the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 27 Aug 2025
| 27 Aug 2025
Impact-based temporal clustering of multiple meteorological hazard types in southwestern Germany
Katharina Küpfer
Alexandre Tuel
Michael Kunz
A series of multiple meteorological extreme events in close succession can lead to a substantial increase in total losses compared to randomly distributed events. In this study, different temporal clustering methods are applied to insurance loss data from southwestern Germany from 1986 to 2023 for the following hazards: windstorms, convective gusts, and hail, as well as pluvial, fluvial, and mixed flood events. We assess the timing and significance of seasonal clustering of single hazard types as well as their serial combination by use of both a simple counting algorithm and the clustering metric Ripley's K. Results show that clustering is significant only for certain hazard types compared to a random time series. However, clustering is robust for a combination of multiple hazard types, namely hail, mixed or pluvial floods, and storms. This particular combination of hazard types is also associated with higher losses compared to their isolated occurrence. Clusters of damaging hazards occur mainly during May–August and depend on the method of defining independent events (peaks-over-threshold method with flexible lengths vs. hours clause method with fixed lengths) and their resulting duration. This study demonstrates the relevance of considering multiple hazard types when evaluating clustering of meteorological hazards.
- Article
(8541 KB) - Full-text XML
- BibTeX
- EndNote




Weather- and climate-related hazards frequently cause considerable loss and damage in Germany, such as the extreme flood caused by the low-pressure system Bernd in western Germany and Belgium in July 2021 (Mohr et al., 2023) or the storm series Dudley, Eunice, and Franklin in February 2022 (Mühr et al., 2022). These events can also lead to fatalities and major societal impacts, such as damage to critical infrastructure with potential long-term consequences (Schäfer et al., 2021). In Central Europe, the most relevant hazard types with regard to losses are hydro-meteorological extremes (European Environment Agency, 2023), such as floods, winter storms, hail, and convective gusts. Damage by those hazards has increased globally (Banerjee et al., 2024) and in Europe (Kron et al., 2019), which can partly be attributed to climate change.
Between 1980 and 2023, total losses caused by natural hazards are estimated at EUR 738 billion in the European Union (European Environment Agency, 2023). Germany, and the southwest in particular, has been a hotspot for damaging meteorological hazards in recent decades, resulting in high losses compared to other regions in Europe (Kron et al., 2019). Between 2001 and 2021, extreme events amounted to annual losses of about EUR 6.6 billion in Germany, including indirect effects (Trenczek et al., 2022). Flood and storm events are the major drivers of losses in Germany (Kreibich et al., 2014). For example, the winter storm Lothar in 1999 caused total economic losses of more than EUR 15 billion (Swiss Re, 2019), the hail event Andreas in 2013 led to an economic loss of more than EUR 1 billion (Kunz et al., 2018), and most recently, in June 2024, southwestern Germany was hit by flooding that led to an expected economic loss of more than EUR 2 billion (GDV, 2024).
These extreme events often do not occur in isolation. In southwestern Germany, for example, there was a sequence of multiple events in 2013: an exceptional flood occurred during the end of May and the beginning of June, which was followed by extreme heat and a severe hailstorm in July, as well as extreme heat at the beginning of August (Deutscher Wetterdienst, 2013). All of these events caused severe impacts, with inundated towns and villages after the flooding, damaged roofs and facades of buildings due to large hail (Kunz et al., 2018), and blocked water routes due to drought hindering the transportation of goods (Thieken et al., 2016). Impacts of cascading events can lead to additional problems, such as blocked traffic routes after a previous event (Mohr et al., 2023), disturbed emergency responses (Raymond et al., 2020), an increased recovery time (Ruiter et al., 2020), or additional damage to buildings after a storm if damaged roofs fail to stop rainwater from entering (Martius et al., 2016). Other examples of cascading impacts are increased runoff in the case of a heavy rain event after a heatwave or an increased debris flow with damage potential in the case of flooding after a storm event (see, for example, Kreibich et al., 2014). These cascading events can also lead to societal impacts; e.g., while recovery is still ongoing, authorities and technical organizations can become overburdened in a series of events due to limited availabilities for repeated action, since many of the organizations are based on volunteers. In longer periods of action, lack of food supply or lack of rest for rescuers can harm recovery. Insurance companies and their regulators can become overburdened by a succession of several events as well. With major damaging hazards happening in close succession, this can therefore lead to capacity problems for civil protection, local authorities, insurance companies, and NGOs.
When a combination of multiple drivers and/or hazards contributes to societal or environmental risk, this is referred to as compound weather or climate events (Zscheischler et al., 2018). Similarly, the United Nations Office for Disaster Risk Reduction (UNDRR) defines multi-hazards as “the specific contexts where hazardous events may occur simultaneously, cascadingly or cumulatively over time, and taking into account the potential interrelated effects” (UNDRR, 2016, p. 19). It has recently been shown that these compound or multi-hazard events are quite frequent: 19 % of events in the global disaster database EM-DAT can be classified as multi-hazard events, leading to an overproportionally high share of 59 % of global economic losses, with the primary meteorological hazard types being floods and storms (Lee et al., 2024). Despite this large proportion, risk models such as those used by the insurance industry generally consider the different hazard types independently (Hillier et al., 2015; Mitchell-Wallace et al., 2017; Priestley et al., 2018). Risk analyses and risk management often lack this multi-hazard perspective as well (Kreibich et al., 2014).
In the past years, many studies have investigated compound events; however, most of them have focused on single hazard types or multiple dry hazard types, such as heatwaves and droughts (Ruiter and Loon, 2022). There is only little research on the co-occurrence or compound occurrence of different hazard types, particularly in relation to their impact. However, this perspective has gained increasing attention in recent years. For example, Ruiter et al. (2020) evaluate consecutive disasters of different types, and recent work focuses on the classification of multiple hazards including a range of hazard types (Claassen et al., 2023). Specifically, the interrelationship between flood and wind occurrence has received quite some attention (e.g., Hillier et al., 2015; Martius et al., 2016; Bloomfield et al., 2023, 2024; Hillier et al., 2024).
The temporal dependence of multiple hazards can be quantified using different clustering techniques. Temporal clustering, also referred to as serial clustering (Mailier et al., 2006), has been widely investigated for single hazard types, mainly for extratropical cyclones in Europe (e.g., Vitolo et al., 2009; Mailier et al., 2006; Pinto et al., 2013, 2016; Karremann et al., 2014; Dacre and Pinto, 2020) and heavy precipitation at various spatial scales (Barton et al., 2016; Kopp et al., 2021; Tuel and Martius, 2021b; Banfi and De Michele, 2024). There are also some studies on the serial clustering of hail (Barras et al., 2021) as well as droughts (Brunner and Stahl, 2023). The basic idea of serial clustering is to quantify the deviation of a binary time series from a homogeneous Poisson process, i.e., a Poisson process with a constant rate of occurrence. This is typically done in two different ways. The dispersion index can identify overdispersion, i.e., the overall tendency of a time series to cluster (e.g., Mailier et al., 2006; Vitolo et al., 2009; Karremann et al., 2014). Another common approach is to use Ripley's K function (e.g., Barton et al., 2016; Tuel and Martius, 2021a, b), which is a statistical metric that quantifies the average number of events around a random event in a time series.
To our knowledge, there has been no research on the identification and quantification of serial clustering considering multiple (meteorological) hazard types. We want to close this gap using insurance loss data from a building insurance company operating mainly in southwestern Germany. Although loss data only cover insured objects and do not necessarily represent societal damage, they are commonly used as a proxy, which allows us to compare between different hazard types (Hillier et al., 2015). We use a counting method to identify clustering periods and Ripley's K to assess the degree of clustering. Ripley's K, primarily used in hydrologic data analysis, is here being newly applied to impact data. Furthermore, we use two methods to identify extreme events: (1) a flexible event definition with a varying event duration and (2) a fixed definition and corresponding event duration. The flexible event definition is common in meteorological and hydrological research, whereas the fixed definition is common for insurance applications. Both methods lead to a different number of events. This is relevant, as the impact of a set of loss events on an insurance is often dependent not only on the overall loss, but also on the number of individual loss events. Reasons for this are the Solvency II European Directive as well as the structure of reinsurance contracts (Vitolo et al., 2009), which take into account the frequency of losses and therefore also the number of events.
We furthermore aim to help close the gap between the multi-hazard research domain and meteorological clustering research using impact data on multiple hazard types (i.e., multivariate extreme events) combined with observation data to categorize the events according to their meteorological drivers: pluvial, mixed, and fluvial floods; hail; convective gusts; and large-scale storms.
The objective of this study is to address the following research questions:
-
When do clusters of individual damaging hazard types as well as clusters of their serial combination occur in southwestern Germany, and is this clustering significant compared to a random process?
-
How do the degree and significance of clustering depend on the chosen duration of the event?
-
Does clustering exacerbate the impact of hydro-meteorological hazards, as measured by insured losses?
This article is structured as follows: Sect. 2 provides an overview of the datasets used to identify distinct events and their subdivision into meteorological categories, of the methods used to identify events, as well as of the methods used to identify and quantitatively assess temporal clusters. Section 3 describes how we have refined the hazard types into meteorological categories. In Sect. 4, we give an overview of the resulting loss distribution and seasonality of the events depending on their hazard type. In Sect. 5, we first explain how we combined events of different hazard types, then show and interpret the results of different metrics of clustering, (a) a counting method and (b) Ripley's K, before we discuss loss patterns and trends regarding clusters. Section 7 elaborates on the main conclusions.
This study is based on loss data (Sect. 2.1.1) from the SV Sparkassenversicherung building insurance company operating mainly in southwestern Germany and covers the period from 1986 to 2023. All data were adjusted for inflation and the number of contracts (Sect. 2.1.3), which varied substantially during the study period. Events lasting 1 or several days are identified from the loss data using two different methods (Sect. 2.2). Meteorological observations (Sect. 2.1.2) were used to assign a meteorological category to the loss data (Sect. 3).
2.1 Data
The region of Baden-Württemberg (BW) has a size of approximately 36 000 km 2 and is characterized by the broad Rhine valley to the west and the Neckar valley in the center, as well as the low mountain ranges of the Black Forest and the Swabian Jura. It represents Germany's major hail hotspot (Puskeiler et al., 2016; Kunz et al., 2020). Heavy rain, which is particularly orographically enhanced over the Black Forest, often triggers flooding in small- to medium-sized catchments (Kunz et al., 2023). Winter storms may also be impactful but are less frequent than in northern Germany, since BW is further away from storm tracks that usually originate in the North Atlantic and propagate mainly towards northwestern Europe (Dacre and Pinto, 2020).
2.1.1 Loss data
Extreme events, i.e., hydro-meteorological events leading to a major loss, are identified using data from the building insurance company SV Sparkassenversicherung.
The dataset includes residential building losses (with deductibles subtracted) and the number of claims. The data have a daily temporal resolution and were originally divided into storm, hail, and flood hazard types. During the study period, the portfolio expanded through mergers with direct insurance companies from other federal states. To determine the overall loss for BW exclusively, we correct the dataset considering only the fraction of contracts for BW. Although this means that the dataset may also contain events that did not affect BW only, this step is necessary to ensure comparability over the years. In addition, most of the contracts (around 85 % on average during the period under study) are from BW, so the resulting uncertainty is relatively low. As there is no consistent finer-spatial-resolution information (such as on the municipality level) available in our dataset, we use the spatially aggregated losses per day for the whole region. Due to the limited size of BW, we can assume that there is only a single synoptic cause of major events at the same time.
In Germany, about 95 % of all buildings are insured against storm and hail damage (GDV, 2023). Other hazards, including floods, can be insured with an additional insurance cover, the so-called elementary insurance. The coverage of this additional insurance is very heterogeneous in Germany, with a mean coverage of 54 % and an increasing overall trend over recent years, ranging from 31 % of insured buildings in Bremen to 94 % in BW (GDV, 2023). The particularly high insurance coverage in BW is mainly due to the fact that insurance was compulsory until 1994. Currently, about 60 % of all private buildings in BW are covered by the data-providing insurer. Given the high settlement density in BW (Rösch and Treffinger, 2019), we can assume that almost all events leading to significant damage are reflected in the data. We therefore did not further consider any exposure correction of the data.
2.1.2 Meteorological data
The individual definitions of the three original hazard types in the loss data (flood, storm, and hail) are not unambiguous. For example, the storm category includes both winter storms and convective gusts, which are more likely to occur in summer. Given the different environmental conditions triggering these events, which also lead to different temporal and spatial scales of the respective events, we further separate the storm and flood categories according to their main characteristics. For this subdivision (see Sect. 3), we use meteorological observations from the German Weather Service (Deutscher Wetterdienst, DWD).
For the flood hazard types, the Hydrometeorologischer Rasterdatensatz Niederschlag für Deutschland (HYRAS-DE-PRE) dataset is used. It consists of station-based regionalized daily precipitation totals for Germany interpolated to the almost equidistant 1 × 1 km2 grid of the Regionalisierung der Niederschlagshöhen (REGNIE) product (Rauthe et al., 2013; Deutscher Wetterdienst, 2024).
For the storm hazard types, the subdivision is performed using hourly measurements of surface pressure reduced to sea level (mean sea level pressure, MSLP) at selected stations from the Climate Data Center (CDC) of the Deutscher Wetterdienst (2022). Data from six different weather stations distributed across and around BW are used.
2.1.3 Data adjustment
The loss data are adjusted for both inflation and the number of contracts in the portfolio of the insurer, which varies significantly from year to year. Inflation adjustment is performed against the base year of 2022 with the so-called Gleitender Neuwertfaktor (glN), a factor commonly used in the German insurance industry (Dietz et al., 2015). This factor captures the development of construction prices as well as standard wages and is made available to insurance companies annually by the German Insurance Association. This factor reflects the actual reconstruction costs, since it captures the development of construction prices as well as standard wages, and is therefore a more accurate correction factor than the inflation factor as a whole. The inflation correction factor is defined as
Insured daily losses are then multiplied by this factor for the respective year:
The portfolio variability is adjusted as follows: following the abolition of the insurance obligation in 1994 in BW, the portfolio has declined almost continuously. We therefore additionally adjust the insured losses with a factor that captures the number of contracts (NC) in the course of time, where NCmean refers to the mean contract number over the entire time period:
The number of claims are adjusted by the ratio
as well as by the losses incurred,
These adjustments ensure comparability across the time series, so the loss data represent a solid basis for the assessment of clustering. The regional variability is assumed to be uniform due to past analyses of these data in a higher spatial resolution (not published).
2.2 Identification of major loss events
Since our intention is to analyze the temporal variability and clustering of major loss events only, we retain data above the 90th percentile (p90) based on the daily loss data. The percentile filter is applied to both the damage claims and the insured losses of the entire time series; values of zero, which relate to a loss lower than the deductible, are excluded before filtering. By using p90, we ensure that we only capture relevant meteorological hazards. Note that this percentile filtering scheme leads to a different number of events for each hazard type. Although all hazards follow strong seasonal patterns (see Sect. 4.2), percentiles are computed on an annual basis. This is because events and clusters can go beyond the limits of seasons and because, with an annual definition, the seasonal pattern within the loss data is kept.
Furthermore, as a prerequisite for applying extreme value statistics, the events are required to be independent. Towards this end and to avoid clustering on the timescale of synoptic systems (around 5 d), clustering on the timescale of a few days needs to be removed (Wilks, 2006). This is called (runs) declustering (Coles, 2001) and means, in our case, that the daily data are aggregated to events with a length of either 1 or several days. Thereby, we avoid events from the same synoptic cause appearing as distinct events, which would lead to artificial clustering.
Two different methods are used to define events: (a) the peaks-over-threshold (POT) method, a standard method of extreme value theory (Sect. 2.2.1), and (b) the hours clause (HC) method (Sect. 2.2.2), a method commonly used in the insurance industry (Mitchell-Wallace et al., 2017). We are not aware of any other study using the HC method or a comparison between POT and HC methods for insurance loss data.
