the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 14 Apr 2025
| 14 Apr 2025
Brief communication: Visualizing uncertainties in landslide susceptibility modelling using bivariate mapping
Matthias Schlögl
Anita Graser
Raphael Spiekermann
Jasmin Lampert
Stefan Steger
Effectively communicating uncertainties inherent to statistical models is a challenging yet crucial aspect of the modelling process. This is particularly important in applied research, where output is used and interpreted by scientists and decision-makers alike. In disaster risk reduction, susceptibility maps for natural hazards are vital for spatial planning and risk assessment. We present a novel type of landslide susceptibility map that jointly visualizes the estimated susceptibility and the corresponding prediction uncertainty, using an example from a mountainous region in Carinthia, Austria. We also provide implementation guidelines to create such maps using popular free and open-source software packages.
- Article
(9643 KB) - Full-text XML
-
Supplement
(22811 KB) - BibTeX
- EndNote




In the context of disaster risk reduction, landslide risk assessment plays a pivotal role in identifying, assessing, understanding, managing, and mitigating the potential impacts of landslides on human lives, infrastructure, and the environment (Schlögl et al., 2019; Dai et al., 2002). Landslide susceptibility modelling comprises a set of computational approaches tailored towards the identification of areas exhibiting an increased likelihood of landslide occurrence (Guzzetti et al., 2006). In contrast to deterministic physical slope stability modelling, empirical statistical landslide susceptibility modelling usually employs methods of statistical learning applied in the context of a binary classification problem (Spiekermann et al., 2023). Statistically based landslide susceptibility models use documented landslides from inventories as target variables (training labels) and a number of predisposing factors such as terrain conditions, lithology, or land cover as independent variables. Having completed the model tuning, training, and prediction process, the estimated class probability of the positive class is referred to as landslide susceptibility (Reichenbach et al., 2018). Thus, areas with high probabilities exhibit similar characteristics to landslide locations in the past and are therefore assumed to be more susceptible to slope instability during future triggering events.
Despite the generally acknowledged utility of landslide susceptibility models in certain contexts, their impact is contingent on the input data quality (Loche et al., 2022; Lima et al., 2021; Gaidzik and Ramírez-Herrera, 2021; Steger et al., 2016a) and geomorphic plausibility of the results (Steger et al., 2021). Geomorphic plausibility evaluation aims to assess whether a landslide susceptibility map aligns with fundamental process knowledge or instead reflects errors stemming from input data or the modelling approach, as detailed in Steger et al. (2016b). On the other hand, overall usability of maps and interpretability of the underlying models are other aspects influencing the practical applicability. Thus, communicating complex scientific findings effectively is crucial for not only scientific advancement but also decision-making in policy and practice (Weigold, 2001).
In this context, a particularly crucial aspect of science communication is the uncertainty associated with scientific methods and findings (Schneider, 2016). Yet uncertainty evaluation is often underrated despite having potentially far-reaching implications for decision-makers needing to interpret the information on landslide susceptibility. Uncertainty is inherent to science, as it describes the quality and reliability of observations and models and, consequently, is also relevant to science communication (Gustafson and Rice, 2020). Effectively conveying uncertainty is essential for upholding trust in research and supporting successful user uptake of findings (Fischhoff and Davis, 2014). This is particularly the case in the context of numerical modelling of natural systems, where verification and validation is impossible and the primary value of models is heuristic (Oreskes et al., 1994).
In the area of landslide susceptibility modelling, different sources of uncertainty have been investigated. This includes, among other things, the error propagation of inventory-based positional errors (Steger et al., 2016a), the effects of different landslide boundaries and spatial shape expressions (Huang et al., 2022), the effect of spatial resolution (Huang et al., 2023), the number of non-landslides sampled (Hong et al., 2019), and the different resampling strategies (Moreno et al., 2023).
While quantification of model fit and model performance has become standard practice (Reichenbach et al., 2018), the vast majority of published landslide susceptibility maps do not spatially compute the uncertainty associated with the estimated susceptibility. As the uncertainty in landslide susceptibility predictions can be highly variable in space, it is imperative that decision-makers have access to spatial information describing the uncertainty. A small number of studies have used ensemble modelling as a means to quantify uncertainty, employing metrics for statistical dispersion to the ensemble predictions to quantify uncertainty. Rossi et al. (2010) suggested that the combination of landslide susceptibility zones based on multiple forecasts can improve the quality of susceptibility assessments. In their comparative model evaluation study, they provided maps of the geographical distribution of the model error across slope units. Petschko et al. (2014) provided a comprehensive analysis of model uncertainty based on the standard error in model prediction in their quality assessment of landslide susceptibility maps and also presented a spatial visualization of map uncertainty. Lombardo et al. (2014) accounted for the dispersion of the susceptibility estimates obtained by training a series of models using different partitioning strategies and reported the results in a model error map, using an interval of 2 standard deviations. Heckmann et al. (2014) used the inter-quantile range (between the 0.95 quantile and the 0.05 quantile) of 100 susceptibility maps derived via random resampling as a non-parametric measure of dispersion to quantify the uncertainty caused by sampling and stepwise model selection in their debris flow susceptibility modelling assessment. Peng et al. (2014) used a rough-set support vector machine model trained on five different random samples to obtain estimates of landslide susceptibility for all mapping units. They also used 2 standard deviations as the metric to quantify model uncertainty. Achu et al. (2023) employed an ensemble of different machine-learning models and visualized the uncertainty stemming from the model types using the coefficient of variation across the predicted probabilities of all ensemble members.
Against the backdrop of the diverse methodologies available to account for uncertainties, scientists face challenges in effectively communicating their results, while decision-makers struggle to interpret this complex information. Although the challenge of representing and managing geospatial information uncertainty is well understood in geoinformation science, particularly in cartography, this awareness is not as pervasive in other scientific disciplines and application areas, including geomorphology. Various methods for visualizing geospatial information uncertainty have been presented and discussed (Kinkeldey et al., 2014; MacEachren et al., 2005), including applications in slope stability modelling (Davis and Keller, 1997). All previously mentioned studies on landslide susceptibility modelling reported results by including separate maps for the estimated susceptibility and uncertainty. In this study, we visualize the uncertainty caused by the sampling of negative instances by showing the variability in the predictions contingent on sampling in space, utilizing an ensemble of random-forest models. We present a novel type of visualization of landslide susceptibility maps that jointly represents the susceptibility estimate along with the corresponding uncertainty. We advocate for bivariate mapping as a straightforward yet sound and effective way to communicate landslide susceptibility and the associated uncertainty. We provide implementation guidelines to create such maps using free and open-source software (FOSS), with examples in R and QGIS.
2.1 Landslide susceptibility modelling
The study region encompasses an area of 5785 km2 within the Central Eastern Alps in Carinthia, Austria. A total of 1973 shallow landslides were documented in the landslide inventory compiled for the study region. These events served as the target variable (i.e. training labels). A wide range of predisposing factors were considered independent variables, including indicators describing geomorphology, hydrology, climatology, lithology, land cover, surface runoff, and transportation infrastructure. A subset of 21 features was eventually distilled from the total set of 46 features initially identified as potentially relevant determinants of landslide occurrence after an iterative feature selection process. Feature selection was conducted based on two main considerations. First, highly correlated features were dropped to ease interpretability of feature effects. Second, features effectively representing potential inventory biases were removed.
We used a pixel-based approach at a spatial resolution of 10 m. Given the large study area and the comparatively small number of landslides, this resulted in an event rate of only 2.7 × 10−5. Therefore, we used random downsampling in the context of balanced bagging to counter the severe class imbalance present in the data set. Negative instances were randomly sampled using probability-proportional-to-size sampling. The no-sampling area was constrained to avoid sampling in trivial (e.g. lakes) and problematic (e.g. too close to existing slides, high-elevation regions such as glaciers exhibiting different process characteristics) areas. In order to obtain a balanced data set, the number of negative instances sampled was identical to the number of positive samples present in the data set. In order to quantify sampling uncertainty, we repeated the sampling process 10 times. Since all positive instances were kept in all iterations, the sampling variation stems entirely from the negative instances. There are more robust methods available that also account for variations in landslide presence data (Lima et al., 2023; Pourghasemi et al., 2020). The resulting 10 data sets served as the basis for the training of random-forest models using nested spatial resampling for model tuning and performance evaluation. Hyperparameter tuning was conducted using model-based optimization.
