the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 25 Aug 2025
| 25 Aug 2025
BN-FLEMOΔ: a Bayesian-network-based flood loss estimation model for adaptation planning in Ho Chi Minh City, Vietnam
Kasra Rafiezadeh Shahi
Nivedita Sairam
Lukas Schoppa
Le Thanh Sang
Do Ly Hoai Tan
Heidi Kreibich
The risk of flooding is on the rise in delta cities, such as Ho Chi Minh City (HCMC) in Vietnam, with projections indicating further increases due to climate change and urbanization. Flood risk analyses, for which loss modelling is a key component, play a crucial role in decisions on flood risk management and urban development. Probabilistic multi-variable loss models are increasingly being used to improve loss estimation, as they describe loss processes better and inherently provide a quantification of uncertainties. However, such models are often based on input variables that are determined by expert judgement. Thus, we propose the first probabilistic multi-variable flood loss model designed for residential buildings in delta cities such as HCMC. The Bayesian-network-based flood loss estimation model BN-FLEMOΔ is built upon new building-level empirical survey data. The model is developed with an automatic machine-learning-based (ML-based) feature selection framework and a systematic learning process to determine the optimal structure of the Bayesian network. Based on a method comparison, we demonstrate the following key advantages of BN-FLEMOΔ: (1) enhanced empirically based description of flood loss processes leading to improved accuracy in loss estimation; (2) provision of a probability distribution of losses and inherent quantification of modelling uncertainty; and a (3) network structure that allows model application even when data for one or more input variables are missing, which is particularly valuable in data-scarce environments. We therefore expect that BN-FLEMOΔ will significantly improve risk analyses in HCMC and similar delta cities and support decision-makers in developing sustainable flood risk management strategies for these dynamic flood-prone regions.
- Article
(3837 KB) - Full-text XML
- BibTeX
- EndNote




The risk of flooding in delta cities such as Ho Chi Minh City (HCMC) in Vietnam is severe due to complex, compound flood situations and rapidly increasing exposure due to population growth, urban sprawl, and densification (Garschagen and Romero-Lankao, 2015; Bangalore et al., 2019; IPCC, 2023). HCMC, located at the periphery of the Mekong Delta, experiences pluvial, riverine, and coastal floods (Luu et al., 2019; Vachaud et al., 2019; Nguyen et al., 2021; UNDRR, 2022). The city has 2953 canals, predominantly sourced from the Dong Nai, Saigon, and Vam Co rivers. Elevated water levels in rivers and canals, particularly those associated with the Mekong River basin, contribute significantly to widespread inundation (Nguyen et al., 2023; Cao et al., 2021). Furthermore, heavy and recurrent rainfall exacerbates flooding in HCMC, particularly when it surpasses the drainage system's capacity (Luu et al., 2019). The intricate interplay between topography and land subsidence also significantly influences flood dynamics. Specifically, elevation gradients and surface roughness dictate the flow pathways of floodwaters, while land subsidence, driven by factors such as groundwater extraction and urban development, worsens flooding by raising relative sea levels and altering drainage patterns (Bank, 2010). As a result, it is expected that flood risk will continue to increase in HCMC due to climate change, e.g. increased precipitation and sea level rise, as well as due to socio-economic changes (Bank, 2010; Hanson et al., 2011; Hallegatte et al., 2013; Lasage et al., 2014; Cao et al., 2021). To counteract this trend, sustainable adaptation strategies need to be planned on the basis of comprehensive risk analyses, including reliable flood loss modelling (Apel et al., 2009; Poljansek et al., 2017).
In flood risk analyses, flood loss models play a pivotal role in assessing the impact of hazards on exposed assets such as buildings. Traditionally, deterministic stage–damage functions (SDF-Dets) differentiated by building or land use have been used, with water depth being the sole input variable (Smith, 1994; Merz et al., 2010). However, despite their limitations, SDF-Dets are still the most common method for estimating flood-related financial losses and can still be considered state of the art (Scawthorn et al., 2006; Thieken et al., 2008; Schoppa et al., 2020). Nonetheless, with many studies recognizing that damage processes are driven by various factors, such as inundation duration, contamination of floodwater, effectiveness of flood warnings, and precautionary measures, multi-variable flood loss models have been developed (Wind et al., 1999; Penning-Rowsell and Green, 2000; Thieken et al., 2005; De Moel et al., 2015; Gerl et al., 2016). For instance, Thieken et al. (2008) proposed utilizing various loss-influencing variables, including building type and precautionary measures in addition to inundation depth, as predictors for a rule-based flood loss estimation model designed for the private sector. Their research demonstrated that such multi-variable models describe damage processes better and thus outperform SDF-Dets, but the uncertainties associated with loss estimation remained high (Thieken et al., 2008; Elmer et al., 2010). In addition, the selection of input variables for the loss models heavily relies on the literature review and expert judgement. Therefore, advanced, data-based, and automated frameworks for feature selection are crucial to enhance our understanding of complex flood loss processes and to improve flood loss models.
Flood loss modelling is associated with high uncertainty, which can be separated into aleatoric uncertainty that is not reducible and epistemic uncertainty that can be reduced by more knowledge. Aleatory uncertainty refers to stochastic processes that are inherently variable in time, space, or populations of objects, such as a tree trunk that may severely damage one building and may spare the adjacent building or localized high-flow velocity that may scour the foundation of one building, leading to collapse, whereas a neighbouring building may only be inundated (Merz and Thieken, 2009). Epistemic uncertainty results from incomplete knowledge and is related to our inability to understand, measure, and describe the damage processes; it is thus linked to disregarding factors influencing damage or the misjudgement of their manifestations and effects (Merz and Thieken, 2009). It is, therefore, crucial to quantify uncertainties in flood loss estimates and hereby support informed and robust decision making (de Brito and Evers, 2016; Pappenberger and Beven, 2006). To quantify this uncertainty, probabilistic loss models have been developed (e.g. Bayesian networks), which inherently provide quantitative information on uncertainty associated with the input data’s random heterogeneity and the model structure (Schröter et al., 2014; Vogel et al., 2018; Paprotny et al., 2021). Bayesian networks can capture the joint probability distribution of all input variables and model the probabilistic dependency among the variables (Jensen and Nielsen, 2007). As such, they can model damage processes better and are applicable even when data for one or more predictors are missing. Further, Bayesian networks offer the option to incorporate prior information (e.g. from previous studies or expert knowledge) and to communicate the model functionality transparently through the graph structure (Vogel et al., 2014). Nevertheless, probabilistic loss models are also specific to the region and the type of flood for which they were developed (Schröter et al., 2014; Wagenaar et al., 2018; Mohor et al., 2021). The transfer of damage models in time and space is critical and leads to significantly increased uncertainty (Wagenaar et al., 2018; Mohor et al., 2021). This is due to differences in hazard characteristics, e.g. between slowly rising river floods in the lowlands and flash floods in the mountains, as well as due to differences in vulnerability between countries, e.g. due to differences in building composition. For example, Chinh et al. (2017) showed that under the specific flooding conditions in the Mekong Delta, with relatively well-adapted households, long flood duration, and shallow water depth, water depth does not determine flood damage as much as in other regions. Despite the high flood risk in the Mekong Delta, not many studies have focused on flood loss modelling in this region (Luu et al., 2019). Scussolini et al. (2017) and Couasnon et al. (2022) used deterministic depth–damage curves to calculate flood risk. Wu et al. (2021) assessed flood risk in HCMC using a nature–human framework, which integrated social and environmental factors to develop flood hazard and vulnerability maps.
