the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 03 Mar 2023
| 03 Mar 2023
Multi-station automatic classification of seismic signatures from the Lascar volcano database
Pablo Salazar
Franz Yupanqui
Claudio Meneses
Susana Layana
Gonzalo Yáñez
This study was aimed to build a multi-station automatic classification system for volcanic seismic signatures such as hybrid, long period, tremor, tectonic, and volcano–tectonic events. This system was based on a probabilistic model made using transfer learning, which has, as the main tool, a pre-trained convolutional network named AlexNet. We designed five experiments using different datasets with data that were real, synthetic, two different combinations of these (combined 1 and combined 2), and a balanced subset without synthetic data. The experiment presented the highest scores when a process of data augmentation was introduced into processing sequence. Thus, the lack of real data in some classes (imbalance) dramatically affected the quality of the results, because the learning step (training) was overfitted to the more numerous classes. To test the model stability with variable inputs, we implemented a k-fold cross-validation procedure. Under this approach, the results reached high predictive performance, considering that only the percentage of recognition of the tectonic events (TC) class was partially affected. The results obtained showed the performance of the probabilistic model, reaching high scores over different test datasets. The most valuable benefit of using this technique was that the use of volcano seismic signals from multiple stations provided a more generalizable model which, in the near future, can be extended to multi-volcano database systems. The impact of this work is significant in the evaluation of hazard and risk by monitoring the dynamic evolution of volcanic centers, which is crucial for understanding the stages in a volcano’s eruptive cycle.
- Article
(2465 KB) - Full-text XML
- BibTeX
- EndNote





1.1 The problem of monitoring
The task of detecting the seismic activity of an active volcano and the subsequent characterization (classification) of these events is, in many cases, the most time-consuming in observatories worldwide. This is because of the massive amount of data that are collected daily in a continuous record by a single seismic network with a few stations. In this context, big data analysis tools have become an attractive option for reaching levels of processing that have never been achieved using traditional techniques.
This study proposed the use of machine learning and transfer learning techniques to automatically classify volcanic seismic events. Determining the type of volcanic event in a continuous seismic record (time series) will facilitate the construction of a model of evolution associated with the dynamics of a volcanic center. This should create better understanding and evaluation of the hazards and risks associated with volcanic activity, improving efforts made in this matter (e.g., de Natale et al., 2019; Magrin et al., 2017; Rapolla et al., 2010). The novelty of this approach is in its use of previously trained deep convolutional networks, such as AlexNet, in a scenario that considers the information recorded by a network of multiple stations. It permits variability in the input of data and improves the generalization of the system. The generalization of the system directly impacts the performance of the training models of pattern recognition for each class and creates the possibility of applying the generated models in a common multi-volcano database system in the near future.
1.2 A summary of methods used in volcano seismic recognition
Among the classification techniques, methods based on a probabilistic approach and hidden Markov models (HMMs) are most relevant. The advantages of HMMs include the possibility of managing data with different durations, computational efficiency, and an elegant interpretation of results based on Bayes’ theorem (Carniel, 2014). Several studies have been performed on volcanic systems using this technique with different approaches. Continuous HMMs were used for the simultaneous detection and classification of continuous volcanic responses (Beyreuther and Wassermann, 2008), whereas discrete HMMs were applied to analyze and classify events as described by Ohrnberger (2001). Other applications for HMMs were considered in the works of Bebbington (2007), who used the method to analyze a catalogue of flank eruptions recorded at Mt. Etna. Hidden semi-Markov models were applied by Beyreuther and Wasserman (2011) using time dependence to improve the performance of the method. Beyreuther et al. (2012) also introduced state clustering to improve the time discretization in induced seismicity experiments. Contrastingly, Bicego et al. (2013) used an HMM method, based on a hybrid generative–discriminative classification paradigm, in pre-triggered signals recorded at the Galeras Volcano in Colombia.
Other classification techniques, such as artificial neural networks, provide an efficient approach for the classification of not only seismic events, but also time slices of continuous signals, such as volcanic tremors (Carniel, 2014). The multi-layer perceptron (MLP) is often used for the analysis of seismic signals recorded at volcanoes. Esposito et al. (2013) applied the MLP technique for landslide recognition, while Esposito et al. (2014) utilized MLP to estimate the possible trend of the seismicity level in Campi Flegrei (Italy). Self-organizing maps (SOMs), another class of artificial neural networks, have been used to analyze very long period events at the Stromboli volcano (Esposito et al., 2008), as well as volcanic tremors at the Etna volcano (Langer et al., 2009, 2011), Raoul Island volcano (Carniel et al., 2013a), and Ruapehu volcano (Carniel et al., 2013b). Furthermore, self-organizing maps with time-varying structures (SOM-TVS) have been applied to volcanic signals to achieve improvements in relation to SOMs (Araujo and Rego, 2013).
Notably, the support vector machine (SVM) approach developed by Vapnik (1995), which is based on linear discrimination, should be mentioned. For a two-class problem, SVM uses linear elements for discrimination, i.e., lines, planes, or hyperplanes. Masotti et al. (2006, 2008) used this technique in analyzing volcanic tremor data recorded at Mt. Etna in 2001. Langer et al. (2009) applied this approach to compare several supervised and unsupervised pattern-classification techniques. Ceamanos et al. (2010) built a multi-SVM classifier for remote-sensing hyperspectral data. The simultaneous application of SVM and MLP was also performed by Giacco et al. (2009), who used the two methods to discriminate between explosion quakes, landslides, and tremors recorded at the Stromboli volcano.
Thus, numerous studies have been conducted to develop an automated system for the detection and classification of volcanic signals. The early systems consisted of classifiers that used data from a single station to design different approaches (Masotti et al., 2006; Beyreuther and Wassermann, 2008; Rouland et al., 2009; Langer et al., 2011; Bicego et al., 2015). However, after some years, the systems evolved into more complex algorithms that facilitated the building of models using the information from a few stations or channels (Z, E, N). Nevertheless, they did not use the data from all the possible stations in the network, instead their results were based on one station or channel that was used as a pattern (Álvarez et al., 2012; Esposito et al., 2013; Carniel et al., 2013b; Cortés et al., 2014, 2015; Curilem et al., 2014a, b; Bicego et al., 2015). Interestingly, the work of Curilem et al. (2016), based on station-dependent classifiers, shows the possibility to mix information from different stations to create models that enable the classification of events at different stations, despite the fact that experiments were performed with a reduced database.
1.3 Supervised machine learning as strategy for automatization
The systems that allow us to build probabilistic models for an automatic classification of volcanic event are called Volcano–Seismic Recognition (VRS). The probabilistic models are built from data determined previously by an expert geophysicist. The models obtained are later used over continuous seismic records for automatic and unsupervised classification.
As previously mentioned, pattern recognition and automatic classification require the previous classification of seismic signals into different classes, making this one of the most important, but also one of the most time-consuming, tasks when accomplished daily by a human operator.
The study was aimed to present a novel approach that considered a supervised machine-learning strategy (transfer learning) using AlexNet, a previously trained deep convolutional neural network, to create a multi-station automatic classification system for volcanic seismic signatures.
Transfer learning for deep neural networks is the process of first training a base network on a source dataset and then transferring the learned features (network weights) to a second network to receive training on a target-related dataset. From a practical point of view, the reuse or transfer of information from previously learned tasks for the learning of new tasks has the potential to significantly improve the efficiency of a reinforcement learning agent.
AlexNet was the first convolutional network which used GPU to boost performance. Its architecture consists of five convolutional layers, three max-pooling layers, two normalization layers, two fully connected layers, and one softmax layer (Zulkeflie et al., 2019). Each convolutional layer consists of convolutional filters and a nonlinear activation function ReLU. The pooling layers are used to perform max pooling. Input size is fixed due to the presence of fully connected layers and is mentioned at most of the places as . However, due to some padding it works out to be . Overall, AlexNet has 60 million parameters.
In 2012, AlexNet won the ImageNet visual object recognition challenge, i.e., the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) (Krizhevsky et al., 2012). The numbers of classes to be classified by the ImageNet dataset consist of 1000. Therefore the final fully connected layer also contains 1000 neurons. The ReLU activation function is implemented to the first seven layers, respectively. A dropout ratio of 0.5 is applied to the sixth and seventh layer. The eighth layer output is finally supplied to a softmax function. Dropout is a regularization technique, being used to overcome the overfitting problem that remains a challenge in a deep neural network. Thus, it reduces the training time for each epoch.