2.2.1 The peaks-over-threshold (POT) method
The POT method is widely used in hydrological and meteorological research (e.g., Barton et al., 2016; Tuel and Martius, 2021a) to model extreme events. We apply it as follows: first, we filter the loss data to retain only the most damaging events above a threshold u, which in our case corresponds to p90 (see Fig. 1a). We then apply runs declustering and aggregating events above u separated by less than r days (or, more generally, time steps), i.e., count them as a single event (see Fig. 1b). A value of r = 2 is common for Central Europe regarding precipitation (Tuel and Martius, 2021a; Barton et al., 2016) and wind (Brabson and Palutikof, 2000) and therefore is used here as well. We tested a threshold of r = 3 and detected few changes (in some cases a slight reduction in the degree of clustering). For more details on the method, we refer to Barton et al. (2016). Resulting extreme events are mapped to a binary variable (i.e., we discard their actual associated losses; see Fig. 1), with a varying start and end date for each event, which can then be used as an input for the clustering analyses.
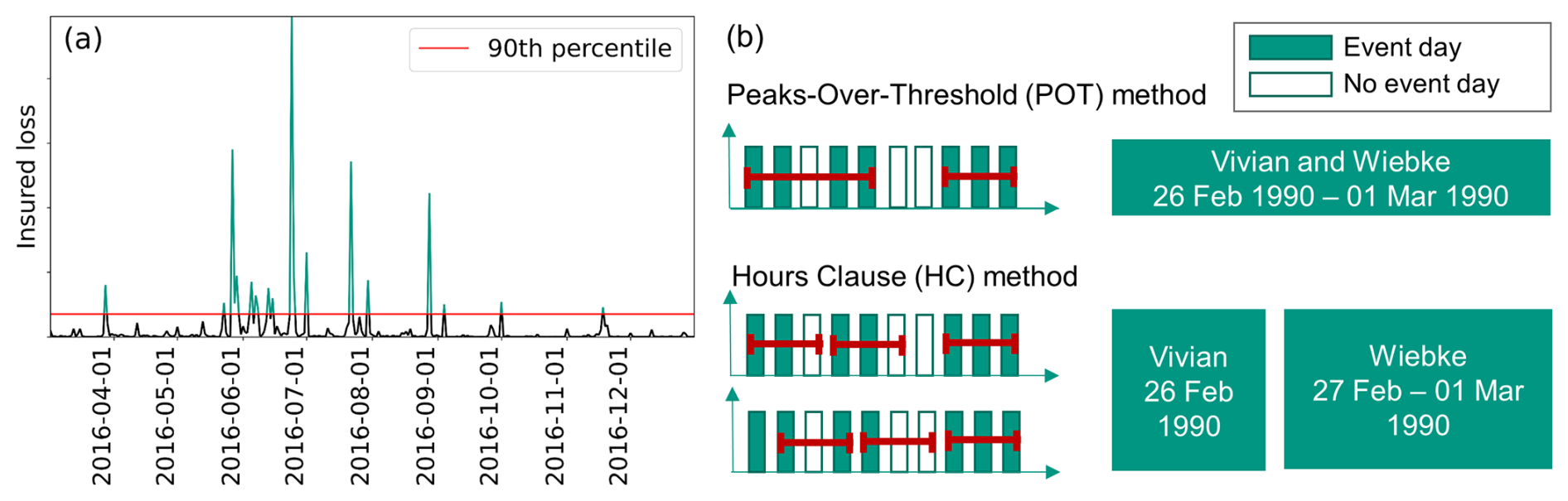
Figure 1(a) Example time series demonstrating the peaks-over-threshold (POT) method, where only events above the 90th percentile are selected, and (b) visualization of the two aggregation methods (POT; hours clause, HC): event days and non-event days are aggregated to multi-day events; a winter storm example is consequently defined as one (POT) or two (HC) events.
2.2.2 The hours clause (HC) method
The HC method is a commonly used method in the (re)insurance industry to identify individual loss events. It relies on a predetermined fixed event duration to obtain independent events. This event duration depends on the insurer as well as on the hazard type (Mitchell-Wallace et al., 2017). The maximum number of hours we are aware of is 504 h (= 21 d). Here we use an event duration of 72 h (= 3 d) for storm and hail events and 168 h (= 7 d) for flood events. These values are also used by the building insurance company providing the data. We therefore calculate running sums of losses and claims over 3 and 7 d, respectively, depending on the hazard type, and aggregate over these non-filtered time series. For periods with loss records lasting longer than the predefined number of days, the day with the maximum loss is determined as the center of an event (day 2 for storm and hail and day 4 for flood events). Additional potential data points become further events assigned around this event (ending at its first day minus 1 d or starting at its last day plus 1 d). Then, the predefined events based on moving sums are filtered using p90. From this method, we obtain a sample of major damaging events for each type with a fixed duration.
The HC and POT methods in some cases identify a different number of events. This can be seen, for example, for the severe winter storms Vivian and Wiebke in 1990, which are combined into a single event with the POT method but identified as two separate events with the HC method (see Fig. 1b). In Sect. 5, the degree of clustering in the data is evaluated and compared for both methods.
2.3 Clustering methods
We combine two methods to assess serial clustering of the events, namely a counting method (Sect. 2.3.1) and the metric Ripley's K (Sect. 2.3.2). The former is used to identify time periods with an accumulation of extremes of single and multiple hazard types, while the latter is used to assess the degree of clustering by quantifying the deviation from a homogeneous Poisson process. Since the spatial extent of the study area is rather small, we exclusively investigate clustering in the temporal dimension.
2.3.1 Counting method
To count and thereby identify clusters, we adapt a method developed by Kopp et al. (2021). We first compute the number of (filtered) events nw(t) for each hazard type and their respective combinations as well as their corresponding accumulated insured losses ilw(t) within forward-looking windows of a fixed length w for each day t of the time series Yt ().
Building on this, we apply an algorithm that identifies cluster periods as follows. First, all counted time periods across the dataset with are identified. Within that subset, the counted time period with maximum ilw is identified, which is the first cluster period. For that cluster period, the cluster start (t0) represents the day on which the first event within the cluster starts. The end of the cluster period is defined by t0+w, independently of how many further events occur during this interval. Finally, to avoid overlapping clusters, all potential further events within t0+w and t0−w are removed. If there are further periods for which , the second cluster is identified with the second highest ilw, and so forth. If no clusters of remain, the subsequent cluster is identified at . This procedure is continued until no further clusters can be identified, i.e., 2.
2.3.2 Ripley's K
To quantify the degree of clustering, we employ the statistical tool Ripley's K (Ripley, 1981), which is a function originally applied to quantify the clustering of point patterns at varying spatial scales. Ripley's K has also been applied to one-dimensional time series of meteorological or hydrological extremes (e.g., Barton et al., 2016; Tuel and Martius, 2021a, b; Brunner and Stahl, 2023). For a time series and clustering window w, Ripley's K is defined as the average number of events E(w) within a time window w (here in days) around any event in the time series,
and can be estimated, for example, by
as in, for example, Barton et al. (2016), where Yt relates to the binary time series. Ripley's K therefore quantifies the average number of events (major loss events in our case) within ±w days of an event. We let the time window w range from the timescale of a few days (note that due to the identification of independent events, K=0 for the first few days) to the seasonal level (w = 45 or w = 60, depending on the length of the season). Clustering on the seasonal timescale in our case compares the occurrence of events between different years (i.e., seasons).
As in Barton et al. (2016) and Tuel and Martius (2021a), the statistical significance of the clustering is tested by a comparison with a random homogeneous Poisson process, which consists of independent events and is therefore characterized by temporal randomness. It is simulated here by 1000 Monte Carlo runs with the same probability of occurrence (or average density of events) as the observed extremes. These simulations are also declustered, using POT for both methods of event identification. Due to the strong seasonality present in the data (see Sect. 4.2), each month is simulated separately. For each w where the observed K(w) exceeds the 95th percentile of the simulated K(w), the data are significantly clustered. Conversely, where the observed K(w) is lower than the 5th percentile of the simulated K(w), the data are significantly regularly spaced (Barton et al., 2016). Otherwise, the series cannot be statistically distinguished from a homogeneous Poisson process. For a detailed explanation of the significance analysis and p values, see Tuel and Martius (2021a). Note that this significance analysis actually determines the degree of clustering – due to seasonal patterns (see Sect. 4.2), events are likely to be surrounded by other events. The significance analysis serves the purpose of quantifying the deviation from the expected number of surrounding events and thereby provides an assessment of clustering.
Since Ripley's K function can only take one event date per event as input, we use the start of each event (identified with POT or HC) as an input time series to Ripley's K. We take only hazard types with > 20 events throughout the time series into consideration. To avoid artificial clustering caused by the recurring seasonal patterns (see Sect. 4.2), we analyze the data for specific seasons separately: May to August (MJJA) and December to February (DJF).
Before clustering, we further subdivide the storm and flood loss events in our loss dataset. In fact, both types of events can be attributed to different underlying mechanisms. Convection-driven events usually extend over a few kilometers to a few dozen kilometers only and last less than 1 h. By contrast, events that are triggered and maintained by large-scale lifting processes in the mid-troposphere usually extend across several hundreds to thousands of kilometers and may persist for several hours to several days. These two types of events will therefore affect substantially different areas, a fact which must be considered in the event definition and for the cluster analysis.
3.1 Flood damage events
A predominantly stratiform precipitation event is characterized by low to moderate rainfall intensities, a duration of several hours to days, and a large affected area, sometimes extending over several hundred kilometers (Houze, 1993). It can result in fluvial floods, i.e., rivers breaking their banks. By contrast, a convection-dominated precipitation event is characterized by high rainfall intensities combined with a short duration of a few minutes to a few hours and has a small spatial footprint. It can result in pluvial floods. However, a clear separation between these two hazard types is not always possible, in particular for mesoscale convective systems (MCSs), in which convective activity is embedded within a stratiform precipitation field (Cannon et al., 2012); for clustered convective events with a mixture of stratiform and convective precipitation primarily towards the end of the life cycle (Houze, 1993); or for orographic precipitation. The latter can attain very high precipitation totals, particularly over the low mountain ranges of the Black Forest (Kunz, 2011). Therefore, we define three categories of predominantly stratiform, predominantly convective, and mixed precipitation, typically leading to fluvial, pluvial, and mixed floods, respectively.
The most straightforward method to distinguish between these precipitation types would rely on radar data (e.g., Wang et al., 2021). However, radar data are not available for the entire period of our study. Therefore, we use gridded daily precipitation totals from HYRAS-DE-PRE during identified insurance loss events. Two metrics are considered for the separation between the precipitation types: the 99th percentile and the coefficient of variation (CV) of daily gridded precipitation totals (calculated in space). The CV, also called normalized standard deviation, is defined as the ratio between standard deviation σ and mean μ (Abdi, 2010):
For CV(t), only grid points with precipitation (i.e., > 0 mm) are considered.
In order for a day t to be classified as convection-dominated (associated with pluvial flooding), the following conditions must be met: (i) the spatial 99th percentile of daily precipitation totals exceeds 40 mm for any day from t−2 to t, (ii) CV(t) is larger than or equal to 0.55 mm, and (iii) t is between 1 April and 30 September (since convective activity primarily occurs during the summer months in Germany; Kunz, 2007; Mohr et al., 2017). We go back up to t−2 because of a potential time lag between the precipitation and the flood damage, particularly in the case of a stratiform-dominated event or for heavy rain around midnight. Remaining days are categorized as mixed floods if CV(t) > 0.45 mm, and otherwise they are categorized as stratiform-dominated (fluvial flood) events if the mean precipitation between all grid points is larger than 2 mm for that day. These thresholds were selected and extensively tested by comparison to radar images from DWD (available after 2005).
Of course, the above-described criteria do not separate all events clearly. Therefore, uncategorizable events – mainly those around the two defined thresholds – were visually checked and reassigned with expert knowledge partly in combination with the existing literature (e.g., Kunz, 2003) as well as by taking into account the terrain height (e.g., Brommundt and Bárdossy, 2007). In cases of multi-day events, the hazard type of the day with the largest precipitation totals in the (spatial) 99th percentile was assigned to the entire multi-day event. Hereinafter, we refer to the stratiform-dominated flood hazard as fluvial flood, to the mixed flood hazard as mixed flood, and to the convection-dominated flood hazard as pluvial flood.
3.2 Storm damage events
Damaging hazard types related to the storm category are typically either so-called windstorms/extratropical cyclones that extend on a synoptic scale (around 1000 km) or (severe) convective gusts that have much smaller spatial scales (tens of km) (Markowski and Richardson, 2011). As with precipitation, insured losses categorized as storm damage can also result from the interaction of local- and large-scale processes. During the passage of cold fronts of winter storms, for example, convection can strengthen surface winds by convection-driven downbursts (Markowski and Richardson, 2011; Mohr et al., 2017). In the case of convective gusts, the vertical transport of horizontal momentum increases convective gusts at the surface. However, all these processes occur on a local scale and cannot be simply estimated from available observation data. In addition, our main purpose here is to separate between damage created by the different triggering mechanisms, which presumably feature different clustering characteristics. For these two reasons, we only distinguish between synoptic- and convection-driven storms and do not consider a mixed class for storm events as we do for the flood hazard.
To differentiate between these two main storm hazard types, we use the method of Mohr et al. (2017) using the MSLP gradient between selected weather stations. We consider hourly MSLP observations from six DWD weather stations available from the CDC for the entire investigation period. For three axes across BW, station pairs were created: northwest–northeast (stations Karlsruhe/Rheinstetten and Weißenburg-Emetzheim), southwest–southeast (stations Freiburg and Lechfeld), and north–south (stations Michelstadt-Vielbrunn and Konstanz). For each of these pairs, we compute the MSLP gradient as the ratio of the difference in MSLP to the distance between the stations. If, between any station pair at any time on a specific day, this MSLP gradient exceeds a threshold of 3 Pa km−1, the day is defined as a synoptic-storm day. Otherwise, it is classified as a convective-gust day. The threshold was slightly reduced compared to that of Mohr et al. (2017) after testing with severe winter storms in recent years. For multi-day events, if any day is classified as synoptic, we classify the entire multi-day event as synoptic. If this condition does not hold true, the event is defined as convective. In the following, we refer to storms with a synoptic trigger as large-scale storms and to convection-driven storms as convective gusts.
Before presenting the results of the clustering methods, this section gives an overview of the loss dataset we use, in particular the distribution of losses and their seasonality. If not stated otherwise, events are identified using the POT method for these analyses.
4.1 General loss distribution
Regarding cumulative insured losses and damage claims, two large-scale storms and two hail events (Fig. 2a) were responsible for 30 % of the total cumulative insured losses in the entire period (18 % of all claims). More generally, only 3 % of events are responsible for 86 % of the insured losses throughout the time series. Similarly skewed distributions are found for Europe between 1980–2022, where 1 % of all climate-related events account for 28 % of insured losses (European Environment Agency, 2023).
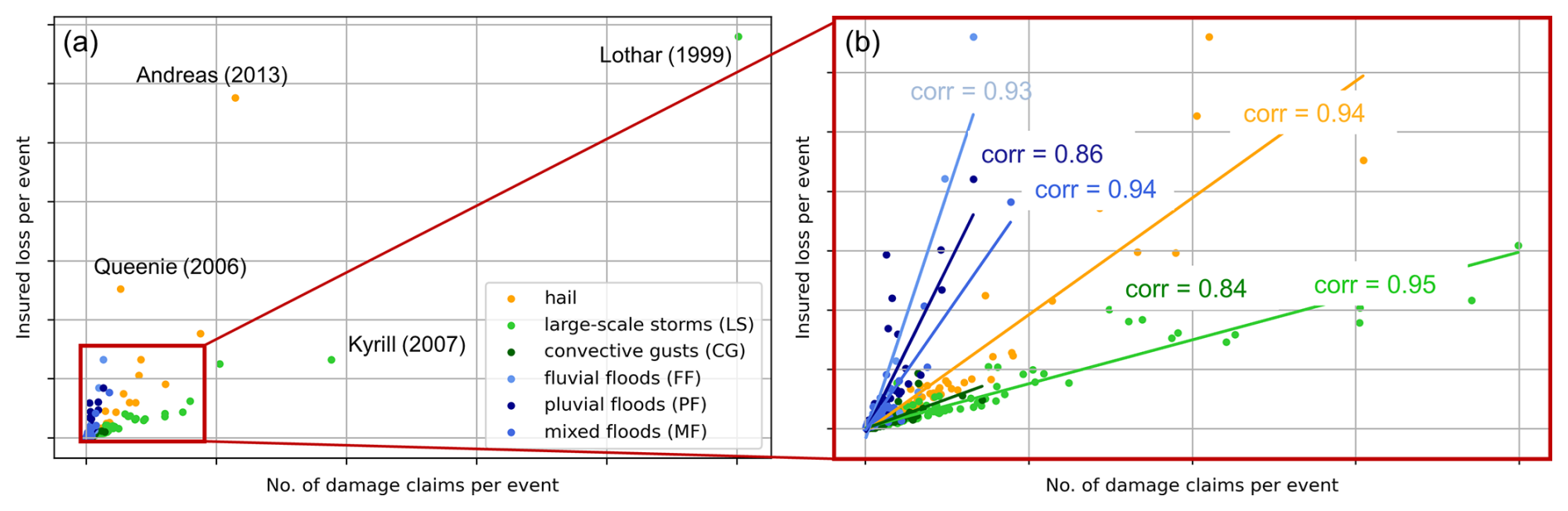
Figure 2(a) Total insured losses versus number of claims for building insurance for hail damage; damage by convective gusts and large-scale storms; and pluvial, fluvial, and mixed flood damage, in BW from 1986 to 2023, with events defined and aggregated using p90 and POT. Four of the most damaging events in terms of losses and/or claims are indicated. (b) As in panel (a) but without major damaging events, including the linear fit and Pearson correlation coefficient for the respective hazard type.