The objective of our study is to fill this gap and tackle some of the challenges in developing the first probabilistic flood loss model tailored to HCMC and to similar delta cities. Our framework shall not only enable the quantification of model uncertainty through Bayesian inference, essential for decision-making, but also incorporate an automatic feature selection workflow. The latter aids in automatically identifying the key factors determining flood loss in HCMC.
The remainder of the paper is organized as follows. Section 2.1 outlines the survey data utilized for model development. The method is detailed in Sect. 2.2. Section 3 presents the results obtained along with a discussion. Finally, Sect. 4 summarizes the conclusions drawn from the study.
2.1 Household survey data
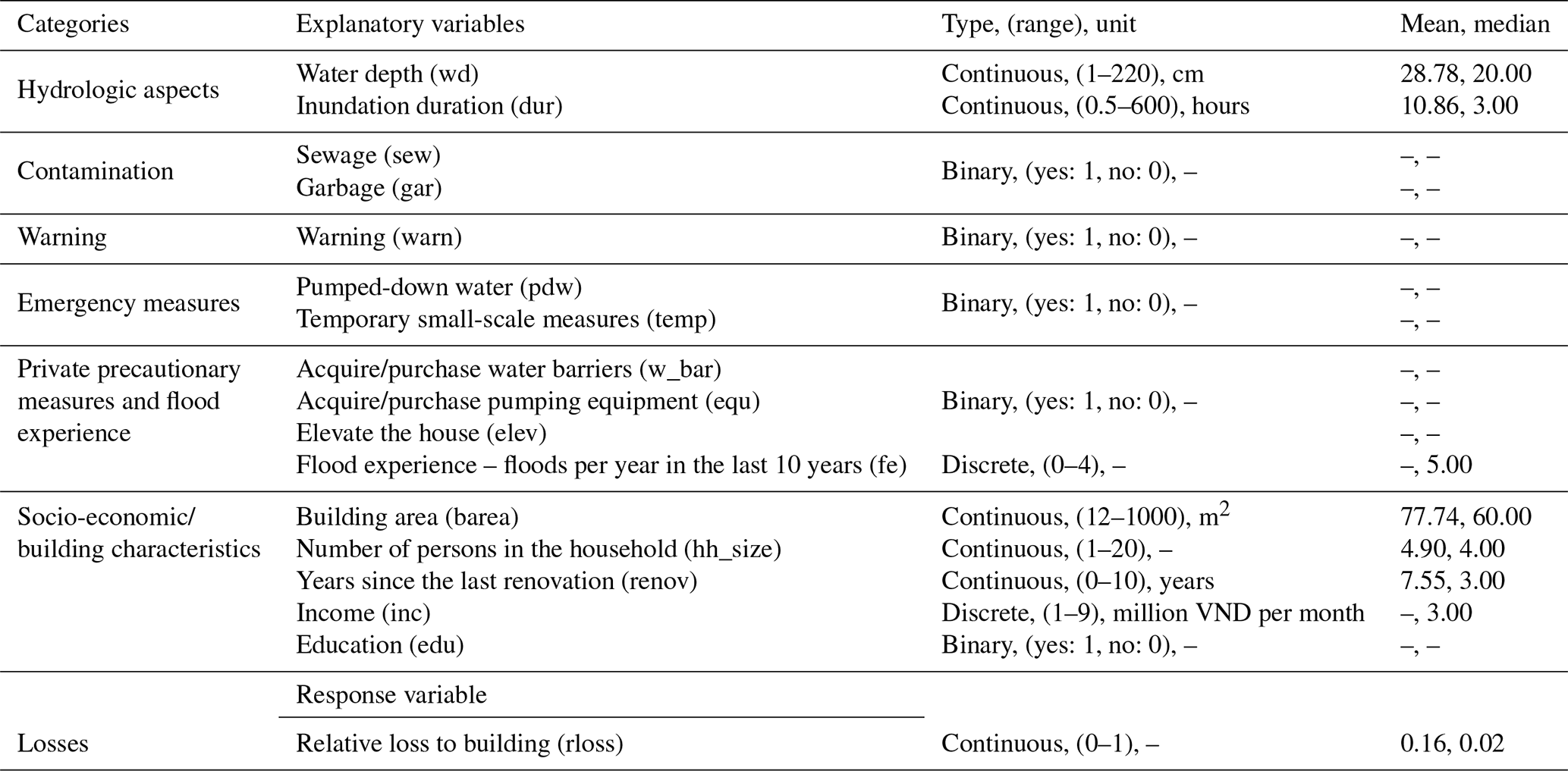
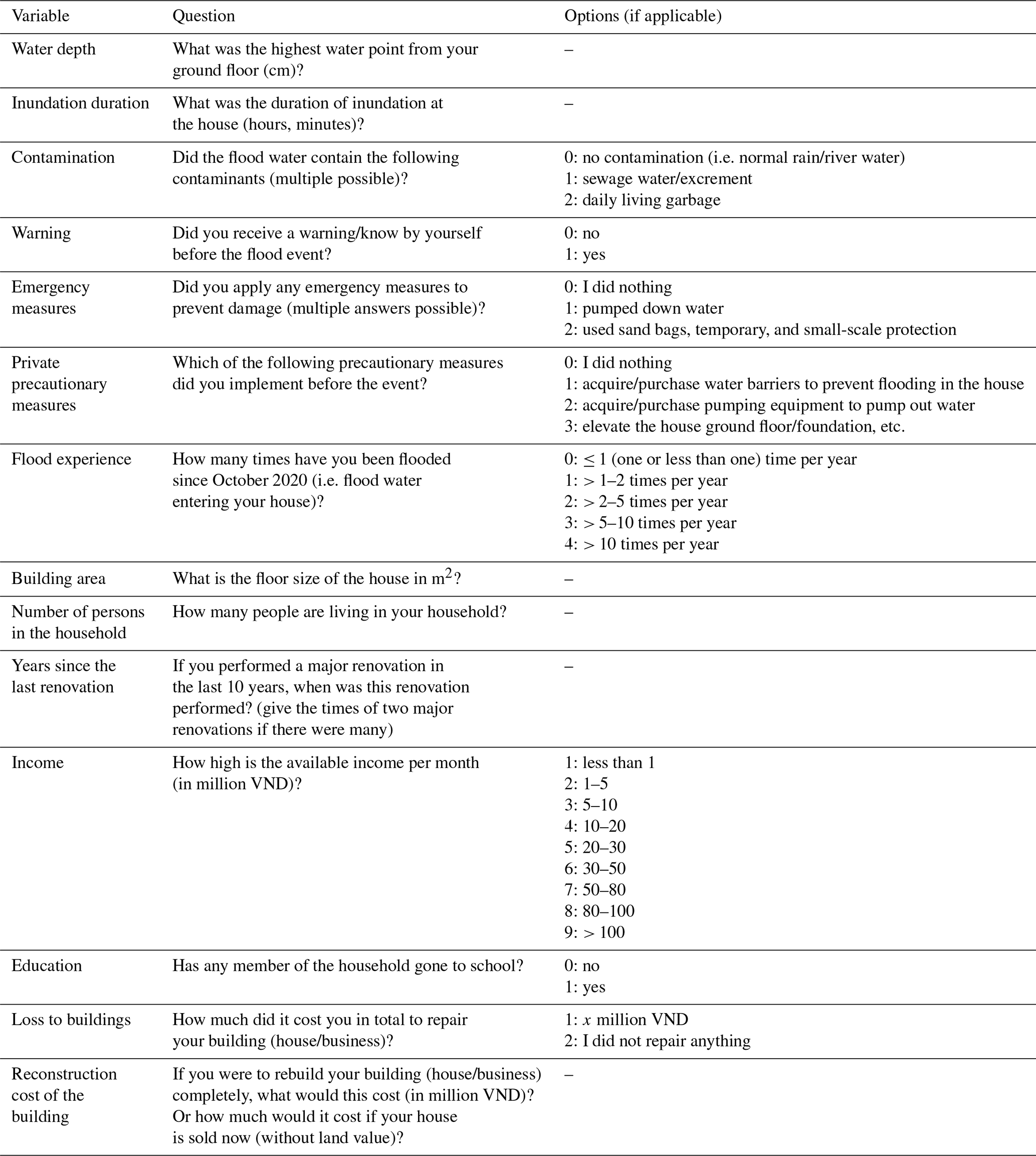
The empirical data used in the development of the flood loss model were collected from a questionnaire-based structured household survey of 1000 households (Vishwanath Harish et al., 2023). The individuals in the households were interviewed face-to-face. The prerequisite for the households to participate was that they must have experienced flood damage in the last 10 years before 2020, i.e. starting in 2010. In addition to information pertaining to flood hazard and impacts, the questions covered a variety of topics including household composition, building characteristics, implementation of private precautionary measures, socio-economic aspects, previous flood experience, and their perception of changing flood risk and potential adaptation options. Based on discussions with flood risk experts from HCMC, the survey areas were chosen such that they spread over different socio-economic profiles and flood types. The spatial distribution of the survey can be found in Appendix A (see Fig. A1). However, the household selection within the areas was made at random. Households were asked to report on two flood events (i.e. the most recent event and the most serious event in terms of impact within the last 10 years). Out of 1000 households, 530 provided information on both types of events, while the remaining households reported only one event (in these cases, the more recent event was also the most serious). This resulted in 1530 records of flood loss data. Among these records, 467 contained missing values in one or more of the flood loss predictors (e.g. water depth, inundation duration) or in the target variable (rloss). To ensure the integrity of the analysis, we adopted a complete-case approach by excluding all records with missing values. Subsequently, 16 loss-influencing variables were selected based on an extensive literature review and consultations with domain experts in Ho Chi Minh City (Table 1). As shown in Table 1, these 16 variables cover a wide range of loss-influencing variables, including hydrological factors, socio-economic indicators, and building characteristics. As for the target variable, the relative loss to the building is computed as the ratio of absolute monetary building damage to the building's reconstruction cost. Further details on these 16 variables can be found in Appendix A (see Table A1).
Table 1The 16 potential flood-loss-influencing variables along with the target variable (rloss).
2.2 Development of the Bayesian-network-based flood loss estimation model
Our proposed framework consists of two phases: (1) an automatic feature selection process to identify the most important variables that determine flood loss and (2) development of the Bayesian-network-based flood loss estimation model (BN-FLEMOΔ) (see Fig. 1). In the following sections, we elaborate on each of these phases.
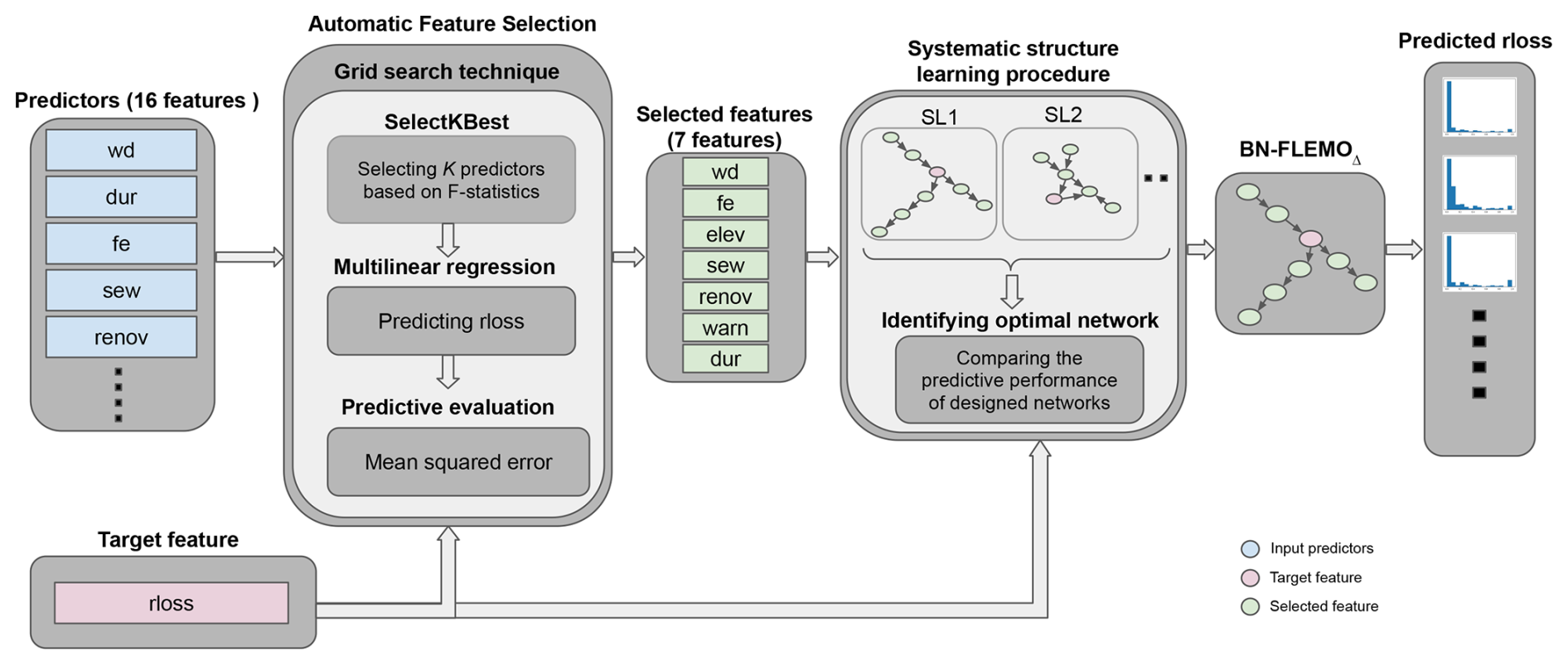
Figure 1The proposed workflow to develop the flood loss estimation model. In the systematic structure learning procedure, SL1 and SL2 refer to the first and the second structure learning algorithms utilized.
2.2.1 Automatic feature selection using machine learning
The first step of flood loss model development is the identification of the most important factors influencing flood loss. Traditionally, this has been done relying on expert judgement or the existing literature. In recent years, there has been a shift towards data-driven approaches to identify significant predictors from empirical datasets (Vishwanath Harish et al., 2023; Schoppa et al., 2020; Vogel et al., 2018). Such data-driven approaches provide users with insights into the importance of loss-influencing variables. We propose an automatic feature selection framework that employs the SelectKBest technique to assign scores to each predictor based on their F statistics (Ayyanar et al., 2022). F statistics assesses the overall significance of the relationship between independent variables and the dependent target variable and are calculated as the ratio of two variances, one capturing the explained variability by the model and the other representing unexplained variability (Fisher, 1970). A high F value signifies a strong relationship between predictors and the outcome, indicating improved model performance. Conversely, a low F value suggests that the model may not substantially enhance predictions (Desyani et al., 2020). SelectKBest then selects the top k predictors with the highest scores for further analysis. Although SelectKBest contributes to improving the predictive performance of models, there are some disadvantages (Ayyanar et al., 2022).
Firstly, the method investigates each predictor variable individually. Secondly, the user must define the parameter k prior to feature selection. As depicted in Fig. 1, to address the former challenge, we analyse the predictive performance of selected k predictors using standard multi-variable linear regression (MLR) in terms of the mean squared error (MSE) (Hocking, 1976). To address the latter challenge, we create an automatic framework using the grid search technique. This technique serves as a hyperparameter optimizer and searches within a specified range to determine the optimal value of a hyperparameter (Liashchynskyi and Liashchynskyi, 2019). In our study, we explore a range of values for k from 1 to 𝒟, where 𝒟 represents the original number of features (i.e. the 16 features described in Table 1). By leveraging the proposed automated feature selection workflow, we identify the optimal subset of features to use as input variables for the loss model and gain knowledge about the loss processes in terms of the underlying relationship between the drivers and the relative loss.
2.2.2 Systematic learning process to determine the structure of the Bayesian network
Bayesian networks (BNs) are graphical models that describe the probabilistic dependencies between a set of random variables as a directed acyclic graph (Aguilera et al., 2011; Nagarajan et al., 2013). The graph consists of nodes representing random variables and arcs indicating conditional dependencies between the variables. Analogously, network variables that are not connected are considered statistically independent. BNs can be used for both continuous and discrete variables, but in practice, BNs assume that all random variables are discrete (Chen et al., 2017). Thus, in this study, we design a discrete BN model to estimate flood loss. Thus, we discretize the continuous model variables using equal-frequency binning. We performed a sensitivity analysis regarding the discretization of relative loss to determine how to effectively capture the variability in flood loss. This analysis specifically investigated the effects of discretizing relative loss into three, five, and seven bins. Our findings indicated that the alterations in the final BN structure were not substantial. Consequently, we opted for five bins for all continuous variables including relative loss, as they allow for a nuanced representation of patterns within the dataset (see Fig. A2). Using factorization, the global joint probability distribution (P(X) = ) of a random variable X can be written as
where k denotes the number of input features for the BN. Xi and pa(Xi) represent the ith node and its corresponding parental node/nodes, respectively (i.e. the set of nodes pointing towards Xi) (Aguilera et al., 2011).