This procedure eventually resulted in an ensemble consisting of 10 models trained and evaluated by means of nested spatial cross-validation. Results of the single models were aggregated using the ensemble mean as an estimate of predicted susceptibility and the ensemble standard deviation to quantify the corresponding sampling uncertainty in the model. A more detailed description of the modelling approach as well as an in-depth discussion focusing on statistical performance and geomorphic plausibility is provided in Schlögl et al. (2025).
2.2 Visualization
2.2.1 Concept
The theory and applications of bivariate (choropleth) maps are well established (De Cola, 2002; Nelson, 1999; Trumbo, 1981), including applications in climatology (Teuling et al., 2011) and hydrology (Speich et al., 2015). A seminal and easily accessible introduction to bivariate choropleth maps was provided by Joshua Stevens in 2015 (Stevens, 2015). We build upon these considerations and apply the general principle to landslide susceptibility modelling, using the ensemble mean and the ensemble standard deviation of predicted probabilities as variables for the bivariate mapping of landslide susceptibility and corresponding uncertainty.
We utilize a classical 3 × 3 bivariate visualization, resulting in nine classes in total. The reclassification method employed to stratify the continuous outputs into classes depends on the feature.
-
Susceptibility (ensemble mean). Landslide susceptibility maps are commonly created using probabilistic binary classifiers, with the predicted outcomes naturally occurring on a continuous scale within the interval [0,1]. While discretizing continuous variables poses certain challenges, such as the loss of information and certain pitfalls caused by the artificial breakpoints, categorizing continuous outcomes can aid in conveying results to stakeholders. Inspired by the methodology of Spiekermann et al. (2023), we established two thresholds based on the descending rank order plot, utilizing the empirical 0.8 and 0.95 quantiles of the predicted landslide susceptibility values for positive instances to separate the three susceptibility categories. This effectively means that 80 % of the observed events fall into the highest class, 15 % of the events are contained in the medium class, and only 5 % of the events fall into the lowest class. This reclassification method was chosen due to its straightforward and intuitive interpretability. The thresholds resulting from the two selected quantiles are 0.4481 and 0.6096, respectively.
-
Uncertainty (ensemble standard deviation). Given the skewness of the standard deviation, we used quantile-based reclassification to split the continuous variable into three classes. In the present case, this corresponds to the thresholds 0.0297 and 0.0416.
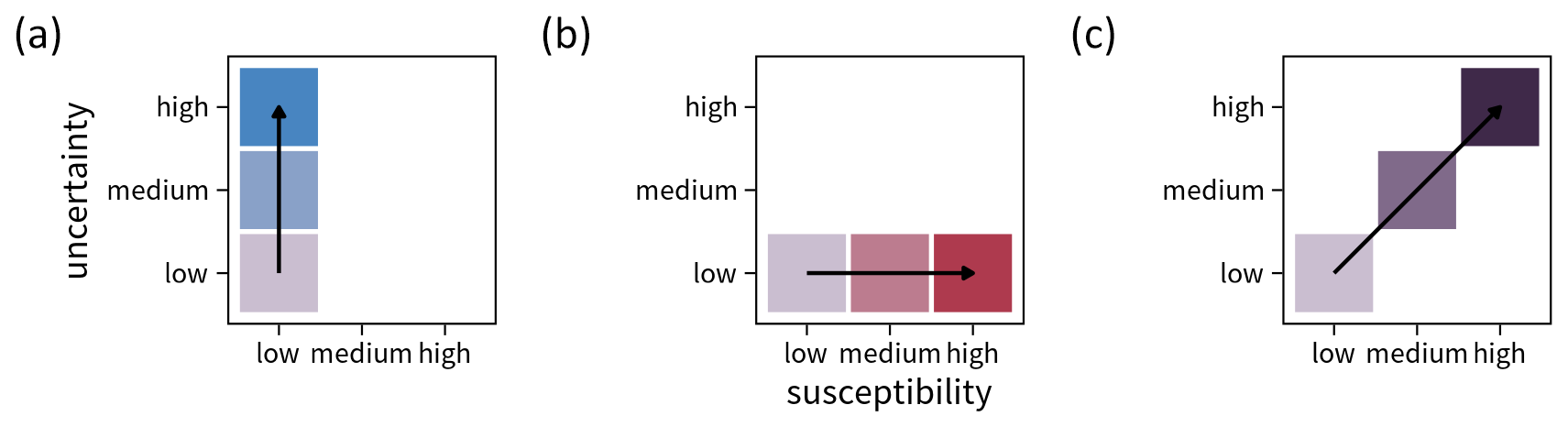
Figure 1Conceptual illustration of a bivariate legend in the context of landslide susceptibility mapping. Panel (a) shows the univariate colour scheme for the uncertainty mapped to the y axis, with uncertainty increasing from bottom to top. Panel (b) displays the univariate colour scheme for susceptibility along the x axis, with susceptibility increasing from left to right. In both cases, single-hue colour palettes are used, and higher values are characterized by higher saturation and value. Panel (c) depicts the combined bivariate result after blending the two individual colour palettes, with the diagonal showing joint increases in both variables.
The bivariate susceptibility maps are based on two sequential single-hue colour schemes, each increasing in saturation and value, with one scheme representing each variable. By blending these colour schemes, a bivariate colour palette emerges (Fig. 1).
We conducted stakeholder workshops using the world café method (Löhr et al., 2020), with selected expert users from our main target group. Seven representatives from national civil protection and disaster management organizations participated, including geologists from the Austrian National Geological Survey, geologists from Austrian federal governments, and representatives from disaster relief forces. They provided unstructured feedback on the use of the map in specific contexts and for specific applications, such as for spatial planning tasks. The world café sessions were held on 27 February 2024 in Vienna under the aegis of the Disaster Competence Network Austria. Informed consent procedures were followed to ensure that stakeholders participated willingly and were adequately informed about the research. All statements were collected and summarized under the preservation of anonymity.
2.2.2 Implementation
There are several tools that support the practical implementation of the concept of bivariate susceptibility mapping. Here we exemplarily illustrate the implementation using two open-source tools representing one programming approach and one desktop GIS approach.
Bivariate susceptibility maps can be created programmatically in R using commonly used packages for managing geodata, as well as the ggplot2 plotting framework. The package biscale provides convenience functions for reclassifying data into the desired number of classes and creating bivariate legends. It also offers a predefined set of bivariate colour palettes. Technical details are provided in Appendix A, and all code is available in the GitHub repository in the Supplement.
Bivariate susceptibility maps can also be created using a classical desktop geographic information system (GIS). In QGIS, there are two main kinds of approaches to generating bivariate maps from rasters: (1) combining two raster layers with blending modes (such as multiply) to generate the bivariate effect or (2) reclassifying the raster into the desired number of classes using raster algebra. The bivariate polygon renderer plugin can be used to create the legend in the print layout of the map. Technical details are provided in Appendix B, and a QGIS project is available in the GitHub repository in the Supplement.
Figure 2Example of a bivariate susceptibility map and its univariate components. Panel (a) shows the susceptibility, panel (b) uncertainty, and panel (c) the bivariate result using multiply blending. Lakes (transparency of 0 %) and high-elevation areas (transparency of 20 %) are masked out.
The bivariate visualization of landslide susceptibility and associated uncertainty is shown for a small area for demonstrative purposes (Fig. 2). The map shows an area of the Nockberge range of Carinthia. Lakes (most notably Brennsee in the west) and high-elevation areas (> 1900 m) around the Wöllaner Nock mountain (2145 m, east) are masked out since they are out of the scope of the model (Schlögl et al., 2025).
The legend of the bivariate map is grid-like, with the four corner cases signifying the most extreme combination of the two variables, susceptibility and uncertainty. The description and interpretation of the combined information hold irrespective of the number of classes used.
-
Lower-left corner – low susceptibility and low uncertainty. These areas exhibit low susceptibility with a high degree of confidence, with the model ensemble consistently indicating a low occurrence probability of shallow landslides. Thus, the occurrence of shallow landslides in these areas is unlikely. Yet, the predictions still need to be interpreted with care, given the limitations of the underlying data, including the landslide inventory used. Results should still be assessed in light of geomorphic plausibility of the results (Steger et al., 2016b), and the data basis as well as the modelling approach should be integrated in the assessment.
-
Lower-right corner – high susceptibility and low uncertainty. These areas are identified as highly susceptible to landslides with a high degree of confidence. This means that the data and model ensemble used to predict landslide susceptibility yield consistent and reliable results in these areas. Areas falling into this class could be candidates for prioritizing mitigation efforts, monitoring, and preventive measures.