When removing major events (Fig. 2b), we find that the amount of insured losses is strongly related to the number of damage claims per hazard type. Indeed, insured losses show a high correlation with the number of claims, especially for large-scale storms (Pearson's r = 0.95), hail and mixed floods (r = 0.94), and fluvial floods (r = 0.93), and their relationship can be described by a linear function for each hazard type. This has important implications for insurance loss modeling, notably to set risk premiums.
These relationships imply that the mean loss per claim for each hazard type does not vary significantly with the extent of an event, even in the case of events that affect a large area (i.e., a high number of claims). This implies that the number of damage claims could be used as a proxy to estimate total damage in the absence of loss data. Second, mean loss patterns, i.e., loss per damage claim, differ substantially depending on the hazard type. Fluvial floods cause the highest mean losses of all hazard types, while large-scale storms cause the lowest mean losses (without major events).
An explanation for the differences in mean losses could be the nature of the damaging hazard type: large-scale storms, by definition, affect a large area, much of it only suffering from low damage, e.g., some removed roof tiles. By contrast, hail events occur locally and have higher damage potential, since more parts of a building become susceptible (Stucki and Egli, 2007). The highest mean loss for flood events might be due to a flood event being more likely, compared to hail or storm events, to affect not only the exterior, but also the interior of a house. Entire floors can get flooded once the water has entered (Merz et al., 2010), and reconstruction is a tedious and expensive undertaking (e.g., Mohr et al., 2023). This is especially relevant considering that there is no mandatory insurance against floods for residential buildings (GDV, 2023).
When investigating annual insured losses (not shown), it is evident that, in addition to the hail hazard, a relatively small number of major large-scale flood and storm events can cause extreme damage in Germany. The convective hazards, namely pluvial floods and convective gusts, are of secondary importance in our dataset in terms of the damage they cause.
4.2 Seasonality
All major damaging hazard types show a strong seasonality, with most events occurring in summer (MJJA) for most hazard types (Fig. 3). Hail damage in the winter half year is marginal compared to the summer months. Therefore, hail damage occurring between October and April was reassigned to the storm loss category prior to event identification with POT or HC.
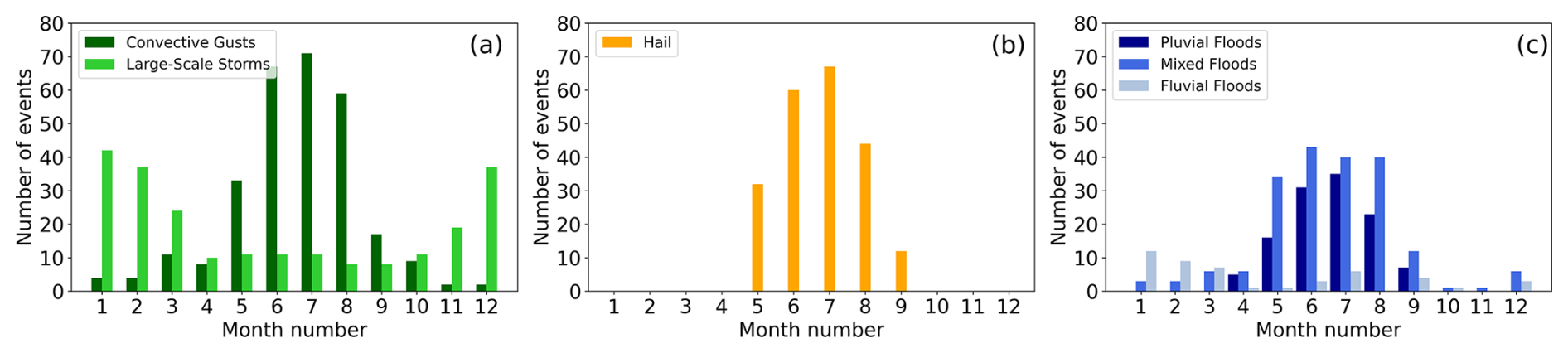
Figure 3Distribution of events identified with POT in p90 over aggregated months of (a) storm damage triggered by large-scale storms and convective gusts; (b) hail damage; and (c) flood damage triggered by pluvial, fluvial, and mixed floods in BW from 1986 to 2023.
All convection-driven hazard types, i.e., hail, convective gusts, and pluvial floods, show similar seasonality: the number of events peaks in June or July, with significantly fewer events in August and even fewer in May, when the convective season starts (Taszarek et al., 2020). In August and September, convective storms occur more frequently compared to hail, which is robust with regard to the event loss threshold (p95) but with a weaker pattern (not shown). This might indicate that the damage-related convective gusts are less likely to be accompanied by (damaging) hail in BW in late summer. Mixed floods are the most common flood hazard causing extreme damage from April to September. In contrast to the solely convection-driven events, there is a similar number of mixed flood events throughout MJJA without a strong fluctuation.
Both large-scale storms and fluvial floods occur mainly during the winter months. Damaging windstorms show a peak in DJF, which follows the general seasonal distribution of extreme wind speed (Gliksman et al., 2023). Most fluvial floods occur between January and March. Thus, we see a strong seasonal pattern of the occurrence of all hazard types, with a smaller number of large-scale events being dominant in the winter months and a higher number of local extremes being more relevant in summer.
When analyzing temporal clustering on the timescale of calendar years with POT (Fig. 4), we find that the number of damaging events varies substantially over time. There is a pronounced peak in the early 2000s for both storm hazards, a peak between 2017 and 2019 for hail events, a smaller number of storm and hail events before 1998, and an especially high inter-annual variability in the flood hazard types. The HC event definition generally identifies a smaller number of events than POT, although the general distribution of events throughout the years is similar. For both definitions, we see a kind of wave pattern throughout the years, with some years showing an exceptionally small number of events. This wave pattern could be related to decadal variability, which has been discussed with regard to hail in Europe by, e.g., Mohr et al. (2015).
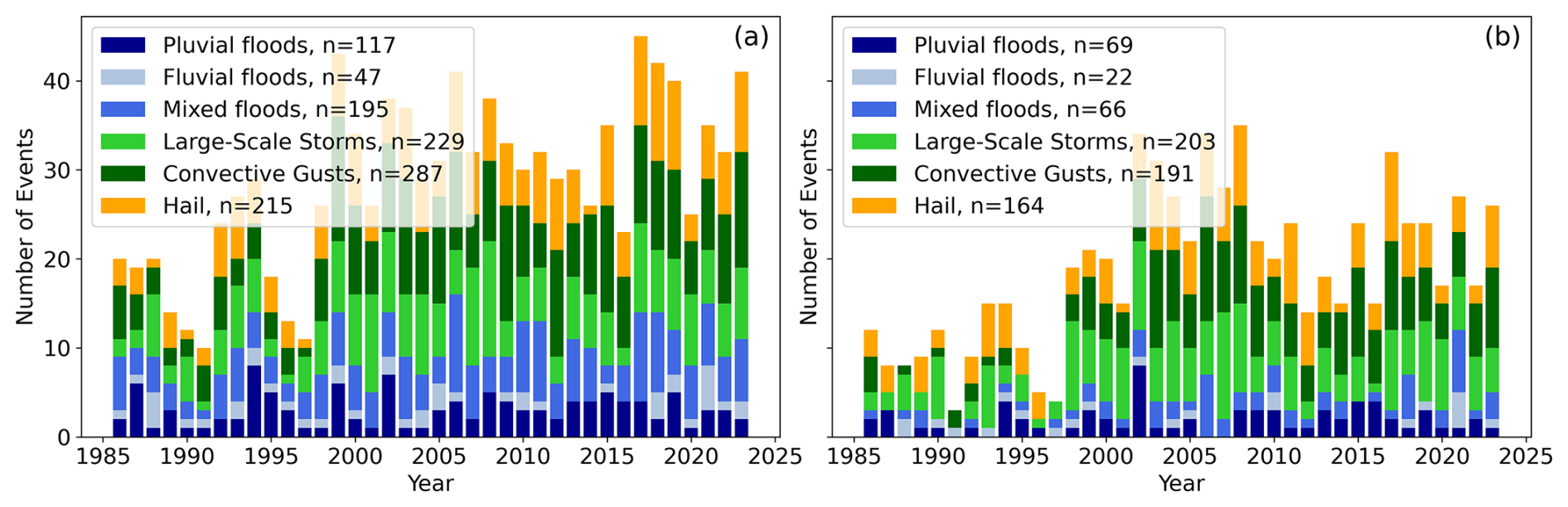
Figure 4Number of events per hazard type and year with the (a) event definition with POT and (b) event definition with HC, for events defined by the 90th percentile (see Sect. 2.2).
5.1 Combination of hazard types
Before analyzing clustering of single hazard types and their combinations, we here explain how the different hazard types are combined. Single hazard types include pluvial flood (PF), mixed flood (MF), fluvial flood (FF), large-scale storm (LS), convective gust (CG), and hail (H). We refer to the combinations between events of different hazard types by abbreviations that combine those of the single hazard types. Therefore, a combination of pluvial floods, convective gusts, and hail, for example, is referred to as PF-CG-H. All combinations between the three flood hazards and the two storm hazards as well as hail are performed. Within the storm and flood hazard types, no combinations are analyzed, since the goal is to investigate the combination of different hazard types.
When events of different hazard types are combined, they again need to be declustered to avoid artificial clustering of events from the same meteorological driver (see Sect. 2.2 for declustering of single hazard types). We perform the following procedure: first, overlaps of events are identified, where only the event with the highest losses is kept. Of the deleted events, however, the type, insured losses, and number of claims are added to the maximum loss event. Keeping all hazard types is important since, thereby, both hazard types can potentially lead to the clustering of multiple hazard types (e.g., if a hail event and convective gust event occur on the same day and another convective gust event occurs within the clustering window, this is defined as a combined cluster of hail and convective gusts only because both types are retained).
5.2 Cluster identification: counting
Figure 5 shows the resulting cluster periods for (a) single and (b) combined extremes for clustering window w=21 and events identified with POT. Clustering is analyzed on the timescale of 21 d since this is a common window for clustering analyses in the field of hydrology and includes hydrologically relevant durations. It furthermore is the longest time period of event identification with HC that we are aware of (see Sect. 2.2.2). It is evident that most clusters occur during MJJA, consistent with the seasonal distribution of the events (see also Fig. 3). These are mainly clusters of multiple hazard types, with the most damaging combination being PF-CG-H, followed by PF-H. This means that the most damaging clusters consist of three hazard types which are registered separately by the insurance company. In winter (DJF), we see a much lower number of clustered events. Predominant in this season are clusters of large-scale storms and FF-LS, which also aligns with the seasonal cycle of these hazard types.
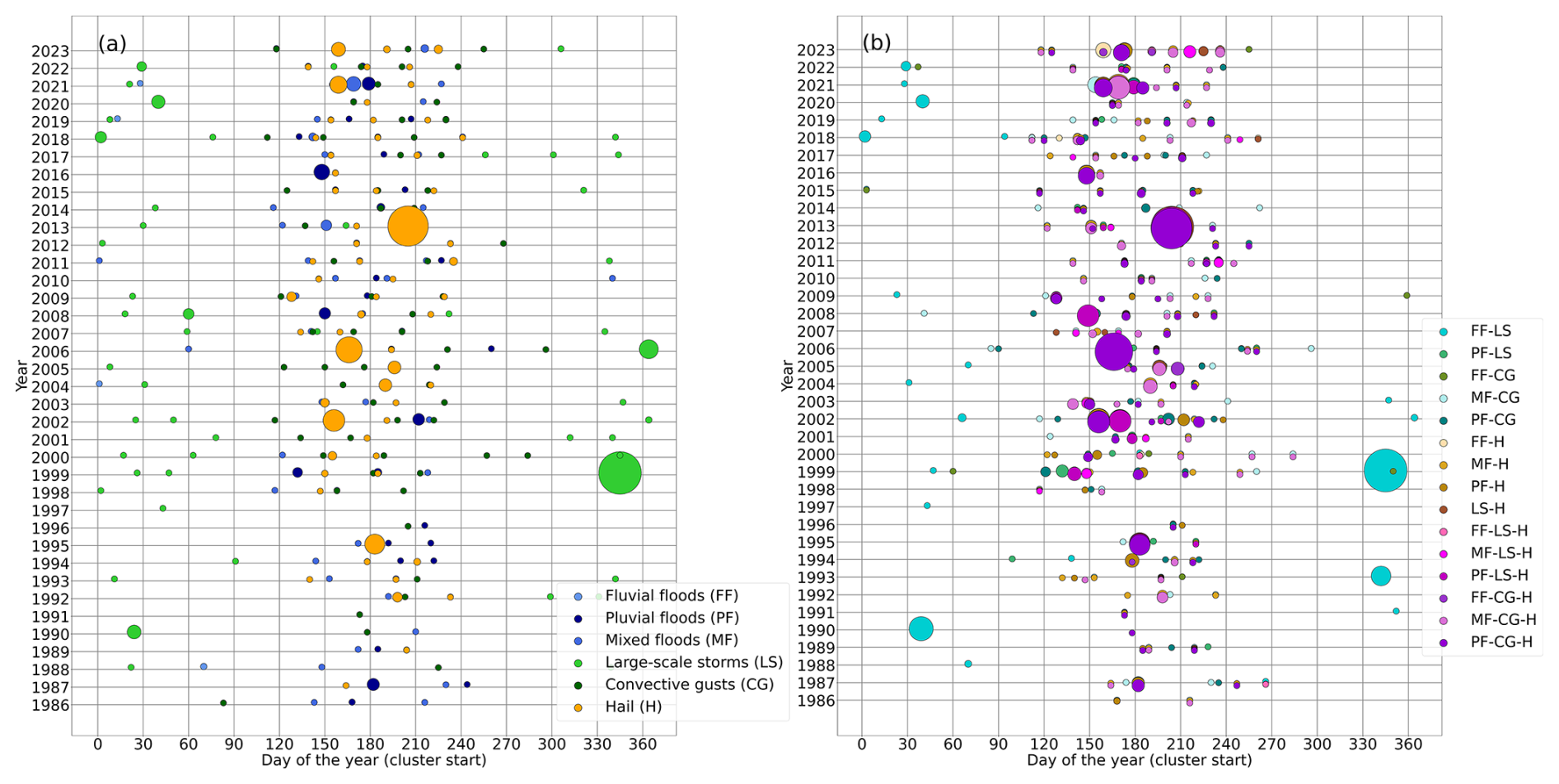
Figure 5Cluster start by the day of the year (x axis) plotted against the corresponding years (y axis), identified by the counting method with a clustering window w of 21 d for (a) single and (b) combined hazard types (p90, POT method). The size of the circles relates to the loss corresponding to each cluster (normalized).