To build the BN-FLEMOΔ structure, we utilize a data-driven learning approach in which 500 bootstrap samples are drawn from the data, and various structure learning algorithms are applied to generate potential Bayesian networks. These algorithms fall into three primary categories: score-based, constraint-based, and hybrid methods. In our study, we explore widely used structure learning approaches from each category (Lüdtke et al., 2019; Schoppa et al., 2020). Specifically, we employ hill-climbing (hc) (Russell, 2010) as a score-based approach, incremental association (iamb) (Tsamardinos et al., 2003) as a constraint-based approach, and max–min hill climbing (mmhc) (Tsamardinos et al., 2006) along with general two-phase restricted maximization (rs2max) (Friedman et al., 2013) as hybrid approaches. Applying each method to the bootstrap samples results in 500 independent networks per algorithm. These realizations are then averaged, and arcs that appear frequently based on a quantitative selection criterion are retained in the final structure. The quantitative evaluation using the mean absolute error (MAE), root-mean-squared error (RMSE), and mean continuous ranked probability score (mean CRPS) indicates that the structure learned via the hill-climbing algorithm performs favourably compared to the other approaches (see Fig. A3). A qualitative assessment further supports this finding, showing that the hc-derived structure more accurately represents the underlying flood damage process (see Fig. A4). Therefore, we selected the hc algorithm to construct the final BN-FLEMOΔ structure. In addition to the network structure, the complete specification of the Bayesian network requires estimating the conditional probability tables (CPTs) for each node. For this purpose, we apply Bayesian parameter estimation using the Bayesian Dirichlet equivalent uniform (BDeu) score with an exact inference algorithm implemented in the bnlearn R package (Scutari and Denis, 2014). This method is used on the full empirical survey dataset or on relevant subsets during cross-validation to ensure robust parameter learning.
2.3 Model validation
2.3.1 Model performance comparison
To assess the predictive efficacy of BN-FLEMOΔ, we compare its performance with other flood loss modelling approaches. To make a fair model comparison, we compare our proposed probabilistic model with other probabilistic models, with the only exception being a deterministic stage damage function (SDF-Det), as this represents the state of the art (Merz et al., 2010; Scussolini et al., 2017; Couasnon et al., 2022). The uni- and multi-variable machine-learning-based (ML-based) approaches include the following:
-
Stage damage functions (SDFs). The most commonly used flood loss modelling methods are deterministic SDFs, which are univariate techniques relying on water depth as a single flood loss driver (Merz et al., 2010; Scussolini et al., 2017; Couasnon et al., 2022). Various studies have shown that the square root function provides more accurate estimates compared to linear relationships. Additionally, we use a probabilistic SDF (SDF-Prob) that utilizes probabilistic modelling techniques, such as Monte Carlo sampling, to estimate the probability distribution of flood damage (Schoppa et al., 2020). We formulate an SDF-Det that uses water depth as its independent variable as
where represents the measured water depth, and c is an unknown coefficient. expresses the relative loss values, and α denotes the intercept. To transform SDF-Det into a probabilistic version, we must define a distribution function that can approximate the distribution of our target variable. Given that our target variable (relative loss) falls within the range of 0 to 1 and exhibits a bimodal distribution with peaks at 0 (no loss) and 1 (total loss), we opt for a zero-and-one-inflated beta (BEINF) distribution to represent the target variable. The cumulative distribution function (CDF) of a zero-and-one-inflated beta distribution can then be expressed as
where the CDF function FBernoulli represents a Bernoulli random variable with the parameter γ, while Fbeta represents a beta distribution with parameters μ (location) and ϕ (precision). In Eq. (3), the values of λ, μ, and γ are constrained to the range [0,1], while ϕ must be greater than zero (Ospina and Ferrari, 2010). In this model formulation, μ varies for each household, whereas the other distribution parameters (λ, ϕ, γ) remain constant across all households.
-
Random forest (RF). RF is a powerful multi-variable ML tool in flood loss modelling due to its adeptness at handling intricate datasets and diverse predictor types effectively. This method is particularly advantageous for flood loss modelling tasks owing to its ability to accommodate both numerical and categorical variables that are commonly encountered in flood risk assessment data (Sieg et al., 2017). In flood loss modelling with RF, an ensemble of decision trees is constructed, with each tree trained on a random subset of the dataset. These decision trees individually predict flood losses based on various input variables. By amalgamating the predictions of multiple trees, RF can capture the underlying relationships between predictors and the relative losses, thereby yielding accurate and dependable estimates. Notably, RF excels at handling nonlinear relationships and interactions between predictors, which is indispensable in flood risk assessment (Merz et al., 2013). Nonetheless, RF can be biased toward predictors with many possible splits. To address this issue, the conditional inference tree (CIT) algorithm based on permutation tests was developed, wherein RF can obtain conditional response distributions instead of mean values using quantile regression forest methodology (Hothorn et al., 2006). Recent studies have increasingly employed the conditional inference tree algorithm or a combination of conditional inference trees and quantile regression forests due to their advantages over conventional classification and regression tree algorithms (Sieg et al., 2017). The parameters controlling the RF model include the number of trees (ntree) and the number of randomly sampled predictors during partitioning (mtry). In our experiment we follow the common parameter values, typically set to ntree = 1000 and mtry = 3 (Schoppa et al., 2020). While BN-FLEMOΔ can update the parameters of the network (the conditional probability distributions associated with each node) using new data, RF requires complete retraining with new data.
-
Bayesian regression (BR). BR is a statistical modelling technique that extends traditional linear regression by incorporating Bayesian principles. In BR, instead of estimating fixed model parameters, we treat them as random variables with probability distributions. This allows us to quantify uncertainty in our estimates and make probabilistic predictions (Gelman et al., 1995). Thus, within flood loss modelling, we can adapt the BR concept to model relative loss using a zero‐and‐one‐inflated beta distribution (Schoppa et al., 2020). This way we ensure that the model is capable of reproducing the extreme cases of no damage or total damage within our dataset. Although BR offers flexibility in modelling complex relationships and handling various types of uncertainties, making it a powerful tool in data analysis and prediction tasks, it does not provide a graphical representation to assist experts in analysing the loss processes. Additionally, BR models the conditional distribution of the relative loss given the predictor variables, while BN computes the joint probability distribution over sets of variables using conditional probabilities (Mohor et al., 2021). In addition, unlike BN, which can handle missing input parameters, BR requires complete data and is prone to issues if missing inputs are not properly addressed.
For the probabilistic approaches SDF-Prob, BR, and BN-FLEMOΔ, we calculate the average of the distribution of predicted values to calculate the evaluation metrics.
The proposed feature selection workflow was implemented using Python 3.10 with the Scikit-learn 1.2.2 library. BN-FLEMOΔ was implemented in R 4.2.2 using the Bnlearn 4.8.1 package. Notably, to ensure consistency across different components of the proposed framework, we used the same set of training and testing samples for each phase.
2.3.2 Evaluation metrics
To assess the performance of BN-FLEMOΔ in comparison with other flood loss modelling approaches, we employ 10-fold cross-validation. This method involves iteratively training the model on 9 subsets of the data and testing it on the remaining 10th subset. This process is repeated 10 times to ensure that all data points are used for both training and testing. Then we report the average over these 10 runs in terms of the following metrics:
-
Root-mean-squared error (RMSE). RMSE is a commonly used metric in regression analysis to measure the average magnitude of the errors between predicted and observed values. RMSE is calculated by taking the square root of the average of the squared differences between predicted and observed values. It provides a measure of the model's accuracy, with lower RMSE values indicating better performance.
-
Mean absolute error (MAE). MAE is the average of the absolute difference between the predicted and observed values (residuals). MAE can be written as
-
Mean bias error (MBE). MBE quantifies the average difference between predicted values and actual observations in a dataset. It measures the tendency of a model to consistently overestimate or underestimate the true values. MBE is calculated by taking the average of the differences between predicted and observed values, where positive values indicate an overall overestimation and negative values indicate an overall underestimation.
-
Continuous ranked probability score (CRPS). CRPS is a metric used to evaluate probabilistic models by assessing the accuracy and reliability of their predictions. Unlike traditional point estimates, which provide only a single value, probabilistic models generate entire distributions of possible outcomes. The CRPS compares these predicted distributions with observed outcomes. By considering both the accuracy of the predicted values and the uncertainty represented by the distribution for each observation (Gneiting and Raftery, 2007), we can formulate CRPS as follows:
where Fi(x) is the empirical CDF of the predictive distribution fi(x), and 1{.} is the indicator function, which represents conditions or events in probability theory. We compute CRPS using an empirical CDF estimated from samples of fi(x). The CRPS ranges between 0 and 1, with the optimum at 0. Additionally, to facilitate comparison with other evaluation metrics, we computed the mean CRPS value in each cross-validation fold.
3.1 Important variables for flood loss modelling
Our proposed feature selection workflow automatically identifies the relevant features for estimating flood losses (see Fig. 2). Figure 2a illustrates that the optimal number of features to obtain the lowest MSE value (≈ 0.0719) is seven. The top seven features with the highest scores are water depth (wd), flood experience (fe), building elevation (elev), sewage contamination (sew), years since last renovation (renov), warning (warn), and inundation duration (dur) (see Fig. 2b).
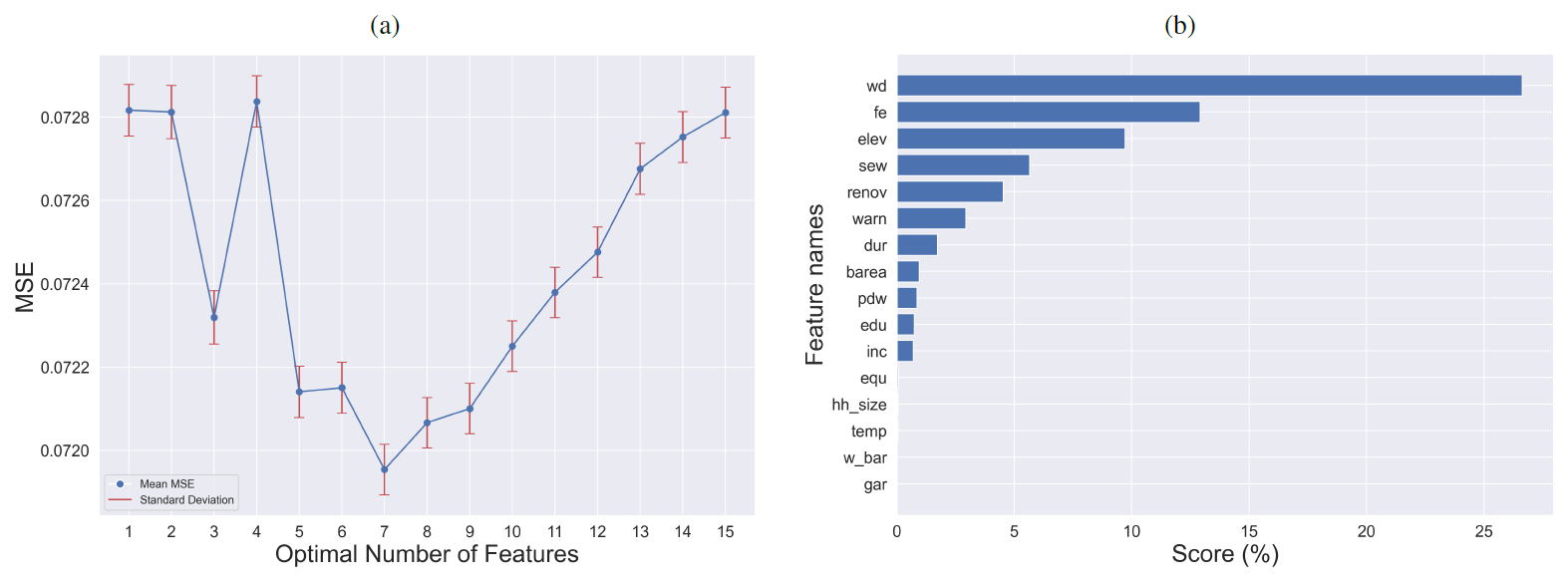
Figure 2The proposed feature selection workflow (a) identifies the optimal number of features (k) and (b) provides the corresponding scores to each feature. The results are based on the mean of 10-fold cross-validation.
Water depth is found to be the most important driver for flood loss, which is in agreement with comprehensive reviews and state-of-the-art flood loss models (Merz et al., 2013; Chinh et al., 2017; Rözer et al., 2019; Merz et al., 2010). The second flood intensity parameter, i.e. inundation duration, has been identified as an important predictor of flood loss as well, although it is only in the seventh position with a score of ≈ 1.72.
