https://doi.org/10.3389/feart.2021.628772, 2021.
Cover, T. M. and Thomas, J. A.: Elements of information theory, Wiley, New York, ISBN: 0-471-06259-6, 1991.
Charvet, I., Ioannou, I., Rossetto, T., Suppasri, A., and Imamura, F.: Empirical fragility assessment of buildings affected by the 2011 Great East Japan tsunami using improved statistical models, Nat. Hazards, 73, 951–973, 2014.
Charvet, I., Suppasri, A., Kimura, H., Sugawara, D., and Imamura, F.: A multivariate generalized linear tsunami fragility model for Kesennuma City based on maximum flow depths, velocities and debris impact, with evaluation of predictive accuracy, Nat. Hazards, 79, 2073–2099, 2015.
Charvet, I., Macabuag, J., and Rossetto, T.: Estimating tsunami-induced building damage through fragility functions: critical review and research needs, Front. Built Environ., 3, 36, https://doi.org/10.3389/fbuil.2017.00036, 2017.
Chua, C. T., Switzer, A. D., Suppasri, A., Li, L., Pakoksung, K., Lallemant, D., Jenkins, S. F., Charvet, I., Chua, T., Cheong, A., and Winspear, N.: Tsunami damage to ports: cataloguing damage to create fragility functions from the 2011 Tohoku event, Nat. Hazards Earth Syst. Sci., 21, 1887–1908, https://doi.org/10.5194/nhess-21-1887-2021, 2021.
De Risi, R., Goda, K., Mori, N., and Yasuda T.: Bayesian tsunami fragility modelling considering input data uncertainty, Stoch. Env. Res. Risk A., 31, 1253–1269, 2017a.
De Risi, R., Goda, K., Yasuda, T., and Mori, N.: Is flow velocity important in tsunami empirical fragility modeling?, Earth-Sci. Rev., 166, 64–82, 2017b.
Ebrahimian, H. and Jalayer, F: Selection of seismic intensity measures for prescribed limit states using alternative nonlinear dynamic analysis methods, Earthq. Eng. Struct. D., 50, 1235–1250, 2021.
Ebrahimian, H. and Jalayer, F.: ComputeFrag, Version 2, provided by the European Tsunami Risk Service (ETRiS), GitHub [code], https://github.com/eurotsunamirisk/computeFrag/tree/main/Code_ver2, last access: 30 November 2022.
Eidsvig, U. M. K., Papathoma-Köhle, M., Du, J., Glade, T., and Vangelsten, B. V.: Quantification of model uncertainty in debris flow vulnerability assessment, Eng. Geol., 181, 15–26, 2014.
Epanechnikov, V. A.: Nonparametric estimation of a multidimensional probability density, Theor. Probab. Appl., 14, 153–158, 1969.
Goff, J. and Dominey-Howes, D.: The 2009 South Pacific Tsunami, Earth-Sci. Rev., 107, v–vii, 2011.
Grünthal, G.: European macroseismic scale 1998, European Seismological Commission (ESC), ISBN N2-87977-008-4, 1998.
Hastings, W. K.: Monte-Carlo sampling methods using Markov chains and their applications, Biometrika, 57, 97–109, 1970.
Jalayer, F. and Ebrahimian, H.: Seismic reliability assessment and the non-ergodicity in the modelling parameter uncertainties, Earthq. Eng. Struct. D., 49, 434–457, 2020.
Jalayer, F., Beck, J., and Zareian, F.: Analyzing the sufficiency of alternative scalar and vector intensity measures of ground shaking based on information theory, J. Eng. Mech., 138, 307–316, 2012.
Jalayer, F., De Risi, R., and Manfredi, G.: Bayesian Cloud Analysis: efficient structural fragility assessment using linear regression, B. Earthq. Eng., 13, 1183–1203, 2015.
Jalayer, F., Ebrahimian, H., Miano, A., Manfredi, G., and Sezen, H.: Analytical fragility assessment using unscaled ground motion records, Earthq. Eng. Struct. D., 46, 2639–2663, 2017.
Jalayer, F., Ebrahimian, H., and Miano, A.: Intensity-based demand and capacity factor design: a visual format for safety-checking, Earthq. Spectra, 36, 1952–1975, 2020.
Koshimura, S., Namegaya, Y., and Yanagisawa, H.: Tsunami Fragility–A New Measure to Identify Tsunami Damage, J. Disaster Res., 4, 479–488, 2009a.
Koshimura, S., Oie, T., Yanagisawa, H., and Imamura, F.: Developing fragility functions for tsunami damage estimation using numerical model and post-tsunami data from Banda Aceh, Indonesia, Coast. Eng. J., 51, 243–273, 2009b.