Throughout the years, we see a peak of clusters during May–August of the early 2000s, which resembles the general pattern of event occurrence. Interestingly, this is not the case for clusters in the winter months. Winter clusters were most frequent, and also most damaging, in the 1990s as well as from 2017 on. Between 2005 and 2018, there were very few clusters of different hazard types in winter, which does not relate to a generally lower event number (cf. Fig. 4). The number of clusters in summer was also quite low in some of those years, e.g., in 2014 and 2015. Seasonal patterns are visible even more clearly with clusters of different hazard types (Fig. 4b) than with single-hazard-type clusters (Fig. 4a). There are almost no clusters between mid-February and mid-April, and similarly very few clusters between the end of September and the end of November. Note, however, that this refers to the cluster start date (e.g., clusters starting in February might contain events in March). Furthermore, it can be seen that many of the single-hazard-type clusters also occur in multi-hazard clusters, particularly the most damaging ones. This shows that many clusters consist of multiple hazard types but also include multiple occurrences of a single hazard type. Note that the number of events is much higher when assessing clustering with multiple hazard types; i.e., naturally, a higher number of clusters can be found.
When events are identified using the HC method, the number of clusters is reduced (not shown), since the number of events is also lower. However, this mainly relates to the least damaging clusters; the most severe clusters are similar to those detected with the POT method. Using the HC method, some additional clusters are detected, such as a mixed flood cluster in 2021 and several multi-hazard clusters in 2001. Hail clusters as well as those clusters leading to the highest cumulative losses when events are identified with HC are most frequent.
These results are tested for robustness by increasing the clustering window w. For w=28 d, for example, the number of clusters is higher in summer and slightly shifted to earlier start dates in winter.
5.3 Clustering assessment: Ripley's K
The number of events influences the degree of clustering in a time series (recall the differences in event numbers between POT and HC; see Fig. 4). Therefore, when applying Ripley's K, the number of events identified by POT for each hazard type is reduced, using a ranking of insured losses, until the number of events identified with HC for that hazard type is reached.
5.3.1 Clustering of single hazard types
Due to the seasonality of the events (see Sect. 4.2), we investigate large-scale storms and fluvial floods in winter (DJF) and convective gusts, pluvial and mixed floods, and hail in summer (MJJA). Generally, Ripley's K for events identified with the HC method (KHC) is significant across a broad range of timescales compared to a random series. It is also higher than Ripley's K for events identified by the POT method (KPOT; Fig. 6).
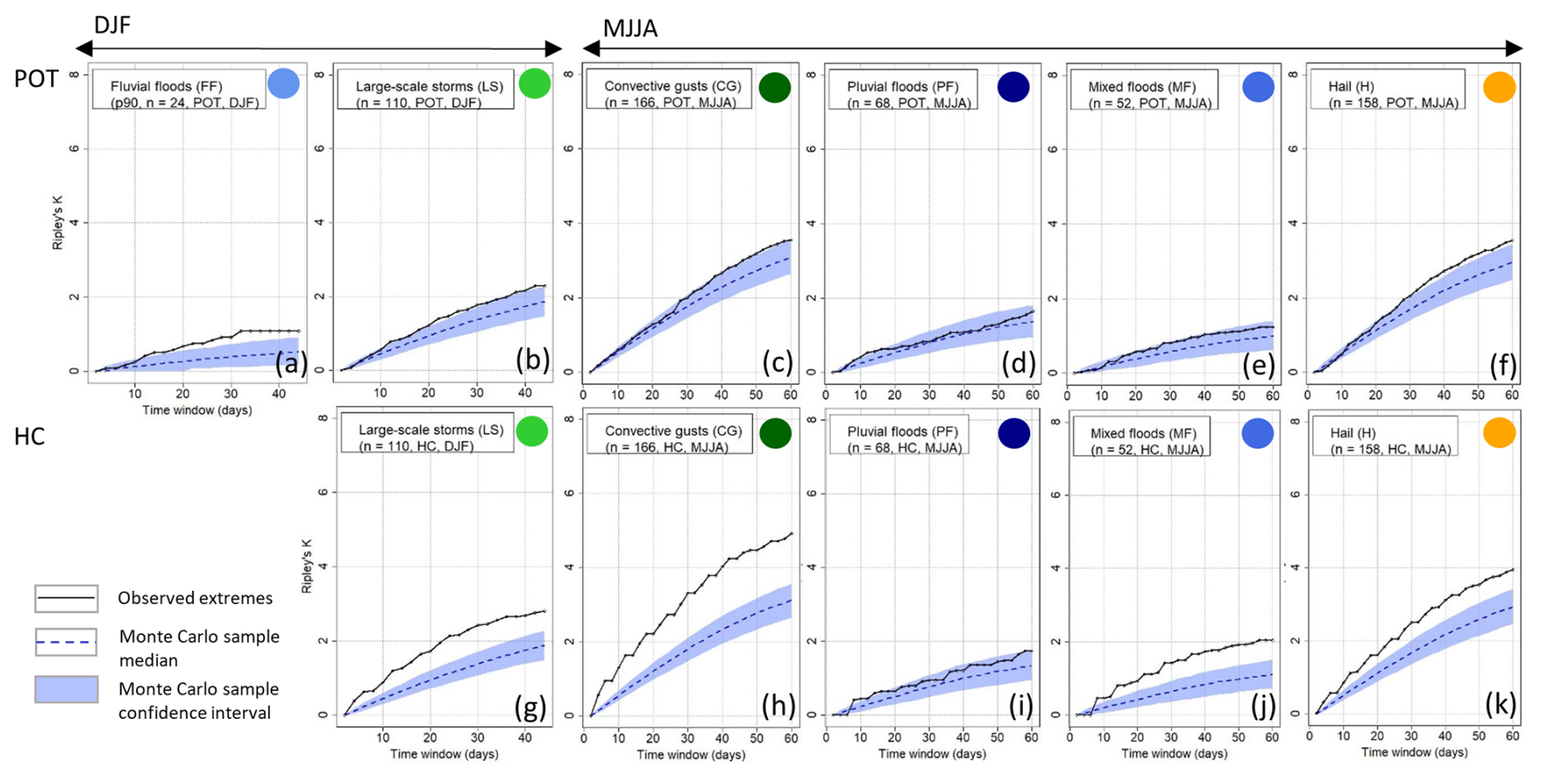
Figure 6Clustering results using Ripley's K for single hazard types: large-scale storms, pluvial floods, convective gusts, fluvial floods, mixed floods, and hail damage, depending on the season (columns) and method of event identification (rows).
Overall, the strongest clustering, which is significant compared to the 95 % confidence interval of a Monte Carlo sample (hereinafter, significant), is found for convective gusts during MJJA with KHC: at a seasonal timescale, around five additional convective gust events can be expected around a random convective gust event. However, for KPOT, i.e., a flexible event definition, the time series of convective gusts is within the 95 % confidence interval on almost all timescales and only slightly exceeds it around the seasonal scale. We see a similar pattern for mixed floods during MJJA: KHC is significant on all timescales, whereas KPOT is not significant. Pluvial floods do not cluster significantly during MJJA with both methods of event identification. Hail clusters are significant on all timescales with KHC but only from the timescale of 30 d to the seasonal level for KPOT. During DJF, fluvial floods cluster significantly on the timescale from 20 d to the seasonal level with KPOT but with low values of K, i.e., a low number of surrounding events (due to a generally low number of events). This cannot be compared to KHC because of a very small sample size (15 events). Large-scale storms during DJF cluster significantly on all timescales with KHC, and they are significant with KPOT starting from about 20 d but with a low difference from the 95 % confidence interval.
To assess the robustness of the results, we systematically changed various variables. Changing the seasonal focus from MJJA to only JJA, KPOT is not significant for convective gusts and hail. This implies that the occurrence in JJA follows a homogeneous Poisson process but clusters in those months if May is added. Interestingly, when events are identified using p95 instead of p90, we see an increased degree of significant clustering for hail and convective gusts with KPOT but a decreased degree of clustering for KHC. For the flood hazards, there is only little change. If no declustering is applied, events do cluster significantly in both seasons and for all original hazard types as defined by the insurance company (storm, hail, and flood). This shows that clustering occurs at short timescales, which is why declustering is needed. The results do not change when increasing the number of simulations for the significance test.
One reason for the increased number of significant results concerning clustering of events defined with the HC method is the duration of events. Due to the definition of HC, the duration of any event cannot be lower than 3 d (or 7 d for flood events). However, the average duration for events identified with the POT method is 1.92 d. This on average much shorter duration of events identified by POT compared to those identified by HC influences the degree of clustering. Although both methods can only approximately reproduce the actual duration of events, because of the only daily temporal resolution of the underlying loss data, it should be noted that POT is clearly more accurate because of its flexible nature. We therefore argue that by using HC, the degree of clustering is often overestimated. This furthermore proves that the (multi-day) events identified are not derived from the same weather systems, since the degree of clustering is higher with longer durations (HC method) than with short ones (POT).
In their global analysis of precipitation extremes, Tuel and Martius (2021a) find low values of Ripley's K for European regions and detect significant clustering over Europe only for a few grid cells for both DJF and JJA. For heavy precipitation events in Switzerland, defined using POT from gridded daily precipitation data, Barton et al. (2016) show similar results. For DJF and JJA, they find no significant clustering on the seasonal timescale for p95 when declustering is applied. Tuel and Martius (2021b) similarly detect low values of Ripley's K and no significant clustering of heavy precipitation for most Swiss regions during DJF and JJA. This is in line with our results for southwestern Germany, since we detect low or not significant values of Ripley's K for all three flood hazards in both DJF and MJJA.
To our knowledge, clustering of extratropical cyclones has not yet been assessed with Ripley's K but has mainly been investigated using the dispersion statistic. A statistically significant overdispersion, indicating clustering, is identified specifically in northwestern Europe, over the exit region of the North Atlantic storm track (e.g., Mailier et al., 2006; Vitolo et al., 2009), summarized in Dacre and Pinto (2020). This region however does not clearly extend to Germany. Dacre and Pinto (2020) also highlight that in Europe, more intense extratropical cyclones tend to cluster more frequently than larger samples of cyclones, including also less intense ones in Europe, as shown across multiple studies. We find contrasting results: when we decrease our sample size towards more extreme large-scale storms, we find a decreased degree of clustering.
For hail events, to our knowledge, there is no systematic assessment of temporal clustering on the seasonal scale.
5.3.2 Clustering of two hazard types
When we apply Ripley's K to a combination of two hazard types, no combination may consist of more than 80 % of a single hazard type throughout the (seasonally filtered) time series. This prevents a particular type of hazard from dominating the cluster. With this condition, the combinations of pluvial floods–convective gusts (PF-CG), mixed floods–convective gusts (MF-CG), convective gusts–hail (CG-H), mixed floods–hail (MF-H), pluvial floods–hail (PF-H), and pluvial floods–large-scale storms (PF-LS) are feasible for MJJA. For DJF, the combinations of large-scale storms–mixed floods (LS-MF) and large-scale storms–pluvial floods (LS-PF) are feasible.
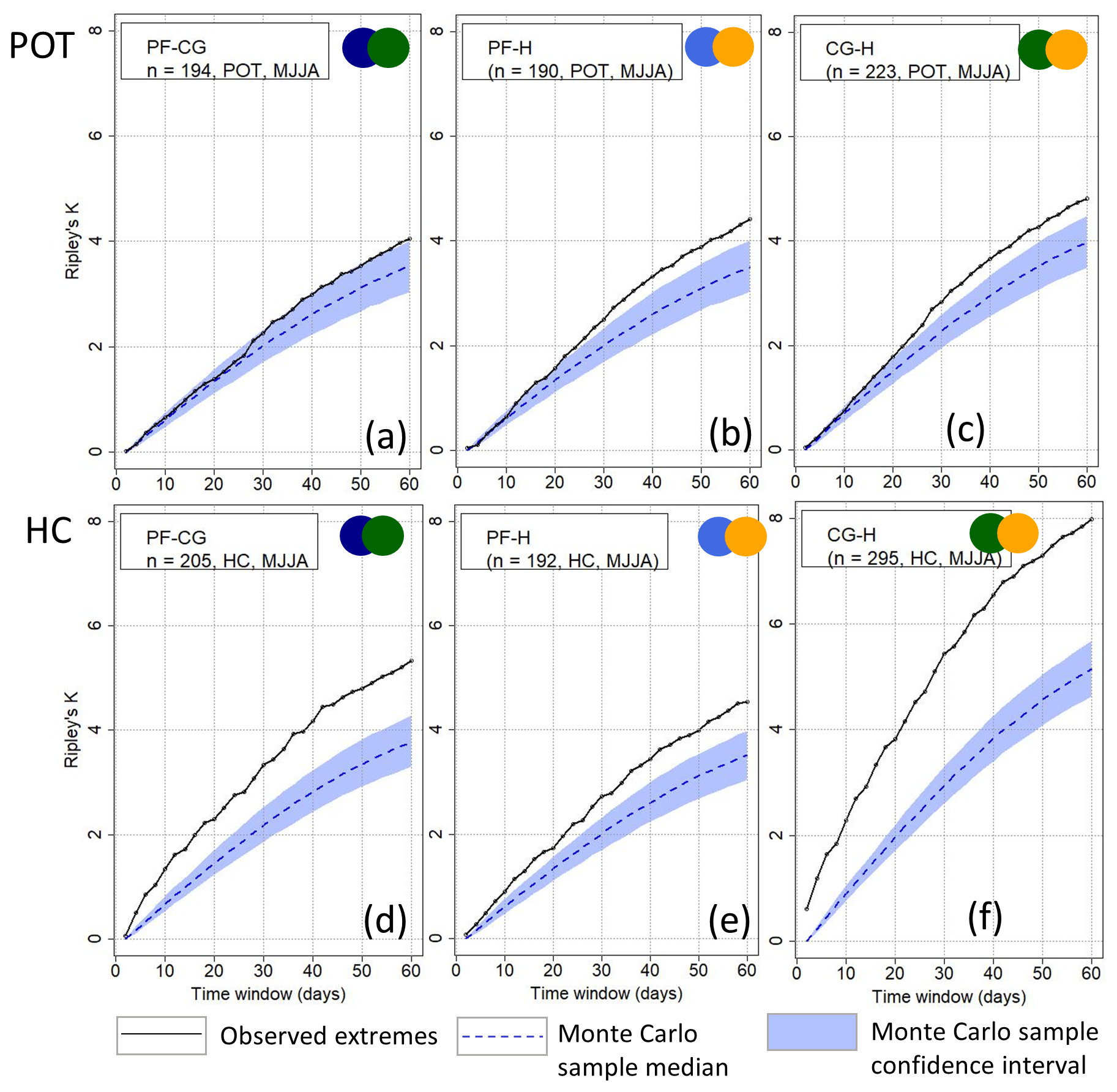
Figure 7Clustering results using Ripley's K depending on the method of event identification (rows) and during MJJA for the combination of two hazard types (part 1; see also Fig. 8) including pluvial flood (PF), hail (H), and/or convective gust (CG) events.