The main characteristics of AlexNet implementation can be summarized in four aspects: (a) data augmentation is carried out to reduce overfitting. This data augmentation includes mirroring and cropping the images to increase the variation in the training dataset. The network uses an overlapped max-pooling layer after the first, second, and fifth CONV (convolutional) layers. Overlapped maxpool layers are simply maxpool layers with strides less than the window size. The 3×3 maxpool layer is used with a stride of two, hence creating overlapped receptive fields. This overlapping improved the top-one and top-five errors by 0.4 % and 0.3 %, respectively. (b) Before AlexNet, the most commonly used activation functions were sigmoid and tanh. Due to the saturated nature of these functions, they suffer from the vanishing gradient (VG) problem and make it difficult for the network to train. AlexNet uses the ReLU activation function which does not suffer from the VG problem. The original paper (Krizhevsky et al., 2012) showed that the network with ReLU achieved a 25 % error rate about 6 times faster than the same network with tanh non-linearity. (c) Although ReLU helps with the vanishing gradient problem, due to its unbounded nature the learned variables can become unnecessarily high. To prevent this, AlexNet introduced local response normalization (LRN). The idea behind LRN is to carry out a normalization in a neighborhood of pixels by amplifying the excited neuron while dampening the surrounding neurons at the same time. (d) AlexNet also addresses the overfitting problem by using drop-out layers where a connection is dropped during training with a probability of p=0.5. Although this avoids the network from overfitting by helping it escape from bad local minima, the number of iterations required for convergence is doubled.
2.1 Seismic monitoring of Lascar volcano
The Lascar volcano (23∘22′ S, 67∘44′ W; 5.592 m a.s.l.) is located in northern Chile, 270 km NE from Antofagasta and 70 km SE from San Pedro de Atacama, on the western border of the Altiplano-Puna “plateau” (Fig. 1). Lascar is considered the most active volcano in the Central Andean Volcanic Zone (de Silva and Francis, 1991). It is a compound elongated strato-volcano, comprised of two truncated western and eastern cones (Gardeweg et al., 1998) that host five nested craters aligned ENE–WSW. The Lascar volcano has been seismically monitored by the CKELAR-VOLCANES group using a temporal network of 11 three-component stations (Shallow Posthole Seismometers, Model F72-2.0). These short-period 2 Hz seismometers were monitored continuously at 200 Hz from March to October 2018 in this first step of processing. Notably, only the Z channel was considered in building our database. The reason for this is that the spectrograms obtained in the different channels of a particular station are very similar, but in the case of the Z channel, the P phase is clearly identified for tectonic and volcano–tectonic events; the use of the other channels is reserved for future studies.
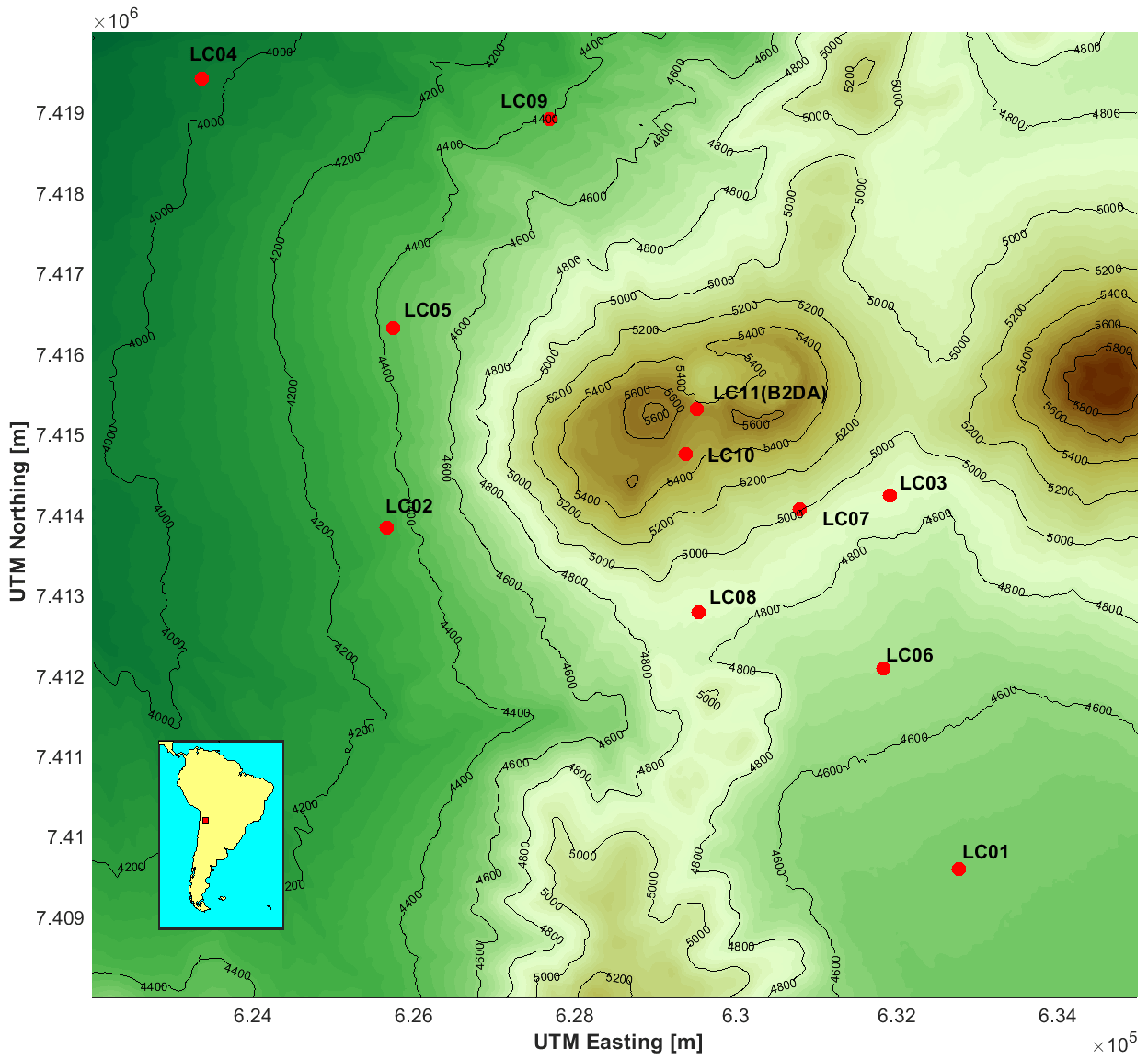
Figure 1Location map of the Lascar volcano experiment. The red dots indicate the position of the short-period seismic stations, and the black bold text represents the corresponding names. The LC10 and LC11 (B2DA) are located eastward, near the crater of the Lascar volcano. The DEM data are a product of ASTER Global Digital Elevation Model version 3 (ASTGTM v003), these can be downloaded directly by OPeNDAP link (https://lpdaac.usgs.gov/tools/opendap/, last access: 24 February 2023). The processing of the DEM was made using MATLAB©.
2.2 Lascar's database
Lascar's database corresponds to a catalogue of 6145 seismic events, from which only 3947 can be classified as volcanic events. The others, based on the distance to the hypocenters, are mainly tectonic events (not directly related to volcanic activity) recorded by Lascar’s network during the period of observation. To guarantee the reliability of the database regarding volcanic activity, all observations were manually segmented, labeled, and checked from the continuous seismic record by CKELAR-VOLCANES experts. The processing routines consider the following 4 steps.
- a.
Signal detection. The analysts detect the signal from the continuous seismic record using SEISAN software (Havskov and Ottemöller, 2000); once detected, they proceed to write down the start and end times of the signal in a list (based on the duration times of the event for each station, Fig. 2a).
- b.
Preliminary classification. The analysts give, as appropriate, a preliminary label of hybrid (HY), long period (LP), tectonic (TC), tremor (TR), or volcano–tectonic (VT) to the event. Both detection and preliminary classification are based solely on visual observation of its raw waveforms (seismograms) from the different stations that recorded the event (Fig. 2b).
- c.
Classification. The analysts, using the duration time of each event and the ObsPy package (Beyreuther et al., 2010), trim the signal, apply a linear detrend, and apply a bandpass filter between 0.5 and 25 [Hz]. After that, they proceed to plot, one by one, the seismograms of the different stations, their amplitude spectra, and their spectrograms. Therefore, they decide by visual inspection of the frequency content and the seismogram of all stations that recorded the event the respective class (Fig. 2c).
- d.
Signal segmentation. The analysts, using the list of absolute time of durations of each event, proceed to the segmentation of the signal to prepare an isolate corpus of seismograms as a database (Fig. 2d). The selection of the station for each event is decided by visual inspection of the frequency content and the seismogram of all stations that recorded the event, in relation to the level of noise in both the seismograms and the spectrograms (Fig. 3).
