the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 06 Jul 2021
| 06 Jul 2021
Regional analysis of multivariate compound coastal flooding potential around Europe and environs: sensitivity analysis and spatial patterns
Ivan D. Haigh
Ahmed A. Nasr
Thomas Wahl
Stephen E. Darby
Robert J. Nicholls
In coastal regions, floods can arise through a combination of multiple drivers, including direct surface run-off, river discharge, storm surge, and waves. In this study, we analyse compound flood potential in Europe and environs caused by these four main flooding sources using state-of-the-art databases with coherent forcing (i.e. ERA5). First, we analyse the sensitivity of the compound flooding potential to several factors: (1) sampling method, (2) time window to select the concurrent event of the conditioned driver, (3) dependence metrics, and (4) wave-driven sea level definition. We observe higher correlation coefficients using annual maxima than peaks over threshold. Regarding the other factors, our results show similar spatial distributions of the compound flooding potential. Second, the dependence between the pairs of drivers using the Kendall rank correlation coefficient and the joint occurrence are synthesized for coherent patterns of compound flooding potential using a clustering technique. This quantitative multi-driver assessment not only distinguishes where overall compound flooding potential is the highest, but also discriminates which driver combinations are more likely to contribute to compound flooding. We identify that hotspots of compound flooding potential are located along the southern coast of the North Atlantic Ocean and the northern coast of the Mediterranean Sea.
- Article
(10508 KB) - Full-text XML
-
Supplement
(1088 KB) - BibTeX
- EndNote





Floods are the most dangerous and costly natural hazard. For example, in Europe, the economic losses from all natural disasters amounted to EUR 557 billion during 1980–2017 (EEA, 2019), of which 63 % resulted from hydro-meteorological events. Moreover, losses associated with the highest-magnitude floods are disproportionately large: around 3 % of these European floods accounted for around 75 % of total deflated losses. The October 2000 flood in Italy and France, for example, was one of the most expensive climate extremes, with damages totalling EUR 13 billion. Since compound floods – floods generated by different source events occurring concurrently, or in close succession – are often larger than floods generated by a single source event, it follows that the adverse consequences of “compound flooding” are, therefore, likely also disproportionately large. As an example, the November 1966 coastal flood was one of the most severe observed compound events along the northernmost coast of the Adriatic Sea, which resulted in approximately 25 fatalities and thousands of people affected (HANZE database; Paprotny et al., 2018).
The definition of compound events has evolved in recent years. Compound events were defined by the Intergovernmental Panel on Climate Change (Seneviratne et al., 2012) as “(1) two or more extreme events occurring simultaneously or successively, (2) combinations of extreme events with underlying conditions that amplify the impact, or (3) combinations of events that are not themselves extremes but lead to an extreme event when combined.” More recently, Zscheischler et al. (2018) defined compound events as “a combination of multiple drivers and/or hazards that contributes to societal or environmental risk”. This new perspective suggests the use of bottom-up approaches to understand the nature of the risks before identifying the relevant drivers and hazards (Zscheischler et al., 2018). However, the impacts of compound events are commonly felt at a local scale over relatively short timescales, embedded at the same time within larger-scale systems, which requires modelling approaches that fully represent these wide ranges of space and timescales. To help bridge the gap between the climate science and impact modelling communities, multi-level methodologies which include a quantification of flooding potential using proxies of flood hazard (Bevacqua et al., 2019; Ward et al., 2018; Wahl et al., 2015; Couasnon et al., 2020; Ridder et al., 2020) have been used to identify potential hotspots at regional, continental, or global scales at a first “screening” level. The results can then be used to inform high-resolution risk assessments, where these are most necessary, which integrate all flooding sources through process-based models to simulate their physical interaction (Bevacqua et al., 2019), as well as their interaction with human systems (Sebastian et al., 2019; Wang et al., 2020).
According to the proposed typology in Zscheischler et al. (2020), flooding is considered a multivariate event because multiple climate drivers and/or hazards can occur in the same geographical region that may not be extreme themselves, but their joint occurrence causes an extreme impact. In coastal regions, flooding can arise from the combination of multiple sources: pluvial (direct surface runoff), fluvial (increased river discharge), and/or oceanographic (storm surges plus tides and/or waves). The main drivers of flooding are typically causally related through their associated weather patterns, for instance, when a storm causes extreme rainfall and/or a storm surge and/or high waves. The statistical modelling approach suggested for this typology consists of multivariate probability distribution functions, which represent both the marginal and joint features of multiple random variables (Zscheischler et al., 2020).
High-dimensional systems can be modelled using copula-based approaches, but due to their complexity these multivariate statistical models have been limited to local-scale studies (Bevacqua et al., 2017; Couasnon et al., 2018). At global or regional scales, where compound flooding risk varies substantially along coastlines, the risk is estimated indirectly by quantifying the dependence limited to bivariate drivers (proxies of the flooding hazard). For example (1) Zheng et al. (2013) found a significant dependence between maximum daily storm surge and daily precipitation along the coast of Australia, (2) Wahl et al. (2015) detected an increasing risk of compound flooding from storm surge and precipitation for major US coastal cities, and (3) Hendry et al. (2019) analysed the characteristics of compound flooding arising from the combination of river discharge and sea level along the UK coast. Such quantifications of compound flooding potential are based on dependence measures (e.g. using correlation coefficients, Wahl et al., 2015; or joint occurrence, Hendry et al., 2019) or bivariate statistical models (e.g. bivariate logistic threshold-excess model, Zheng et al., 2013; or copulas, Wahl et al., 2015; Moftakhari et al., 2017; Ward et al., 2018). Furthermore, recent advances in large-scale sea level and river discharge modelling (Muis et al., 2016; Yamazaki et al., 2014), which provide time series of these drivers over durations of more than 30 years, allow the identification of potential hotspots at country, continental, and global scales (Wu et al., 2018; Bevacqua et al., 2019, 2020; Couasnon et al., 2020).
Regarding the identification of compound events, conditional sampling is usually applied (Wahl et al., 2015; Ward et al., 2018; Couasnon et al., 2020), which implies that compound events are conditioned to one of the drivers being extreme. For this reason, when limiting to a bivariate characterization of compound events (e.g. when using correlation coefficients), two subsets of extreme events are identified, and the dependence is analysed when one or the other of the variables is extreme. Another option is to select pairs of high values when both variables exceed individual high percentiles (e.g. 95th percentile; Bevacqua et al., 2019), but in this case, compound events are defined only when both individual drivers are characterized as being extreme. This issue is similar to what happens when measuring compound flooding potential based on factors or indices that quantify the effect of the dependency using copula AND hazard scenarios (Ward et al., 2018; Ganguli and Merz, 2019; Couasnon et al., 2020). However, it could be sufficient that only one of the driver variables was extreme to make a bivariate occurrence hazardous (OR hazard scenario; Moftakhari et al., 2017).
In the compound flooding studies summarized above, it is evident that a wide range of different statistical approaches have been used to define compound flooding potential, usually caused by the combination of two drivers. To date, no study has yet analysed the dependence between the four potential drivers of flooding in coastal regions independently for each pair combination. Ridder et al. (2020) have identified hotspots of compound events that potentially cause high-impact floods related to wet conditions based on the joint occurrence of multiple hazard pairs (precipitation, wind, hail, streamflow, and storm surge). In other studies, the wave component has typically been included in the sea level directly (by combining wave height with storm surge and/or astronomical tide) without analysing the correlation with the other drivers (Bevacqua et al., 2019; Paprotny et al., 2020). Similarly precipitation and river discharge have often been considered equivalent drivers in the analysis of compound coastal flooding in combination with storm surge (Bevacqua et al., 2020). Additionally, different sampling methods to identify compound events and dependence measures to quantify compound flooding potential are used. The net effect of these variations in practice is to complicate comparisons between different studies.
The overall aim of this paper is to perform a regional analysis along the North Atlantic (27–70.5∘ N), Baltic, Mediterranean, and Black Sea coastlines of the compound flood potential caused by pluvial, fluvial, and oceanographic sources in the period 1979 to 2018, using state-of-the-art model hindcasts with homogenous forcing (i.e. ERA5). Two objectives are defined: (1) to assess the sensitivity of the compound flood potential to several factors that can affect the identification of compound events and the analysis of the spatial distribution of compound flooding potential and (2) to detect different types of compound events and the spatial patterns of compound flooding potential that arise from the combination of the four drivers. The paper is structured as follows. The datasets and methods are detailed in Sects. 2 and 3, respectively. The results of the two objectives are discussed in Sect. 4. Key findings are discussed in Sect. 5, with conclusions given in Sect. 6.
We use modelled data to cover the entire coastlines that are the focus of this study, using long-term, spatially continuous, and temporally consistent gridded data for all four flood source variables, as discussed in each of the sub-sections below. Of note is that although these databases are not available on a common grid and there are differences in their spatial resolution, they are all derived from the latest European Centre of Medium-Range Weather Forecasts (ECMWF) global atmospheric reanalysis (ERA5; Hersbach et al., 2020), or from hindcasts forced by this atmospheric reanalysis. The new database GloFAS-ERA (Harrigan et al., 2020) is used for the first time to characterize river discharge when studying compound flooding potential. We do not account for pluvial flooding directly, as pluvial flooding is a much smaller-scale process. Instead, following Wahl et al. (2015), we use precipitation at each analysis site as a proxy for surface runoff potential. Our four flood source variables are therefore precipitation (P), river discharge (Q), storm surge (S), and waves (W), with this latter variable being characterized by the significant wave height. Each of the four databases employed are described in the following sub-sections, including how we have selected the locations for the sensitivity analyses and compound event characterization.
2.1 Precipitation time series
Precipitation time series have been extracted from the ERA5 reanalysis, which is based on the Integrated Forecasting System (IFS) Cy41r2, which has been used in the ECMWF operational medium-range forecasting system since 2016 and benefits from a decade of developments in model physics, core dynamics and data assimilation (Hersbach et al., 2020). The ERA5 reanalysis replaces the ERA-Interim reanalysis with a significantly enhanced horizontal resolution of 31 km, compared to 80 km for ERA-Interim. Long-term (1998–2018) and monthly average precipitation rates from ERA-Interim and ERA5 have been evaluated by comparing them with values from other datasets (e.g. NASA's TRMM Multi-satellite Precipitation Analysis (TMPA) 3B43 dataset, version 7; Huffman et al., 2010), and there is a marked improvement in the estimated precipitation in ERA5 compared to ERA-Interim (Hersbach et al., 2020). The ERA5 hourly dataset spans 1979 onwards, and it is currently publicly available at the Copernicus Climate Change Service. Here, accumulated daily precipitation is calculated from hourly data.
2.2 River discharge time series
River discharge time series were extracted from the Global Flood Awareness System (GloFAS)-ERA5 reanalysis (Harrigan et al., 2020). This reanalysis is a global gridded dataset (excluding Antarctica), with a horizontal resolution of 0.1∘ at a daily time step and with a 40-year-long duration starting 1 January 1979. The GloFAS-ERA5 river discharge reanalysis was produced by coupling the land surface model runoff component of the ECMWF ERA5 global reanalysis with the LISFLOOD hydrological and channel routing model (van der Knijff et al., 2010). LISFLOOD allows the lateral connectivity of ERA5 runoff grid cells routed through the river channel to produce river discharge. ERA5 runoff is produced from the HTESSEL land surface model (Hydrology Tiled ECMWF Scheme for Surface Exchanges over Land; Balsamo et al., 2009) with an advanced land data assimilation system to assimilate conventional in situ and satellite observations for land surface variables. Groundwater and river routing parameters in GloFAS were calibrated against river discharge observations for 1287 catchments globally by Hirpa et al. (2018). A total of 463 of the largest lakes (surface area >100 km2) and 667 of the largest reservoirs have been incorporated into the GloFAS river network.
2.3 Storm surge time series
Hourly and daily storm surge time series have been extracted from the Coastal Dataset for the Evaluation of Climate Impact (CoDEC) (Muis et al., 2020). The third-generation Global Tide and Surge Model (GTSM; Kernkamp et al., 2011), with a coastal resolution of 2.5 km (1.25 km in Europe), was forced with meteorological fields from the ERA5 climate reanalysis to simulate extreme sea levels for the period 1979 to 2017. Besides the increase in the resolution of GTSM v3.0 from 5 km along the coast (50 km in the deep ocean) to 2.5 km along the coast (25 km in the deep ocean), the GTSM v3.0 model performance for tides was also improved by the implementation of additional physical processes. The validation against observed sea levels demonstrated a good performance which reflects not only the more skilful hydrodynamic simulations, but also the accuracy of the meteorological forcing. ERA5 better represents the evolution of weather systems due to an increase in the spatial and temporal resolution. The annual maxima had a mean bias 50 % lower than the mean bias of the previous Global Tide and Surge reanalysis dataset (Muis et al., 2016).
2.4 Wave time series
Hourly wave time series have been extracted from the ERA5 reanalysis at a spatial resolution of 0.5∘ with some improvements and updates compared to ERA-Interim (Hersbach et al., 2020). The model bathymetry was updated to use a more recent version of ETOPO2 (NOAA, 2006). A new wave advection scheme was introduced in the WAM model with a revised unresolved bathymetry scheme to better account for the propagation along coastlines and to better model the impact of unresolved islands (Bidlot, 2012). The slow attenuation of long period swells as well as the impact of shallow water on the wind input was introduced with an overall retuning of the level of dissipation due to white-capping (Bidlot, 2012). The atmosphere and ocean are coupled by a two-way interaction: the atmosphere generates ocean waves through the surface wind stress, while the waves influence the atmospheric boundary layer via sea-state dependencies in the surface roughness. Altimeter measurements were used to assimilate information on significant wave height. Independent buoy data were used for validation showing significant improvement in the wave height in ERA5 data compared to ERA-Interim (Hersbach et al., 2020).