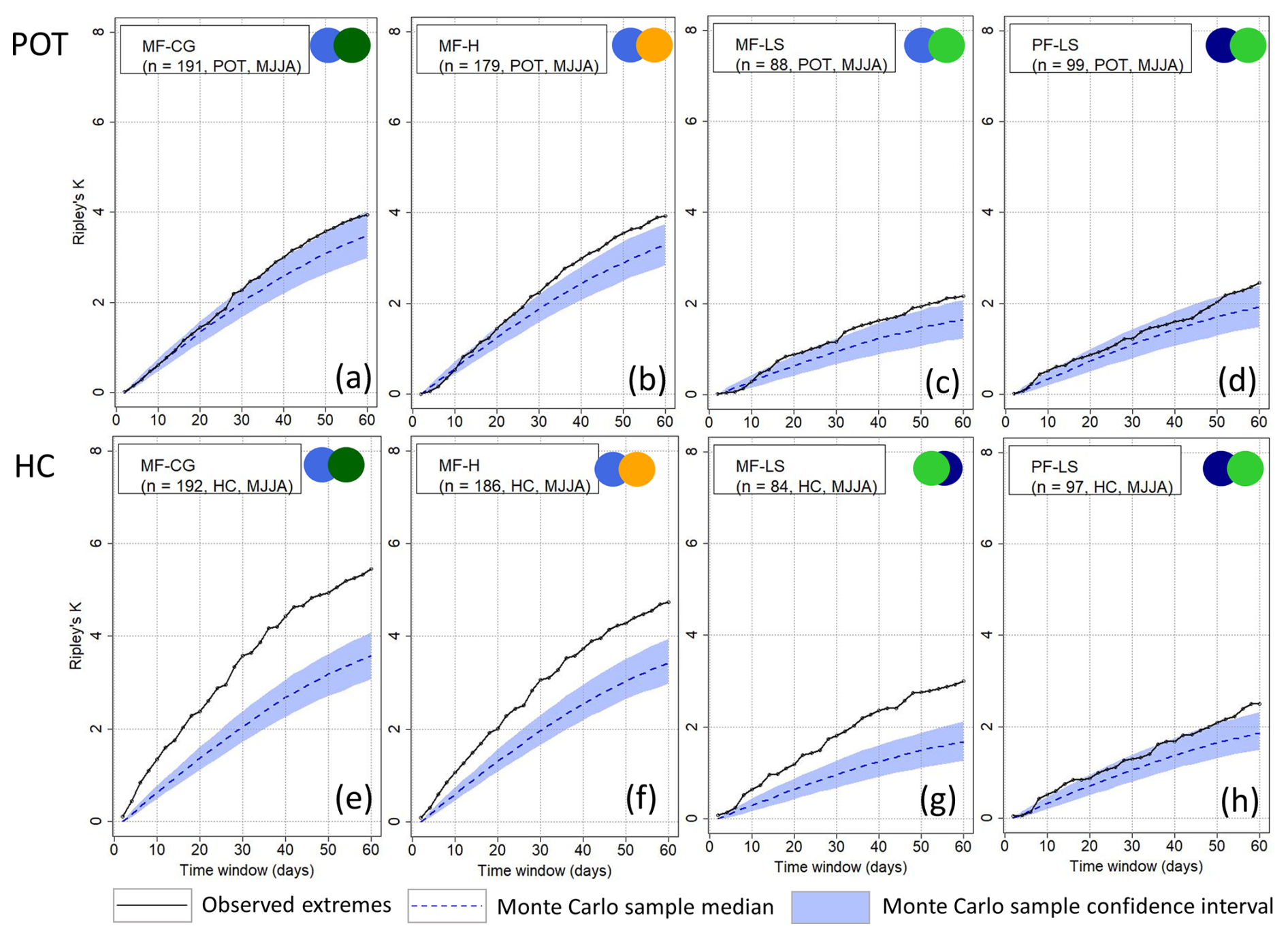
Figure 8Clustering results using Ripley's K depending on the method of event identification (rows) and during MJJA for the combination of two hazard types (part 2; see also Fig. 7) including pluvial flood (PF), mixed flood (MF), large-scale storm (LS), hail (H), and/or convective gust (CG) events.
Ripley's K results (Figs. 7 and 8) show that KHC is significant for all feasible event combinations during MJJA for all timescales from a few days to a season, with the exception of PF-LS. The degree of clustering is highest for CG-H. On average, eight events are found around a random event in the time series at the seasonal scale, which significantly deviates from a homogeneous Poisson process. This is probably not only due to the strong degree of clustering of convective gusts (see Fig. 6), but also due to the strong clustering of hail. Convective gusts and hail often occur in close succession if an unstable air mass prevails for several days. The significance of KPOT is more pronounced when two hazard types are combined compared to the single hazard types. KPOT is significant for PF-H and CG-H from the timescale of about 20 d but not for PF-CG (see Fig. 7). KPOT for MF-CG and PF-LS, respectively, does not significantly differ from a homogeneous process. For the combination of MF-H and MF-LS (see Fig. 8), KPOT is significant from about 30 d.
In summary, we see significant clustering for combinations of two hazards in MJJA for KHC. Concerning KPOT, the results suggest that combinations of two hazard types involving hail lead to clustering. The combinations cannot be quantitatively evaluated for DJF due to the low sample size. When decreasing the number of events up to the 95th percentile, the degree of clustering decreases, as with the single hazard types.
5.3.3 Clustering of three hazard types
For combinations of three hazard types, we introduce an additional condition: each hazard type must account for at least 10 % of the total event count (per season) of all three hazard types. Without this requirement, the combination could include a very small number of events from one hazard type, leading to clustering results that effectively reflect only events from the other two hazard types.
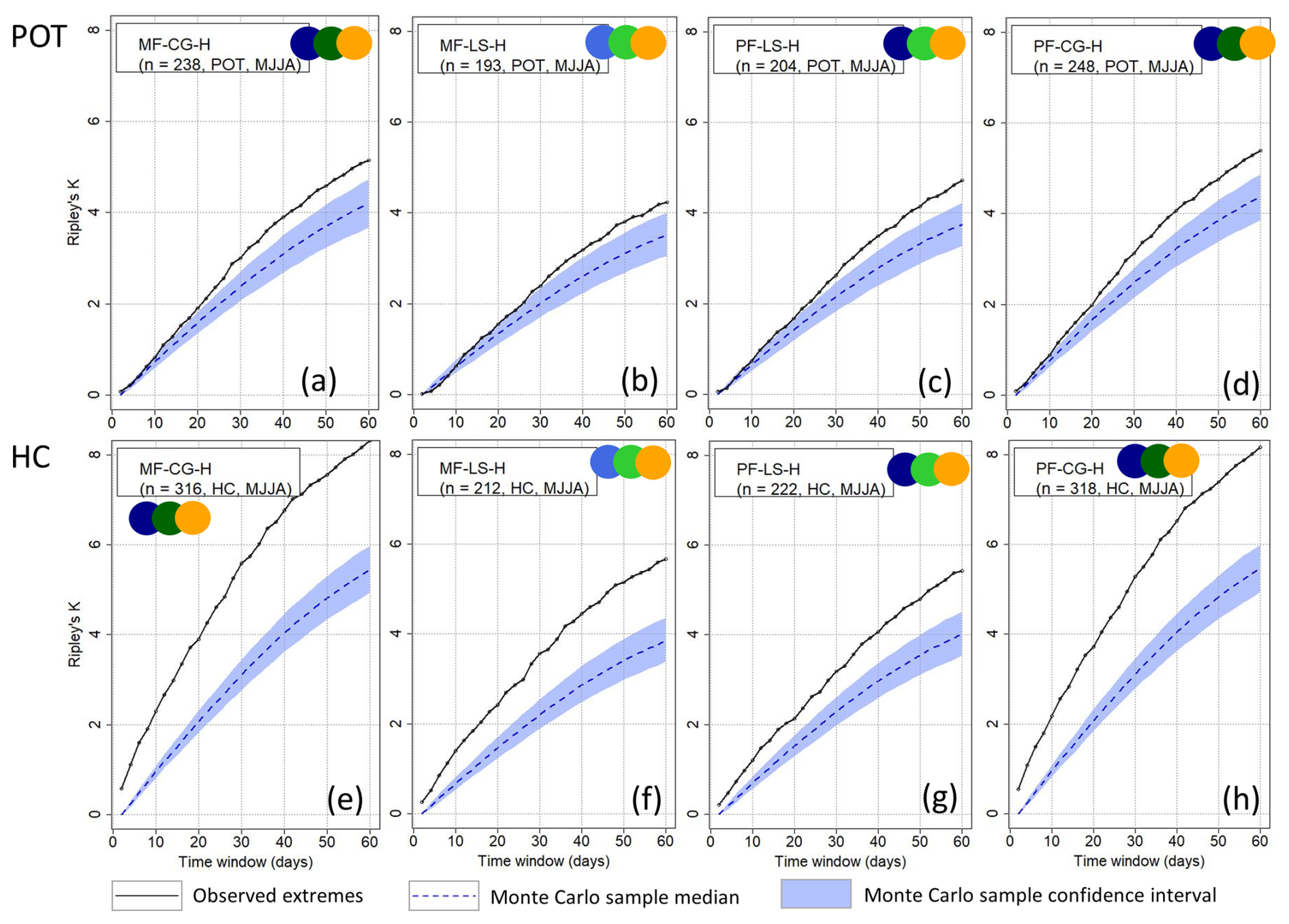
Figure 9Clustering results using Ripley's K depending on the method of event identification (rows) and during MJJA for the combination of three hazard types including pluvial flood (PF), mixed flood (MF), hail (H), large-scale storm (LS), and/or convective gust (CG).
The combinations MF-CG-H, MF-LS-H, PF-CG-H, and PF-LS-H fulfill this condition within MJJA. As with the combination of two events, KHC is higher and more often significant compared to KPOT in almost all cases, especially where CG and H are involved (Fig. 9). For the POT method, we also find significant clustering for all combinations of three hazard types, at least at the seasonal scale and starting from 10–30 d. The occurrence of combinations of three damaging hazard types during MJJA therefore differs significantly from a homogeneous Poisson process at timescales of 30 d up to a season, regardless of the definition of events. When reducing the number of extremes to p95, the degree of clustering remains similar.
Overall, for events identified by POT, the clustering of the combination of several hazard types often starts from the timescale of about 2 to 3 weeks. For Germany, Bloomfield et al. (2023) show that correlations between winter storm and flood events are highest at a monthly scale (impacted by storm clustering). Therefore, with a counting window of 21 d (see Sect. 5.2), we should be able to detect most of the clusters. It can also be seen that for KPOT, where large-scale storms, convective gusts, pluvial floods, and mixed floods do not cluster on most timescales during MJJA (Fig. 6), the combination with other hazard types increases their degree of clustering. This means that the approach of analyzing single hazard types only could overlook a cluster due to the occurrence of other hazard types.
To our knowledge, there are no other studies quantifying the degree of temporal clustering with respect to different types of (meteorological) hazards. We therefore contribute to the literature by considering a variety of meteorological hazard types related to impact data and finding that they do cluster when combined, irrespective of the event definition. We expect that these results are robust with regard to the choice of input data for this region, since we can assume that a large part of all major natural hazards are included in our impact datasets for the following reasons: firstly, population density is generally high in Germany and exceeded 100 inhabitants km−2 for all districts in Baden-Württemberg as of 2022 (Statistisches Landesamt Baden-Württemberg, 2022). Secondly, insurance coverage against all hazards included in this analysis is very high across BW, and SV Sparkassenversicherung has a high market share (see Sect. 2.1.1). Finally, by using the 90th percentile across all years, we include a large number of events (see, e.g., Fig. 4). Thereby, a major part of meteorological hazards, also in less densely populated regions with lower insured losses, should be included as well.
5.4 Loss patterns and clustering
For large-scale storms and fluvial floods during DJF, the median loss of clusters within 21 d windows (n=37) exceeds the median loss of isolated events (n=91) by a factor of 4 (not shown). This pattern also holds for clustering windows of 14 or 28 d, highlighting that multi-hazard clusters lead to higher losses during DJF compared to isolated hazards. A similar result is found for Germany overall by Xoplaki et al. (2025), who show a much higher loss ratio for residential buildings regarding co-occurring wind and precipitation extremes in winter compared to their isolated occurrence. For the UK, Hillier et al. (2015) show, based on rail data, that interactions between floods, winter storms, and shrink–swell subsidence events increase insured losses by up to 26 % yr−1.
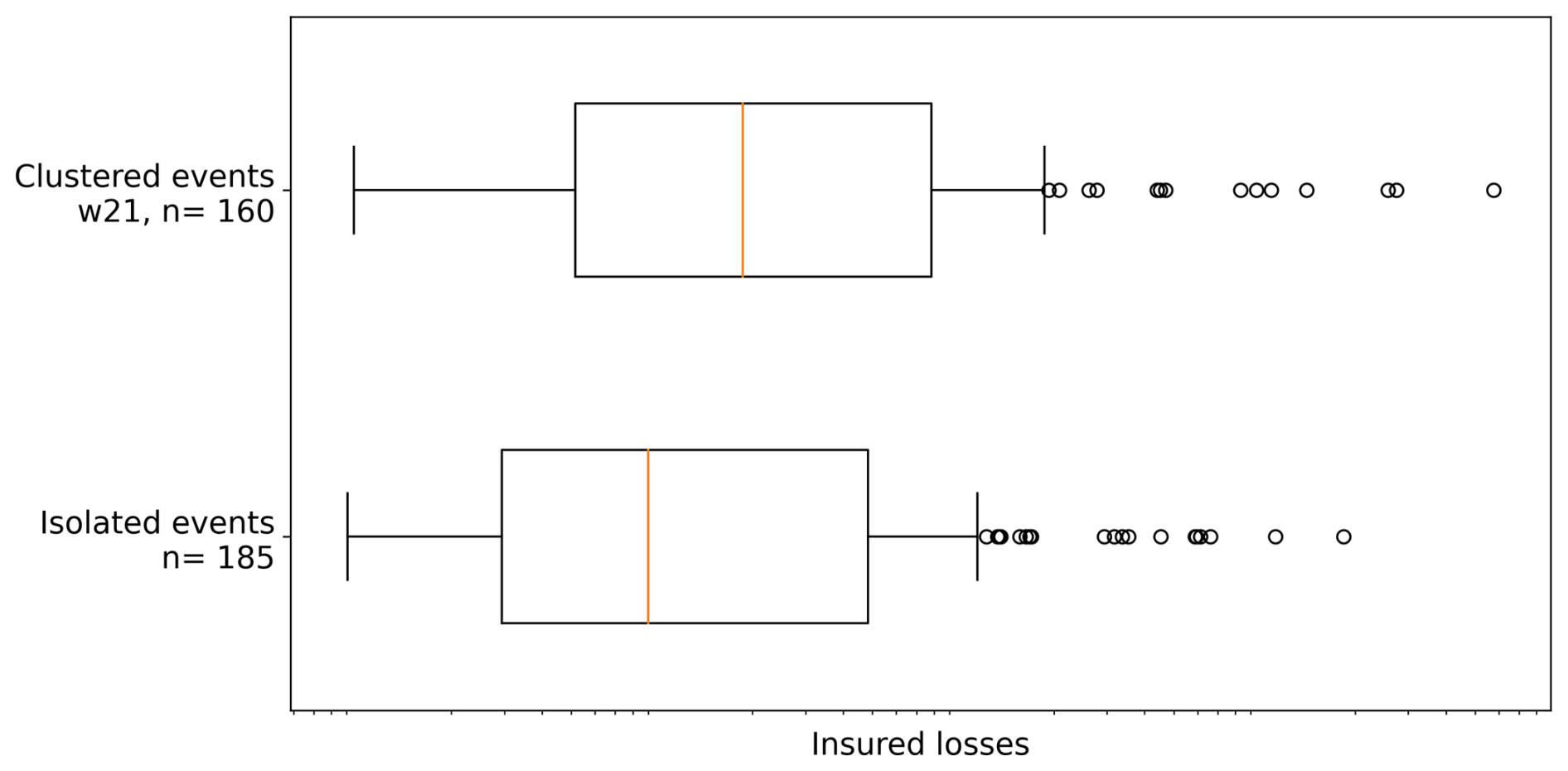
Figure 10Insured losses (logarithmic) of clustered vs. isolated extremes within a clustering window of 21 d, here related to the combination of pluvial floods, convective gusts, and hail. Loss amounts are not shown due to their confidentiality.
Figure 10 shows that this phenomenon is also present for convective clusters during MJJA: clusters of PF-CG-H lead to higher losses (median loss increased by a factor of 1) compared to the isolated occurrence of any of these hazard types. Note that this specific hazard combination also leads to the highest degree of clustering. The most damaging clustered events include, for example, the hail event Andreas on 28 July 2013 (see Fig. 2), which was accompanied by pluvial flood damage and preceded by another pluvial flood as well as convective gusts on 23 July 2013. Another cluster with high losses includes the hail event Queenie on 28 June 2006, which was accompanied by a pluvial flood and preceded by convective gusts and hail on 25 June.
The substantial amplification of losses by clusters of damaging events from different hazard types highlights the importance of considering this effect in applications such as risk modeling. This is even more important, as damaging hazards of different types frequently occur in close succession during persistent synoptic settings or weather patterns, such as blocking or an extended Atlantic trough (Grams et al., 2017), which can trigger individual extremes.
