the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 20 Jan 2026
| 20 Jan 2026
Meteorological Drought Trend Analysis and Forecasting Using a Hybrid SG-CEEMDAN-ARIMA-LSTM Model Based on SPI from Rain Gauge Data
Shaun Ramroop
Sileshi Melesse
Nkanyiso Mbatha
Meteorological drought presents considerable challenges to water supplies, agriculture, and socio-economic stability, especially in areas heavily reliant on precipitation. The Standardized Precipitation Index (SPI) is esteemed for its efficacy in drought monitoring, owing to its straightforwardness and applicability across many time scales. This study examines meteorological drought dynamics in the uMkhanyakude district using the Standardized Precipitation Index (SPI) at 6-, 9-, and 12-month timescales. Trend analysis was conducted using Mann–Kendall (MK), Modified Mann–Kendall (MMK), and Innovative Trend Analysis (ITA) methods. The study also proposes a hybrid model that integrates the Savitzky–Golay (SG) filter, Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN), Autoregressive Integrated Moving Average (ARIMA), and Long Short-Term Memory (LSTM) networks, referred to as SG-CEEMDAN-ARIMA-LSTM, for forecasting of the SPI time series. Analysis of SPI trends and variability revealed statistically significant declining trends at five monitoring stations, characterized by negative Z-scores and p-values, showing a marked downward trajectory across several SPI scales. On the other hand, the forecasting results demonstrate that the SG-CEEMDAN-ARIMA-LSTM methodology outperformed benchmark models across all temporal scales, achieving high prediction accuracy with R2 values of 0.9839 (SPI-6), 0.9892 (SPI-9), and 0.9990 (SPI-12). These findings highlight the effectiveness of decomposition techniques (SG, CEEMDAN) in enhancing model performance and confirm the suitability of the hybrid model for both short-term and long-term drought forecasting. This study merges robust trend analysis with advanced hybrid forecasting techniques, providing a reliable framework for early warning systems and sustainable water resource management in drought-prone regions.
- Article
(8441 KB) - Full-text XML
- BibTeX
- EndNote




Drought is a complex and recurring natural hazard with significant economic, social, and environmental implications globally (Bagmar and Khudri, 2021; Kalisa et al., 2021; Song and Park, 2021). In contrast to other natural disasters, droughts manifest gradually, often persisting for extended periods, and their effects permeate various sectors, including agriculture, water resources, and socio-economic systems (Wilhite and Glantz, 1985; Cunha et al., 2019). This study specifically focuses on meteorological drought, characterized as a sustained period of below-average precipitation (Taylan, 2024). Meteorological drought often serves as the initial phase that subsequently evolves into agricultural, hydrological, and socioeconomic drought (Malik et al., 2021; Latifoğlu and Özger, 2023). As it is solely influenced by precipitation variability, meteorological drought can be effectively quantified using precipitation-based indices.
Several indices have been established to quantify drought conditions, including the Standardized Precipitation Index (SPI) and the Standardized Precipitation Evapotranspiration Index (SPEI). While the SPEI integrates both precipitation and temperature data, its requirement for extensive datasets and complex computations may restrict its applicability in regions with limited data availability (Xu et al., 2020). Conversely, the SPI depends exclusively on precipitation, rendering it widely used for analysing meteorological drought, especially in semi-arid regions. Its versatility across multiple timescales facilitates the robust identification of both short- and long-term drought patterns. Accordingly, given the data constraints in the uMkhanyakude district of South Africa, this study adopts the SPI as the primary drought index, while recognizing that its exclusive reliance on precipitation constitutes a methodological limitation. Since SPI is precipitation-driven, analysing rainfall trends is a necessary first step before applying SPI under climate change conditions. Without first establishing rainfall trends, one risks misinterpreting SPI signals as short-term anomalies when they may actually reflect long-term climate-driven shifts.
In this context, the escalating concerns regarding climate change and its influence on local climates have underscored the necessity of analyzing drought trends. Thus, trend analysis of rainfall and SPI together provides a comprehensive picture of rainfall trends, revealing the climatic forcing, while SPI trends quantify the standardized drought intensity and persistence, which is crucial for understanding drought risk in the context of climate change. Systematic evaluations of drought occurrences not only contribute to the development of evidence-based water resource management strategies but also enhance the calibration of early warning systems and inform climate adaptation policies at both regional and national levels. Furthermore, temporal analyses enable researchers to assess the effectiveness of mitigation measures and anticipate emerging risks, thereby bolstering resilience in vulnerable sectors such as agriculture and public water supply. In the absence of structured trend analyses, drought management remains predominantly reactive, constraining the transition towards proactive and sustainable adaptation strategies. Building on trend analysis, drought forecasting is essential for deepening the understanding of drought dynamics. Effective forecasting provides early warnings that are critical for mitigating impacts and strengthening drought management strategies (Balti et al., 2020; Zhang et al., 2022, 2024; Tan et al., 2023).
Accurate forecasting of the SPI is crucial in regions such as uMkhanyakude, which is prone to recurrent and severe drought events. Enhanced prediction capabilities support agricultural resilience, water resource planning, and the establishment of early warning systems (Xu et al., 2020). Traditional statistical models, such as ARIMA or SARIMA, alongside contemporary machine learning methods, have been extensively employed for forecasting drought indices, including the SPI. However, each approach has inherent limitations. For example, Gudko et al. (2025) utilized SARIMA to analyze precipitation dynamics in Russia, demonstrating efficacy in short-term predictions while exhibiting constrained accuracy for long-term forecasts. Similarly, Hussain et al. (2025) integrated ARIMA with machine learning models to enhance SPI and SPEI predictions, achieving accuracies exceeding 92 %. This highlights the advantages of combining statistical and machine learning techniques. Nonetheless, these methodologies often encounter challenges associated with nonlinear and complex rainfall patterns, particularly over short time scales. To mitigate the limitations of standalone models, hybrid approaches have gained prevalence, capitalizing on the complementary strengths of diverse techniques. Alquraish et al. (2021) compared hybrid models such as HMM-GA, ARIMA-GA, and ARIMA-GA-ANN against, such as HMM-GA, ARIMA-GA, and ARIMA-GA-ANN, with conventional HMM and ARIMA models for SPI prediction in the Arabian Peninsula, revealing that hybrid models consistently outperformed their standalone counterparts. Likewise, Xu et al. (2022) and Ding et al. (2022) demonstrated that the combination of CEEMD with ARIMA or LSTM significantly improves SPI forecasts across multiple time scales in China, suggesting that decomposition-based hybrid methods effectively capture intricate temporal patterns.
Recent studies have significantly advanced hybrid methodologies through the implementation of sophisticated preprocessing and optimization techniques. Latifoğlu and Özger (2023) utilized phase transfer entropy (pTE) in conjunction with Tunable Q Factor Wavelet Transform (TQWT), optimized via Grey Wolf Optimization (GWO), followed by artificial neural networks (ANN), support vector regression (SVR), machine learning (ML), and Gaussian process regression (GPR), resulting in superior predictive performance. Sibiya et al. (2024) introduced the CEEMDAN-ARIMA-LSTM model for SPI predictions in Cape Town, demonstrating that the combination of CEEMDAN decomposition with both linear and nonlinear models can significantly improve forecast accuracy. Wei et al. (2025) adopted the Informer model and developed the VMD-JAYA-Informer hybrid, which integrates Variational Mode Decomposition (VMD) with an optimization algorithm, thereby enhancing short-term Standardized Precipitation Index (SPI) and Standardized Precipitation-Evapotranspiration Index (SPEI) forecasts.
Despite the successes achieved by hybrid models, several challenges persist. Decomposition techniques such as Empirical Mode Decomposition (EMD), Ensemble Empirical Mode Decomposition (EEMD), Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN), and Variational Mode Decomposition (VMD) are computationally demanding, particularly when applied to large datasets or in real-time contexts (Sibiya et al., 2024). CEEMDAN, specifically, can yield misleading intrinsic mode functions (IMFs) when utilized on excessively noisy or unstable time series, which undermines the efficiency and reliability of subsequent predictions. Furthermore, existing research has not investigated the synergistic application of advanced smoothing filters in conjunction with decomposition techniques to mitigate noise prior to hybrid modeling.
To address these limitations, this study proposes an innovative hybrid model that integrates the Savitzky-Golay (SG) filter with CEEMDAN for preprocessing, followed by the Autoregressive Integrated Moving Average (ARIMA) and Long Short-Term Memory (LSTM) models for drought prediction. The SG filter is effective in smoothing high-frequency noise, thereby enhancing the decomposition process and alleviating the computational burden. The integration of the Savitzky-Golay smoothing filter with CEEMDAN substantially improves forecasting accuracy by enhancing the quality and interpretability of the input time series prior to modeling. This combination enables CEEMDAN to produce IMFs that are cleaner, more distinct, and less prone to spurious fluctuations, thus offering a more reliable foundation for subsequent predictive modeling. Cleaner IMFs facilitate the training of both linear (ARIMA) and nonlinear (LSTM) models, resulting in more accurate and robust forecasts. This approach capitalizes on the complementary strengths of both statistical and machine learning models, addressing noise-related issues inherent in raw data.
Although hybrid models have demonstrated superior performance in drought forecasting, no prior study has examined:
-
The combined use of smoothing techniques (SG filter) with CEEMDAN to enhance the quality of decomposition.
-
The implementation of an integrated SG-CEEMDAN-ARIMA-LSTM framework for trend-based Standardized Precipitation Index (SPI) predictions (SPI-6, SPI-9, SPI-12).
-
Forecasting efforts that explicitly incorporate both trend analysis and predictive modeling for semi-arid regions characterized by limited meteorological data.
As a result, the proposed SG-CEEMDAN-ARIMA-LSTM model addresses these gaps by enhancing decomposition efficiency, reducing computational costs, and improving prediction accuracy across multiple SPI timescales. This methodology offers valuable insights for water resource management, infrastructure planning, early warning systems, and the advancement of hybrid drought prediction models.
This study utilizes various time series forecasting models to analyse the intricate dynamics of meteorological drought as indicated by the Standardized Precipitation Index (SPI). The foundational statistical model examined is the Autoregressive Integrated Moving Average (ARIMA), which is adept at addressing linear relationships in time series data. The Long Short-Term Memory (LSTM) neural network is employed to tackle nonlinear patterns, supplemented by a hybrid ARIMA-LSTM framework that amalgamates the advantages of both models. Additional improvements are investigated by incorporating a Savitzky-Golay (SG) digital smoothing filter, which is often used to remove noise from time series or spectral data, into the ARIMA-LSTM model, and by utilizing the Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN) before ARIMA-LSTM to more effectively manage nonstationary signals. The work introduces a unique hybrid model, SG-CEEMDAN-ARIMA-LSTM, which integrates decomposition and hybrid modeling techniques to enhance the accuracy and robustness of drought forecasts.
Therefore, the subsequent Materials and Methods section will provide a detailed account of the study area, the data employed, and the preprocessing steps undertaken, including the trend extraction methods applied prior to forecasting. This will be followed by an in-depth description of each modeling approach, outlining their theoretical foundations, implementation procedures, and parameterization strategies. Such a structured presentation ensures transparency in model development and establishes a comprehensive methodological framework for the proposed forecasting system.
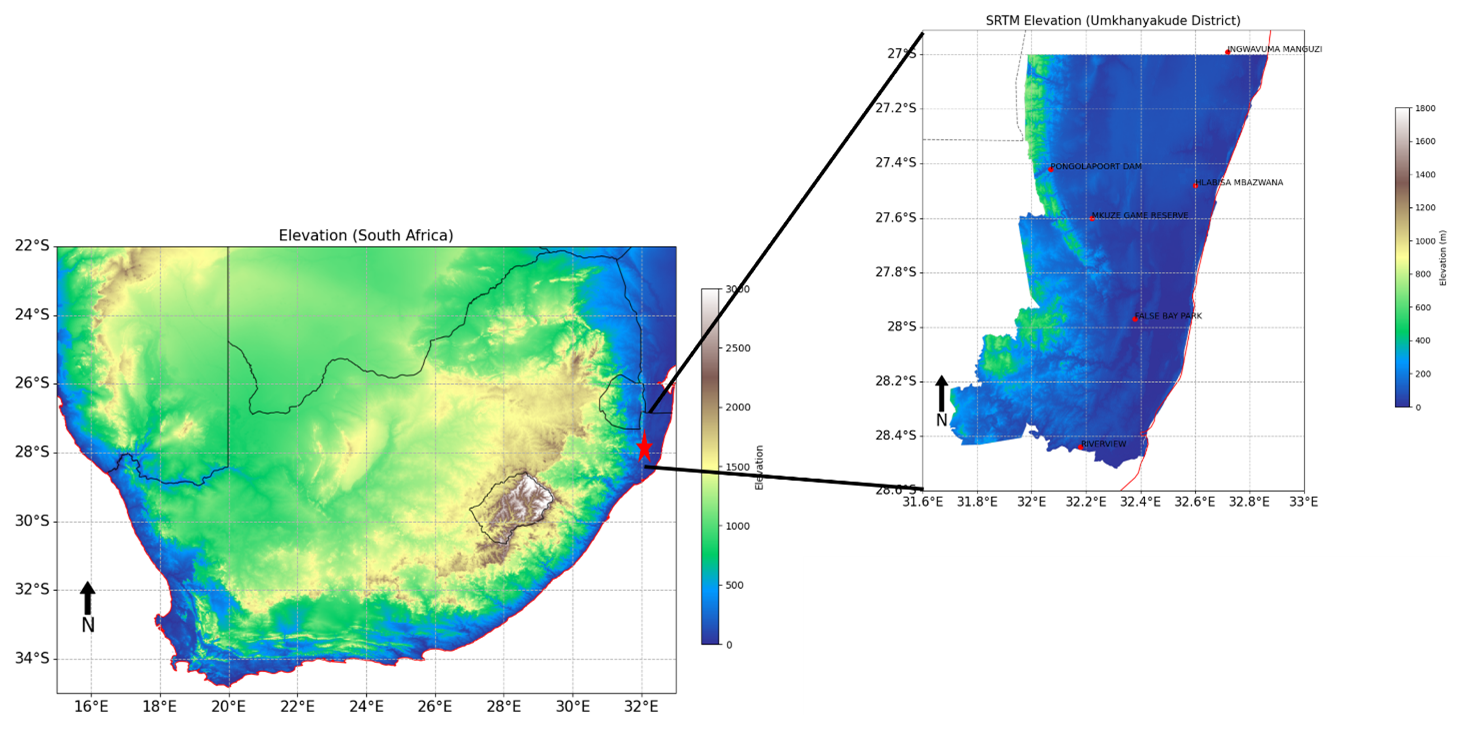
Figure 1Overview of the uMkhanyakude District, South Africa. Rain gauge stations are marked red.
2.1 Study Area and Data
This study employed monthly mean precipitation records from 1980 to 2023, obtained from the South African Weather Service (SAWS) for the uMkhanyakude District in South Africa. The uMkhanyakude District Municipality is located in the far northern region of the KwaZulu-Natal (KZN) province (coordinates: 32.014489° S, 27.622242° E). The municipality covers a total area of 13 855 km2, making it the second largest in the province, exceeded only by the Zululand Municipality. The uMkhanyakude District was formed immediately after the local government elections in December 2000, as part of the municipal demarcation process, encompassing some of the most destitute and underdeveloped areas of KwaZulu-Natal. The uMkhanyakude District consists of four local municipalities: uMhlabuyalingana, Jozini, Big Five Hlabisa, and Mtubatuba. The municipality is geographically surrounded by Mozambique to the north, the Indian Ocean to the east, the uThungulu River to the south, Zululand to the west, and the Kingdom of Swaziland to the northwest. Figure 1 illustrates the spatial distribution of the stations.