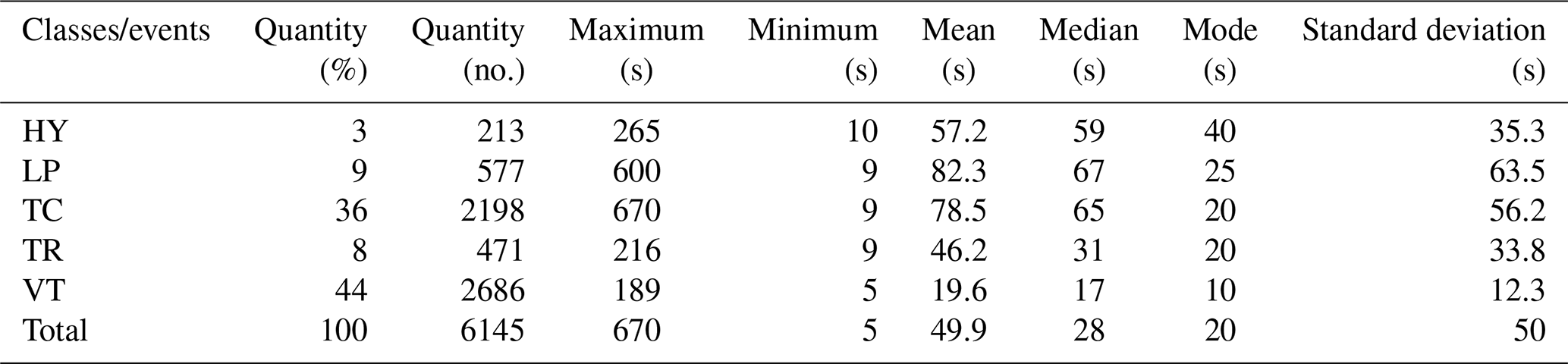
Finally, the database used for the automatic classification experiment corresponds to an isolated corpus of seismograms of five classes of events (Figs. 4 and 5): 213 events cataloged as (HY), 577 events cataloged as (LP), 471 events correspond to (TR), 2686 events recorded as (VT), and 2198 events, not related to volcanic activity, classified as (TC) (Tables 1 and 2).
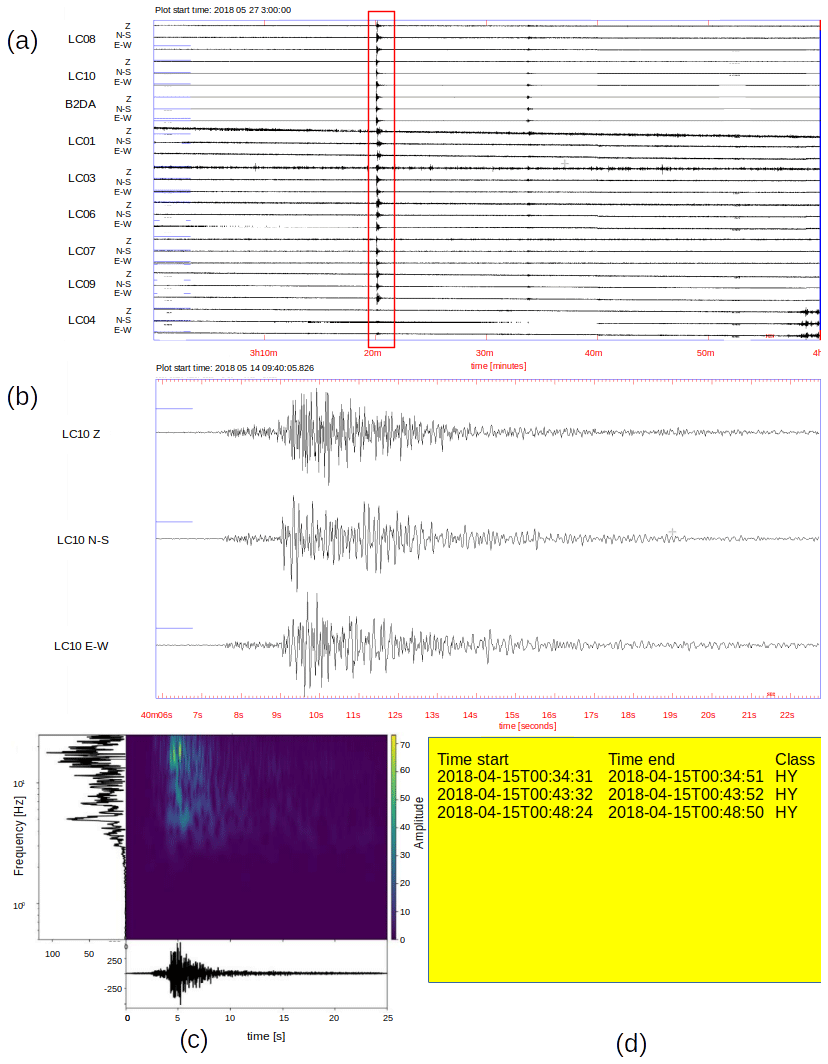
Figure 2Building Lascar's database: (a) signal detection, (b) preliminary classification, (c) classification, and (d) signal segmentation.

Figure 3Station selection for each event: example of station selection for the VT event that occurred on 3 April 2018 22:58:44 UTC, the event was recorded by the stations (a) LC01, (b) LC03, (c) LC04, and (d) LC07. The spectrogram of the station LC07 was selected for its frequency content.

Figure 4Examples of time series (left) and spectrograms (right) for the different classes in the Lascar database: (a) hybrid events (HY), (b) long period (LP), (c) tectonic events (TC), (d) tremors (TR), and (e) volcano–tectonic (VT).
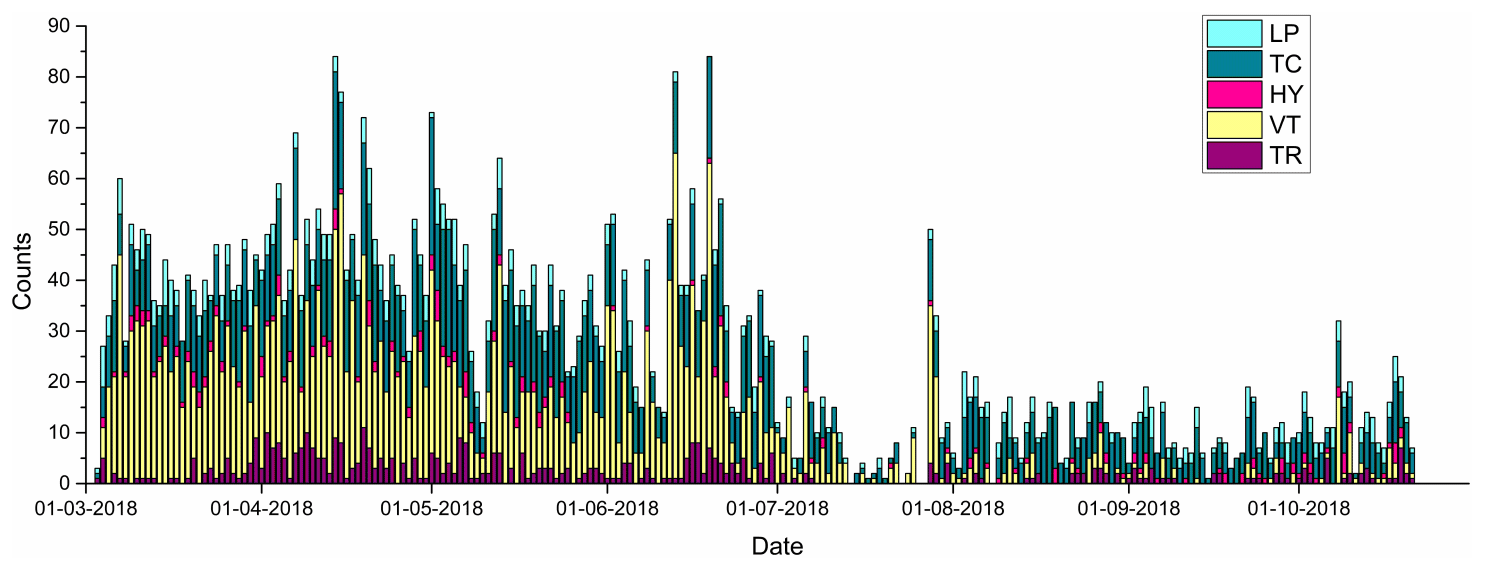
Figure 5Temporal evolution in the production of events of the different classes for the Lascar volcano in the period from March to October 2018.
Table 1Contribution of each station to Lascar’s database.

This experiment considered only the Z channels (vertical).
Table 2Statistics of the seismic records, based on the majority of the records.
We proposed a framework based on transfer learning, consisting of a previously trained deep convolutional neural network called AlexNet (Krizhevsky et al., 2012). The main reasons for adopting this approach were, on one hand, to avoid the steps of an extensive search and selection of features and, on the other hand, to deal with the limited number of labeled data. The data considered as input were spectrograms of the labeled dataset (waveform) from each class of seismic event. The line of processing consists of five steps: the first step describes the process applied in the time series (seismogram); the second step details obtaining spectrograms from the labeled seismograms; the third step consists of using the data augmentation technique to increase the number of data in the training and test datasets; the fourth step indicates how the prediction model is built; and, finally, the fifth step is performed to estimate the model’s performance. In the following paragraphs, each step is explained in detail.
Step 1 (pre-processing). The observations were recorded with the same type of sensors, but at times the sample ratio should have been varied because of technical problems. Thus, many of the stations recorded at 200 Hz, but a few stations recorded at 500 or 100 Hz. Considering this, we decided to apply two processing alternatives. (a) Resample the entire time series at 100 Hz; thereafter, we removed the mean and normalized the signals. Following this process, we applied a 10th order Butterworth bandpass filter between 1 and 10 Hz. (b) Remove the mean and normalize, to apply the 10th order Butterworth bandpass filter between 1 and 20 Hz, and after then resample the time series to 100 [Hz]. The entire pre-processing was implemented using ObsPy (Beyreuther et al., 2010).