2.5 Selection of the study locations
The spatial resolution of the four datasets is shown in Fig. 1a for the area of Ireland, the UK, and northwestern France. The ERA5 precipitation database has a resolution of , the ERA5 wave database has a resolution of , the CODEC storm surge database has a resolution of 2.5 km along the coast, and the GloFAS-ERA5 river discharge database has a resolution of . The river network data implemented in GloFAS for routing operations were produced using fine-scale hydrography inputs from HydroSHEDS (Lehner et al., 2008).
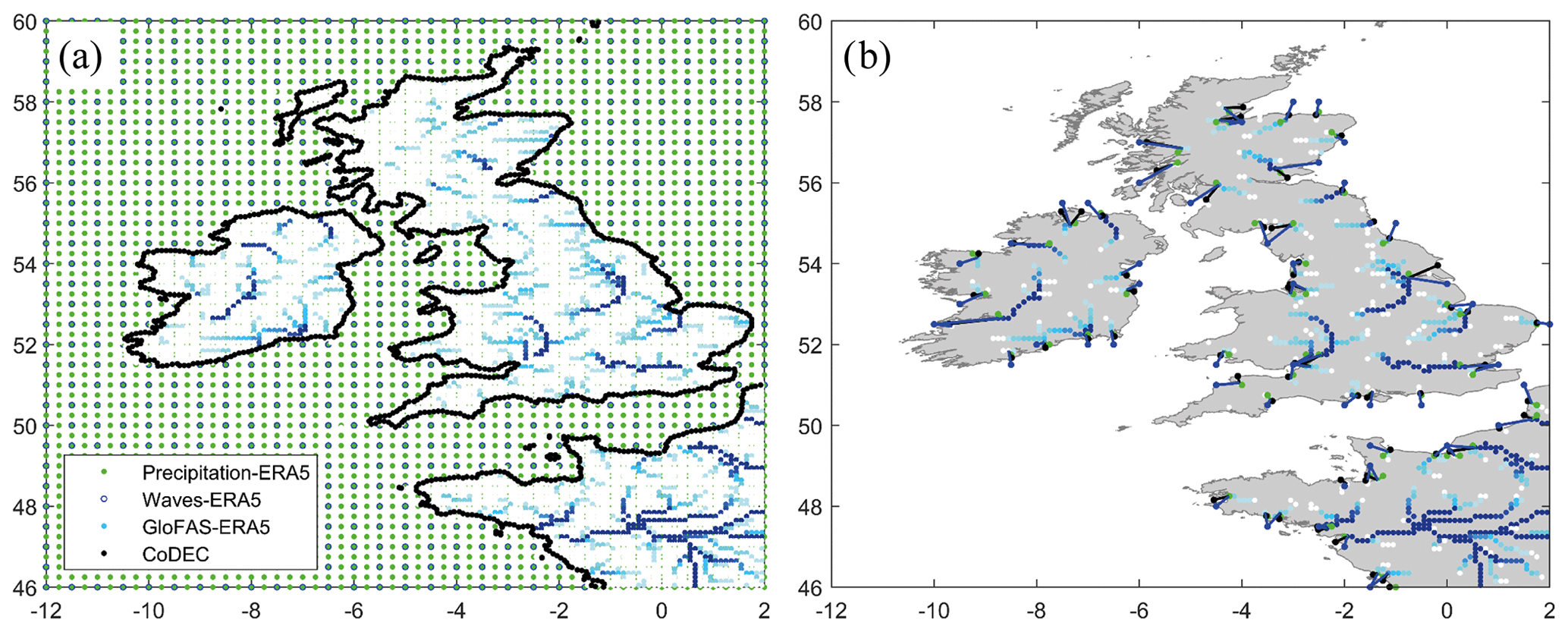
Figure 1(a) Spatial resolution of the precipitation (ERA5), river discharge (GloFAS-ERA5), storm surge (CoDEC), and wave (ERA5) data in the area of Ireland, the UK, and northwestern France. (b) Selected river discharge grid nodes at the mouth of rivers with a catchment area >1000 km2 and the closest precipitation, storm surge, and wave grid nodes along these coasts.
We used HydroSHEDS data to identify the mouths of rivers with a catchment area higher than 1000 km2 to adjust the distribution of study locations for a regional analysis. The GloFAS grid nodes closest to the locations of the river mouths were checked, and we selected the grid node with the highest river discharge. The closest grid nodes of the precipitation, wave, and storm surge databases to the selected GloFAS grid nodes were identified and are shown in Fig. 1b. Across the whole domain (see Fig. S1 in the Supplement) we analyse 540 locations.
We characterize the compound flooding potential generated by the four flood drivers (P, Q, S, W) by calculating the dependence between all possible pairs of the four main source variables along the coasts in the study area. In addition, we also linearly superimpose the storm surge and wave components into a combined sea level, ignoring the astronomical tidal component of sea level, which is deterministic (we note that for detailed flood risk assessments the timing of tidal levels with the other drivers is important, but this is beyond the scope of this analysis). We do this considering two definitions of the wave-driven sea level component: (1) a simplified wave contribution to sea level as 0.2W (e.g. Vousdoukas et al., 2017) and (2) a more sophisticated semi-empirical formulation (e.g. Vitousek et al., 2017) that also considers the wave period (Tp) to calculate setup. We refer to the resulting variables after combining the surge and wave contribution respectively as SW (sum of S and 0.2W) and WL (sum of S and semi-empirical setup) and compare results of compound flooding potential using both definitions. The seven paired driver combinations we consider here are therefore (1) Q–P [P–Q], (2) Q–S [S–Q], (3) Q–W [W–Q], (4) Q–SW [SW–Q] or Q–WL [WL–Q], (5) P–S [S–Q], (6) P–W [W–P], and (7) P–SW [SW–P] or P–WL [WL–P]. Here the indicated leading variable is the conditioning variable (dominant driver) and the second one is conditioned on the first (secondary driver) in the two-sided conditional sampling we apply.
In the following sub-sections, we first describe the sensitivity analysis designed to elucidate the extent to which the methodology employed affects the quantification of compound flooding potential. Second, we describe the clustering method used here to identify different types of multivariate compound events and the spatial distribution of compound flooding potential thereby arising across the four flood drivers considered in this study.
3.1 Sensitivity analysis
Our first objective is to assess the sensitivity of compound flood potential to different aspects of the underpinning methodology: (1) sampling method used, (2) time window investigated, (3) dependence metrics employed, and (4) definition of wave-driven sea level. Each of these sensitivity tests is discussed in turn below.
3.1.1 Sampling
Evaluation of the dependence between multiple drivers is limited to a bivariate analysis which imposes a two-sided conditional sampling to select multivariate extremes. Compound extreme events are defined in previously published studies and selected using either annual maxima (AM) or peak over threshold (POT). Although Ward et al. (2018) performed a sensitivity analysis and compared correlations between river discharge and storm surge using both POT with two thresholds (equal to 95th and 99th percentiles) and AM sampling, here we build on that prior work to also examine the effect of the sampling method in the dependence between the four coastal flooding drivers considered. The disadvantage of the AM is that events are selected that might not be considered extreme in the dominant variable. On the other hand, the POT approach increases the number of selected extreme events but introduces two parameters in the selection process: (1) the threshold and (2) the definition of independent events established by a minimum time between peaks or below the threshold. The independence between extreme events is assured by de-clustering the events based on the duration of the storms in the study area and selecting the highest event within each storm. The criteria used to select independent events in this study comprise a storm duration of 5 d for river discharge and 3 d for precipitation, storm surge, and waves. These values were selected based on an analysis of the duration of the highest storms conditioned to each variable in the study domain and following numbers used in previous studies (Ward et al., 2018; Hendry et al., 2019; Marcos et al., 2019; Bevacqua et al., 2019). Many methodologies for an automated threshold selection have been proposed based on graphical methods combined with goodness of fit (e.g. Solari et al., 2017), but such techniques are difficult to implement in regional studies due to the different characteristics of time series of the several drivers involved in coastal flooding. Hence, we decide to apply the POT method with a threshold that guarantees three (POT3) or six (POT6) events per year to also analyse the effect of the value of the threshold.
3.1.2 Time window
The conditional sampling introduces another factor that could affect the definition of compound events and this is related to the selection of the concurrent value of the secondary variable to the identified extreme events of the dominant variable. Specifically, there could be a temporal lag between variables that leads to a potential coastal flooding event. This lag can be implemented after identifying both series of extremes from the two drivers (Hendry et al., 2019) or by a time window when identifying the value of the conditioned variable (Wahl et al., 2015; Ward et al., 2018; Couasnon et al., 2020). Once a time window (Δt) is established, the value of the secondary variable is selected as the maximum value within ±Δt days (d). A variety of temporal windows have been considered, from zero lag (Bevacqua et al., 2020), through ±1 d (Wahl et al., 2015) to ±3 d (Couasnon et al., 2020) and ±5 d (Ward et al., 2018; Hendry et al., 2019). Furthermore, although river discharge data have been extracted at the river mouth, not all the databases for the four coastal flooding drivers have the same spatial resolution, with the distance between grid nodes at each location of the study domain varying considerably. Therefore, here we test the sensitivity of the identification of bivariate compound events to time windows of ±10 or ±3 d, keeping the lag which provides the highest correlation coefficient between each pair of variables at each location.
3.1.3 Dependence metrics
Several correlation coefficient definitions (e.g. Kendall's tau, Wahl et al., 2015; or Spearman's rho, Couasnon et al., 2020) and other metrics for the characterization of the dependence between events when both drivers are extreme (e.g. joint occurrence, Hendry et al., 2019; or tail dependence, Marcos et al., 2019) have been used in previous studies. Here we analyse the extent to which characterization of compound events could be affected by the selection of these varying dependence metrics.
Correlation coefficient. We use the Kendall rank correlation coefficient tau and Spearman rank correlation coefficient rho because they are commonly used nonparametric methods of detecting associations between two variables. Significance is assessed at α=0.05 (i.e. 95 % confidence level), using corresponding p values. The Spearman rank correlation between two variables is defined as the covariance of the two variables normalized by the product of their standard deviations between the rank scores of those two variables. The Kendall tau is also a rank order correlation coefficient which quantifies the difference between the percent of concordant and discordant pairs among all possible pairwise events. The Kendall correlation is considered to be more robust than the Spearman correlation because it offers better estimates with smaller asymptotic variance and is less susceptible to outliers (Ganguli and Merz, 2019).
Joint occurrence. The “joint occurrence method” (Hendry et al., 2019) consists of simply counting the number of times extreme events are identified in the two drivers analysed within the time window (Δt) considered.
Tail dependence. The dependence structure in the tails between two variables can be measured by the pair of statistics (χ,) (e.g. Coles, 2001). Both coefficients χ and are defined as limit values which tend to 1 if both variables are asymptotically dependent over a certain threshold. The coefficient χ represents the probability of bivariate extreme events when both variables are extreme and provides a measure of the dependence strength (Marcos et al., 2019), referred to as extremal correlation (Zscheischler et al., 2021). is the residual tail dependence coefficient and contains additional information about the association () between extremes of both variables when they are asymptotically independent (χ=0). We use the function taildep from the R package extRemes (Gilleland and Katz, 2016) to derive these values.
3.1.4 Definition of wave-driven sea level
Although non-linear interactions between storm surges and waves could amplify the magnitude of the sea level, the assumption that both contributions may be linearly summed is generally adopted and has often been used as a proxy of coastal flooding driven by oceanographic variables (Rueda et al., 2016; Bevacqua et al., 2019; Marcos et al., 2019). Regarding the wave contribution to sea level, when wind-generated waves approach nearshore and break in the shallow surf zone, they induce variations in the sea level at different time and space scales, enhancing coastal flooding. The highest wave-driven contribution to the total water level, called run-up, depends on two dynamically different processes: (1) wave setup, which is a time-average sea level rise occurring over a few hours to several days, and which is determined by local wind sea and swell conditions, and (2) swash, which is a high-frequency process by which sea level fluctuates due to individual incident waves, with an additional low-frequency component generated by infragravity waves (related to the presence of groups in incident short waves). The magnitude and expanse of both components depend on the sea-state characteristics (significant wave height, period, and spectrum shape; Guza and Feddersen, 2012), as well as nearshore bathymetry and topography. Spatially, setup could extend from tens of metres in steep coastal areas to several kilometres in low-sloping coastal areas, while runup extension varies from a few metres to the order of a hundred metres in reflective and dissipative environments, respectively (Dodet et al., 2019). Runup is not usually included in the wave component of the sea level driver in coastal flooding analysis because its temporal duration is on the order of hours and requires local geological characteristics that could artificially inflate the wave contribution in global and regional studies (Aucan et al., 2019). The setup contribution is defined with different levels of sophistication. Wave setup has been approximated as the significant wave height multiplied by 0.2 (Vousdoukas et al., 2017; Bevacqua et al., 2019; Marcos et al., 2019) or by applying the Stockdon formulation (Stockdon et al., 2006) with different parameterizations (Vitousek et al., 2017; Rueda et al., 2017; Melet et al., 2018). The wave setup contribution to the total water level is very sensitive to this parameterization (Aucan et al., 2019). Following Vitousek et al., 2017, we used the Stockdon formulation for dissipative beaches (Eq. 1), which is known to provide similar results as using a beach slope of 0.02 (∼50 % of the world's beaches have slopes smaller than 0.02; Aucan et al., 2019). The two variables we use here to represent the sea level are (1) SW as the sum of S and setup given as 0.2W and (2) WL as the sum of S and the setup calculated using the Stockdon formulation.
where Hs and L0 are the deep-water wave height and wavelength, respectively.