The second important driver is flood experience. Flood experience has been found to cause households to implement precautionary measures such as elevating the building (Vishwanath Harish et al., 2023; Kreibich et al., 2005), which is the next-most-important driver. It has been shown before that it leads to flood loss reduction (Chinh et al., 2017). As another important factor, we can refer to sewage contamination. In several cases, contamination of the flood water entering the buildings was found to increase the damage (Rözer et al., 2019; Thieken et al., 2005; Penning-Rowsell et al., 2014). Furthermore, the number of years since the building was last renovated was also identified as an important factor. This finding also aligns with the fact that the building quality degenerates over time; recently renovated buildings are of better quality and were found to be more resistant to flooding (Chinh et al., 2017). Warning (i.e. whether the household received a warning before the flood event) is also an important feature, which is a prerequisite for the implementation of emergency measures, such as deploying sandbags and water barriers that reduce flood damage to buildings.
3.2 BN-FLEMOΔ
The trained Bayesian network model using the seven features identified elucidates the interactions across these features and their relationships to relative loss to residential buildings (see Fig. 3). The direction of arrows in BN-FLEMOΔ indicates an association between two variables but does not necessarily imply causality (Lüdtke et al., 2019; Sairam et al., 2019). In BN-FLEMOΔ, the variable rloss has direct connections with water depth (wd), flood experience (fe), and years since last renovation (renov), which form the Markov blanket of rloss. In cases where the Markov blanket is fully observed, the other independent variables can be ignored. Thus, wd, fe, and renov are the most important predictors, which is aligned with flood loss dynamics and prior research findings (Chinh et al., 2017). If observations of wd, fe, and renov are missing, observations related to variables from outside the Markov blanket provide knowledge that helps to improve the prediction of rloss. This is most likely the case in relation to “renov”. Since it is difficult to know when the building was last renovated, but it is possible to observe whether the building is elevated (for instance by Google Street View; Pelizari et al., 2021), the application of the loss model is improved in practice by the use of elev. Elevating the building is one of the most common flood precautionary measures among households in HCMC (Vishwanath Harish et al., 2023). Interestingly, we also observe some differences compared to a somewhat similar study by Chinh et al. (2017) in Can Tho City, Mekong Delta; they found a significantly higher importance of flood duration. These differences in flood processes and important input parameters for damage models confirm the need for region- and flood-type-specific loss models (Wagenaar et al., 2018; Mohor et al., 2021). While applying the BN-FLEMOΔ (see Fig. A5), known values are set to the predictor nodes, which updates the marginal probability distribution of the response variable conditioned on the predictors. When one or more values of nodes are unknown, the relative loss is conditioned on the values of the other known variables. Hence, the Bayesian network provides loss estimates even when some predictors are missing (Fig. A5b). Figure A5 depicts the BN-FLEMOΔ structure and parameters inferred from the survey data. In Fig. A5a, the marginal probability distributions of the fitted network are presented. Furthermore, Fig. A5b showcases an example prediction generated by BN-FLEMOΔ, utilizing three predictor variables assumed to be known (wd, fe, elev). The marginal probability distribution of the relative loss is updated conditionally based on the evidence in the nodes corresponding to these three predictors. The equal-frequency discretization of relative loss resulted in narrow bins for very low (less than 17 %) losses such that these losses are precisely captured. This discretization reflects the damage processes in HCMC, which are characterized by frequent nuisance flooding resulting in rather low losses (Scheiber et al., 2023).
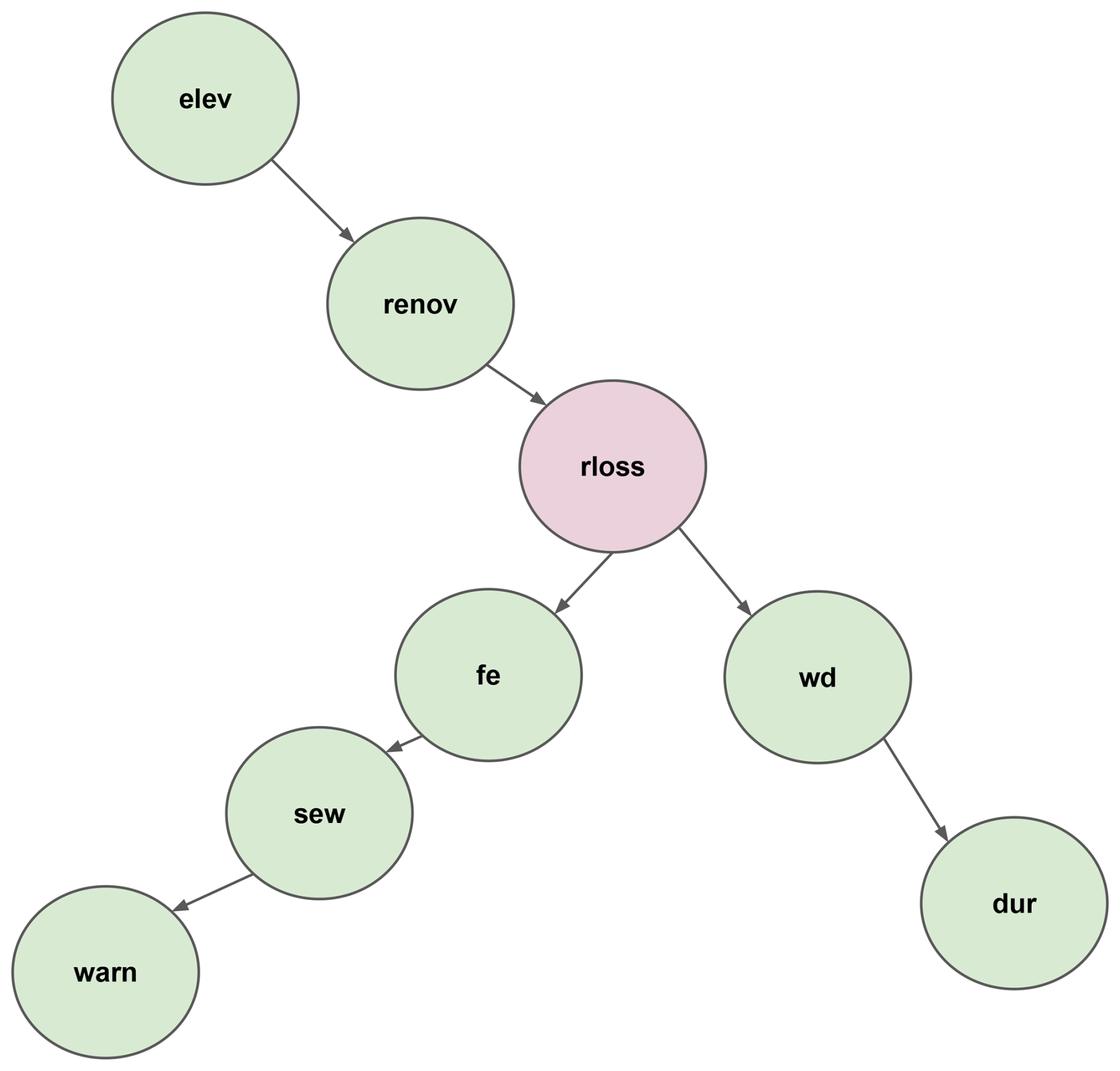
Figure 3The final structure of BN-FLEMOΔ. The green nodes represent independent variables, including water depth (wd), flood experience (fe), years since the last renovation (renov), building elevation (elev), sewage contamination (sew), warning (warn), and inundation duration (dur). The pink node presents the target variable, relative loss to residential buildings (rloss).
Furthermore, BN-FLEMOΔ can provide information on the uncertainty involved in the flood loss estimation. Figure 4 illustrates predictive distributions for building loss of three randomly selected buildings. Vertical orange and green lines represent the actual observed relative loss and the average of the predictive distribution, respectively. However, it is evident that prediction accuracy and sharpness are greater for buildings with lower loss magnitudes (i.e. sample IDs 133 and 100) compared to the ones with more severe losses (i.e. sample ID 800). Such an observation is due to the scarcity of extreme losses in the dataset. As shown in Fig. 4, BN-FLEMOΔ can model the lower relative losses with less uncertainty, while in severe cases (i.e. complete damage = 1) the model has higher uncertainty.
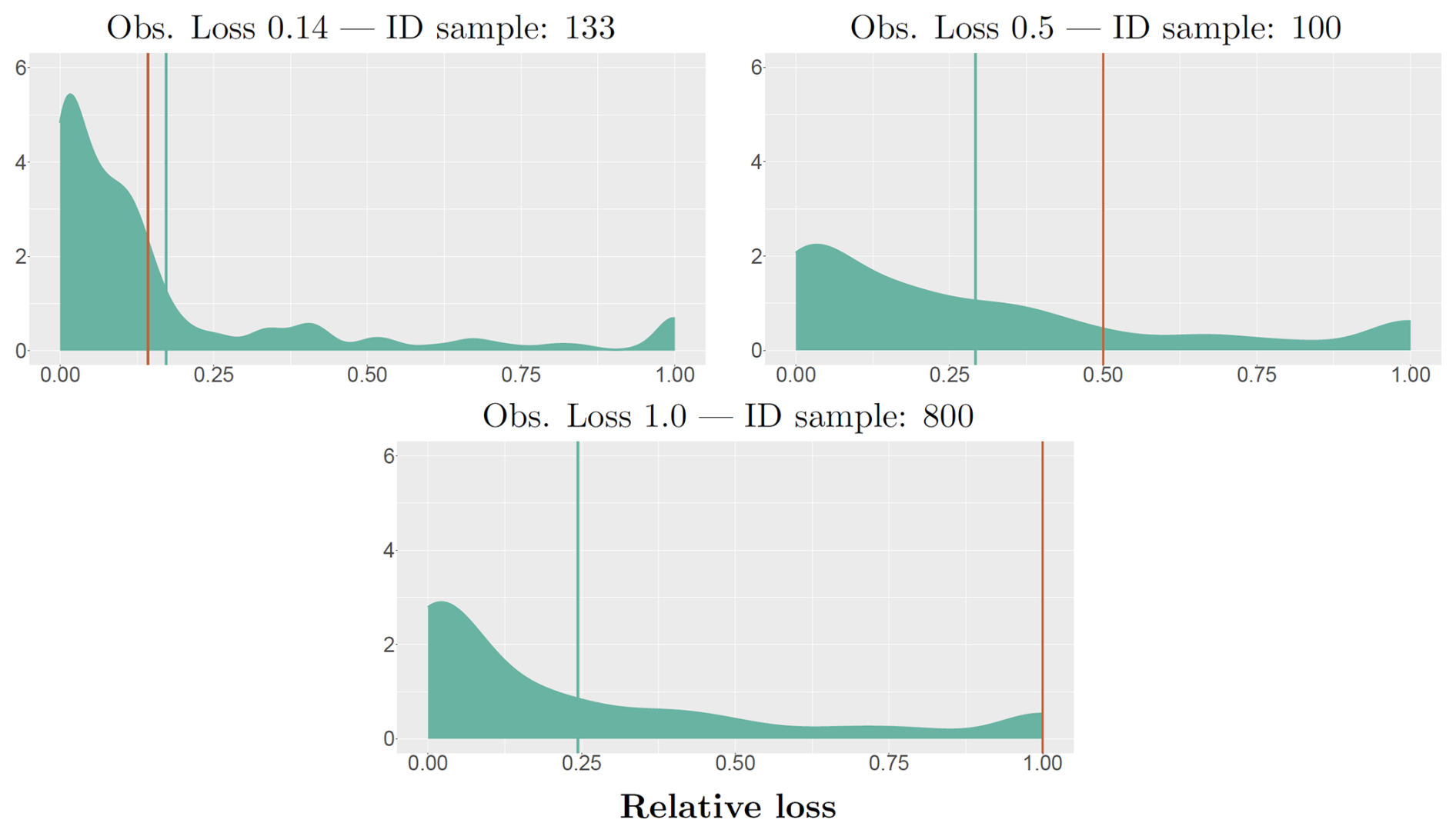
Figure 4Samples of predictive densities of relative loss generated by BN-FLEMOΔ for three randomly selected buildings (identified by ID sample). The observed loss is represented by the orange lines, and green lines showcase the average of the predicted distribution generated by BN-FLEMOΔ. In this visualization, the x axes represent the relative loss, while the y axes display the density.