Step 2 (spectrogram). The spectrograms were calculated by applying a short-time Fourier transform using the formula
where x(t) and y(t) represent the seismic signal and short-time Fourier transform sliding window, respectively. The sliding window size was set to 1 s with a 95 % overlap. The frequency interval used to calculate the spectrograms ranged from 1 to 10 Hz. All spectrograms were transformed to RGB images of 224×224 pixels.
Step 3 (data augmentation). Due to the imbalance produced on the labeled data, we decided to apply the data augmentation technique to generate a balanced number of different classes of seismic events (Table 2). Considering all the techniques for data augmentation, a time stretch was chosen. This transformation was implemented by rotations around the frequency axis that were as random as possible, between 5 % and 25 % of the length of the signal, which were applied at the beginning, middle, or ending of the spectrogram as appropriate (Fig. 6). The amount of data that were created for each class depended on the number of events in the most populated class; in this particular case the VT class was used as reference. The new signals generated were processed using the same procedure applied to the original signals (see Steps 1 and 2). The number of synthetic data were created by considering all possible combinations of integers that represent a rotation angle between 5 % and 25 %, that is, 21 possibilities. Subsequently, we apply these 21 rotation angles to the three possible rotation axes, corresponding to a total of 63 combinations of transformations to each event, without considering the repetition in the combination. Thus, each class has several synthetic data according to this relationship (63 times number of event per class). Accordingly with the transformations exposed above, the synthetic database was created using two criteria: (a) considering the least populated class (HY) with 213 events, the number of events selected for each class must be equal to the maximum number of synthetic data that can be generated in the (HY) class, it means 13 419 events to obtain a balanced dataset. Thus, in the case of the (HY) class, all the synthetic data will be used, and for the other classes, a random selection procedure, without repetition, will be implemented. Therefore, the number of events for this synthetic database comes to 67 095. (b) The amount of data that were created for each class depended on the number of events in the most populated class; in this case the (VT) class was used as reference (2686 events). Thus, the number of events for each class must be equal to 2686 and the amount of synthetic data that must be selected per each class depending on the number of events necessary to reach this quantity. Therefore, the total number of events for this database will be 13 430.
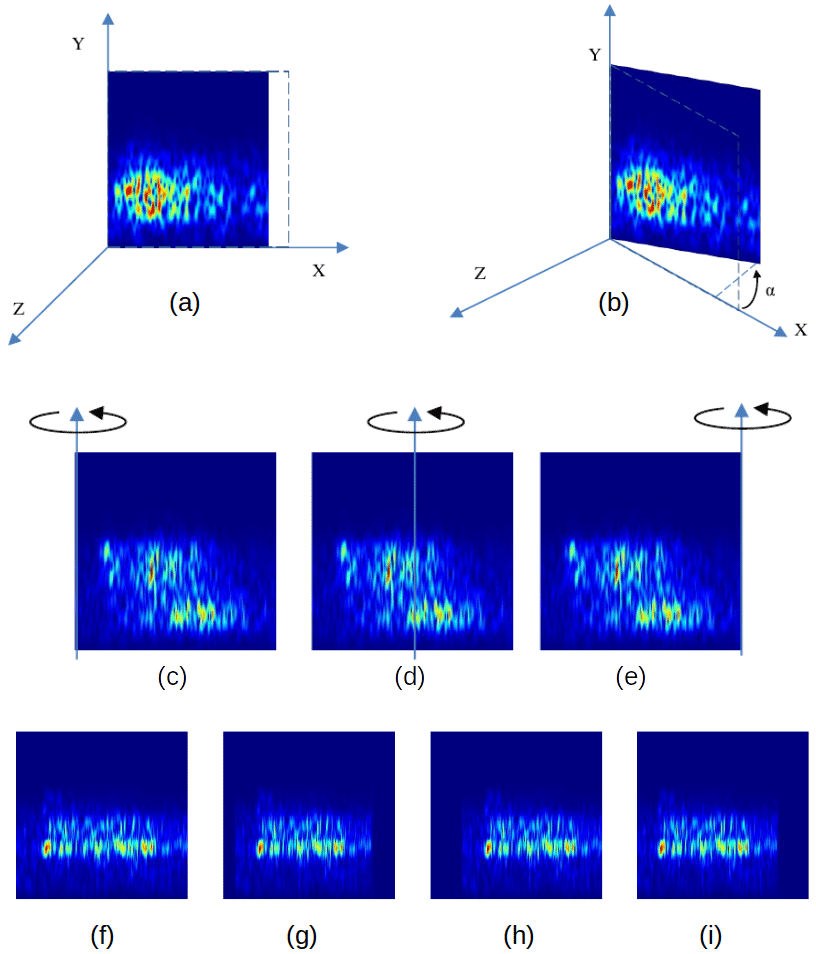
Figure 6Transformation by rotations, the time stretching (a) is produced when we change the angle of rotation α around the frequency axis (b); examples of the tree possibilities of rotations, around a left (c), central (d), and right axis (e), respectively; examples of how the time stretching is produced by rotations, (f) original spectrogram, (g) rotation of 19 % around the central axis, (h) rotation of 23 % around a right axis, and (i) rotation of 24 % around a left axis.
Step 4 (AlexNet). AlexNet is a deep convolutional neural network proposed by Krizhevsky et al. (2012) to classify the 1.2 million high-resolution images in the ImageNet LSVRC-2010 contest into 1000 different classes. AlexNet was used in our study as a pre-trained deep convolutional neural network for spectrogram recognition, mainly because the spectrogram can be easily represented as an RGB image of 224×224 pixels.
Step 5 (model performance). This step was considered to evaluate the performance of the model and, thus, to validate the classification. This step was executed through a set of tests composed of signals that were not considered in the training step. We considered the following measures from the TorchMetrics in PyTorch:
- i.
Accuracy
where yi and are the tensor of the target values and the tensor of the predictions, respectively.
- ii.
F1-score
- iii.
Recall
where TP and FN represent the number of true positives and false negatives, respectively.
- iv.
Precision
where TP and FP represent the number of true positives and false positives, respectively.
- v.
Cohen’s kappa
where p0 is the empirical probability of agreement and pe is the expected agreement when both annotators assign labels randomly. Note that this is estimated using a per-annotator empirical prior over the class labels.
Due to the fact that our database is clearly imbalanced, with 3 % (HY), 9 % (LP), 36 % (TC), 8 % (TR), and 44 % (VT) events (Table 2), we suspect that this natural behavior most likely affects the automatic classification performance. Therefore, we designed five experiments based on different datasets to test the ability of the model to classify the data. The build of the dataset is explained in the following paragraphs.
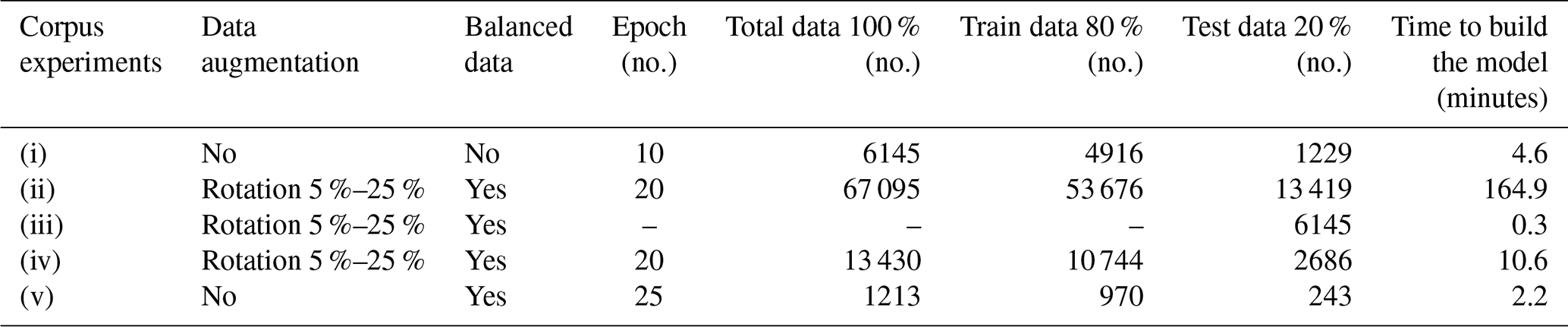
(i) Corpus of real data (6145 events). An imbalanced database of the Lascar volcano was used, without the application of augmentation processes. Thus, the 80 % of real data (4916 events) were used to build the probabilistic model of classification, and the other 20 % (1229 events) were used to test and validate this model (Table 3). This experiment permits us to evaluate the influence of an imbalanced database in the performance of a probabilistic model based on transfer learning (AlexNet).
Table 3Statistics related to the transfer learning experiments using AlexNet for hybrid events (HY), long period (LP), tectonic events (TC), tremors (TR), and volcano–tectonic (VT) classes.