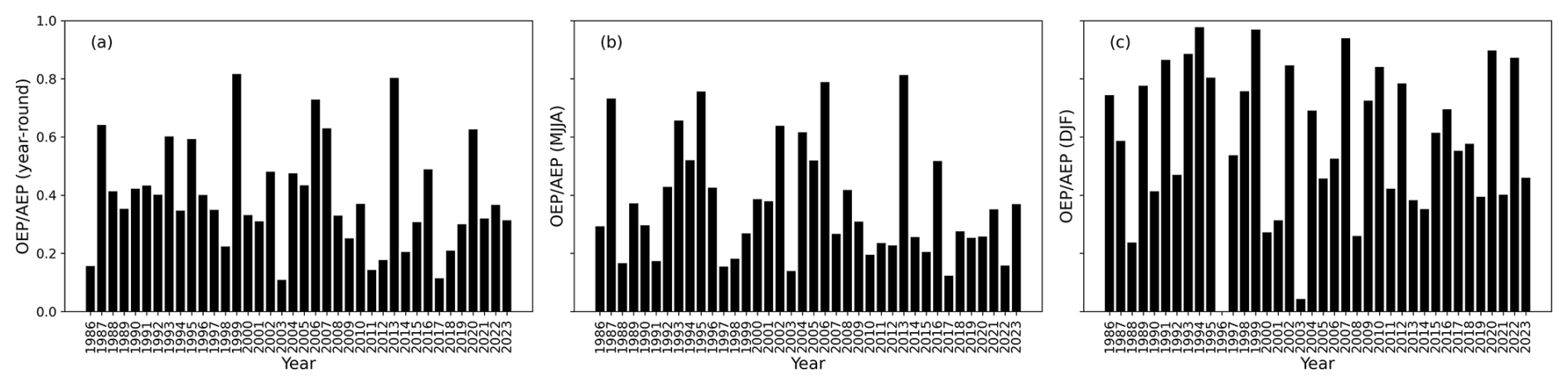
Figure 11Clustering measure of the main event contribution vs. overall losses: occurrence exceedance probability, relating to the maximum loss event in a season, vs. the aggregate exceedance probability, i.e., the (a) total annual losses or (b, c) total seasonal losses, during (b) May–August and (c) December–February.
Another common practice with insurance loss data is to assess loss clustering by comparing the losses of the most damaging event to the total losses of all events during that time period (Dacre and Pinto, 2020). Therefore, Fig. 11 shows the ratio of occurrence exceedance probability (OEP), i.e., the loss of the main event in a year, versus the annual exceedance probability (AEP), corresponding to the total losses in a year. In contrast to other studies, OEP and AEP are applied to aggregate losses across hazards. It can be seen that in certain years with major events (e.g., 1999, 2013; see also Fig. 2), the ratio of OEP AEP is about 0.8, indicating a large contribution of a single event and thus a low degree of clustering. The mean ratio of yearly OEP AEP across 1986–2023, however, equals 0.39, which means that on average, the contribution of several events is relevant to annual losses. It is also visible that the degree of clustering as measured by OEP AEP is much higher during DJF than during MJJA. When evaluated against the return period, medium loss years never exceed an OEP AEP ratio of 0.5 (not shown).
From 1986 to 2023, the number of damaging extremes in BW increased significantly, and the same can be said for clusters of damaging extremes (see Fig. 12). Note that although the linear regression only explains a limited part of the variance due to the strong annual variability, the upward trend is clearly significant (p value < 0.0001 for all events; p value = 0.0001 for clustered events). This upward trend is also significant with events that occur in clusters of 14 d. When investigating all multi-hazard clusters separately, there is a significant increase in clusters consisting of MF, CG, MF-CG, MF-H, and MF-CG-H. The number of clustered events of other hazard types or combinations does not increase significantly throughout the time frame. Note however that these upward trends are also governed by increasing values of the objects and vulnerable extensions, such as conservatories or solar panels. Additionally, throughout the entire period, both the reporting and the regulation of claims have undergone substantial changes.
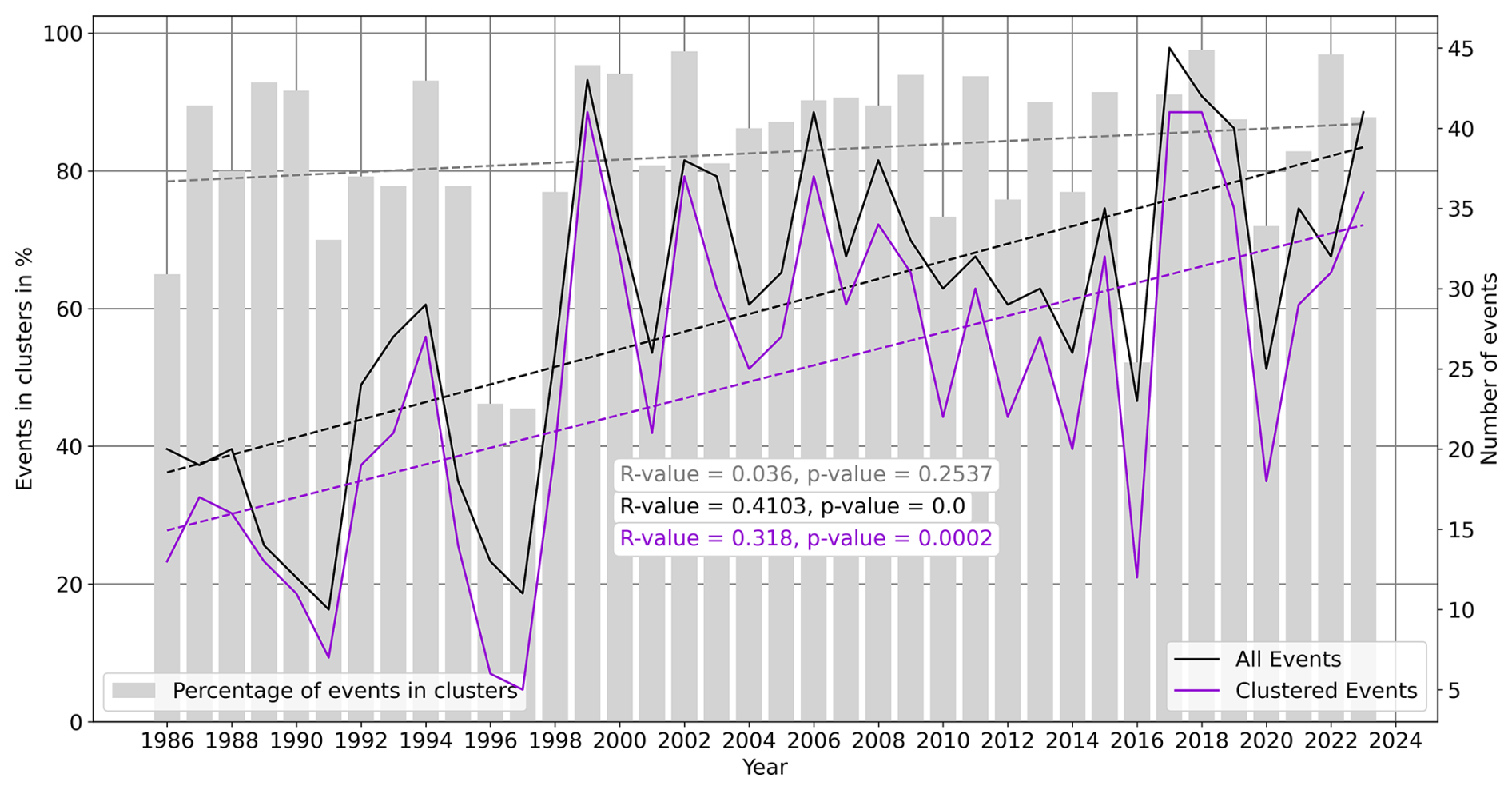
Figure 12Time series of the percentage of meteorological hazards in clusters (clustering window = 21 d) as well as the number of all events and clustered events during 1986–2023, including trend lines and significance.
Since all of the natural hazards under consideration occur seasonally, the share of events within clusters compared to all events within a year is quite high (65 % with a clustering window of 14 d, 83 % with a window of 21 d, and 86 % with a window of 28 d). However, certain years stand out: in 1996, 1997, and 2016 only half or fewer than half of the events occurred within clusters of 21 d. This share of clustered extremes compared to all extremes increased throughout 1986–2023 by about 8 %, even though this increase is statistically not significant.
The overall annual losses have also increased throughout the past years by about EUR 1.5 million per year (adjusted for inflation, not significant either). This increasing trend is also influenced by non-meteorological factors, which are partly accounted for as described in Sect. 2.1.3 and could partly not be factored in, such as changed behavior of citizens, fluctuation in insurance regulation, and a change in building vulnerability due to changing building materials. In the literature, for Germany overall, an increasing trend regarding storm and hail damage is found (GDV, 2023). Globally, there is an increasing trend of inflation-adjusted insured losses by about 6 % yr−1 (Banerjee et al., 2024).
The large-scale atmospheric circulation may play an important role in the formation and occurrence of such clustered extreme events. A teleconnection pattern describing differences in atmospheric pressure over large distances in Central Europe is the North Atlantic Oscillation (NAO). In our data, events from all hazard types in MJJA occurred mainly during a negative NAO from 1986–2023 (see Fig. A1a). Particularly in recent years, the NAO has been mainly negative during MJJA (Fig. A1b). For events during DJF, the opposite is the case (Fig. A2). Synoptic storm events, which are most frequent during DJF, occur predominantly within a positive NAO, which has become more frequent in recent years.
In this study, we have assessed the occurrence and degree of clustering of multiple meteorological hazard types (hail; pluvial, fluvial, and mixed floods; convective gusts; and windstorms) in southwestern Germany based on building insurance loss data. We have shown that random clustering of damaging meteorological hazard types and their combinations exists. Clustering mainly occurs during May–August for pluvial floods, convective gusts, and hail and during December–February for large-scale storms as well as for fluvial floods. When events are defined using the 90th percentile of insured loss and claims and using the peaks-over-threshold method, clustering is significant for hail as well as for convective gust events from about 30 d during May–August (but not for pluvial or mixed floods). Clustering is also significant for large-scale storms and fluvial floods in winter compared to a random sample. This aligns with the existing literature regarding the detection of clustering among extratropical cyclones (e.g., Dacre and Pinto, 2020) and the detection of no significant clustering regarding precipitation (e.g., Tuel and Martius, 2021a) in Europe. When two hazard types are combined, the degree of clustering is increased. Clustering is generally robust for the combination of three hazard types using a flexible event definition. This shows that clustering of multiple hazard types is a relevant phenomenon and therefore needs more consideration, since a cluster of extremes can lead to cascading impacts. These impacts, e.g., capacity problems, can also affect the insurance sector.
We have furthermore compared and evaluated different methods of declustering (event definition) using a data-driven (peaks-over-threshold) vs. a predetermined (hours clause) method. We find that when using a fixed event definition, a significant deviation from a homogeneous Poisson process is detected in almost all cases. It should however be noted that events have varying characteristics and resulting durations; the hours clause method does therefore not reflect their true occurrence. Applications in the insurance sector however often use the hours clause method to define events. From the differing clustering results with varying durations, we can see that it is important to accurately assess the actual duration of extreme events.
We find a skewed distribution of losses, where a low number of events creates a large share of the overall losses. Nonetheless, clusters of convective and large-scale hazard types in summer and winter, respectively, result in higher losses compared to their isolated occurrence. These clustered extremes have increased significantly throughout the past 38 years.
This study is unique regarding the use of impact data to assess clustering with methods that have so far been primarily used in hydrological research and regarding the use of a long time period, from 1986–2023. However, some limitations need to be taken into account: insurance data are generally dependent on how claims are regulated. Although the losses are adjusted for inflation and the number of contracts, we cannot account for changes such as policy adjustments or changes in exposed assets (e.g., solar panels on roofs), general wealth, and the susceptibility to meteorological hazards (Kron et al., 2019). However, since the loss data do not show a significant increasing trend in annual losses, these factors might be less relevant in this case. Furthermore, the damage regulation is biased towards the first day of the month, probably because of simplicity for damage regulators; this however is within the scope of the usual fluctuation for the most extreme events. A bias of insurance loss data to being fraudulent is also possible; it is however assumed to be less relevant since we only evaluate major loss events.
The study is based on comprehensive data but focuses on a limited geographic area. We therefore suggest extending the spatial scope in future studies. Furthermore, the impact we refer to is purely insurance-related and therefore monetary. Damage to critical infrastructures or municipality assets is not captured by the data. Due to a lack of comparable data, no societal impacts such as fatalities are included to measure impact. In addition, other hazard types such as cold spells, droughts, or heatwaves, which do not lead to high direct monetary (insured) damages attributed to the event, were not included. These events also usually occur on different timescales: impact-relevant durations of those hazards range from about 2 weeks to 2 months (Polt et al., 2023) and hydrological droughts cluster most strongly on the annual timescale and generally from seasonal to 3-year timescales (Brunner and Stahl, 2023). Therefore, a comparison with the present hazard types with a mean duration of less than 2 d is not sensible. It should furthermore not be neglected that there is a stochastic element within impact data, which may lead to the effect that a meteorologically relevant event at the local scale is not captured due to low population density and therefore low losses. We argue that these events are less relevant to the public, since they do not create major damage. Nevertheless, future research could be directed at analyzing these clustering patterns with larger datasets and including larger geographic scopes.
Compound hazards are often observed related to specific atmospheric patterns such as atmospheric blocking (e.g., Kautz et al., 2022). Future research could therefore be directed towards investigating the drivers of multivariate hazards, which, e.g., Bloomfield et al. (2024) did for Great Britain, where they connected daily flood–wind extremes to synoptic conditions. When atmospheric patterns related to clusters of multivariate extremes are identified, future predictions of those hazards and their joint occurrence could be enhanced. Clustering and atmospheric patterns have already been investigated regarding single hazard types by Tuel and Martius (2022a, b), Yang and Villarini (2019), and Villarini et al. (2011) for precipitation and by, e.g., Vitolo et al. (2009) for extratropical cyclones. Another interesting topic for further research would be to investigate how the clustering of different types of meteorological hazards changes due to climate change. This has been investigated for windstorms, where Karwat et al. (2024) have shown that extratropical cyclone clustering is expected to increase significantly by 25 % in Europe during 2060 to 2100. Another interesting aspect from an impact-based view would be the extension towards non-meteorological hazards and impacts, e.g., capacities of authorities and relief organizations.
We generally argue towards a holistic view of hazards, since a lot of research and its application, e.g., in insurance modeling, follow a single-hazard-type approach. Risk can only be assessed accurately if we incorporate a multi-hazard view including all relevant types of hazards, interactions, and consequences.