In addition, to evaluate the performance of BN-FLEMOΔ under the influence of different sets of input features, we designed an experiment where input features were incrementally added following the order determined by the feature selection process. As shown in Fig. A6, using only the two initial loss-influencing variables (set 2), namely wd and fe, results in poor performance in terms of RMSE values. In contrast, set 7, which includes seven identified features (wd, fe, elev, sew, renov, warn, dur), achieves the best performance compared to other configurations. We also observe that increasing the number of independent variables beyond this point does not improve predictive performance, highlighting the importance of the feature selection phase prior to the estimation process.
3.3 Model validation
The quantitative evaluation of the model comparison, i.e. evaluation metrics, is illustrated in Fig. 5. Our proposed BN-FLEMOΔ performs better than the other ML-based approaches across nearly all error metrics, e.g. achieving the lowest absolute MAE value of 0.18 ± 0.01 and the lowest mean CRPS of 0.11 ± 0.01. Results in terms of MBE, shown in Fig. 5, reveal that BN-FLEMOΔ has a relatively low bias compared to other ML-based approaches. BR and both stage–damage functions show a slightly lower bias, while RF tends to strongly overestimate the target value. In general, BR, SDF-Prob, and SDF-Det performed similarly well across all error metrics, whereas RF demonstrates the weakest performance of all approaches across all error metrics. Despite partly marginal differences between BN-FLEMOΔ and BR, SDF-Prob, and SDF-Det, the advantages of our model are its applicability even with some missing input variables, the inherent quantification of predictive uncertainty, and the graphical representation of the interaction between different flood-loss-influencing factors and relative loss, offering insights into loss processes.
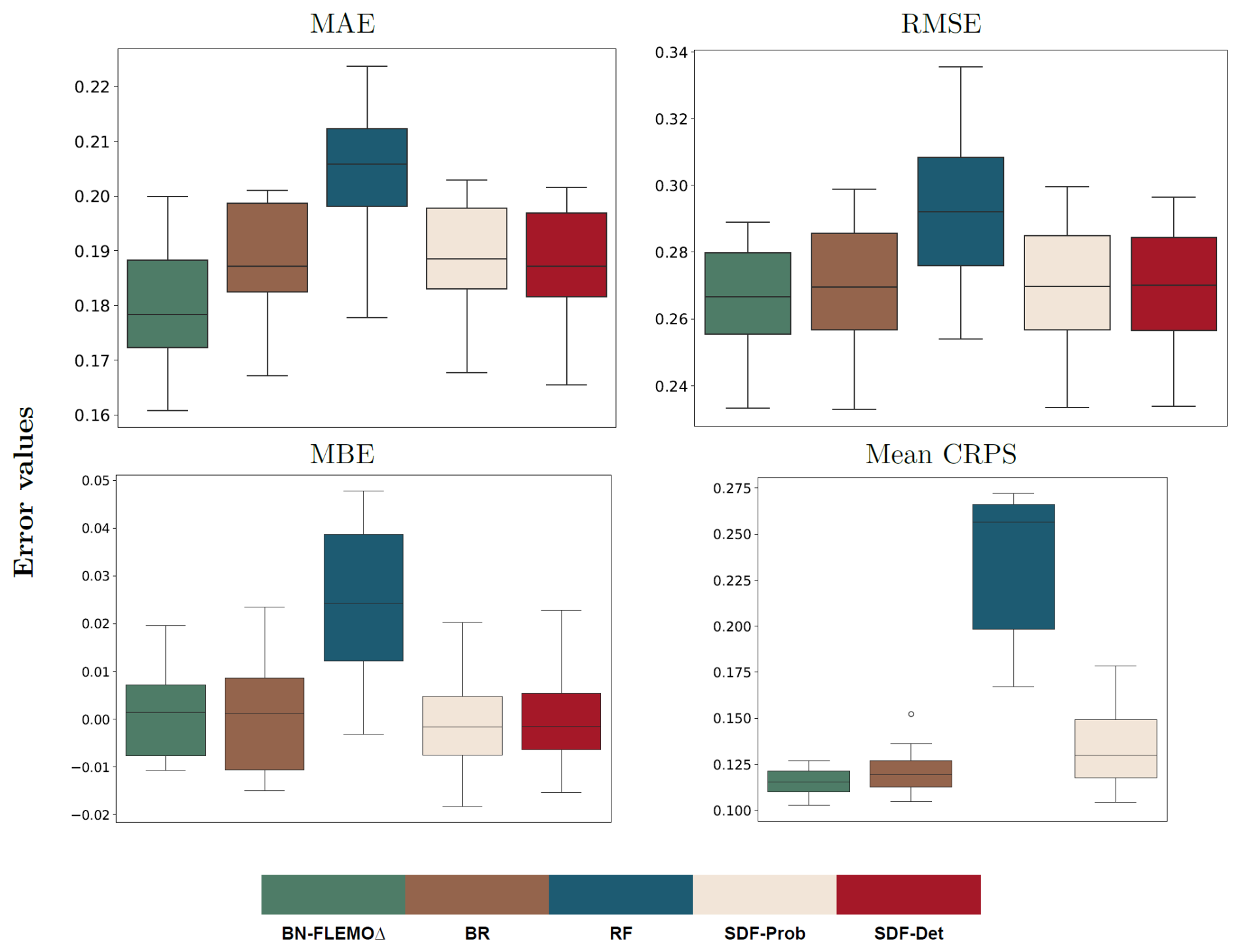
Figure 5The quantitative evaluation of the predictive performance of ML-based approaches including the Bayesian network flood loss estimation model (BN-FLEMOΔ), Bayesian regression (BR), random forest (RF), the probabilistic stage damage function (SDF-Prob), and the deterministic stage damage function (SDF-Det). The x axes display the ML-based approaches deployed, while the y axes illustrate their respective error values based on various evaluation metrics.
The probabilistic flood loss estimation model BN-FLEMOΔ presented here is based on a large dataset (n = 1000) of newly acquired empirical building-level survey data from HCMC. To construct this model, we introduce an automatic feature selection framework for the identification of key drivers of loss, complemented by a systematic learning approach for optimizing the Bayesian network structure to accurately capture loss processes. Notably, BN-FLEMOΔ offers the ability to quantify model uncertainty by providing a probability distribution of losses, making it robust even in scenarios where data for certain predictors are missing. Moreover, the model incorporates predictors related to precautionary measures (e.g. building elevation), enabling the evaluation of adaptation strategies. Since Bayesian networks provide structured updating mechanisms with new data, BN-FLEMOΔ is adaptable to changing conditions and transferable to other, similar delta cities. Consequently, it is a valuable tool for supporting decision-makers in developing adaptation strategies in data-scarce and rapidly evolving environments like delta cities. To this end, BN-FLEMOΔ is provided to flood risk experts for application via the DECIDER decision support tool (DST, https://plan-risk-consult.de/decider/, last access: 31 October 2023), complemented by descriptions and data. To ease in model application, a precomputed lookup table is provided, which associates all possible combinations of predictor variable values with the building loss that the Bayesian network predicts.
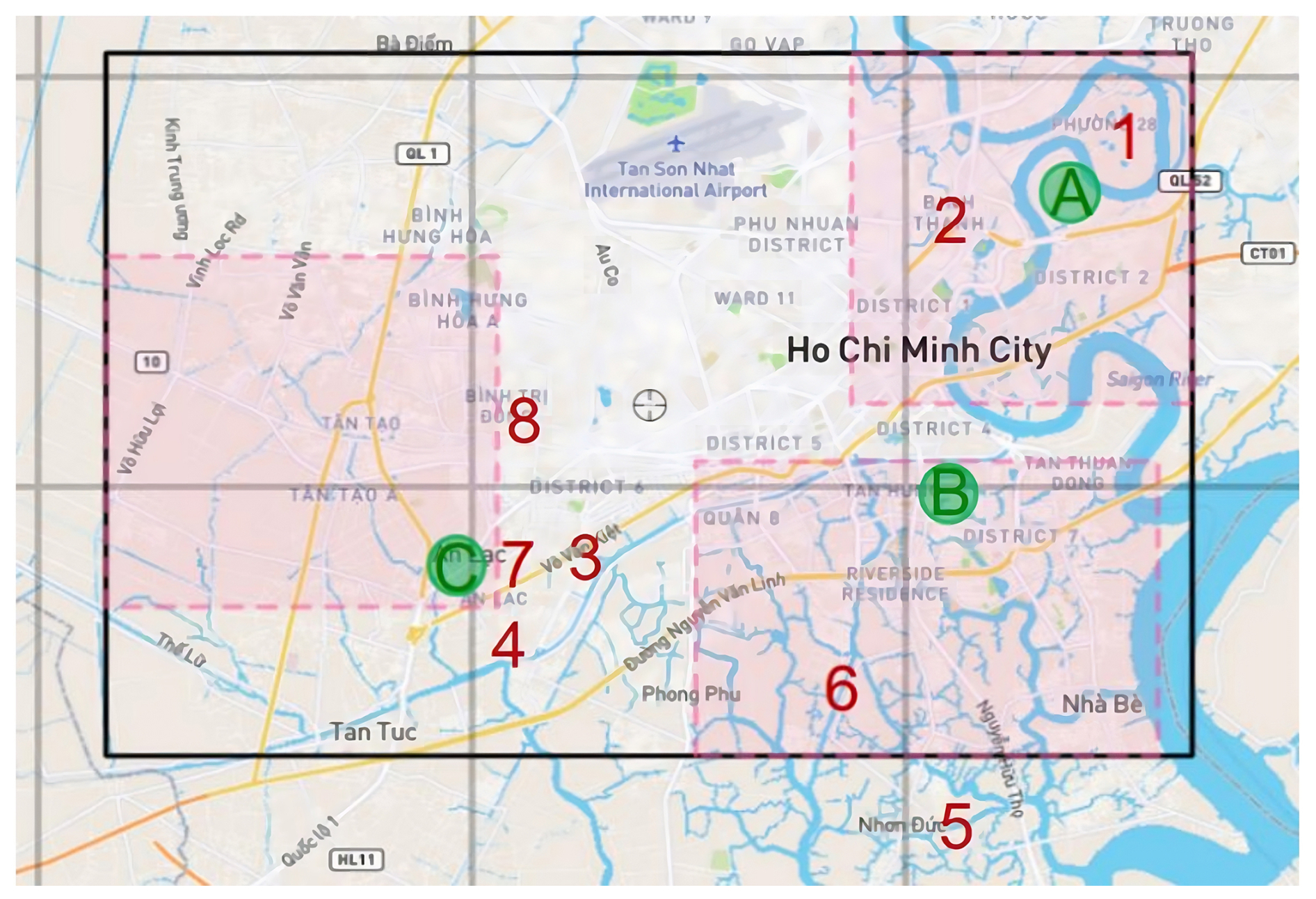
Figure A1Selected survey areas in Ho Chi Minh City. Red numbers are the sites of the main survey in 2020. Green letters indicate the areas of the pretest survey in December 2019 (Yang et al., 2020).