(ii) Synthetic data corpus (67 095 events). Where the synthetic data were created by data augmentation processes (for more details, see Step 3 in Sect. 3). Once the synthetic database was created, 80 % of it (53 676 events) was used to build the probabilistic classification model, and the other 20 % (13 419 events) was used to test and validate it (Table 3). This experiment allows us to assess the usefulness of our implementation of the data augmentation technique and whether, with synthetic data, transfer learning (AlexNet) was able to build a probabilistic model with good performance for automatic event classification.
(iii) Combined 1 (59 821 events). The experiment consisted of using the previous probabilistic model (ii) training with 53 676 events and testing it with all events of the real database of 6145 events (Table 3). In this case, the performance of the probabilistic model built with synthetic data is evaluated on real data and, therefore, it will allow validating the efficiency of the data augmentation technique.
(iv) Combined 2 (13 430 events). This experiment used real and synthetic data to build and test the model. Thus, in the case of training we use 10 744 events, and for testing we use 2686 events (Table 3). This approach will allow for evaluating whether or not the amount of synthetic data created by data augmentation plays a key role in the performance of the probabilistic model to automatically classify events.
(v) Real database subset (1213 events). The experiment consists of selecting a subset of real data, where the number of data in each class depends on the number of events in the least populated class (HY) with 213 events. Thus, considering the class (HY) as a reference, we estimate that the number of events for the other classes will be 250 events, where 970 events correspond to the training set of the model and the other 243 events correspond to the testing set (Table 3). This experiment allows us to evaluate the performance of the probabilistic model built with a minimum number of data that provides an almost balanced database, without considering the generation of synthetics data by a data augmentation process.
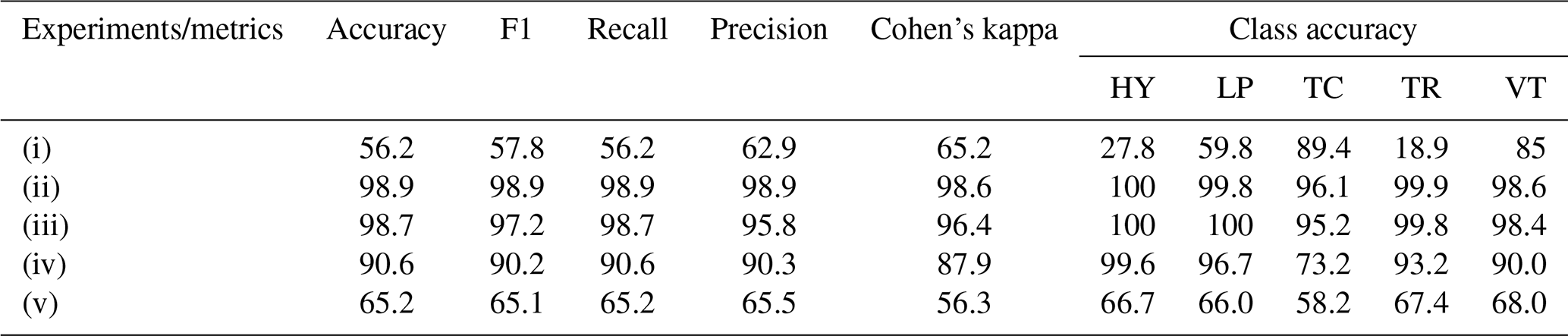
Tables 3 and 4 present the statistics and metrics of the different experiments. It is evident that in the case of the unbalanced database, in experiment (i), the performance of the experiment was inferior (56.2 % accuracy); however, when the data augmentation process was applied, in experiments (ii)–(iv), the results reached a particularly good percentage of the metric parameters (98.9 %, 98.7 %, 90.6 % accuracy, respectively). In the case of the balanced real data subset experiment (v), the performance of the experiments was higher than experiment (i) 65.2 % in accuracy, but notably lower than the experiments executed using the database with balanced classes (ii)–(iv). We want to highlight the results of the experiment, where the real data were used exclusively in the test (without being included in the model building). In this case, the metrics showed the second highest ranking, preceding only the experiment that exclusively included synthetic data.
Table 4Performance of the transfer learning experiments to 1–10 [Hz].
In analyzing the complete training and validation phase, through the loss and accuracy epoch, the process was less effective when the (i) database was used (Fig. 7a–b), whereas the best performance was achieved by the process using the (ii) database (Fig. 7c–d). In the case of the database balanced with data augmentation and real data (iv) database, this showed a good performance (Fig. 8a–b). Conversely, the performance for the experiment with the database balanced only using real data (v), the results showed that despite having a balanced database, these are below the results obtained using data augmentation (Fig. 8c–d).
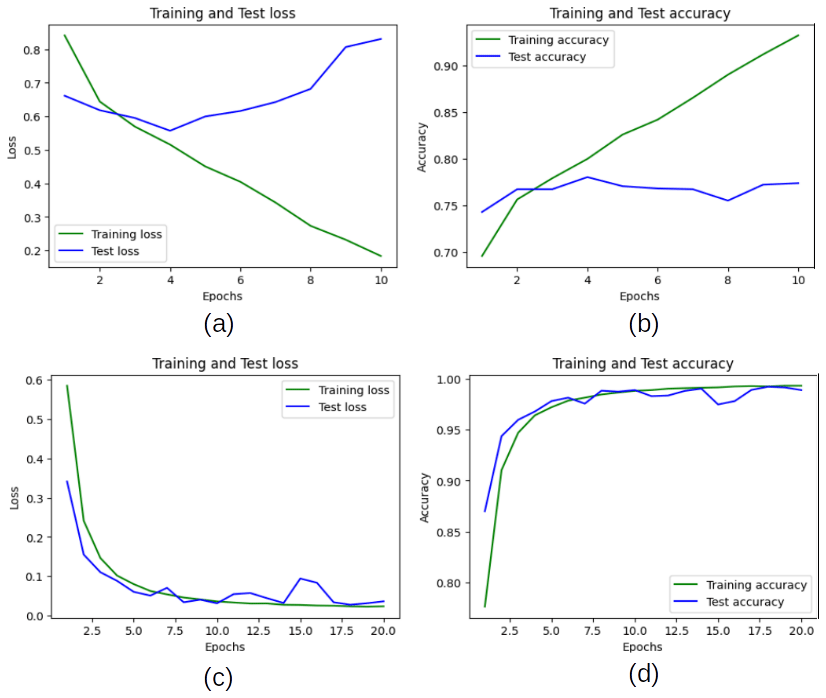
Figure 7Training and validation performance scores of the transfer learning AlexNet for experiment: (a) training and test loss for the experiment (i); (b) training and test accuracy for the experiment (i); (c) training and test loss for the experiment (ii), and (d) training and test accuracy for the experiment (ii).
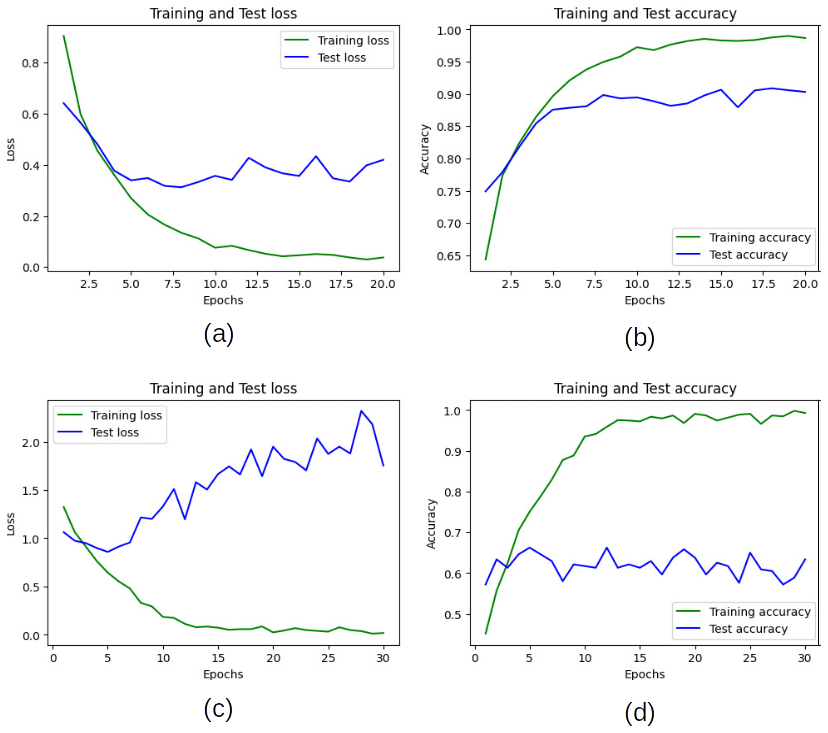
Figure 8Training and validation performance scores of the transfer learning AlexNet for experiment: (a) training and test loss for the experiment (iv), (b) training and test accuracy for the experiment (iv), (c) training and test loss for the experiment (v), and (d) training and test accuracy for the experiment (v).