-
Upper-left corner – low susceptibility and high uncertainty. This class represents areas that are identified as having low susceptibility to landslides, but the model prediction is associated with high uncertainty. In the case of an ensemble modelling approach, this means that the ensemble members disagree, yielding a considerable spread of predicted probabilities across the individual models. This suggests that the model's prediction of low susceptibility is less reliable, meaning that the high uncertainty warrants caution. While these regions could be considered relatively safe from landslides, which may in turn imply that resources for adaptation and mitigation measures might be better allocated elsewhere, these regions must not simply be neglected. Additional studies and data collection may be necessary to confirm the low susceptibility, especially if the area is important from a geomorphic point of view.
-
Upper-right corner – high susceptibility and high uncertainty. These areas are also identified as highly susceptible to landslides but with a high degree of uncertainty. This indicates that while the model suggests high susceptibility, the prediction is less reliable. Decision-makers should exercise caution and consider additional analyses or validation before taking action. Areas within this category could be designated as priority areas requiring further investigation to reduce uncertainty. This can be accomplished by employing local model interpretation and diagnostic methods to explain these individual predictions (e.g. local surrogate models or individual conditional expectation curves), by investing in additional data collection, or by conducting field-based validation.
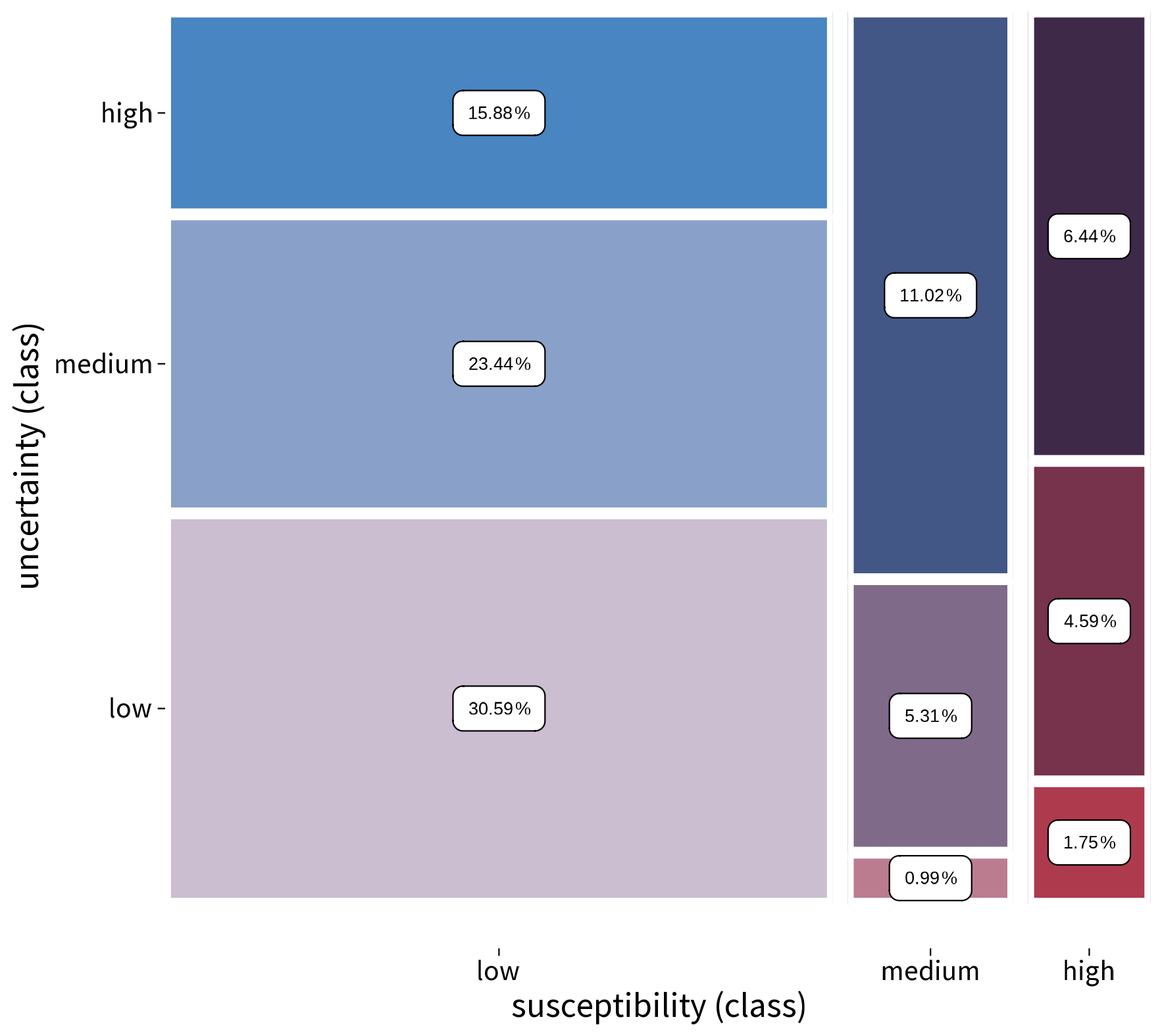
Figure 3Mosaic plot displaying the frequency distribution of the nine bivariate classes of the full area of interest (n = 46 760 232). The plot is based on the contingency table of the classes and shows both the conditional and the marginal distribution of the class counts. The area is proportional to the cell frequencies of the underlying contingency table, and colour is also mapped to the cell frequency.
Counts within the resulting nine classes are not evenly distributed (Fig. 3). In the case of Carinthia, the class where both susceptibility and uncertainty is low constitutes the largest class, containing approximately 30 % of all pixels. Overall, areas with low susceptibility account for about 50 % of the study area.
Feedback on the usability of the bivariate map collected during the stakeholder workshops indicated that users initially needed some time to become accustomed to the visualization. However, once the legend was internalized, the combined map was considered an effective means of communicating the integrated information. Two main benefits over the use of two separate maps were identified. First, there is no need to switch between map views, making the joint interpretation less cumbersome. In the medium and long run, the cognitive effort required to internalize the legend once is lower than that required to switch between maps. Second, the consideration of the second dimension (uncertainty) was deemed less likely to be neglected or overlooked.
There are two main properties that shape the appearance of the resulting map: (1) the definition of classes and (2) the colour palette. In addition, the type of uncertainty conveyed should be kept in mind: the underlying uncertainties can be aleatoric and epistemic in nature. In particular, epistemic uncertainty stemming from different sources along the modelling workflow, including the inventory, explanatory features, or the model used, can be visualized.
Generally speaking, a wide range of methods are available to derive univariate class intervals in continuous numerical vectors, including the use of equal intervals, quantile breaks, breaks derived through hierarchical or partitioning clustering methods, natural break optimization, and algorithms for heavy-tailed distributions (Slocum et al., 2022; Jiang, 2013; Jenks and Caspall, 1971; Fisher, 1958). In landslide susceptibility modelling, results are commonly discretized into three classes signifying low, medium, and high susceptibility. In addition to the aforementioned methods for deriving class intervals (Conoscenti et al., 2016; Hussin et al., 2016; Costanzo et al., 2012), modified methods for calculating breaks in susceptibility have been proposed, including methods based on the rank order (Spiekermann et al., 2023; Petschko et al., 2014; Chung and Fabbri, 2003) or on the receiver operating characteristic curve (Steger et al., 2024). The number of classes and the discretization algorithm used should be carefully considered and documented clearly, as these choices may have considerable impact on the appearance of the resulting map. We recommend limiting the number of classes to three or four in order to retain readability of the resulting bivariate classes on the map. The fact that the two variables are very likely to exhibit skewed distributions should also be taken into account when creating class intervals. Using easily understandable class definitions such as those proposed by Spiekermann et al. (2023) also aids interpretability: 80 % of all events occurred in the highest class, the medium class contained the next 15 % of observed events, and only the final 5 % of observed events fall into the lowest class.
The selection of a colour palette is vital for map design, as it profoundly influences a map's effectiveness, readability, and aesthetic appeal. Thus, choosing an appropriate colour palette is essential to prevent errors or biases in data interpretation (Schloss et al., 2019; Seipel and Lim, 2017). This encompasses considerations of accessibility, especially for people with vision deficiencies (Nowosad, 2020)1. Additionally, the cultural and contextual relevance should be accounted for, recognizing the varying meaning of colours across cultures (Kawai et al., 2022) and the psychological implications as per the colour-in-context theory (Elliot and Maier, 2012). Tailoring visualized information to users through a user-centred design process improves its effectiveness (Twomlow et al., 2022).