Kullback, S. and Leibler, R. A.: On information and sufficiency, Ann. Math. Stat., 22, 79–86, 1951.
Lahcene, E., Ioannou, I., Suppasri, A., Pakoksung, K., Paulik, R., Syamsidik, S., Bouchette, F., and Imamura, F.: Characteristics of building fragility curves for seismic and non-seismic tsunamis: case studies of the 2018 Sunda Strait, 2018 Sulawesi–Palu, and 2004 Indian Ocean tsunamis, Nat. Hazards Earth Syst. Sci., 21, 2313–2344, https://doi.org/10.5194/nhess-21-2313-2021, 2021.
Mas, E., Paulik, R., Pakoksung, K., Adriano, B., Moya, L., Suppasri, A., Muhari, A., Khomarudin, R., Yokoya, N., Matsuoka, M., and Koshimura, S.: Characteristics of tsunami fragility functions developed using different sources of damage data from the 2018 Sulawesi earthquake and tsunami, Pure Appl. Geophys., 177, 2437–2455, 2020.
Miano, A., Jalayer, F., Forte, G., and Santo, A.: Empirical fragility assessment using conditional GMPE-based ground shaking fields: Application to damage data for 2016 Amatrice Earthquake, B. Earthq. Eng., 18, 6629–6659, 2020.
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E.: Equations of state calculations by fast computing machines, J. Chem. Phys., 21, 1087–1092, 1953.
Muhari, A., Imamura, F., Arikawa, T., Hakim, A. R., and Afriyanto, B.: Solving the puzzle of the September 2018 Palu, Indonesia, tsunami mystery: clues from the tsunami waveform and the initial field survey data, J. Disaster Res., 13, sc20181108, https://doi.org/10.20965/jdr.2018.sc20181108, 2018.
Muto, M. and Beck, J. L.: Bayesian updating and model class selection for hysteretic structural models using stochastic simulation, J. Vib. Control, 14, 7–34, 2008.
Paulik, R., Gusman, A., Williams, J. H., Pratama, G. M., Lin, S.-l., Prawirabhakti, A., Sulendra, K., Zachari, M. Y., Fortuna, Z. E. D., Layuk, N. B. P., and Suwarni, N. W. I.: Tsunami hazard and built environment damage observations from Palu city after the September 28 2018 Sulawesi earthquake and tsunami, Pure Appl. Geophys., 176, 3305–3321, 2019.
Rafliana, I., Jalayer, F., Cerase, A., Cugliari, L., Baiguera, M., Salmanidou, D., Necmioğlu, Ö., Ayerbe, I. A., Lorito, S., Fraser, S., Løvholt, F., Babeyko, A., Salgado-Gálvez, M. A., Selva, J., De Risi, R., Sørensen, M. B., Behrens, J., Aniel-Quiroga, I., Del Zoppo, M., Belliazzi, S., Pranantyo, I. R., Amato, A., and Hancilar, U.: Tsunami risk communication and management: Contemporary gaps and challenges, Int. J. Disast. Risk Re., 70, 102771, https://doi.org/10.1016/j.ijdrr.2021.102771, 2022.
Reese, S., Bradley, B. A., Bind, J., Smart, G., Power, W., and Sturman, J.: Empirical building fragilities from observed damage in the 2009 South Pacific tsunami, Earth-Sci. Rev., 107, 156–173, 2011.
Rosti, A., Del Gaudio, C., Rota, M., Ricci, P., Di Ludovico, M., Penna, A., and Verderame, G. M.: Empirical fragility curves for Italian residential RC buildings, B. Earthq. Eng., 19, 3165–3183, 2021.
Rota, M., Penna, A., and Strobbia, C. L.: Processing Italian damage data to derive typological fragility curves, Soil Dyn. Earthq. Eng., 28, 933–947, 2008.
Wing, O. E., Pinter, N., Bates, P. D., and Kousky, C.: New insights into US flood vulnerability revealed from flood insurance big data, Nat. Commun., 11, 1–10, 2020.
- Abstract
- Introduction
- Methodology
- Results
- Discussion
- Conclusion
- Appendix A: The derivation of Eq. (2)
- Appendix B: The derivation of Eq. (7)
- Appendix C: The derivation of log-evidence in Eq. (13)
- Appendix D: Multivariate normal distribution and generating dependent Gaussian variables
- Appendix E: Adaptive MCMC scheme
- Appendix F: MCMC samples for each model
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methodology
- Results
- Discussion
- Conclusion
- Appendix A: The derivation of Eq. (2)
- Appendix B: The derivation of Eq. (7)
- Appendix C: The derivation of log-evidence in Eq. (13)
- Appendix D: Multivariate normal distribution and generating dependent Gaussian variables
- Appendix E: Adaptive MCMC scheme
- Appendix F: MCMC samples for each model
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References