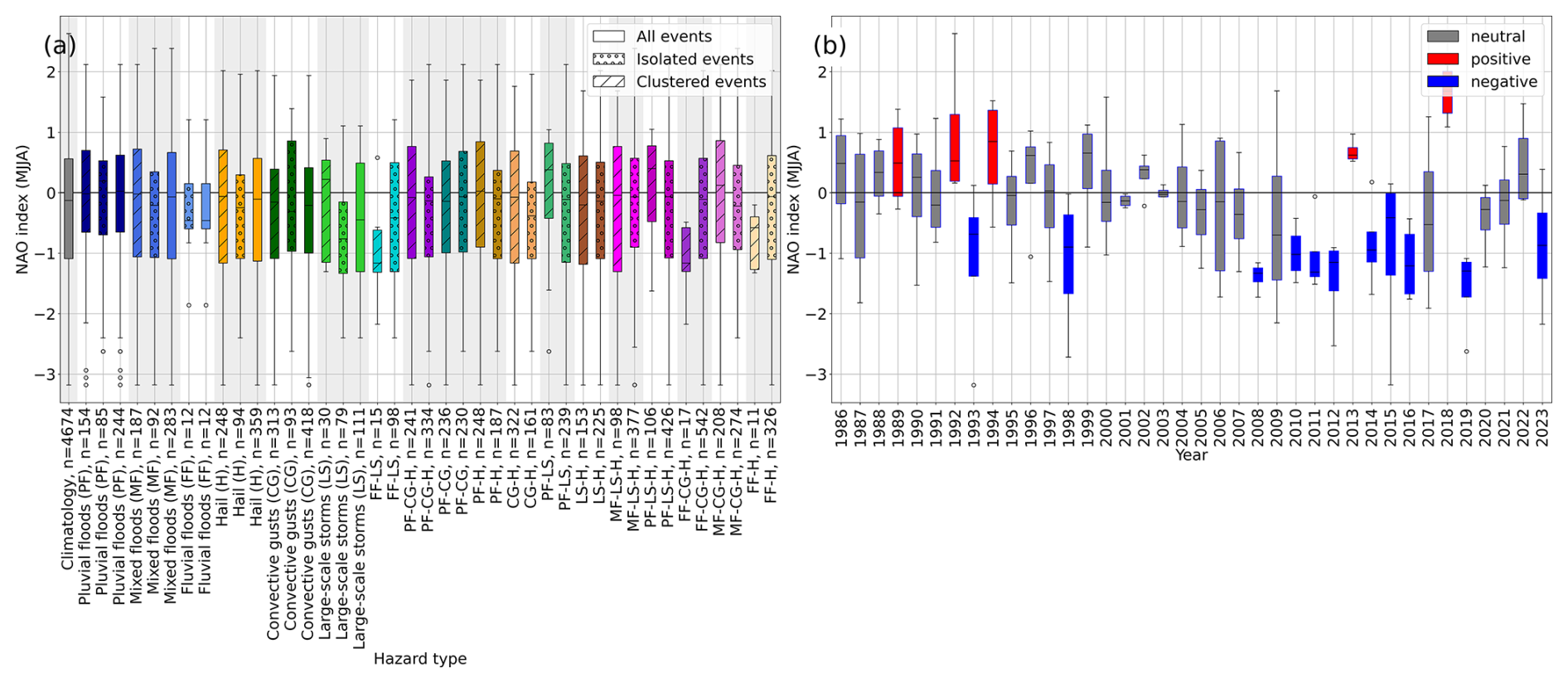
Figure A1May–August: (a) distribution of monthly NAO values during 1986–2023, depending on the event type (colors) and isolated occurrence or occurrence in clusters (hatched), and (b) monthly mean NAO values from 1986–2023. Positive NAO values are detected when mean values > 0.5 and max values > 0.75. Negative values relate to mean values < −0.5 and max values < −0.75. Neutral years are all years classified neither as positive nor as negative. Data: NOAA, available from https://www.cpc.ncep.noaa.gov/products/precip/CWlink/pna/nao.shtml (last access: 5 February 2025).
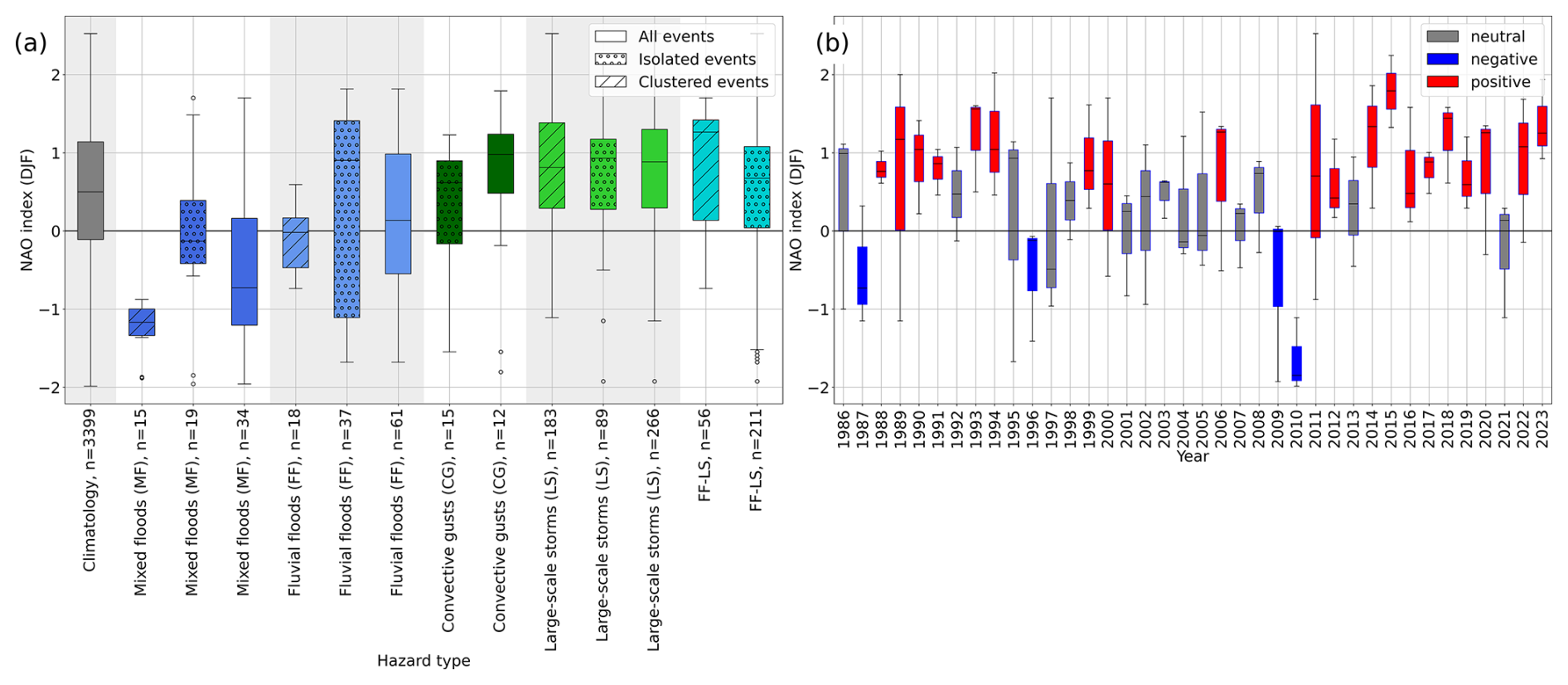
Figure A2December–February: (a) distribution of monthly NAO values during 1986–2023, depending on the event type (colors) and isolated occurrence or occurrence in clusters (hatched), and (b) monthly mean NAO values from 1986–2023. Positive NAO values are detected when mean values > 0.5 and max values > 0.75. Negative values relate to mean values < −0.5 and max values < −0.75. Neutral years are all years classified neither as positive nor as negative. Data: NOAA, available from https://www.cpc.ncep.noaa.gov/products/precip/CWlink/pna/nao.shtml.
The software code used is available at https://doi.org/10.35097/bkbwu1c6cbrqjsq6 (Küpfer, 2025). The insurance loss data by SV Sparkassenversicherung are confidential and therefore not freely available. Both the daily precipitation data (HYRAS-DE-PRE) used to refine the flood category and the hourly climate data used for subdividing the storm category are freely available at https://opendata.dwd.de/climate_environment/CDC/grids_germany/daily/hyras_de/precipitation/ (Deutscher Wetterdienst, 2022) and https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/pressure/ (Deutscher Wetterdienst, 2024).
KK: investigation, formal analysis, software, visualization, writing – original draft preparation, writing – review & editing; AT: software, writing – review & editing; MK: conceptualization, supervision, critical review of all drafts.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
This article is part of the special issue “Methodological innovations for the analysis and management of compound risk and multi-risk, including climate-related and geophysical hazards (NHESS/ESD/ESSD/GC/HESS inter-journal SI)”. It is not associated with a conference.
We would like to thank SV Sparkassenversicherung for the provision of data. Katharina Küpfer would also like to thank Susanna Mohr and Achim Gegler for their support throughout the project and Markus Augenstein and Pierre Häsler for proofreading an earlier version of this article.
This research has been supported by the Stiftung Umwelt und Schadenvorsorge (“Foundation for Protection Against Natural Hazards”, https://www.stiftung-schadenvorsorge.de/, last access: 19 August 2025) and the Helmholtz Association (Research Program “Changing Earth – Sustaining our Future”).
The article processing charges for this open-access publication were covered by the Karlsruhe Institute of Technology (KIT).
This paper was edited by Aloïs Tilloy and reviewed by Sylvie Parey, Dominik Paprotny, and one anonymous referee.
Abdi, H.: Encyclopedia of Research Design, Coefficient of Variation, SAGE Publications, Inc., Thousand Oaks, California, United States, 169–171, https://doi.org/10.4135/9781412961288, 2010. a
Banerjee, C., Bevere, L., Gabers, H., Grollimund, B., Lechner, R., and Weigel, A.: sigma 01/2024: Natural catastrophes in 2023, Tech. rep., Swiss Re Management Ltd, Swiss Re Institute, https://www.swissre.com/institute/research/sigma-research/sigma-2024-01.html (last access: 25 June 2024), 2024. a, b
Banfi, F. and De Michele, C.: Temporal Clustering of Precipitation Driving Landslides Over the Italian Territory, Earths Future, 12, e2023EF003885, https://doi.org/10.1029/2023EF003885, 2024. a
Barras, H., Martius, O., Nisi, L., Schroeer, K., Hering, A., and Germann, U.: Multi-day hail clusters and isolated hail days in Switzerland – large-scale flow conditions and precursors, Weather Clim. Dynam., 2, 1167–1185, https://doi.org/10.5194/wcd-2-1167-2021, 2021. a
Barton, Y., Giannakaki, P., Von Waldow, H., Chevalier, C., Pfahl, S., and Martius, O.: Clustering of regional-scale extreme precipitation events in southern Switzerland, Mon. Weather Rev., 144, 347–369, https://doi.org/10.1175/MWR-D-15-0205.1, 2016. a, b, c, d, e, f, g, h, i, j
Bloomfield, H. C., Hillier, J., Griffin, A., Kay, A., Shaffrey, L. C., Pianosi, F., James, R., Kumar, D., Champion, A., and Bates, P.: Co-occurring wintertime flooding and extreme wind over Europe, from daily to seasonal timescales, Wea. Clim. Extrem., 39, 100550, https://doi.org/10.1016/j.wace.2023.100550, 2023. a, b
Bloomfield, H. C., Bates, P., Shaffrey, L. C., Hillier, J., Champion, A., Cotterill, D., Pope, J. O., and Kumar, D.: Synoptic conditions conducive for compound wind-flood events in Great Britain in present and future climates, Environ. Res. Lett., 19, 024019, https://doi.org/10.1088/1748-9326/ad1cb7, 2024. a, b
Brabson, B. B. and Palutikof, J. P.: Tests of the generalized pareto distribution for predicting extreme wind speeds, J. Appl. Meteorol. Climatol., 39, 1627–1640, https://doi.org/10.1175/1520-0450(2000)039<1627:TOTGPD>2.0.CO;2, 2000. a
Brommundt, J. and Bárdossy, A.: Spatial correlation of radar and gauge precipitation data in high temporal resolution, Adv. Geosci., 10, 103–109, https://doi.org/10.5194/adgeo-10-103-2007, 2007. a
Brunner, M. I. and Stahl, K.: Temporal hydrological drought clustering varies with climate and land-surface processes, Environ. Res. Lett., 18, 034011, https://doi.org/10.1088/1748-9326/acb8ca, 2023. a, b, c
Cannon, D. J., Kirshbaum, D. J., and Gray, S. L.: Under what conditions does embedded convection enhance orographic precipitation?, Q. J. Roy. Meteor. Soc., 138, 391–406, https://doi.org/10.1002/qj.926, 2012. a
Claassen, J. N., Ward, P. J., Daniell, J., Koks, E. E., Tiggeloven, T., and de Ruiter, M. C.: A new method to compile global multi-hazard event sets, Sci. Rep., 13, 13808, https://doi.org/10.1038/s41598-023-40400-5, 2023. a
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, Springer Verlag, Berlin, Germany, https://doi.org/10.1007/978-1-4471-3675-0, 2001. a
Dacre, H. F. and Pinto, J. G.: Serial clustering of extratropical cyclones: a review of where, when and why it occurs, npj Clim. Atmos. Sci., 3, 48, https://doi.org/10.1038/s41612-020-00152-9, 2020. a, b, c, d, e, f
Deutscher Wetterdienst (DWD): Pressemitteilung: Deutschlandwetter im Sommer 2013, Deutscher Wetterdienst, https://www.dwd.de/DE/presse/pressemitteilungen/DE/2013/20130829_DeutschlandwetterimSommer.html?nn=583156 (last access: 3 September 2024), 2013. a
Deutscher Wetterdienst (DWD): HYRAS-DE-PRE: Raster data set of daily sums of precipitation in mm for Germany – HYRAS-DE-PRE, Version v5.0, DWD/CDC [data set], https://opendata.dwd.de/climate_environment/CDC/grids_germany/daily/hyras_de/precipitation/ (last access: 5 September, 2024), 2022. a, b
Deutscher Wetterdienst (DWD): Hourly station observations of pressure for Germany, version v24.03, DWD/CDC [data set], https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/pressure/ (last access: 19 August 2025), 2024. a, b
Dietz, H., Fischer, S., and Gierschek, C.: Wohngebäudeversicherung, VVW GmbH, ISBN 9783862987795, 2015. a
European Environment Agency: Economic losses from weather- and climate-related extremes in Europe, European Environment Agency, https://www.eea.europa.eu/en/analysis/indicators/economic-losses-from-climate-related (last access: 4 December 2023), 2023. a, b, c
GDV: Datenservice zum Naturgefahrenreport 2023, Tech. rep., Gesamtverband der Deutschen Versicherungswirtschaft e.V., https://www.gdv.de/resource/blob/154862/1e5f68dd03dbe238e8238632976dd59b/naturgefahrenreport-datenservice-2023-download-data.pdf (last access: 25 June 2024), 2023. a, b, c, d
GDV: Hochwasser in Süddeutschland: Schäden um die zwei Milliarden Euro erwartet, Gesamtverband der Deutschen Versicherungswirtschaft e.V., https://www.gdv.de/gdv/medien/medieninformationen/ hochwasser-suedeutschland-schadenschaetzung-versicherer-178816 (last access: 28 June 2024), 2024. a
Gliksman, D., Averbeck, P., Becker, N., Gardiner, B., Goldberg, V., Grieger, J., Handorf, D., Haustein, K., Karwat, A., Knutzen, F., Lentink, H. S., Lorenz, R., Niermann, D., Pinto, J. G., Queck, R., Ziemann, A., and Franzke, C. L. E.: Review article: A European perspective on wind and storm damage – from the meteorological background to index-based approaches to assess impacts, Nat. Hazards Earth Syst. Sci., 23, 2171–2201, https://doi.org/10.5194/nhess-23-2171-2023, 2023. a
Grams, C. M., Beerli, R., Pfenninger, S., Staffell, I., and Wernli, H.: Balancing Europe’s wind-power output through spatial deployment informed by weather regimes, Nat. Clim. Change, 7, 557–562, https://doi.org/10.1038/nclimate3338, 2017. a
Hillier, J., Bloomfield, H., Manning, C., Shaffrey, L., Bates, P., and Kumar, D.: Increasingly seasonal jet stream drives stormy episodes with joint wind-flood risk in Great Britain, EarthArXiv [preprint], https://doi.org/10.31223/X5V989, 2024. a
Hillier, J. K., Macdonald, N., Leckebusch, G. C., and Stavrinides, A.: Interactions between apparently “primary” weather-driven hazards and their cost, Environ. Res. Lett., 10, 104003, https://doi.org/10.1088/1748-9326/10/10/104003, 2015. a, b, c, d
Houze, R. A. (Ed.): Cloud Dynamics, International Geophysics Series, Academic Press, Waltham, ISBN 9780123568809, 1993. a, b
Karremann, M. K., Pinto, J. G., von Bomhard, P. J., and Klawa, M.: On the clustering of winter storm loss events over Germany, Nat. Hazards Earth Syst. Sci., 14, 2041–2052, https://doi.org/10.5194/nhess-14-2041-2014, 2014. a, b
Karwat, A., Franzke, C. L. E., Pinto, J. G., Lee, S.-S., and Blender, R.: Northern Hemisphere Extratropical Cyclone Clustering in ERA5 Reanalysis and the CESM2 Large Ensemble, J. Climate, 37, 1347–1365, https://doi.org/10.1175/JCLI-D-23-0160.1, 2024. a
Kautz, L.-A., Martius, O., Pfahl, S., Pinto, J. G., Ramos, A. M., Sousa, P. M., and Woollings, T.: Atmospheric blocking and weather extremes over the Euro-Atlantic sector – a review, Weather Clim. Dynam., 3, 305–336, https://doi.org/10.5194/wcd-3-305-2022, 2022. a
Kopp, J., Rivoire, P., Ali, S. M., Barton, Y., and Martius, O.: A novel method to identify sub-seasonal clustering episodes of extreme precipitation events and their contributions to large accumulation periods, Hydrol. Earth Syst. Sci., 25, 5153–5174, https://doi.org/10.5194/hess-25-5153-2021, 2021. a, b
Kreibich, H., Bubeck, P., Kunz, M., Mahlke, H., Parolai, S., Khazai, B., Daniell, J., Lakes, T., and Schröter, K.: A review of multiple natural hazards and risks in Germany, Nat. Hazards, 74, 1–26, https://doi.org/10.1007/s11069-014-1265-6, 2014. a, b, c
Kron, W., Löw, P., and Kundzewicz, Z. W.: Changes in risk of extreme weather events in Europe, Environ. Sci. Policy, 100, 74–83, https://doi.org/10.1016/j.envsci.2019.06.007, 2019. a, b, c
Kunz, M.: Simulation von Starkniederschlägen mit langer Andauer über Mittelgebirgen, PhD thesis, Institut für Meteorologie und Klimaforschung (IMK), Universität Karlsruhe (TH), https://doi.org/10.5445/IR/1012003, 2003. a
Kunz, M.: The skill of convective parameters and indices to predict isolated and severe thunderstorms, Nat. Hazards Earth Syst. Sci., 7, 327–342, https://doi.org/10.5194/nhess-7-327-2007, 2007. a
Kunz, M.: Characteristics of large-scale orographic precipitation in a linear perspective, J. Hydrometeorol., 12, 27–44, https://doi.org/10.1175/2010JHM1231.1, 2011. a
Kunz, M., Blahak, U., Handwerker, J., Schmidberger, M., Punge, H. J., Mohr, S., Fluck, E., and Bedka, K. M.: The severe hailstorm in southwest Germany on 28 July 2013: characteristics, impacts and meteorological conditions, Q. J. Roy. Meteor. Soc., 144, 231–250, https://doi.org/10.1002/qj.3197, 2018. a, b