Landslide susceptibility models are associated with a wide range of epistemic (i.e. lack of knowledge) and aleatory (i.e. intrinsic randomness) uncertainties that propagate through the modelling chain (Knevels et al., 2023; Lombardo et al., 2020; Steger et al., 2016a; Brenning et al., 2015; Petschko et al., 2014; Rossi et al., 2010). The uncertainty displayed here merely refers to the estimation uncertainty stemming from the sampling of negative instances, as quantified through the ensemble modelling approach. However, the proposed bivariate depiction of landslide susceptibility is not contingent on specific types of uncertainties, and we advocate for a comprehensive inclusion of quantifiable uncertainties in such maps.
We presented a bivariate landslide susceptibility map that jointly visualizes the estimated susceptibility and the corresponding uncertainty. This type of visualization is generally applicable to all different kinds of uncertainty in the context of susceptibility modelling for various natural hazards. The methodology can be easily implemented in popular FOSS packages, using the examples provided in the repository in the Supplement as additional guidance. Overall, we argue that this graphical representation of susceptibility maps can aid in communicating modelling results and associated uncertainty more effectively.
By understanding the combinations of landslide susceptibility and the associated uncertainty, informed decisions about where to focus efforts for data collection, monitoring, risk mitigation, and resource allocation can be supported. This approach ensures a balanced and strategic response to landslide risk management, addressing both the immediate and long-term needs based on the confidence level of the modelled susceptibility.
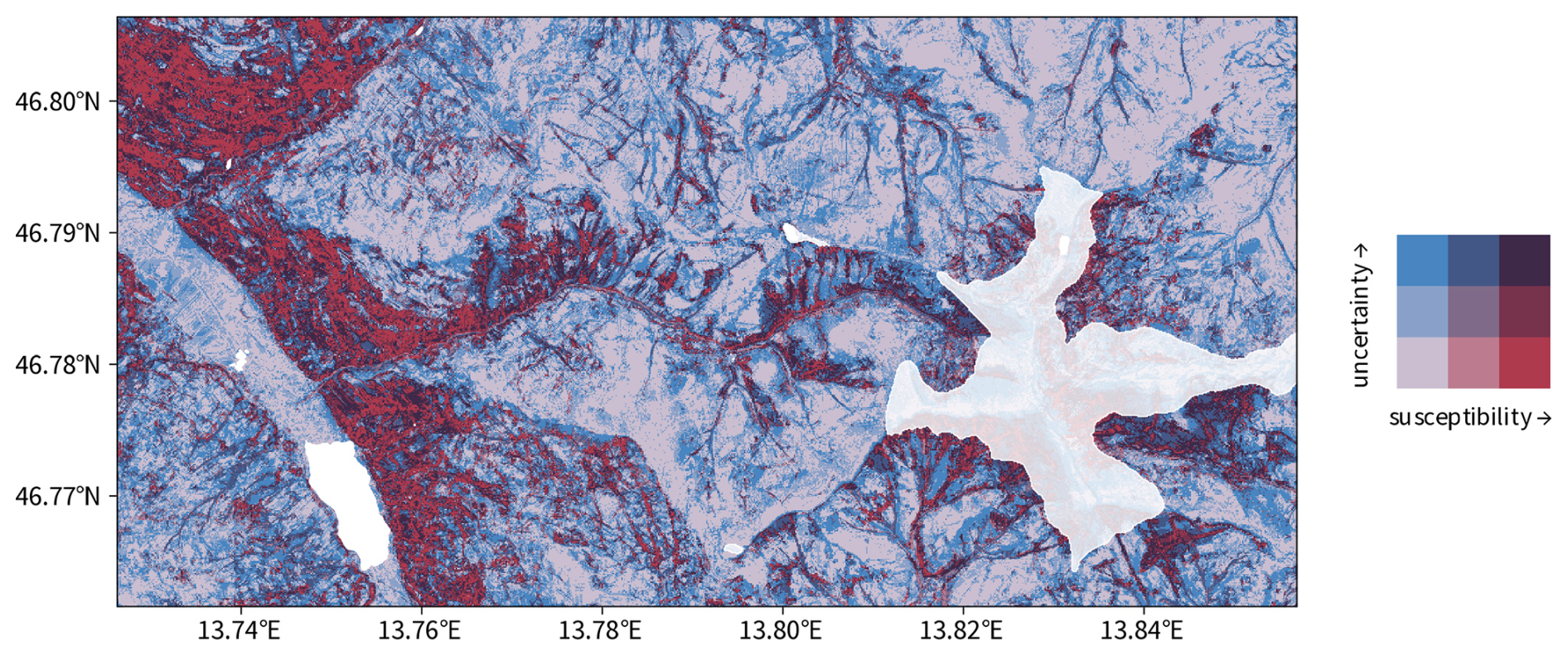
Figure A1Example of a bivariate susceptibility map created in R with ggplot2. Legend created with the package biscale using the “DkViolet” colour ramp created by Grossenbacher and Zehr (2019).
The open-source programming language R (R Core Team, 2024) is a software environment for statistical computing and data visualization. It does also feature excellent support for geospatial data processing, geocomputational analyses, and geographic information science (Wimberly, 2023; Lovelace et al., 2019; Pebesma, 2018). Visualization of bivariate maps in R is straightforward (Fig. A1) and requires the following add-on packages.
-
sf(Pebesma et al., 2024a) is used to handle spatial vector data by extending data frames with a geometry column, thereby providing simple feature access (Pebesma and Bivand, 2023; Pebesma, 2018). -
stars(Pebesma et al., 2024b) is used to handle spatial raster data (Pebesma and Bivand, 2023). -
ggplot2(Wickham et al., 2024) provides a system for declaratively creating graphics based on The Grammar of Graphics (Wickham, 2016; Wilkinson, 2005) and is used as a plotting framework. -
biscale(Prener et al., 2022) extendsggplot2by providing tools and colour palettes for bivariate thematic mapping. -
ggspatial(Dunnington et al., 2023) extendsggplot2by providing additional support for plotting spatial objects. -
patchwork(Pedersen, 2024) orcowplot(Wilke, 2024) can be used to arrange multipleggplot2objects and compose a unified single plot. -
rayshader(Morgan-Wall, 2024) can be used for 3D visualizations of bivariate susceptibility maps.
Note that plotting raster data as points using geom_raster() is recommended for reasons of computational performance.

Figure A2Example of a 3D visualization of the bivariate susceptibility map using rayshader. The figure displays two rendered snapshots. An interactive version is provided as Supplement.
Existing QGIS plugins for bivariate mapping (bivariate legend (https://plugins.qgis.org/plugins/BivariateLegend/, last access: 10 April 2025) and bivariate polygon renderer (https://plugins.qgis.org/plugins/BivariateRenderer/, last access: 10 April 2025)) focus on vector data and, therefore, do not support the creation of bivariate maps from susceptibility rasters. While simply polygonizing the rasters and plotting the resulting polygons is possible, this does not scale well to large files.
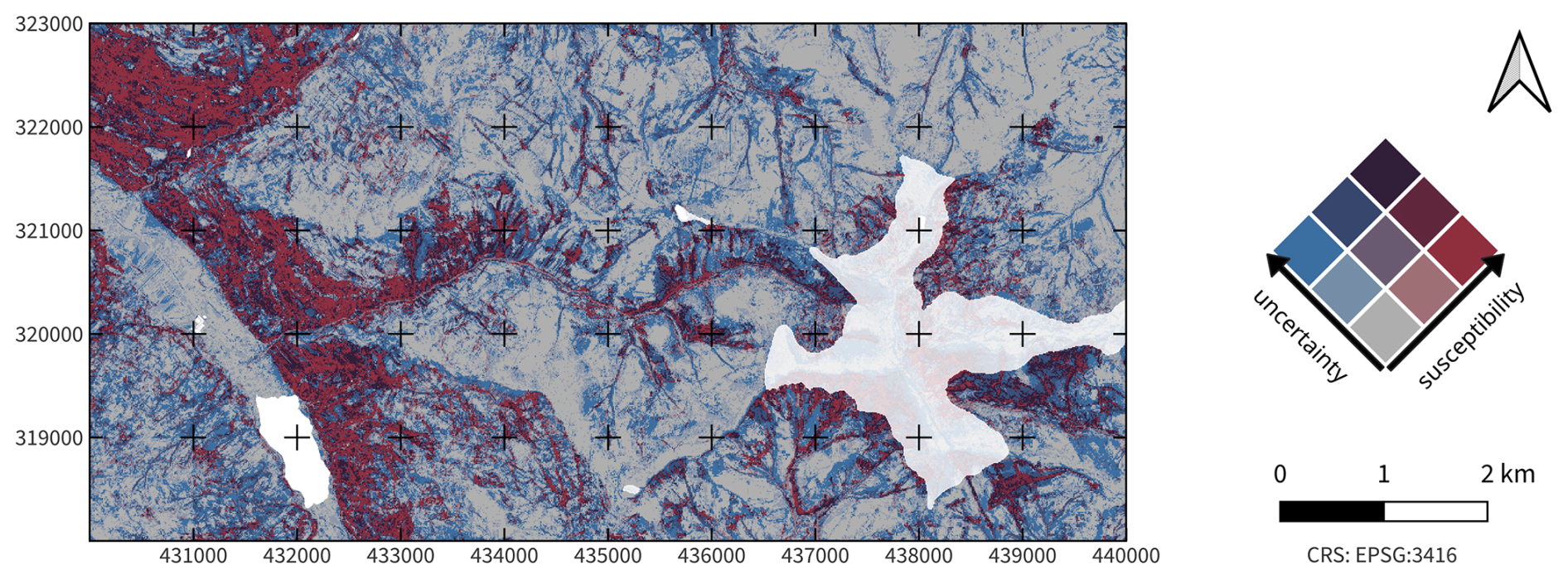
Figure B1Example of a bivariate susceptibility map created in QGIS using multiply blending. Legend created using the bivariate renderer plugin with the “Violet–Blue” colour ramp.