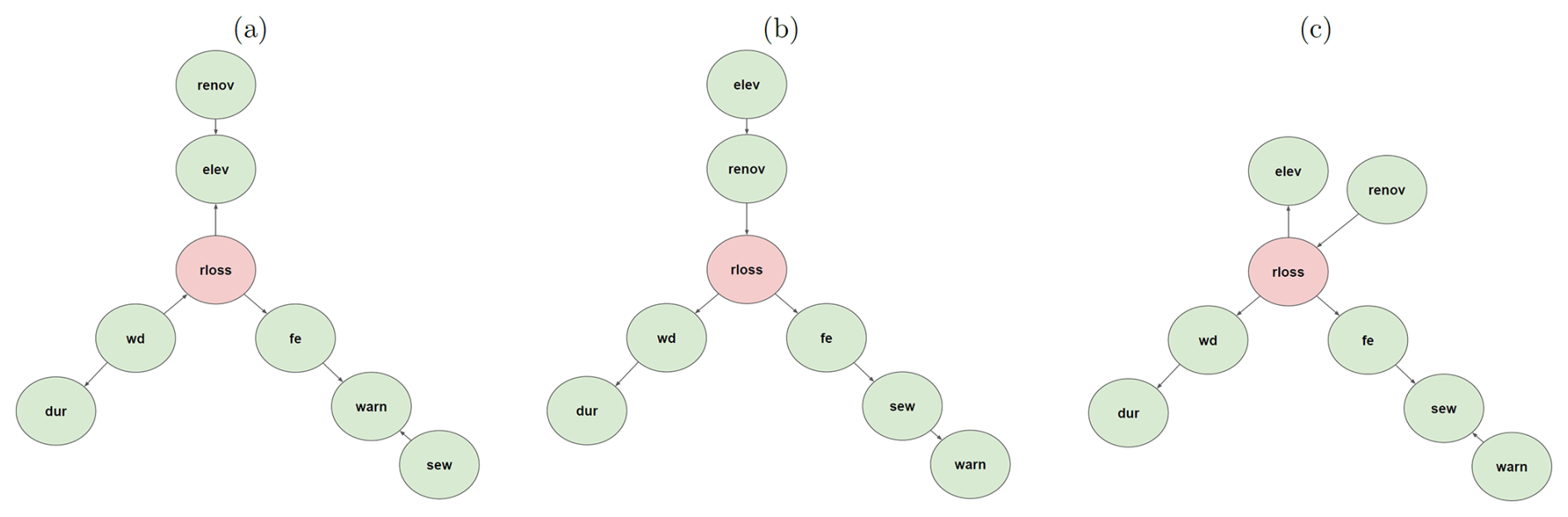
Figure A2The Bayesian networks constructed by categorizing the relative loss (rloss) into (a) three bins, (b) five bins, and (c) seven bins.
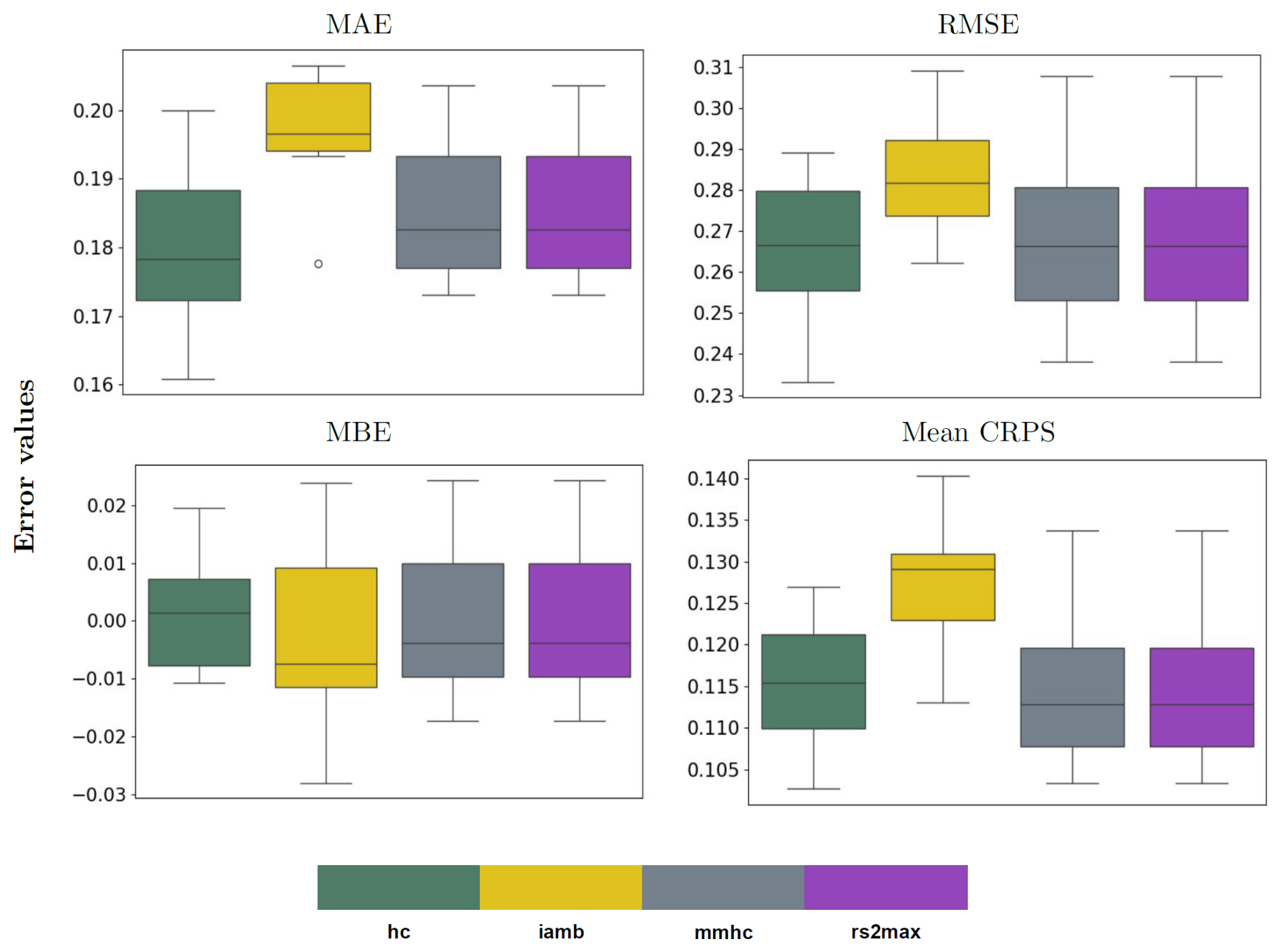
Figure A3The quantitative performance of different structure learning algorithms, namely hill-climbing (hc), incremental association (iamb), max–min hill climbing (mmhc), and general two-phase restricted maximization (rs2max), which were used to build the BN-FLEMOΔ model.
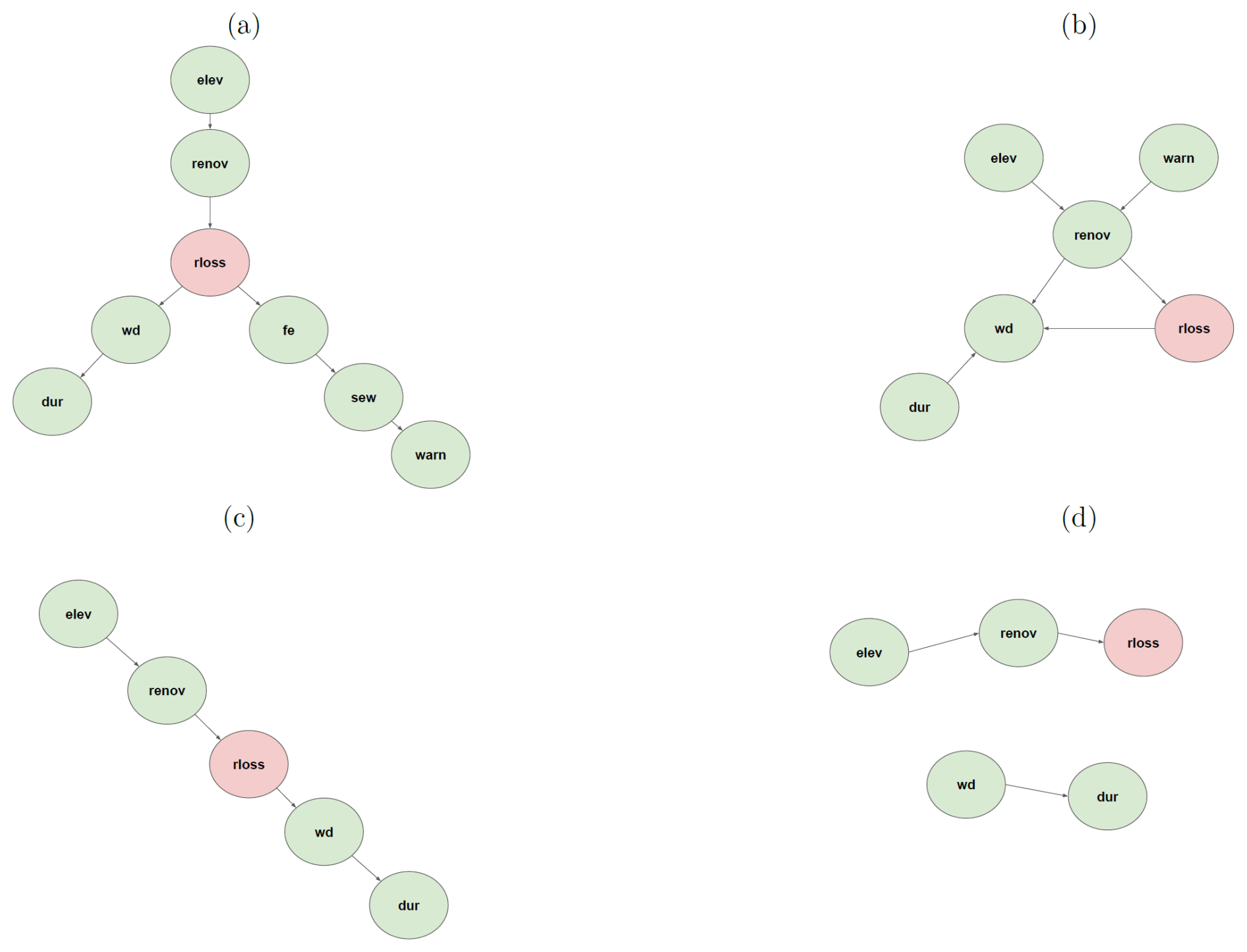
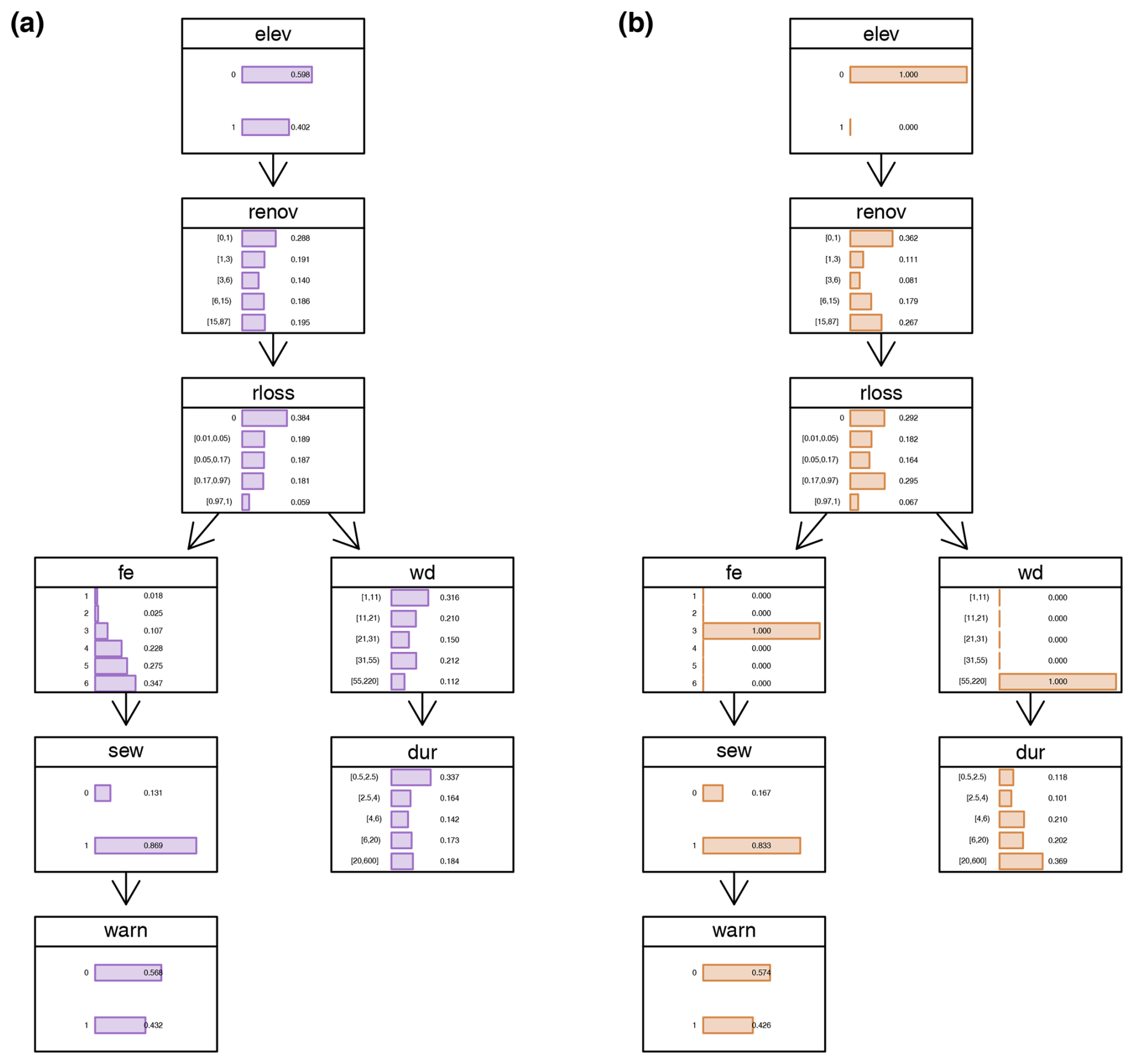
Figure A5Bayesian network structure and parameters learned from the survey data. Panel (a) shows the marginal probability distributions of the fitted network. Panel (b) shows an example prediction of the Bayesian network, in which three predictor variables are assumed to be known (wd, fe, elev). The marginal probability distribution of the relative loss is updated based on the evidence in the nodes of these three predictors.