To evaluate the accuracy of the classification process for each experiment, we computed the confusion matrix. In the case of experiment (i), we noticed that classes with less data were negatively affected. In this case, a high percentage of HY events were confused by TC events, and thus, the TR events were also mistaken for TC events (Fig. 9a–b). Conversely, the classification process of experiment (ii) performed well, and no confusion in the class recognition was found (Fig. 9c–d). For experiment (ii), the performance was high, considering that the confusion of classes was practically minimal (Fig. 10a–b). Experiment (iv) also presented a high score, and the confusion matrix indicated a small problem in the recognition of TC and VT classes, in which some are confused by TR and TC, respectively (Fig. 10c–d). In the case of experiment (v) the main recognition problems are in the HY and TC class, in which some are confused with TR and LP (Fig. 11a–b).
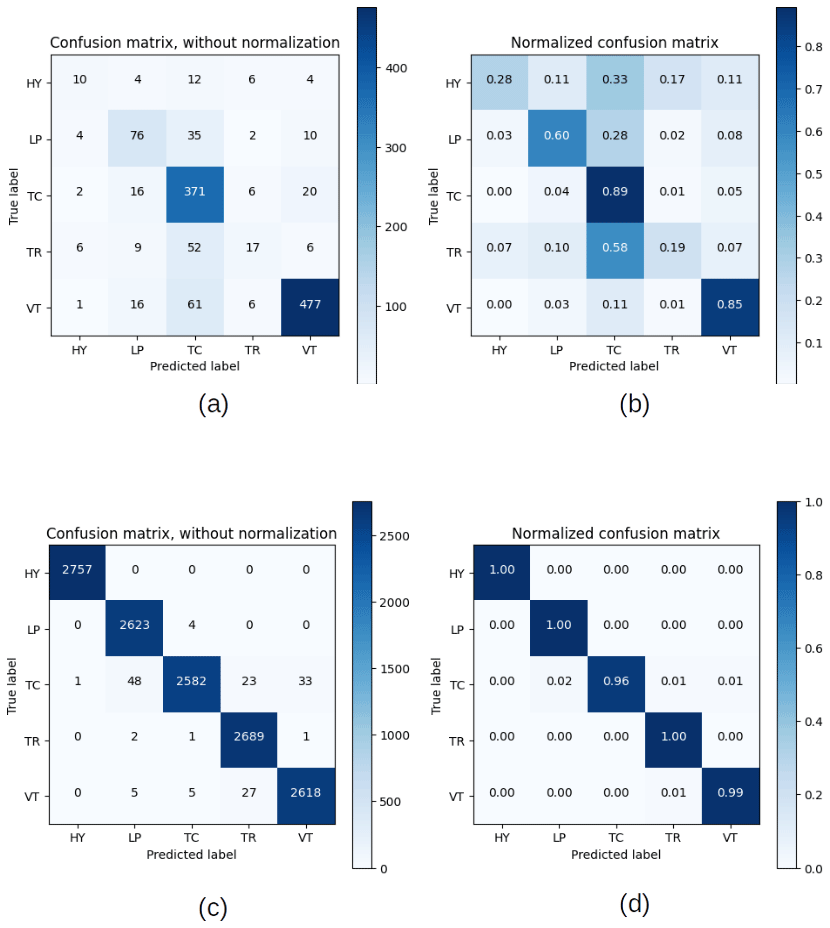
Figure 9Confusion matrices without normalization (a) and normalized (b), for experiment (i), and without normalization (c) and normalized (d), for experiment (ii).
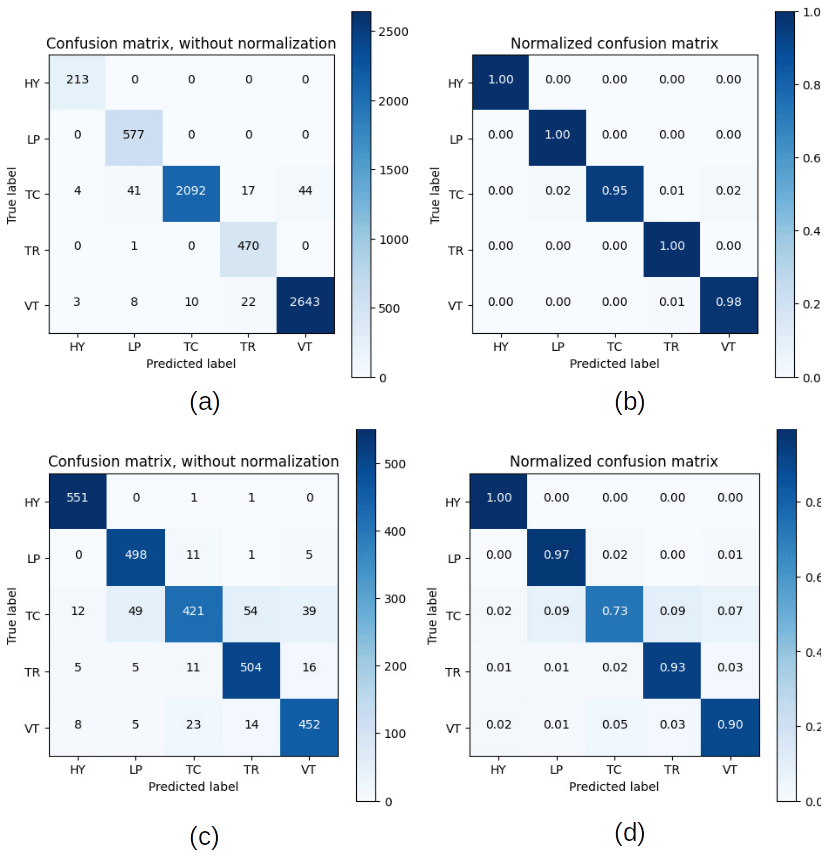
Figure 10Confusion matrices without normalization (a) and normalized (b), for experiment (iii), and without normalization (c) and normalized (d), for experiment (iv).
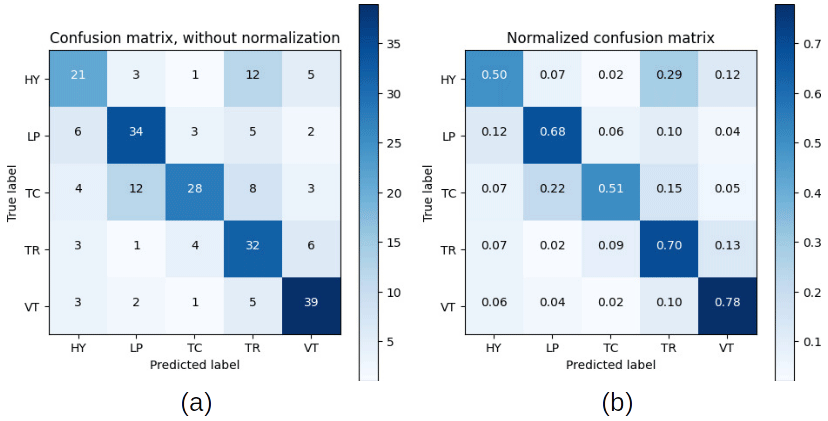
Figure 11Confusion matrices without normalization (a) and normalized (b), for experiment (v).
To test whether the probabilistic model, built with both real and augmented data, is stable under the variability of the input data, a k-fold cross-validation procedure was implemented (Table 5). The results showed that the metrics for the different classes, as in the previous experiments, were high. There was only one class (TC) affected (with more variability), but good scores were always maintained, which in the worst case was over 67 %.
Table 5Performance of the transfer learning experiments applying k-fold validation.
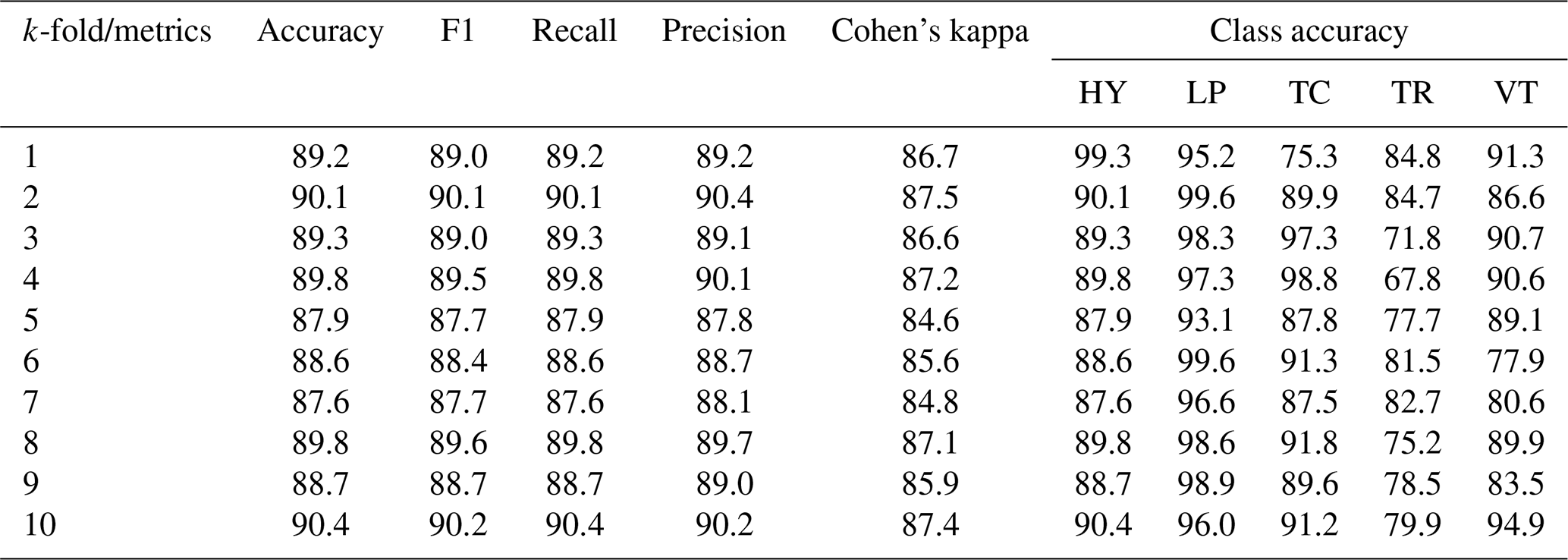
In the case of the experiments that used a frequency band of 1–20 [Hz] (see Step 1, “case b” in Sect. 3), the results showed a relative improvement compared to “case a” (frequency band 1–10 [Hz]), but this is not comparable to the improvement achieved by applying the data augmentation process. The best improvement was achieved in experiment (i), where there is a 6 % difference in accuracy (Table 6).