There are two main kinds of approaches to generating bivariate maps from rasters: (1) combining two raster layers with blending modes (such as multiply) to generate the bivariate effect or (2) reclassifying the raster into the desired number of classes using raster algebra. Starting in QGIS 3.22, the raster calculator supports IF statements (https://www.qgis.org/project/visual-changelogs/visualchangelog322/index.html, last access: 10 April 2025), which make it straightforward to reclassify the susceptibility raster into the classes required for the bivariate map.
The bivariate polygon renderer is based on the blending approach, with support for multiply, darken, and mixing blending. It is worth noting however, that blending colours, as shown in Fig. B1, does not result in the exact same bivariate colour maps that can be seen in Fig. A1 since the pink and blue colours are always blended with the grey, resulting in slightly darker tones.

Figure C1Overview of the colour palettes for bivariate maps available in the R package biscale.
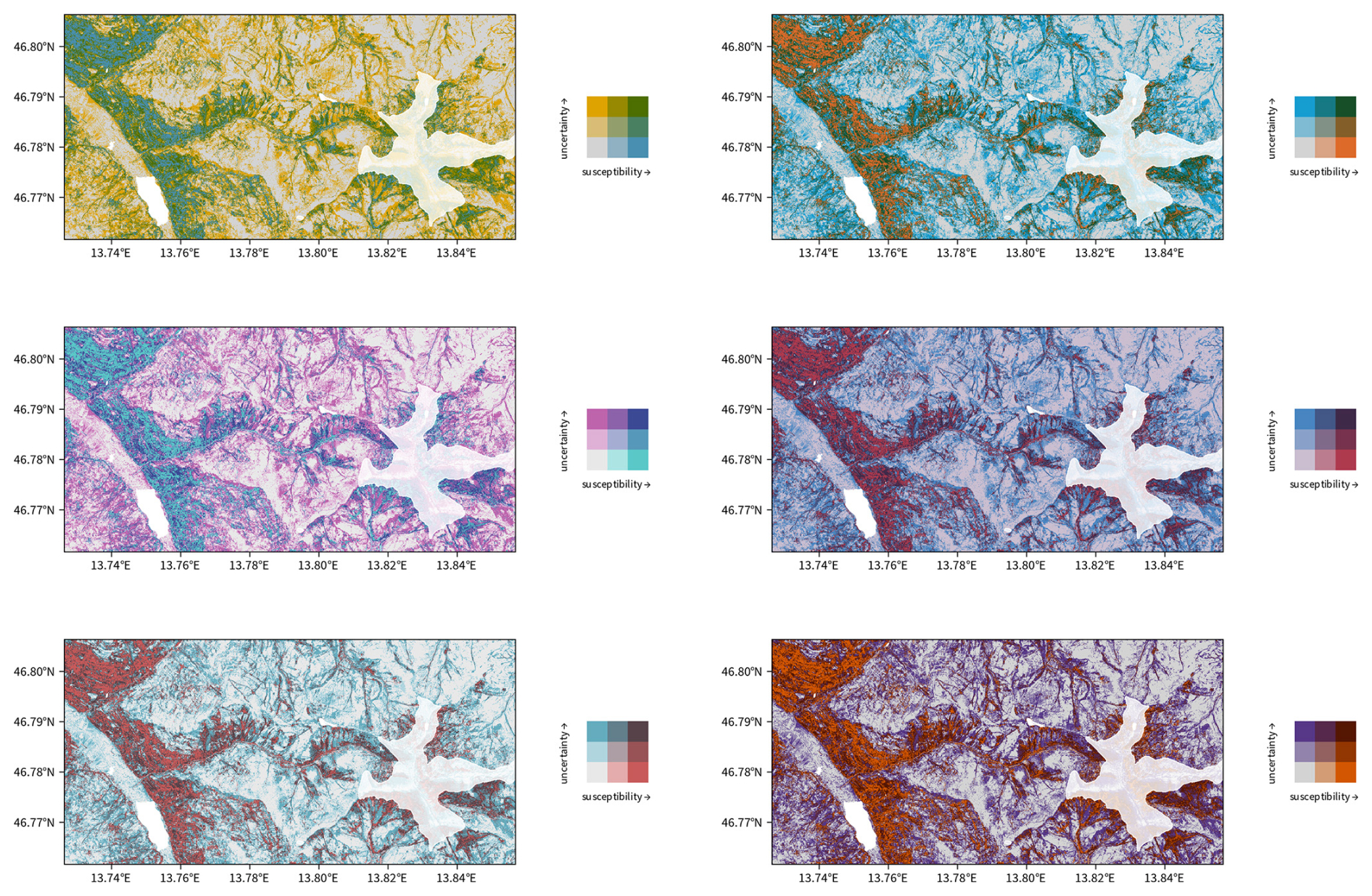
Figure C2Illustrations of the bivariate susceptibility map using the colour palettes “BlueGold”, “BlueOr”, “DkBlue”, “DkViolet”, “GrPink”, and “PurpleOr”.
When interpreting the uncertainty estimate, the conditional dependence of the ensemble standard deviation on the mean susceptibility needs to be considered (Fig. D1). It can be observed that the uncertainty in the outcome has a maximum around 0.5 to 0.6 and decreases towards both ends of the susceptibility spectrum, exhibiting an approximately quadratic relationship that can be approximated as . Given the high heteroscedasticity, this relationship was estimated using robust regression with M estimation, employing Tukey's bisquare loss function.