2.2 Modified Mann-Kendall
The modified Mann-Kendall methodology is derived from the nonparametric Mann-Kendall method (Mann, 1945; Kendall, 1975), which is widely used to detect trends in hydro-meteorological time series (Caloiero et al., 2011; Bard et al., 2015; Wang et al., 2017; Mirabbasi et al., 2020). The modified Mann–Kendall (MMK) test was employed for serially correlated data exhibiting a substantial lag-1 autocorrelation coefficient, utilising the variance correction method proposed by Yue et al. (2002). Hamed and Rao (1998) created this methodology to eradicate all substantial autocorrelation in the time series. Under the assumption that the data are independent and identically distributed, the S statistic of the Mann-Kendall test is computed as follows (Sharifi et al., 2024):
where n denotes the sample size; xi and xj denote sequential ith and jth data points, respectively, and sign(.) is the sign function which can be computed as
with the mean and variance of the S statistics in the equation are as follows (Helsel and Hirsch, 1993; Ma et al., 2014; Ashraf et al., 2023)
where p is the number of tied groups and ti denotes the number of data points in the tth group. The second term represents an adjustment for tied group or censored data. The standardized Z statistic is calculated as
The test statistic Z is used to measure the significance of the trends. In the modified Mann-Kendall approach, a modified variance of S is computed as follows (Hamed and Rao, 1998)
where n∗ is the effective sample size. The ratio can be calculated as follows (Hamed and Rao, 1998)
where ri denotes the lag-i significant autocorrelation coefficient of rank i in a time series. Then the standardized statistic of the S statistic, denoted as Z, can be derived as
If the calculated Z values (ZMK and ZMMK) exceed the critical values of or fall below , there is no discernible trend in the time series at the significance level of α. If the Z value is positive and exceeds , the trend is upward; conversely, if the Z value is negative and falls below , the trend is downward.
2.3 Innovative Trend Analysis
The Innovative Trend Analysis (ITA) method, initially introduced by Şen (2012), has been widely employed for detecting patterns in precipitation time series. Since its debut, the ITA technique has experienced substantial improvements in both mathematical and graphical aspects, as evidenced by Şen (2017) and Alashan (2018). The ITA method does not depend on assumptions of serial autocorrelation, normalcy, or record length, making it appropriate for both graphical and statistical trend analysis (Zena et al., 2022). Initially, the time series is bifurcated into two equal segments and organised in ascending order. The initial segment of the time series () is positioned along the horizontal x-axis, while the subsequent segment () is situated along the vertical y-axis in the Cartesian coordinate system (Ashraf et al., 2023). The ITA approach visually represents trend analysis, specifically indicating monotonic growing, declining, and trendless circumstances (Öztopal and Şen, 2017; Likinaw et al., 2023). A monotonically growing or declining trend can be identified when the majority of points are situated above or below the 45° (1:1 line), respectively. A trendless condition arises when the data points are clustered along the 45° line (Şen, 2012). We employ the magnitude of the slope parameter to convey information about monotonicity. The slope parameter of the ITA technique is a stochastic property dependent on the sample means of the first half (n1) and the second half (n2) of the time-series mean data values. According to Şen (2017), the straight-line trend slope (SITA) can be estimated using the following expression:
where n represents the total number of observations, xi and xj are the arithmetic means of the first and second halves of the sub-series, respectively. Given that xi and xj are stochastic variables, the expected value of the slope can be determined by analysing the expectancies of both the first and second halves of the time series (Alashan, 2020; Harka et al., 2021):
For the no trend condition, E(xj)=E(xi), the E(SITA)=0 and standard deviation (SD) of the two half time-series , σ is the SD is of the parent series. If E(xj)≠E(xi), the differences between E(xj) and E(xi) gives the variance
and the SD of the slope
In the stochastic processes, the term is the correlation coefficient between the two mean values, and can be estimated as
In the end, the upper and lower confidence limit (CL) of the trend slope was calculated (Şen, 2017):
denotes the crucial slope for standardised time-series at ±1.96 for a 95 % significance level or ±1.645 for a 90 % significance level (Alashan, 2020). If the ITA slope value is beyond the lower and upper confidence limits, the null hypothesis of no significant trend should be rejected at the α significance level (Şen, 2017). In a two-tailed scenario, the null hypothesis (H0) posits the absence of a trend in time-series data, while the alternative hypothesis (H1) asserts the presence of a trend in time-series data at a significance level of α. If the slope, , then (H0) is discarded in favour of (H1). The positive and negative values of SITA signify an upward and downward trend in the time-series data, respectively (Şen, 2017).
2.4 The SPI Calculation
For the purpose of analysing the severity of drought, which is caused by a lack of water supply as a result of reduced precipitation in response to rising demand, the SPI was created by McKee et al. (1993) and is based on probability (Zuo et al., 2021). Based on the cumulative likelihood of a specific amount of precipitation, the SPI indicator is calculated by fitting the precipitation throughout the same period with a certain distribution function. At its largest point, the SPI index represents the quantile of a normal distribution. Each time axis has an estimated drought index for 6, 9, and 12 months. This is based on the gamma probability density function, which accounts for the periodic distribution of precipitation for the corresponding data point. The expression of the density function for this distribution is as follows.
where α is the shape parameter, β is the scale parameter and x is the precipitation amount, and is gamma function. The maximum likelihood estimates of the parameters α and β are:
where , is the precipitation average and n is the sample size. The following equation applies the acquired parameters to the cumulative probability distribution:
G(x) represents the likelihood that the precipitation will be equal to or less than x. The distribution function for precipitation needs to be adjusted because the real precipitation samples can contain a value of 0. Based on this, we can calculate the cumulative probability as:
where q denotes the probability when precipitation equals zero. The probability of no rainfall, q, can be articulated as , where m represents the number of days without rainfall and r denotes the number of days with rainfall (Song and Park, 2021). Consequently, H(x) is converted to the conventional random variable Z of the standard normal distribution, characterised by a mean of 0 and a variance of 1, resulting in:
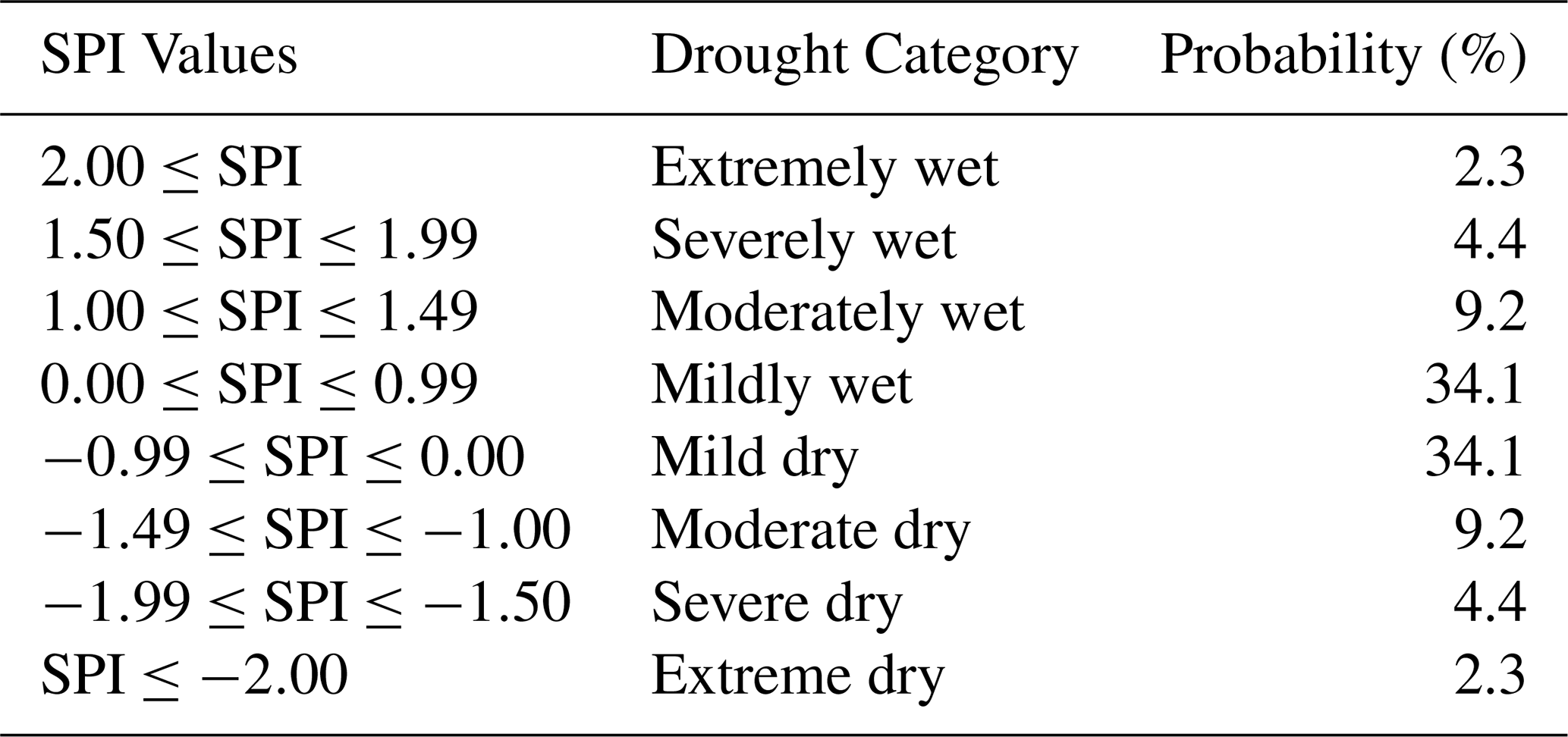
where , c1=0.802853, , , , are constants. Furthermore, the SPI indicator is a standardised normalised index, establishing a correlational relationship with likelihood. Table 1 presents the probability associated with each category of drought.
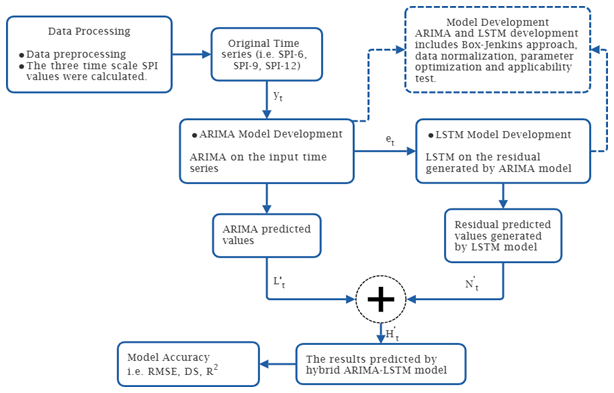
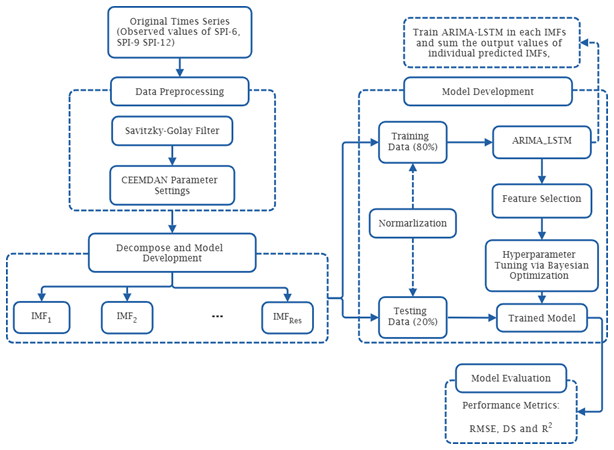
Table 1Drought classification using SPI values and corresponding event probability (Lloyd-Hughes and Saunders, 2002).
2.5 The Savitzky-Golay Filter
The Savitzky-Golay (SG) smoothing technique is a widely used method for noise filtration. Savitzky and Golay (1964) introduced the SG filter as an effective technique for signal smoothing. The SG technique attenuates noise utilising two parameters: polynomial order and window size. By flexibly adjusting these two parameters, the SG filter can achieve exceptional performance in various pre-processing circumstances. The essence of this procedure involves fitting a low-degree polynomial to the samples within a sliding window using the least squares method, resulting in a new smoothed value for the central point derived by convolution. The SG filter is a specific variant of a low-pass filter that substitutes each value in the time series with a new value derived from a polynomial fit to 2m+1 surrounding points, including the point to be smoothed, where m is equal to or larger than the polynomial's order. The polynomial is articulated as follows:
where N is the power of the polynomial and . The following equation is used to determine the error between the estimated and original values; in order to find the desired polynomial result, this error must be minimised.
The following form of discrete convolution can be used to express the filter's output:
This work employs the SG filter for two primary reasons: firstly, it enhances system performance by preserving the width and height of waveform peaks in noisy SPI, and secondly, it modifies the SPI while maintaining its fundamental qualities.
2.6 The Complete Ensemble Empirical Mode Decomposition with Adaptive Noise
The model's ability to fit functions and converge will be constrained by the complexity and volatility of the original time sequence, which in turn limits the model's predictive power. To overcome this challenge, the complete ensemble empirical mode decomposition (CEEMDAN) technique is employed to preprocess the original nonstationary and nonlinear time series. Both empirical mode decomposition (EMD) and ensemble empirical mode decomposition (EEMD), have been enhanced by the CEEMDAN. The computational efficiency is improved, and the reconstructed sequences of both the EMD and EEMD algorithms are free of modal confusion and noise residuals (Zhang et al., 2023). A residual term and a sequence of intrinsic mode functions (IMFs) are the building blocks of a complicated time series signal that the CEEMDAN breaks down.
Step 1: Incorporate a constrained quantity of adaptive white noise into the original sequence
where N denotes the number of trials, δ0 signifies a coefficient of intensity, and ωi(t) indicates the ith realisation of a stochastic Gaussian process.
Step 2: The residual r1(t) and the first modal component IMF1 are obtained by decomposing each Eq. (1) using EMD.
In this context, EMD1(.) denotes the initial IMF component produced by the EMD algorithm, while r1(t) signifies the residual associated with the first stage.
Step 3: Add white noise δ1EMD1(ωi(t)) to the residual r1(t) and further decomposed by EMD to obtain the second modal component IMF2 and residual r2(t).
For the , the jth IMF component and the jth residual can be computed as:
where denotes the (j−1)th intrinsic mode function component derived from the empirical mode decomposition technique, and rj(t) represents the residual following the jth decomposition.
Step 3: Continue executing step 3 until the residual rj(t) meets a predetermined termination criterion.
The time series x(t) can ultimately be articulated as
2.7 The Autoregressive Integrated Moving Average Model
The Autoregressive Integrated Moving Average (ARIMA) model, pioneered by Box and Jenkins in the 1970s, serves as a robust and effective forecasting approach for time series analysis (Box et al., 2015). The ARIMA model, often known as the Box-Jenkins approach, is depicted through the concepts presented by Sibiya et al. (2024) in Fig. 2. The ARIMA models predict future values of the time series as a linear combination of historical and residual data. This model comprises three components: the order of seasonal differentiation, autoregressive order, and moving average order (Montgomery et al., 2015). The backward shift operator B is employed to eliminate nonstationarity. A time series, yt, is called homogeneous nonstationary if it first order difference, or the dth difference is also stationary time series. Furthermore, yt is referred to as an ARIMA model with orders pd and q, noted ARIMA(pdq). Hence, an ARIMA(pdq) is often expressed as
The backward shift operators for AR(p) and MA(q) are defined as and with , where μ and εt are the mean and white noise, respectively and the εt is independent and normal distributed with mean and variance of .