Table 6Performance of the transfer learning experiments for the experiment to 1–20 [Hz].

The analyses of this study clearly showed the impact of imbalance in the database and how the process of machine learning was conditioned to build probabilistic models of classifications for the different classes. The model building process was notably influenced by classes with more events, which in this case were TC and VT. Under these conditions, an overfitted model was built in the training phase, which largely coincided with the recognition of these two classes, to the detriment of the less numerous ones.
Conversely, the process of data augmentation facilitated a balance in the data of the different classes, which directly impacted the performance of the probabilistic model, reaching optimal scores over different test datasets. This can be explained by the fact that data augmentation provides an efficient process for searching the features of each class during the training process.
We want to highlight the results of the experiment, where the real data were used exclusively in the test (without being included in the model building). In this case, the metrics showed the second highest ranking, preceding only the experiment that exclusively included synthetic data.
Although the frequency content was the main classification characteristic to differentiate the different volcanic event types, the choice of stretch as a data augmentation method along the time axis was a successful strategy that did not reduce effectiveness. The artificial production of data using stretches in frequency should provoke overlap (on the dimensional map) between the different classes of volcanic events when these are analyzed using the spectrogram image.
The experiment (v), where we use a balanced real data subset, shows us that if we train with a balanced database, but the events per class are not enough, the results do not reach the values obtained with the experiments carried out with data augmentation as a mechanism to balance the classes. Thus, the probabilistic model built is not fully reliable, and there are more quantities of events confused with other classes.
Another important topic is the technique used to build the probabilistic model. Transfer learning with a pre-trained large neural network, such as AlexNet, facilitated model building in less time. Instead of manually selecting the best features, this task was performed by learning features from the pre-trained models of AlexNet, thereby dramatically saving time in the process. This point was verified when the model built using AlexNet was validated using only real data in experiment (iii), where high scores in the metrics of the experiment were achieved.
Thus, the use of a transfer learning approach allowed the transference of the information about the feature characteristics collected from the training dataset to the testing dataset, improving the efficiency of the process.
The limitations found in our implementation of AlexNet on spectrograms correspond mainly to the fact that although AlexNet has its own data augmentation process, it was not efficient enough to counteract the imbalance in the different classes studied. This shortcoming was solved by implementing our own data augmentation process.
The other limitation was that the spectrogram must be scaled to a fixed input size of pixels, due to the presence of fully connected layers in the convolutional neural network. While this is not a big problem, it limits the graphical resolution of the image, although this can be advantageous since our main objective is to obtain a generalized probabilistic model.
A key issue for the proposed methodology was to generate a multi-station probabilistic model, developing a system trained with a multi-station subset and confronted with another independent multi-station subset. This approach permits us to reach a generalized set of characteristics that defined an optimal space for each class. Thus, we can avoid biases related to site effects (e.g., instruments installed in rocks, soil).
From the experiments implemented in this study, the following conclusions were drawn.
First, the usefulness of a multi-station framework to build a probabilistic model of the Lascar database allowed us to obtain a more generalizable model, thereby avoiding the bias associated with the choice of a particular station to retrieve the features. This fact led us to believe that we are very close to obtaining high-score results, with the AlexNet tool playing a key role in reaching the challenge of building a multi-volcano probabilistic model to classify the seismic events.
Second, data augmentation plays a key role as the main factor to improve the metrics of the experiments, thereby providing a built model validated by real data.
Last, and perhaps the most relevant, the proposal based on transfer learning provided an efficient feature retrieval process using learning features. The performance of this approach was clearly superior when compared with an exhaustive process of evaluation for a list of 100 statistical features sent to the system, as it is a process of designed features. Our approach has a high impact when the time process matters, as is the case in early warning systems for volcanic activity, and provides a more generalizable model of prediction.
Following the same methodology used in the case of multi-station, we can expand, in the near future, our probabilistic models considering a network with different types of instruments, different setup of the instruments in a network, and different temporality of the data analyzed and, finally, can reach a probabilistic model multi-volcano. The portability generated to apply this methodology will permit us to work to different scales of operation of a network (from small temporal networks to world-wide volcano observatories). The acquisition of more generalizable models creates a good opportunity to develop a multi-volcano probabilistic model for volcanoes worldwide.
The data are registered by https://doi.org/10.5281/Zenodo.6001869 (Salazar et al., 2022). These can be also founded in the link: https://zenodo.org/record/6001870#.YkGXKffQ-Xl (last access: 24 February 2023).
SL, GY, and PS designed the experiments and carried them out. FY, CM, and PS developed the model code and performed the simulations. PS prepared the paper with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We express our acknowledgements to the CKELAR-VOLCANES team – Gabriel Ureta, Javier Valdés, Christian Ibaceta, Felipe Aguilera, Felipe Rojas, Diego Jaldín, Álvaro Vergara, Alfredo Esquivel, José Pablo Sepúlveda, Manuel Inostroza and Cristóbal González – and to Greg Wait for his priceless course of training in volcanic signals.
This research has been supported by ANID/FONDECYT-INICIACIÓN (grant no. 11190190); the Antofagasta regional government, FIC-R project, code BIP (grant no. 30488832-0); the Millennium Institute on Volcanic Risk Research – Ckelar Volcanoes ANID/MILENIO (grant no. ICN2021_038); and the Research Center for Integrated Disaster Risk Management (CIGIDEN), ANID/FONDAP (grant no. 15110017). Susana Layana was funded by the ANID-PCHA Doctorado Nacional (grant no. 2016-21160276) fellowship and is currently funded by the Millennium Institute on Volcanic Risk Research – Ckelar Volcanoes ANID/MILENIO (grant no. ICN2021_038) through a postdoctoral fellowship. Franz Yupanqui is funded by the Millennium Institute on Volcanic Risk Research – Ckelar Volcanoes ANID/MILENIO (grant no. ICN2021_038) and UCN doctoral fellowship.
This paper was edited by Giovanni Macedonio and reviewed by two anonymous referees.