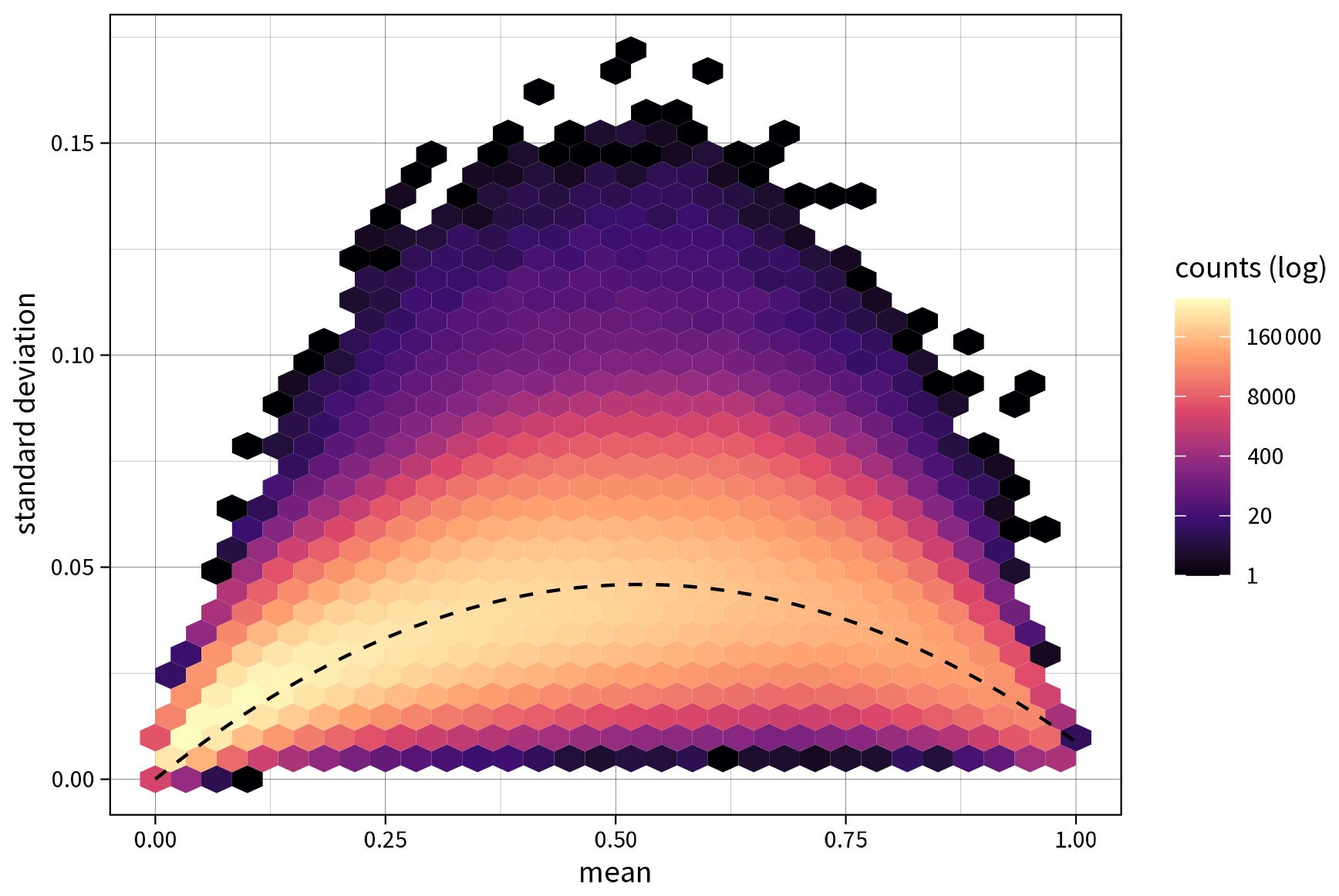
Figure D1Ensemble mean versus ensemble standard deviation for all predictions of the full area of interest in Carinthia, Austria.
There are two main reasons for this emerging pattern. First, the standard deviation is bound to be lower towards both ends of the available susceptibility range for purely mathematical reasons. Since susceptibility values are confined between 0 and 1, the standard deviation is truncated at both ends of the spectrum. Naturally, this effect becomes more pronounced as the mean approaches either the minimum or the maximum of the feature range. Second, predicted outcomes near the class discrimination threshold of 0.5 are typically more uncertain than instances classified as positive or negative with high confidence. In this medium range, the model ensemble has difficulties classifying the terrain as either stable or unstable, which results in a higher standard deviation of the estimate and thus decreases the reliability of the prediction (Guzzetti et al., 2006).
All code to generate the plots and maps is available on GitHub at https://github.com/r3xth0r/bivariate-lsm (last access: 10 April 2025, released on Zenodo via https://doi.org/10.5281/zenodo.15189349, Schlögl and Graser, 2025). Sample data are also provided in this repository via Git LFS. Code for the underlying landslide susceptibility model for Carinthia is available on GitLab at https://gitlab.com/Rexthor/lsm-carinthia (Schlögl, 2025).
The supplement related to this article is available online at https://doi.org/10.5194/nhess-25-1425-2025-supplement.
MS – conceptualization, methodology, software, validation, formal analysis, data curation, writing (original draft), writing (review & editing), and visualization. AG – conceptualization, methodology, software, and visualization. SS – validation and writing (review and editing). JL – conceptualization, visualization, and writing (review and editing). RS – validation and writing (review and editing).
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We thank Christina Rechberger and Susanna Wernhart from the Disaster Competence Network Austria (DCNA) for their efforts in preparing and moderating the stakeholder workshops, as well as for compiling the acceptance analysis and exploitation concept.
This research has been supported by the Österreichische Forschungsförderungsgesellschaft (grant no. FO999886369).
This paper was edited by Bayes Ahmed and reviewed by two anonymous referees.
Achu, A., Aju, C., Di Napoli, M., Prakash, P., Gopinath, G., Shaji, E., and Chandra, V.: Machine-learning based landslide susceptibility modelling with emphasis on uncertainty analysis, Geosci. Front., 14, 101657, https://doi.org/10.1016/j.gsf.2023.101657, 2023. a
Brenning, A., Schwinn, M., Ruiz-Páez, A. P., and Muenchow, J.: Brenning, A., Schwinn, M., Ruiz-Páez, A. P., and Muenchow, J.: Landslide susceptibility near highways is increased by 1 order of magnitude in the Andes of southern Ecuador, Loja province, Nat. Hazards Earth Syst. Sci., 15, 45–57, https://doi.org/10.5194/nhess-15-45-2015, 2015. a
Chung, C.-J. F. and Fabbri, A. G.: Validation of Spatial Prediction Models for Landslide Hazard Mapping, Nat. Hazards, 30, 451–472, https://doi.org/10.1023/b:nhaz.0000007172.62651.2b, 2003. a
Conoscenti, C., Rotigliano, E., Cama, M., Caraballo-Arias, N. A., Lombardo, L., and Agnesi, V.: Exploring the effect of absence selection on landslide susceptibility models: A case study in Sicily, Italy, Geomorphology, 261, 222–235, https://doi.org/10.1016/j.geomorph.2016.03.006, 2016. a
Costanzo, D., Rotigliano, E., Irigaray, C., Jiménez-Perálvarez, J. D., and Chacón, J.: Costanzo, D., Rotigliano, E., Irigaray, C., Jiménez-Perálvarez, J. D., and Chacón, J.: Factors selection in landslide susceptibility modelling on large scale following the gis matrix method: application to the river Beiro basin (Spain), Nat. Hazards Earth Syst. Sci., 12, 327–340, https://doi.org/10.5194/nhess-12-327-2012, 2012. a
Dai, F., Lee, C., and Ngai, Y.: Landslide risk assessment and management: an overview, Eng. Geol., 64, 65–87, https://doi.org/10.1016/s0013-7952(01)00093-x, 2002. a
Davis, T. J. and Keller, C.: Modelling and visualizing multiple spatial uncertainties, Comput. Geosci., 23, 397–408, https://doi.org/10.1016/s0098-3004(97)00012-5, 1997. a
De Cola, L.: Spatial Forecasting of Disease Risk and Uncertainty, Cartogr. Geogr. Inf. Sc., 29, 363–380, https://doi.org/10.1559/152304002782008413, 2002. a
Dunnington, D., Thorne, B., and Hernangómez, D.: ggspatial: Spatial Data Framework for ggplot2, CRAN, https://doi.org/10.32614/CRAN.package.ggspatial, R package version 1.1.9, 2023. a
Elliot, A. J. and Maier, M. A.: Color-in-Context Theory, in: Advances in Experimental Social Psychology, edited by: Devine, P. and Plant, A., Elsevier, https://doi.org/10.1016/b978-0-12-394286-9.00002-0, 61–125 pp., 2012. a
Fischhoff, B. and Davis, A. L.: Communicating scientific uncertainty, P. Natl. Acad. Sci. USA, 111, 13664–13671, https://doi.org/10.1073/pnas.1317504111, 2014. a
Fisher, W. D.: On Grouping for Maximum Homogeneity, J. Am. Stat. Assoc., 53, 789–798, https://doi.org/10.1080/01621459.1958.10501479, 1958. a
Gaidzik, K. and Ramírez-Herrera, M. T.: The importance of input data on landslide susceptibility mapping, Sci. Rep.-UK, 11, 19334, https://doi.org/10.1038/s41598-021-98830-y, 2021. a
Grossenbacher, T. and Zehr, A.: Bivariate maps with ggplot2 and sf, Tutorials, https://timogrossenbacher.ch/bivariate-maps-with-ggplot2-and-sf (last access: 10 April 2025), 2019. a
Gustafson, A. and Rice, R. E.: A review of the effects of uncertainty in public science communication, Public Underst. Sci., 29, 614–633, https://doi.org/10.1177/0963662520942122, 2020. a
Guzzetti, F., Reichenbach, P., Ardizzone, F., Cardinali, M., and Galli, M.: Estimating the quality of landslide susceptibility models, Geomorphology, 81, 166–184, https://doi.org/10.1016/j.geomorph.2006.04.007, 2006. a, b
Heckmann, T., Gegg, K., Gegg, A., and Becht, M.: Sample size matters: investigating the effect of sample size on a logistic regression susceptibility model for debris flows, Nat. Hazards Earth Syst. Sci., 14, 259–278, https://doi.org/10.5194/nhess-14-259-2014, 2014. a
Hong, H., Miao, Y., Liu, J., and Zhu, A.-X.: Exploring the effects of the design and quantity of absence data on the performance of random forest-based landslide susceptibility mapping, CATENA, 176, 45–64, https://doi.org/10.1016/j.catena.2018.12.035, 2019. a
Huang, F., Yan, J., Fan, X., Yao, C., Huang, J., Chen, W., and Hong, H.: Uncertainty pattern in landslide susceptibility prediction modelling: Effects of different landslide boundaries and spatial shape expressions, Geosci. Front., 13, 101317, https://doi.org/10.1016/j.gsf.2021.101317, 2022. a