3.2 Characterization
The evaluation of compound flooding potential due to the combination of four drivers based on a bivariate analysis is a complex problem due to the high dimensionality (e.g. spatial variability of the dependence metrics and relative contribution of each pair of drivers). We apply a two-step cascade classification with two sub-objectives: (1) to analyse the dependence between the metrics that characterize the bivariate compound flooding potential between the pairs of drivers and (2) to extract spatial patterns from this dataset in order to identify hot spots of compound flooding potential arising from P–Q–S–W.
The two-step classification method consists of the use of self-organizing maps (SOMs) as the first step and applying the k-means algorithm (KMA) as the second step (Rueda et al., 2017). In this study, SOM is applied first to take advantage of the powerful visualization characteristics but not to obtain a reduced number of clusters. The k-means algorithm is a classification technique that divides the high-dimensional data space into a number of clusters, each one defined by a centroid and formed by the data for which the centroid is the nearest (Hastie et al., 2001). The SOM automatically extracts clusters of high-dimensional data and projects them into a two-dimensional organized space (2D lattice), allowing an intuitive visualization of the classification (Kohonen, 2000). A SOM algorithm is a version of the KMA in which the centroids are forced with a neighbourhood adaptation mechanism to a 2D lattice preserving the original topology of the data and producing similar patterns in the original space that are close in the 2D lattice. The maximum-dissimilarity algorithm (MDA; Camus et al., 2011) is applied to initialize the KMA to obtain a better distribution of the centroids over the multi-dimensional data space and avoid random initialization. The optimal number of clusters is evaluated using the Davis–Boudin (Davies and Bouldin, 1979) and the gap criteria (Tibshirani et al., 2001).
4.1 Sensitivity analysis
This section describes the results for the first objective, relating to the sensitivity analysis. Results from each of the four sensitivity tests are described in turn.
4.1.1 Sampling
Two-sided conditional sampling has been applied to the seven pairs of drivers identified when applying the AM and the POT methods with either three or six events per year using a time window of ±3 d. Figure 2 shows the comparison of the correlation coefficients between Q and P using the three approaches when either Q or P is the dominant driver. Only this pair of variables is shown because it presents the highest correlation, and the purpose of this subsection is only to test the sampling method. Locations are divided into five regions (see Fig. S1 for the locations of these regions): northwestern Europe (NEW, 99 locations), northeastern Europe (NEE, 165 locations), southern North Atlantic coast (SNA, 60 locations), western Mediterranean Sea (WM, 99 locations), and eastern Mediterranean Sea (EM, 117 locations). Correlation is higher between the conditional pairs of extremes selected using AM while similar correlation is obtained using POT3 or POT6, with higher dispersion in the lower values of the coefficients. Correlation coefficients calculated with AM subsets of extremes are, on average, around 0.2 higher than those derived with the POT approach, and this is consistent across all regions. Scatter plots display data only for those locations where significant (p<0.05) correlation coefficients are present. Overall, conclusions about the comparisons for all other pairs of drivers are similar to those for Q–P (Fig. S2 in the Supplement).
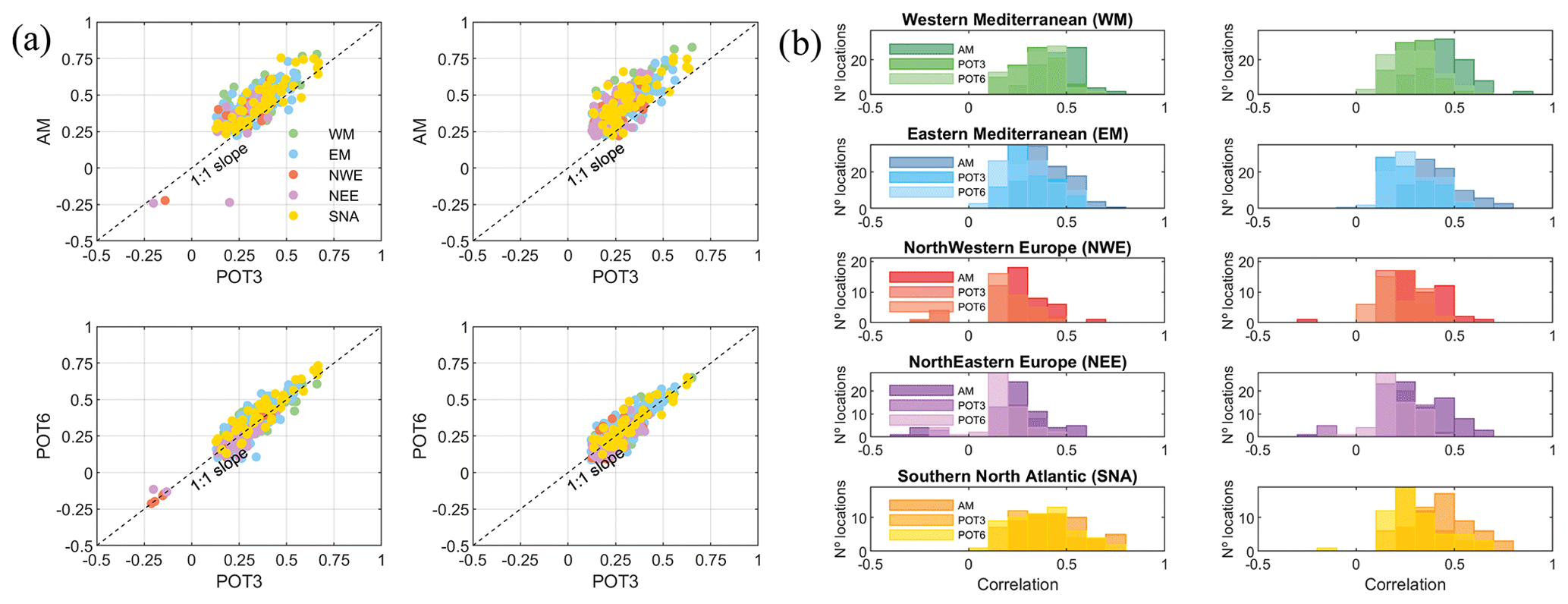
Figure 2(a) Scatter plots of the Kendall correlation (p<0.05) between Q and P using POT3 vs. AM (upper panels) and POT3 vs. POT6 (lower panels), using either Q (left panels) or P (right panels) as the dominant variable. (b) Histograms of the correlation coefficients using the three approaches (AM, POT3, and POT6) for each region when either Q (left panels) or P (right panels) is the dominant driver.
Figure 3 shows the comparison of the number of co-occurring events between Q and P using the three approaches. The number of events is higher when using POT3 compared to AM and when using POT3 compared to POT6, as expected. The scatter plots follow roughly the 1:3 or 1:2 slope, indicating an approximate tripling or doubling in the number of events between different approaches. However, the spatial pattern is similar (correlation coefficient between the number of co-occurring events is around 0.93–0.98), which means that the three methods identify broadly equivalent areas prone to compound events with both variables being extreme. Results for all pairs of drivers are shown in Fig. S3 in the Supplement, which has a similar behaviour, albeit with an overall lower number of co-occurring events.
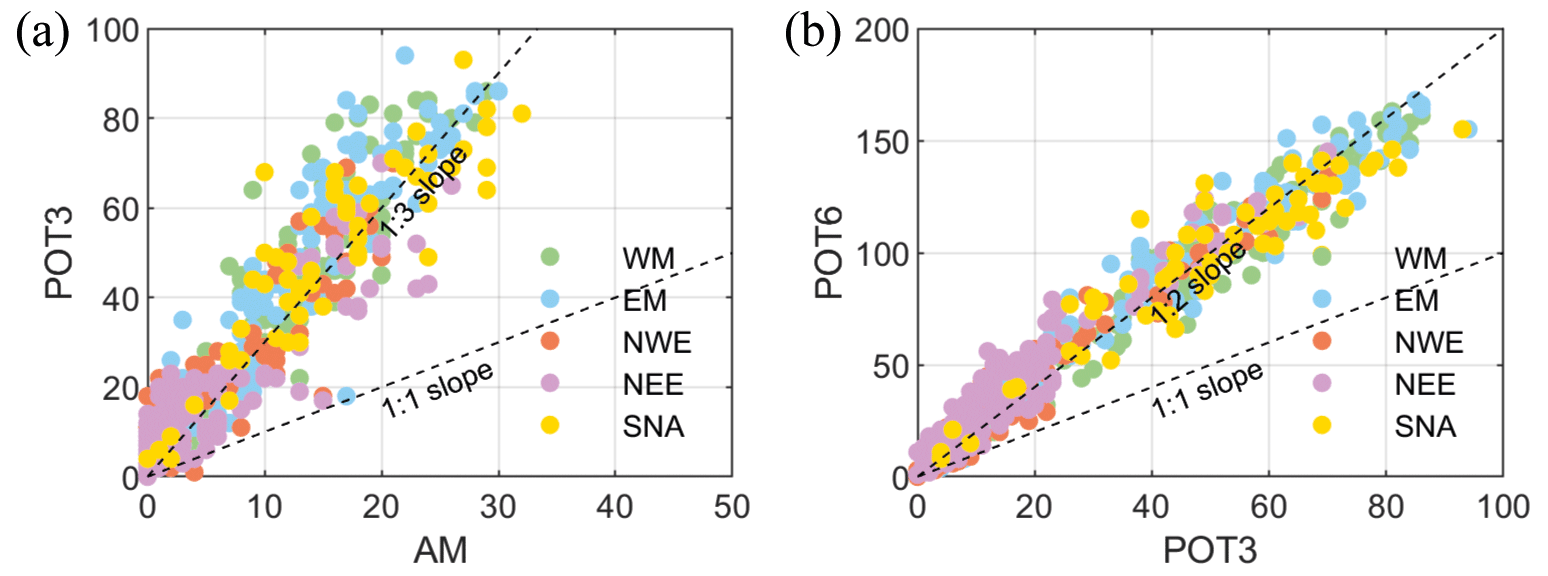
Figure 3(a) Scatter plots of the number of co-occurring events between Q and P using AM vs. POT3 (a) and using POT3 vs. POT6 (b). Dashed lines mark relationships between AM and POT3 or between POT3 and POT6 covering scaling factors equal to 2.0 and 3.0.
4.1.2 Time window
Figure 4 shows the comparison between the highest correlation coefficient obtained when using a time window (Δt) of ±3 d vs. using d for the pairs of variables Q and P, S, W, or SW using POT3 and the joint occurrence between Q and P, S, W, or SW. Only locations with a significant correlation (p<0.05) are represented in Fig. 4. Results indicate there is no major difference in the correlation between drivers when employing the two investigated time windows. Larger differences (∼0.1 higher correlation) are obtained when Q is the dominant variable in the few locations (9 of the 540) where correlation is moderate overall (∼0.30). The joint occurrences tend to be slightly higher (10 number of co-occurring events) with a higher time window, but also fewer compound events (by half) are detected in locations with low–medium joint occurrence () using a d (lower left corner of scatter plots in Fig. 4b).
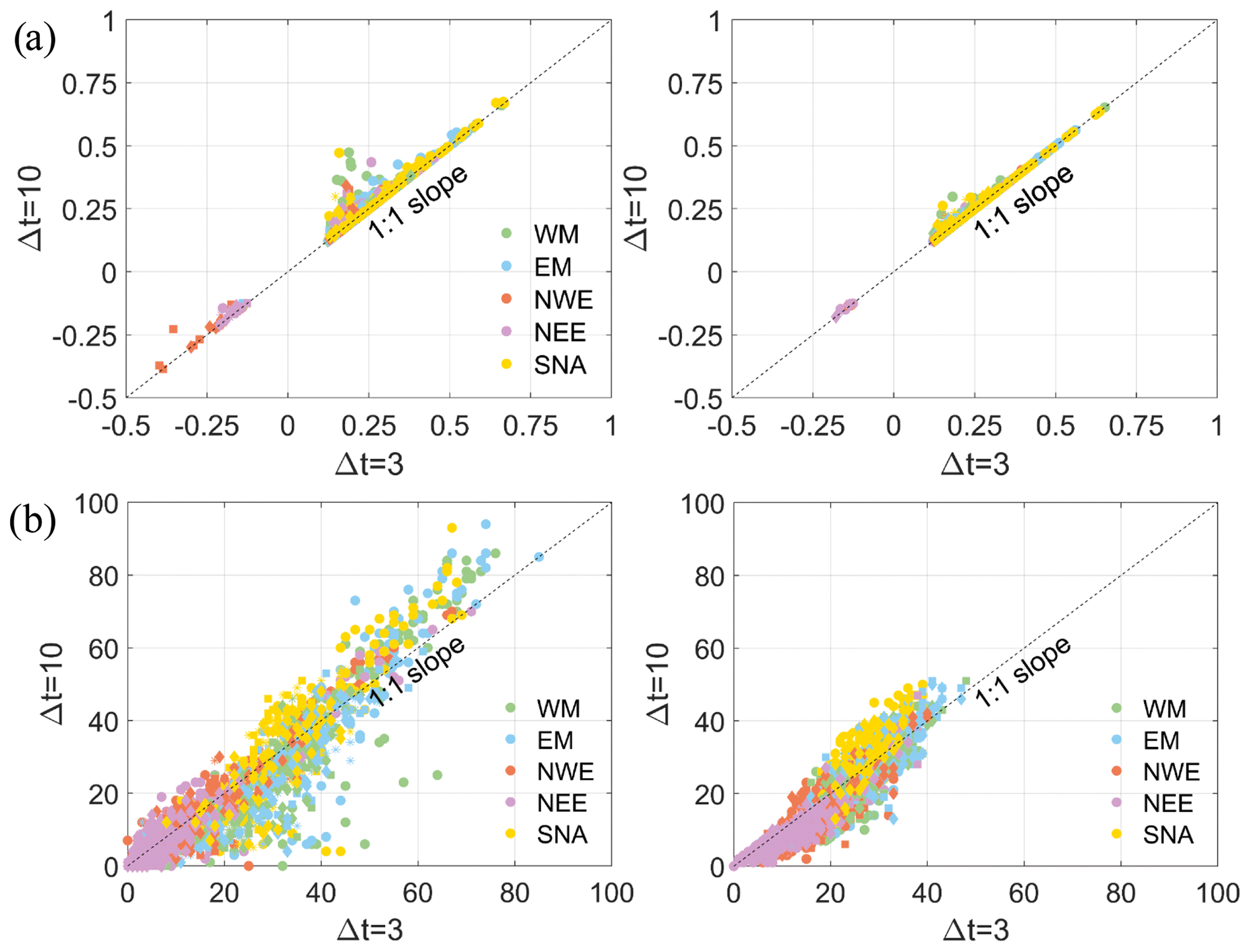
Figure 4(a) Scatter plots of the highest correlation coefficient (p<0.05) between Q and P (•), S (∗), W (▪), and SW (⧫) using a time window (Δt) of ±3 and 10 d with a POT3 approach, using Q either as the dominant (left panel) or secondary (right panel) variable in the conditional sampling. (b) Scatter plots of the joint occurrences between Q and S, W, and SW (left panel) and between P and S, W, and SW (right panel); markers are the same as in (a).