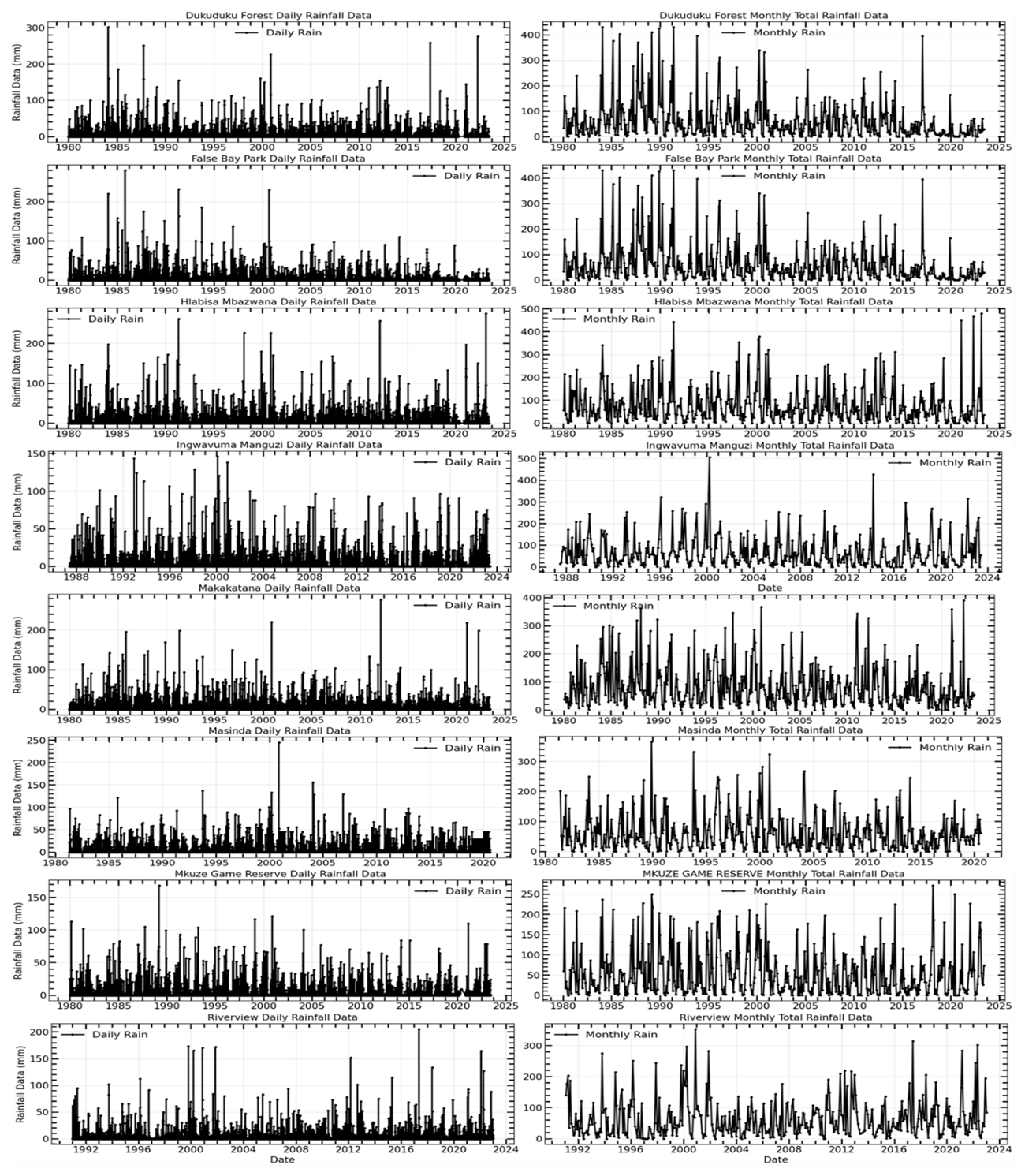
Figure 6Time series plots of daily and monthly total rainfall data for uMkhanyakude district from early 1980's to 2023. The (left) plot shows the daily rainfall data in millimeters (mm), illustrating the high variability and intermittent nature of daily rainfall events over the years. The (right) plot presents the monthly total rainfall data (mm), which smooths out the daily variability and reveals clearer patterns of rainfall distribution over time.
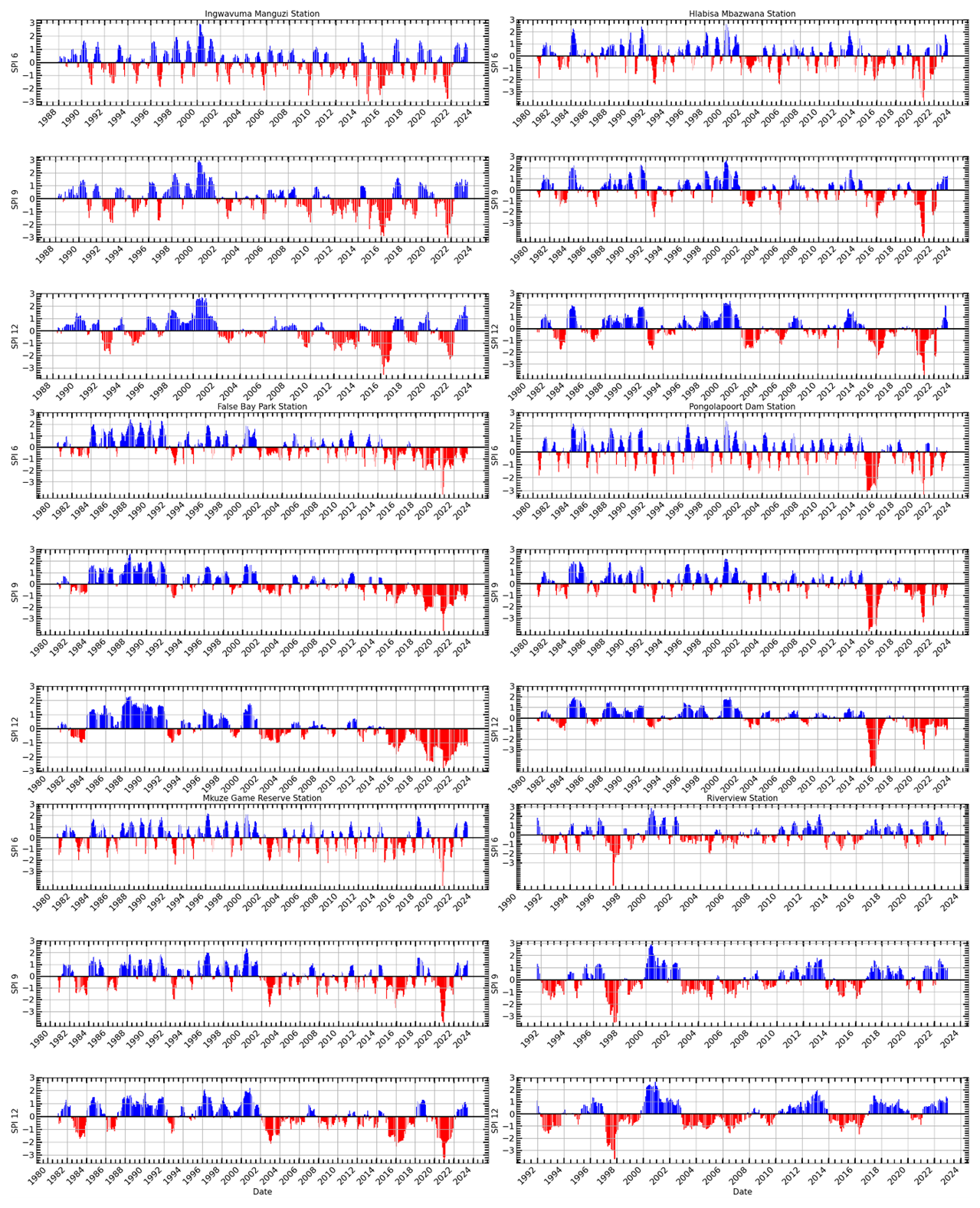
Figure 7Standardized Precipitation Index (SPI) time series plots for uMkhanyakude district over 6-month (SPI-6), 9-month (SPI-9), and 12-month (SPI-12) periods from early 1980's to 2023. Positive SPI values (blue bars) indicate wetter-than-normal conditions, while negative SPI values (red bars) indicate drier-than-normal conditions.
2.8 The Long Short-Term Memory
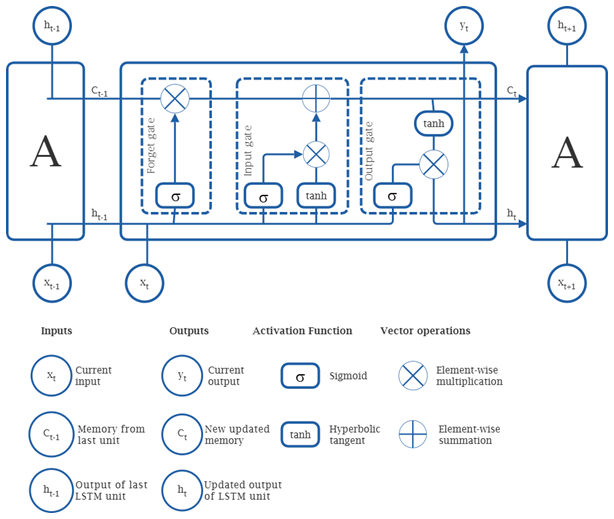
Long short-term memory (LSTM) algorithms represent a category of recurrent neural network (RNN) designs that are proficient in handling sequential input and identifying temporal relationships (Hochreiter and Schmidhuber, 1997). LSTM networks incorporate specific memory cells and gates for the efficient management and regulation of information flow over various time steps. Consequently, they can effectively represent the data input while maintaining essential dependencies and patterns. The LSTM methodology addresses the problem of vanishing gradients encountered by RNN algorithms. This occurs when the gradient diminishes to a level insufficient for effectively updating the weights throughout prolonged sequences. The LSTM facilitates the flow of gradients across time by employing memory cells and gates. The model's foundational design primarily consists of three control gates: input, forget, and output. The activation function is represented by σ, whereas the cell states at time t−1 and t are designated as Ct−1 and Ct respectively. At time t and time t−1, the cell possesses two concealed states, ht and ht−1. Figure 3 illustrates the building of the LSTM unit, and the mathematical Eqs. (35) to (40) for the LSTM method are provided below. Initially, by employing the model's forget gate, we may determine the current hidden state ht−1 and the degree to which the input xt has been preserved. The formula is
Secondly, the input gate allows us to ascertain the volume of content from the input variable that can be retained in the cell state Ct
The output gate of the LSTM produces outputs, and the hidden state of each cell is represented by the formula:
In the aforementioned formulas, Wf, Wi, and Wo represent the weight matrices associated with the various control gates. The terms bf, bi, and bo correspond to the bias terms for each respective control gate. The notation signifies the complete input activation vector, while the operator ⊙ (Hadamard product) indicates the element-wise multiplication of the elements between two vectors. The σ activation function quantifies the amount of information that is transmitted through the various control gates.
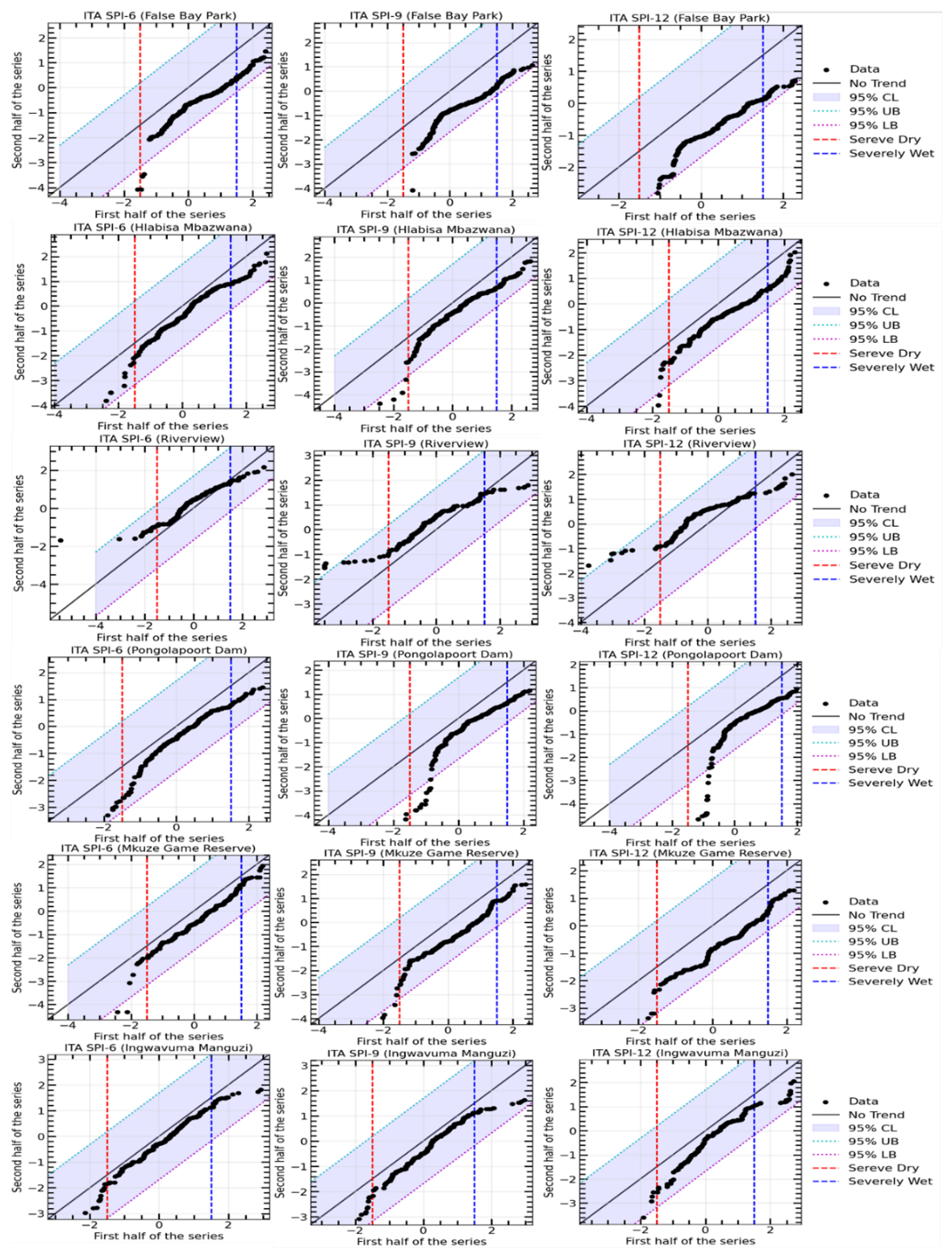
Figure 8Results of Innovative trend analysis applied to different time scales values (SPI-6 (left), SPI-9 (middle), SPI-12 (right)). The blue shaded area represents the 95 % confidence level area. The red and blue vertical lines represent the severe drought and severely wet, respectively.
2.9 The ARIMA-LSTM hybrid Model
Achieving accurate estimates of SPI index values through a forecasting model is essential for informed decision-making. Zhang (2003) offers a hybrid model wherein the ARIMA model extracts and predicts linear components, while the residuals, representing nonlinear data subcomponents, are then modelled by the LSTM approach. This study employs a hybrid model that integrates ARIMA and LSTM to predict both linear and nonlinear behaviours with optimal accuracy.
where Lt and ℵt denote the linear and nonlinear components, respectively, for the hybrid technique which are computed using the initial time series (yt). Consider the original dataset at time t and the forecast results obtained from applying the ARIMA model as the prediction results. Thus, is the definition of the residual Et that is derived by removing from yt. Subsequently we compute the value by feeding the series of residuals into the LSTM model, which predicts the nonlinear component of the values. This equation may be written as
where is a nonlinear expression associated with the LSTM model and ϵt is the random error. The combined forecasts from the two steps were then used to determine the value for the ARIMA-LSTM hybrid model. As illustrated in Fig. 4, the equation predicts the linearity and nonlinearity values, respectively, using ARIMA and LSTM models.
Table 2Statistical summary of trend analysis for SPI-6, SPI-9, and SPI-12 using Mann-Kendall (MK) and Modified Mann-Kendall (MMK) tests.
