the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 13 May 2020
| 13 May 2020
Non-stationary extreme value analysis applied to seismic fragility assessment for nuclear safety analysis
Pierre Gehl
Marine Marcilhac-Fradin
Yves Guigueno
Nadia Rahni
Julien Clément
Fragility curves (FCs) are key tools for seismic probabilistic safety assessments that are performed at the level of the nuclear power plant (NPP). These statistical methods relate the probabilistic seismic hazard loading at the given site to the required performance of the NPP safety functions. In the present study, we investigate how the tools of non-stationary extreme value analysis can be used to model in a flexible manner the tail behaviour of the engineering demand parameter as a function of the considered intensity measure. We focus the analysis on the dynamic response of an anchored steam line and of a supporting structure under seismic solicitations. The failure criterion is linked to the exceedance of the maximum equivalent stress at a given location of the steam line. A series of three-component ground-motion records (∼300) were applied at the base of the model to perform non-linear time history analyses. The set of numerical results was then used to derive a FC, which relates the failure probability to the variation in peak ground acceleration (PGA). The probabilistic model of the FC is selected via information criteria completed by diagnostics on the residuals, which support the choice of the generalised extreme value (GEV) distribution (instead of the widely used log-normal model). The GEV distribution is here non-stationary, and the relationships of the GEV parameters (location, scale and shape) are established with respect to PGA using smooth non-linear models. The procedure is data-driven, which avoids the introduction of any a priori assumption on the shape or form of these relationships. To account for the uncertainties in the mechanical and geometrical parameters of the structures (elastic stiffness, damping, pipeline thicknesses, etc.), the FC is further constructed by integrating these uncertain parameters. A penalisation procedure is proposed to set to zero the variables of little influence in the smooth non-linear models. This enables us to outline which of these parametric uncertainties have negligible influence on the failure probability as well as the nature of the influence (linear, non-linear, decreasing, increasing, etc.) with respect to each of the GEV parameters.
- Article
(3355 KB) - Full-text XML
- BibTeX
- EndNote





A crucial step of any seismic probability risk assessment (PRA) is the vulnerability analysis of structures, systems and components (SSCs) with respect to the external loading induced by earthquakes. To this end, fragility curves (FCs), which relate the probability of an SSC to exceed a predefined damage state as a function of an intensity measure (IM) representing the hazard loading, are common tools. Formally, FC expresses the conditional probability with respect to the IM value (denoted “im”) and to the EDP (engineering demand parameter) obtained from the structural analysis (force, displacement, drift ratio, etc.) as follows:
where “th” is an acceptable demand threshold.
FCs are applied to a large variety of different structures, like residential buildings (e.g. Gehl et al., 2013), nuclear power plants (Zentner et al., 2017), wind turbines (Quilligan et al., 2012), underground structures (Argyroudis and Pitilakis, 2012), etc. Their probabilistic nature makes them well suited for PRA applications, at the interface between probabilistic hazard assessments and event tree analyses, in order to estimate the occurrence rate of undesirable top events.
Different procedures exist to derive FCs (see e.g. an overview by Zentner et al., 2017). In the present study, we focus on the analytical approach, which aims at deriving a parametric cumulative distribution function (CDF) from data collected from numerical structural analyses. A common assumption in the literature is that the logarithm of “im” is normally distributed (e.g. Ellingwood, 2001) as follows:
where Φ is the standard normal cumulative distribution function, α is the median and β is lognormal standard deviation. The parameters of the normal distribution are commonly estimated either by maximum likelihood estimation (see e.g. Shinozuka et al., 2000) or by fitting a linear probabilistic seismic demand model on the log scale (e.g. Banerjee and Shinozuka, 2008).
This procedure faces, however, limits in practice.
-
Limit (1). The assumption of normality may not always be valid in all situations, as discussed by Mai et al. (2017) and Zentner et al. (2017). This widely used assumption is especially difficult to justify when the considered EDP corresponds to the maximum value of the variable of interest (for instance maximum transient stress value), i.e. when the FC serves to model extreme values.
-
Limit (2). A second commonly used assumption is the homoscedasticity of the underlying probabilistic model, i.e. the variance term β is generally assumed to be constant over the domain of the IM.
-
Limit (3). The assumption of linearity regarding the relation between the median and IM may not always hold valid, as shown for instance by Wang et al. (2018) using artificial neural networks.
-
Limit (4). A large number of factors may affect the estimate of Pf in addition to IM; for instance epistemic uncertainties due to the identification and characterisation of some mechanical (elastic stiffness, damping ratio, etc.) and geometrical parameters of the considered structure.
The current study aims at going a step forward in the development of seismic FCs by improving the procedure regarding the aforementioned limits. To deal with limit (1), we propose relying on the tools of extreme value statistics (Coles, 2001) and more specifically on the generalised extreme value (GEV) distribution, which can model different extremes' behaviour.
Note that the focus is on the extremes related to EDP, not on the forcing, i.e. the analysis does not model the extremes of IM as is done for current practices of probabilistic seismic hazard analysis (see e.g. Dutfoy, 2019). This means that no preliminary screening is applied, which implies that the FC derivation is conducted by considering both large and intermediate earthquakes, i.e. IM values that are small–moderate to large.
The use of GEV is examined using criteria for model selection like Akaike or Bayesian information criteria (Akaike, 1998; Schwarz, 1978). Limits (2) and (3) are addressed using tools for distributional regression (e.g. Koenker et al., 2013) within the general framework of the Generalized Additive Model for Location, Scale and Shape (GAMLSS) parameter (e.g. Rigby and Stasinopoulos, 2005). GAMLSS is very flexible in the sense that the mathematical relation of the median and variance in Eq. (1) can be learnt from the data via non-linear smooth functions. GAMLSS can be applied to any parametric probabilistic model and here to the GEV model as a particular case. This enables us to fit a non-stationary GEV model, i.e. a GEV model for which the parameters vary as a function of some covariates (here corresponding to IM and U). The use of data-driven non-linear smooth functions avoids introducing a priori a parametric model (linear or polynomial) as many authors do (see an example by for sea level extremes by Wong, 2018, and for temperature by Cheng et al., 2014).
Finally, accounting for the epistemic uncertainties in the FC derivation (limit (4)) can be conducted in different manners. A first option can rely on the incremental dynamic analysis (IDA), where the uncertain mechanical and geometrical parameters result in uncertain capacities (i.e. related to the threshold “th” in Eq. 1). The FC is then derived through convolution with the probabilistic distribution of the demand parameter; see Vamvatsikos and Cornell (2002). Depending on the complexity of the system (here for NPP), the adaptation of IDA to non-linear dynamic structural numerical simulations can be tedious (this is further discussed in Sect. 3.1). In the present study, we preferably opt for a second approach by viewing Pf as conditional on the vector of uncertain mechanical and geometrical factors U (in addition to IM), namely
Dealing with Eq. (3) then raises the question of integrating a potentially large number of variables, which might hamper the stability and quality of the procedure for FC construction. This is handled with a penalisation procedure (Marra and Wood, 2011), which enables the analyst to screen the uncertainties of negligible influence.
The paper is organised as follows. Section 2 describes the statistical methods to derive non-stationary GEV-based seismic fragility curves. Then, in Sect. 3, we describe a test case related to the seismic fragility assessment for a steam line of a nuclear power plant. For this case, the derivation of FC is performed by considering the widely used IM in the domain of seismic engineering, namely peak ground acceleration (PGA). Finally, the proposed procedure is applied in Sect. 4 to two cases, without and with epistemic uncertainties, and the results are discussed in Sect. 5.
In this section, we first describe the main steps of the proposed procedure for deriving the FC (Sect. 2.1). The subsequent sections provide technical details on the GEV probability model (Sect. 2.2), its non-stationary formulation and implementation (Sect. 2.3) within the GAMLSS framework, and its combination with variable selection (Sect. 2.4).
2.1 Overall procedure
To derive the seismic FC, the following overall procedure is proposed.
-
Step 1 consists of analysing the validity of using the GEV distribution with respect to alternative probabilistic models (like the normal distribution of Eq. 2 in particular).
-
Depending on the results of step 1, step 2 aims at fitting the non-stationary GEV model using the double-penalisation formulation described in Sect. 2.2 and 2.3.
-
Step 3 aims at producing some diagnostic information about the fitting procedure and results. The first diagnostic test uses the Q–Q plot of the model deviance residuals (conditional on the fitted model coefficients and scale parameter) formulated by Augustin et al. (2012). If the model distributional assumptions are met, then the Q–Q plot should be close to a straight line. The second diagnostic test relies on a transformation of the data to a Gumbel distributed random variable (e.g. Beirlant et al., 2004) and on an analysis of the corresponding Gumbel Q–Q and P–P plot.
-
Step 4 aims at analysing the partial effect of each input variable (i.e. the smooth non-linear term; see Eq. 4 in Sect. 2.3) to assess the influence of the different GEV parameters.
-
Step 5 aims at deriving the seismic FC by evaluating the failure probability . The following procedure is conducted to account for the epistemic uncertainties:
-
Step 5.1 – the considered IM is fixed at a given value,
-
Step 5.2 – for the considered IM value, a large number (here chosen at n=1000) of U samples are randomly generated,
-
Step 5.3 – for each of the randomly generated U samples, the failure probability is estimated for the considered IM value,
-
Step 5.4 – return to step 5.1.
-
The result of the procedure corresponds to a set of n FCs from which we can derive the median FC as well as the uncertainty bands based on the pointwise confidence intervals at different levels. These uncertainty bands thus reflect the impact of the epistemic uncertainty related to the mechanical and geometrical parameters. Due to the limited number of observations, the derived FC is associated to the uncertainty on the fitting of the probabilistic model (e.g. GEV or Gaussian) as well. To integrate this fitting uncertainty in the analysis, step 5 can be extended by randomly generating parameters of the considered probabilistic model at step 5.2 (by assuming that they follow a multivariate Gaussian distribution).
2.2 Model selection
Selecting the most appropriate probabilistic models is achieved by means of information criteria, as recommended in the domain of non-stationary extreme value analysis (e.g. Kim et al., 2017; Salas and Obeysekera, 2014) and more particularly recommended for choosing among various fragility models (e.g. Lallemant et al., 2015); see also an application of these criteria in the domain of nuclear safety by Zentner (2017). We focus on two information criteria, namely Akaike and Bayesian information criteria (Akaike, 1998; Schwarz, 1978), respectively denoted AIC and BIC, whose formulation holds as follows:
where l(.) is the log likelihood of the considered probability model, k is the number of parameters and n is the size of the dataset used to fit the probabilistic model.
Though both criteria share similarities in their formulation, they provide different perspectives on model selection.
-
AIC-based model selection considers a model to be a probabilistic attempt to approach the “infinitely complex data-generating truth – but only approaching not representing” (Höge et al., 2018: Table 2). This means that AIC-based analysis aims at addressing which model will predict the best the next sample; i.e. it provides a measure of the predictive accuracy of the considered model (Aho et al., 2014: Table 2).
-
The purpose of BIC-based analysis considers each model to be a “probabilistic attempt to truly represent the infinitely complex data-generating truth” (Höge et al., 2018: Table 2), assuming that the true model exists and is among the candidate models. This perspective is different from the one of AIC and focuses on an approximation of the marginal probability of the data (here lEDP – log-transformed EDP) given the model (Aho et al., 2014: Table 2) and gives insights on which model generated the data; i.e. it measures goodness of fit.
The advantage of testing both criteria is to account for both perspectives on model selection, predictive accuracy and goodness of fit while enabling the penalisation of models that are too complex; the BIC generally penalises more strongly than the AIC. Since the constructed models use penalisation for the smoothness, we use the formulation provided by Wood et al. (2016: Sect. 5) to account for the smoothing parameter uncertainty.
However, selecting the most appropriate model may not be straightforward in all situations when two model candidates present close AIC and BIC values. For instance, Burnham and Anderson (2004) suggest an AIC difference (relative to the minimum value) of at least 10 to support the ranking between model candidates with confidence. If this criterion is not met, we propose complementing the analysis by the likelihood ratio test (LRT; e.g. Panagoulia et al., 2014: Sect. 2), which compares two hierarchically nested GEV formulations using , where l0 is the maximised log likelihood of the simpler model M0 and l1 is the one of the more complex model M1 (that presents q additional parameters compared to M0 and contains M0 as a particular case). The criterion L follows a χ2 distribution with q degrees of freedom, which allows deriving a p value of the test.
2.3 Non-stationary GEV distribution
The CDF of the GEV probability model holds as follows:
where “edp” is the variable of interest, and μ, σ and ξ are the GEV location, scale and shape parameters, respectively. Depending on the value of the shape parameter, the GEV distribution presents an asymptotic horizontal behaviour for ξ<0 (i.e. the asymptotically bounded distribution, which corresponds to the Weibull distribution), unbounded behaviour when ξ>0 (i.e. high probability of occurrence of great values can be reached, which corresponds to the Fréchet distribution) and intermediate behaviour in the case of ξ=0 (Gumbel distribution).
Figure 1a illustrates the behaviour of the GEV density distribution for μ=12.5, σ=0.25 and different ξ values: the higher ξ, the heavier the tail. Figure 1b and c further illustrate how changes in the other parameters (the location and the scale, respectively) affect the density distribution. The location primarily translates the whole density distribution, while the scale affects the tail and, to a lesser extent (for the considered case), the mode.