4.1.3 Dependence metrics
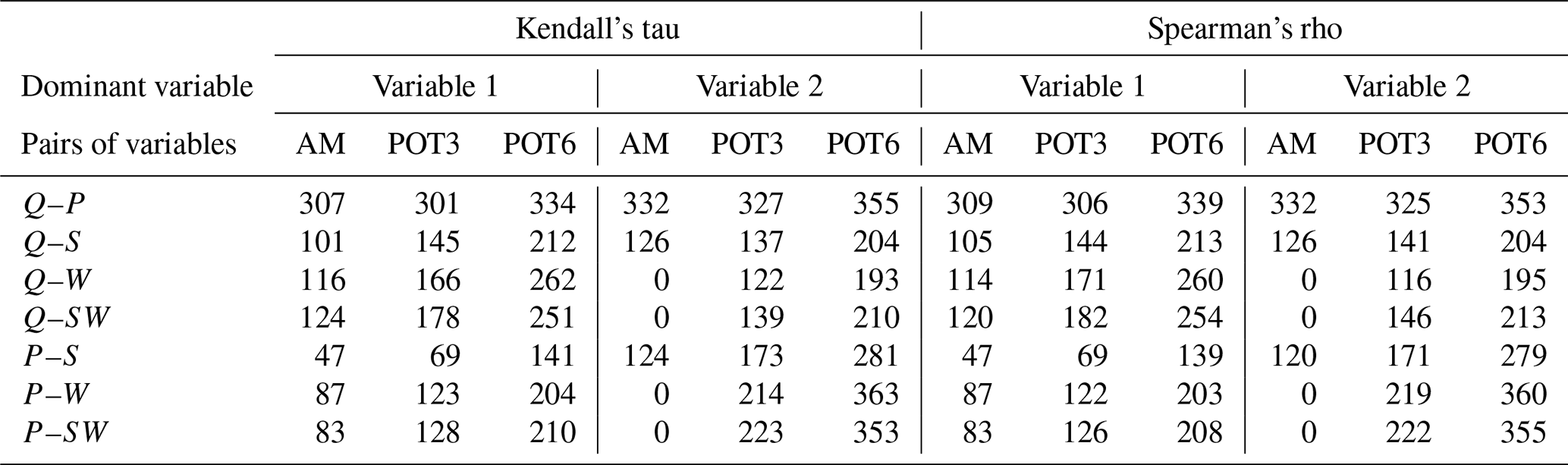
Figure 5a shows the comparisons when using the Kendall vs. Spearman rank coefficients for the pairs of variables (Q––Q, Q––Q, Q––Q, Q––Q, P––P, P––P, and P––P), using a time window of ±3 d and across the three approaches (AM, POT3, POT6) considered in the conditional sampling. There is a categorical correspondence between both correlation coefficients, with Kendall's coefficient having a tendency to be smaller than the Spearman coefficient. Therefore, to characterize compound events in terms of correlation and its spatial distribution, the information provided by both coefficients is equivalent. The number of locations with significant correlation is very similar to both correlation coefficients (see Table 1).
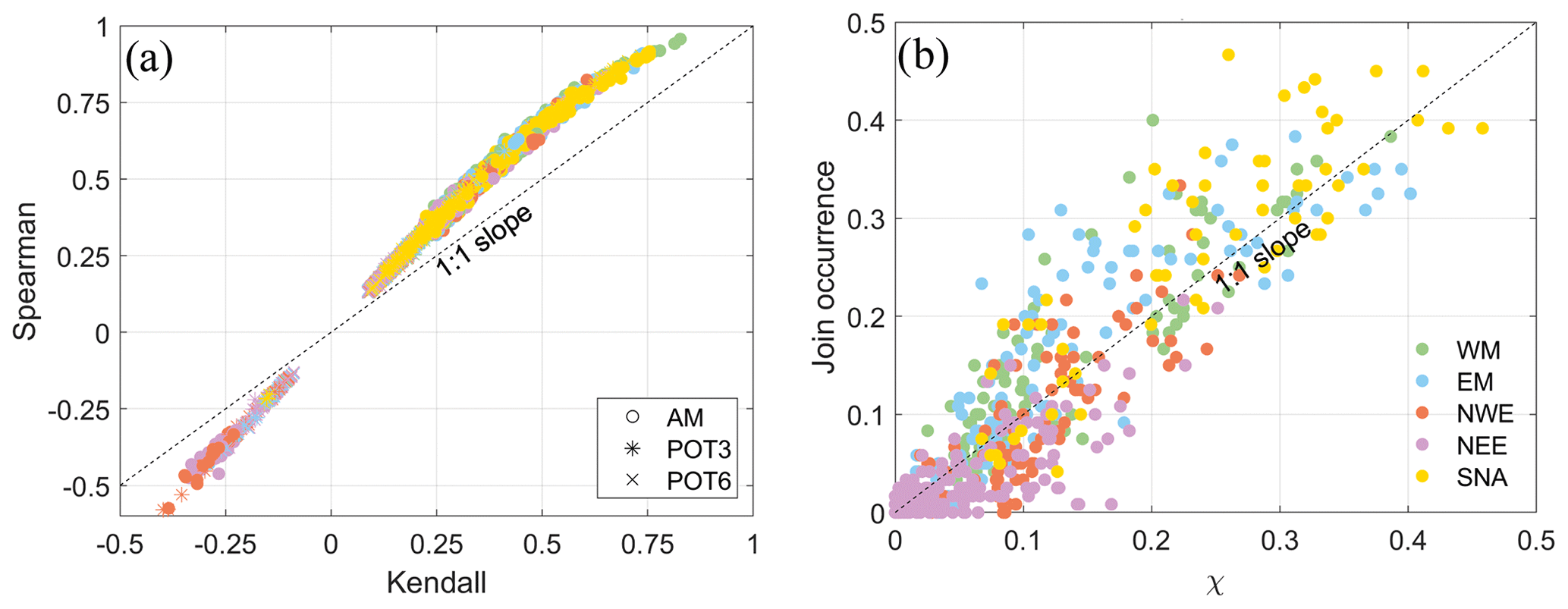
Figure 5(a) Scatter plot of the Kendall correlation coefficient (p<0.05) vs. Spearman correlation coefficient (p<0.05) between all pairs of variables. (b) Scatter plot of the statistic χ (threshold = 0.95) against the joint occurrence divided by three events per year for the pair of variables Q–S.
Table 1Number of locations with significant correlation (p<0.05), with 540 being the total number of locations.
Regarding () statistics, the usual way to decide the threshold involves making a visual examination of the evolution of their empirical estimates for increasing threshold levels (Zscheischler et al., 2021). Here, we decided to estimate χ at a probability threshold of 0.95 after careful examination of the results for different levels. The comparison between χ and the joint occurrences divided by three events per year, and the number of years (40) for the pair of variables Q–S is shown in Fig. 5b. There is high correspondence (correlation coefficient around 0.9) between both dependence metrics mainly because both of them measure the probability of bivariate extremes when both drivers are extreme. The remaining small differences may be due to different sampling processes leading to different extreme subsets. The statistic χ is estimated using the empirical distribution of the daily time series of Q (mean daily values) and S (maximum daily values), and the extremes are selected without any clustering. On the other hand, the number of co-occurring events was calculated using a POT with a threshold that guarantees three events per year and with a storm duration of 3 or 5 d to select independent events. A similar relationship between both metrics has been found for other combinations of variable pairs (not shown here).
4.1.4 Definition of wave-driven sea level
The effect of the definition of sea level (oceanographic flooding drivers) in the characterization of compound events is analysed here by comparing the Kendall correlation coefficients obtained between the pair of variables Q or P when using the two varying sea level definitions (SW and WL) used in this study (Fig. 6). Differences in the obtained correlation coefficients are typically small (mainly around 0.05), except along the southern Atlantic coast where the differences are slightly higher than 0.15. The southern Atlantic coast region presents the highest correlations between pluvial or fluvial sources and oceanographic drivers (correlation coefficients around 0.6–0.7) within the entire study domain, meaning that the identification of this region as an area with significance dependence is still preserved. The effect of the sea level definition on the correlation when Q or P is the dominant variable in the conditional sampling is much smaller (around 0.05, not shown here).

Figure 6Differences in the Kendall correlation coefficient (p<0.05) between [SW–Q] and [WL–Q] (a) and between [SW–P] and [WL–P] (b), when SW or WL is the dominant variable.
4.2 Characterization of compound flooding potential
This section describes the results obtained in relation to the second objective and contains (1) a description of the dependence between all identified pairs of drivers based on the Kendall correlation coefficient and the joint occurrences, (2) formulation of a severity index to represent the metocean climate in the study domain and which combines the extremeness of the four drivers, and (3) an identification of spatial patterns of compound flooding potential derived based on a classification of the dependence metrics between the pairs of drivers and the severity index.
4.2.1 Dependence between pairs of the four flooding drivers
Here we consider the results obtained using the POT3 method and a time window of ±3 d to characterize the multivariate compound events along the North Atlantic, Mediterranean, and Black Sea coasts. The analysis of the dependence between S–W is performed at an hourly temporal resolution and using a smaller Δt (1 d) because it is considered that both drivers contribute simultaneously to the definition of sea level. The dependence between S–W as calculated using daily data is compared with the results using hourly data (Fig. S4 in the Supplement). A reduction of the correlation coefficients in the whole study domain, especially along the Atlantic coasts of Spain and France and along the Baltic Sea coast is evident while the number of joint occurrences increases in almost all locations, especially along the Atlantic coast of the Iberian Peninsula up to north of Africa and in the Mediterranean Sea.
Kendall's correlation coefficient and the joint occurrences between the four pairs of variables: Q–P, Q–S, Q–W, and Q–SW are represented in Fig. 7. The variables Q and P (Fig. 7a) present correlation coefficients of around 0.6–0.7 along the most southern coasts of the Atlantic study region and also in some locations in the Mediterranean Sea (coast of Gibraltar Strait, Algeria, southern Italy, east coast of Turkey and Levante region in the eastern Mediterranean), while correlation coefficients of around 0.1–0.2 are more predominant along northern European coasts (except the west coast of Jutland and west coast of the UK). Similar spatial correlations are found whether Q (red scale) or P (blue scale) is used as the dominant variable in the conditional sampling, except in locations along the French coast of the English Channel, the eastern coast of the UK, and the coasts of Tunisia and Libya, where higher correlations are obtained when the compound events are conditioned to P. The joint occurrence (circle size) presents a similar spatial pattern to the correlation coefficient between these two variables, with the maximum number of co-occurring events close to 100.
For Q and S (Fig. 7b), the highest correlations are of around 0.3–0.4 when both drivers are dominant, mainly along the southern Atlantic coasts of the Iberian Peninsula, north of Africa and the Gibraltar Strait. The dependency is slightly higher when Q is the main variable in the identification of compound events, even the only correlation along most of the northern coasts of the Mediterranean Sea. Higher joint occurrences are detected in locations with higher correlation, with around 50–60 of co-occurring events. However, similar numbers of joint occurrences are found in locations along the eastern coast of Italy and the eastern north Mediterranean coasts with lower correlation.

Figure 7Kendall's correlation coefficients (p<0.05) between multivariate extremes selected using the POT3 approach and the joint occurrences between (a) Q–P, (b) Q–S, (c) Q–W, and (d) Q–SW. Correlations between compound events selected when variable 1 is the dominant driver are represented on the red scale while the blue scale denotes the correlations obtained when variable 2 is the dominant driver. The size of the circles on the blue scale represents the joint occurrences (maximum = 100). If correlation is insignificant when variable 2 is the conditioning variable, the size of the circle on the red scale represents the joint occurrences. When both correlation coefficients are insignificant, the size of the grey circle represents the joint occurrences.