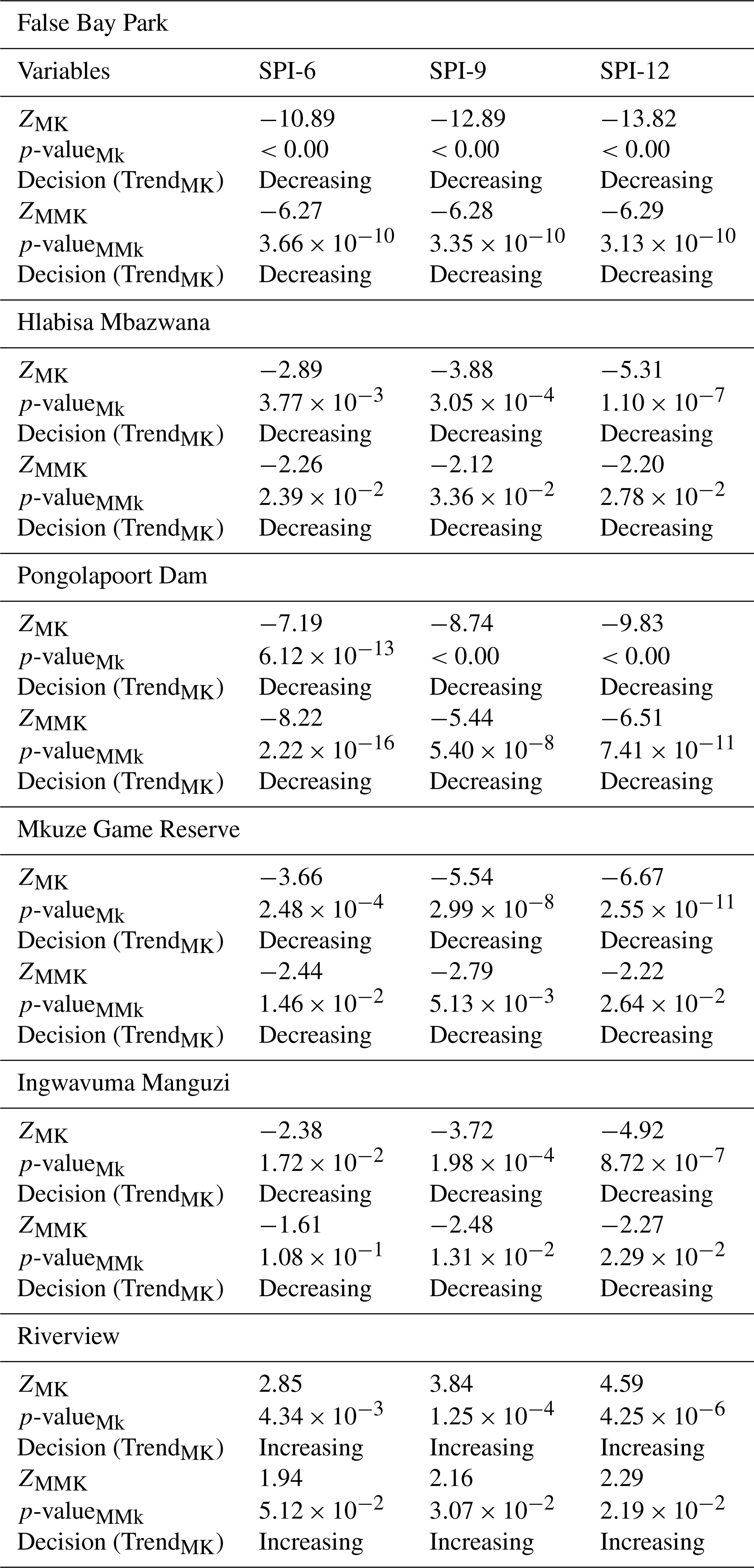
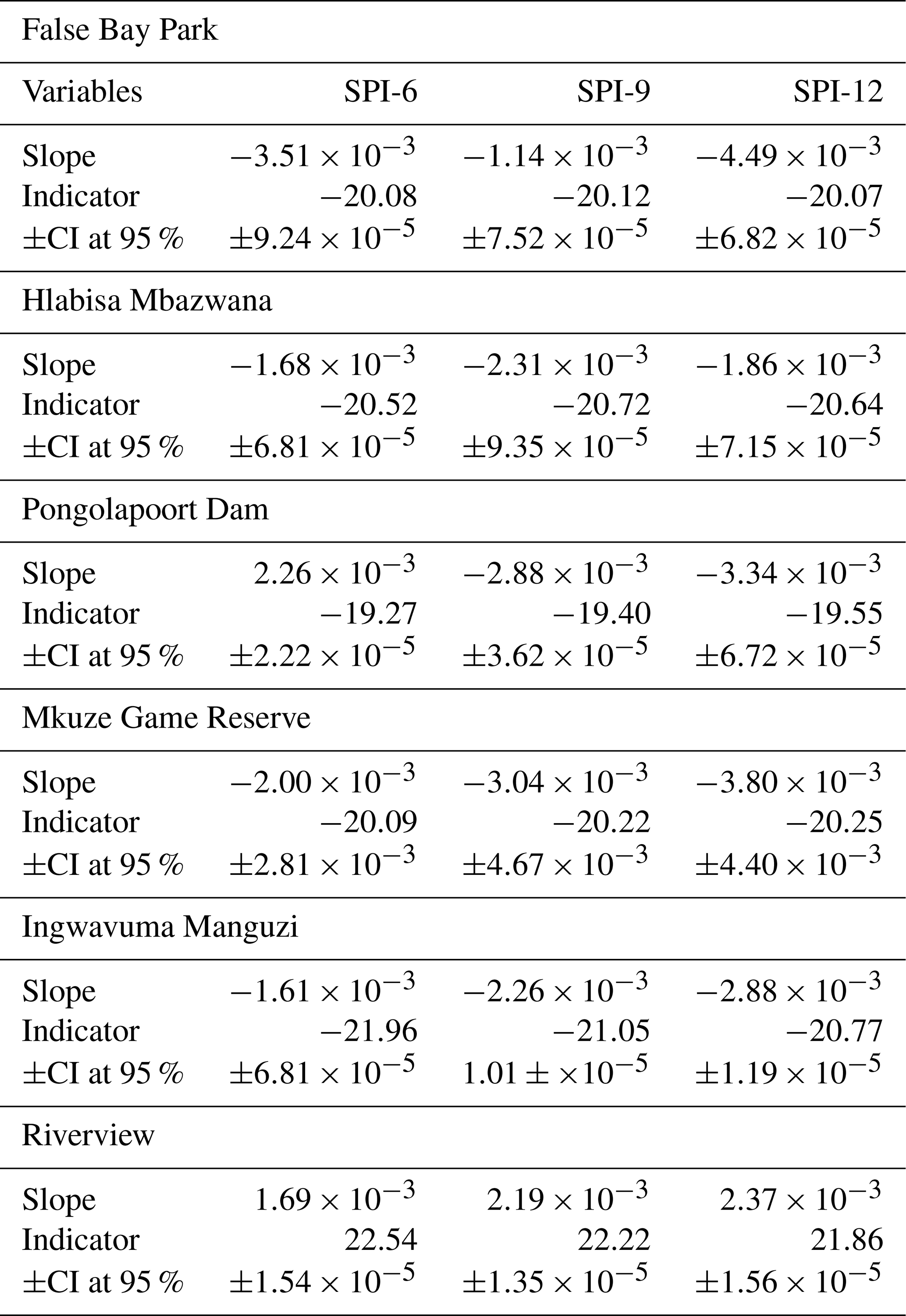
Table 3The results of the trend analysis for SPI-6, SPI-9, and SPI-12 obtained through a two-tailed test at a significance level of 5 % using ITA technique.
2.10 The development of the proposed SG-CEEMDAN-ARIMA-LSTM hybrid model
Due to the great uncertainty of the drought data and the existence of complexity, nonlinearity, and nonstationary trends, the single prediction model is greatly limited; however, the hybrid method has better prediction accuracy. The SG-CEEMDAN-ARIMA-LSTM algorithm that combines different techniques for improved accuracy in predicting drought based on the standardised precipitation index is proposed this study. This hybrid model is designed as a sequential framework where each step refines the data for subsequent modelling. The SG-CEEMDAN pre-processing stage enhances the data by smoothing and decomposing it into the meaningful components. The benefits of integrating the Savitzky–Golay smoothing filter with CEEMDAN significantly contribute to the enhancement of forecasting accuracy by improving the quality and interpretability of the input time series prior to modeling. The Savitzky–Golay filter acts as a noise suppression mechanism that preserves essential features of the time series, while eliminating high-frequency noise. This step ensures that the input to the CEEMDAN decomposition process is already denoised, leading to more stable and physically meaningful decomposed components. The CEEMDAN generates IMFs that are cleaner, more distinct, and less affected by spurious fluctuations. This results in better mode separation, reduces signal leakage across IMFs, and enhances the stationarity and regularity of each component. This hybrid preprocessing pipeline can enhances model generalization, reduces overfitting, and ultimately leads to more reliable and accurate forecasts. The components fed to the ARIMA-LSTM model that involves two-step process: the ARIMA for initial prediction utilising the Box-Jekins methodology and the LSTM model for refining and enhancing predictions. The hybrid model combines the ARIMA and the LSTM predictions to form the final hybrid forecasts. Figure 5 illustrates the proposed hybrid model algorithm. The process of SPI prediction based on ARIMA-LSTM combined with SG and CEEMDAN as is shown in Fig. 5. The process of the data smoothing, decomposition and prediction include four main steps.
Step 1: Data Preprocessing Phase: To enhance the quality of the data and prepare it for decomposition, the original SPI time series undergo a data preprocessing phase:
-
Savitzky–Golay Filter: This filter is applied to smooth the SPI data and preserves the essential shape and trends of the original time series while minimizing high-frequency noise. This step ensures that important signal patterns are retained during further processing. The smoothed signal becomes the input signal for decomposition technique.
-
CEEMDAN Parameter Settings: CEEMDAN is used to break the smoothed signal into several IMFs and a residual component. Before decomposition, the necessary parameters for CEEMDAN are configured. These parameters control the number of realizations, noise amplitude, and stopping criteria for decomposition.
Step 2: Model Development Phase: Each IMF, including the residual, is independently modelled using a hybrid ARIMA–LSTM approach. This process involves several steps:
- a.
Data Partitioning
-
The data for each IMF is split into: Training set (80 %) and Testing set (20 %). This split ensures that model learning and evaluation are based on separate subsets to avoid overfitting.
-
- b.
Normalization
-
Prior to model training, the data is normalized using Min-Max normalization to ensure that input features fall within a similar scale, which improves training stability and convergence speed.
-
- c.
Modelling Each IMF with ARIMA–LSTM
-
The two models are integrated so that both linear (ARIMA) and nonlinear (LSTM) dependencies within each IMF are effectively captured. The modelling process follows the algorithm shown in Fig. 4.
-
- d.
Feature Selection and Hyperparameter Tuning
-
The performance of ARIMA and LSTM models heavily depends on the feature selection and hyperparameters. The auto_arima( ) function and Bayesian Optimization were used to automate and optimize the search for best-performing hyperparameters for the ARIMA-LSTM model by evaluating model performance over a probabilistic space.
-
- e.
Model Training
-
Each IMF is trained individually using the selected features and optimized hyperparameters, resulting in a trained model for each component.
-
Step 3: Forecast Reconstruction Phase
-
After training, each IMF is forecasted individually. The final forecasted SPI value is obtained by summing the predictions of all individual IMFs, including the residual component:
This additive reconstruction ensures that the original structure and dynamics of the SPI series are preserved in the forecast, improving overall accuracy.
Step 4: Model Evaluation Phase
The reconstructed SPI prediction is then evaluated using multiple performance metrics: RMSE, DS, and coefficient of determination. The Taylor diagram is also utilised to evaluate the model performance. These metrics help quantify the predictive accuracy and reliability of the hybrid framework.
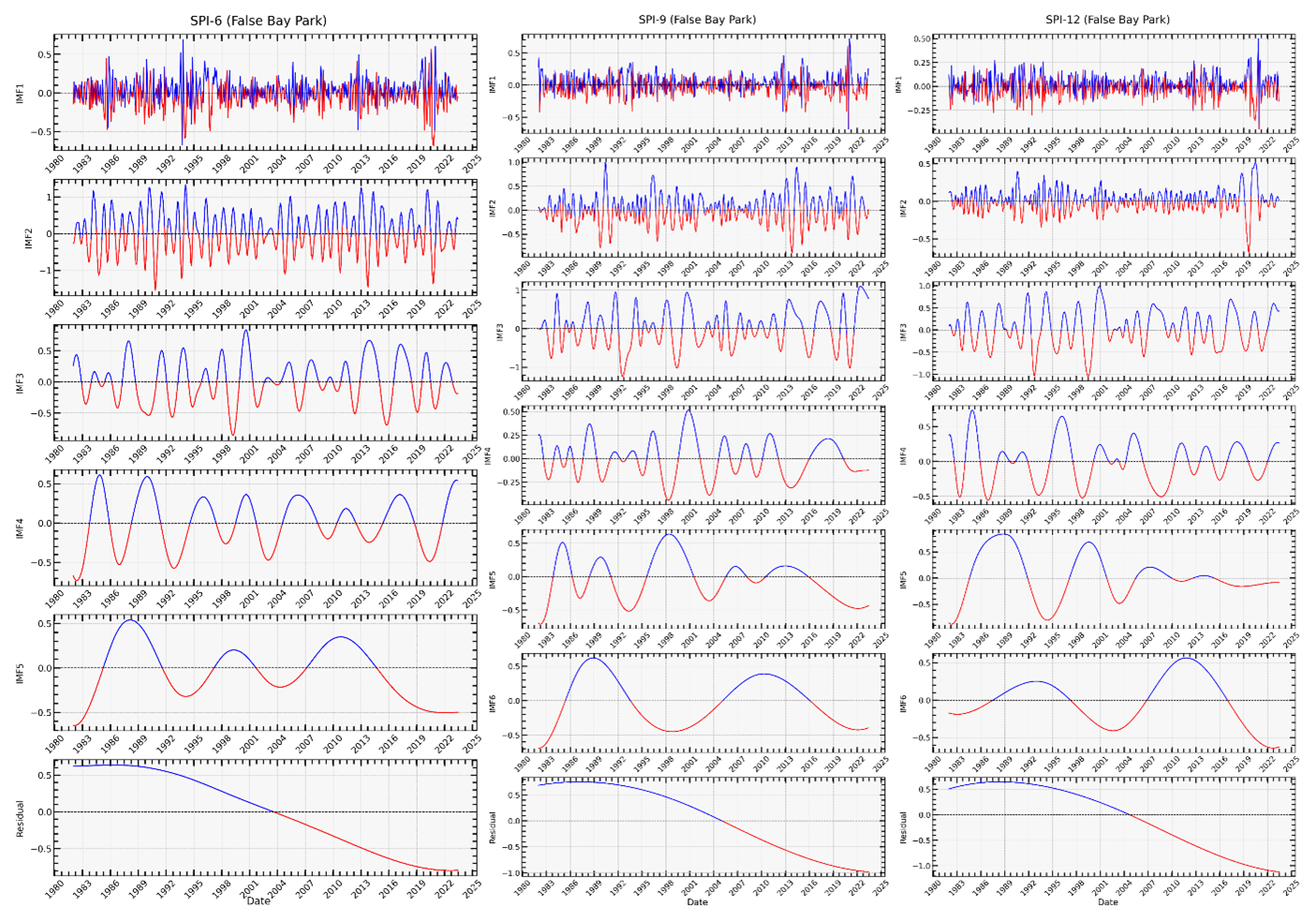
Figure 10Decomposition of Smoothed SPI-6, SPI-9 and SPI-12 Index Using CEEMDAN: Each IMF represents different frequency components of the SPI index, from high-frequency oscillations (IMF1) to low-frequency trends (IMF5), showing the variability in precipitation patterns over the years from 1980 to 2023.
2.11 Performance Evaluation
To establish the predictive superiority of the SG-CEEMDAN-ARIMA-LSTM model, a comparison was conducted against other models, including ARIMA, LSTM, ARIMA-LSTM, SG-ARIMA-LSTM, and CEEMDAN-ARIMA-LSTM models. The performance of the proposed hybrid-based model is evaluated using three indicators namely, root mean square error (RMSE), coefficient of determination (R2) and directional symmetry (DS). The high value of R2 and DS reflects the better performance of the forecasting model while the lower the value of RMSE illustrates better forecasting performance.
where
n is number of data points, yi and observed and forecasted, respectively. yavg and an average of the actual and forecasted values, respectively. Furthermore, this study conducts a qualitative evaluation of the prediction model's performance using a Taylor diagram (Taylor, 2001). The Taylor diagram offers a statistical evaluation of the degree of agreement between the models in terms of their SD, RMSE, and R2, while providing a concise summary of the correspondence between predicted and observed values. The differences in DS, RMSE, and R2 values among the prediction models are depicted as individual points on a two-dimensional plot within the Taylor diagram. This diagram, though it follows a common structure, proves especially valuable when evaluating intricate models.
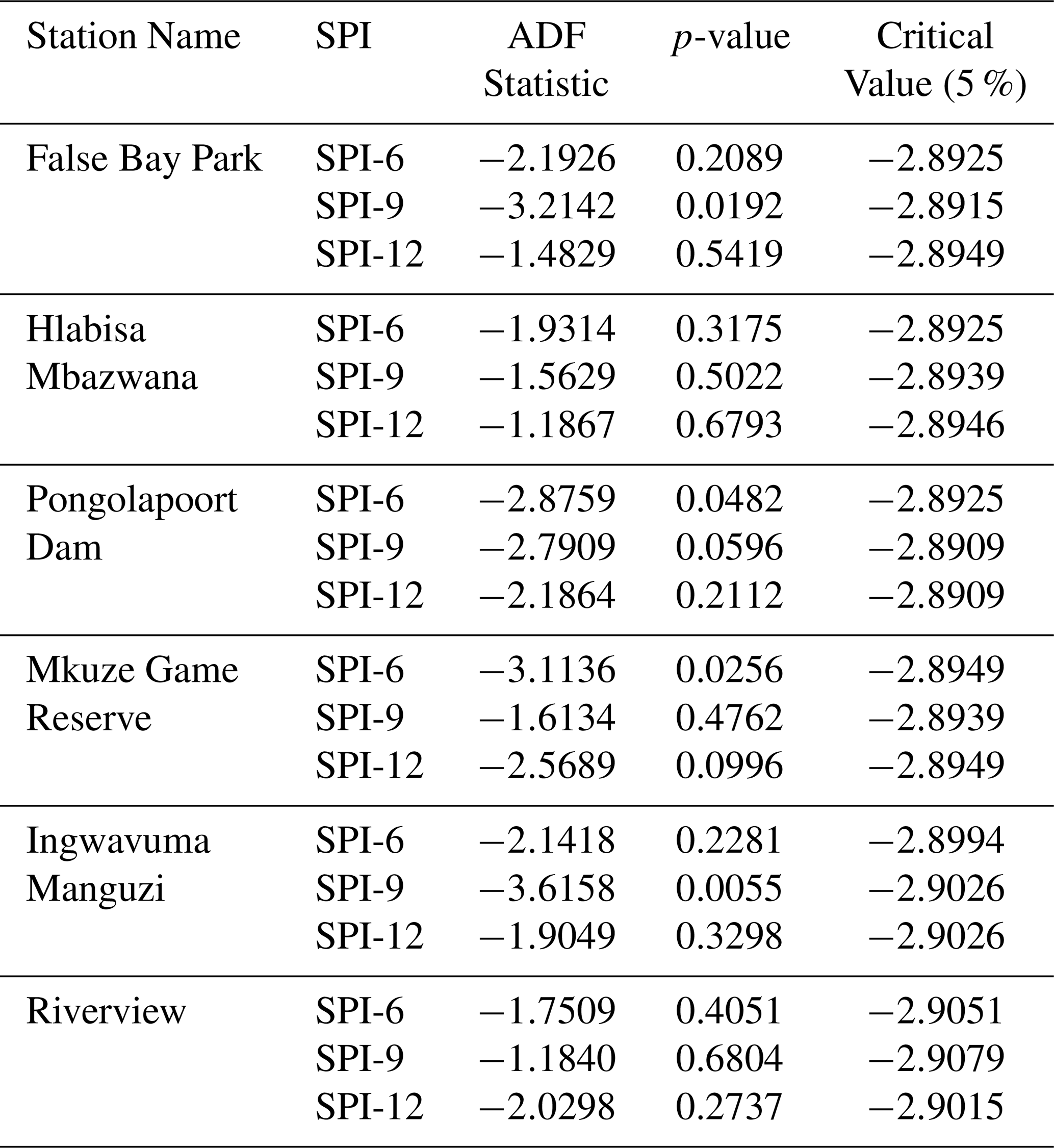
Table 4ADF Test Results for SPI Values (SPI-6, SPI-9, SPI-12) at Different Stations.
3.1 Rainfall Data Series
Figure 6 illustrates the daily and monthly cumulative precipitation data recorded at the uMkhanyakude district meteorological stations in KwaZulu-Natal province, South Africa, from the early 1980s to 2023. The data comprising 20 % was employed for prediction, whereas the data representing 80 % was applied for training. The SPI was computed utilising rainfall data from meteorological stations in the uMkhanyakude district, which provide sufficiently extensive records and a consistent structure (Hırca et al., 2022).
3.2 SPI Time Series and Trend Analysis
This study SPI values for the 6-, 9-, and 12-month intervals were computed using the monthly mean time series shown in Fig. 6. Figure 7 illustrates the time series of the SPI calculated for the 6-month (SPI-6), 9-month (SPI-9), and 12-month (SPI-12) intervals. All SPIs (SPI-6, SPI-9, and SPI-12) demonstrate numerous occurrences of moderate to severe droughts in the studied area. A significant drought episode was reported from late 2004 to 2009. Moreover, SPI-12 exhibits a persistent drought spell that commenced between 2014 and 2016, resulting in a decline in water supply conditions in the region (Bukhosini and Moyo, 2023). The statistics across all timelines indicate a troubling trend of extended and intense drought conditions in recent years. This underscores the pressing necessity for efficient water management and drought readiness in the area. Initially, we assess the trend throughout the research area employing nonparametric techniques. The ensuing conclusions will be obtained via advanced trend analysis methods employed to investigate SPI trends.
Figure 8 illustrates the regional outcomes of the ITA methodology used on the 6-, 9-, and 12-month SPI series to ascertain the potential meteorological drought trend in the uMkhanyakude district. Figure 8 includes two vertical bands to elucidate the potential trends of arid and humid conditions: a red band indicating the drought threshold (SPI ) and a blue band denoting the wet threshold (SPI =1.5). The zone between the two bands signifies normal conditions, hence facilitating the depiction of both low and high SPI trends using the ITA methodology. Each plot compares the first and second halves of the data series to identify trends.
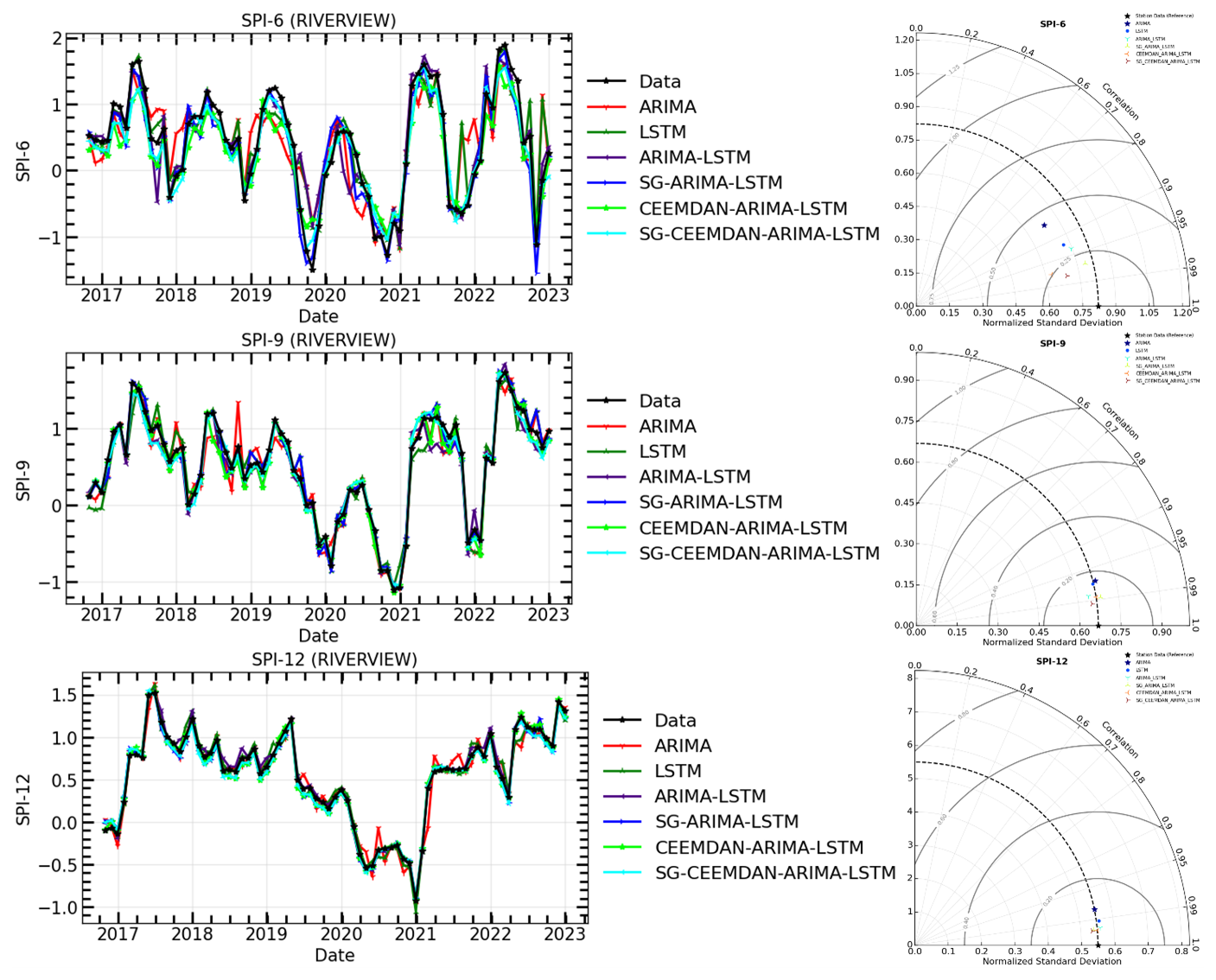
Figure 11The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of Riverview meteorological station.
In general, both Fig. 8 and Table 3 show that all stations, except Riverview, indicate a downward trend for all time scales, in terms of the ITA. For example, the ITA results obtained using 6-month SPI values exhibit a slightly decreasing trend in precipitation, moving toward the upper right quadrant, indicating the detection of drier conditions over the 6-month timescale. Some points approach the severely wet threshold but do not cross it, indicating that there were no extreme wet periods, though some drier periods are evident near the severe dry line. The ITA results obtained using 9-month SPI values show a more pronounced decreasing trend, indicating a relatively weaker increase in wet conditions over a 9-month timescale. Several points approach the severe dry threshold, but the data remains mostly within the 95 % confidence bounds, indicating moderate variability in precipitation trends. On the other hand, the SPI-12 plot demonstrates a noticeable decreasing trend toward dryness, as many points fall below the no-trend line and approach the severe dry region. Riverview indicates the increasing trend across all time scales. The increasing distance between the black dots and the no-trend line highlights a shift toward drier conditions in the second half of the series. In general, the analysis suggests a gradual increase in precipitation for shorter periods (SPI-6), moderate upward trends for medium-term periods (SPI-9), and a more substantial shift toward dry conditions over longer periods (SPI-12) for Riverview. The variability is evident, but a clear progression toward drier conditions is evident, particularly in the SPI-12 plot. This observation could be indicative of changing precipitation patterns, which is crucial for understanding drought risk and informing water resource management strategies.
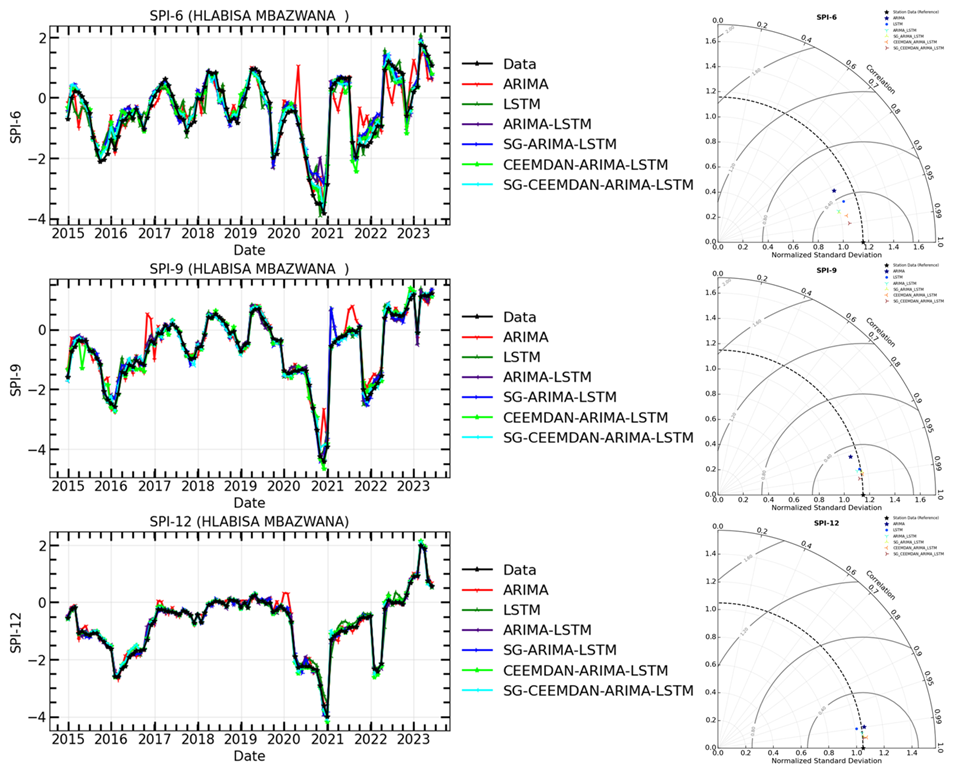
Figure 12The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of Hlabisa Mbazwana meteorological station.
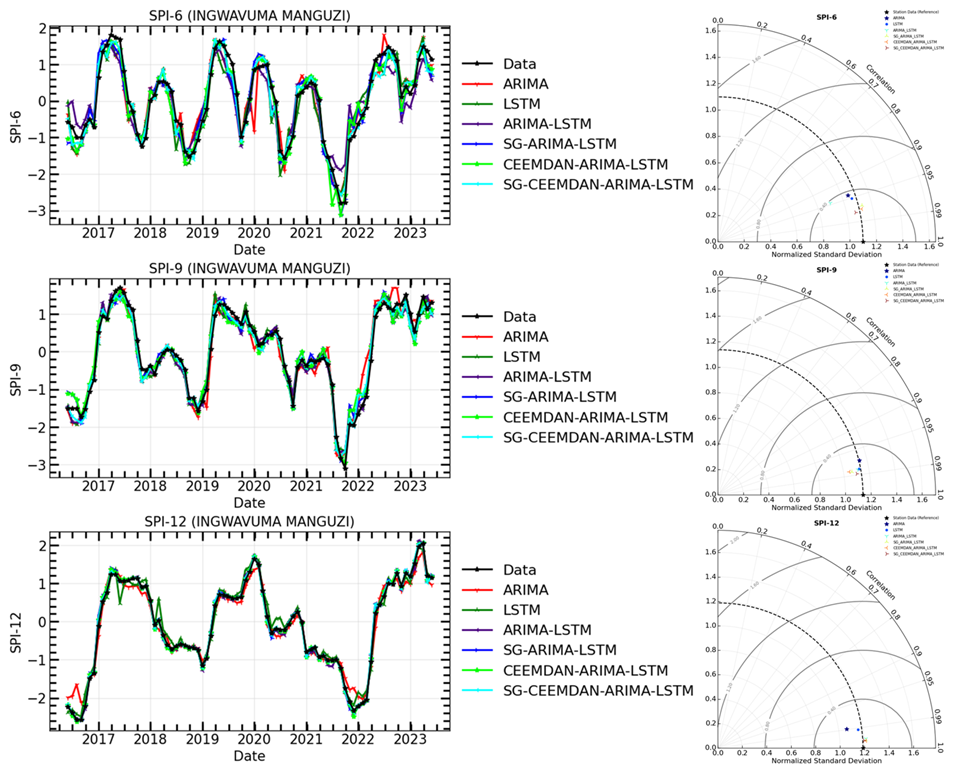
Figure 13The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of Ingwavuma Manguzi meteorological station.
Table 2 presents the results of the Mann-Kendall (MK) and Modified Mann-Kendall (MMK) trend tests for the Standardized Precipitation Index (SPI) over 6-month (SPI-6), 9-month (SPI-9), and 12-month (SPI-12) periods. The results indicate that across five stations all time scales both MK and MMK methods showed significant decreasing trend with negative Z-score values. For example, False Bay Park, Z_MK are , , and Z_MMK are , , . The p-values of MK and MMK show the significance of the trends, with values way below 0.05 confirming statistically significant trends. In all cases except Riverview, the p-values are extremely low (≪0.05), indicating strong evidence of significant decreasing trends in precipitation for all SPI periods. Both the MK and MMK tests confirm decreasing trends across all time scales, with the Z_MK and Z_MMK values becoming more negative as the SPI period increases, reflecting an intensifying downward trend over longer periods (from SPI-6 to SPI-12). For Riverview station, the results indicate an increasing trend with positive Z-score values, i.e. Z_MK are ZSPI-6=2.85, ZSPI-9=3.84, ZSPI-12=4.59 and Z_MMK are ZSPI-6=1.19, ZSPI-9=2.16, ZSPI-12=2.29. In general, all these results are consistent with those shown using the ITA (see Table 3). The Riverview station experience increasing trend because it is located closer to the coast, hence it is influenced by a combination of geographic, oceanic and climatic factors. For an example, this station could be influenced by the Agulhas Current, which flows southwards along the east coast of South Africa, bringing warm, moist air from the Indian Ocean, and thus enhancing evaporation that brings constant availability of moisture in the atmosphere.