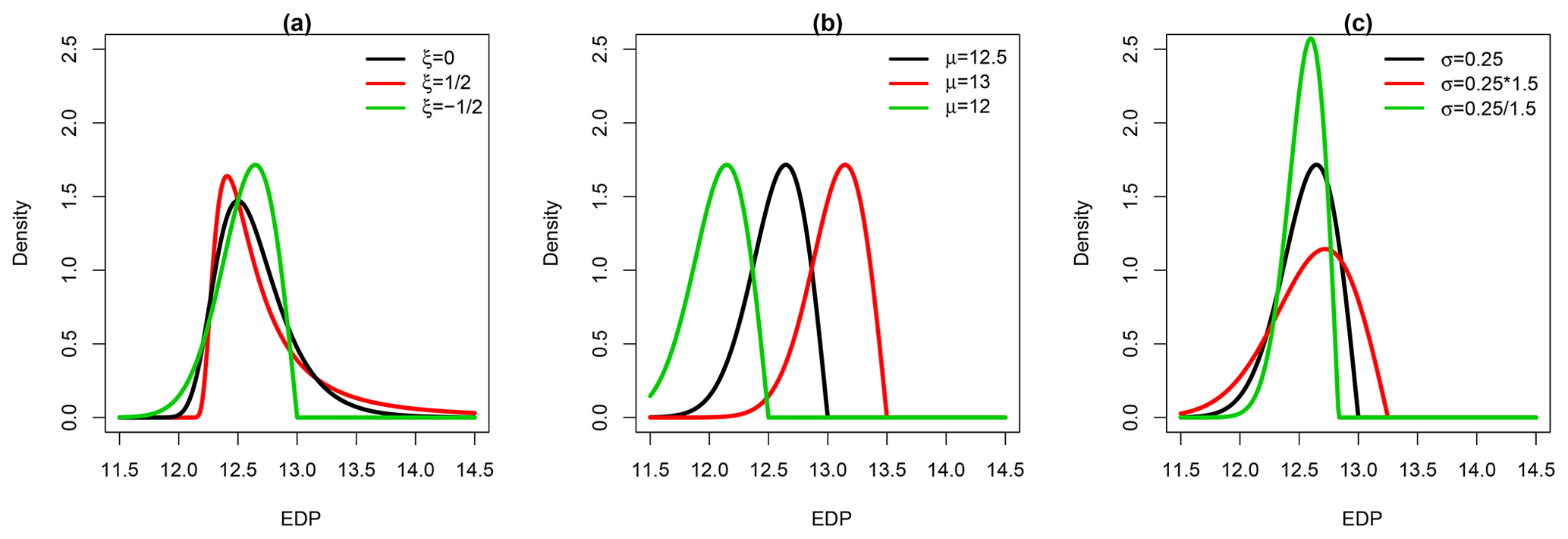
Figure 1Behaviour of the GEV density distributions depending on the changes in the parameter value: (a) ξ (with μ fixed at 12.5 and σ fixed at 0.25), (b) μ (with ξ fixed at 0.5 and σ fixed at 0.25) and (c) σ (with μ fixed at 12.5 and ξ fixed at 0.5).
The GEV distribution is assumed to be non-stationary in the sense that the GEV parameters θ=(μ, σ, ξ) vary as a function of x the vector of input variables, which include IM and the uncertain input variables U (as described in the Introduction). The fitting is performed within the general framework of the GAMLSS parameter (e.g. Rigby and Stasinopoulos, 2005). Since the scale parameter satisfies σ>0, we preferably work with its log transformation, which is denoted lσ. In the following, we assume that θ follows a semi-parametric additive formulation as follows:
where J is the number of functional terms that is generally inferior to the number of input variables (see Sect. 2.3). fj(.) corresponds to a univariate smooth non-linear model, described as follows:
with bb(.) being the thin-plate spline basis function (Wood, 2003) and βj the regression coefficients for the considered smooth function.
These functional terms (called partial effect) hold the information of each parameter's individual effect on the considered GEV parameter. The interest is to model the relationship between each GEV parameter and the input variables' flexibly. Alternative approaches would assume a priori functional relationships (like linear or of a polynomial form), which may not be valid.
The model estimation consists of evaluating the regression coefficients β (associated to the GEV parameters θ) by maximising the log likelihood l(.) of the GEV distribution. To avoid overfitting, the estimation is based on the penalised version of l(.) to control the roughness of the smooth functional terms (hence their complexity) as follows:
where λj controls the extent of the penalisation (i.e. the trade-off between goodness of fit and smoothness), and Sj is a matrix of known coefficients (such that the terms in the summation measure the roughness of the smooth functions). Computational methods and implementation details are detailed in Wood et al. (2016) and references therein. In particular, the penalisation parameter is selected through minimisation of the generalised cross-validation score.
2.4 Variable selection
The introduction of the penalisation coefficients in Eq. (8) has two effects: they can penalise how “wiggly” a given term is (i.e. it has a smoothing effect), and they can penalise the absolute size of the function (i.e. it has a shrinkage effect). The second effect is of high interest to screen out input variables of negligible influence. However, the penalty can only affect the components that have derivatives, i.e. the set of smooth non-linear functions called the “range space”. Completely smooth functions (including constant or linear functions), which belong to the “null space” are, however, not influenced by Eq. (8). For instance, for one-dimensional thin-plate regression splines, a linear term might be left in the model, even when the penalty value is very large (λ→∞); this means that the aforementioned procedure does not ensure that an input variable of negligible influence will completely be filtered out of the analysis (with corresponding regression coefficient shrunk to zero). The consequence is that Eq. (8) does not usually remove a smooth term from the model altogether (Marra and Wood, 2011). To overcome this problem, a double-penalty procedure was proposed by Marra and Wood (2011) based on the idea that the space of a spline basis can be decomposed into the sum of two components, one associated with the functions in the null space and the other with the range space. See Appendix A for further implementation details. This double-penalty procedure is adopted in the following.
To exemplify how the procedure works, we apply it to the following synthetic case. Consider a non-stationary GEV distribution whose parameters are related to two covariates x1 and x2 (see Eq. 9) as follows:
A total of 200 random samples are generated by drawing x1 and x2 from a uniform distribution on [0; 4] and [0; 2], respectively. Figure 2a provides the partial effects for the synthetic test case using the single-penalisation approach. The non-linear relationships are clearly identified for μ (Fig. 2a – i, ii) and for lσ (Fig. 2a – ii). However, the single-penalisation approach fails to identify properly the absence of influence of x2 on lσ and of both covariates on ξ (Fig. 2a – iv, v, vi), since the resulting partial effects still present a linear trend (though with small amplitude and large uncertainty bands). Figure 2b provides the partial effects using the double-penalisation approach. Clearly, this type of penalisation achieves a more satisfactory identification of the negligible influence of x2 on lσ and of both covariates on ξ (Fig. 2b – iv, v, vi) as well the non-linear partial effects for μ (Fig. 2b – i, ii) and for lσ (Fig. 2b – ii).

Figure 2Partial effect for the synthetic test case using the single-penalisation approach (a) and the double-penalisation approach (b).
This section provides details on the test case on which the proposed statistical methods (Sect. 2) for the derivation of FCs are demonstrated. The numerical model of the main steam line of a nuclear reactor is described in Sect. 3.1. A set of ground-motion records (Sect. 3.2) is applied to assess the seismic fragility of this essential component of a nuclear power plant.
3.1 Structural model
The 3-D model of a steam line and its supporting structure (i.e. the containment building; see schematic overview in Fig. 3a), previously assembled by Rahni et al. (2017) in the Cast3M finite-element software (Combescure et al., 1982), are introduced here as an application of the seismic fragility analysis of a complex engineered object. The containment building consists of a double-wall structure: the inner wall (reinforced pre-stressed concrete) and the outer wall (reinforced concrete) are modelled with multi-degree-of-freedom stick elements (see Fig. 3b). The steel steam line is modelled by means of beam elements, representing pipe segments and elbows, as well as several valves, supporting devices and stops at different elevations of the supporting structure.
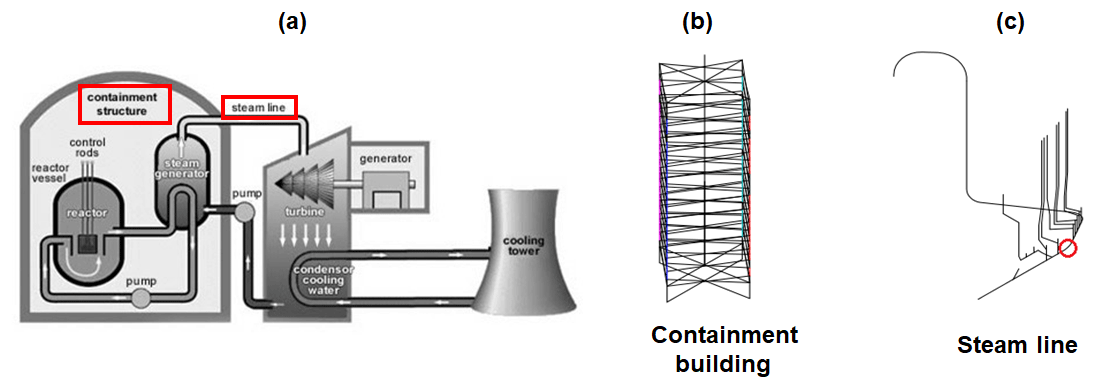
Figure 3(a) Schematic overview of a nuclear power plant (adapted from https://www.iaea.org/resources/nucleus-information-resources, last access: 2 December 2019). The red rectangles indicate the main components represented in the structural model. (b) Stick model of the containment building. (c) Steam line beam model, originally built by Rahni et al. (2017). The red circle indicates the location of the vertical stop.
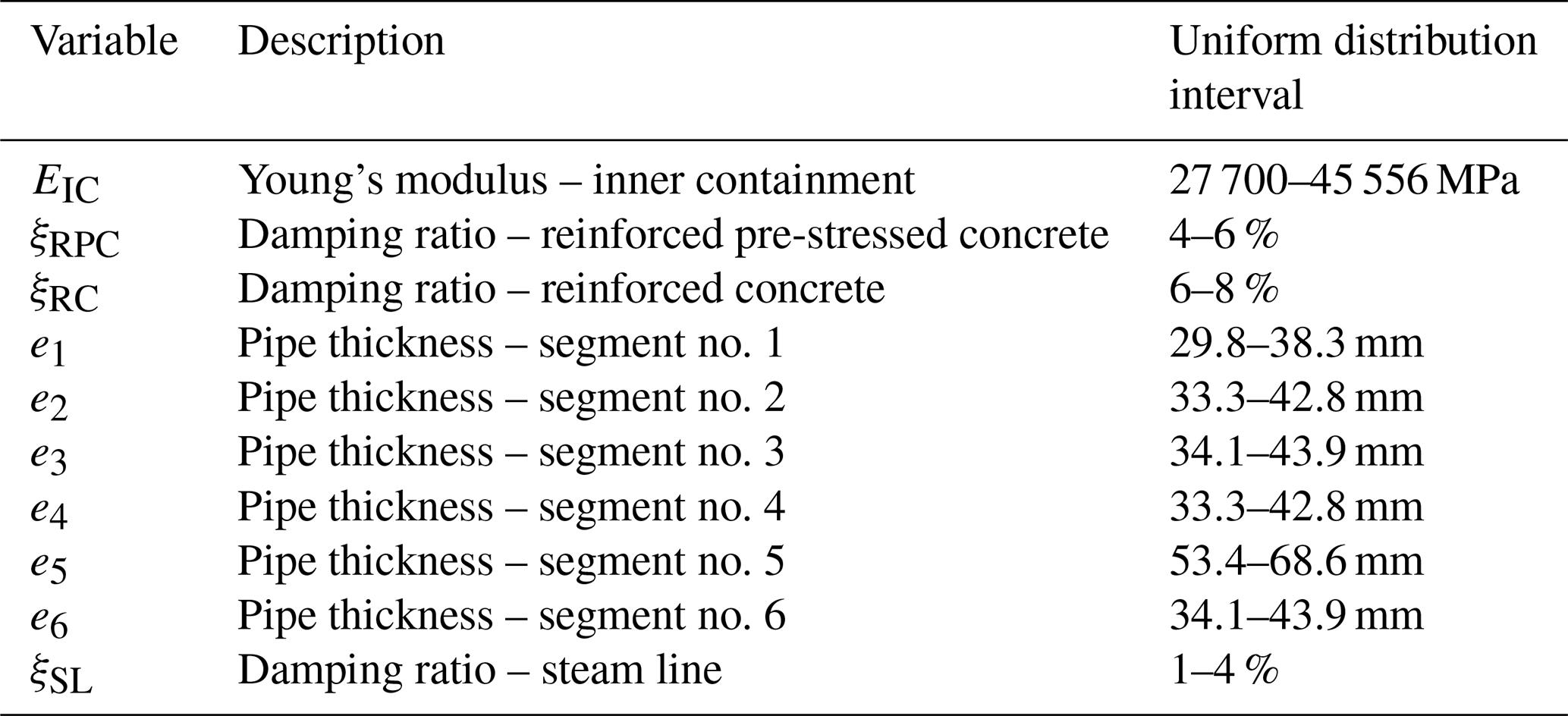
The objective of the fragility analysis is to check the integrity of the steam line: one of the failure criteria identified by Rahni et al. (2017) is the effort calculated at the location corresponding to a vertical stop along the steam line (Fig. 3c). Failure is assumed when the maximum transient effort exceeds the stop's design effort, i.e. EDP ≥ 775 kN (i.e. 13.56 on log scale). The model also accounts for epistemic uncertainties due to the identification of some mechanical and geometrical parameters, namely Young's modulus of the inner containment, the damping ratio of the structural walls and of the steam line, and the thickness of the steam line along various segments of the assembly. The variation range of the 10 selected parameters, constituting the vector U of uncertain factors (see Eq. 3), is detailed in Table 1. A uniform distribution is assumed for these parameters following the values provided by Rahni et al. (2017).
Table 1Input parameters of the numerical model, according to Rahni et al. (2017).
3.2 Dynamic structural analyses
A series of non-linear time history analyses are performed on the 3-D model by applying ground-motion records (i.e. acceleration time histories) at the base of the containment building in the form of a three-component loading. In the Cast3M software, the response of the building is first computed, and the resulting displacement time history along the structure is then applied to the steam line model in order to record the effort demands during the seismic loading. The non-linear dynamic analyses are performed on a high-performance computing cluster, enabling the launch of the multiple runs in parallel (e.g. a ground motion of a duration of 20 s is processed in around 3 or 4 h). Here, the main limit with respect to the number of ground-motion records is not necessarily related to the computation time cost but more related to the availability of natural ground motions that are able to fit the conditional spectra at the desired return periods (as detailed below). Another option would be the generation of synthetic ground motions, using for instance the stochastic simulation method by Boore (2003) or the non-stationary stochastic procedure by Pousse et al. (2006). It has been decided, however, to use only natural records in the present application in order to accurately represent the inherent variability in other ground-motion parameters such as duration.