For Q and W (Fig. 7c), the spatial distribution is quite similar to Q–S, with slightly smaller correlation along the most southern Atlantic coast and higher along the west coast of the Iberian Peninsula. Correlation only when Q is the dominant variable is even more pronounced in locations along the Mediterranean Sea (e.g. eastern coast of Spain). These spatial patterns are also reflected in the distribution of the correlation coefficient between Q and SW as a combination of both (Fig. 7d).
Spatial distribution of the dependence between P and S, W, or SW (Fig. S5 in the Supplement) is relatively similar to the spatial distribution between Q and the three oceanographic variables. The highest correlation between P–S or P–W (with values around 0.3–0.4) is concentrated on the southern coast of the North Atlantic Ocean. In the case of the Mediterranean Sea, similar areas with high dependence are detected including the western coast of the Black Sea and excluding many locations along the Greek coast. Correlation is higher when the conditional sampling is conditioned to oceanographic variables. S and W (Fig. S5d) are the drivers with the highest correlation, with coefficients of around 0.6–0.7 in the north Atlantic Ocean to minimum values of 0.2 in some regions in the Mediterranean Sea.
4.2.2 Severity index
Here we define an index, based on driver severity, to be included in the characterization of the spatial patterns of compound flooding potential. The driver severity is calculated as the sum of normalized thresholds of each driver, applied in the conditional sampling (multiplied by 0.2 in the case of W). Q thresholds, which cover a wide range of values, have been categorized into 10 intervals [0–10–25–50–100–250–500–750–1000–5000 → 25 000 m3 s−1] to avoid skewing the driver severity due to very high discharge magnitude in several locations. Driver severity is divided into 11 scores from 0 to 1. Figure 8d shows the spatial distribution of the severity index (SI). Areas with the highest SI are concentrated in the North Sea, the northwest of the Iberian Peninsula, the eastern coast of the Adriatic Sea, the eastern coast of the Black Sea, and a few locations that represent large rivers. Coastal areas with the lowest SI are mainly concentrated along the southern coast of the Mediterranean Sea and the most southern coast of the Atlantic Ocean of our study domain. The SI spatial distribution indicates that an identical SI ranking can be determined by different combinations of driver extremes. To facilitate this analysis, we classify the thresholds of the four drivers (shown in Fig. S6 in the Supplement) into 10 clusters to define the main combinations of driver extremeness (Fig. 8a). The probability of occurrence of each cluster (number of locations of the study domain represented by each cluster) associated with each SI rank (Fig. 8b) provides which combinations of the four driver thresholds have an equal SI rank. For example, locations with SI equal to 0 are associated with only one cluster (represented in light green), which is defined by a combination of the lowest thresholds of Q, P, and S and low W severity. On the other hand, locations with SI equal to 1 are associated with clusters 1 and 2 (in yellow and orange, respectively) which are characterized mainly by the severity of one driver (Q or S, respectively) but also associated with clusters 3, 7, and 8 (in red and dark and light blue, respectively) with high severity of two or three drivers (Q, P, and W; or Q and P; or Q and S, respectively). The spatial distribution of these clusters (Fig. 8c) allows identification of the representative combination of the four driver thresholds for each location.
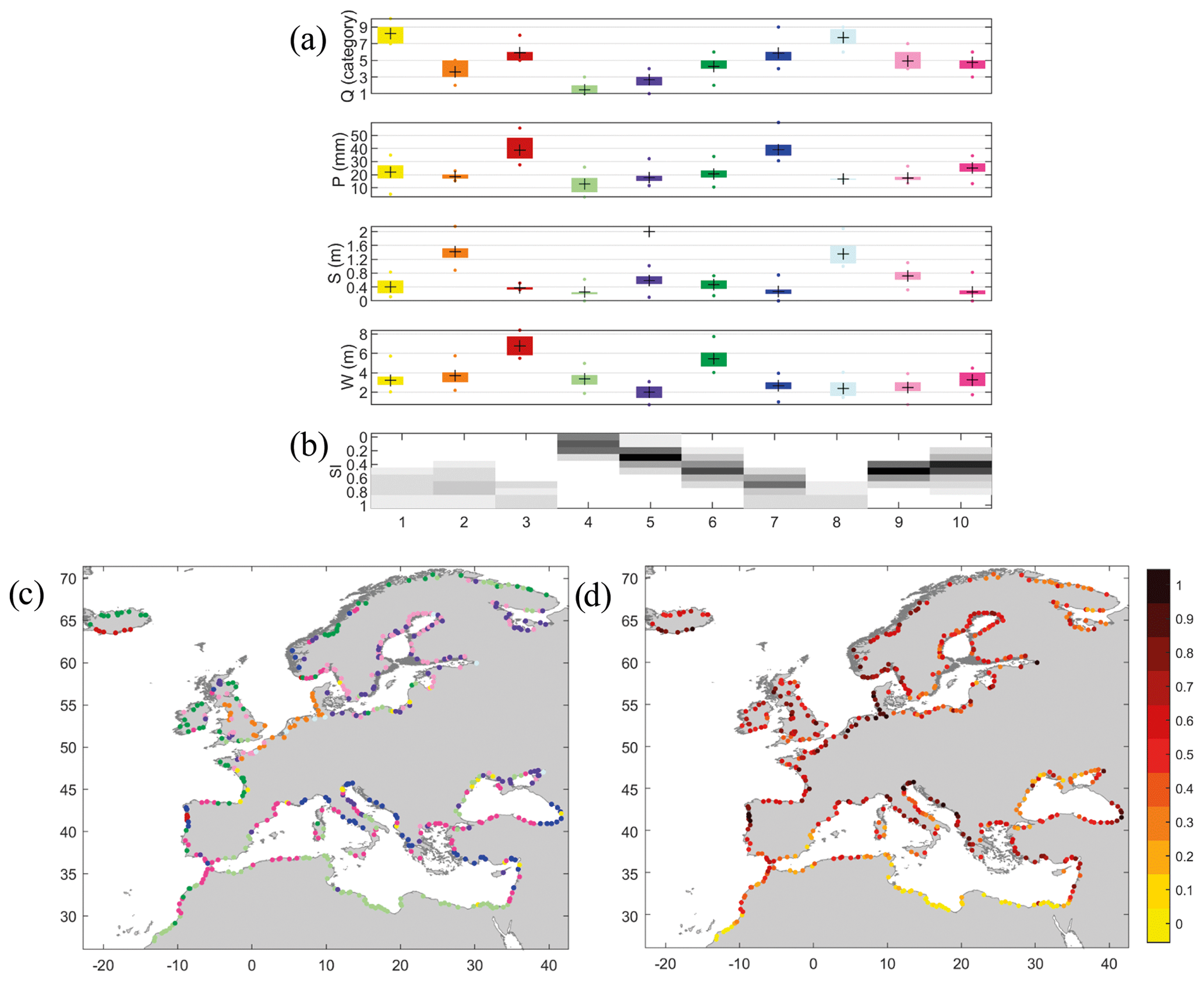
Figure 8(a) A total of 10 clusters defined by the combination of the thresholds of four drivers (Q, P, S, W) used in the conditional sampling (the same colour is used to represent the four thresholds by the mean, 25th, 75th, 5th, and 95th percentiles within each cluster). (b) Probability of occurrence of each cluster for each severity index (SI) score (greyscale shows the number of locations represented by each cluster). (c) Spatial distribution of the clusters represented in the same colour as used in (a). (d) Spatial distribution of SI based on the sum of the normalized thresholds of the four drivers.
4.2.3 Spatial patterns of compound flooding potential
The characterization of compound flooding potential can be summarized using the combination of two metrics: the Kendall correlation (τ) and the joint occurrence (JO) for the pairs Q–P, Q–SW, and P–SW and the number of co-occurring events when all three variables are extreme JO(Q–P–SW). The two-step cascade classification method is applied to the 11-dimensional array Xi=[τ1(Q–P)i, τ2(P–Q)i, JO(Q–P)i, τ1(Q–SW)i, τ2(SW–Q)i, JO(Q–SW)i, τ1(P–SW)i, τ2(SW–P)i, JO(P–SW)i, JO(Q–P–SW)i, SIi], where the subscript represents the ith grid point. Each parameter is normalized to avoid assigning different weights in the classification process. We first use the SOM algorithm to obtain a large collection of centroids () projected onto a 2D organized lattice that helps to analyse the dependence between the 11 parameters. The hexagonal SOM of 20×20 size of the compound flooding potential derived from the 11 metrics outlined above for the study sites is shown in Fig. 9. Results are shown in individual panels (Fig. 9a–k) over the same 2D lattice for the different metrics defining the SOM centroids (the hexagons in a certain position correspond to the same map unit in each figure). Note that each figure has a different scale. For example, we can observe that the three parameters related with the pair Q–P (τ1, τ2, JO; see Fig. 9a–c) present a similar distribution in the lattice, which means that there is a high dependence between them. Locations with the highest correlation between Q–P(P–Q) (Fig. 9a and b) also have the highest number of joint occurrences (Fig. 9c). Centroids with the highest dependence parameters between Q–SW and P–SW are concentrated in the upper right corner of the lattice (Fig. 9d–j). They are also characterized by the highest number of joint occurrences between Q–P (Fig. 9c) and high–medium dependence between Q–P (Fig. 9a and b). Accordingly, the highest joint occurrences between all three variables are also found in the upper right corner (Fig. 9i). Other centroids located in the upper left side of the lattice represent locations with high dependence between P–SW (Fig. 9g–h) but not between Q–SW and relatively smaller dependence between Q–P.
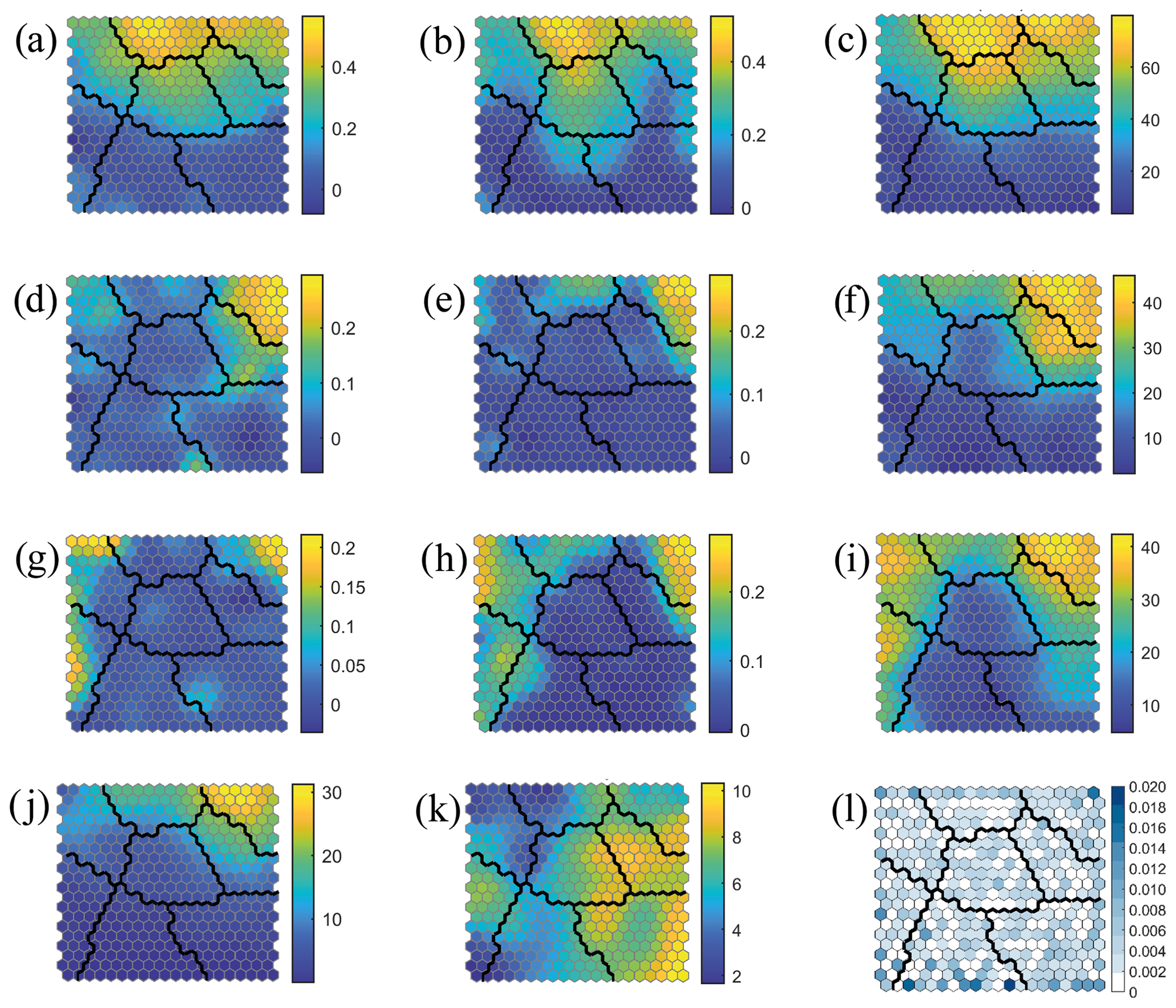
Figure 9SOM classification: (a) τ1(Q–P), (b) τ2(P–Q), (c) JO(Q–P), (d) τ1(Q–SW), (e) τ2(SW–Q), (f) JO(Q–SW), (g) τ1(P–SW), (h) τ2(SW–P), (i) JO(P–SW), (j) JO(Q–P–SW), (k) SI, (l) probability of each SOM centroid.