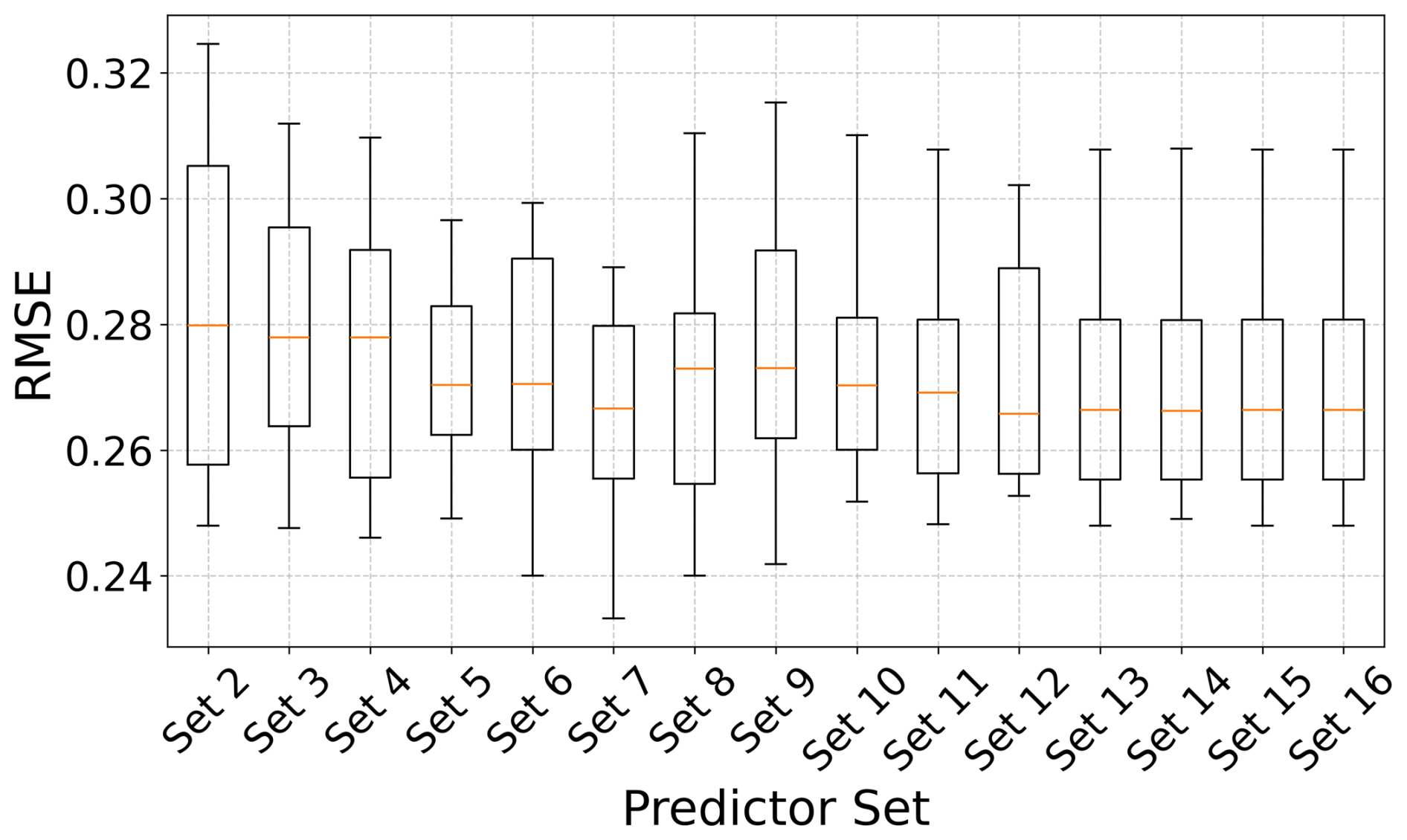
Figure A6This figure illustrates the predictive performance of BN-FLEMOΔ in terms of RMSE, with different predictor sets representing the incremental addition of independent variables as inputs to the model, following the order determined by the feature selection process.
Table A1The questionnaire that was used during the survey campaign. This subset of the original version contains information on the 16 potentially important flood loss drivers studied in this work.
The code used for our analysis can be provided upon request to the corresponding author.
The survey data used in this study will be made available via the HOWAS21 flood damage database. The HOWAS21 database is made accessible at https://doi.org/10.1594/GFZ.SDDB.HOWAS21 (Kreibich et al., 2007). In addition, precomputed lookup tables generated by BN-FLEMOΔ can be found at https://doi.org/10.5880/GFZ.4.4.2023.002 (Rafiezadeh Shahi et al., 2025). Such information facilitates the extension of flood loss estimation for mesoscale application in HCMC.
KRS, NS, LS, and HK: conceptualization; KRS, NS, LS, and HK: methodology; KRS and NS: data curation; KRS and LS: software; KRS: analysis and visualization; KRS: writing – original draft; KRS, NS, LS, LeS, DT, and HK: writing – review and editing.
At least one of the (co-)authors is a member of the editorial board of Natural Hazards and Earth System Sciences. The peer-review process was guided by an independent editor, and the authors also have no other competing interests to declare.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This research has been supported by the Bundesministerium für Bildung und Forschung (grant nos. 01LZ1703G and 01LZ1703A).
The article processing charges for this open-access publication were covered by the GFZ Helmholtz Centre for Geosciences.
This paper was edited by Maria-Carmen Llasat and reviewed by two anonymous referees.
Aguilera, P. A., Fernández, A., Fernández, R., Rumí, R., and Salmerón, A.: Bayesian networks in environmental modelling, Environ. Modell. Softw., 26, 1376–1388, 2011. a, b
Apel, H., Aronica, G., Kreibich, H., and Thieken, A.: Flood risk analyses – how detailed do we need to be?, Nat. Hazards, 49, 79–98, 2009. a
Ayyanar, M., Jeganathan, S., Parthasarathy, S., Jayaraman, V., and Lakshminarayanan, A. R.: Predicting the Cardiac Diseases using SelectKBest Method Equipped Light Gradient Boosting Machine, in: 2022 6th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 28–30 April 2022, IEEE, 117–122, https://doi.org/10.1109/ICOEI53556.2022.9777224, 2022. a, b
Bangalore, M., Smith, A., and Veldkamp, T.: Exposure to floods, climate change, and poverty in Vietnam, Economics of Disasters and Climate Change, 3, 79–99, 2019. a
Bank, A. D.: Ho Chi Minh City adaptation to climate change, Summary Report, Asian Development Bank, Mandaluyong City, Philippines, ISBN 978-971-561-893-9, 2010. a, b
Cao, A., Esteban, M., Valenzuela, V. P. B., Onuki, M., Takagi, H., Thao, N. D., and Tsuchiya, N.: Future of Asian Deltaic Megacities under sea level rise and land subsidence: current adaptation pathways for Tokyo, Jakarta, Manila, and Ho Chi Minh City, Curr. Opin. Env. Sust., 50, 87–97, 2021. a, b
Chen, Y.-C., Wheeler, T. A., and Kochenderfer, M. J.: Learning discrete Bayesian networks from continuous data, J. Artif. Intell. Res., 59, 103–132, 2017. a
Chinh, D. T., Dung, N. V., Gain, A. K., and Kreibich, H.: Flood loss models and risk analysis for private households in Can Tho City, Vietnam, Water, 9, 313, https://doi.org/10.3390/w9050313, 2017. a, b, c, d, e, f
Couasnon, A., Scussolini, P., Tran, T., Eilander, D., Muis, S., Wang, H., Keesom, J., Dullaart, J., Xuan, Y., Nguyen, H., Winsemius, H. C., and Ward, P. J.: A Flood Risk Framework Capturing the Seasonality of and Dependence Between Rainfall and Sea Levels – An Application to Ho Chi Minh City, Vietnam, Water Resour. Res., 58, e2021WR030002, https://doi.org/10.1029/2021WR030002, 2022. a, b, c
de Brito, M. M. and Evers, M.: Multi-criteria decision-making for flood risk management: a survey of the current state of the art, Nat. Hazards Earth Syst. Sci., 16, 1019–1033, https://doi.org/10.5194/nhess-16-1019-2016, 2016. a
De Moel, H., Jongman, B., Kreibich, H., Merz, B., Penning-Rowsell, E., and Ward, P. J.: Flood risk assessments at different spatial scales, Mitig. Adapt. Strat. Gl., 20, 865–890, 2015. a
Desyani, T., Saifudin, A., and Yulianti, Y.: Feature selection based on naive bayes for caesarean section prediction, IOP Conf. Ser.-Mat. Sci., 879, 012091, https://doi.org/10.1088/1757-899X/879/1/012091, 2020. a
Elmer, F., Thieken, A. H., Pech, I., and Kreibich, H.: Influence of flood frequency on residential building losses, Nat. Hazards Earth Syst. Sci., 10, 2145–2159, https://doi.org/10.5194/nhess-10-2145-2010, 2010. a
Fisher, R. A.: Statistical methods for research workers, in: Breakthroughs in statistics: Methodology and distribution, Springer, 66–70, ISBN 9788130701332, 1970. a
Friedman, N., Nachman, I., and Pe'er, D.: Learning Bayesian network structure from massive datasets: The “sparse candidate” algorithm, arXiv [preprint], https://doi.org/10.48550/arXiv.1301.6696, 23 January 2013. a
Garschagen, M. and Romero-Lankao, P.: Exploring the relationships between urbanization trends and climate change vulnerability, Climatic Change, 133, 37–52, 2015. a
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B.: Bayesian data analysis, 3rd edn., Chapman and Hall/CRC, ISBN 9780429113079, https://doi.org/10.1201/b16018, 2013. a
Gerl, T., Kreibich, H., Franco, G., Marechal, D., and Schröter, K.: A review of flood loss models as basis for harmonization and benchmarking, PLoS ONE, 11, e0159791, https://doi.org/10.1371/journal.pone.0159791, 2016. a
Gneiting, T. and Raftery, A. E.: Strictly proper scoring rules, prediction, and estimation, J. Am. Stat. Assoc., 102, 359–378, 2007. a
Hallegatte, S., Green, C., Nicholls, R. J., and Corfee-Morlot, J.: Future flood losses in major coastal cities, Nat. Clim. Change, 3, 802–806, 2013. a
Hanson, S., Nicholls, R., Ranger, N., Hallegatte, S., Corfee-Morlot, J., Herweijer, C., and Chateau, J.: A global ranking of port cities with high exposure to climate extremes, Climatic Change, 104, 89–111, 2011. a
Hocking, R. R.: A Biometrics invited paper. The analysis and selection of variables in linear regression, Biometrics, 32, 1–49, 1976. a
Hothorn, T., Hornik, K., and Zeileis, A.: Unbiased recursive partitioning: A conditional inference framework, J. Comput. Graph. Stat., 15, 651–674, 2006. a
IPCC: Climate Change 2022 – Impacts, Adaptation and Vulnerability: Working Group II Contribution to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change, Cambridge University Press, 2023. a
Jensen, F. V. and Nielsen, T. D.: Bayesian networks and decision graphs, Vol. 2, Springer, ISBN 0387682821, https://doi.org/10.1007/978-0-387-68282-2, 2007. a
Kreibich, H., Thieken, A. H., Petrow, Th., Müller, M., and Merz, B.: Flood loss reduction of private households due to building precautionary measures – lessons learned from the Elbe flood in August 2002, Nat. Hazards Earth Syst. Sci., 5, 117–126, https://doi.org/10.5194/nhess-5-117-2005, 2005. a
Kreibich, H., Thieken, A., Haubrock, S.-N., and Schröter, K.: HOWAS21, the German flood damage database, GFZ German Research Centre for Geosciences [data set], https://doi.org/10.1594/GFZ.SDDB.HOWAS21, 2007. a
Lasage, R., Veldkamp, T. I. E., de Moel, H., Van, T. C., Phi, H. L., Vellinga, P., and Aerts, J. C. J. H.: Assessment of the effectiveness of flood adaptation strategies for HCMC, Nat. Hazards Earth Syst. Sci., 14, 1441–1457, https://doi.org/10.5194/nhess-14-1441-2014, 2014. a
Liashchynskyi, P. and Liashchynskyi, P.: Grid search, random search, genetic algorithm: a big comparison for NAS, arXiv [preprint], https://doi.org/10.48550/arXiv.1912.06059, 12 December 2019. a
Lüdtke, S., Schröter, K., Steinhausen, M., Weise, L., Figueiredo, R., and Kreibich, H.: A Consistent Approach for Probabilistic Residential Flood Loss Modeling in Europe, Water Resour. Res., 55, 10616–10635, https://doi.org/10.1029/2019WR026213, 2019. a, b
Luu, C., von Meding, J., and Mojtahedi, M.: Analyzing Vietnam's national disaster loss database for flood risk assessment using multiple linear regression-TOPSIS, Int. J. Disast. Risk Re., 40, 101153, https://doi.org/10.1016/j.ijdrr.2019.101153, 2019. a, b, c
Merz, B. and Thieken, A. H.: Flood risk curves and uncertainty bounds, Nat. Hazards, 51, 437–458, 2009. a, b