3.3 SPI Time Series Forecasting Results
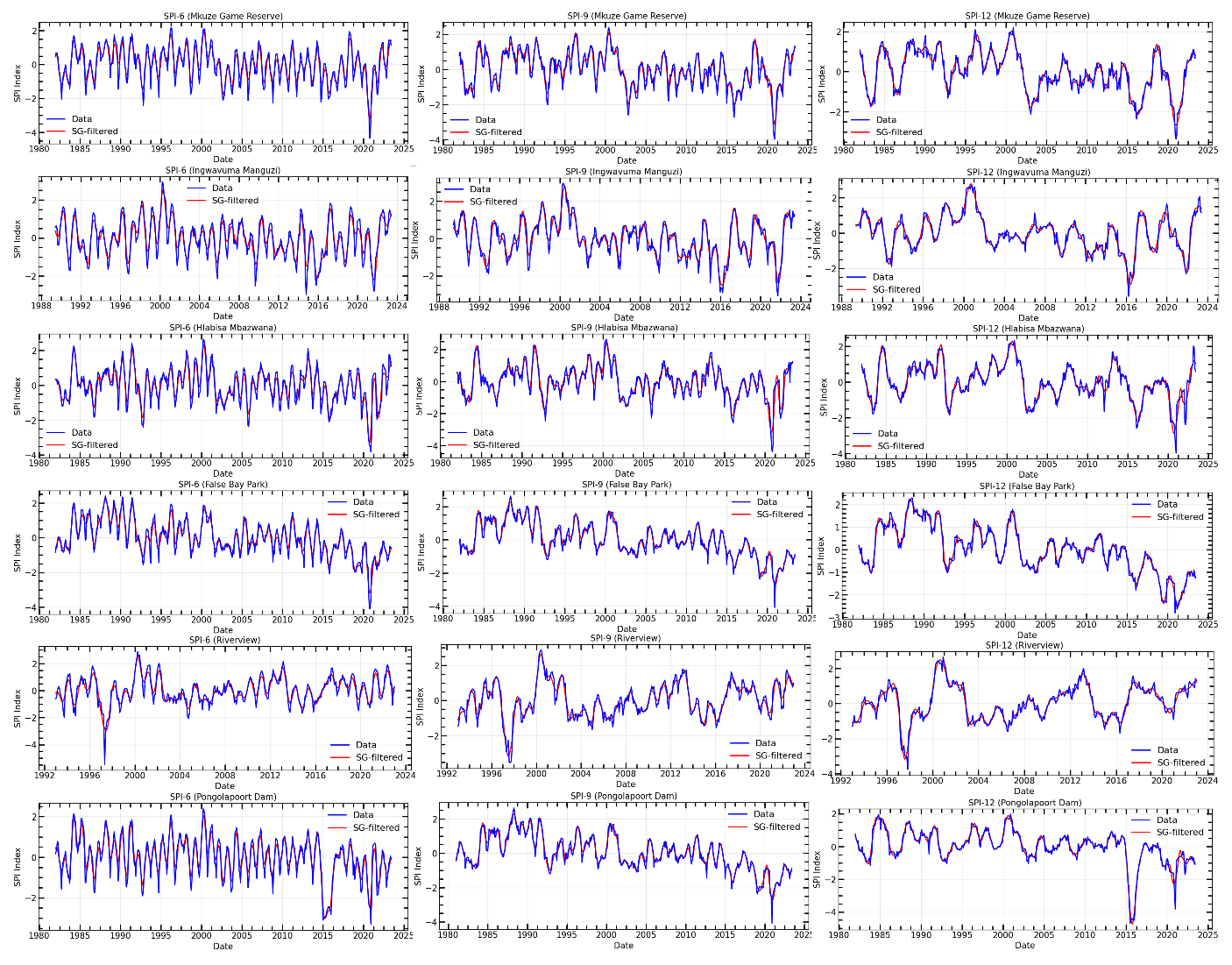
The study proposes a hybrid model that applies the Savitzky-Golay (SG) filter to process raw SPI data, thereby reducing noise and enhancing forecasting analysis. To demonstrate the effectiveness of the SG filter, appropriate parameters such as window size and polynomial order were selected through trial and error using data from the study sites (Sibiya et al., 2024). A window size of 21 and a polynomial order of 5 were chosen for smoothing. Figure 9 shows how the SG filter effectively tracks the general trend while preserving the shape of peaks and minimizing noise. This filter was applied to different time scales of the SPI time series. It autonomously calibrates according to peak distribution, exhibiting optimal performance, particularly with asymmetric peaks, while preserving peak height integrity. The application of the SG filter effectively mitigates short-term fluctuations and eliminates noise from the time series, resulting in cleaner data, thereby enhancing the reliability of the subsequent decomposition process. By reducing noise, decomposition techniques can more accurately capture the authentic underlying patterns and components within the data.
After applying a Savitzky-Golay filter to the series, the CEEMDAN algorithm decomposes the filtered SPI series into six subseries with different amplitudes and frequencies. The results from the False Bay Park station are utilized here as an illustration to prevent repetition. In these results, the decomposed set of time series consists of five IMF components and a residual component, as shown in Fig. 10 (for all time scales). During the decomposition process, white Gaussian noise is added to create noisy signals. The original sequence exhibits high nonlinearity and nonstationarity, with the frequency of the IMF components gradually decreasing. Figure 10 depicts this gradual decrease in frequency as the order of the IMF components increases. As each IMF is further decomposed, it becomes less volatile and cyclical, which aligns with the characteristics of the decomposed IMF. Therefore, by predicting each IMF and the residual, the forecast precision can be enhanced. A forecasting model is then constructed for each component, and the prediction results are obtained by summing up the outputs of all predicted components.
In predictive modeling, this study employed Bayesian optimization for hyperparameter tuning because of its effectiveness in improving model performance for complex, black-box, and non-differentiable functions. The hyperparameter configuration space comprises an n-dimensional functional space that encompasses all possible combinations of hyperparameters for the specified model. The benchmark analysis began with the ARIMA model, using the Box–Jenkins methodology. This process started with an assessment of stationarity through the augmented Dickey–Fuller (ADF) test. The series showed p-values exceeding the 5 % significance threshold, indicating non-stationarity (see Table 4). As a result, differencing was applied to achieve stationarity. This study employed a stepwise approach using the auto_arima( ) function within the ARIMA framework to identify the optimal parameters (see Table 5). Table 6 delineates the hyperparameter search space employed for tuning the LSTM model utilizing a Bayesian optimization approach. Each hyperparameter is presented alongside its respective range or selected value, which delineates the parameters within which the Bayesian search investigated optimal configurations.
Table 5Accuracy criteria for different model parameters of the ARIMA model applied in SPI-6, SPI-9 and SPI-12 at different meteorological stations of uMkhanyakude district.
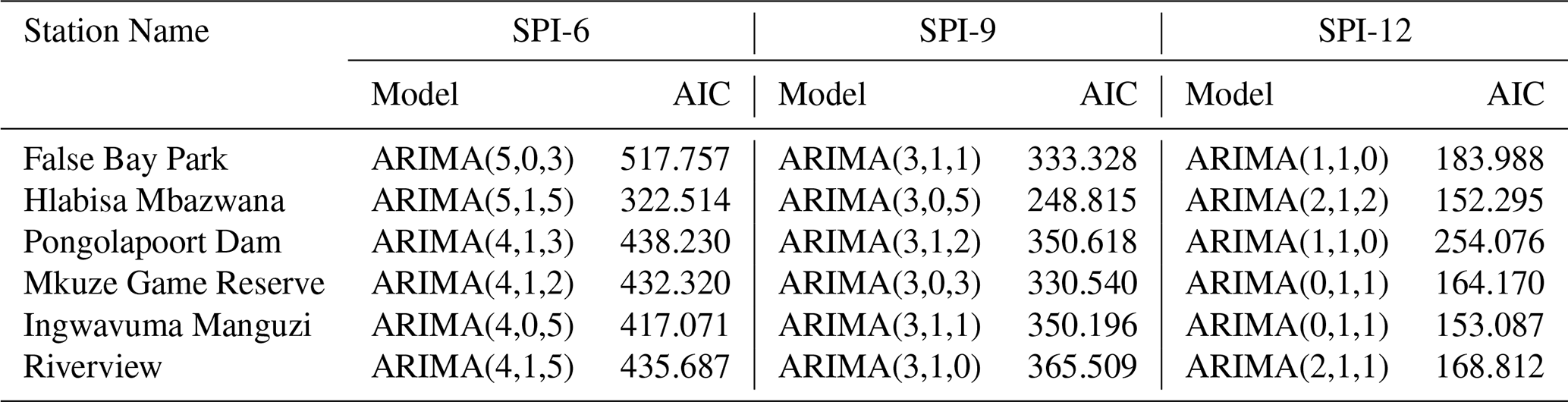
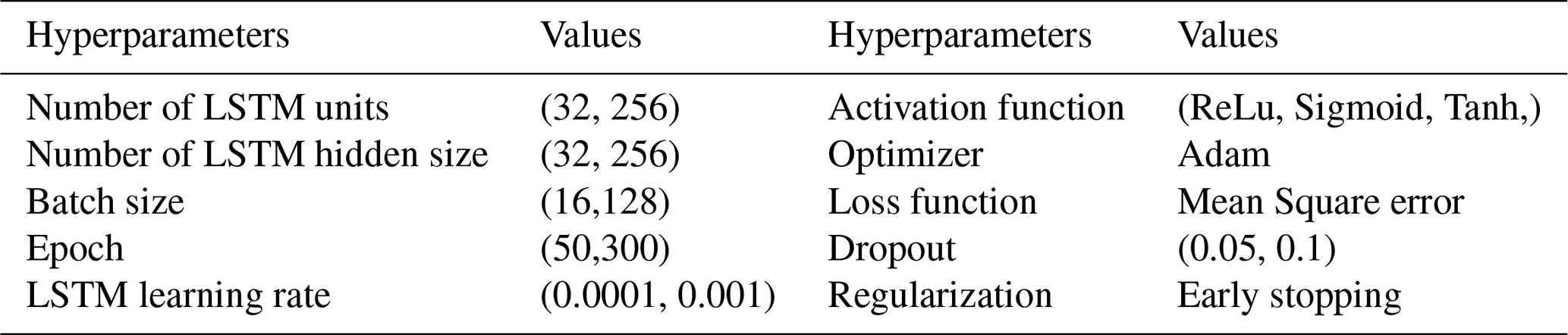
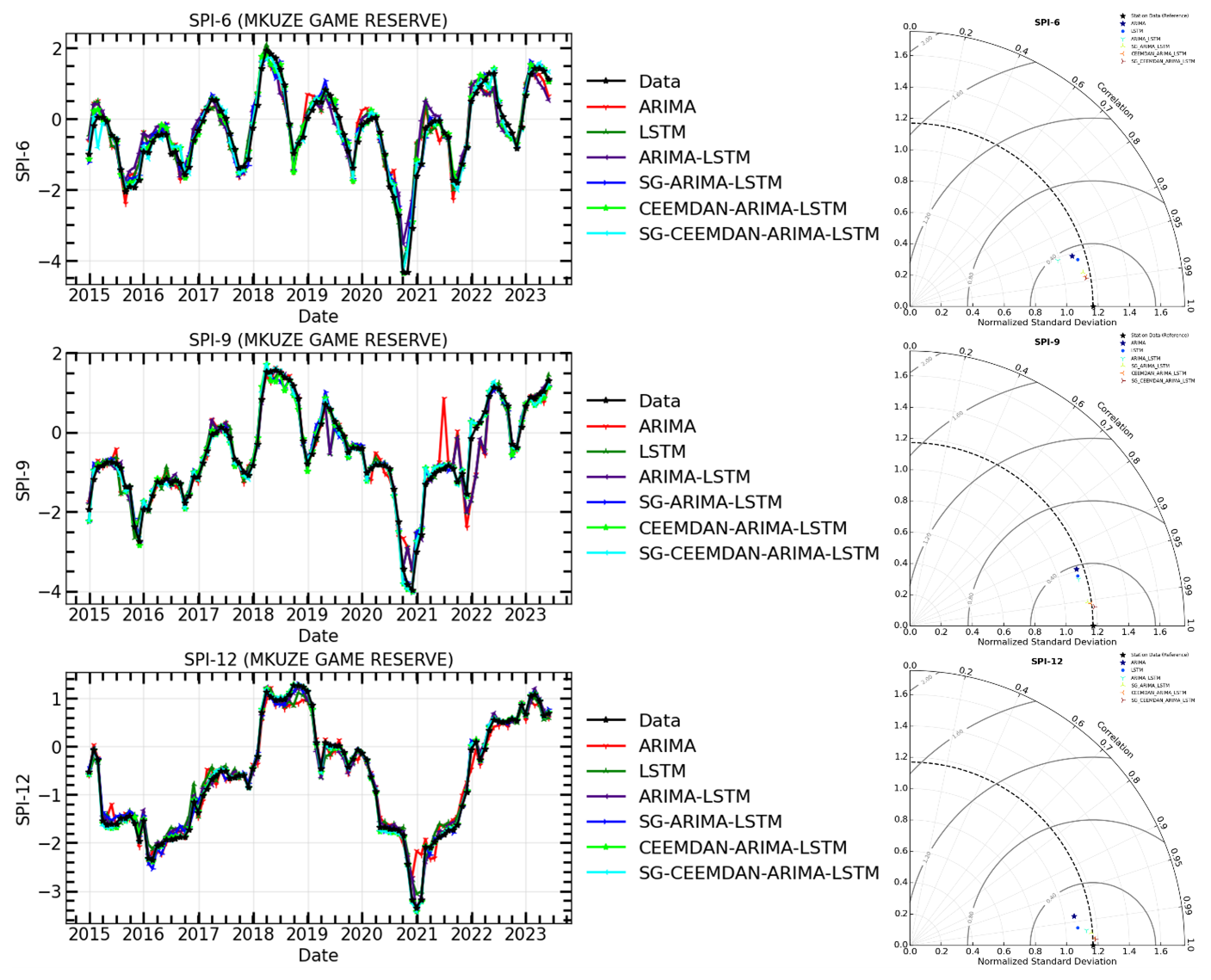
Figure 14The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of Mkuze Game Reserve meteorological station.
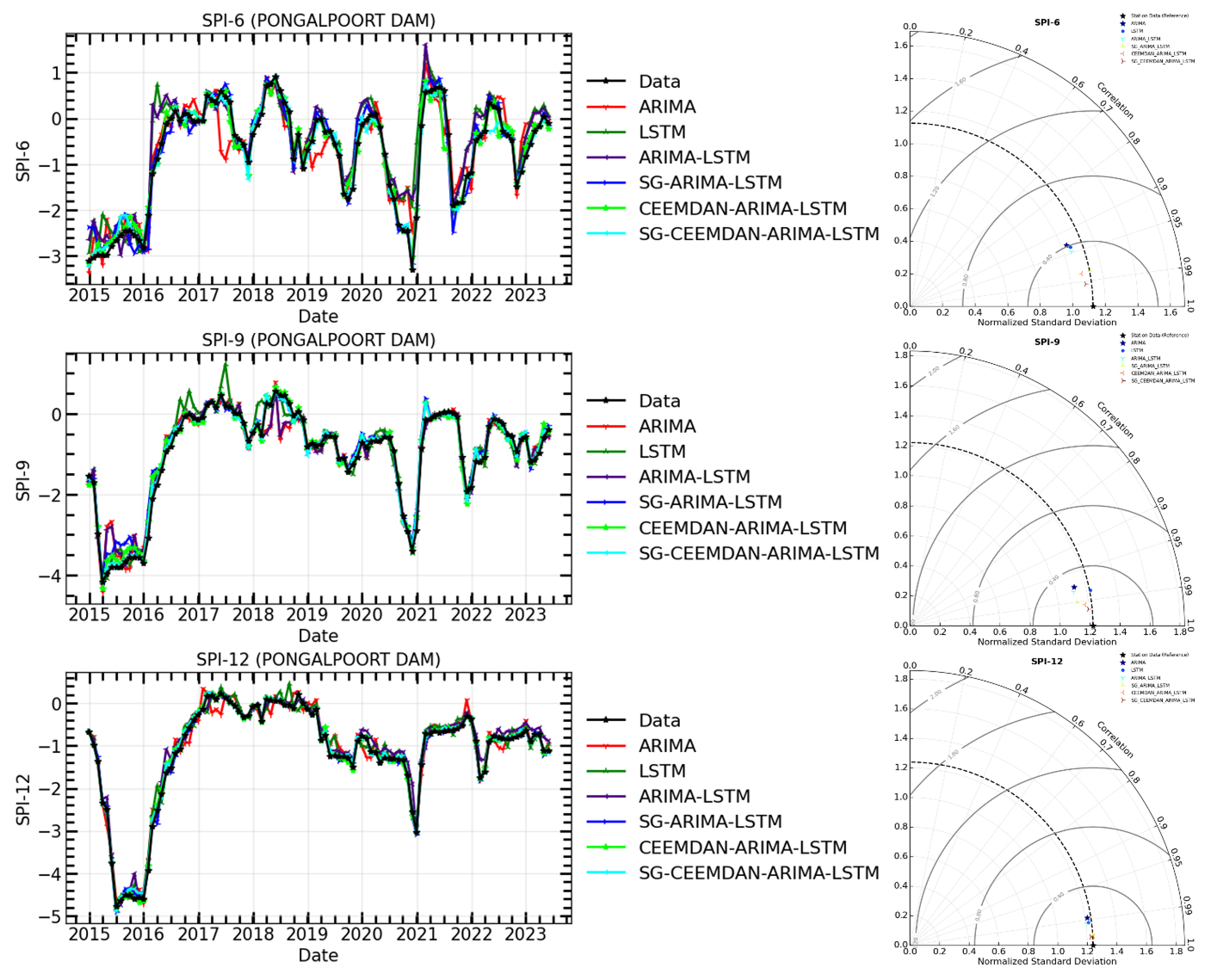
Figure 15The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of Pongolapoort dam meteorological station.
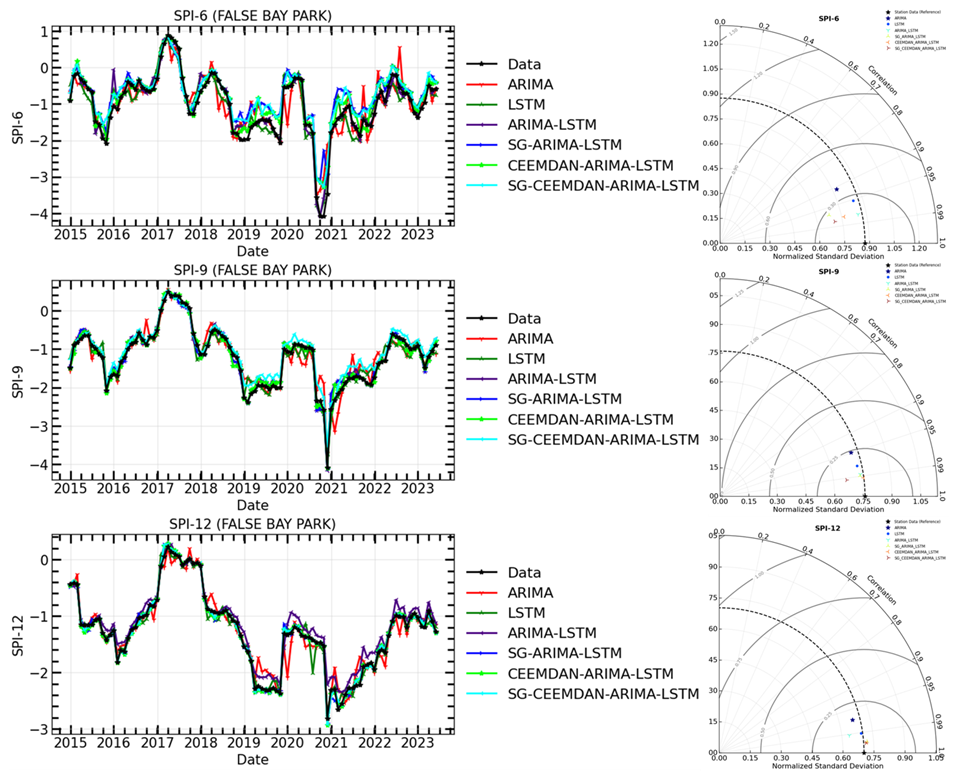
Figure 16The time series of observations and hybrid forecasting models for SPI prediction (Left) and their Taylor diagram plots at different timescales (Right) for SPI-6, SPI-9, and SPI-12 of False Bay Park meteorological station.
The models in Table 7 were compared for their prediction ability before and after time series decomposition in this research. The objective was to determine if smoothing and decomposing time series improve the model's prediction performance. Figures 11–16 show a comparison of the various models' prediction outcomes using the Taylor diagram. In general, all the models accurately replicate the original SPI time series at all timescales (refer to Figs. 11–16) in terms of the time series plot. However, the SG-CEEMDAN-ARIMA-LSTM model (shown in red) appears to have the closest fit to the data, displaying superior accuracy across different phases, particularly in extreme values. Nonetheless, the hybrid models (SG-ARIMA-LSTM, CEEMDAN-ARIMA-LSTM, and SG-CEEMDAN-ARIMA-LSTM) show better precision in capturing peaks, rapid transitions and troughs compared to the standalone LSTM or ARIMA models. Table 7 displays an assessment of the predictive performance metrics of several models utilising RMSE, R2, and DS. As the period extends, the RMSE values decrease; however, the DS and cap R-squared values typically enhance (see Table 7). This indicates that the models' predictive accuracy progressively enhances with an extended duration, reaching its highest point at the 12-month interval. In terms of RMSE, the SG-CEEMDAN-ARIMA-LSTM model outperforms the others, exhibiting the lowest error values across all indices. For example, Riverview station, 0.2165 for SPI-6, 0.0921 for SPI-9, and 0.0566 for SPI-12. This indicates that this model has the smallest prediction error, making it the most accurate in terms of error reduction. Concerning R2, which measures how well the model explains the variance in the data, SG-CEEMDAN-ARIMA-LSTM again leads with the highest values: 0.9602 for SPI-6, 0.9846 for SPI-9, and 0.9939 for SPI-12. This shows that the model provides the best fit to the data. The CEEMDAN-ARIMA-LSTM model is the second-best performer, also exhibiting impressive results, particularly in R2, where it achieves higher values of 0.9483 for SPI-6, 0.9751 for SPI-9, and 0.9933 for SPI-12. The SG-ARIMA-LSTM model is the third-best hybrid performer, with RMSE values of 0.2262 for SPI-6, 0.1051 for SPI-9, and 0.05639 for SPI-12. The SG-ARIMA-LSTM model is the third-best performer, also exhibiting impressive results, particularly in R2, where it achieves higher values of 0.9392 for SPI-6, 0.9763 for SPI-9, and 0.9904 for SPI-12. The SG-ARIMA-LSTM model is the third-best hybrid performer, with RMSE values of 0.2597 for SPI-6, 0.1157 for SPI-9, and 0.0567 for SPI-12. In general, these results highlight the efficacy of hybrid models, particularly those incorporating SG and CEEMDAN processes, in improving predictive accuracy across multiple timescales of SPI, particularly for the SG-CEEMDAN-ARIMA-LSTM model. These results are consistent with the Taylor diagram (see Figs. 11–16), which indicates a significant improvement in prediction accuracy after incorporating the SG and CEEMDAN signal decomposition technique as the hybrid model exhibits superior performance in terms of prediction accuracy across all timescales, surpassing other models. This suggests that the inclusion of these techniques enhances the models' ability to capture both short-term and long-term dependencies, thus making them more robust for drought prediction purposes. Therefore, this hybrid model appears to be the most effective for drought prediction in this analysis. These findings highlight the superiority of the proposed hybrid model in enhancing drought prediction accuracy compared to standalone approaches.
Table 7Performance measures for the comparison of observed and forecasted data of the models for SPI-6, SPI-9 and SPI-12 across various lead times using statistical criteria.
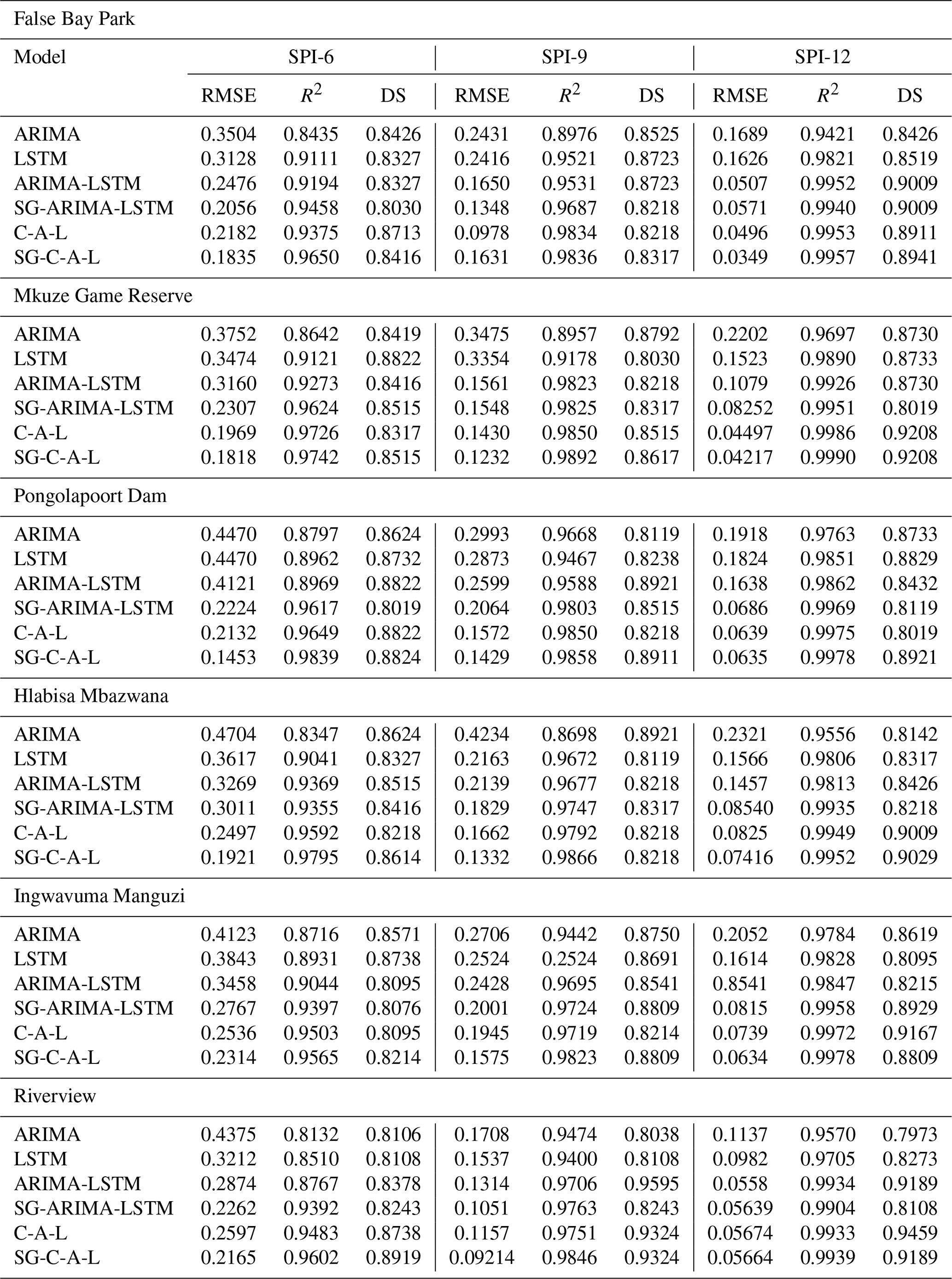
Note: C-A-L = CEEMDAN-ARIMA-LSTM.
In this study, we utilized the Mann-Kendall and Modified Mann-Kendall tests to determine the drought trend index in meteorological variables within the basin. The MK and MMK trend methods showed a significant decrease in all SPI time scales based on rainfall data from five stations; however, the district, except for the Riverview station, showed an increasing trend in the uMkhanyakude district. The study's findings align with prior research by Kganvago et al. (2021) and Ngwenya et al. (2024). Ngwenya et al. (2024) conducted a study using the Mann-Kendall test to assess the SPI values at a 5 % significance level, revealing sustained drought conditions in the Western Cape region. Kganvago et al. (2021) indicated a notable decline in drought conditions in the Western Cape area of South Africa. We have also employed the ITA, which enhances the MK and MMK tests in identifying trends, and the results underscore the importance of comprehending drought conditions. The findings of our analysis validate previous research by Naik and Abiodun (2020), highlighting the need to conduct trend studies on drought indicators to investigate the impacts of climate change. The study highlights the crucial role of SPI as a primary variable in monitoring and forecasting droughts in the region, and its potential to mitigate the adverse impacts of droughts and water scarcity in the uMkhanyakude district in the future. The objective was to determine if the model's predictive performance is enhanced by smoothing and deconstructing time series data.
According to the statistical metrics in Table 7 and the Taylor diagram (see Figs. 11–16), the effectiveness of hybrid models that incorporate filter and signal decomposition techniques (SG and CEEMDAN) in improving prediction accuracy, particularly for drought forecasting, is highlighted. These findings support other research (Taylan et al., 2021; Elbeltagi et al., 2023; Rezaiy and Shabri, 2024), which highlights the superior accuracy of hybrid drought forecasting models compared to individual models. For example, Taylan et al. (2021) developed a hybrid model to forecast drought using precipitation data from Çanakkale, Gökçeada, and Bozcaada stations between 1975 and 2010. The study found that the hybrid models, which incorporated preprocessing techniques, performed better. Elbeltagi et al. (2023) utilized a hybrid model to estimate the SPI for 3, 6, and 12-month drought periods from 2000 to 2019. The findings demonstrated that RSS-M5P model yielded the most precise SPI predictions, with MAE =0.497, RMSE =0.682, RAE =81.88, RRSE =87.22, and R2=0.507 for SPI-3; MAE =0.452, RMSE =0.717, RAE =69.76, RRSE =85.24, and R2=0.402 for SPI-6 and MAE =0.294, RMSE =0.377, RAE = 55.79, RRSE =59.57, and R2=0.783 for SPI-12. The models employed to analyse drought in Jaisalmer, Rajasthan, yielded the most effective results, exceeding those of RSS-RF and RSS-RT. Additionally, Rezaiy and Shabri (2024b) introduced a W-EEMD-ARIMA model for drought prediction. This model utilises monthly precipitation data from Kabul spanning 1970 to 2019. The R2 value was 0.9946, the MAPE was 18.9674, the RMSE was 0.0736, the MAE was 0.0575, and the SPI-12 validation indicated that our model was accurate. The outcomes obtained here surpassed those of the ARIMA, Wavelet-ARIMA, and EEMD-ARIMA models in terms of raw data (RMSE: 0.0858, MAE: 0.0660, MAPE: 24.5411, R2: 0.9925), analytical method (MAE: 0.1874, MAPE: 60.0220, R2: 0.9361), and maximum likelihood estimation (RMSE: 0.1002, MAE: 0.0691, MAPE: 23.7122, R2: 0.9898). During the SPI-3, SPI-6, and SPI-9 periods, our hybrid model consistently outperformed other models. Our proposed hybrid model surpasses ARIMA, Wavelet-ARIMA, and EEMD-ARIMA in enhancing the precision of drought predictions, as evidenced by this data.
In terms of term forecasting accuracy, the hybrid models, particularly SG-CEEMDAN-ARIMA-LSTM, consistently outperformed all other models across all SPI timescales, according to a comparison of this study's results with previous research. All models successfully reproduced the original SPI time series. With the range values of RMSE of 0.1453–0.2314 for SPI-6, 0.0921–0.1631 for SPI-9, and 0.0349–0.07416 for SPI-12, and the highest R2 values of 0.9565–0.9839 for SPI-6, 0.9836–0.9892 for SPI-9, and 0.9939–0.9990 for SPI-12 across all timescales, the SG-CEEMDAN-ARIMA-LSTM model showed the most proficiency in capturing extreme values and rapid transitions. That these methods, when combined, improve the models' capacity to represent drought in the uMkhanyakude district, both in the short and long term, is supported by the data. This makes the models far better at foretelling when droughts will occur. In light of the foregoing, our study provides useful information regarding the use of the hybrid SG-CEEMDAN-ARIMA-LSTM model to the forecasting of meteorological droughts.
This study examined the trends in the Standardised Precipitation Index (SPI) over different timescales (SPI-6, SPI-9, and SPI-12) utilising the Mann-Kendall (MK), modified Mann-Kendall (MMK) test, and the innovative trend analysis (ITA) protocol. The monthly rainfall data from the uMkhanyakude district, South Africa, covering the years 1980 to 2023, was used for these calculations. Rainfall has been trending downward at a 95 % confidence level, according to the MK and MMK tests. The ITA results supported these findings as well, revealing a declining trend with most of the data points going below the 1:1 line. To predict SPI data over various timescales, this research employed LSTM and autoregressive integrated moving average (ARIMA) models. Researchers used a hybrid model that combines the SG-CEEMDAN processing method with the ARIMA-LSTM model to enhance the precision of SPI forecasts. They also used SG filtering and full ensemble empirical mode decomposition with adaptive noise (CEEMDAN). Figures 11–16 and Table 4 display the results of a thorough comparison examination of the forecast outcomes. The results revealed that the inclusion of preprocessing techniques (SG filtering, CEEMDAN, and SG-CEEMDAN) significantly improved the model performance in forecasting SPI at all timescales. The performance consistently increased with higher timescales, potentially due to lower noise levels. Across different timescales, the SG and CEEMDAN combined hybrid model consistently outperformed the individual models. Notably, the CEEMDAN-ARIMA-LSTM model outperformed the SG-ARIMA-LSTM model at all timescales, while the SG-CEEMDAN-ARIMA-LSTM model consistently exhibited the lowest root mean square error (RMSE) values across all indices. These results demonstrate that combining SG-CEEMDAN with ARIMA-LSTM has the potential to significantly enhance the accuracy of meteorological drought forecasting. The principal conclusion of the study is that ARIMA-LSTM, in conjunction with SG, CEEMDAN, and SG-CEEMDAN, serves as an effective instrument for early warning systems and meteorological drought prediction. The proposed methodology in this paper serves as a framework for modeling complex meteorological phenomena such as drought, which is particularly pertinent in semi-arid regions. Enhancing model performance and creating efficient models for weather forecasting can be achieved through techniques that address data noise, nonlinearity, and nonstationarity. To enhance water resource management, make informed decisions regarding agricultural output and tourism management, and establish regulations, it is essential to acquire extremely effective models for drought prediction. The omission of exogenous environmental variables in the SG-CEEMDAN-ARIMA-LSTM model represents a significant drawback of the study. The model's forecast accuracy and real-world application are limited by disregarding these exogenous effects, which can substantially affect drought conditions. Future studies should aim to include external variables, including temperature, soil moisture, vegetation indices, and anthropogenic factors such as land use and water management, to improve the model's efficacy. This integration would provide a more thorough comprehension of drought dynamics, hence improving the model's accuracy and dependability in drought predictions. Additionally, it is essential to investigate alternate decomposition methods, such as enhanced CEEMDAN (iCEEMDAN), which may provide significant insights.
The dataset and python codes used in this study can be provided upon request to the corresponding author.
Supervision: SR, SM, NM; writing – original draft: SS, NM; writing – review & editing: SR, SM; data acquisition: SS, NM. All authors have read and agreed to the published version of the paper.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. The authors bear the ultimate responsibility for providing appropriate place names. Views expressed in the text are those of the authors and do not necessarily reflect the views of the publisher.
This paper was edited by Leonard K. Amekudzi and reviewed by three anonymous referees.
Alashan, S.: An improved version of innovative trend analyses, Arab. J. Geosci., 11, 50, https://doi.org/10.1007/s12517-018-3393-x, 2018.
Alashan, S.: Combination of modified Mann-Kendall method and Şen innovative trend analysis, Eng. Rep., 2, e12131, https://doi.org/10.1002/eng2.12131, 2020.
Alquraish, M., Abuhasel, K. A., Alqahtani, S. A., and Khadr, M.: SPI-based hybrid hidden Markov–GA, ARIMA–GA, and ARIMA–GA–ANN models for meteorological drought forecasting, Sustainability, 13, 12576, https://doi.org/10.3390/su132212576, 2021.
Ashraf, M. S., Shahid, M., Waseem, M., Azam, M., and Rahman, K. U.: Assessment of variability in hydrological droughts using the improved innovative trend analysis method, Sustain., 15, 9065, https://doi.org/10.3390/su15119065, 2023.
Bagmar, M. S. H. and Khudri, M. M.: Application of box-jenkins models for forecasting drought in north-western part of Bangladesh, Environmental Engineering Research, 26, https://doi.org/10.4491/eer.2020.294, 2021.
Balti, H., Abbes, A. B., Mellouli, N., Farah, I. R., Sang, Y., and Lamolle, M.: A review of drought monitoring with big data: Issues, methods, challenges, and research directions, Ecological Informatics, 60, 101136, https://doi.org/10.1016/j.ecoinf.2020.101136, 2020.
Bard, A., Renard, B., Lang, M., Giuntoli, I., Korck, J., Koboltschnig, G., Janža, M., d’Amico, M., and Volken, D.: Trends in the hydrologic regime of Alpine rivers, J. Hydrol., 529, 1823–1837, https://doi.org/10.1016/j.jhydrol.2015.08.052, 2015.
Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M.: Time series analysis: forecasting and control, 5th Edn., John Wiley & Sons, Hoboken, NJ, https://doi.org/10.1111/jtsa.12194, 2015.
Bukhosini, Z. and Moyo, I.: An analysis of the challenges faced by small-scale farmers and their response to the 2014–2016 drought in Mfekayi, Mtubatuba, KZN, South Africa, Afr. J. Dev. Stud., 13, 1, 2023.
Caloiero, T., Coscarelli, R., Ferrari, E., and Mancini, M.: Trend detection of annual and seasonal rainfall in Calabria (Southern Italy), Int. J. Climatol., 31, 44–56, https://doi.org/10.1002/joc.2054, 2011.
Ding, Y., Yu, G., Tian, R., and Sun, Y.: Application of a hybrid CEEMD-LSTM model based on the standardized precipitation index for drought forecasting: the case of the Xinjiang Uygur Autonomous Region, China, Atmosphere, 13, 1504, https://doi.org/10.3390/atmos13091504, 2022.
Elbeltagi, A., Kumar, M., Kushwaha, N. L., Pande, C. B., Ditthakit, P., Vishwakarma, D. K., and Subeesh, A.: Drought indicator analysis and forecasting using data driven models: case study in Jaisalmer, India, Stoch. Environ. Res. Risk Assess., 37, 113–131, https://doi.org/10.1007/s00477-022-02277-0, 2023.
Gudko, V., Tanwar, S., Minkina, T., Sushkova, S., Usatov, A., Azarin, K., Safronenkova, I., Melnik, Y., Voloshchuk, V., Gülser, C., and Kızılkaya, R.: Analysis of drought dynamics using SPI and SARIMA models: A case study of the Rostov Region, Russia, Eurasian Journal of Soil Science 14, 208–218, https://doi.org/10.18393/ejss.1682888, 2025.
Hamed, K. H. and Rao, A. R.: A modified Mann-Kendall trend test for autocorrelated data, J. Hydrol., 204, 182–196, https://doi.org/10.1016/S0022-1694(97)00125-X, 1998.
Harka, A. E., Jilo, N. B., and Behulu, F.: Spatial-temporal rainfall trend and variability assessment in the Upper Wabe Shebelle River Basin, Ethiopia: Application of innovative trend analysis method, J. Hydrol. Reg. Stud., 37, 100915, https://doi.org/10.1016/j.ejrh.2021.100915, 2021.
Helsel, D. R. and Hirsch, R. M.: Statistical methods in water resources, Elsevier, Amsterdam, https://doi.org/10.3133/tm4A3, 1993.
Hırca, T., Eryılmaz Türkkan, G., and Niazkar, M.: Applications of innovative polygonal trend analyses to precipitation series of Eastern Black Sea Basin, Turkey, Theor. Appl. Climatol., 147, 651–667, https://doi.org/10.1007/s00704-021-03837-0, 2022.
Hochreiter, S. and Schmidhuber, J.: Long short-term memory, Neural Comput., 9, 1735–1780, https://doi.org/10.1162/neco.1997.9.8.1735, 1997.
Hussain, A., Rizwan, N., Al-Rezami, A. Y., Adam M. O., Fuad S. A., and Mohammed M. A. A.: Application of random forest for identification of an appropriate model for predicting meteorological drought, Advances in Meteorology, 2025, 7674140, https://doi.org/10.1155/adme/7674140, 2025.
Kalisa, W., Zhang, J., Igbawua, T., Kayiranga, A., Ujoh, F., Aondoakaa, I. S., and Nibagwire, D.: Spatial multi-criterion decision making (SMDM) drought assessment and sustainability over East Africa from 1982 to 2015, Remote Sensing, 13, 5067, https://doi.org/10.3390/rs13245067, 2021.
Kendall, M.: Rank Correlation Methods, Griffin, London, https://www.cabidigitallibrary.org/doi/full/10.5555/19521603271, 1975.
Kganvago, M., Mukhawana, M. B., Mashalane, M., Mgabisa, A., and Moloele, S.: Recent trends of drought using remotely sensed and in-situ indices: Towards an integrated drought monitoring system for South Africa, in: 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, 6225–6228, https://doi.org/10.1109/IGARSS47720.2021.9553994, 2021.
Latifoğlu, L. and Özger, M.: A novel approach for high-performance estimation of SPI data in drought prediction, Sustainability, 15, 14046, https://doi.org/10.3390/su151914046, 2023.
Likinaw, A., Alemayehu, A., and Bewket, W.: Trends in extreme precipitation indices in Northwest Ethiopia: Comparative analysis using the Mann–Kendall and innovative trend analysis methods, Climate, 11, 164, https://doi.org/10.3390/cli11080164, 2023.
Lloyd-Hughes, B. and Saunders, M. A.: A drought climatology for Europe, Int. J. Climatol., 22, 1571–1592, https://doi.org/10.1002/joc.846, 2002.
Ma, X., He, Y., Xu, J., van Noordwijk, M., and Lu, X.: Spatial and temporal variation in rainfall erosivity in a Himalayan watershed, Catena, 121, 248–259, https://doi.org/10.1016/j.catena.2014.05.012, 2014.
Malik, A., Kumar, A., Rai, P., and Kuriqi, A.: Prediction of multi-scalar standardized precipitation index by using artificial intelligence and regression models, Climate 9, 28, https://doi.org/10.3390/cli9020028, 2021.
Mann, H. B.: Nonparametric tests against trend, Econometrica, 13, 245–259, https://doi.org/10.2307/1907187, 1945.
McKee, T. B., Doesken, N. J., and Kleist, J.: The relationship of drought frequency and duration to time scales, in: Proceedings of the 8th Conference on Applied Climatology, Anaheim, California, American Meteorological Society, 17, 179–183, 1993.
McKee, T. B., Doesken, N. J., and Kleist, J.: Drought monitoring with multiple time scales, in: Proceedings of the Conference on Applied Climatology, Boston, MA, USA, American Meteorological Society, 1995.
Mirabbasi, R., Ahmadi, F., and Jhajharia, D.: Comparison of parametric and non-parametric methods for trend identification in groundwater levels in Sirjan plain aquifer, Iran, Hydrol. Res., 51, 1455–1477, https://doi.org/10.2166/nh.2020.041, 2020.
Montgomery, D. C., Jennings, C. L., and Kulahci, M.: Introduction to time series analysis and forecasting, 2nd Edn., Wiley, Hoboken, NJ, 2015.
Naik, M. and Abiodun, B. J.: Projected changes in drought characteristics over the Western Cape, South Africa, Meteorological Applications, 27, e1802, https://doi.org/10.1002/met.1802, 2020.
Ngwenya, M., Gidey, E., and Simatele, M. D.: Agroecological-based modeling of meteorological drought at 12-month time scale in the Western Cape Province of South Africa, Earth Sci. Inform., 17, 1851–1865, https://doi.org/10.1007/s12145-023-01193-3, 2024.
Öztopal, A. and Şen, Z.: Innovative trend methodology applications to precipitation records in Turkey, Water Resour. Manag., 31, 727–737, https://doi.org/10.1007/s11269-016-1343-5, 2017.
Rezaiy, R. and Shabri, A.: An innovative hybrid W-EEMD-ARIMA model for drought forecasting using the standardized precipitation index, Nat. Hazards, https://doi.org/10.1007/s11069-024-06758-z, 2024b.
Savitzky, A. and Golay, M. J. E.: Smoothing and differentiation of data by simplified least squares procedures, Anal. Chem., 36, 1627–1639, https://doi.org/10.1021/ac60214a047, 1964.
Şen, Z.: Innovative trend analysis methodology, J. Hydrol. Eng., 17, 1042–1046, https://doi.org/10.1061/(ASCE)HE.1943-5584.0000556, 2012.
Şen, Z.: Innovative trend significance test and applications, Theor. Appl. Climatol., 127, 939–947, https://doi.org/10.1007/s00704-015-1681-x, 2017.
Sharifi, A., Baubekova, A., Patro, E. R., Klöve, B., and Haghighi, A. T.: The combined effects of anthropogenic and climate change on river flow alterations in the Southern Caspian Sea, Iran, Heliyon, 10, e18663, https://doi.org/10.1016/j.heliyon.2024.e31960, 2024.
Sibiya, S., Mbatha, N., Ramroop, S., Melesse, S., and Silwimba, F.: Forecasting of Standardized Precipitation Index Using Hybrid Models: A Case Study of Cape Town, South Africa, Water, 16, 2469, https://doi.org/10.3390/w16172469, 2024.
Song, Y. and Park, M.: A study on the appropriateness of the drought index estimation method using damage data from Gyeongsangnamdo, South Korea, Atmosphere, 12, 998, https://doi.org/10.3390/atmos12080998, 2021.
Tan, Y. X., Ng, J. L., and Huang, Y. F.: A review on drought index forecasting and their modelling approaches, Archives of Computational Methods in Engineering, 30, 1111–1129, https://doi.org/10.1007/s11831-022-09828-2, 2023.
Taylan, E. D.: An approach for future droughts in Northwest Türkiye: SPI and LSTM methods, Sustainability 16, 6905, https://doi.org/10.3390/su16166905, 2024.
Taylan, E. D., Özlem, T., and Baykal, T.: Hybrid wavelet-artificial intelligence models in meteorological drought estimation, Journal of Earth System Science 130, 38, https://doi.org/10.1007/s12040-020-01488-9, 2021.
Taylor, K. E.: Summarizing multiple aspects of model performance in a single diagram, J. Geophys. Res.-Atmos., 106, 7183–7192, https://doi.org/10.1029/2000JD900719, 2001.
Wang, X., Hou, X., and Wang, Y.: Spatiotemporal variations and regional differences of extreme precipitation events in the coastal area of China from 1961 to 2014, Atmos. Res., 197, 94–104, https://doi.org/10.1016/j.atmosres.2017.06.010, 2017.
Wilhite, D. A. and Glantz, M. H.: Understanding: the drought phenomenon: the role of definitions, Water International, 10, 111–120, https://doi.org/10.1080/02508068508686328, 1985.
Xu, D., Ding, Y., Liu, H., Zhang, Q., and Zhang, D.: Applicability of a CEEMD–ARIMA combined model for drought forecasting: a case study in the Ningxia Hui Autonomous Region, Atmosphere, 13, 1109, https://doi.org/10.3390/atmos13071109, 2022.
Yue, S., Pilon, P., Phinney, B., and Cavadias, G.: The influence of autocorrelation on the ability to detect trend in hydrological series, Hydrol. Process., 16, 1807–1829, https://doi.org/10.1002/hyp.1095, 2002.
Zena, B. K., Demissie, T. A., and Feyessa, F. F.: Comparative analysis of long-term precipitation trends and its implication in the Modjo catchment, central Ethiopia, J. Water Clim. Change, 13, 3883–3905, https://doi.org/10.2166/wcc.2022.234, 2022.
Zhang, G. P.: Time series forecasting using a hybrid ARIMA and neural network model, Neurocomputing, 50, 159–175, https://doi.org/10.1016/S0925-2312(01)00702-0, 2003.
Zhang, H., Loaiciga, H. A., and Sauter, T.: A novel fusion-based methodology for drought forecasting, Remote Sensing, 16, 828, https://doi.org/10.3390/rs16050828, 2024.
Zhang, X., Duan, Y., Duan, J., Chen, L., Jian, D., Lv, M., and Ma, Z.: A daily drought index-based regional drought forecasting using the Global Forecast System model outputs over China, Atmospheric Research, 273, 106166, https://doi.org/10.1016/j.atmosres.2022.106166, 2022.
Zhang, X., Qiao, W., Huang, J., Shi, J., and Zhang, M.: Flow prediction in the lower Yellow River based on CEEMDAN-BILSTM coupled model, Water Supply, 23, 396–409, https://doi.org/10.2166/ws.2022.215, 2023.
Zuo, D., Hou, W., Wu, H., Yan, P., and Zhang, Q.: Feasibility of calculating standardized precipitation index with short-term precipitation data in China, Atmosphere, 12, 603, https://doi.org/10.3390/atmos12050603, 2021.