The severity index (Fig. 9k) reveals that locations with the highest driver severity do not present dependence between any pair of drivers (lower right corner of each individual panel in Fig. 9). These locations are the ones represented principally by clusters with the severity determined by only one driver (clusters 1 and 2 in Fig. 8a). The probability of many SOM centroids is null (Fig. 9l) because a large lattice size (20×20) is required to guarantee that SOM centroids cover the multidimensional data space defined by the 11 parameters.
In the second step, we apply the KMA to find a reduced number of clusters applied to the SOM centroids. We obtain an optimal number of eight clusters by applying the Davis–Bouldin and gap criteria. Figure 10b shows the KMA classification in eight groups over the SOM lattice and highlights the similarity between KMA clusters because neighbouring centroids in the 2D lattice have similar values of the 11 parameters (see black contours of Fig. 9 which delimitate the SOM centroids belonging to each KMA cluster). Figure 10a shows the mean value of the 11 parameters associated with each cluster and the variability within each group (25th, 75th, 5th, and 95th percentiles). The number of locations represented by each cluster is shown in Fig. 10c.
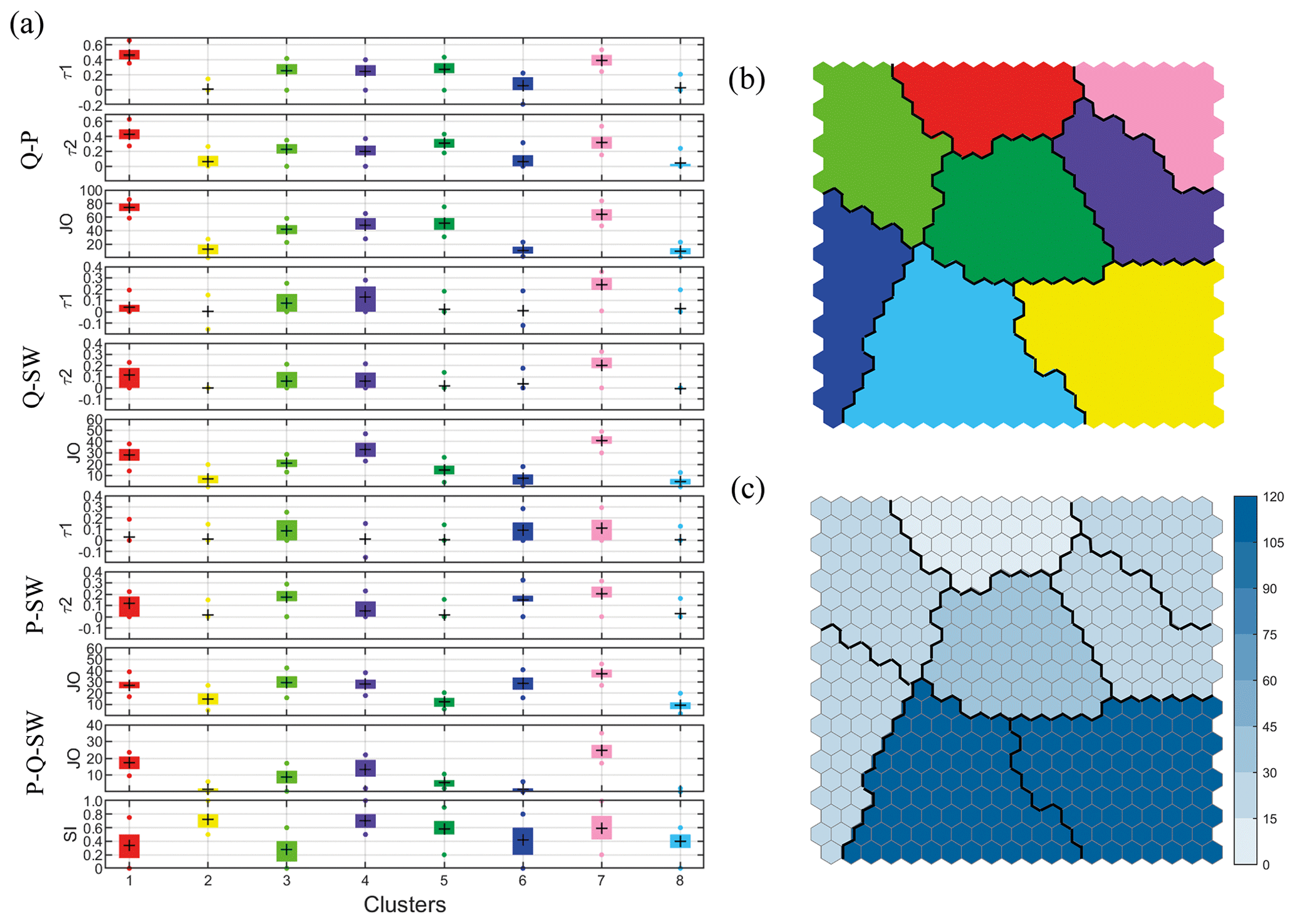
Figure 10KMA classification. (a) Characteristics of each cluster: τ1(Q–P), τ2(P–Q), JO(Q–P), τ1(Q–SW), τ2(SW–Q), JO(Q–SW), τ1(P–SW), τ2(SW–P), JO(P–SW), JO(Q–P–SW), SI. (b) The eight KMA clusters over the SOM lattice. (c) Number of locations represented by each KMA cluster.
The KMA classification reveals two clusters (red and pink groups) that represent locations where more compound flood events can occur. The pink group is characterized by the highest dependence (both correlation and joint occurrences) between Q–SW (SW–Q) and P–SW (SW–Q) and high dependence between Q–P (P–Q), which is reflected in the highest number of joint occurrences between the three drivers. The SI centroid presents a medium–high severity with a wide variability. The red group represents locations with the highest dependence between Q–P (P–Q) and medium correlation, only when extremes are selected conditioned to oceanographic drivers, and high joint occurrence between Q–SW and Q–P. It is characterized by a low–medium severity index because most of the locations present mild meteocean conditions (represented by cluster 4 in Fig. S8a in the Supplement). The purple cluster follows the other two in terms of compound flooding potential. It is characterized by a high joint occurrence between Q–SW and P–SW but lower dependence between Q–P and represents locations with a high severity index. Green and blue clusters stand out for the high numbers of compound events resulting mainly from the combination of P–SW. The green cluster is also characterized by significant dependence between Q–P and Q–SW at locations with low-severity meteocean climates. In contrast, the blue cluster represents locations without compound events generated by the combination of Q and SW. The dark green cluster represents locations where only compound events from the combination of Q–P can occur. The two remaining clusters, which represent 43 % of all study locations, are characterized by negligible compound flooding potential and are distinguished by the severity of the drivers, with the yellow cluster representing locations with high severity index and the light blue cluster representing locations with low severity index.
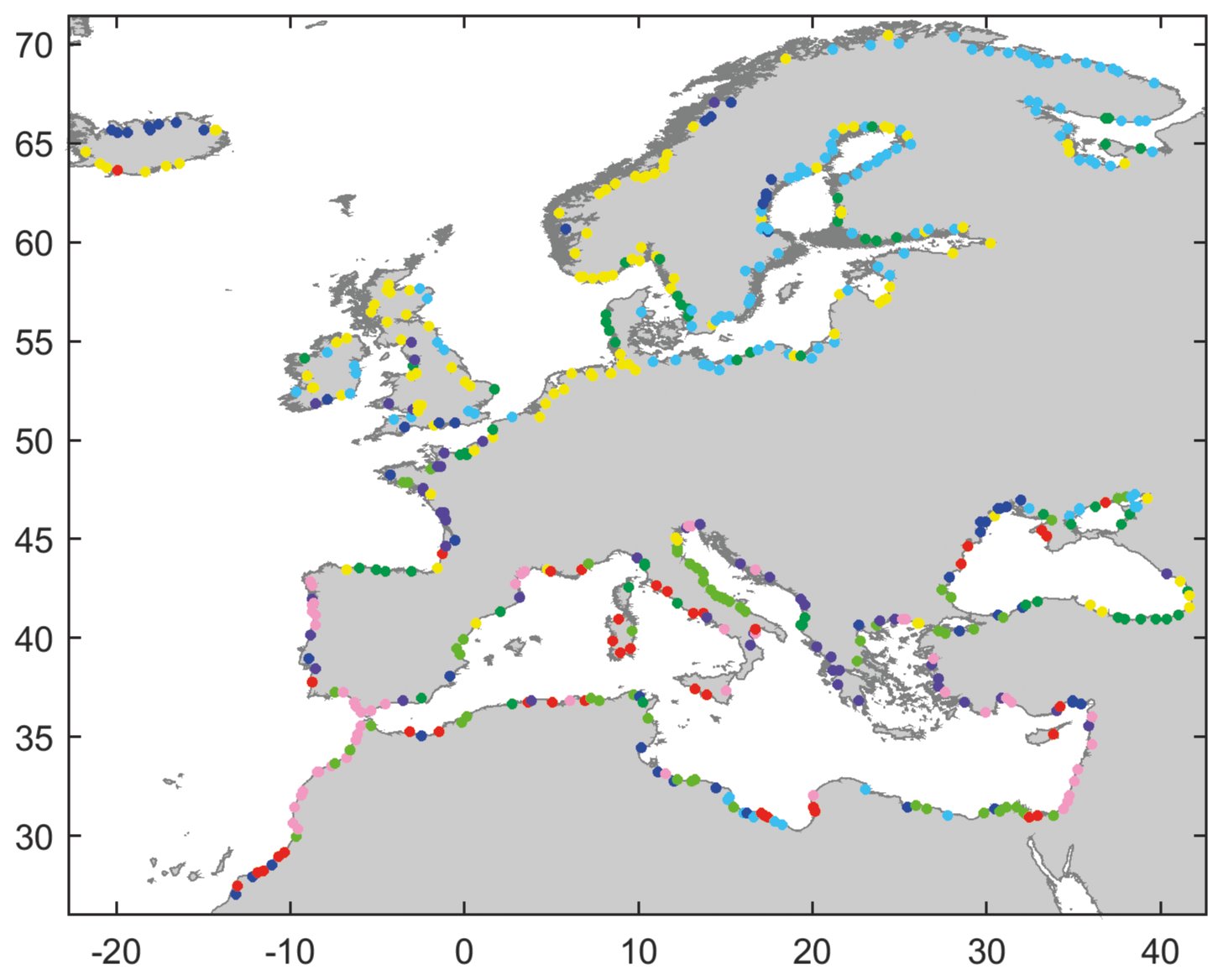
Figure 11Compound flooding potential patterns identified in this study as highlighted by the spatial distribution of the eight KMA clusters. Each KMA cluster is represented in the same colour as used in Fig. 10.
The geographical distribution of the eight KMA clusters represents the compound flooding potential patterns across the study domain (see Fig. 11). For example, the pink cluster which characterizes the pattern where the most compound events occur from the combination of the four drivers is distributed along the southern coasts of the North Atlantic Ocean, the eastern coast of France, and scattered locations along the northern coast and off the eastern coast of the Mediterranean Sea. On the other hand, the red cluster is mainly localized along the most southern coast of the North Atlantic Ocean and isolated locations in the Mediterranean and Black Sea; recall that this cluster represents locations with low driver severity. Other locations identified with significant compound flooding potential, including along the western coast of France and the UK or the northeastern coast of the Mediterranean Sea, are part of the purple cluster.
In this paper, we have analysed the compound flooding potential arising from pluvial, fluvial, and oceanographic sources. The assessment is based on a bivariate analysis of the dependence between drivers (P, Q, S, and W) using a two-sided conditional sampling. Our first objective is focused on the analysis of the sensitivity of the results to several factors that have been applied indiscriminately in previous studies with the purpose of identifying compound events and characterizing compound flooding potential.
First, we apply AM and POT sampling approaches to analyse how the choice of these approaches affects the computed dependency between variables. It is noteworthy that our results show that a lower statistical dependence is obtained when using the POT method, which is in agreement with Ward et al. (2018), yet a broad consensus has emerged in favour of the use of the POT approach for identifying extreme events (Mazas et al., 2014; Coles, 2001). The larger correlation coefficient derived using the AM approach might be due to a higher tendency that annual peaks of both drivers co-occurred, when the dependence between them is significant, while the POT method selects more combinations where drivers are less extreme, which in turn is reflected in the lower correlation coefficient. However, AM can potentially disregard information on extremes in the remaining data from using only one data point per year (Méndez et al., 2006), or select events that are not extreme, as we have observed in several of our study sites. However, the spatial patterns in both approaches are similar, and comparable areas are identified as hotspots with relatively higher dependence.
In our second sensitivity analysis, we found that the choice of the time window used has almost a negligible effect on the computed correlation coefficients (at least for the time windows in excess of the 3 d used here). The higher probability of finding more severe events using a longer Δt has only been reflected in a higher correlation in a few locations. However, it can result in a lower number of compound events when both drivers are extreme (i.e. fewer joint occurrences).
In the third sensitivity analysis, we investigated differences in the characterization of the dependence between drivers using different metrics. We found that the correlations obtained are always higher when using the Spearman rank correlation coefficient compared to the Kendall coefficient, but they are unequivocally related, and equivalent spatial distributions are obtained irrespective of the choice of the correlation coefficient. Regarding joint occurrences and tail dependence, we found that both provide comparable quantifications of the dependence between driver variables when both variables are extreme. Moreover, the concept of joint occurrences provides a better measure of the compound flooding potential because it applies a declustering method to select independent events.