Kunz, M., Wandel, J., Fluck, E., Baumstark, S., Mohr, S., and Schemm, S.: Ambient conditions prevailing during hail events in central Europe, Nat. Hazards Earth Syst. Sci., 20, 1867–1887, https://doi.org/10.5194/nhess-20-1867-2020, 2020. a
Kunz, M., Karremann, M. K., and Mohr, S.: Klimawandel in Deutschland, Auswirkungen des Klimawandels auf Starkniederschläge, Gewitter und Schneefall, Springer, Berlin, Heidelberg, 73–84, https://doi.org/10.1007/978-3-662-66696-8_7, 2023. a
Küpfer, K.: Code for Küpfer et al. 2025 (NHESS): Impact-based temporal clustering of multiple meteorological hazard types in southwestern Germany, version 1.0, RADAR [code], https://doi.org/10.35097/bkbwu1c6cbrqjsq6, 2025. a
Lee, R., White, C. J., Adnan, M. S. G., Douglas, J., Mahecha, M. D., O'Loughlin, F. E., Patelli, E., Ramos, A. M., Roberts, M. J., Martius, O., Tubaldi, E., van den Hurk, B., Ward, P. J., and Zscheischler, J.: Reclassifying historical disasters: From single to multi-hazards, Sci. Total Environ., 912, 169120, https://doi.org/10.1016/j.scitotenv.2023.169120, 2024. a
Mailier, P. J., Stephenson, D. B., Ferro, C. A., and Hodges, K. I.: Serial clustering of extratropical cyclones, Mon. Weather Rev., 134, 2224–2240, https://doi.org//10.1175/MWR3160.1, 2006. a, b, c, d
Markowski, P. and Richardson, Y.: Mesoscale Meteorology in Midlatitudes, John Wiley & Sons, Chichester, UK, ISBN 9781119966678, 2011. a, b
Martius, O., Pfahl, S., and Chevalier, C.: A global quantification of compound precipitation and wind extremes, Geophys. Res. Lett., 43, 7709–7717, https://doi.org/10.1002/2016GL070017, 2016. a, b
Merz, B., Kreibich, H., Schwarze, R., and Thieken, A.: Review article “Assessment of economic flood damage”, Nat. Hazards Earth Syst. Sci., 10, 1697–1724, https://doi.org/10.5194/nhess-10-1697-2010, 2010. a
Mitchell-Wallace, K., Jones, M., Hillier, J., and Foote, M.: Natural catastrophe risk management and modelling: A practitioner's guide, John Wiley & Sons, https://doi.org/10.1002/9781118906057, 2017. a, b, c
Mohr, S., Kunz, M., and Geyer, B.: Hail potential in Europe based on a regional climate model hindcast, Geophys. Res. Lett., 42, 10904–10912, https://doi.org/10.1002/2015GL067118, 2015. a
Mohr, S., Kunz, M., Richter, A., and Ruck, B.: Statistical characteristics of convective wind gusts in Germany, Nat. Hazards Earth Syst. Sci., 17, 957–969, https://doi.org/10.5194/nhess-17-957-2017, 2017. a, b, c, d
Mohr, S., Ehret, U., Kunz, M., Ludwig, P., Caldas-Alvarez, A., Daniell, J. E., Ehmele, F., Feldmann, H., Franca, M. J., Gattke, C., Hundhausen, M., Knippertz, P., Küpfer, K., Mühr, B., Pinto, J. G., Quinting, J., Schäfer, A. M., Scheibel, M., Seidel, F., and Wisotzky, C.: A multi-disciplinary analysis of the exceptional flood event of July 2021 in central Europe – Part 1: Event description and analysis, Nat. Hazards Earth Syst. Sci., 23, 525–551, https://doi.org/10.5194/nhess-23-525-2023, 2023. a, b, c
Mühr, B., Eisenstein, L., Pinto, J. G., Knippertz, P., Mohr, S., and Kunz, M.: CEDIM Forensic Disaster Analysis Group (FDA): Winter storm series: Ylenia, Zeynep, Antonia (int: Dudley, Eunice, Franklin) – February 2022 (NW & Central Europe), Tech. rep., Center for Disaster Management and Risk Reduction Technology (CEDIM), https://doi.org/10.5445/IR/1000143470, 2022. a
Pinto, J. G., Bellenbaum, N., Karremann, M. K., and Della-Marta, P. M.: Serial clustering of extratropical cyclones over the North Atlantic and Europe under recent and future climate conditions, J. Geophys. Res., 118, 12476–12485, https://doi.org/10.1002/2013JD020564, 2013. a
Pinto, J. G., Ulbrich, S., Economou, T., Stephenson, D. B., Karremann, M. K., and Shaffrey, L. C.: Robustness of serial clustering of extratropical cyclones to the choice of tracking method, Tellus A, 68, 32204, https://doi.org/10.3402/tellusa.v68.32204, 2016. a
Polt, K. D., Ward, P. J., Ruiter, M. d., Bogdanovich, E., Reichstein, M., Frank, D., and Orth, R.: Quantifying impact-relevant heatwave durations, Environ. Res. Lett., 18, 104005, https://doi.org/10.1088/1748-9326/acf05e, 2023. a
Priestley, M. D. K., Dacre, H. F., Shaffrey, L. C., Hodges, K. I., and Pinto, J. G.: The role of serial European windstorm clustering for extreme seasonal losses as determined from multi-centennial simulations of high-resolution global climate model data, Nat. Hazards Earth Syst. Sci., 18, 2991–3006, https://doi.org/10.5194/nhess-18-2991-2018, 2018. a
Puskeiler, M., Kunz, M., and Schmidberger, M.: Hail statistics for Germany derived from single-polarization radar data, Atmos. Res., 178–179, 459–470, https://doi.org/10.1016/j.atmosres.2016.04.014, 2016. a
Rauthe, M., Steiner, H., Riediger, U., Mazurkiewicz, A., and Gratzki, A.: A Central European precipitation climatology – Part I: Generation and validation of a high-resolution gridded daily data set (HYRAS), Metorol. Z., 22, 235–256, https://doi.org/10.1127/0941-2948/2013/0436, 2013. a
Raymond, C., Horton, R. M., Zscheischler, J., Martius, O., AghaKouchak, A., Balch, J., Bowen, S. G., Camargo, S. J., Hess, J., Kornhuber, K., Oppenheimer, M., Ruane, A. C., Wahl, T., and White, K.: Understanding and managing connected extreme events, Nat. Clim. Change, 10, 611–621, https://doi.org/10.1038/s41558-020-0790-4, 2020. a
Ripley, B. D.: Spatial statistics, Wiley Series in Probability and Statistics, John Wiley & Sons, Hoboken, NJ, USA, https://doi.org/10.1002/0471725218, 1981. a
Rösch, T. and Treffinger, P.: Cluster Analysis of Distribution Grids in Baden-Württemberg, Energies, 12, 4016, https://doi.org/10.3390/en12204016, 2019. a
Ruiter, M. C. d. and Loon, A. F. v.: The challenges of dynamic vulnerability and how to assess it, iScience, 25, 104720, https://doi.org/10.1016/j.isci.2022.104720, 2022. a
Ruiter, M. C. d., Couasnon, A., Homberg, M. J. C. v. d., Daniell, J. E., Gill, J. C., and Ward, P. J.: Why we can no longer ignore consecutive disasters, Earths Future, 8, e2019EF001425, https://doi.org/10.1029/2019EF001425, 2020. a, b
Schäfer, A., Mühr, B., Daniell, J., Ehret, U., Ehmele, F., Küpfer, K., Brand, J., Wisotzky, C., Skapski, J., Rentz, L., Mohr, S., and Kunz, M.: Hochwasser Mitteleuropa, Juli 2021 (Deutschland), Tech. Rep. 1, Center for Disaster Management and Risk Reduction Technology (CEDIM), https://doi.org/10.5445/IR/1000135730, 2021. a
Statistisches Landesamt Baden-Württemberg: Pressemitteilung 28/2022, Statistisches Landesamt Baden-Württemberg, https://www.statistik-bw.de/Presse/Pressemitteilungen/2022028 (last access: 17 December 2024), 2022. a
Stucki, M. and Egli, T.: Synthesebericht Elementarschutzregister Hagel: Untersuchungen zur Hagelgefahr und zum Widerstand der Gebäudehülle, Tech. rep., Präventionsstiftung der kantonalen Gebäudeversicherungen, Bern, 2007. a
Swiss Re: Weihnachten vor 20 Jahren: Die Stürme Lothar und Martin richten verheerende Schäden in ganz Europa an, Swiss Re, https://www.swissre.com/risk-knowledge/mitigating-climate-risk/winter-storms-in-europe/weihnachten-vor-20-jahren-die-sturme-lothar-martin.html (last access: 19 December 2024), 2019. a
Taszarek, M., Allen, J. T., Púčik, T., Hoogewind, K. A., and Brooks, H. E.: Severe Convective Storms across Europe and the United States. Part II: ERA5 Environments Associated with Lightning, Large Hail, Severe Wind, and Tornadoes, J. Climate, 33, 10263–10286, https://doi.org/10.1175/JCLI-D-20-0346.1, 2020. a
Thieken, A. H., Bessel, T., Kienzler, S., Kreibich, H., Müller, M., Pisi, S., and Schröter, K.: The flood of June 2013 in Germany: how much do we know about its impacts?, Nat. Hazards Earth Syst. Sci., 16, 1519–1540, https://doi.org/10.5194/nhess-16-1519-2016, 2016. a
Trenczek, J., Lühr, O., Eiserbeck, L., Sandhövel, M., and Leuschner, V.: Übersicht vergangener Extremwetterschäden in Deutschland, Tech. rep., Prognos AG, https://www.prognos.com/sites/default/files/2022-07/Prognos_KlimawandelfolgenDeutschland_%C3%9Cbersicht%20vergangener%20Extremwettersch%C3%A4den_AP2_1.pdf (last access: 3 September 2024), 2022. a
Tuel, A. and Martius, O.: A global perspective on the sub-seasonal clustering of precipitation extremes, Wea. Clim. Extrem., 33, 100348, https://doi.org/10.1016/j.wace.2021.100348, 2021a. a, b, c, d, e, f, g, h
Tuel, A. and Martius, O.: A climatology of sub-seasonal temporal clustering of extreme precipitation in Switzerland and its links to extreme discharge, Nat. Hazards Earth Syst. Sci., 21, 2949–2972, https://doi.org/10.5194/nhess-21-2949-2021, 2021b. a, b, c, d
Tuel, A. and Martius, O.: The influence of modes of climate variability on the sub-seasonal temporal clustering of extreme precipitation, iScience, 25, 103855, https://doi.org/10.1016/j.isci.2022.103855, 2022a. a
Tuel, A. and Martius, O.: Subseasonal temporal clustering of extreme precipitation in the northern hemisphere: Regionalization and physical drivers, J. Climate, 35, 3537–3555, https://doi.org/10.1175/JCLI-D-21-0562.1, 2022b. a
UNDRR: Report of the Open-ended Intergovernmental Expert Working Group on Indicators and Terminology relating to Disaster Risk Reduction, Tech. rep., United Nations Office for Disaster Risk Reduction (UNDRR), United Nations General Assembly, https://digitallibrary.un.org/record/852089 (last access: 3 September 2024), 2016. a
Villarini, G., Smith, J. A., Baeck, M. L., Vitolo, R., Stephenson, D. B., and Krajewski, W. F.: On the frequency of heavy rainfall for the Midwest of the United States, J. Hydrol., 400, 103–120, https://doi.org/10.1016/j.jhydrol.2011.01.027, 2011. a
Vitolo, R., Stephenson, D. B., Cook, I. M., and Mitchell-Wallace, K.: Serial clustering of intense European storms, Metorol. Z., 18, 411–424, https://doi.org/10.1127/0941-2948/2009/0393, 2009. a, b, c, d, e
Wang, Y., Tang, L., Chang, P.-L., and Tang, Y.-S.: Separation of convective and stratiform precipitation using polarimetric radar data with a support vector machine method, Atmos. Meas. Tech., 14, 185–197, https://doi.org/10.5194/amt-14-185-2021, 2021. a
Wilks, D. S.: Statistical Methods in the Atmospheric Sciences, Academic Press, ISBN 9780127519661, https://doi.org/10.1016/C2017-0-03921-6, 2006. a
Xoplaki, E., Ellsäßer, F., Grieger, J., Nissen, K. M., Pinto, J. G., Augenstein, M., Chen, T.-C., Feldmann, H., Friederichs, P., Gliksman, D., Goulier, L., Haustein, K., Heinke, J., Jach, L., Knutzen, F., Kollet, S., Luterbacher, J., Luther, N., Mohr, S., Mudersbach, C., Müller, C., Rousi, E., Simon, F., Suarez-Gutierrez, L., Szemkus, S., Vallejo-Bernal, S. M., Vlachopoulos, O., and Wolf, F.: Compound events in Germany in 2018: drivers and case studies, Nat. Hazards Earth Syst. Sci., 25, 541–564, https://doi.org/10.5194/nhess-25-541-2025, 2025. a
Yang, Z. and Villarini, G.: Examining the capability of reanalyses in capturing the temporal clustering of heavy precipitation across Europe, Clim. Dynam., 53, 1845–1857, https://doi.org/10.1007/s00382-019-04742-z, 2019. a
Zscheischler, J., Westra, S., van den Hurk, B. J. J. M., Seneviratne, S. I., Ward, P. J., Pitman, A., AghaKouchak, A., Bresch, D. N., Leonard, M., Wahl, T., and Zhang, X.: Future climate risk from compound events, Nat. Clim. Change, 8, 469–477, https://doi.org/10.1038/s41558-018-0156-3, 2018. a
- Abstract
- Introduction
- Data and methods
- Categorization into meteorological hazard types
- Loss distribution analysis
- Clustering
- Trends
- Conclusions
- Appendix A: Different hazard types and their combination in relation to the North Atlantic Oscillation (NAO)
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Data and methods
- Categorization into meteorological hazard types
- Loss distribution analysis
- Clustering
- Trends
- Conclusions
- Appendix A: Different hazard types and their combination in relation to the North Atlantic Oscillation (NAO)
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References