Huang, F., Teng, Z., Guo, Z., Catani, F., and Huang, J.: Uncertainties of landslide susceptibility prediction: Influences of different spatial resolutions, machine learning models and proportions of training and testing dataset, Rock Mechanics Bulletin, 2, 100028, https://doi.org/10.1016/j.rockmb.2023.100028, 2023. a
Hussin, H. Y., Zumpano, V., Reichenbach, P., Sterlacchini, S., Micu, M., van Westen, C., and Bălteanu, D.: Different landslide sampling strategies in a grid-based bi-variate statistical susceptibility model, Geomorphology, 253, 508–523, https://doi.org/10.1016/j.geomorph.2015.10.030, 2016. a
Jenks, G. F. and Caspall, F. C.: Error on Choroplethic Maps: Definition, Measurement, Reduction, Ann. Assoc. Am. Geogr., 61, 217–244, https://www.jstor.org/stable/2562442 (last access: 10 April 2025), 1971. a
Jiang, B.: Head/Tail Breaks: A New Classification Scheme for Data with a Heavy-Tailed Distribution, Prof. Geogr., 65, 482–494, https://doi.org/10.1080/00330124.2012.700499, 2013. a
Kawai, C., Zhang, Y., Lukács, G., Chu, W., Zheng, C., Gao, C., Gozli, D., Wang, Y., and Ansorge, U.: The good the bad and the red: implicit color-valence associations across cultures, Psychological Research, 87, 704–724, https://doi.org/10.1007/s00426-022-01697-5, 2022. a
Kinkeldey, C., MacEachren, A. M., and Schiewe, J.: How to Assess Visual Communication of Uncertainty? A Systematic Review of Geospatial Uncertainty Visualisation User Studies, Cartogr. J., 51, 372–386, https://doi.org/10.1179/1743277414y.0000000099, 2014. a
Knevels, R., Petschko, H., Proske, H., Leopold, P., Mishra, A. N., Maraun, D., and Brenning, A.: Assessing uncertainties in landslide susceptibility predictions in a changing environment (Styrian Basin, Austria), Nat. Hazards Earth Syst. Sci., 23, 205–229, https://doi.org/10.5194/nhess-23-205-2023, 2023. a
Lima, P., Steger, S., and Glade, T.: Counteracting flawed landslide data in statistically based landslide susceptibility modelling for very large areas: a national-scale assessment for Austria, Landslides, 18, 3531–3546, https://doi.org/10.1007/s10346-021-01693-7, 2021. a
Lima, P., Steger, S., Glade, T., and Mergili, M.: Conventional data-driven landslide susceptibility models may only tell us half of the story: Potential underestimation of landslide impact areas depending on the modeling design, Geomorphology, 430, 108638, https://doi.org/10.1016/j.geomorph.2023.108638, 2023. a
Loche, M., Alvioli, M., Marchesini, I., Bakka, H., and Lombardo, L.: Landslide susceptibility maps of Italy: Lesson learnt from dealing with multiple landslide types and the uneven spatial distribution of the national inventory, Earth-Sci. Rev., 232, 104125, https://doi.org/10.1016/j.earscirev.2022.104125, 2022. a
Löhr, K., Weinhardt, M., and Sieber, S.: The “World Café” as a Participatory Method for Collecting Qualitative Data, Int. J. Qual. Meth., 19, https://doi.org/10.1177/1609406920916976, 2020. a
Lombardo, L., Cama, M., Maerker, M., and Rotigliano, E.: A test of transferability for landslides susceptibility models under extreme climatic events: application to the Messina 2009 disaster, Nat. Hazards, 74, 1951–1989, https://doi.org/10.1007/s11069-014-1285-2, 2014. a
Lombardo, L., Opitz, T., Ardizzone, F., Guzzetti, F., and Huser, R.: Space-time landslide predictive modelling, Earth-Sci. Rev., 209, 103318, https://doi.org/10.1016/j.earscirev.2020.103318, 2020. a
Lovelace, R., Nowosad, J., and Muenchow, J.: Geocomputation with R, Chapman and Hall/CRC, https://doi.org/10.1201/9780203730058, 2019. a
MacEachren, A. M., Robinson, A., Hopper, S., Gardner, S., Murray, R., Gahegan, M., and Hetzler, E.: Visualizing Geospatial Information Uncertainty: What We Know and What We Need to Know, Cartogr. Geogr. Inf. Sc., 32, 139–160, https://doi.org/10.1559/1523040054738936, 2005. a
Moreno, M., Steger, S., Tanyas, H., and Lombardo, L.: Modeling the area of co-seismic landslides via data-driven models: The Kaikōura example, Eng. Geol., 320, 107121, https://doi.org/10.1016/j.enggeo.2023.107121, 2023. a
Morgan-Wall, T.: rayshader: Create Maps and Visualize Data in 2D and 3D, CRAN, https://doi.org/10.32614/CRAN.package.rayshader, R package version 0.37.3, 2024. a
Nelson, E. S.: Using Selective Attention Theory to Design Bivariate Point Symbols, Cartographic Perspectives, 32, 6–28, https://doi.org/10.14714/cp32.625, 1999. a
Nowosad, J.: How to Choose a Bivariate Color Palette?, Thinking in spatial patterns, https://jakubnowosad.com/posts/2020-08-25-cbc-bp2 (last access: 10 April 2025), 2020. a
Oreskes, N., Shrader-Frechette, K., and Belitz, K.: Verification, Validation, and Confirmation of Numerical Models in the Earth Sciences, Science, 263, 641–646, https://doi.org/10.1126/science.263.5147.641, 1994. a
Pebesma, E.: Simple Features for R: Standardized Support for Spatial Vector Data, R J., 10, 439, https://doi.org/10.32614/rj-2018-009, 2018. a, b
Pebesma, E. and Bivand, R.: Spatial Data Science: With Applications in R, Chapman and Hall/CRC, https://doi.org/10.1201/9780429459016, 2023. a, b
Pebesma, E., Bivand, R., Racine, E., Sumner, M., Cook, I., Keitt, T., Lovelace, R., Wickham, H., Ooms, J., Müller, K., Pedersen, T. L., Baston, D., and Dunnington, D.: sf: Simple Features for R, CRAN, https://doi.org/10.32614/CRAN.package.sf, R package version 1.0-16, 2024a. a
Pebesma, E., Sumner, M., Racine, E., Fantini, A., Blodgett, D., and Dyba, K.: stars: Spatiotemporal Arrays, Raster and Vector Data Cubes, CRAN, https://doi.org/10.32614/CRAN.package.stars, R package version 0.6-6, 2024b. a
Pedersen, T. L.: patchwork: The Composer of Plots, CRAN, https://doi.org/10.32614/CRAN.package.patchwork, R package version 1.2.0, 2024. a
Peng, L., Niu, R., Huang, B., Wu, X., Zhao, Y., and Ye, R.: Landslide susceptibility mapping based on rough set theory and support vector machines: A case of the Three Gorges area, China, Geomorphology, 204, 287–301, https://doi.org/10.1016/j.geomorph.2013.08.013, 2014. a
Petschko, H., Brenning, A., Bell, R., Goetz, J., and Glade, T.: Assessing the quality of landslide susceptibility maps – case study Lower Austria, Nat. Hazards Earth Syst. Sci., 14, 95–118, https://doi.org/10.5194/nhess-14-95-2014, 2014. a, b, c
Pourghasemi, H. R., Kornejady, A., Kerle, N., and Shabani, F.: Investigating the effects of different landslide positioning techniques, landslide partitioning approaches, and presence-absence balances on landslide susceptibility mapping, CATENA, 187, 104364, https://doi.org/10.1016/j.catena.2019.104364, 2020. a
Prener, C., Grossenbacher, T., and Zehr, A.: biscale: Tools and Palettes for Bivariate Thematic Mapping, CRAN, https://doi.org/10.32614/CRAN.package.biscale, R package version 1.0.0, 2022. a
R Core Team: R: A Language and Environment for Statistical Computing, R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/ (last access: 10 April 2025), 2024. a
Reichenbach, P., Rossi, M., Malamud, B. D., Mihir, M., and Guzzetti, F.: A review of statistically-based landslide susceptibility models, Earth-Sci. Rev., 180, 60–91, https://doi.org/10.1016/j.earscirev.2018.03.001, 2018. a, b