The last factor we assessed is the definition of the wave-driven contribution to the sea level when using the sum of the S and W components. Any differences in correlation emerging as a result of the definition of wave-driven contribution to sea level seem to be explained by a higher dependence between surge and the simplified wave-driven sea level (20 % of W) than surge and setup also based on the wave period (see Fig. S7 in the Supplement), so that this could be due to the influence of swells. Although the same beach slope is considered in all study locations, our results showed that the combination of W and Tp in the estimation of setup influences the selection of compound events conditioned to sea level more than the semi-empirical formulation itself.
Our second objective was focused on estimating the spatial distribution of compound flooding potential considering the drivers Q, P, S, W, and SW. We observed significant differences in the dependence between the pairs of drivers and even for one individual pair depending on which driver is employed as the dominant one in the selection of the compound events. We find that the correlation coefficient and joint occurrences are not always positively related. Therefore, we considered that combinations of both metrics provide complementary information about the type of compound events and represent different flooding mechanisms (Wahl et al., 2015). The joint occurrence only characterizes compound events when both drivers are extreme. On the other hand, correlation coefficients characterize those compound events generated when one of the drivers is extreme but not necessarily the other, providing information about the relative severity of the secondary driver.
Regarding a comparison with previous global and regional studies of compound flooding potential in the study domain, the hotspots we have identified on the coasts of Portugal, the Strait of Gibraltar, and Morocco have also been detected in Couasnon et al. (2020). However, although we found a higher number of joint Q–S occurrences on the southwest and west coasts of the UK than on the east coast, as previously noted by Hendry et al. (2019), the number of co-occurrences is lower in our analysis, as is also the case around the coast of Ireland. Similar high joint occurrences between Q–S on the northern and eastern Mediterranean coasts and on the coast of Tunisia are found, in accordance with Couasnon et al. (2020). We do not observe a predominance of higher correlation when compound events are conditioned to Q as in Couasnon et al. (2020). However, differences in the correlation between the two conditional samples are found between P and S, W, or SW. As pointed out by Hendry et al. (2019), storms that generate high precipitation are different to the ones that generate high storm surges. Specifically, heavy precipitation and extreme surges are driven by deep low-pressure systems, while intense rainfall can also be caused by convection without intense cyclonic activity (Bevacqua et al., 2019). Therefore, there is higher probability of compound events when S or W is the dominant variable (generated by extratropical storms) than when compound events are conditioned to P (convective storms). This effect seems to be less perceptible between river discharge and oceanographic variables because other climatic and non-climatic factors affect the fluvial source driver (Bevacqua et al., 2020), as for example, land use characteristics or snowmelt, evaporation, and accumulated precipitation over previous weeks or months. Bevacqua et al., 2019 found the lowest joint return periods due to high dependence between P–S were concentrated along the Atlantic coast and in the Mediterranean Sea (particularly in the regions of the Gulf of Valencia (Spain), northwest Algeria, the Gulf of Lion (France), the Adriatic coast of the Balkan Peninsula, the Aegean coast, southern Turkey, and the Levante region). Even though we did not calculate return periods, our results suggest similar areas of higher dependency between P–S. We find a distinct pattern between southern and northern European coasts with more joint occurrences between S–W, especially over the Irish Sea, English Channel, and south coasts of the North Sea and Baltic Sea in line with the results of Petroliagkis (2018). Similar regional patterns of dependence between S–W as we find here were reported by Marcos et al. (2019), but we find some additional local areas with strong dependence when both drivers are extreme (characterized by the statistic χ or joint occurrence) such as the western coast of the Iberian Peninsula and certain areas in the Mediterranean Sea, perhaps because we used a higher Δt than in Marcos et al. (2019).
We apply a two-step clustering method to synthesize the high-dimensional results of the bivariate characterization of compound flooding potential from the four sources. First, the SOM algorithm allows us to analyse the multivariate dependence between the correlation coefficients and the joint occurrences between the pairs of drivers Q–P, Q–SW, and P–SW, enabling the establishment of the degree of contribution of each driver combination to compound flooding in the study area. Moreover, the method also distinguishes whether the identified compound events are more likely to occur when both drivers are extreme or when only one driver is extreme. With the second step of the clustering method, we identify a reduced number of types of compound events based on the contribution of each driver combination and the driver severity. The spatial distribution of these types of compound events reveals spatial patterns of compound flooding potential. These patterns allow us to discern locations with the highest overall compound flooding potential and the associated contributions of each pair of drivers. Additionally, we introduce a severity index to distinguish between locations with similar compound flooding potential (from the dependence perspective) but very different driver severity.
The main limitation of our study is the identification of the compound events based on drivers. None of the contributing variables have to be necessarily extreme to create a compound flooding event. Therefore, the selection of compound events should ideally be based on an impact function or a risk function that accounts for exposure and vulnerability. However, this function is usually unknown and difficult to derive, especially in regional and global studies. An intermediate approach could be based on the selection of the compound events in the extreme water levels generated by the interaction between oceanographic drivers and riverine drivers. The amplification of the flooding impact has been identified at the local scale (van den Hurk et al., 2015; Kumbier et al., 2018) and recently at the global scale (Eilander et al., 2020) using a global coupled river–coast flood model framework (Ikeuchi et al., 2017).
Although compound flooding drivers have been found to be generally captured well in different reanalysis and hindcast products (Paptrony et al., 2020), differences in the strength of dependence derived from observations and models can vary spatially and across different variables, which is more evident when regional climate models are used, even after bias corrections have been made (Ganguli et al., 2020). In addition, Paprotny et al. (2020) also detected false positive and large compound floods in observations that were missed in the modelled products. We therefore acknowledge that model biases might mischaracterize absolute values of dependence in some cases. However, the conclusions we draw from our results regarding sensitivity analysis are not likely to be altered, and the relative importance of drivers and spatial patterns would also likely be less (or not at all) affected.
In this paper we have evaluated the compound flooding potential arising from the combination of precipitation, river discharge, storm surge, and waves along the coasts of the eastern North Atlantic Ocean, Baltic Sea, Mediterranean Sea, and Black Sea (i.e. Europe and environs). The paper provides two advances. First, we performed a series of sensitivity analyses to establish how methodological choices affect the identification of compound flood events. Specifically, we investigated (1) the sampling method, (2) the time window used to match events in the two-way sampling, (3) the use of typical metrics applied in the evaluation of the dependence between drivers, and (4) the definition of the wave-driven sea level contribution. Among these, the sampling approach shows the highest differences in the quantification of the compound flooding potential. However, none of the factors analysed cause significant differences in the spatial distribution of the compound flooding potential, so similar results are identified irrespective of the method.
Second, our work provides a new regional characterization of compound flood potential using a methodology which aggregates the bivariate dependence between driver combinations. This multivariate characterization reveals three main locations with high compound flooding potential: the southern coast of the North Atlantic, the western coasts of France and the UK, and the northern coast of the Mediterranean Sea. These locations are characterized by compound events that arise from the combination of the four drivers, albeit with differences related to the driver severity, the contribution of each pair of drivers, and the predominance of compound events when drivers are extreme. Other locations of relatively high compound flood potential include the eastern coast of Italy and the southern Mediterranean Sea, where compound flooding is mainly driven by combinations of precipitation and sea level.
This regional quantitative assessment of multivariate compound flooding potential can be considered a screening tool for coastal management. The results provide information about which areas are more predisposed to experience compound flooding. In addition, this multivariate flooding potential classification identifies the relevant drivers of coastal compound flooding at each location. This assists the selection of the most appropriate methodological approach to perform high-resolution hydrodynamic and impact modelling.
ERA5 (https://doi.org/10.24381/cds.adbb2d47, Hersbach et al., 2018), GloFAS-ERA5 (https://doi.org/10.24381/cds.a4fdd6b9, Harrigan et al., 2019), and CoDEC (https://cds.climate.copernicus.eu/cdsapp#!/dataset/10.24381/cds.8c59054f?tab=overview, Muis et al., 2020) data are available on the Copernicus Climate Change Service (C3S) Climate Data Store.
The supplement related to this article is available online at: https://doi.org/10.5194/nhess-21-2021-2021-supplement.
IDH and TW conceived the project and supervised the work. PC performed the whole analysis and wrote the first draft of the manuscript. IDH, TW, and AAN provided advice on the methodology and on data analysis, discussed the results, and contributed to the writing. SED and RJN contributed to the interpretation of the results and reviewed the manuscript.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Paula Camus and Ivan D. Haigh's time on this research has been supported by the UK NERC grant CHANCE (grant no. NE/S010262/1). This material is based upon work supported by the National Science Foundation (NERC-NSF joint funding opportunity) under NSF grant number 1929382 (Thomas Wahl and Ahmed A. Nasr).
This research has been supported by the UK NERC grant CHANCE (grant no. NE/S010262/1).
This paper was edited by Bart van den Hurk and reviewed by Dominik Paprotny and one anonymous referee.
Aucan, J., Hoeke, R. K., Storlazzi, C. D., Stopa, J., Wandres, M., and Lowe, R.: Waves do not contribute to global sea-level rise, Nat. Clim. Change, 9, 2, https://doi.org/10.1038/s41558-018-0377-5, 2019.
Balsamo, G., Beljaars, A., Scipal, K., Viterbo, P., van den Hurk, B., Hirschi, M., and Betts, A. K.: A Revised Hydrology for the ECMWF Model: Verification from Field Site to Terrestrial Water Storage and Impact in the Integrated Forecast System, J. Hydrometeorol., 10, 623–643, https://doi.org/10.1175/2008JHM1068.1, 2009.
Bevacqua, E., Maraun, D., Hobæk Haff, I., Widmann, M., and Vrac, M.: Multivariate statistical modelling of compound events via pair-copula constructions: analysis of floods in Ravenna (Italy), Hydrol. Earth Syst. Sci., 21, 2701–2723, https://doi.org/10.5194/hess-21-2701-2017, 2017.
Bevacqua, E., Maraun, D., Vousdoukas, M. I., Voukouvalas, E., Vrac, M., Mentaschi, L., and Widmann, M.: Higher probability of compound flooding from precipitation and storm surge in Europe under anthropogenic climate change, Sci. Adv., 5, eaaw5531, https://doi.org/10.1126/sciadv.aaw5531, 2019.
Bevacqua, E., Vousdoukas, M. I., Shepherd, T. G., and Vrac, M.: Brief communication: The role of using precipitation or river discharge data when assessing global coastal compound flooding, Nat. Hazards Earth Syst. Sci., 20, 1765–1782, https://doi.org/10.5194/nhess-20-1765-2020, 2020.
Bidlot, J.-R.: Present Status of Wave Forecasting at ECMWF, in: ECMWF Workshop on Ocean Waves, Shinfield Park, Reading RG2 9AX, UK, 25–27 June 2012, 2012.
Camus, P., Méndez, F. J., Medina, R., and Cofiño, A. S.: Analysis of clustering and selection algorithms for the study of multivariate wave climate, Coast. Eng., 58, 453–462, 2011.
Coles, S.: An introduction to statistical modeling of extreme values, I Springer series in statistics, London, UK, Springer‐Verlag, 2001.
Couasnon, A., Sebastian, A., and Morales-Nápoles, O.: A Copula-based bayesian network for modeling compound flood hazard from riverine and coastal interactions at the catchment scale: An application to the houston ship channel, Texas, Water-Sui, 10, 1190, https://doi.org/10.3390/w10091190, 2018.
Couasnon, A., Eilander, D., Muis, S., Veldkamp, T. I. E., Haigh, I. D., Wahl, T., Winsemius, H. C., and Ward, P. J.: Measuring compound flood potential from river discharge and storm surge extremes at the global scale, Nat. Hazards Earth Syst. Sci., 20, 489–504, https://doi.org/10.5194/nhess-20-489-2020, 2020.
Davies, D. L. and Bouldin, D. W.: A Cluster Separation Measure, IEEE T. Pattern Anal., PAMI-1, 224–227, 1979.
Dodet, G., Melet, A., Ardhuin, F., Bertin, X., Idier, D., and Almar, R.: The Contribution of Wind-Generated Waves to Coastal Sea-Level Changes, Surv. Geophys., 40, 1563–1601, 2019.
Eilander, D., Couasnon, A., Ikeuchi, H., Muis, S., Yamazaki, D., Winsemius, H. C., and Ward, P. J.: The effect of surge on riverine flood hazard and impact in deltas globally, Environ. Res. Lett., 15, 104007, https://doi.org/10.1088/1748-9326/ab8ca6, 2020.
European Environment Agency: Economic losses from climate-related extremes in Europe, available at: https://www.eea.europa.eu/data-and-maps/indicators/direct-losses-from-weather-disasters-4/assessment (last access: 29 June 2021), 2019.
Ganguli, P. and Merz, B.: Trends in Compound Flooding in Northwestern Europe during 1901–2014, Geophys. Res. Lett., 46, 10810–10820, https://doi.org/10.1029/2019gl084220, 2019.
Ganguli, P., Paprotny, D., Hasan, M., Güntner, A., and Merz, B.: Projected changes in compound flood hazard from riverine and coastal floods in Northwestern Europe, Earths Future, 8, e2020EF001752, https://doi.org/10.1029/2020EF001752, 2020.
Gilleland, E. and Katz, R. W.: 320 extRemes 2.0: An Extreme Value Analysis Package in R, J. Stat. Softw., 72, 1–39, https://doi.org/10.18637/jss.v072.i08, 2016.
Guza, R. T. and Feddersen, F.: Effect of wave frequency and directional spread on shoreline runup, Geophys. Res. Lett., 39, L11607, https://doi.org/10.1029/2012GL051959, 2012.