Merz, B., Kreibich, H., Schwarze, R., and Thieken, A.: Review article “Assessment of economic flood damage”, Nat. Hazards Earth Syst. Sci., 10, 1697–1724, https://doi.org/10.5194/nhess-10-1697-2010, 2010. a, b, c, d
Merz, B., Kreibich, H., and Lall, U.: Multi-variate flood damage assessment: a tree-based data-mining approach, Nat. Hazards Earth Syst. Sci., 13, 53–64, https://doi.org/10.5194/nhess-13-53-2013, 2013. a, b
Mohor, G. S., Thieken, A. H., and Korup, O.: Residential flood loss estimated from Bayesian multilevel models, Nat. Hazards Earth Syst. Sci., 21, 1599–1614, https://doi.org/10.5194/nhess-21-1599-2021, 2021. a, b, c, d
Nagarajan, R., Scutari, M., and Lèbre, S.: Bayesian Networks in R, Springer New York, New York, NY, https://doi.org/10.1007/978-1-4614-6446-4, ISBN 978-1-4614-6445-7, 2013. a
Nguyen, M., Le, N., Nguyen, N., Dang, Q., Le, D., Nguyen, N., and Nguyen, T.: The main causes of flooding in Ho Chi Minh City, Vietnam Journal of Hydrometeorological, 716, 21–36, https://doi.org/10.36335/VNJHM.2023(747).21-36, 2023. a
Nguyen, M. T., Sebesvari, Z., Souvignet, M., Bachofer, F., Braun, A., Garschagen, M., Schinkel, U., Yang, L. E., Nguyen, L. H. K., Hochschild, V., Assmann, A., and Hagenlocher, M.: Understanding and assessing flood risk in Vietnam: current status, persisting gaps, and future directions, J. Flood Risk Manag., 14, e12689, https://doi.org/10.1111/jfr3.12689, 2021. a
Ospina, R. and Ferrari, S. L.: Inflated beta distributions, Stat. Pap., 51, 111–126, 2010. a
Pappenberger, F. and Beven, K. J.: Ignorance is bliss: Or seven reasons not to use uncertainty analysis, Water Resour. Res., 42, W05302, https://doi.org/10.1029/2005WR004820, 2006. a
Paprotny, D., Kreibich, H., Morales-Nápoles, O., Wagenaar, D., Castellarin, A., Carisi, F., Bertin, X., Merz, B., and Schröter, K.: A probabilistic approach to estimating residential losses from different flood types, Nat. Hazards, 105, 2569–2601, 2021. a
Pelizari, P. A., Geiß, C., Aguirre, P., Santa María, H., Peña, Y. M., and Taubenböck, H.: Automated building characterization for seismic risk assessment using street-level imagery and deep learning, ISPRS J. Photogramm., 180, 370–386, 2021. a
Penning-Rowsell, E. and Green, C.: New insights into the appraisal of flood-alleviation benefits: (1) flood damage and flood loss information, Water Environ. J., 14, 347–353, 2000. a
Penning-Rowsell, E., Priest, S., Parker, D., Morris, J., Tunstall, S., Viavattene, C., Chatterton, J., and Owen, D.: Flood and Coastal Erosion Risk Management: A Manual for Economic Appraisal, Taylor & Francis, ISBN 9781135074531, https://books.google.de/books?id=6ReMAgAAQBAJ (last access: 17 April 2023), 2014. a
Poljansek, K., Marin Ferrer, M., De Groeve, T., and Clark, I. (Eds.): Science for Disaster Risk Management 2017: Knowing better and losing less, Publications Office of the European Union, Luxembourg, 2017, ISBN 978-92-79-60679-3 (main report online), 978-92-79-60678-6 (main report print), 978-92-79-69673-2 (executive summary online), 978-92-79-69674-9 (executive summary print), 978-92-79-74167-8 (executive summary ePub), JRC102482, https://doi.org/10.2788/842809, 2017. a
Rafiezadeh Shahi, K., Sairam, N., Schoppa, L., Thanh Sang, L., Ly Hoai Tan, D., and Kreibich, H.: Lookup table of the BN-FLEMOΔ: A Bayesian Network-based Flood Loss Estimation Model for Ho Chi Minh City, Vietnam, GFZ Data Services [data set], https://doi.org/10.5880/GFZ.4.4.2023.002, 2025. a
Rözer, V., Kreibich, H., Schröter, K., Müller, M., Sairam, N., Doss-Gollin, J., Lall, U., and Merz, B.: Probabilistic models significantly reduce uncertainty in Hurricane Harvey pluvial flood loss estimates, Earth's Future, 7, 384–394, 2019. a, b
Russell, S. J.: Artificial intelligence a modern approach, Pearson Education, Inc., ISBN 978-0-13-4610993, 2010. a
Sairam, N., Schröter, K., Rözer, V., Merz, B., and Kreibich, H.: Hierarchical Bayesian approach for modeling spatiotemporal variability in flood damage processes, Water Resour. Res., 55, 8223–8237, 2019. a
Scawthorn, C., Flores, P., Blais, N., Seligson, H., Tate, E., Chang, S., Mifflin, E., Thomas, W., Murphy, J., Jones, C., and Lawrence, M.: HAZUS-MH flood loss estimation methodology. II. Damage and loss assessment, Nat. Hazards Rev., 7, 72–81, 2006. a
Scheiber, L., Hoballah Jalloul, M., Jordan, C., Visscher, J., Nguyen, H. Q., and Schlurmann, T.: The potential of open-access data for flood estimations: uncovering inundation hotspots in Ho Chi Minh City, Vietnam, through a normalized flood severity index, Nat. Hazards Earth Syst. Sci., 23, 2313–2332, https://doi.org/10.5194/nhess-23-2313-2023, 2023. a
Schoppa, L., Sieg, T., Vogel, K., Zöller, G., and Kreibich, H.: Probabilistic flood loss models for companies, Water Resour. Res., 56, e2020WR027649, https://doi.org/10.1029/2020WR027649, 2020. a, b, c, d, e, f
Schröter, K., Kreibich, H., Vogel, K., Riggelsen, C., Scherbaum, F., and Merz, B.: How useful are complex flood damage models?, Water Resour. Res., 50, 3378–3395, 2014. a, b
Scussolini, P., Tran, T. V. T., Koks, E., Diaz-Loaiza, A., Ho, P. L., and Lasage, R.: Adaptation to sea level rise: a multidisciplinary analysis for Ho Chi Minh City, Vietnam, Water Resour. Res., 53, 10841–10857, 2017. a, b, c
Scutari, M. and Denis, J.-B.: Bayesian Networks, Chapman and Hall/CRC, Boca Raton, https://doi.org/10.1201/b17065, ISBN 9781482225594, 2014. a
Sieg, T., Vogel, K., Merz, B., and Kreibich, H.: Tree-based flood damage modeling of companies: Damage processes and model performance, Water Resour. Res., 53, 6050–6068, 2017. a, b
Smith, D. I.: Flood damage estimation-A review of urban stage-damage curves and loss functions, Water SA, 20, 231–238, 1994. a
Thieken, A., Olschewski, A., Kreibich, H., Kobsch, S., and Merz, B.: Development and evaluation of FLEMOps–a new Flood Loss Estimation MOdel for the private sector, WIT Trans. Ecol. Envir., 118, 315–324, 2008. a, b, c
Thieken, A. H., Müller, M., Kreibich, H., and Merz, B.: Flood damage and influencing factors: New insights from the August 2002 flood in Germany, Water Resour. Res., 41, W12430, https://doi.org/10.1029/2005WR004177, 2005. a, b
Tsamardinos, I., Aliferis, C., and Statnikov, A.: Algorithms for Large Scale Markov Blanket Discovery, The AAAI Press, Menlo Park, California, 376–381, ISBN 978-1-57735-177-1, 2003. a
Tsamardinos, I., Brown, L. E., and Aliferis, C. F.: The max-min hill-climbing Bayesian network structure learning algorithm, Mach. Learn., 65, 31–78, 2006. a
UNDRR: Global Assessment Report on Disaster Risk Reduction 2022: Our World at Risk: Transforming Governance for a Resilient Future, United Nations Office for Disaster Risk Reduction, Geneva, Switzerland, ISBN 9789210015059, https://doi.org/10.18356/9789210015059c007, 2022. a
Vachaud, G., Quertamp, F., Phan, T. S. H., Ngoc, T. D. T., Nguyen, T., Luu, X. L., Nguyen, A. T., and Gratiot, N.: Flood-related risks in Ho Chi Minh City and ways of mitigation, J. Hydrol., 573, 1021–1027, 2019. a
Vishwanath Harish, T., Sairam, N., Yang, L. E., Garschagen, M., and Kreibich, H.: Identifying the drivers of private flood precautionary measures in Ho Chi Minh City, Vietnam, Nat. Hazards Earth Syst. Sci., 23, 1125–1138, https://doi.org/10.5194/nhess-23-1125-2023, 2023. a, b, c, d
Vogel, K., Riggelsen, C., Korup, O., and Scherbaum, F.: Bayesian network learning for natural hazard analyses, Nat. Hazards Earth Syst. Sci., 14, 2605–2626, https://doi.org/10.5194/nhess-14-2605-2014, 2014. a
Vogel, K., Weise, L., Schröter, K., and Thieken, A. H.: Identifying driving factors in flood-damaging processes using graphical models, Water Resour. Res., 54, 8864–8889, 2018. a, b
Wagenaar, D., Lüdtke, S., Schröter, K., Bouwer, L. M., and Kreibich, H.: Regional and Temporal Transferability of Multivariable Flood Damage Models, Water Resour. Res., 54, 3688–3703, https://doi.org/10.1029/2017WR022233, 2018. a, b, c
Wind, H., Nierop, T., De Blois, C., and de Kok, J.-L.: Analysis of flood damages from the 1993 and 1995 Meuse floods, Water Resour. Res., 35, 3459–3465, 1999. a
Wu, C.-F., Chen, S.-H., Cheng, C.-W., and Trac, L. V. T.: Climate Justice Planning in Global South: Applying a Coupled Nature–Human Flood Risk Assessment Framework in a Case for Ho Chi Minh City, Vietnam, Water, 13, 2021, https://doi.org/10.3390/w13152021, 2021. a
Yang, L., Garschagen, M., Revilla Diez, J., Kreibich, H., Sairam, N., Scheiber, L., Hochschild, V., and Leitold, R.: DECIDER Project Newsletter, 1, https://doi.org/10.13140/RG.2.2.23567.41125, 2020. a