Natural ground-motion records are selected and scaled using the conditional spectrum method described by Lin et al. (2013). Thanks to the consideration of reference earthquake scenarios at various return periods, the scaling of a set of natural records is carried out to some extent while preserving the consistency of the associated response spectra. The steps of this procedure hold as follows.
-
Choice of a conditioning period. The spectral acceleration (SA) at s (fundamental mode of the structure) is selected as the ground-motion parameter upon which the records are conditioned and scaled.
-
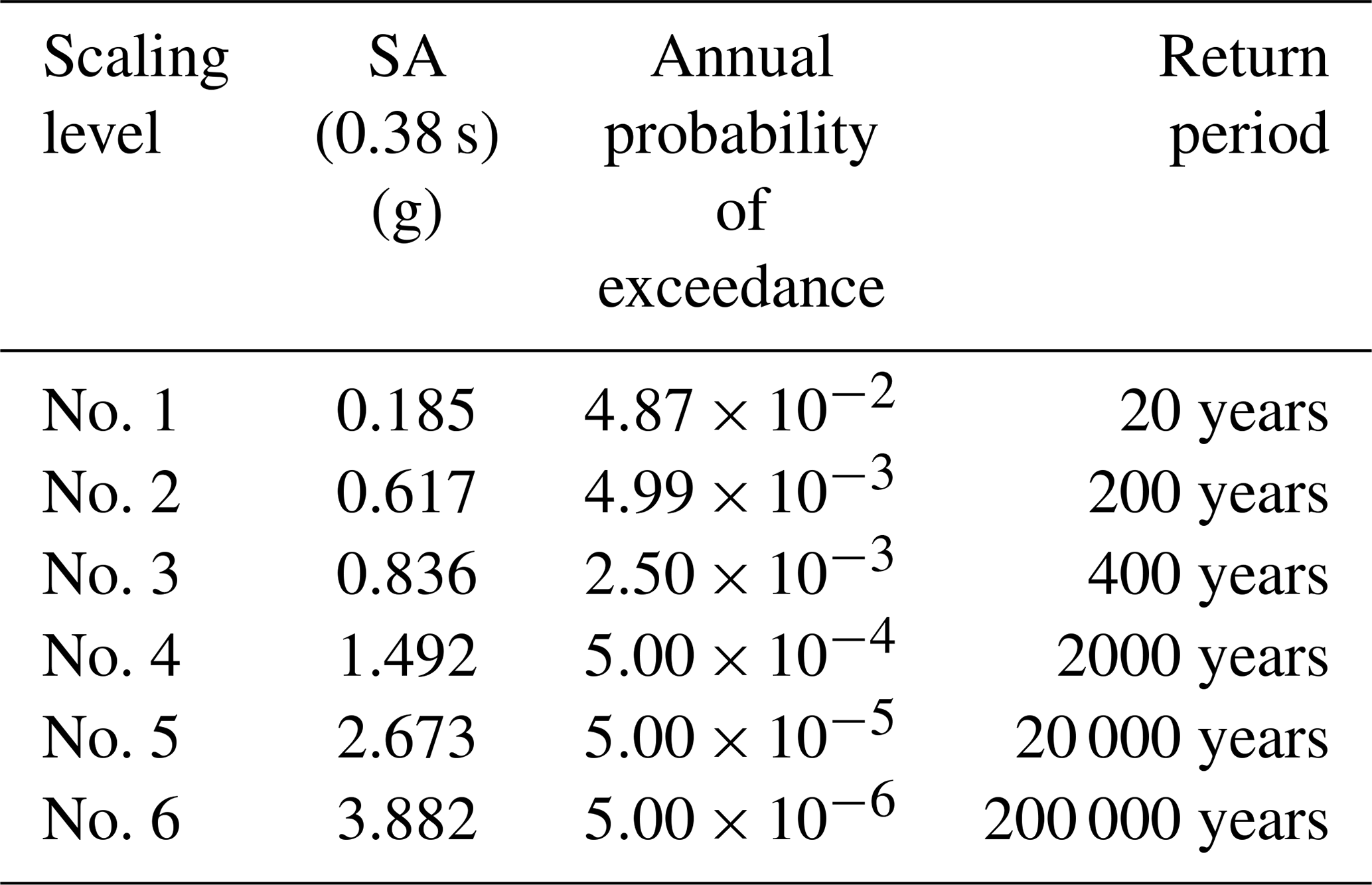
Definition of seismic hazard levels. Six hazard levels are arbitrarily defined, and the associated annual probabilities of exceedance are quantified with the OpenQuake engine1, using the SHARE seismic source catalogue (Woessner et al., 2013), for an arbitrary site in southern Europe. The ground-motion prediction equation (GMPE) from Boore et al. (2014) is used to generate the ground motions, assuming soil conditions corresponding to m s−1 at the considered site. Data associated with the mean hazard curve are summarised in Table 2.
-
Disaggregation of the seismic sources and identification of the reference earthquakes. The OpenQuake engine is used to perform a hazard disaggregation for each scaling level. A reference earthquake scenario may then be characterised through the variables [Mw; Rjb; ε] (i.e. magnitude, Joyner–Boore distance, error term of the ground-motion prediction equation), which are averaged from the disaggregation results (Bazzurro and Cornell, 1999). This disaggregation leads to the definition of a mean reference earthquake (MRE) for each scaling level.
-
Construction of the conditional spectra. For each scaling level, the conditional mean spectrum is built by applying the GMPE to the identified MRE. For each period Ti, it is defined as follows (Lin et al., 2013):
where μln SA(Mw, Rjb, Ti) is the mean output of the GMPE for the MRE considered, is the cross-correlation coefficient between SA(Ti) and SA(T*) (Baker and Jayaram, 2008), ε(T*) is the error term value at the target period s, and σln SA(Mw, Ti) is the standard deviation of the logarithm of SA(Ti), as provided by the GMPE. The associated standard deviation is also evaluated, thanks to the following equation:
The conditional mean spectrum and its associated standard deviation are finally assembled in order to construct the conditional spectrum at each scaling level. The conditional mean spectra may be compared with the uniform hazard spectra (UHS) that are estimated from the hazard curves at various periods. As stated in Lin et al. (2013), the SA value at the conditioning period corresponds to the UHS, which acts as an upper-bound envelope for the conditional mean spectrum.
-
Selection and scaling of the ground-motion records. Ground-motion records that are compatible with the target conditional response spectrum are selected, using the algorithm by Jayaram et al. (2011): the distribution of the selected ground-motion spectra, once scaled with respect to the conditioning period, has to fit the median and standard deviation of the conditional spectrum that is built from Eqs. (10) and (11). The final selection from the PEER database (PEER, 2013) consists of 30 records for each of the six scaling levels (i.e. 180 ground-motion records in total).
Table 2Estimation of the seismic hazard distribution for the application site.
Two distinct cases are considered for the derivation of FCs, depending on whether parametric uncertainties are included in the statistical model or not.
-
Case no. 1 (without epistemic uncertainties). A first series of numerical simulations are performed by keeping the mechanical and geometrical parameters fixed at their best estimate values, i.e. the midpoint of the distribution intervals detailed in Table 1. The 180 ground-motion records are applied to the deterministic structural model, resulting in a database of 180 (IM, EDP) pairs, with PGA chosen as the IM.
-
Case no. 2 (with epistemic uncertainties). A second series of numerical simulations are performed by accounting for parametric uncertainties. This is achieved by randomly varying the values of the mechanical and geometrical input parameters of the numerical model (Table 1) using the Latin hypercube sampling technique (McKay et al., 1979). A total number of 360 numerical simulations are performed (using 180 ground-motion records).
Therefore, multiple ground motions are scaled at the same IM value, and statistics on the exceedance rate of a given EDP value may be extracted at each IM step, in a similar way to what is carried out in multiple-stripe analyses or incremental dynamic analyses (Baker, 2015; Vamvatsikos and Cornell, 2002) for the derivation of FC. In the present study, the conditional spectrum method leads to the selection and scaling of ground motions with respect to SA (0.38 s), which corresponds to the fundamental modal of the structure. For illustration purposes, Fig. 4 displays the damage probabilities at the six selected return periods, which may be associated to unique values of SA (0.38 s).
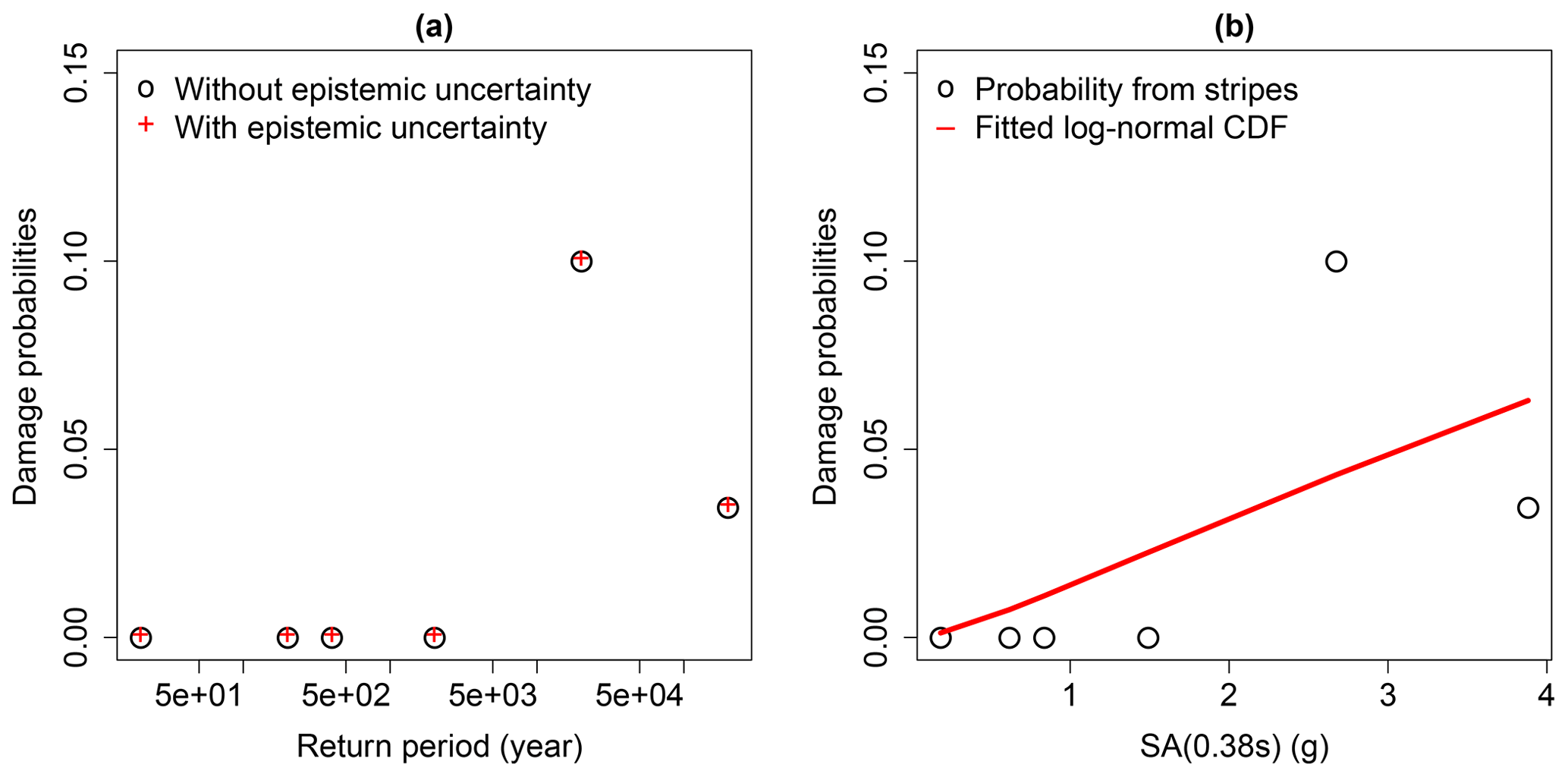
Figure 4(a) Damage probabilities directly extracted from the six scaling levels (or return periods). (b) Damage probabilities with respect to the six SA(T*) levels, and fitted lognormal cumulative distribution function.
From Fig. 4, two main observations can be made: (i) the multiple-stripe analysis does not emphasise any difference between the models with and without parametric uncertainty, and (ii) the FC directly derived from the six probabilities does not provide a satisfying fit. However, the fragility analysis is here focused on the pipeline component (located along the structure), which appears to be more susceptible to PGA: therefore, PGA is chosen as IM in the present fragility analysis.
Figure 5 provides the evolution of lEDP versus lPGA (log-transformed PGA) for both cases. We can note that only a few simulation runs (five for Case no. 1 and eight for Case no. 2) lead to the exceedance of the acceptable demand threshold. As shown in Fig. 4, there is a variability around the six scaling levels: for this reason, it is not feasible to represent probabilities at six levels of PGA. In this case, conventional approaches for FC derivation are the “regression on the IM-EDP cloud” (i.e. least-squares regression, as demonstrated by Cornell et al., 2002) or the use of generalised linear model regression or maximum likelihood estimation (Shinozuka et al., 2000).
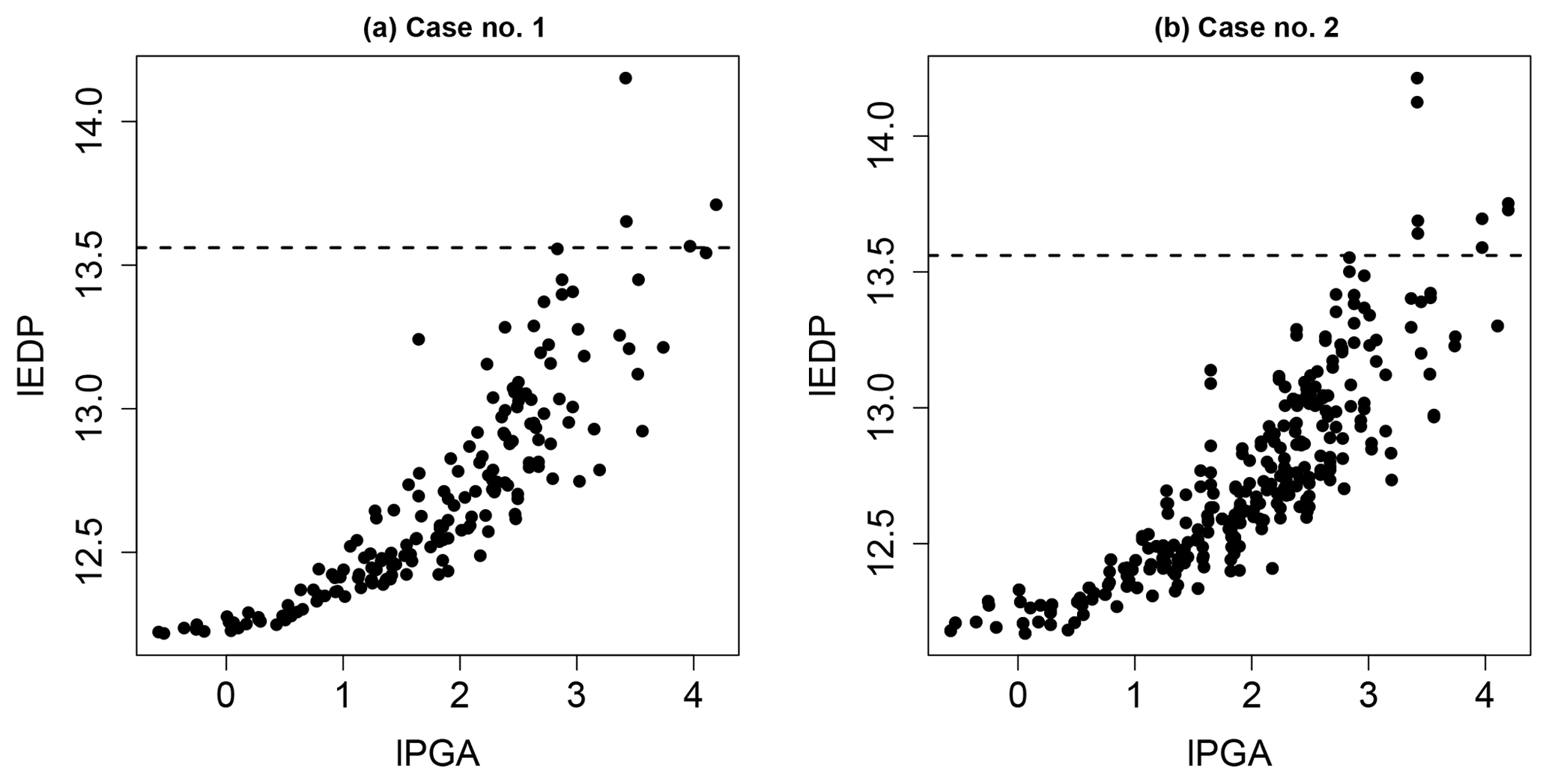
Figure 5Evolution of lEDP (log-transformed EDP) as a function of lPGA (log-transformed PGA) for Case no. 1 (a) without parametric uncertainty and for Case no. 2 (b) with parametric uncertainty. The horizontal dashed line indicates the acceptable demand threshold.
In this section, we apply the proposed procedure to both cases described in Sect. 3.2. Section 4.1 and 4.2 describes the application for deriving the FCs without (Case no. 1) and with epistemic uncertainty (Case no. 2), respectively. For each case, we first select the most appropriate probabilistic model, then analyse the partial effects and, finally, compare the derived FC with the one based on the commonly used assumption of normality. The analysis is here focused on the lPGA to derive the FC.
4.1 Case no. 1: derivation of seismic FC without epistemic uncertainties
4.1.1 Model selection and checking
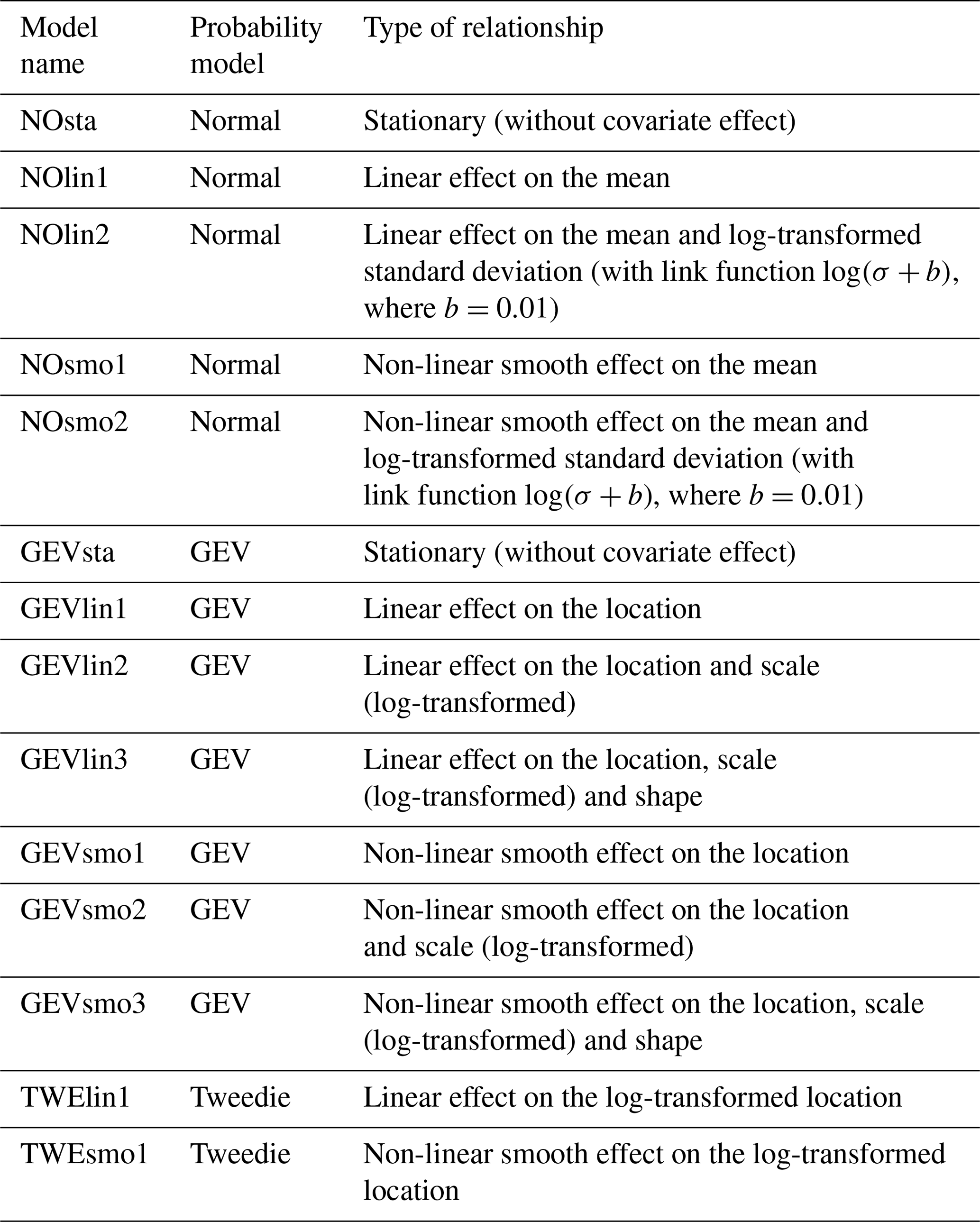
A series of different probabilistic models (Table 3) were fitted to the database of (IM, EDP) points described in Sect. 3.2 (Fig. 5a). Three different probabilistic models (normal, Tweedie, GEV) and two types of effects on the probabilistic model's parameters were tested (linear or non-linear). Note that the Tweedie distribution corresponds to a family of exponential distributions which takes as special cases the Poisson distribution and the gamma distribution (Tweedie, 1984).
The analysis of the AIC and BIC differences (relative to the minimum value; Fig. 6) here suggests that both models, GEVsmo3 and GEVsmo2, are valid (as indicated by the AIC and BIC differences close to zero). The differences between the criteria value are less than 10, and to help the ranking, we complement the analysis by evaluating the LRT p value, which reaches ∼18 %, hence suggesting that GEVsmo2 should be preferred (for illustration, the LRT p value for a stationary GEV model and the non-stationary GEVsmot2 model is here far less than 1 %). In addition, we also analyse the regression coefficients of GEVsmo3, which shows that the penalisation procedure imposes all coefficients of the shape parameters to be zero, which indicates that lPGA only acts on the location and scale parameters.
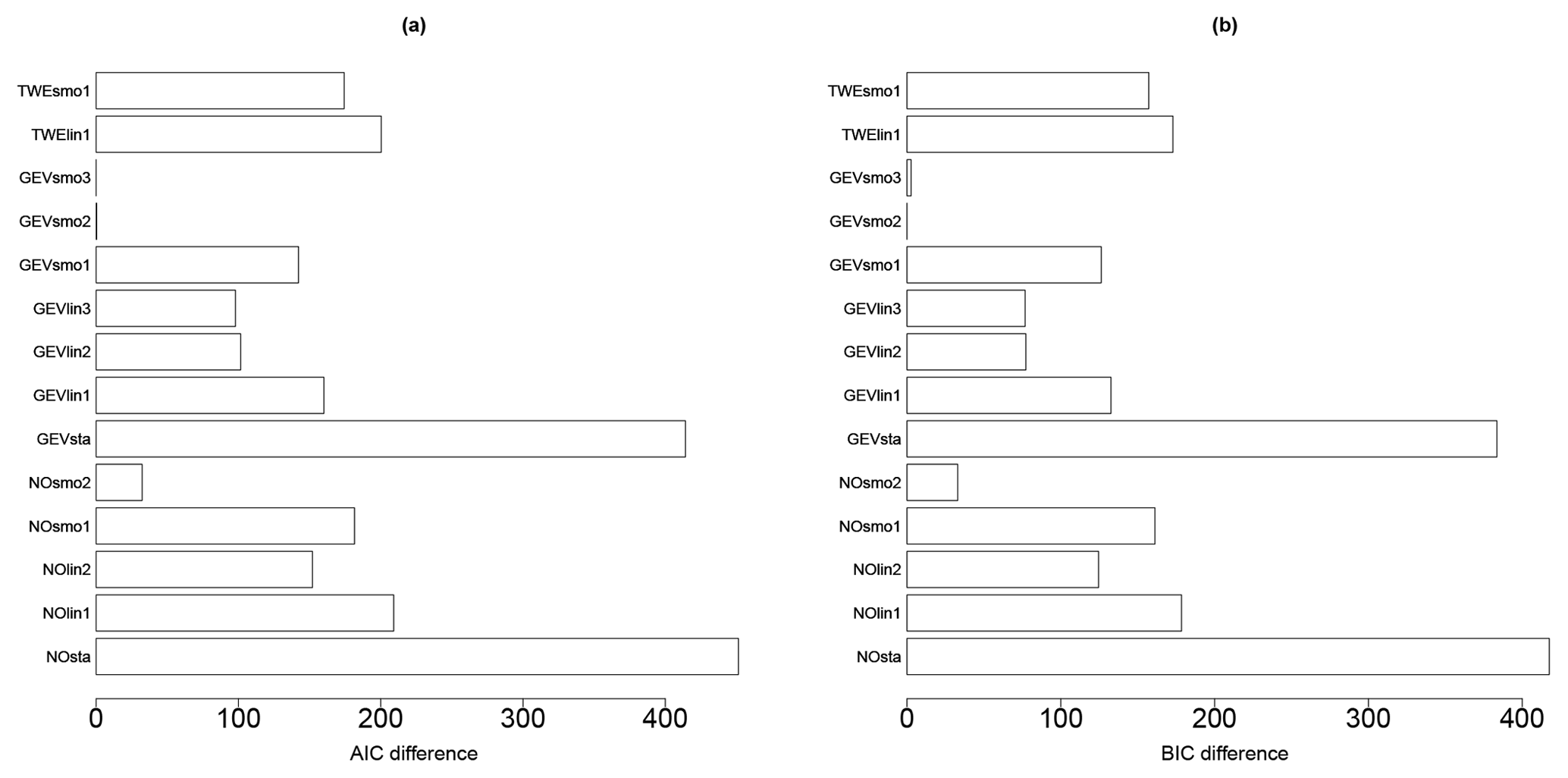
Figure 6Model selection criteria (AIC – a – and BIC – b – differences relative to the minimum value) for the different models described in Table 3 considering the derivation of a FC without epistemic uncertainty.
Table 3Description of the probabilistic model used to derive the FCs.
These results provide support in favour of GEVsmo2, i.e. a GEV distribution with a non-linear smooth term for the location and scale parameters only. The estimated shape parameter reaches here a constant value of 0.07 (±0.05), hence indicating a behaviour close to the Gumbel domain. This illustrates the flexibility of the proposed approach based on the GEV, which encompasses the Gumbel distribution as a particular case. We also note that the analysis of the AIC and BIC values would have favoured the selection of NOsmo2 if the GEV model had not been taken into account, i.e. a heteroscedastic log-normal FC.
The examination of the diagnostic plots (Fig. 7a) of the model deviance residuals (conditional on the fitted model coefficients and scale parameter) shows a clear improvement of the fitting, in particular for large theoretical quantiles above 1.5 (the dots better aligned along the first bisector in Fig. 7b). The Gumbel Q–Q and P–P plots (Fig. 7c and d) also indicate a satisfactory fitting of the GEV model.
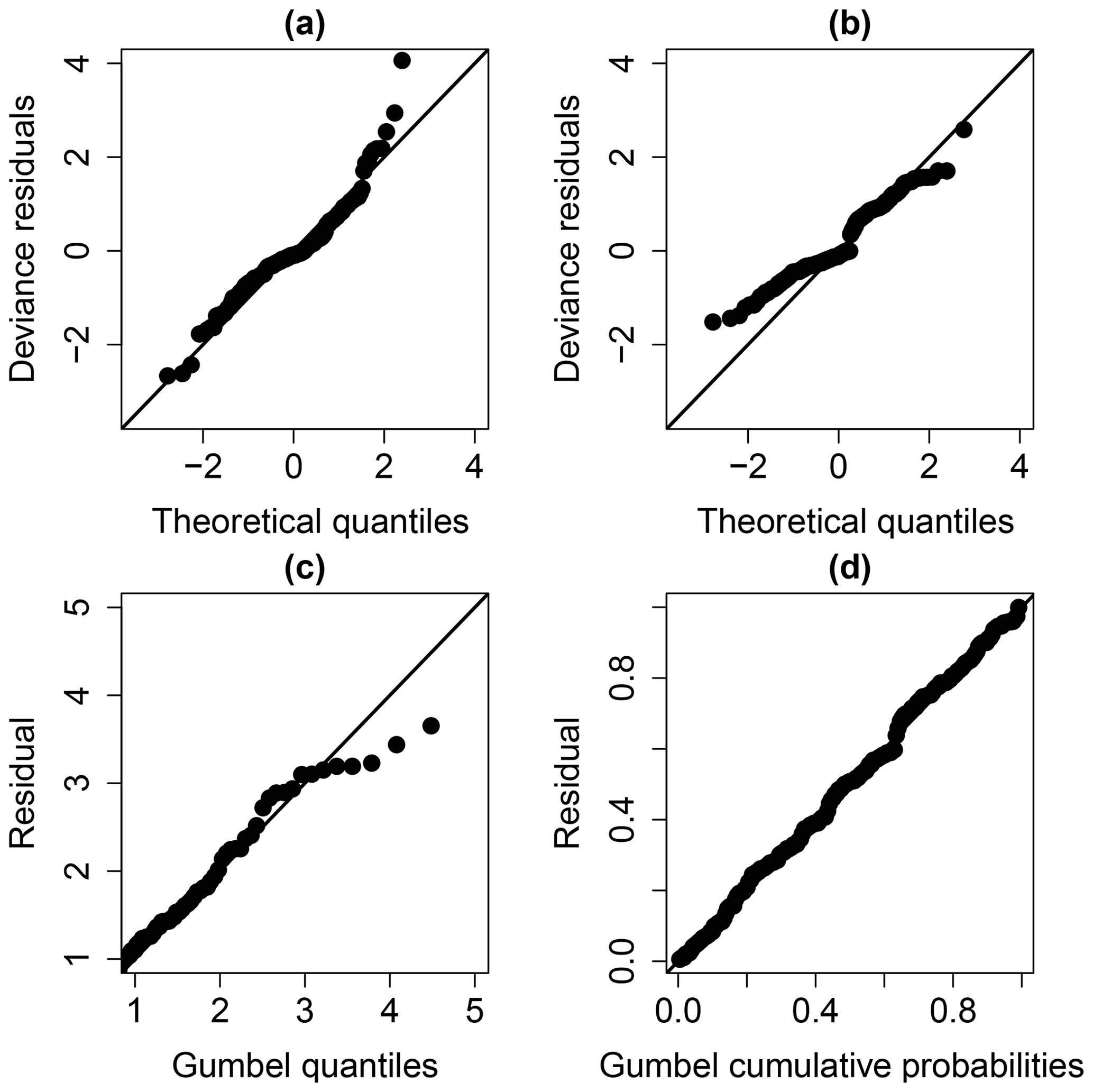
Figure 7Diagnostic plots to check the validity of the considered model: (a) Q–Q plot for the deviance residuals for the NOsmo2 model, (b) Q–Q plot for the deviance residuals for the GEVsmo2 model without parametric uncertainty, (c) Q–Q plot on Gumbel scale and (d) P–P plot on Gumbel scale.
4.1.2 Partial effects
Figure 8a and b provides the evolution of the partial effects (as formally described in Sect. 2.3: Eqs. 6 and 7) with respect to the location and to the log-transformed scale parameter, respectively. We note that the assumption of the relationship between EDP and lPGA is non-linear (contrary to the widely used assumption). An increase in lPGA both induces an increase in μ and of lσ, hence resulting in a shift of the density (as illustrated in Fig. 1b), and an impact on the tail (as illustrated in Fig. 1c). We note that the fitting uncertainty (indicated by the ± 2 standard errors above and below the best estimate) remains small, and the aforementioned conclusions can be considered with confidence.
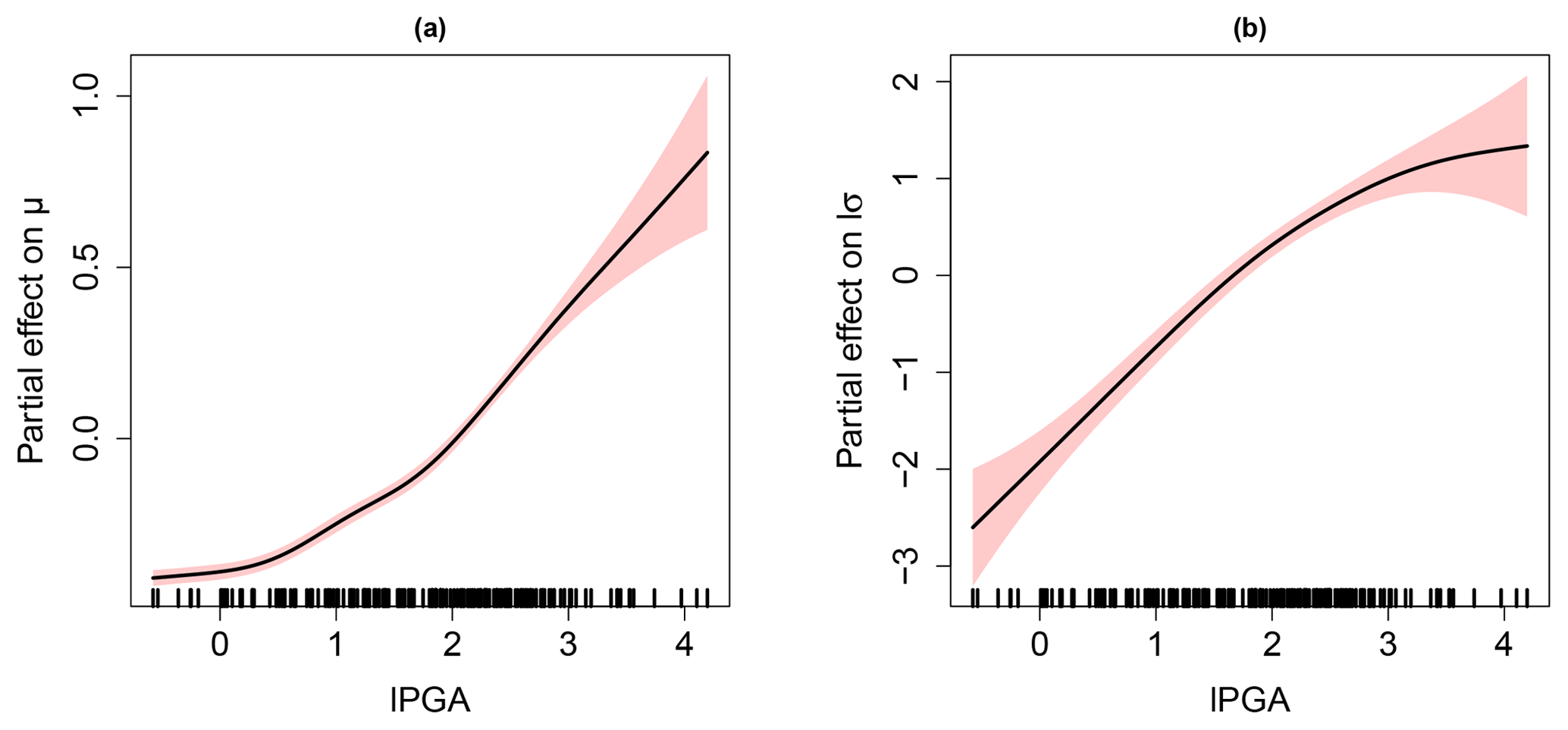
Figure 8Partial effect of (a) PGA on the GEV location parameter and (b) PGA on the log-transformed GEV scale parameter. The red-coloured bands are defined by 2 SE (standard errors) above and below the estimate.
4.1.3 FC derivation
Using the Monte Carlo-based procedure described in Sect. 2.1, we evaluate the failure probability Pf (Eq. 1) to derive the corresponding GEV-based FC (Fig. 9a) with accounts for fitting uncertainties. The resulting FC is compared to the one based on the normal assumption (Fig. 9b). This shows that Pf would have been underestimated for moderate-to-large PGA from 10 to ∼25 m2 s−1 if the selection of the probability model had not been applied (i.e. if the widespread assumption of normality had been used); for instance at PGA = 20 m2 s−1, Pf is underestimated by ∼5 %. This is particularly noticeable for the range of PGA from 10 to 15 m2 s−1, where the GEV-based FC clearly indicates a non-zero probability value, whereas the Gaussian model indicates negligible probability values below 1 %. For very high PGA, both FC models approximately provide almost the same Pf value. These conclusions should, however, be analysed with respect to the fitting uncertainty, which has here a clear impact; for instance at PGA = 20 m2 s−1, the 90 % confidence interval has a width of 10 % (Fig. 9a), i.e. of the same order of magnitude than a PGA variation from 10 to 20 m2 s−1. We note also that the fitting uncertainty reaches the same magnitude between both models. This suggests that additional numerical simulation results are necessary to decrease this uncertainty source for both models.
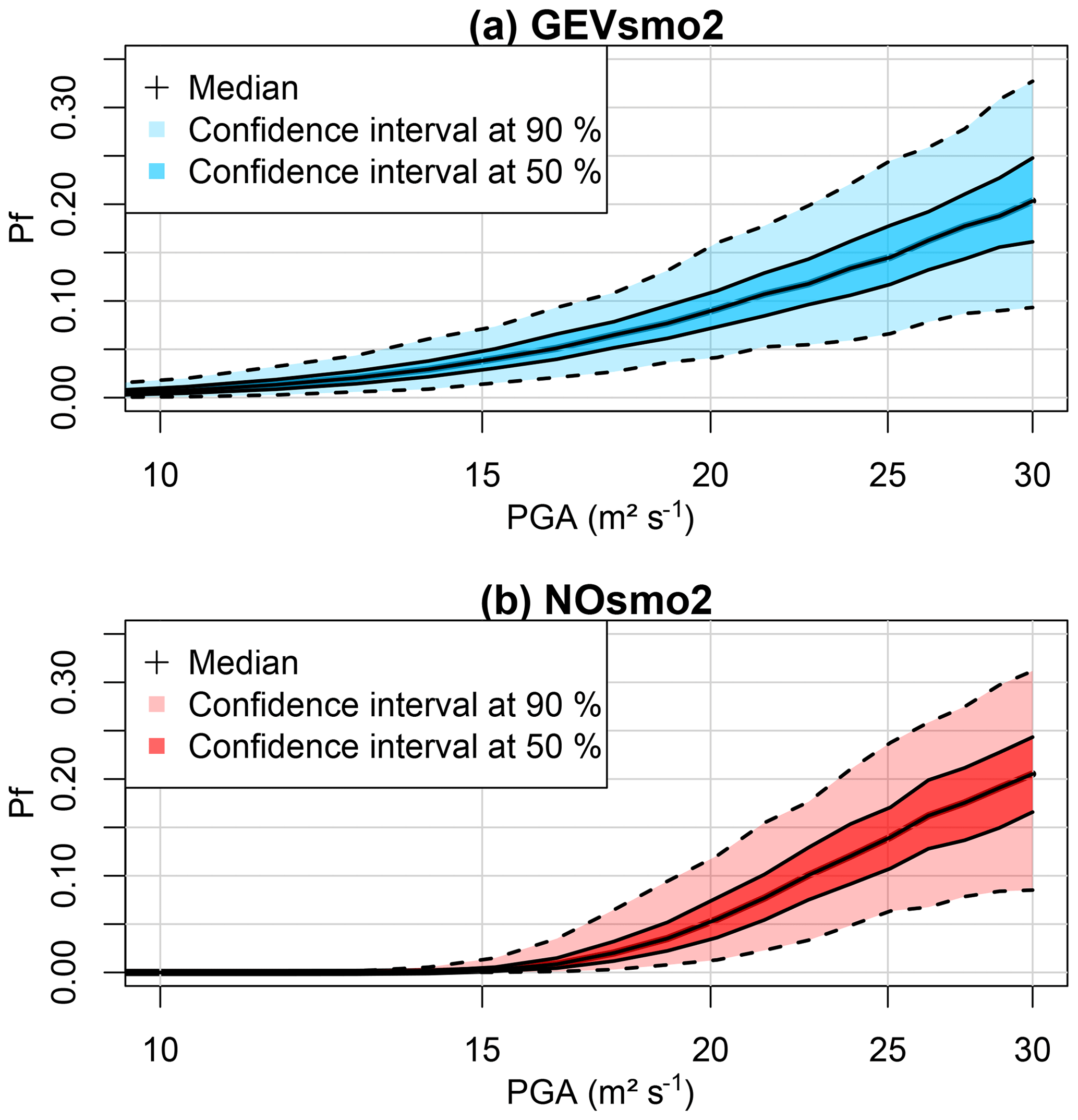
Figure 9Fragility curve (relating the failure probability Pf to PGA) based on (a) the non-stationary model GEVsmo2 and (b) the Gaussian NOsmo2 model. The coloured bands reflect the uncertainty in the fitting.
4.2 Case no. 2: derivation of seismic FC with epistemic uncertainties
4.2.1 Model selection and checking
In this case, the FCs were derived by accounting not only for lPGA but also for 10 additional uncertain parameters (Table 1).
The AIC and BIC differences (relative to the minimum value; Fig. 10) for the different probabilistic models (described in Table 2) show that GEVsmo2 model should preferably be selected. Contrary to Case no. 1, the AIC and BIC differences are large enough to rank with confidence GEVsmo2 as the most appropriate model. This indicates that the location and scale parameters are non-linear smooth functions of IM and of the uncertain parameters. The estimated shape parameter reaches here a constant value of −0.24 (±0.06), hence indicating a Weibull tail behaviour. Similarly to the analysis without parametric uncertainties (Sect. 4.1), we note that the AIC and BIC values would have favoured the selection of NOsmo2 if the GEV model had not been taken into account.
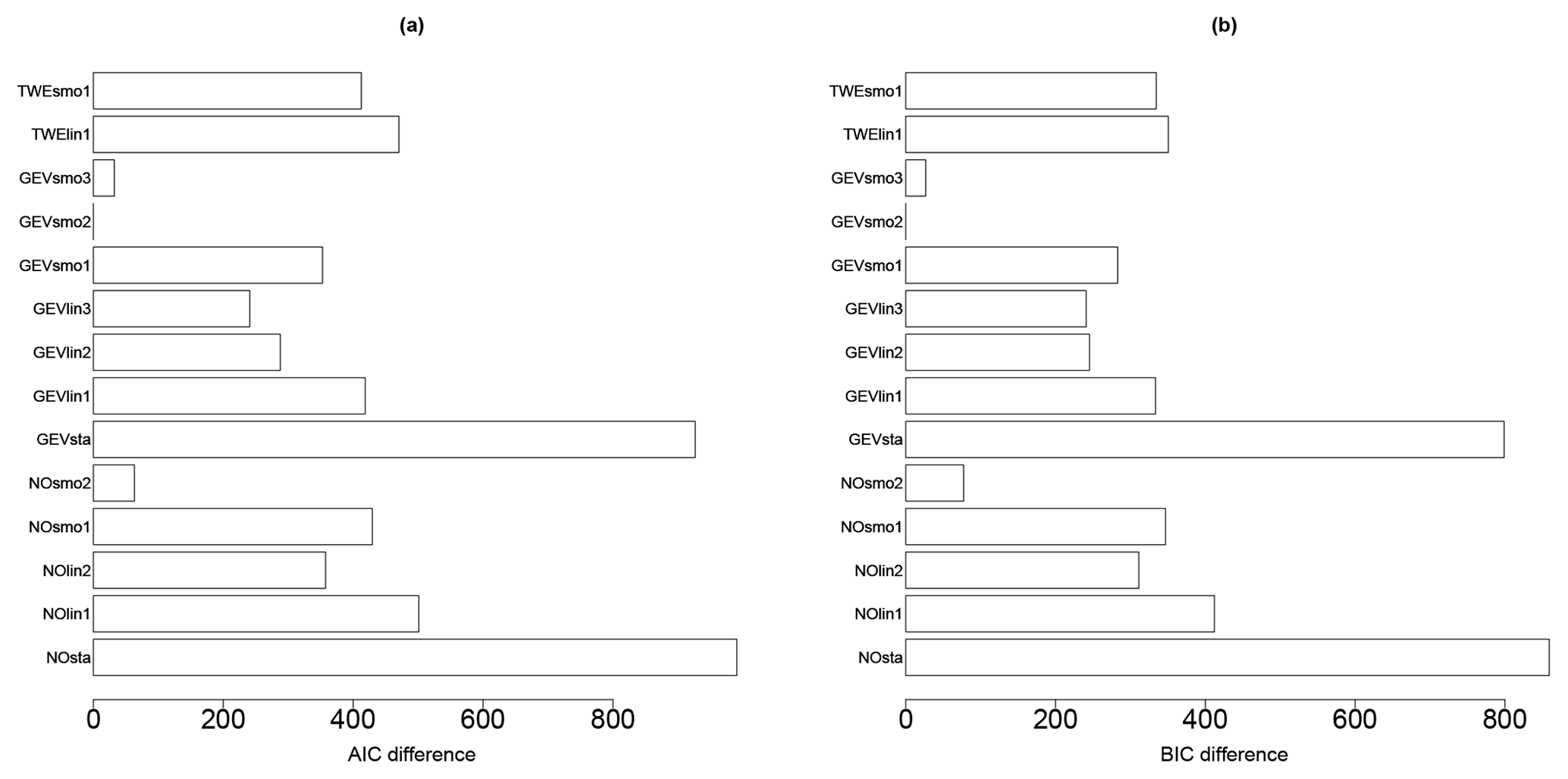
Figure 10Model selection criteria (AIC – a – and BIC – b – differences relative to the minimum value) for the different models described in Table 3 considering the derivation of a FC with epistemic uncertainty.
The examination of the Q–Q plots (Fig. 11) of the model deviance residuals (conditional on the fitted model coefficients and scale parameter) shows an improvement of the fitting, in particular for large theoretical quantiles above 1.0 (the dots better aligned along the first bisector in Fig. 11b). The Gumbel Q–Q and P–P plot (Fig. 11c and d) also indicate a very satisfactory fitting of the GEV model.
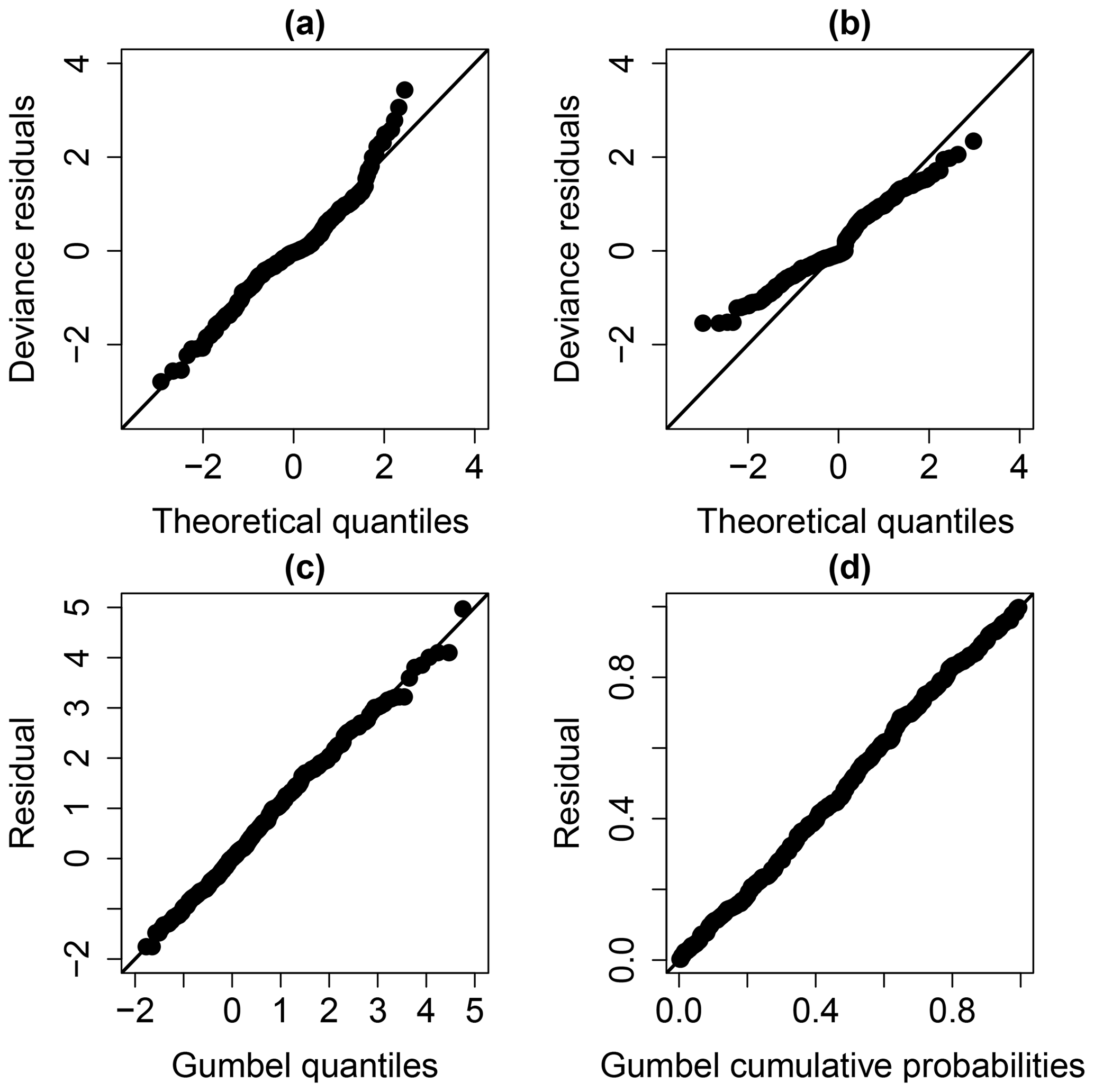
Figure 11Diagnostic plots to check the validity of the considered model: (a) Q–Q plot for the deviance residuals for the NOsmo2 model, (b) Q–Q plot for the deviance residuals for the GEVsmo2 model with epistemic uncertainty, (c) Q–Q plot on Gumbel scale and (d) P–P plot on Gumbel scale.
4.2.2 Partial effects
Figure 12 provides the evolution of the partial effects with respect to the location parameter. Several observations can be made.
-
Figure 12a shows quasi-similar partial effect for lPGA in Case no. 1 (Fig. 8a).
-
Three out of the ten uncertain parameters were filtered out by the procedure of Sect. 2.4, namely two mechanical parameters (the damping ratio of reinforced pre-stressed concrete ξRPC and the damping ratio of the steam line ξSL) and one geometrical parameter (the pipe thickness of segment no. 2). As an illustration, Fig. 12e depicts the partial effect of a parameter, which was identified as of negligible influence: here, the partial effect of e2 is shrunk to zero.
-
Three thickness parameters (e1, e4, e5) present an increasing linear effect on μ (Fig. 12d, g and h).
-
Two parameters (Young's modulus of the inner containment EIC and the thickness e3) present a decreasing linear effect on μ (Fig. 12b and f).
-
The damping ratio of the reinforced concrete ξRC presents a non-linear effect, with a minimum value at around 0.0725 (Fig. 12c).
-
The thickness e6 presents a non-linear effect, with a maximum value at around 0.04 (Fig. 12i).
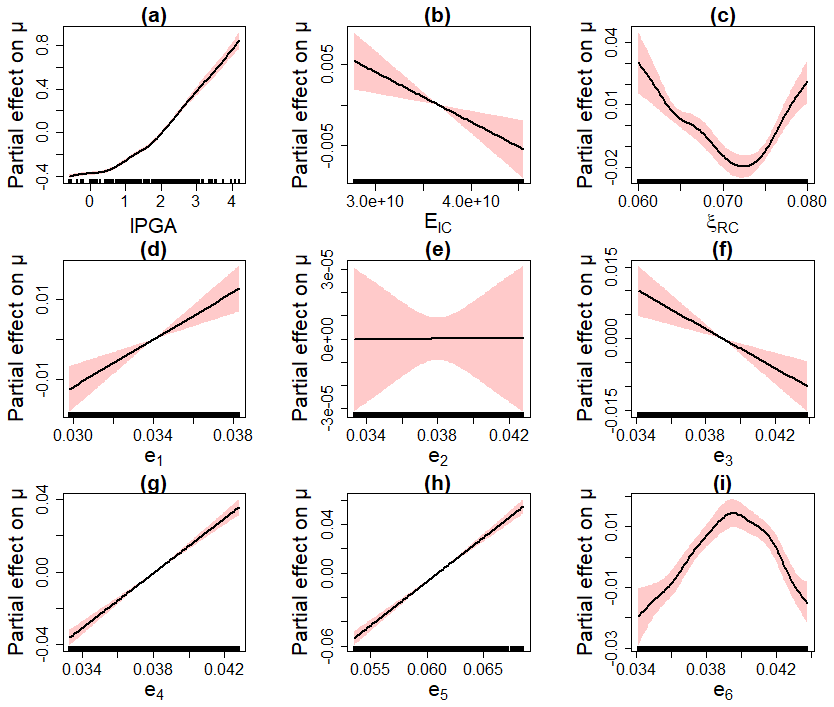
Figure 12Partial effect on the GEV location parameter. The red-coloured bands are defined by 2 SE (standard errors) above and below the estimate.
Figure 13 provides the evolution of the partial effects with respect to the (log-transformed) scale parameter. We show here that a larger number of input parameters were filtered out by the selection procedure; i.e. only the thickness e5 is selected as well as the damping ratios of the concrete structures ξRPC and ξRC (related to the containment building). The partial effects are all non-linear, but with larger uncertainty than for the location parameter (compare the widths of the red-coloured uncertain bands in Figs. 12 and 13). In particular, the strong non-linear influence of ξRPC and ξRC may be due to the simplified coupling assumption between structural dynamic response and anchored steam line (i.e. the displacement time history at various points of the building is directly used as input for the response of the steam line). Identifying this problem is possible thanks to the analysis of the partial effects, though it should be recognised that this behaviour remains difficult to interpret and further investigations are here necessary. We also note that the partial effect for lPGA is quasi-similar to Fig. 8b in Case no. 1.
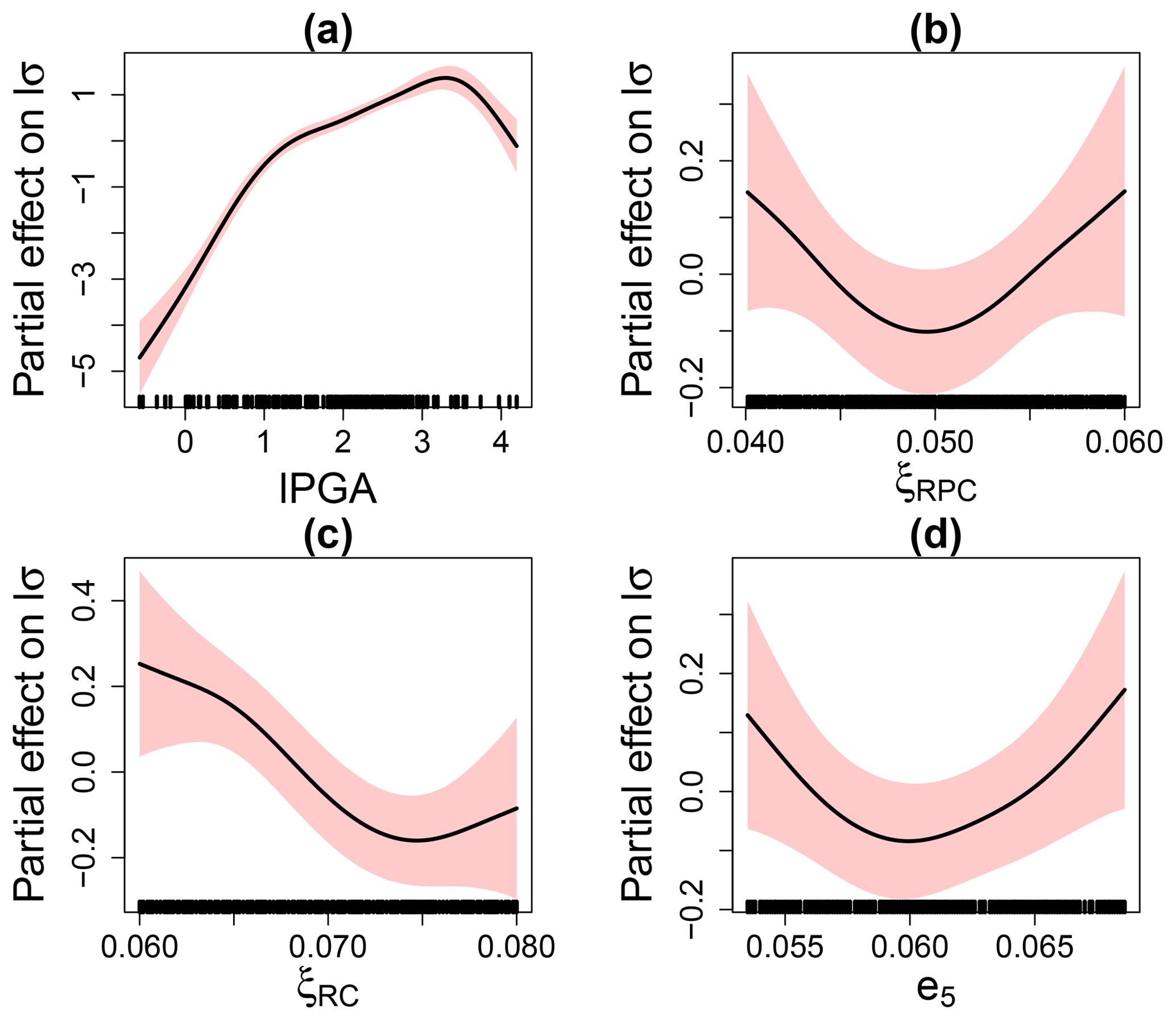
Figure 13Partial effect on the log-transformed GEV scale parameter. The red-coloured bands are defined by 2 SE (standard errors) above and below the estimate.
Table 4 summarises the different types of influence identified in Figs. 12 and 13, i.e. linear, non-linear or absence of influence as well as the type of monotony when applicable.
Table 4Influence of the geometrical and mechanical parameters on the GEV parameters, μ and lσ, of the GEVsmo2 model.

4.2.3 FC derivation
Based on the results of Figs. 12 and 13, the FC is derived by accounting for the epistemic uncertainties by following the Monte Carlo procedure (step 5 described in Sect. 2.1) by including (or not) fitting uncertainty (Fig. 14a and b, respectively). We show that the GEV-based FC is less steep than the one for Case no. 1 (Fig. 9): this is mainly related to the value of the shape parameter (close to Gumbel regime for Case no. 1 without epistemic uncertainty and to Weibull regime for Case no. 2 with epistemic uncertainty). Figure 14a also outlines that the uncertainty related to the mechanical and geometrical parameters has a non-negligible influence, as shown by the width of the uncertainty bands: for PGA = 30 m2 s−1, the 90 % confidence interval has a width of ∼20 %. In addition, the inclusion of the fitting uncertainty (Fig. 14b) increases the width of the confidence interval, but it appears to mainly impact the 90 % confidence interval (compare the dark- and the light-coloured envelope in Fig. 14); for instance, compared to Fig. 14a, this uncertainty implies a +5 % (respectively −5 %) shift of the upper bound (respectively lower bound) of the 90 % confidence interval at PGA = 30 m2 s−1.
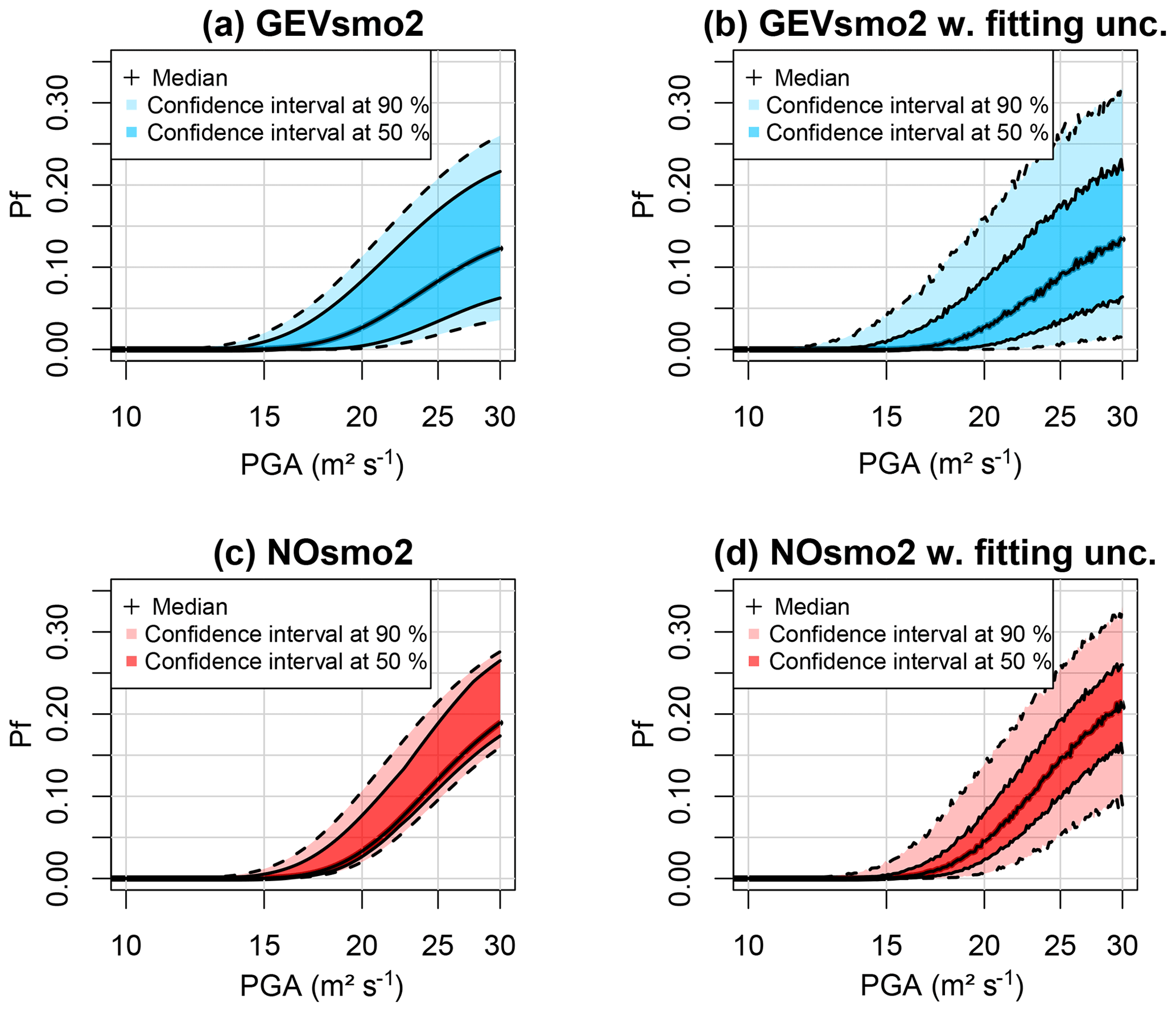
Figure 14Fragility curve (relating the failure probability Pf to PGA) considering epistemic uncertainties only (a, c) and fitting uncertainty as well (b, d). (a, b) GEV-based FC; (c, d) FC based on the normal assumption. The coloured bands are defined based on the pointwise confidence intervals derived from the set of FCs (see text for details).
Compared to the widely used assumption of normality, Fig. 14c and d show that the failure probability reached with this model is larger than with the GEV-based FC; at PGA = 30 m2 s−1, the difference reaches ∼5 %. In practice, this means that a design based on the Gaussian model would have here been too conservative. Regarding the impact of the different sources of uncertainty, the epistemic uncertainty appears to influence the Gaussian model less than the GEV one. The impact of the fitting uncertainty is, however, quasi-equivalent for both models.
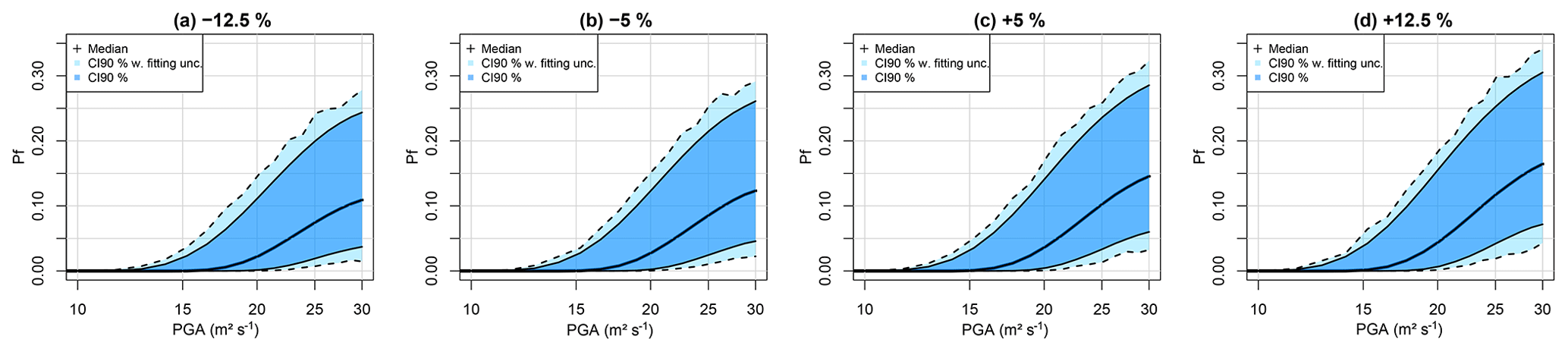
Figure 15FC considering different thickness e4: (a) −12.5 %, (b) −5 %, (c) +5 % and (d) +12.5 % of the original value. Uncertainty bands are provided by accounting for epistemic uncertainty only (dark blue) and by accounting for the fitting uncertainty as well (light blue).
The interest of incorporating the mechanical and geometrical parameters directly into the equation of the FC is the ability to study how the FC in Fig. 14 evolves as a function of the parametric uncertainties, hence identifying regions of the parameters' values leading to large failure probability. This is illustrated in Fig. 15, where the FC is modified depending on the value of the thickness e4, from −12.5 % (0.033 m) to +12.5 % (∼0.043 m), with respect to the median value of 0.038 m. Here larger e4 induces a steeper FC. This appears to be in agreement with the increasing effect of e4 as shown in Fig. 12g. Figure 15 also shows that the effect of e4 on Pf only becomes significant when the e4 variation is of a least ±5 %, compared to the fitting uncertainty (of the order of magnitude of ±2.5 %).
The current study focused on the problem of seismic FC derivation for nuclear power plant safety analysis. We propose a procedure based on the non-stationary GEV distribution to model, in a flexible manner, the tail behaviour of the EDP as a function of the considered IM. The key ingredient is the use of non-linear smooth functional EDP–IM relationships (partial effects) that are learnt from the data (to overcome limits (2) and (3) as highlighted in the Introduction). This avoids the introduction of any a priori assumption to the shape or form of these relationships. In particular, the benefit is shown in Case no. 1 (without epistemic uncertainty), where the non-linear relation is clearly outlined for both μ and lσ. The interest of such data-driven non-parametric techniques has also been shown using alternatives techniques (like neural network – Wang et al., 2018 – or kernel smoothing – Mai et al., 2017). To bring these approaches to an operative level, an extensive comparison or benchmark exercise on real cases should be conducted in the future.
The second objective of the present study was to compare the GEV-based FC with the one based on the Gaussian assumption. We show that if a careful selection of the most appropriate model is not performed (limit (1) described in the Introduction), the failure probability would be either under- or overestimated for Case no. 1 (without epistemic uncertainty) and Case no. 2 (with epistemic uncertainty), respectively. This result brings an additional element against the uncritical use of the (log-)normal fragility curve (see discussions by Karamlou and Bocchini, 2015; Mai et al., 2017; Zentner et al., 2017, among others).
The third objective was to propose an approach to incorporate the mechanical and geometrical parameters in the FC derivation (using advanced penalisation procedures). The main motivation was to allow studying the evolution of the failure probability as a function of the considered covariate (as illustrated in Fig. 15). As indicated in the Introduction, an alternative approach would rely on the principles of the IDA method, the advantage being to capture the variability of the structural capacity and to get deeper insight into the structural behaviour. See an example for masonry buildings by Rota et al. (2010). However, the adaptation of this technique would impose additional developments to properly characterise collapse through the numerical model (see discussion by Zentner et al., 2017: Sect. 2.5). Section 3.1 also points out the difficulty in applying this approach in our case. Combining the idea underlying IDA and our statistical procedure is worth investigating in the future.
The benefit of the proposed approach is to provide information on the sensitivity to the epistemic uncertainties by both identifying the parameters of negligible influence (via the double-penalisation method) and using the derived partial effects. The latter hold information on the magnitude and nature of the influence (linear, non-linear, decreasing, increasing, etc.) for each GEV parameter (to overcome limit (4)). Additional developments should, however, be performed to derive the same levels of information for the FC (and not only for the parameters of the probabilistic model). In this view, Fig. 15 provides a first basis that can be improved by (1) analysing the role of each covariate from a physical viewpoint, as done for instance by Salas and Obeysekera (2014) to investigate the evolution of hydrological extremes over time (e.g. increasing, decreasing or abrupt shifts of hydrologic extremes), as some valuable lessons can also be drawn from this domain of application to define and communicate an evolving probability of failure (named return period in this domain), and (2) deriving a global indicator of sensitivity via variance-based global sensitivity analysis (see e.g. Borgonovo et al., 2013). The latter approach introduces promising perspectives to ease the fitting process by filtering out beforehand some negligible mechanical and geometrical parameters. It is also expected to improve the interpretability of the procedure by clarifying the respective role of the different sources of uncertainty, i.e. related to the mechanical and geometrical parameters and also to the fitting process, which appears to have a non-negligible impact in our study.
The treatment of this type of uncertainty can be improved with respect to two aspects: (1) it is expected to decrease by fitting the FC with a larger number of numerical simulation results. To relieve the computational burden (each numerical simulation has a computation time cost of several hours; see Sect. 3.2), replacing the mechanical simulator by surrogate models (like neural network – Wang et al., 2018 – or using model order reduction strategy – Bamer et al., 2017) can be envisaged, and (2) the modelling of such uncertainty can be done in a more flexible and realistic manner (compared to the Gaussian assumption made here) using Bayesian techniques within the framework of GAMLSS (Umlauf et al., 2018).
Finally, from an earthquake engineering viewpoint, the proposed procedure has focused on a single IM (here PGA), but any other IMs could easily be incorporated, similarly to for the mechanical and geometrical parameters, to derive vector-based FC as done by Gehl et al. (2019) using the same structure. The proposed penalisation approach can be seen as a valuable option to solve a recurrent problem in this domain, namely the identification of most important IMs (see discussion by Gehl et al., 2013, and references therein).
This Appendix gives further details on the double-penalisation procedure used to select variables in the non-stationary GEV. Full details are described by Marra and Wood (2011).
Consider the smoothing penalty matrix Sj in Eq. (6) (associated to the jth smooth function in the semi-parametric additive formulation of Eq. 4). This matrix can be decomposed as
where Uj is the eigenvector matrix associated with the jth smooth function, and Λj is the corresponding diagonal eigenvalue matrix. As explained in Sect. 2.4, the penalty as described in Eq. (6) can only affect the components that have derivatives, i.e. the set of smooth non-linear functions called the “range space”. Completely smooth functions (including constant or linear functions), which belong to the “null space”, are, however, not influenced. This problem implies that Λj contains zero eigenvalues, which makes the variable selection difficult for “nuisance” functions belonging to the null space, i.e. functions with negligible influence on the variable of interest. The idea of Marra and Wood (2011) is to introduce an extra penalty term which penalises only functions in the null space of the penalty to achieve a complete removal of the smooth component. Considering the decomposition (Eq. A1), an additional penalty can be defined as , where is the matrix of eigenvectors corresponding to the zero eigenvalues of Λj. In practice, the penalty in Eq. (6) holds as follows:
where two penalisation parameters (λj, ) are estimated, here by minimisation of the generalised cross-validation score.
Code is available upon request to the first author. Statistical analysis was performed using R package “mgcv” (available at https://cran.r-project.org/web/packages/mgcv/index.html (last access: 20 March 2020). See Wood (2017) for an overview. Numerical simulations were performed with Cast3M simulator (Combescure et al., 1982).
JR designed the concept, with input from PG. MMF, YG, NR and JC designed the structural model and provided to PG for adaptation and implementation to the described case. PG performed the dynamical analyses. JR undertook the statistical analyses and wrote the paper, with input from PG.
The authors declare that they have no conflict of interest.
This article is part of the special issue “Advances in extreme value analysis and application to natural hazards”. It is a result of the Advances in Extreme Value Analysis and application to Natural Hazard (EVAN), Paris, France, 17–19 September 2019.
We thank both reviewers for their constructive comments, which led to the improvement of the paper.
This study has been carried out within the NARSIS project, which has received funding from the European Union's Horizon 2020 Euratom programme under grant agreement no. 755439.
This paper was edited by Yasser Hamdi and reviewed by two anonymous referees.
Aho, K., Derryberry, D., and Peterson, T.: Model selection for ecologists: the worldviews of AIC and BIC, Ecology, 95, 631–636, 2014.
Akaike, H.: Information theory and an extension of the maximum likelihood principle, in: Selected papers of hirotugu akaike, Springer, New York, NY, 199–213, 1998.
Argyroudis, S. A. and Pitilakis, K. D.: Seismic fragility curves of shallow tunnels in alluvial deposits, Soil Dynam. Earthq. Eng., 35, 1–12, 2012.
Augustin, N. H., Sauleau, E. A., and Wood, S. N.: On quantile quantile plots for generalized linear models, Comput. Stat. Data Anal., 56, 404–409, 2012.
Baker, J. W.: Efficient analytical fragility function fitting using dynamic structural analysis, Earthq. Spectra, 31, 579–599, 2015.
Baker, J. W. and Jayaram, N.: Correlation of spectral acceleration values from NGA ground motion models, Earthq. Spectra, 24, 299–317, 2008.
Bamer, F., Amiri, A. K., and Bucher, C.: A new model order reduction strategy adapted to nonlinear problems in earthquake engineering, Earthq. Eng. Struct. Dynam., 46, 537–559, 2017.
Banerjee, S. and Shinozuka, M.: Mechanistic quantification of RC bridge damage states under earthquake through fragility analysis, Prob. Eng. Mech., 23, 12–22, 2008.
Bazzurro, P. and Cornell, C. A.: Disaggregation of seismic hazard, Bull. Seismol. Soc. Am., 89, 501–520, 1999.
Beirlant, J., Goegebeur, Y., Segers, J., and Teugels, J.: Statistics of Extremes: Theory and Applications, Wiley & Sons, Chichester, UK, 2004.
Boore, D. M.: Simulation of ground motion using the stochastic method, Pure Appl. Geophys., 160, 635–676, 2003.
Boore, D. M., Stewart, J. P., Seyhan, E., and Atksinson, G. M.: Nga-west2 equations for predicting pga, pgv, and 5 % damped psa for shallow crustal earthquakes, Earthq. Spectra, 30, 1057–1085, 2014.
Borgonovo, E., Zentner, I., Pellegri, A., Tarantola, S., and de Rocquigny, E.: On the importance of uncertain factors in seismic fragility assessment, Reliabil. Eng. Syst. Safe., 109, 66–76, 2013.
Burnham, K. P. and Anderson, D. R.: Multimodel inference: understanding AIC and BIC in model selection, Sociolog. Meth. Res., 33, 261–304, 2004.
Cheng, L., AghaKouchak, A., Gilleland, E., and Katz, R. W.: Non-stationary extreme value analysis in a changing climate, Climatic Change, 127, 353–369, 2014.
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, Springer, London, UK, 2001.
Combescure, A., Hoffmann, A., and Pasquet, P.: The CASTEM finite element system, in: Finite Element Systems, Springer, Berlin, Heidelberg, 115–125, 1982.
Cornell, C. A., Jalayer, F., Hamburger, R. O., and Foutch, D. A.: Probabilistic basis for 2000 SAC federal emergency management agency steel moment frame guidelines, J. Struct. Eng., 128, 526–533, 2002.
Dutfoy, A.: Estimation of Tail Distribution of the Annual Maximum Earthquake Magnitude Using Extreme Value Theory, Pure Appl. Geophys., 176, 527–540, 2019.
Ellingwood, B. R.: Earthquake risk assessment of building structures, Reliab. Eng. Syst. Safe., 74, 251–262, 2001.
Gehl, P., Seyedi, D. M., and Douglas, J.: Vector-valued fragility functions for seismic risk evaluation, Bull. Earthq. Eng., 11, 365–384, 2013.
Gehl, P., Marcilhac-Fradin, M., Rohmer, J., Guigueno, Y., Rahni, N., and Clément, J.: Identifying Uncertainty Contributions to the Seismic Fragility Assessment of a Nuclear Reactor Steam Line, in: 7th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Crete, Greece, https://doi.org/10.7712/120119.7312.18915, 2019.
Höge, M., Wöhling, T., and Nowak, W.: A primer for model selection: The decisive role of model complexity, Water Resour. Res., 54, 1688–1715, 2018.
Jayaram, N., Lin, T., and Baker, J. W.: A computationally efficient ground-motion selection algorithm for matching a target response spectrum mean and variance, Earthq. Spectra, 27, 797–815, 2011.
Karamlou, A. and Bocchini, P.: Computation of bridge seismic fragility by large-scale simulation for probabilistic resilience analysis, Earthq. Eng. Struct. Dynam., 44, 1959–1978, 2015.
Kim, H., Kim, S., Shin, H., and Heo, J. H.: Appropriate model selection methods for nonstationary generalized extreme value models, J. Hydrol., 547, 557–574, 2017.
Koenker, R., Leorato, S., and Peracchi, F.: Distributional vs. Quantile Regression, Technical Report 300, Centre for Economic and International Studies, University of Rome Tor Vergata, Rome, Italy, 2013.
Lallemant, D., Kiremidjian, A., and Burton, H.: Statistical procedures for developing earthquake damage fragility curves, Earthq. Eng. Struct. Dynam., 44, 1373–1389, 2015.
Lin, T., Haselton, C. B., and Baker, J. W.: Conditional spectrum-based ground motion selec-tion. Part I: hazard consistency for risk-based assessments, Earthq. Eng. Struct. Dynam., 42, 1847–1865, 2013.
Mai, C., Konakli, K., and Sudret, B.: Seismic fragility curves for structures using non-parametric representations, Front. Struct. Civ. Eng., 11, 169–186, 2017.
Marra, G. and Wood, S. N.: Practical variable selection for generalized additive models, Comput. Stat. Data Anal., 55, 2372–2387, 2011.
McKay, M., Beckman, R., and Conover, W.: A comparison of three methods for selecting values of input variables in the analysis of output from a computer code, Technometrics, 21, 239–245, 1979.
Panagoulia, D., Economou, P., and Caroni, C.: Stationary and nonstationary generalized extreme value modelling of extreme precipitation over a mountainous area under climate change, Environmetrics, 25, 29–43, 2014.
PEER: PEER NGA-West2 Database, Pacific Earthquake Engineering Research Center, available at: https://ngawest2.berkeley.edu (last access: 2 December 2019), 2013.
Pousse, G., Bonilla, L. F., Cotton, F., and Margerin L.: Nonstationary stochastic simulation of strong ground motion time histories including natural variability: application to the K-net Japanese database, Bull. Seismol. Soc. Am., 96, 2103–2117, 2006.
Quilligan, A., O'Connor, A., and Pakrashi, V.: Fragility analysis of steel and concrete wind turbine towers, Eng. Struct., 36, 270–282, 2012.
Rahni, N., Lancieri, M., Clement, C., Nahas, G., Clement, J., Vivan, L., Guigueno, Y., and Raimond, E.: An original approach to derived seismic fragility curves – Application to a PWR main steam line, in: Proceedings of the International Topical Meeting on Probabilistic Safety Assessment and Analysis (PSA2017), Pittsburgh, PA, 2017.
Rigby, R. A. and Stasinopoulos, D. M.: Generalized additive models for location, scale and shape, J. Roy. Stat. Soc. Ser. C, 54, 507–554, 2005.
Rota, M., Penna, A., and Magenes, G.: A methodology for deriving analytical fragility curves for masonry buildings based on stochastic nonlinear analyses, Eng. Struct., 32, 1312–1323, 2010.
Salas, J. D. and Obeysekera, J.: Revisiting the concepts of return period and risk for nonstationary hydrologic extreme events, J. Hydrol. Eng., 19, 554–568, 2014.
Schwarz, G.: Estimating the Dimension of a Model, Ann. Stat., 6, 461–464, 1978.
Shinozuka, M., Feng, M., Lee, J., and Naganuma, T.: Statistical analysis of fragility curves, J. Eng. Mech., 126, 1224–1231, 2000.
Tweedie, M. C. K.: An index which distinguishes between some important exponential families. Statistics: Applications and New Directions, in: Proceedings of the Indian Statistical Institute Golden Jubilee International Conference, edited by: Ghosh, J. K. and Roy, J., Indian Statistical Institute, Calcutta, 579–604, 1984.
Umlauf, N., Klein, N., and Zeileis, A.: BAMLSS: bayesian additive models for location, scale, and shape (and beyond), J. Comput. Graph. Stat., 27, 612–627, 2018.
Vamvatsikos, D. and Cornell, C. A.: Incremental dynamic analysis, Earthq. Eng. Struct. Dynam., 31, 491–514, 2002.
Wang, Z., Pedroni, N., Zentner, I., and Zio, E.: Seismic fragility analysis with artificial neural networks: Application to nuclear power plant equipment, Eng. Struct., 162, 213–225, 2018.
Woessner, J., Danciu, L., Kaestli, P., and Monelli, D.: Database of seismogenic zones, Mmax, earthquake activity rates, ground motion attenuation relations and associated logic trees, FP7 SHARE Deliverable Report D6.6, available at: http://www.share-eu.org/node/52.html (last access: 4 April 2020), 2013.
Wong, T. E.: An Integration and Assessment of Nonstationary Storm Surge Statistical Behavior by Bayesian Model Averaging, Adv. Stat. Climatol. Meteorol. Oceanogr., 4, 53–63, 2018.
Wood, S. N.: Thin-plate regression splines, J. Roy. Stat. Soc. B, 65, 95–114, 2003.
Wood, S. N.: Generalized Additive Models: An Introduction with R, 2nd Edn., Chapman and Hall/CRC, Boca Raton, Florida, 2017.
Wood, S. N., Pya, N., and Säfken, B.: Smoothing parameter and model selection for general smooth models, J. Am. Stat. Assoc., 111, 1548–1563, 2016.
Zentner, I.: A general framework for the estimation of analytical fragility functions based on multivariate probability distributions, Struct. Safe., 64, 54–61, 2017.
Zentner, I., Gündel, M., and Bonfils, N.: Fragility analysis methods: Review of existing approaches and application, Nucl. Eng. Design, 323, 245–258, 2017.
https://www.globalquakemodel.org/ (last access: 2 December 2019).