Harrigan, S., Zsoter, E., Barnard, C., Wetterhall F., Salamon, P., Prudhomme, C. River discharge and related historical data from the Global Flood Awareness System, v2.1, Copernicus Climate Change Service (C3S) Climate Data Store (CDS), https://doi.org/10.24381/cds.a4fdd6b9, 2019.
Harrigan, S., Zsoter, E., Alfieri, L., Prudhomme, C., Salamon, P., Wetterhall, F., Barnard, C., Cloke, H., and Pappenberger, F.: GloFAS-ERA5 operational global river discharge reanalysis 1979–present, Earth Syst. Sci. Data, 12, 2043–2060, https://doi.org/10.5194/essd-12-2043-2020, 2020.
Hastie, T., Tibshirani, R., and Friedman, J.: The Elements of Statistical Learning, Springer, New York, 2001.
Hendry, A., Haigh, I. D., Nicholls, R. J., Winter, H., Neal, R., Wahl, T., Joly-Laugel, A., and Darby, S. E.: Assessing the characteristics and drivers of compound flooding events around the UK coast, Hydrol. Earth Syst. Sci., 23, 3117–3139, https://doi.org/10.5194/hess-23-3117-2019, 2019.
Hersbach, H., Bell, B., Berrisford, P., Biavati, G., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Rozum, I., Schepers, D., Simmons, A., Soci, C., Dee, D., and Thépaut, J.-N.: ERA5 hourly data on single levels from 1979 to present, Copernicus Climate Change Service (C3S) Climate Data Store (CDS), https://doi.org/10.24381/cds.adbb2d47T, 2018.
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., De Chiara, G., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., de Rosnay, P., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, 2020.
Hirpa, F. A., Salamon, P., Beck, H. E., Lorini, V., Alfieri, L., Zsoter, E., and Dadson, S. J.: Calibration of the Global Flood Awareness System (GloFAS) using daily streamflow data, J. Hydrol., 566, 595–606, https://doi.org/10.1016/j.jhydrol.2018.09.052, 2018.
Huffman, G. J., Adler, R. F., Bolvin, D. T., and Nelkin, E. J.: The TRMM Multi-satellite Precipitation Analysis (TMPA), Chapt. 1, in: Satellite Rainfall Applications for Surface Hydrology, edited by: Gebremichael, M. and Hossain, F., Springer, Berlin, 2010.
Ikeuchi, H., Hirabayashi, Y., Yamazaki, D., Muis, S., Ward, P. J., Winsemius, H. C., Verlaan, M., and Kanae, S.: Compound simulation of fluvial floods and storm surges in a global coupled river-coast flood model: Model development and its application to 2007 Cyclone Sidr in Bangladesh, J. Adv. Model. Earth Sy., 9, 1847–1862, 2017.
Kernkamp, H. W. J., Van Dam, A., Stelling, G. S., and de Goede, E. D.: Efficient scheme for the shallow water equations on unstructured grids with application to the Continental Shelf, Ocean Dynam., 61, 1175–1188, 2011.
Kohonen, T.: Self-organizing Maps, 3rd edn. Springer-Verlag, Berlin, 2000.
Kumbier, K., Carvalho, R. C., Vafeidis, A. T., and Woodroffe, C. D.: Investigating compound flooding in an estuary using hydrodynamic modelling: a case study from the Shoalhaven River, Australia, Nat. Hazards Earth Syst. Sci., 18, 463–477, https://doi.org/10.5194/nhess-18-463-2018, 2018.
Lehner, B., Verdin, K., and Jarvis, A.: New global hydrograhy derived from spaceborne elevation data, EOS T. Am. Geophys. Un., 89, 93–94, 2008.
Marcos, M., Rohmer, J., Vousdoukas, M., Mentaschi, L., Le Cozannet, G., and Amores, A.: Increased extreme coastal water levels due to the combined action of storm surges and wind-waves, Geophys. Res. Lett., 46, 4356–4364, https://doi.org/10.1029/2019GL082599, 2019.
Mazas, F., Kergadallan, X., Garat, P., and Hamm, L.: Applying POT methods to the Revised Joint Probability Method for determining extreme sea levels, Coast. Eng., 91, 140–150, 2014.
Melet, A., Meyssignac, B., Almar, R., and Le Cozannet, G.: Under-estimated wave contribution to coastal sea-level rise, Nat. Clim. Change, 8, 234–239. https://doi.org/10.1038/s41558-018-0088-y, 2018.
Méndez, F. J., Menéndez, M., Luceño, A., and Losada, I. J.: Estimation of the long-term variability of extreme significant wave height using a time-dependent peak over threshold (pot) model, J. Geophys. Res.-Oceans, 111, C07024, https://doi.org/10.1029/2005JC003344, 2006.
Moftakhari, H. R., Salvadori, G., AghaKouchak, A., Sanders, B. F., and Matthew, R. A.: Compounding effects of sea level rise and fluvial flooding, P. Natl. Acad. Sci. USA, 114, 9785–9790, 2017.
Muis, S., Verlaan, M., Winsemius, H. C., Aerts, J. C. J. H., and Ward, P. J.: A global reanalysis of storm surges and extreme sea levels, Nat. Commun., 7, 11969, https://doi.org/10.1038/ncomms11969, 2016.
Muis, S., Apecechea, M. I., Dullaart, J., de Lima Rego, J., Madsen, K. S., Su, J., Yan, K., and Verlaan, M.: A High-Resolution Global Dataset of Extreme Sea Levels, Tides, and Storm Surges, Including Future Projections, Frontiers in Marine Science, 7, 263, https://doi.org/10.3389/fmars.2020.00263, 2020 (data available at: https://cds.climate.copernicus.eu/cdsapp#!/dataset/10.24381/cds.8c59054f?tab=overview, last access: 30 June 2021).
NOAA: 2-Minute Gridded Global Relief Data (ETOPO2) v2, National Geophysical Data Center, NOAA, Asheville, NC, 2006.
Paprotny, D., Morales-Nápoles, O., and Jonkman, S. N.: HANZE: a pan-European database of exposure to natural hazards and damaging historical floods since 1870, Earth Syst. Sci. Data, 10, 565–581, https://doi.org/10.5194/essd-10-565-2018, 2018.
Paprotny, D., Vousdoukas, M. I., Morales-Nápoles, O., Jonkman, S. N., and Feyen, L.: Pan-European hydrodynamic models and their ability to identify compound floods, Nat. Hazards, 101, 933–957, https://doi.org/10.1007/s11069-020-03902-3, 2020.
Petroliagkis, T. I.: Estimations of statistical dependence as joint return period modulator of compound events – Part 1: Storm surge and wave height, Nat. Hazards Earth Syst. Sci., 18, 1937–1955, https://doi.org/10.5194/nhess-18-1937-2018, 2018.
Ridder, N. N., Pitman, A. J., Westra, S., Ukkola, A., Hong, X. D., Bador, M., Hirsch, A. L., Evans, J. P., Di Luca, A., and Zscheischler, J.: Global hotspots for the occurrence of compound events, Nat. Commun., 11, 5956, https://doi.org/10.1038/s41467-020-19639-3, 2020.
Rueda, A., Camus, P., Tomás, A., Vitousek, S., and Méndez, F. J.: A multivariate extreme wave and storm surge climate emulator based on weather patterns, Ocean Model., 104, 242–251, https://doi.org/10.1016/j.ocemod.2016.06.008, 2016.
Rueda, A., Vitousek, S., Camus, P., Tomás, A., Espejo, A., Losada, I. J., Barnard, P. L., Erikson, L. H., Ruggiero, P., Reguero, B. G., and Mendez, F. J.: A global classification of coastal flood hazard climates associated with large-scale oceanographic forcing, Sci. Rep.-UK, 7, 5038, https://doi.org/10.1038/s41598-017-05090-w, 2017.
Sebastian, A., Gori, A., Blessing, R. B., Van Der Wiel, K., and Bass, B.: Disentangling the impacts of human and environmental change on catchment response during Hurricane Harvey, Environ. Res. Lett., 14, 124023, https://doi.org/10.1088/1748-9326/ab5234, 2019.
Seneviratne, S. I., Nicholls, N., Easterling, D., Goodess, C. M., Kanae, S., Kossin, J., Luo, Y., Marengo, J., McInnes, K., Rahimi, M., Reichstein, M., Sorteberg, A., Vera, C., and Zhang, X.: Changes in climate extremes and their impacts on the naturalphysical environment, in: Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation, edited by: Field, C. B., Barros, V., Stocker, T. F., Qin, D., Dokken, D. J., Ebi, K. L., Mastrandrea, M. D., Mach, K. J., Plattner, G.-K., Allen, S. K., Tignor, M., and Midgley, P. M., A Special Report of Working Groups I and II of the Intergovernmental Panel on ClimateChange (IPCC), Cambridge University Press, Cambridge, UK, and New York, NY, USA, available at: https://www.ipcc.ch/report/managing-the-risks-of-extreme-events-and-disasters-to-advance-climate-change-adaptation/changes-in-climate-extremes-and-their-impacts-on-the-natural-physical-environment/ (last access: 29 June 2021), 109–230, 2012.
Solari, S., Egüen, M., Polo, M. J., and Losada, M. A.: Peaks Over Threshold (POT): A methodology for automatic threshold estimation using goodness of fit p-value, Water Resour. Res., 53, 2833–2849, 2017.
Stockdon, H. F., Holman, R. A., Howd, P. A., and Sallenger, A. H.: Empirical parameterization of setup, swash, and runup, Coast. Eng., 53, 573–588, https://doi.org/10.1016/j.coastaleng.2005.12.005, 2006.
Tibshirani, R., Walther, G., and Hastie, T.: Estimating the number of clusters in a data set via the gap statistic, J. Roy. Stat. Soc. B Met., 63, 411–423, 2001.
van den Hurk, B., van Meijgaard, E., de Valk, P., van Heeringen, K.-J., and Gooijer, J.: Analysis of a compounding surge and precipitation event in the Netherlands, Environ. Res. Lett., 10, 035001, https://doi.org/10.1088/1748-9326/10/3/035001, 2015.
van der Knijff, J. M., Younis, J., and de Roo, A. P. J. D.: LISFLOOD: a GIS-based distributed model for river basin scale water balance and flood simulation, Int. J. Geogr. Inf. Sci., 24, 189–212, https://doi.org/10.1080/13658810802549154, 2010.
Vitousek, S., Barnard, P. L., Fletcher, C. H., Frazer, N., Erikson, L., and Storlazzi, C. D.: Doubling of coastal flooding frequency within decades due to sea-level rise, Sci. Rep.-UK, 7, 1399, https://doi.org/10.1038/s41598-017-01362-7, 2017.
Vousdoukas, M. I., Mentaschi, L., Voukouvalas, E., Verlaan, M., and Feyen, L.: Extreme sea levels on the rise along Europe's coasts, Earths Future, 5, 304–323, 2017.
Wahl, T., Jain, S., Bender, J., Meyers, S. D., and Luther, M. E.: Increasing risk of compound flooding from storm surge and rainfall for major US cities, Nat. Clim. Change, 5, 1093–1097, https://doi.org/10.1038/nclimate2736, 2015.
Wang, Y., Xie, X., Liang, S., Zhu, B., Yao, Y., Meng, S., and Lu, C.: Quantifying the response of potential flooding risk to urban growth in Beijing, Sci. Total Environ., 705, 135868, https://doi.org/10.1016/j.scitotenv.2019.135868, 2020.
Ward, P. J., Couasnon, A., Eilander, D., Haigh, I. D., Hendry, A., Muis, S., and Veldkamp, T. I. E., Winsemius, H. C. and Wahl, T.: Dependence between high sea-level and high river discharge increases flood hazard in global deltas and estuaries, Environ. Res. Lett., 13, 084012, https://doi.org/10.1088/1748-9326/aad400, 2018.
Wu, W., McInnes, K., O'Grady, J., Hoeke, R., Leonard, M., and Westra, S.: Mapping Dependence Between Extreme Rainfall and Storm Surge, J. Geophys. Res.-Oceans, 123, 2461–2474, https://doi.org/10.1002/2017JC013472, 2018.
Yamazaki, D., O'Loughlin, F., Trigg, M. A., Miller, Z. F., Pavelsky, T. M., and Bates, P. D.: Development of the Global Width Database for Large Rivers, Water Resour. Res., 50, 3467–3480, 2014.
Zheng, F., Westra, S., and Sisson, S. A.: Quantifying the dependence between extreme rainfall and storm surge in the coastal zone, J. Hydrol., 505, 172–187, https://doi.org/10.1016/j.jhydrol.2013.09.054, 2013.
Zscheischler, J., Westra, S., van den Hurk, B. J. J. M., Seneviratne, S. I., Ward, P. J., Pitman, A., AghaKouchak, A., Bresch, D. N., Leonard, M., Wahl, T., and Zhang, X.: Future climate risk from compound events, Nat. Clim. Change, 8, 469–477, https://doi.org/10.1038/s41558-018-0156-3, 2018.
Zscheischler, J., Martius, O., Westra, S., Bevacqua, E., Raymond, C., Horton, R. M., van den Hurk, B., AghaKouchak, A., Jézéquel, A., Mahecha, M. D., Maraun, D., Ramos, A. M., Ridder, N. N., Thiery, W., and Vignotto, E.: A typology of compound weather and climate events, Nat. Rev. Earth Environ., 1, 333–347, https://doi.org/10.1038/s43017-020-0060-z, 2020.
Zscheischler, J., Naveau, P., Martius, O., Engelke, S., and Raible, C. C.: Evaluating the dependence structure of compound precipitation and wind speed extremes, Earth Syst. Dynam., 12, 1–16, https://doi.org/10.5194/esd-12-1-2021, 2021.