Álvarez, I., García, L., Cortés, G., Benítez, C., and De la Torre, Á.: Discriminative feature selection for automatic classification of volcano-seismic signals, IEEE Geosci. Remote S., 9, 151–155, 2012. a
Araujo, A. F. R. and Rego, R. L. M. E.: Self-organizing maps with a time-varying structure, ACM Comput. Surv., 46, 7, https://doi.org/10.1145/2522968.2522975, 2013. a
Bebbington, M.: Identifying volcanic regimes using Hidden Markov Models, Geophys. J. Int., 171, 921–942, https://doi.org/10.1111/j.1365-246X.2007.03559.x, 2007. a
Beyreuther, M. and Wassermann, J.: Continuous earthquake detection and classification using discrete Hidden Markov Models, Geophys. J. Int., 175, 1055–1066, 2008. a, b
Beyreuther, M. and Wassermann, J.: Hidden semi-Markov Model based earthquake classification system using Weighted Finite-State Transducers, Nonlin. Processes Geophys., 18, 81–89, https://doi.org/10.5194/npg-18-81-2011, 2011. a
Beyreuther, M., Barsch, R., Krischer, L., Mejies, T., Behr, Y., and Wassermann, J.: Obspy: A Python Toolbox for Seismology, Seismol. Res. Lett., 81, 530–533, https://doi.org/10.1785/gssrl.81.3.530, 2010. a
Beyreuther, M., Hammer, C., Wassermann, J., Ohrnberger, M., and Megies, T.: Constructing a Hidden Markov Model based earthquake detector: application to induced seismicity, Geophys. J. Int., 189, 602–610, 2012. a
Bicego, M., Acosta-Munoz, C., and Orozco-Alzate, M.: Classification of seismic volcanic signals using hidden-Markov-model-based generative embeddings, IEEE T. Geosci. Remote., 51, 3400–3409, 2013. a
Bicego, M., Londoño-Bonilla, J. M., and Orozco-Alzate, M.: Volcano-seismic events classification using document classification strategies, in: Image Analysis and Processing – ICIAP 2015. ICIAP 2015. Lecture Notes in Computer Science, edited by: Murino, V. and Puppo, E., Springer, Cham, 9279, 119–129, https://doi.org/10.1007/978-3-319-23231-7_11, 2015. a, b
Carniel, R.: Characterization of volcanic regimes and identification of significant transitions using geophysical data: a review, B. Volcanol., 76, 1–22, 2014. a, b
Carniel, R., Barbui, L., and Jolly, A. D.: Detecting dynamical regimes by Self-Organizing Map (SOM) analysis: an example from the March 2006 phreatic eruption at Raoul Island, New Zealand Kermadic Arc, B. Geofis. Teor. Appl., 54, 39–52, 2013a. a
Carniel, R., Jolly, A. D., and Barbui, L.: Analysis of phreatic events at Ruapehu volcano, New Zealand using a new SOM approach, J. Volcanol. Geoth. Res., 254, 69–79, 2013b. a, b
Ceamanos, X., Waske, B., Benediktsson, J. A., Chanussot, J., Fauvel, M., and Sveinsson, J. R.: A classifier ensemble based on fusion of support vector machines for classifying hyperspectral data, Int. J. Image Data Fusion, 1, 293–307, 2010. a
Cortés, G., García, L., Álvarez, I., Benítez, C., de la Torre, T., and Ibáñez, J.: Parallel system architecture (PSA): An efficient approach for automatic recognition of volcano-seismic events, J. Volcanol. Geoth. Res., 271, 1–10, 2014. a
Cortés, G., Benitez, M. C., Garcia, L., Alvarez, I., and Ibanez, J. M.: A comparative study of dimensionality reduction algorithms applied to volcano-seismic signals, IEEE J. Sel. Top. Appl., 9, 253–263, https://doi.org/10.1109/JSTARS.2015.2479300, 2015. a
Curilem, M., Vergara, J., San, Martin C., Fuentealba, G., Cardona, C., Huenupan, F., Chacón, M., Khan, S., Hussein, W., and Becerra, N.: Pattern recognition applied to seismic signals of the Llaima Volcano (Chile): an analysis of the events' features, J. Volcanol. Geoth. Res., 282, 134–177, 2014a. a
Curilem, M., Huenupan, F., San, Martin C., Fuentealba, G., Cardona, C., Franco, L., Acuña, G., and Chacón, M.: Feature analysis for the classification of volcanic seismic events using support vector machines, in: Nature-Inspired Computation and Machine Learning. MICAI 2014. Lecture Notes in Computer Science, edited by: Gelbukh, A., Espinoza, F. C., and Galicia-Haro, S. N., Springer International Publishing Switzerland, 160–171, https://doi.org/10.1007/978-3-319-13650-9_15, 2014b. a
Curilem, M., Huenupan, F., Beltrán, D., San Martin, C., Fuentealba, G., Franco, L., Cardona, C., Acuña, G., Chacón, M., Salman Khane, M. S., and Becerra Yoma, N.: Pattern recognition applied to seismic signals of Llaima volcano (Chile): An evaluation of station-dependent classifiers, J. Volcanol. Geoth. Res., 315, 15–27, 2016. a
de Natale, G., Petrazzuoli, S., Romanelli, F., Troise, C., Vaccari, F., Somma, R., Peresan, A., and Panza, G. F.: Seismic risk mitigation at Ischia island (Naples, Southern Italy): An innovative approach to mitigate catastrophic scenarios, Eng. Geol., 261, 105285, https://doi.org/10.1016/j.enggeo.2019.105285, 2019. a
de Silva, S. and Francis, P.: Volcanoes of Central Andes, Springer-Verlag, New York, https://doi.org/10.1017/S0016756800008372, ISBN 3 540 53706 6, 1991. a
Esposito, A. M., Giudicepietro, F., D'Auria, L., Scarpetta, S., Martini, M., Coltelli, M., and Marinaro, M.: Unsupervised neural analysis of very long period events at Stromboli volcano using the self-organizing maps, B. Seismol. Soc. Am., 98, 2449–2459, https://doi.org/10.1785/0120070110, 2008. a
Esposito, A. M., D’Auria, L., Giudicepietro, F., Peluso, R., and Martini, M.: Automatic recognition of landslides based on neural network analysis of seismic signals: an application to the monitoring of Stromboli volcano (Southern Italy), Pure Appl. Geophys., 170, 1821–1832, 2013. a, b
Esposito, A. M., D’Auria, L., Angelillo, A., Giudicepietro, F., and Martini, M.: Predictive analysis of the seismicity level at Campi Flegrei volcano using a data-driven approach, in: Neural Network Models and Applications. Smart Innovation, Systems and Technologies, edited by: Bassis, S., Esposito, A., and Morabito, F., Springer, Cham, 26, 133–145, https://doi.org/10.1007/978-3-319-04129-2_14, 2014. a
Gardeweg, M., Sparks, R., and Matthews, S.: Evolution of Lascar volcano, Northern Chile, J. Geol. Soc. London, 155, 89–104, 1998. a
Giacco, F., Esposito, A.M., Scarpetta, S., Giudicepietro, F., and Matinaro, M.: Support vector machines and MLP for automatic classification of seismic signals at Stromboli Volcano, in: Proceedings of the 2009 Conference on Neural Nets WIRN09, Salerno, Italy, 28–30 May 2009, IOS Press, 116–123, https://doi.org/10.3233/978-1-60750-072-8-116, ISBN 978-1-60750-072-8, 2009 a
Havskov, J. and Ottemöller, L.: SEISAN earthquake analysis software, Seismol. Res. Lett., 70, 532–534, 2000. a
Krizhevsky, A., Sutskever, I., and Hinton, G.: ImageNet Classification with Deep Convolutional Neural Networks, Commun. ACM, 60, 84–90, https://doi.org/10.1145/3065386, 2012. a, b, c, d
Langer, H., Falsaperla, S., Masotti, M., Campanili, R., Spampinato, S., and Messina, A.: Synopsis of supervised and unsupervised pattern classification techniques applied to volcanic tremor data at Mt. Etna, Italy, Geophys. J. Int., 178, 1132–1144, https://doi.org/10.1111/j.1365-246X.2009.04179.x, 2009. a, b
Langer, H., Falsaperla, S., Messina, A., Spampinato, S., and Behncke, B.: Detecting imminent eruptive activity at Mt Etna, Italy, in 2007–2008 through pattern classification of volcanic tremor data, J. Volcanol. Geoth. Res., 200, 1–17, 2011. a, b
Magrin, A., Peresan, A., Kronrod, T., Vaccari, F., and Panza, G. F.: Neo-deterministic seismic hazard assessment and earthquake occurrence rate, Eng. Geol., 229, 95–109, https://doi.org/10.1016/j.enggeo.2017.09.004, 2017. a
Masotti, M., Falsaperla, S., Langer, H., Spampinato, S., and Campanini, R.: Application of support vector machine to the classification of volcanic tremor at Etna, Italy, Geophys. Res. Lett., 33, L20304, https://doi.org/10.1029/2006GL027441, 2006. a, b
Masotti, M., Campanini, R., Mazzacurati, L., Falsaperla, S., Langer, H., and Spampinato, S.: TREMOrEC: a software utility for automatic classification of volcanic tremor, Geochem. Geophy. Geosy., 9, Q04007, https://doi.org/10.1029/2007GC001860, 2008. a
Ohrnberger, M.: Continuous automatic classification of seismic signals of volcanic origin at Mt. Merapi, Java, Indonesia, PhD thesis, Universität Potsdam, Germany, https://publishup.uni-potsdam.de/frontdoor/index/index/docId/33 (last access: 24 February 2023), 2001. a
Rapolla, A., Paoletti, V., and Secomandi, M.: Seismically-induced landslide susceptibility evaluation: Application of a new procedure to the island of Ischia, Campania Region, Southern Italy, Eng. Geol., 114, 10–25, https://doi.org/10.1016/j.enggeo.2010.03.006, 2010. a
Rouland, D., Legrand, D., Zhizhin, M., and Vergniolle, S.: Automatic detection and discrimination of volcanic tremors and tectonic earthquakes: an application to Ambrym Volcano, Vanuatu, J. Volcanol. Geoth. Res., 181, 196–206, 2009. a
Salazar, P., Yupanqui, F., Meneses, C., Layana, S., and Yáñez, G.: Data Lacar Experiment (2018.03 - 2018.10), Zenodo [data set], https://doi.org/10.5281/zenodo.6001869, 2022. a
Vapnik, V.: The Nature of Statistical Learning Theory, Springer Verlag, ISBN 10: 147572442X, 1475724403, ISBN 13: 9781475724424, 9781475724400, 1995. a
Zulkeflie, S. A., Fammy, F. A., Ibrahim, Z., and Sabri, N.: Evaluation of Basic Convolutional Neural Network, AlexNet and Bag of Features for Indoor Object Recognition, International Journal of Machine Learning and Computing, 9, 801–806, https://doi.org/10.18178/ijmlc.2019.9.6.876, 2019. a