Rossi, M., Guzzetti, F., Reichenbach, P., Mondini, A. C., and Peruccacci, S.: Optimal landslide susceptibility zonation based on multiple forecasts, Geomorphology, 114, 129–142, https://doi.org/10.1016/j.geomorph.2009.06.020, 2010. a, b
Schlögl, M.: Landslide Susceptibility Modelling Carinthia, GitLab [code], https://gitlab.com/Rexthor/lsm-carinthia (last access: 10 April 2025), 2025. a
Schlögl, M. and Graser, A.: Supplementary code and data to “Communicating uncertainties in landslide susceptibility modeling using bivariate mapping”, Version v1.0, Zenodo [code/data set], https://doi.org/10.5281/zenodo.15189349, 2025. a
Schlögl, M., Richter, G., Avian, M., Thaler, T., Heiss, G., Lenz, G., and Fuchs, S.: On the nexus between landslide susceptibility and transport infrastructure – an agent-based approach, Nat. Hazards Earth Syst. Sci., 19, 201–219, https://doi.org/10.5194/nhess-19-201-2019, 2019. a
Schlögl, M., Spiekermann, R., and Steger, S.: Towards a holistic assessment of landslide susceptibility models: insights from the Central Eastern Alps, Environ. Earth Sci., 84, 113, https://doi.org/10.1007/s12665-024-12041-y, 2025. a, b
Schloss, K. B., Gramazio, C. C., Silverman, A. T., Parker, M. L., and Wang, A. S.: Mapping Color to Meaning in Colormap Data Visualizations, IEEE T. Vis. Comput Gr., 25, 810–819, https://doi.org/10.1109/tvcg.2018.2865147, 2019. a
Schneider, S.: Communicating Uncertainty: A Challenge for Science Communication, in: Communicating Climate-Change and Natural Hazard Risk and Cultivating Resilience. Case Studies for a Multi-disciplinary Approach, edited by: Drake, J. L., Kontar, Y. Y., Eichelberger, J. C., Rupp, T. S., and Taylor, K. M., Springer International Publishing, 267–278, https://doi.org/10.1007/978-3-319-20161-0_17, 2016. a
Seipel, S. and Lim, N. J.: Color map design for visualization in flood risk assessment, Int. J. Geogr. Inf. Sci., 31, 2286–2309, https://doi.org/10.1080/13658816.2017.1349318, 2017. a
Slocum, T. A., McMaster, R. B., Kessler, F. C., and Howard, H.: Thematic Cartography and Geovisualization, CRC Press, https://doi.org/10.1201/9781003150527, 2022. a
Speich, M. J., Bernhard, L., Teuling, A. J., and Zappa, M.: Application of bivariate mapping for hydrological classification and analysis of temporal change and scale effects in Switzerland, J. Hydrol., 523, 804–821, https://doi.org/10.1016/j.jhydrol.2015.01.086, 2015. a
Spiekermann, R. I., van Zadelhoff, F., Schindler, J., Smith, H., Phillips, C., and Schwarz, M.: Comparing physical and statistical landslide susceptibility models at the scale of individual trees, Geomorphology, 440, 108870, https://doi.org/10.1016/j.geomorph.2023.108870, 2023. a, b, c, d
Steger, S., Brenning, A., Bell, R., and Glade, T.: The propagation of inventory-based positional errors into statistical landslide susceptibility models, Nat. Hazards Earth Syst. Sci., 16, 2729–2745, https://doi.org/10.5194/nhess-16-2729-2016, 2016a. a, b, c
Steger, S., Brenning, A., Bell, R., Petschko, H., and Glade, T.: Exploring discrepancies between quantitative validation results and the geomorphic plausibility of statistical landslide susceptibility maps, Geomorphology, 262, 8–23, https://doi.org/10.1016/j.geomorph.2016.03.015, 2016b. a, b
Steger, S., Mair, V., Kofler, C., Pittore, M., Zebisch, M., and Schneiderbauer, S.: Correlation does not imply geomorphic causation in data-driven landslide susceptibility modelling – Benefits of exploring landslide data collection effects, Sci. Total Environ., 776, 145935, https://doi.org/10.1016/j.scitotenv.2021.145935, 2021. a
Steger, S., Moreno, M., Crespi, A., Luigi Gariano, S., Teresa Brunetti, M., Melillo, M., Peruccacci, S., Marra, F., de Vugt, L., Zieher, T., Rutzinger, M., Mair, V., and Pittore, M.: Adopting the margin of stability for space–time landslide prediction – A data-driven approach for generating spatial dynamic thresholds, Geosci. Front., 15, 101822, https://doi.org/10.1016/j.gsf.2024.101822, 2024. a
Stevens, J.: Bivariate Choropleth Maps: A How-to Guide, Blog, https://www.joshuastevens.net/cartography/make-a-bivariate-choropleth-map (last access: 10 April 2025), 2015. a
Teuling, A. J., Stöckli, R., and Seneviratne, S. I.: Bivariate colour maps for visualizing climate data, Int. J. Climatol., 31, 1408–1412, https://doi.org/10.1002/joc.2153, 2011. a
Trumbo, B. E.: A Theory for Coloring Bivariate Statistical Maps, Am. Stat., 35, 220–226, https://doi.org/10.2307/2683294, 1981. a
Twomlow, A., Grainger, S., Cieslik, K., Paul, J. D., and Buytaert, W.: A user-centred design framework for disaster risk visualisation, Int. J. Disast Risk Re., 77, 103067, https://doi.org/10.1016/j.ijdrr.2022.103067, 2022. a
Weigold, M. F.: Communicating Science: A Review of the Literature, Science Commun., 23, 164–193, https://doi.org/10.1177/1075547001023002005, 2001. a
Wickham, H.: ggplot2: Elegant Graphics for Data Analysis, Springer New York, https://doi.org/10.1007/978-0-387-98141-3, 2016. a
Wickham, H., Chang, W., Henry, L., Pedersen, T. L., Takahashi, K., Wilke, C., Woo, K., Yutani, H., Dunnington, D., van den Brand, T., and Posit, PBC: ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics, CRAN, https://doi.org/10.32614/CRAN.package.ggplot2, R package version 3.5.1, 2024. a
Wilke, C. O.: cowplot: Streamlined Plot Theme and Plot Annotations for 'ggplot2', CRAN, https://doi.org/10.32614/CRAN.package.cowplot, R package version 1.1.3, 2024. a
Wilkinson, L.: The Grammar of Graphics, Statistics and Computing, Springer, https://doi.org/10.1007/0-387-28695-0, 2005. a
Wimberly, M. C.: Geographic Data Science with R: Visualizing and Analyzing Environmental Change, Chapman and Hall/CRC, https://doi.org/10.1201/9781003326199, 2023. a
Zeileis, A., Fisher, J. C., Hornik, K., Ihaka, R., McWhite, C. D., Murrell, P., Stauffer, R., and Wilke, C. O.: colorspace: A Toolbox for Manipulating and Assessing Colors and Palettes, J. Stat. Softw., 96, 1–49, https://doi.org/10.18637/jss.v096.i01, 2020. a
Tools such as https://colorbrewer2.org (last access: 10 April 2025) or https://hclwizard.org (last access: 10 April 2025), along with the corresponding R package colorspace (Zeileis et al., 2020), provide valuable assistance in selecting colour palettes for users with different types of vision deficiencies.
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Bivariate susceptibility maps in R
- Appendix B: Bivariate susceptibility maps in QGIS
- Appendix C: Bivariate colour palettes
- Appendix D: Conditional dependence of the standard deviation on the mean
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Bivariate susceptibility maps in R
- Appendix B: Bivariate susceptibility maps in QGIS
- Appendix C: Bivariate colour palettes
- Appendix D: Conditional dependence of the standard deviation on the mean
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement