the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 06 May 2021
| 06 May 2021
Opportunities and risks of disaster data from social media: a systematic review of incident information
Matti Wiegmann
Jens Kersten
Hansi Senaratne
Martin Potthast
Friederike Klan
Benno Stein
Compiling and disseminating information about incidents and disasters are key to disaster management and relief. But due to inherent limitations of the acquisition process, the required information is often incomplete or missing altogether. To fill these gaps, citizen observations spread through social media are widely considered to be a promising source of relevant information, and many studies propose new methods to tap this resource. Yet, the overarching question of whether and under which circumstances social media can supply relevant information (both qualitatively and quantitatively) still remains unanswered. To shed some light on this question, we review 37 disaster and incident databases covering 27 incident types, compile a unified overview of the contained data and their collection processes, and identify the missing or incomplete information. The resulting data collection reveals six major use cases for social media analysis in incident data collection: (1) impact assessment and verification of model predictions, (2) narrative generation, (3) recruiting citizen volunteers, (4) supporting weakly institutionalized areas, (5) narrowing surveillance areas, and (6) reporting triggers for periodical surveillance. Furthermore, we discuss the benefits and shortcomings of using social media data for closing information gaps related to incidents and disasters.





A disaster is a hazardous incident, natural or man-made, which causes damage to vulnerable communities that lack sufficient coping and relief capabilities (Carter, 2008).1 Key elements to disaster management are preparedness; early detection; and monitoring a disaster from its sudden, unexpected onset to its unwinding and its aftermath. Disaster-related data may be obtained from sensor telemetry, occurrence metadata, situation reports, and impact assessments. Various stakeholders benefit from receiving such data, including task forces, relief organizations, policymakers, investors, and (re-)insurers. Data not only about ongoing incidents but also about past ones are crucial to enable forecasting efforts and to prepare for future incidents. The broad range of potential incidents and their ambient conditions require an equally broad range of monitoring techniques, each with their benefits and limitations: remote sensing provides spatial coverage but is often heavily delayed and with low resolution, ground-sensors and scientific staff are fast and precise but costly and far from ubiquitous, and citizen observers are ubiquitously available but need training and incentivization to generate reliable observations. As a consequence, disaster monitoring is often spatially sparse and temporally offset, while underfunding causes further systematic information gaps.
A rising trend in the disaster relief community is to fill information gaps through citizen observations, ranging from the registration of tornado sightings and the verification of earthquake impact to reporting hail diameters and water levels. The traditional way of acquiring this information is to actively carry out surveys and to operate hotlines, requiring significant staff and a high level of engagement by citizens. In recent years, however, new information sources are increasingly being tapped: blogs, websites, news (Leetaru and Schrodt, 2013; Nugent et al., 2017), and “citizen sensors” on social media. The promise of passively collecting disaster-related information from social media has spawned pioneering research, from detecting earthquakes to estimating the impact of a flood. However, despite several statements of interest (GDACS, 2020) and early applications – like “Did You Feel It?” (DYFI) by the USGS (2020a) to validate an earthquake's impact – most practical attempts to utilize disaster-related information from social media have yet to be acknowledged by professionals (Thomas et al., 2019).
Given the many approaches that have already been proposed to exploit citizen observations from social media for disaster-related tasks, it seems prudent to take inventory and to refine our understanding of the information gaps that are supposed to be closed. (1) What information is missing in the current acquisition process and what information is too difficult or too expensive to acquire by relief organizations in a complete and consistent way? (2) Can we expect to find this information on social media? (3) What are the risks involved when social media is integrated as a source in the acquisition process? The paper in hand contributes to answering these questions by collating the information extraction from social media to date and the observable gaps in the incident information collected by traditional means:
-
We present a systematic survey of 37 disaster and incident databases, covering a broad range of disasters, hazardous incidents, regions, and timescales. We formalize the data acquisition process underlying the databases, which produces six relevant data points from any of three traditional information sources with a defined spatio-temporal resolution.
-
We review the information gaps left open by the acquisition processes, i.e., their recall, by assessing the comprehensiveness of each database. Six major opportunities for social-media-based citizen observations are identified in this respect: (1) impact assessment and model verification, (2) narrative generation, (3) recruiting citizen volunteers, (4) supporting weakly institutionalized areas, (5) narrowing surveillance areas, and (6) reporting triggers for periodical surveillance.
-
To assess the risks of using social media data to fill the information gaps, we present an overview of the trade-off between the limited recall of traditional information sources revealed by our survey and the limited precision of information extracted from social media based on clues given from past research in the field.
Since the current landscape of disaster information systems has a variety of issues, there are also varied attempts at resolving them. Some organizations created curated collections of disasters to provide a unified index (ACDR, 2019) and harmonize disaster data (Below et al., 2010), to study disaster epidemiology (CRED, 2020), to cover new regions (La Red, 2019), or for profit (MunichRe, 2019; SwissRe, 2020; Ubyrisk Consultants, 2020). Other organizations started collaborations (GDACS, 2020), unified subordinates (NOAA, 2019; EU-JRC, 2020), or other aggregate resources (OCHA, 2019; RSOE, 2020). Even citizens contribute collaboratively through the recent-disaster list by Wikimedians for Disaster Response (2017), the Wikinews (2020) collection on disasters, and the ongoing events and disaster categories of Wikipedia (2020).
Two recent meta-studies analyze the prerequisites of using social media for relief efforts by outlining the general patterns of social media usage during disasters: according to the first study by Eismann et al. (2016), the primary use case is always to acquire and redistribute factual information, followed by any one of five incident-specific secondary uses: (1) to disseminate information about relief efforts, fundraising activities, and early warnings and to raise awareness on natural disasters; (2) to evaluate preparedness for natural disasters and biological hazards; (3) to provide emotional support during natural disasters and societal incidents; (4) to discuss causes, consequences, and implications of biological hazards and technological and societal incidents; and (5) to connect with affected citizens during societal incidents. According to studies by Reuter et al. (2018) and Reuter and Kaufhold (2017), these usage patterns can be categorized in a sender–receiver matrix describing four communication channels: (1) information exchange between authorities and citizens, (2) self-help communities between citizens, (3) inter-organizational crisis management, and (4) evaluation of citizen-provided information by authorities. The operators of disaster information systems consider primarily the unidirectional channel of citizen-to-organization communication. One of those operators, the Global Disaster Alert and Coordination System (GDACS, 2020) of the United Nations and the European Commission, remarks that the extraction of citizen observations is the key benefit of social media for their own sensor-based information system, specifically regarding “assessing the impact of a disaster” on the population to extend and verify traditional models and “assessing the effectiveness of response”, including the extraction of secondary events like building collapses. In another survey, Reuter et al. (2016) assert that “the majority of emergency services have positive attitudes towards social media.”
Most academic works since the pioneering publications by, for example, Palen and Liu (2007) conform with the assessment made by the Global Disaster Alert and Coordination System (GDACS) and focus on extracting information from citizen observations by studying how to infer influenza infection rates (Lampos and Cristianini, 2012), track secondary events (Chen and Terejanu, 2018; Cameron et al., 2012), estimate damages and casualties (Ashktorab et al., 2014), enhance the situational awareness of citizens (Vieweg et al., 2010), coordinate official and public relief efforts (Palen et al., 2010), disseminate information and refute rumors (Huang et al., 2015), generate summaries (Shapira et al., 2017), and create social cohesion via collaborative development (Alexander, 2014). Other research scrutinizes the problem of incident- or region-specific information systems by studying methods to detect earthquakes (Wald et al., 2013; Sakaki et al., 2010, 2013; Robinson et al., 2013; Flores et al., 2017; Poblete et al., 2018), wildfires, cyclones, and tsunamis (Klein et al., 2013) from Twitter streams; map citizen sensor signals to locate these incidents (Sakaki et al., 2013; Middleton et al., 2014); ingest disaster information systems for flash floods and civil unrest exclusively with social media data (McCreadie et al., 2016); and explore the technical possibilities of combining social media streams with traditional information sources in tailored information systems (Thomas et al., 2019). A comprehensive survey of the academic work in crisis informatics has been presented by Imran et al. (2018). Despite significant prior work on techniques and algorithms to detect hazardous incidents from social media streams and to extract corresponding information, the majority of approaches only explore a narrow selection of disaster types, based on little systematic discussion of the needs of traditional disaster information systems and ignoring the wealth of established remote sensing methods. As of yet, there is little understanding of the potential of social media in general and whether computational approaches generalize to the full scope of hazardous incidents.
Several comprehensive monitoring systems have been proposed to generalize from, studying particular events or focusing on a singular region or analysis method, and to effectively expose disaster management to social media data. Twitcident (Abel et al., 2012) is a framework for filtering, searching, and analyzing crisis-related information that offers functionalities like incident detection, profiling, and iterative improvement of the situational-information extraction. Data acquisition from Twitter based on keyword and a human-in-the-loop tweet relevance classification and tagging have been implemented for the Artificial Intelligence for Disaster Response (AIDR) system (Imran et al., 2014). McCreadie et al. (2016) propose an Emergency Analysis Identification and Management System (EAIMS) to enable civil protection agencies to easily make use of social media. The system comprises a crawler, service, and user interface layer and enables real-time detection of emergency events, related information finding, and credibility analysis. Furthermore, machine learning is employed, trained with data gathered from past disasters to build effective models for identifying new events, tracking their development to support decision-making at emergency response agencies. Similarly, the recently proposed Event Tracker (Thomas et al., 2019) aims at providing a unified view of an event, integrating information from news sources, emergency response officers, social media, and volunteers.
There is an apparent need to identify current information gaps and issues of operational disaster information systems as well as to investigate the potential of utilizing social media data to fill these gaps and to augment traditionally used data sources, such as in situ data, satellite imagery, and news feeds, with social media data. Recent research on event metadata extraction and management (McCreadie et al., 2016) forms a starting point for their integration into established disaster information systems.
A key prerequisite for an in-depth analysis of the gaps in incident information databases is a systematic review of the data that are currently collected across disaster types. In a first step, we narrowed the scope of disaster types to the set of most relevant ones while maintaining diversity. We started with the de facto standard, top-down taxonomy used by Emergency Events Database (EM-DAT) (Below et al., 2009), which is based on work from GLIDE, DesInventar, NatCatSERVICE, and Sigma. It has also been closely adapted by the IRDR (2020) and appears to be more scientifically sound than, for example, the glossary of PreventionWeb, the typology of the Hungarian National Association of Radio Distress- Signalling and Infocommunications (RSOE), and the bottom-up Wikipedia category graphs. We reduced the dimensionality of the type spectrum to a manageable degree by excluding exceedingly rare incident types (i.e., meteorite impacts) and combining types that are also commonly combined in the other databases (i.e., coastal and riverine floods) without crossing over sub-type hierarchies.
CDC (2020)ECDC (2020)SWDI (2020)EDO (2020)NDMC (2020)GWIS (2020)SWDI (2020)GFW (2020)EFFIS (2020)NIFC (2020)SWDI (2020)USGS (2020b)IRIS (2020)SWDI (2020)NASA (2020)NCTR (2020)NCEI-V (2020)BGS (2020)GVP (2020)SWDI (2020)ESSL (2020)SWDI (2020)Brakenridge (2020)EFAS (2020)GLOFAS (2020)SWDI (2020)ESSL (2020)SWDI (2020)SWDI (2020)SWDI (2020)ESSL (2020)SWDI (2020)SPC (2019)ESSL (2020)MRCC (2017)IBTrACS (2020)SWDI (2020)SWDI (2020)SWDI (2020)SWDI (2020)EFSA (2020)CNS (2020)eMARS (2020)ICAO (2020)ERAIL (2020)IMO (2020)ITF (2020)Table 1List of disaster groups along with corresponding disaster types and numbers of corresponding disasters in EM-DAT, GLIDE, Wikipedia, Wikidata, and in 33 other incident databases (Incident DB) since 2008. Unavailable or not applicable information is marked with –, and ∨ denotes that the disaster counts are added to the disaster in the next row due to type subsumption.
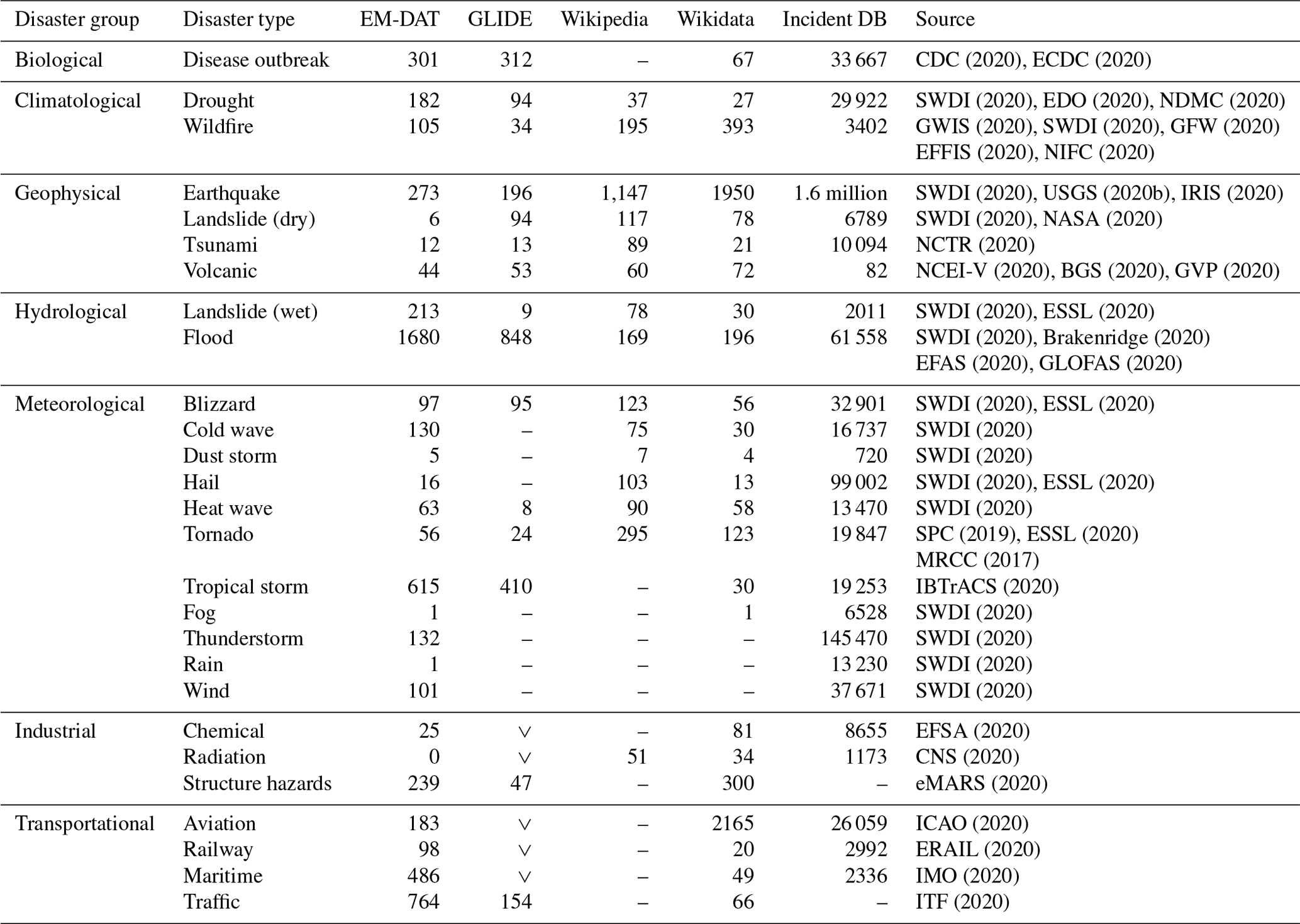
Table 1 shows the resulting taxonomy of disasters and the number of corresponding entries within EM-DAT and GLIDE as the largest expert-built disaster databases with global reach as well as on Wikipedia and Wikidata, representing global bottom-up collaborative projects. The table also lists the existing incident databases and information systems of the major academic and public institutions and NGOs for each disaster type and their cumulative number of entries in the time frame. Only disasters between 2008 and 2019 were counted, where social media started to be sufficiently widespread among the public and since all surveyed databases had consistent coverage from 2008 onward. The table illustrates the differences in size between disasters recorded by experts in EM-DAT and Glide and by citizens on Wikipedia and Wikidata as well as the notion of incidents in the other databases, where incident types are rarely systematically covered. In addition to the four mentioned disaster databases, we surveyed 33 further ones and altogether 27 disaster types.
Table 2Taxonomy of the information commonly collected about disasters.
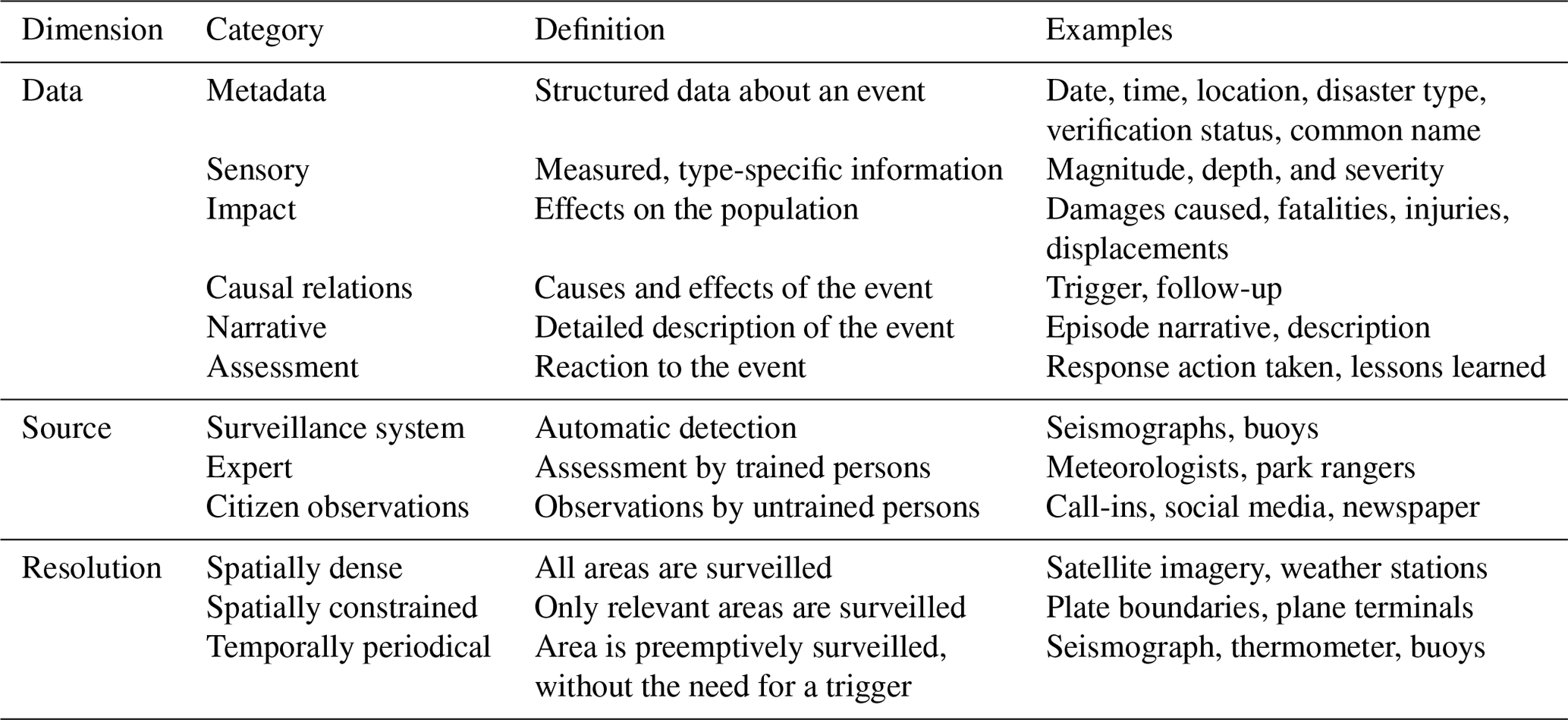
To obtain an overview of the available incident data, we devised the taxonomy shown in Table 2, selected the largest database of each incident type as a representative, and judged the existence and completeness of each category in Table 3. The taxonomy organizes the relevant information within three dimensions relevant to our research questions. (1) The data collected for each incident type show which information is in demand and which is difficult to acquire. (2) The source of the occurrence information and who detected the incident show where citizen observations are meaningful and where surveillance systems or experts are preferable. (3) The spatial and temporal resolution shows the gaps in the acquisition process that can be filled by social media data. Dimensions beyond the scope of this survey include the typical presentation used for analysis, the involvement of post-processing and validation, and whether reports are qualitative or quantitative.
Based on the categories shown in Table 2, we examined the aforementioned databases regarding gaps in the collected data by checking each database for the existence and completeness of information from each category. To acknowledge the diversity of disaster types and to avoid exaggerated expectations, a category was rated “existent” if the database contained at least one piece of information from that category and “incomplete” when less than 90 % of the entries comprise the respective information. A source was rated “existent” if it contributes to the acquisition process, either with a reference to the source in the database or by analyzing the database owner's description of the acquisition process. No sources were found “incomplete,” but we noted the distribution of the participating sources whenever possible. Spatial resolution was rated “constrained” if only selected areas are surveyed (e.g., airports or forests) and “dense” otherwise. Temporal resolution was rated “periodical” if surveillance is scheduled in intervals instead of on-demand and if it does not require a trigger event. The resolution was marked “incomplete” if the surveillance strategy does not fully cover the target, e.g., when some areas are not surveyed due to technical, jurisdictional, or financial constraints, and if incidents might be missed altogether.
Table 3Assessment of the information collected in incident databases following our information taxonomy in Table 2. The x denotes existing and the * incomplete information. The abbreviations correspond to the categories in the taxonomy. Data: metadata (M), sensor data (S), impact data (I), relations (R), narrative (N), assessments (A). Sources: surveillance (S), experts (E), citizens (C). Resolution: spatially dense (S/D) or constrained (S/P) and temporally periodical (T/P).
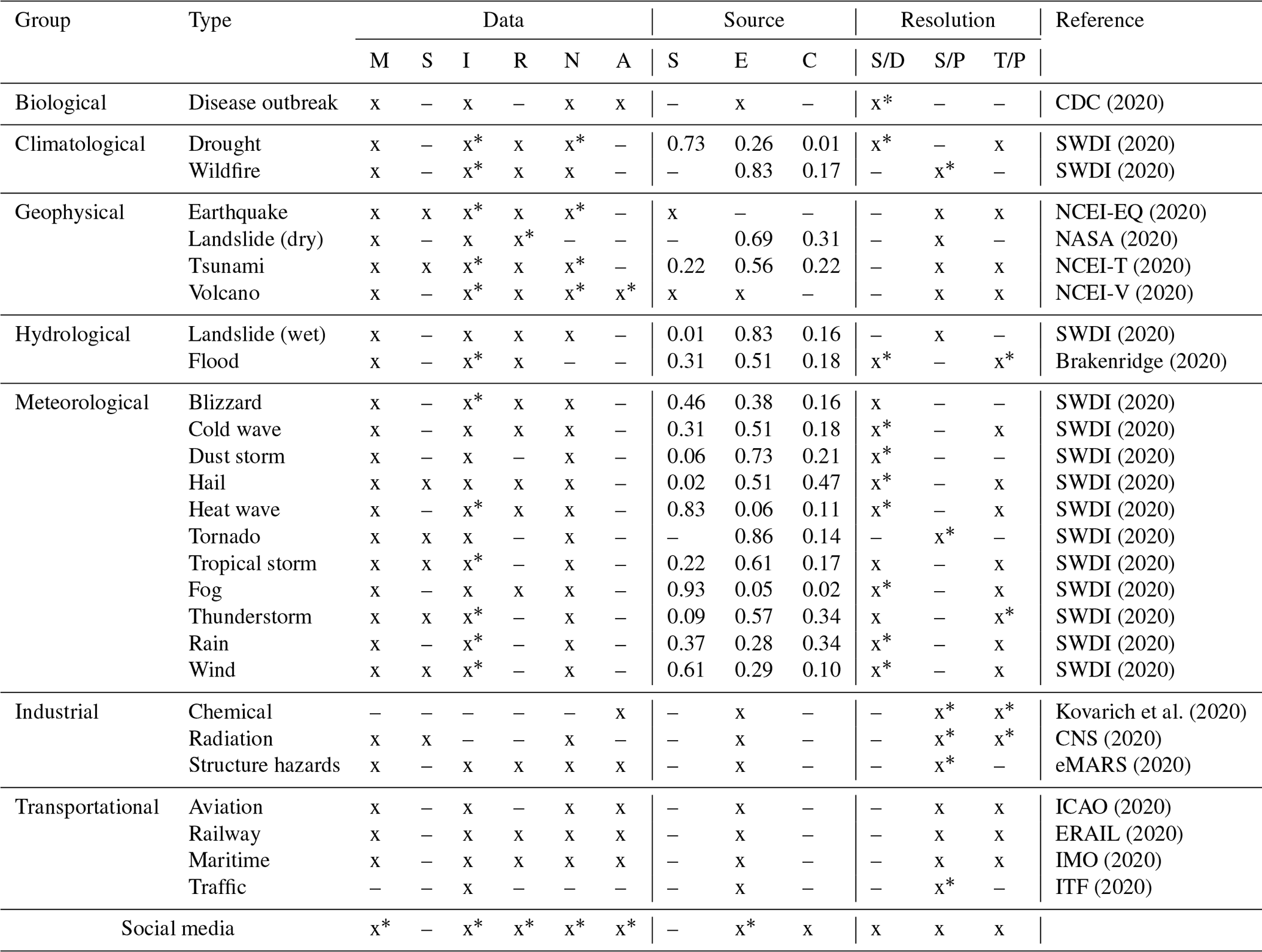
From the results of the survey shown in Table 3, the following six major opportunities of social media data for incident databases can be inferred: (1) more precise assessment of the impact of an incident across the board of disaster types; (2) generation of narratives or short descriptions, especially for droughts, geophysical incidents, and floods; (3) strengthening of the acquisition processes that already involve citizens, which is the case for more than half of the natural disasters surveyed; (4) support of weakly institutionalized regions and extension of surveillance areas; (5) narrowing the areas for spatially constrained surveillance; and (6) noticing trigger events and enabling periodical surveillance.
The first opportunity – to more precisely assess the impact of an incident – can be inferred from the difference between existing impact data (in 93 % of all incidents) and complete impact data (in 66 % of all incidents). This large gap between existing and complete data suggests that these data are frequently required but difficult to acquire. Determining the impact of an incident mostly happens by local observation. Thus, impact data are more difficult to obtain when incidents are quantitatively surveilled, which is common for natural disasters, while man-made incidents are often qualitatively recorded in written reports with a focus on impact assessment. Deriving reliable impact data from quantitative data is difficult, even more so for subtle incident types like droughts (Enenkel et al., 2020). The required observations are frequently shared on social media as images and discussions as well as personal or third-party observations, creating an opportunity to acquire the missing information.
The second opportunity – to generate narratives or short descriptions – can also be inferred from the difference between existing (in 85 % of all incidents) and complete data (in 70 % of all incidents). Narratives are short summaries of the episode, and despite their frequent existence, generating narratives by incorporating social media data as an additional source might serve to reduce the effort required from the experts that create them manually. The incident types that would profit most from narrative generation are geophysical incidents such as earthquakes (showcased by Rudra et al., 2016), droughts, and floods (showcased by Shapira et al., 2017). Social media may be used as a basis to generate narratives due to the typically high velocity of information dissemination.
The third opportunity – to recruit citizen volunteers – can be inferred from the surveyed sources (surveillance systems, experts, and citizen observations), which describe how the incidents were originally reported. Citizen observations constitute a substantial part of the acquisition process in 75 % of the surveyed natural disasters, particularly when surveillance sources are scarce. Examples are the severe weather reports collected by the National Oceanic and Atmospheric Administration (NOAA) and within the European Severe Weather Database (ESWD), NASA's crowdsourcing of landslide data (Juang et al., 2019), and the flood impact observations within PetaJakarta (Ogie et al., 2019). Citizen observations are never noted as a source for man-made incidents. Here, all entries are from involved parties, like train operators or plane engineers. It is conceivable to involve citizens in the acquisition of traffic, industrial, and extreme transportation incidents. The data acquisition for these incident types is often limited by the ability to recruit volunteers or crowdworkers, where the recruitment relies on citizen initiative, and participation demands training with specialized tools, websites, and workflows. Social media platforms simplify contacting potential volunteers and may alleviate the burden of learning specialized tools (Mehta et al., 2017).
The fourth opportunity – to support weakly institutionalized regions and extend surveillance areas – can be inferred from the frequency of incomplete records (77 % of the total) of incident types requiring dense spatial surveillance. If a dense surveillance infrastructure is necessary for a large area, weakly institutionalized regions that are limited by personal, technical, jurisdictional, or financial issues fall behind. The practical consequence is a frequent Western-world bias in data collections as shown by Lorini et al. (2020) for the unequal coverage of floods on Wikipedia. Similar problems exist for meteorological surveillance in sparsely settled or poor areas without a network of weather stations, for wildfire monitoring without terrestrial camera networks, for droughts without precipitation monitoring, and to a certain degree for disease outbreaks.2 Social media can aid the acquisition process of incidents requiring spatially dense surveillance infrastructure to a certain degree since it is also used in sparsely settled and less developed regions.
The fifth opportunity – to narrow the areas for spatially constrained surveillance – can be inferred from the frequency of incomplete records (43 % of the total) of incident types requiring constrained spatial surveillance, which typically occur in large, high-risk areas. Examples are fire watches, tornado spotting, and substance pollution and structural-hazard monitoring. Surveying these risk areas requires many distributed, mostly human spotters (Brotzge and Donner, 2013), which may be found ubiquitously on social media. In practice, these signals can be used to trigger detailed surveillance systems, as showcased by Rashid et al. (2020), who used social media to route drones for disaster surveillance.
The sixth opportunity – to notice trigger events and start periodical surveillance – can be inferred from the frequency of incomplete records (33 % of the total) of incident types requiring periodical temporal surveillance. These events typically require manually recognized trigger events to initiate and guide detailed surveillance, like wildfires, floods, and diseases. Social media can help to detect these trigger events through shared first- and third-party observations. Similarly, social media can assist 22 % of the periodically surveyed incidents with potentially long intervals in their periodical surveillance, like space-based earth observation or scheduled contamination tests.
The survey also reveals two minor opportunities: establishing incident causality and assessing the response, recovery, and mitigation efforts, although we are cautious to point to social media data as a potential solution without significant prior academic effort. Firstly, the causal relations in the databases mostly mention the main cause, e.g., if a flood has been caused by a hurricane. This knowledge is naturally incomplete if the cause is the normal operation of earth systems, for example, for earthquakes. However, causal inference through social media data is sought after for sub-events (Chen and Terejanu, 2018), like roadblocks caused by a storm, which is in this granularity not captured by our survey. Secondly, assessment of the response, recovery, and mitigation efforts are frequent for man-made disasters, where humans have more agency in prevention, but rare for natural ones, where assessments are often only created for significant incidents or in annual reports. There is an apparent value in generating assessments for individual natural incidents, but it is not yet clear how.
Furthermore, the survey hints at areas without an apparent need to utilize social media data. Metadata are largely (93 %) existent and complete if the incident is known. A similar argument can be made for sensory information; however, there is pioneering work on crowdsourcing sensory information from citizen observations, for example, inferring hail diameters or flood levels from posted images (Assumpção et al., 2018). Besides, there is no apparent need to use social media data to increase the spatial resolution if the incidents are surveyed globally through earth observation techniques and have reliable forecasting models, for example, in the case of hurricanes. Also, there is no apparent need for incidents with static or strictly tracked constrained extent, like the surveillance of regionally limited incidents; earthquakes and volcano eruptions; and the scrutiny of incidents that have reliable surveillance systems in place, like transportational incidents.
In the opportunities derived above, the task in focus is often the evaluation of citizen-provided information by authorities. The prevalent communication type of the used social media content might indeed be related to citizens' self-coordination (Reuter and Kaufhold, 2017) and information exchange. However, a more active approach of involvement (e.g., digital volunteers; Starbird and Palen, 2011), official information distribution (Plotnick and Hiltz, 2016), and participation (i.e., a bi-directional communication between involved actors and affected citizens) has the potential to support information gathering for resource planning and local forecasting activities.
When modeling the acquisition process for incident information as a process that derives relevant data from a given source, the quality of this process can be judged in terms of the well-known measures precision (correctness and reliability) and recall (completeness) of the data derived. In general, the risks of using social media as a source of information are founded in the fact that, unlike the other sources, social media is not inherently reliable. At present, using social media requires a trade-off between precision and recall since no “perfect” solution for its analysis is available.
The survey results in Table 1 show that the traditional sources of information (namely sensor-based surveillance systems, experts, and citizen volunteers) often lack recall but are optimized for precision through engineering, education, and expert scrutiny. Our survey results in Sect. 4 show that social media has the potential to increase the overall recall of all other information sources combined, though. But as a kind of “passive” crowdsourcing, the precision of social media must be expected to be significantly lower than, for example, that of “active” crowdsourcing using citizen volunteers: social media users are anonymous, and only a posteriori quality control is possible, whereas, as per Wiggins et al. (2011),3 quality assurance strategies for traditional citizen science projects can be applied before data collection (e.g., training, vetting, and testing citizens), during data collection (e.g., specialized tooling and evidence requirements), after data collection (e.g., expert reviews, statistical analysis of the participants and the data), and by contacting the citizen volunteers.
Several studies outline the general data quality issues of social media for disaster-related use cases, such as its credibility (Castillo et al., 2011) and trustworthiness (Nurse et al., 2011; Tapia and Moore, 2014). Stieglitz et al. (2018) refer to the big data quality criteria (the “Big V's”) for social media data, and in particular highlight variety and veracity as problems. Here, as per the definition of Lukoianova and Rubin (2013), veracity is understood as objectivity, truthfulness, and credibility. However, no general guidelines or best practices for data quality assurance have been established yet. Thus, the precision and the recall of social media as a source of incident information must be traded off, and it remains to be seen whether precision can be maximized without sacrificing so much recall that this source of information practically adds nothing new to the traditional ones combined. And this may depend on the type of incident or disaster at hand, its characteristics, and the opportunities pursued.
5.1 Trade-off when using social media
With the notion of incident data acquisition as a process that produces data from the given sources within spatio-temporal constraints in mind, assessing the risks of social media is equivalent to studying the effects of including versus excluding social media data as an information source. Generally, excluding social media data leads to the information gaps revealed by our survey, and including social media data leads to the issues studied by the aforementioned related work relating to objectivity, truthfulness, credibility, and trust. Although this general notion is macroscopically correct and useful, the detailed trade-off in different scenarios is scarcely explored and varies substantially. We illustrate the trade-off of acquiring incident information from social media with implications of our survey and clues from the related work, categorized within the scope of each opportunity, as summarized in Table 4.
Table 4Overview of the trade-off when using social media data to gather incident information by application scenario. The risks of excluding social media as an information source are due to lower recall, and those of including social media means are due to lower precision.
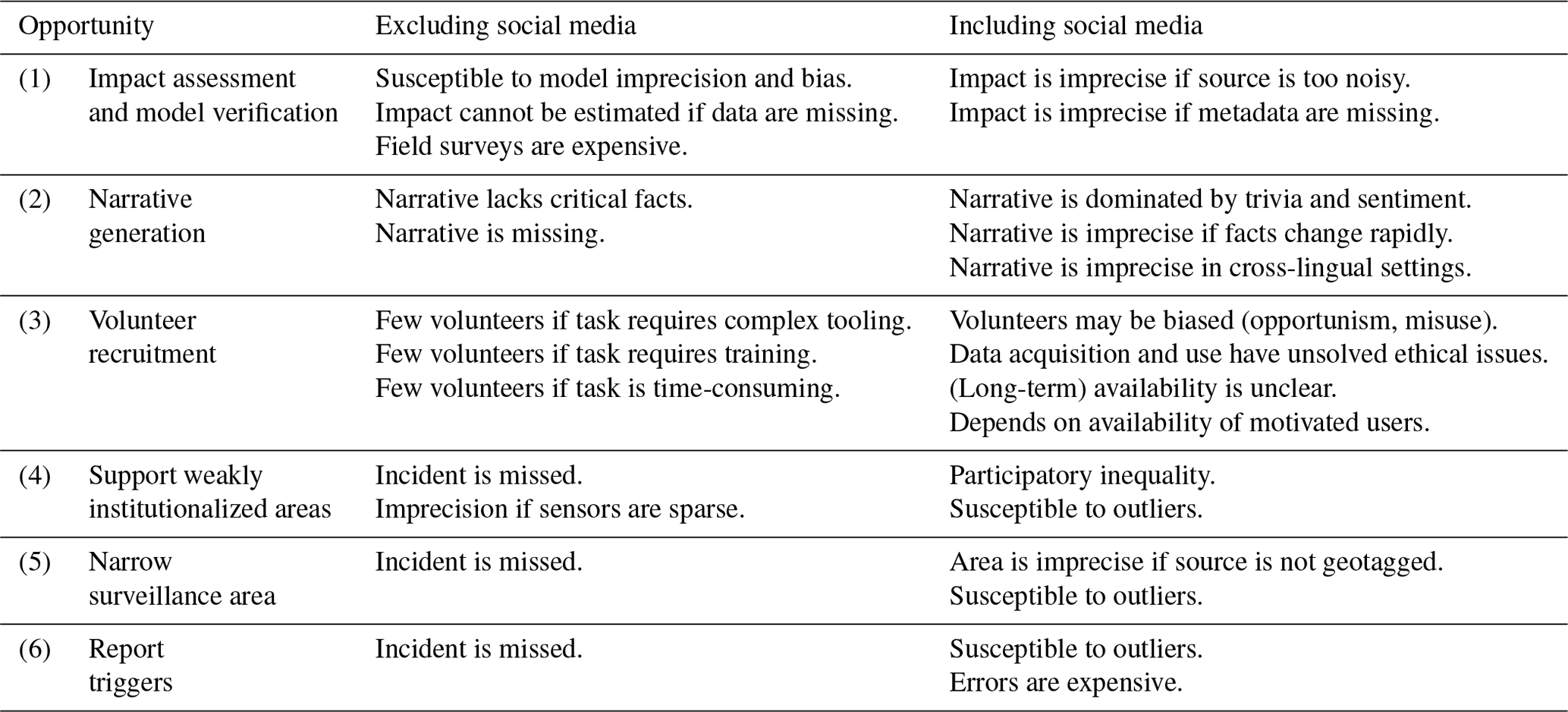
Within the first opportunity – to more precisely assess the impact of an incident – excluding social media leads to missing information, possibly imprecise estimates, and expensive excursions. Impact assessment requires substantial local observation, so the quality of the assessment often depends on the number of trained observers and the existing support infrastructure. Since both are expensive and often unavailable, estimations and modeling are frequently used tools, which naturally introduce imprecision and are susceptible to biases. These effects could be mitigated by including local observations shared through social media. The risks of including social media data are those of introducing other kinds of imprecision. Social media contains exclusively qualitative data,4 essential metadata are often coarse (like city-level geolocation instead of coordinates), and data such as shared imagery are often too complex for impact models (Nguyen et al., 2017; Ogie et al., 2019; Fang et al., 2019). Consequently, in the related work, impact assessments derived from social media are often highly imprecise: for instance, Hao and Wang (2020) resort to 500 m cells for flood mapping, and Fohringer et al. (2015) report flood inundation mapping errors at the scale of decimeters.
Within the second opportunity – to generate narratives or short descriptions – excluding social media data leads to missing narratives or narratives that miss the critical but not previously observed facts. These effects can be mitigated by deriving the necessary facts or narrative steps from information shared on social media. The risks of including social media data are distortions towards trivia, imprecision in evolving situations, and imprecision in cross-lingual settings. Since sharing sentiment and discussion is one of the primary uses of social media in a crisis (Palen and Liu, 2007), factual information is easily drowned out, and narrative generation may become biased towards trivia and sentiment, as noted by Alam et al. (2020). Similarly, Rudra et al. (2018) note that extracting facts from social media relies on semi-automated filtering, and, although these methods achieve accuracies past the 90 % level, critical facts can still be lost. They also conclude that, for example, impact facts change as an incident progresses, and users may not share the most recent information at a given time, so the chronological order on social media may not correspond to the actual order of events, giving rise to conflicting points of view. Rudra et al. (2018) also demonstrate issues in cross-lingual settings since social media discussions on a single topic feature multiple languages and code-switching. Besides the unsolved algorithmic challenges, this also poses challenges to human assessors. Concluding, Aslam et al. (2015) note as a result of the temporal summarization track of the Text REtrieval Conference (TREC) 2015 that automated systems “either had a fairly high precision or novelty with topic coverage, […] and it appears that attaining high precision is more difficult than achieving recall”.
Within the third opportunity – to recruit citizen volunteers – excluding social media data leads to fewer volunteers due to the barriers of entry introduced by lack of awareness, complex tooling, training requirements, and the required time investment, which are partially related to the quality assurance practices. These effects can partially be mitigated by recruiting volunteers for simple tasks through social media. The risks of recruiting volunteers through social media are lack of motivation and biases of the users. Ogie et al. (2018) show that the likelihood of participating and the likelihood of contributing valuable information are lower for ordinary citizens than for response personnel. They conclude that the quality of crowdsourcing via social media heavily depends on the user's perception of the value of their data and the user's exposure to the incident (Ogie et al., 2019). In a review of 169 studies of passive crowdsourcing in environmental research, Ghermandi and Sinclair (2019) additionally conclude that ethics and long-term availability are issues with volunteers on social media.
Within the fourth opportunity – to support weakly institutionalized regions – excluding social media data leads to missing or imprecise incident data, particularly when sensors or experts are sparse, and measures can only be triangulated or estimated. These effects can be mitigated by including local observations shared through social media. The risks of including social media data are imprecision due to participatory inequality and, as a consequence, susceptibility to outliers. Weakly institutionalized regions are highly susceptible to participatory inequality (Ogie et al., 2019) in that fewer but more educated and motivated users dominate social media in these regions, distorting the picture. Xiao et al. (2015) and Wang et al. (2019) confirm that users from socially vulnerable areas share less information via social media and that social media data may not reveal the true picture due to the unequal access to social media and heterogeneous motivations in social media usage. As a consequence, the better-situated areas within weakly institutionalized regions may appear more vulnerable or more affected by incidents.
Within the fifth opportunity – to narrow the areas for spatially constrained surveillance – excluding social media data leads to missing incident data. These effects can be mitigated by determining areas for thorough surveillance based on observations shared through social media. The risks of including social media data are imprecision due to inconsistent metadata and susceptibility to outliers. Metadata like geotags are essential when drawing geographical conclusions from social media data, like the area to survey. However, geotags are often either optional, hence unavailable, or in a coarse, city- or state-level resolution. If precise, spatial information is required, it must be predicted or estimated, which reduces precision. If sufficient observations are shared, the area for spatially constrained surveillance can be triangulated to mitigate the imprecision (Senaratne et al., 2017). Without sufficient observations, the conclusions are susceptible to outliers, particularly if the endangered area is large and uninhabited so that observations naturally become sparse. These outliers occur either when coordinates are wrongly estimated or in the reported cases of misuse like phishing (Verma et al., 2018), fake news (Zhang and Ghorbani, 2020), and rumors or exaggerations (Mondal et al., 2018).
Within the sixth opportunity – to notice trigger events and start periodical surveillance – the risks of excluding or including social media data align with the fifth opportunity. Noticing trigger events is susceptible to outliers in low-activity regions and for low-impact incidents where online discussion is limited. Wrongly noticing triggers for incident types like wildfires, floods, and diseases may lead to expensive surveillance campaigns, blocking resources, and harming citizen trust in institutions.
This work attempts to answer the role which social media data can play in disaster management by systematically surveying the currently available data in 37 disaster and incident databases, assessing the missing and sought-after information, pointing out the opportunities of information spread via social media to fill these gaps, and pondering the risks of including social media data in the traditional acquisition process. The identified gaps hint at six primary opportunities: impact assessment and verification of model predictions, narrative generation, enabling enhanced citizen involvement, supporting weakly institutionalized areas, narrowing surveillance areas, and reporting triggers for periodical surveillance. Additionally, we point to potential opportunities warranting further research: determining causality between incidents and sub-events and generating assessments about the response, recovery, and mitigation efforts. Given proper awareness of the risks, seizing the determined opportunities and including social-media-based citizen observations in incident data acquisition can greatly improve our ability to analyze, cope with, and mitigate future disasters. However, we conclude that social media should not be included undifferentiated but as a tool to mitigate the weaknesses of traditional sources for specific data needs in specific incidents and application scenarios.
6.1 Limitations
In favor of following a reproducible and data-driven approach to surveying, we do not consider information that may be needed but is never contained in any of the databases. This also means that we do not suggest limiting innovation or research when rejecting use cases like earthquake detection or metadata extraction. There may be novel uses for social media data which are not revealed by our survey. Additionally, our analysis does not consider the use of social media analysis to reduce detection times and applications that use social media to retrieve other sources, like shared news articles. Note that we limited our conclusions about traffic incidents due to the limited data in the International Road Traffic and Accident Database (IRTAD) and that we mostly ignored uncommon and unforeseen events because of the naturally limited data to survey.
The origin of the data we surveyed is directly referenced, and criteria for inclusion are described in Sect. 3.
MW and JK conducted the database survey and the survey of the related work. MW provided the inital draft with contributions from JK. HS provided the idea and initial draft of Sect. 5. MP, FK, and BS revised the manuscript. All authors contributed to the analysis.
The authors declare that they have no conflict of interest.
This article is part of the special issue “Groundbreaking technologies, big data, and innovation for disaster risk modelling and reduction”. It is not associated with a conference.
The article processing charges for this open-access publication were covered by the German Aerospace Center (DLR).
This paper was edited by Mario Lloyd Virgilio Martina and reviewed by two anonymous referees.
Abel, F., Hauff, C., Houben, G., Stronkman, R., and Tao, K.: Twitcident: fighting fire with information from social web streams, in: Proceedings of the 21st international conference on world wide web, 16 April 2012, pp. 305–308, Lyon, France, 2012. a
ACDR: Asian Disaster Reduction Centre, GLobal IDEntifier Number, available at: http://glidenumber.net (last access: 28 April 2021), 2019. a
Alam, F., Ofli, F., and Imran, M.: Descriptive and visual summaries of disaster events using artificial intelligence techniques: case studies of Hurricanes Harvey, Irma, and Maria, Behav. Inform. Technol., 39, 288–318, https://doi.org/10.1080/0144929X.2019.1610908, 2020. a
Alexander, D. E.: Social Media in Disaster Risk Reduction and Crisis Management, Sci. Eng. Ethics, 20, 717–733, https://doi.org/10.1007/s11948-013-9502-z, 2014. a
Ashktorab, Z., Brown, C., Nandi, M., and Culotta, A.: Tweedr: Mining Twitter to Inform Disaster Response, in: 11th Proceedings of the International Conference on Information Systems for Crisis Response and Management, University Park, Pennsylvania, USA, 18–21 May 2014, 354–358, 2014. a
Aslam, J. A., Diaz, F., Ekstrand-Abueg, M., McCreadie, R., Pavlu, V., and Sakai, T.: TREC 2015, Temporal Summarization Track Overview, in: Proceedings of The Twenty-Fourth Text REtrieval Conference, TREC 2015, Gaithersburg, Maryland, USA, 17–20 November 2015, National Institute of Standards and Technology (NIST), 2015. a
Assumpção, T. H., Popescu, I., Jonoski, A., and Solomatine, D. P.: Citizen observations contributing to flood modelling: opportunities and challenges, Hydrol. Earth Syst. Sci., 22, 1473–1489, https://doi.org/10.5194/hess-22-1473-2018, 2018. a
Below, R., Wirtz, A., and Guha-Sapir, D.: Disaster Category Classification and Peril Terminology for Operational Purposes, http://cred.be/sites/default/files/DisCatClass_264.pdf (last access: 1 June 2020), 2009. a
Below, R., Wirtz, A., and Guha-Sapir, D.: Moving towards Harmonization of Disaster Data: A Study of Six Asian Databases, Centre for Research on the Epidemiology of Disasters, Brussels, http://www.cred.be/sites/default/files/WP272.pdf (last access: 1 June 2020), 2010. a
BGS: British Geological Survey, Volcano Global Risk Identification and Analysis Project (VOGRIPA), available at: http://www.bgs.ac.uk/vogripa/index.cfm, last access: 1 June 2020. a
Brakenridge, G.: Global Active Archive of Large Flood Events, Dartmouth Flood Observatory, available at: http://floodobservatory.colorado.edu/Archives/index.html, last access: 1 June 2020. a, b
Brotzge, J. and Donner, W.: The Tornado Warning Process: A Review of Current Research, Challenges, and Opportunities, B. Am. Meteorol. Soc., 94, 1715–1733, https://doi.org/10.1175/BAMS-D-12-00147.1, 2013. a
Cameron, M. A., Power, R., Robinson, B., and Yin, J.: Emergency Situation Awareness from Twitter for crisis management, in: Proceedings of the 21st World Wide Web Conference, WWW 2012 – Companion, 695–698, Lyon, France, 16–20 April 2012, https://doi.org/10.1145/2187980.2188183, 2012. a
Carter, W.: Disaster Management: A Disaster Manager's Handbook, Asian Development Bank, Manila, Philippines, 416 pp., http://hdl.handle.net/11540/5035 (last access: 28 April 2021), ISBN 971-561-006-4 and 978-971-561-006-3, 2008. a
Castillo, C., Mendoza, M., and Poblete, B.: Information credibility on twitter, in: Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Hyderabad, India, 28 March–1 April 2011, 675–684, 2011. a
CDC: Centers for Disease Control Prevention, National Notifiable Diseases Surveillance System, available at: https://wwwn.cdc.gov/nndss/, last access: 1 June 2020. a, b
Chen, C. and Terejanu, G.: Sub-event Detection on Twitter Network, in: IFIP Advances in Information and Communication Technology, Springer New York LLC, New York, USA, vol. 519, 50–60, https://doi.org/10.1007/978-3-319-92007-8_5, 2018. a, b
CNS: Center for Nonproliferation Studies, Global Incidents and Trafficking Database (GITD), available at: https://www.nti.org/documents/2096/global_incidents_and_trafficking.xlsm, last access: 1 June 2020. a, b
CRED: Centre for Research on the Epidemiology of Disasters, The Emergency Events Database (EM-DAT), available at: https://www.emdat.be/, last access: 1 June 2020. a
Crooks, A., Croitoru, A., Stefanidis, A., and Radzikowski, J.: #Earthquake: Twitter as a Distributed Sensor System, T. GIS, 17, 124–147, https://doi.org/10.1111/j.1467-9671.2012.01359.x, 2013. a
ECDC: European Centre for Disease Prevention and Control, Publications & Data, available at: https://www.ecdc.europa.eu/en/publications-data, last access: 1 June 2020. a
EDO: European Drought Observatory, European Drought Observatory, available at: https://edo.jrc.ec.europa.eu, last access: 1 June 2020. a
EFAS: European Flood Awareness System, Data access, available at: https://www.efas.eu/en/data-access, last access: 1 June 2020. a
EFFIS: European Forest Fire Information System, Data & Services, available at: https://effis.jrc.ec.europa.eu/applications/data-and-services, last access: 1 June 2020. a
EFSA: European Food Safety Authority, Biological Hazards Reports, available at: https://www.efsa.europa.eu/en/biological-hazards-data/reports, last access: 6 January 2020. a
Eismann, K., Posegga, O., and Fischbach, K.: Collective behaviour, social media, and disasters: A systematic literature review, in: 24th European Conference on Information Systems, ECIS 2016, Istanbul, Turkey, 12–15 June 2016. a
eMARS: European Commission Joint Research Centre, MINERVA Portal – Accident Reports, available at: https://emars.jrc.ec.europa.eu/en/emars/accident/search, last access: 6 January 2020. a, b
Enenkel, M., Brown, M. E., Vogt, J. V., McCarty, J. L., Reid Bell, A., Guha-Sapir, D., Dorigo, W., Vasilaky, K., Svoboda, M., Bonifacio, R., Anderson, M., Funk, C., Osgood, D., Hain, C., and Vinck, P.: Why predict climate hazards if we need to understand impacts? Putting humans back into the drought equation, Climatic Change, 162, 1161–1176, https://doi.org/10.1007/s10584-020-02878-0, 2020. a
ERAIL: European Union Agency for Railways, European Railway Accident Information Links, available at: https://erail.era.europa.eu/investigations.aspx, last access: 1 June 2020. a, b
ESSL: European Severe Storms Laboratory, European Severe Storms Database, available at: https://www.eswd.eu, last access: 1 June 2020. a, b, c, d
EU-JRC: Joint Research Center of the European Union, Copernicus Emergency Management Service, available at: https://emergency.copernicus.eu/, last access: 1 June 2020. a
Fang, J., Hu, J., Shi, X., and Zhao, L.: Assessing disaster impacts and response using social media data in China: A case study of 2016 Wuhan rainstorm, Int. J. Disast. Risk Re., 34, 275–282, https://doi.org/10.1016/j.ijdrr.2018.11.027, 2019. a
Flores, J. A. M., Guzman, J., and Poblete, B.: A Lightweight and Real-Time Worldwide Earthquake Detection and Monitoring System Based on Citizen Sensors, in: Proceedings of the Fifth AAAI Conference on Human Computation and Crowdsourcing, HCOMP, 23–26 October 2017, AAAI Press, Quebec City, Quebec, Canada, 137–146, 2017. a
Fohringer, J., Dransch, D., Kreibich, H., and Schröter, K.: Social media as an information source for rapid flood inundation mapping, Nat. Hazards Earth Syst. Sci., 15, 2725–2738, https://doi.org/10.5194/nhess-15-2725-2015, 2015. a
GDACS: Global Disaster Alert and Coordination System, Assessing secondary effects of earthquakes with Twitter, available at: https://www.gdacs.org/About/social.aspx, last access: 1 June 2020. a, b, c
GFW: Global Forest Watch Fires, available at: https://fires.globalforestwatch.org, last access: 1 June 2020. a
Ghermandi, A. and Sinclair, M.: Passive crowdsourcing of social media in environmental research: A systematic map, Global Environ. Chang., 55, 36–47, https://doi.org/10.1016/j.gloenvcha.2019.02.003, 2019. a
GLOFAS: Global Flood Awareness System, JRC Science Hub, available at: http://www.globalfloods.eu, last access: 1 June 2020. a
GVP: Global Volcanism Program, Smithsonian Institution, National Institution of Natural History, available at: https://volcano.si.edu, last access: 1 June 2020. a
GWIS: Global Wildfire Information System, https://gwis.jrc.ec.europa.eu/applications/data-and-services, last access: 28 April 2021. a
Hao, H. and Wang, Y.: Leveraging multimodal social media data for rapid disaster damage assessment, Int. J. Disast. Risk Re., 51, 101760, https://doi.org/10.1016/j.ijdrr.2020.101760, 2020. a
Huang, Y. L., Starbird, K., Orand, M., Stanek, S. A., and Pedersen, H. T.: Connected Through Crisis: Emotional Proximity and the Spread of Misinformation Online, in: 18th ACM Conference on Computer Supported Cooperative Work and Social Computing, Vancouver, BC, Canada, March 2015, 969–980, https://doi.org/10.1145/2675133.2675202, 2015. a
IBTrACS: International Best Track Archive for Climate Stewardship, availale at: https://www.ncdc.noaa.gov/ibtrac, last access: 29 April 2020. a
ICAO: International Civil Aviation Organization, API Data Service, available at: https://www.icao.int/safety/iStars/Pages/API-Data-Service.aspx, last access: 29 April 2021. a, b
IFRC: International Federation of Red Cross and Red Crescent Societies, What is a disaster?, available at: http://www.ifrc.org/en/what-we-do/disaster-management/about-disasters/what-is-a-disaster (last access: 1 June 2020), 2017. a
IMO: International Maritime Organization, Global Integrated Shipping Information System (GISIS), available at: https://gisis.imo.org, last access: 1 June 2020. a, b
Imran, M., Castillo, C., Lucas, J., Meier, P., and Vieweg, S.: AIDR: artificial intelligence for disaster response, in: 23rd International World Wide Web Conference, WWW '14, Seoul, Republic of Korea, 7–11 April 2014, Companion Volume, 159–162, https://doi.org/10.1145/2567948.2577034, 2014. a
Imran, M., Castillo, C., Diaz, F., and Vieweg, S.: Processing Social Media Messages in Mass Emergency, in: WWW'18: Companion Proceedings of The Web Conference 2018, Lyon, France, 23–27 April 2018, 507–511, https://doi.org/10.1145/3184558.3186242, 2018. a
IRDR: Integrated Research on Disaster Risk, Peril Classification and Hazard Glossary (IRDR DATA Publication No. 1), Integrated Research on Disaster Risk, Beijing, available at: http://www.irdrinternational.org/wp-content/uploads/2014/04/IRDR_DATA-Project-Report-No.-1.pdf, last access: 1 June 2020. a
IRIS: Incorporated Research Institutions for Seismology, available at: http://service.iris.edu, last access: 1 June 2020. a
ITF: International Transport Forum, The International Road Traffic and Accident Database (IRTAD), available at: https://www.itf-oecd.org/irtad-road-safety-database, last access: 1 June 2020. a, b
Juang, C. S., Stanley, T. A., and Kirschbaum, D. B.: Using citizen science to expand the global map of landslides: Introducing the Cooperative Open Online Landslide Repository (COOLR), PloS one, 14, e0218657, https://doi.org/10.1371/journal.pone.0218657, 2019. a
Klein, B., Castanedo, F., Elejalde, I., López-de-Ipiña, D., and Nespral, A. P.: Emergency Event Detection in Twitter Streams Based on Natural Language Processing, in: Ubiquitous Computing and Ambient Intelligence: Context-Awareness and Context-Driven Interaction – 7th International Conference, UCAmI 2013, Carrillo, Costa Rica, 2–6 December 2013, https://doi.org/10.1007/978-3-319-03176-7_31, 2013. a
Kovarich, S., Ceriani, L., Ciacci, A., Baldin, R., Perez Miguel, M., Gibin, D., Carnesecchi, E., Roncaglioni, A., Mostrag, A., Tarkhov, A., Di Piazza, G., Pasinato, L., Sartori, L., Benfenati, E., Yang, C., Livaniou, A., and Dorne, J. L.: OpenFoodTox: EFSA's chemical hazards database, Zenodo, https://doi.org/10.5281/zenodo.3693783, 2020. a
La Red: Inventory system of the effects of disasters (DesInventar), available at: https://www.desinventar.org/ (last access: 1 June 2020), 2019. a
Lampos, V. and Cristianini, N.: Nowcasting Events from the Social Web with Statistical Learning, ACM Transactions on Intelligent Systems and Technology (TIST), 3, 1–22, https://doi.org/10.1145/2337542.2337557, 2012. a
Leetaru, K. and Schrodt, P. A.: GDELT: Global Data on Events, Location and Tone, 1979–2012, SA Annual Convention, 3 April 2013, 2, 1–49, International Studies Association, 2013. a
Lorini, V., Rando, J., Saez-Trumper, D., and Castillo, C.: Uneven Coverage of Natural Disasters in Wikipedia: the Case of Flood, in: 17th International Conference on Information Systems for Crisis Response and Management (ISCRAM), 688–703, Blacksburg, VA, USA, 2020. a
Lukoianova, T. and Rubin, V. L.: Veracity Roadmap: Is Big Data Objective, Truthful and Credible?, Advances in Classification Research Online, 24, 4, https://doi.org/10.7152/acro.v24i1.14671, 2013. a
McCreadie, R., Macdonald, C., and Ounis, I.: EAIMS: Emergency Analysis Identification and Management System, in: Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, 7 July 2016, 1101–1104, https://doi.org/10.1145/2911451.2911460, 2016. a, b, c
Meek, S., Jackson, M. J., and Leibovici, D. G.: A flexible framework for assessing the quality of crowdsourced data, in: Proceedings of the AGILE'2014 International Conference on Geographic Information Science, Castellón, 3–6 June 2014, 2014. a
Mehta, A. M., Bruns, A., and Newton, J.: Trust, but verify: social media models for disaster management, Disasters, 41, 549–565, https://doi.org/10.1111/disa.12218, 2017. a
Middleton, S. E., Middleton, L., and Modafferi, S.: Real-Time Crisis Mapping of Natural Disasters Using Social Media, IEEE Intelligent Systems, 29, 9–17, https://doi.org/10.1109/MIS.2013.126, 2014. a
Mondal, T., Pramanik, P., Bhattacharya, I., Boral, N., and Ghosh, S.: Analysis and Early Detection of Rumors in a Post Disaster Scenario, Inform. Syst. Front., 20, 961–979, 2018. a
MRCC: Midwestern Regional Climate Center, available at: https://mrcc.illinois.edu/gismaps/cntytorn.htm (last access: 1 June 2020), 2019. a
MunichRe: NatCatSERVICE – Natural catastrophe know-how for risk management and research, available at: https://natcatservice.munichre.com/ (last access: 1 June 2020), 2019. a
NASA: Global Landslide Catalogue, available at: https://data.nasa.gov/Earth-Science/Global-Landslide-Catalog/h9d8-neg4, last access: 1 June 2020. a, b
NCEI-EQ: National Geophysical Data Center/World Data Service (NGDC/WDS), Significant Earthquake Database, available at: https://www.ngdc.noaa.gov/hazel/view/hazards/earthquake/search, last access: 1 June 2020. a
NCEI-T: National Geophysical Data Center/World Data Service, Global Historical Tsunami Database, available at: https://www.ngdc.noaa.gov/hazel/view/hazards/tsunami/event-search, last access: 1 June 2020. a
NCEI-V: National Geophysical Data Center/World Data Service (NGDC/WDS), Global Significant Volcanic Eruptions Database, available at: https://www.ngdc.noaa.gov/hazel/view/hazards/volcano/event-search, last access: 1 June 2020. a, b
NCTR: NOAA Center for Tsunami Research, available at: https://nctr.pmel.noaa.gov/Dart/, last access: 1 June 2020. a
NDMC: National Drought Mitigation Center, Global Drought Information System GDIS, available at: https://www.drought.gov, last access: 1 June 2020. a
Nguyen, D. T., Ofli, F., Imran, M., and Mitra, P.: Damage Assessment from Social Media Imagery Data During Disasters, in: Proceedings of the 2017 IEEE/ACM international conference on advances in social networks analysis and mining, 31 July 2017, 569–576, https://doi.org/10.1145/3110025.3110109, 2017. a
NIFC: National Interagency Fire Center, available at: https://www.nifc.gov/fireInfo/fireInfo_statistics.html, last access: 1 June 2020. a
NOAA: National Oceanic and Atmospheric Administration, About the National Centers for Environmental Information, available at: https://www.ncei.noaa.gov/about (last access: 1 June 2020), 2019. a
Nugent, T., Petroni, F., Raman, N., Carstens, L., and Leidner, J. L.: A Comparison of Classification Models for Natural Disaster and Critical Event Detection from News, in: 2017 IEEE International Conference on Big Data (Big Data), 11 Dec 2017, 3750–3759, https://doi.org/10.1109/BigData.2017.8258374, 2017. a
Nurse, J. R., Rahman, S. S., Creese, S., Goldsmith, M., and Lamberts, K.: Information quality and trustworthiness: A topical state-of-the-art review, in: The International Conference on Computer Applications and Network Security (ICCANS), 2011, IEEE, 492–500, 2011. a
OCHA: United Nations Office for the Coordination of Humanitarian Affairs, What is ReliefWeb?, available at: https://reliefweb.int/about (last access: 1 June 2020), 2019. a
Ogie, R. I., Forehead, H., Clarke, R. J., and Perez, P.: Participation Patterns and Reliability of Human Sensing in Crowd-Sourced Disaster Management, Inform. Syst. Front., 20, 713–728, 2018. a
Ogie, R. I., Clarke, R. J., Forehead, H., and Perez, P.: Crowdsourced social media data for disaster management: Lessons from the PetaJakarta.org project, Comput. Environ. Urban, 73, 108–117, https://doi.org/10.1016/j.compenvurbsys.2018.09.002, 2019. a, b, c, d
Palen, L. and Liu, S. B.: Citizen communications in crisis: Anticipating a future of ICT-supported public participation, in: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI'07), San Jose, California, USA, 29 April 2007, 727–736, 2007. a, b
Palen, L., Anderson, K. M., Mark, G., Martin, J., Sicker, D., Palmer, M., and Grunwald, D.: A vision for technology-mediated support for public participation and assistance in mass emergencies and disasters, in: ACM-BCS Visions of Computer Science, Edinburgh, United Kingdom, 14–16 April 2010, 1–12, 2010. a
Plotnick, L. and Hiltz, S. R.: Barriers to Use of Social Media by Emergency Managers, J. Homel. Secur. Emerg., 13, 247–277, https://doi.org/10.1515/jhsem-2015-0068, 2016. a
Poblete, B., Guzman, J., Maldonado, J., and Tobar, F.: Robust Detection of Extreme Events Using Twitter: Worldwide Earthquake Monitoring, IEEE T. Multimedia, 20, 2551–2561, https://doi.org/10.1109/TMM.2018.2855107, 2018. a
Rashid, M. T., Zhang, D. Y., and Wang, D.: SocialDrone: An Integrated Social Media and Drone Sensing System for Reliable Disaster Response, in: IEEE INFOCOM 2020 – IEEE Conference on Computer Communications, 218–227, https://doi.org/10.1109/INFOCOM41043.2020.9155522, 2020. a
Reuter, C. and Kaufhold, M. A.: Fifteen years of social media in emergencies: A retrospective review and future directions for crisis Informatics, J. Conting. Crisis Man., 26, 41–57, https://doi.org/10.1111/1468-5973.12196, 2017. a, b
Reuter, C., Ludwig, T., Kaufhold, M., and Spielhofer, T.: Emergency services' attitudes towards social media: A quantitative and qualitative survey across Europe, Int. J. Hum.-Comput. St., 95, 96–111, https://doi.org/10.1016/j.ijhcs.2016.03.005, 2016. a
Reuter, C., Hughes, A. L., and Kaufhold, M. A.: Social Media in Crisis Management: An Evaluation and Analysis of Crisis Informatics Research, Int. J. Hum.-Comput. Int., 34, 280–294, https://doi.org/10.1080/10447318.2018.1427832, 2018. a
Robinson, B., Power, R., and Cameron, M.: A Sensitive Twitter Earthquake Detector, in: Proceedings of the 22nd international conference on world wide web, 13 May 2013, 999–1002, https://doi.org/10.1145/2487788.2488101, 2013. a
RSOE: Hungarian National Association of Radio Distress-Signalling and Infocommunications, Emergency and Disaster Information Service (EDIS), available at: http://hisz.rsoe.hu/, last access: 1 June 2020. a
Rudra, K., Banerjee, S., Ganguly, N., Goyal, P., Imran, M., and Mitra, P.: Summarizing Situational Tweets in Crisis Scenario, in: Proceedings of the 27th ACM conference on hypertext and social media, 10 July 2016, 137–147, https://doi.org/10.1145/2914586.2914600, 2016. a
Rudra, K., Ganguly, N., Goyal, P., and Ghosh, S.: Extracting and Summarizing Situational Information from the Twitter Social Media during Disasters, ACM Transactions on the Web (TWEB), 17 July 2018, 12, 1–35, https://doi.org/10.1145/3178541, 2018. a, b
Sakaki, T., Okazaki, M., and Matsuo, Y.: Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors, in: Proceedings of the 19th international conference on World wide web, 26 April 2010, 851–860, https://doi.org/10.1145/1772690.1772777, 2010. a
Sakaki, T., Okazaki, M., and Matsuo, Y.: Tweet analysis for real-time event detection and earthquake reporting system development, IEEE Transactions on Knowledge and Data Engineering, 14 February 2012, 25, 919–931, https://doi.org/10.1109/TKDE.2012.29, 2013. a, b
Senaratne, H., Mobasheri, A., Ali, A. L., Capineri, C., and Haklay, M.: A review of volunteered geographic information quality assessment methods, Int. J. Geogr. Inf. Sci., 31, 139–167, https://doi.org/10.1080/13658816.2016.1189556, 2017. a
Shapira, O., Ronen, H., Adler, M., Amsterdamer, Y., Bar-Ilan, J., and Dagan, I.: Interactive Abstractive Summarization for Event News Tweets, in: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, September 2017, 109–114, https://doi.org/10.18653/v1/d17-2019, 2017. a, b
SPC: NOAA Storm Prediction Center, Severe Weather Database, available at: https://www.spc.noaa.gov/wcm/#data (last access: 1 June 2020), 2019. a
Starbird, K. and Palen, L.: “Voluntweeters”: self-organizing by digital volunteers in times of crisis, edited by: Tan, D. S., Amershi, S., Begole, B., Kellogg, W. A., and Tungare, M., in: Proceedings of the SIGCHI conference on human factors in computing systems, 7 May 2011, 1071–1080, https://doi.org/10.1145/1978942.1979102, 2011. a
Stieglitz, S., Mirbabaie, M., Fromm, J., and Melzer, S.: The Adoption of Social Media Analytics for Crisis Management – Challenges and Opportunities, in: 26th European Conference on Information Systems: Beyond Digitization – Facets of Socio-Technical Change, ECIS 2018, Portsmouth, UK, 23-28 June 2018, available at: https://aisel.aisnet.org/ecis2018_rp/4 (last access: 29 April 2021), 2018. a
SWDI: NOAA Severe Weather Data Inventory, available at: https://www.ncdc.noaa.gov/stormevents/, last access: 1 June 2020. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, aa, ab, ac
SwissRe: Sigma Explorer, available at: https://www.sigma-explorer.com/, last access: 1 June 2020. a
Tapia, A. H. and Moore, K.: Good Enough is Good Enough: Overcoming Disaster Response Organizations' Slow Social Media Data Adoption, Comput. Supp. Coop. W. J., 23, 483–512, https://doi.org/10.1007/s10606-014-9206-1, 2014. a
Thomas, C., McCreadie, R., and Ounis, I.: Event Tracker: A Text Analytics Platform for Use During Disasters, in: Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval, 18 July 2019, 1341–1344, https://doi.org/10.1145/3331184.3331406, 2019. a, b, c
Ubyrisk Consultants: The NATural DISasters (NATDIS) Database, available at: https://www.catnat.net/natdis-database, last access: 1 June 2020. a
USGS: U.S. Geological Survey, Did You Feel It?, available at: https://earthquake.usgs.gov/data/dyfi/, last access: 1 June 2020a. a
USGS: Earthquakes Hazards Program, https://earthquake.usgs.gov, last access: 1 June 2020b. a
Verma, R., Crane, D., and Gnawali, O.: Phishing During and After Disaster: Hurricane Harvey, in: 2018 Resilience Week (RWS), 20 August 2018, 88–94, IEEE, https://doi.org/10.1109/RWEEK.2018.8473509, 2018. a
Vieweg, S., Hughes, A. L., Starbird, K., and Palen, L.: Microblogging during two natural hazards events: What twitter may contribute to situational awareness, in: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, Georgia, USA, 10 Apr 2010, 1079–1088, https://doi.org/10.1145/1753326.1753486, 2010. a
Wald, D. J., Earle, P. S., and Shanley, L. A.: Transforming Earthquake Detection and Science Through Citizen Seismology, Woodrow Wilson International Center for Scholars, Washington, DC, available at: https://www.wilsoncenter.org/publication/transforming-earthquake-detection-and-science-through-citizen-seismology (last access: 29 April 2021), 2013. a
Wang, W., Wang, Y., Zhang, X., Li, Y., Jia, X., and Dang, S.: WeChat, a Chinese social media, may early detect the SARS-CoV-2 outbreak in 2019, medRxiv, 2020. a
Wang, Z., Lam, N. S. N., Obradovich, N., and Ye, X.: Are vulnerable communities digitally left behind in social responses to natural disasters? An evidence from Hurricane Sandy with Twitter data, Appl. Geogr., 108, 1–8, https://doi.org/10.1016/j.apgeog.2019.05.001, 2019. a
Wiggins, A., Newman, G., Stevenson, R. D., and Crowston, K.: Mechanisms for Data Quality and Validation in Citizen Science, in: IEEE Seventh International Conference on e-Science Workshops, 5 December 2011, 14–19, IEEE, https://doi.org/10.1109/eScienceW.2011.27, 2011. a
Wikimedians for Disaster Response: WikiProject Humanitarian Wikidata/Recent disasters, available at: https://www.wikidata.org/wiki/Wikidata:WikiProject_Humanitarian_Wikidata/Recent_disasters (last access: 29 April 2021), 2017. a
Wikinews: Disasters and Accidents, available at: https://en.wikinews.org/wiki/Category:Disasters_and_accidents, last access: 1 June 2020. a
Wikipedia: Category:Natural disasters by year, available at: https://en.wikipedia.org/wiki/Category:Natural_disasters_by_year, last access: 1 June 2020. a
Xiao, Y., Huang, Q., and Wu, K.: Understanding social media data for disaster management, Nat. Hazards, 79, 1663–1679, 2015. a
Zhang, X. and Ghorbani, A. A.: An Overview of Online Fake News: Characterization, Detection, and Discussion, Inform. Process. Manag., 57, 102025, https://doi.org/10.1016/j.ipm.2019.03.004, 2020. a
The International Federation of Red Cross (IFRC, 2017) provides a more detailed definition: “A disaster is a sudden, calamitous event that seriously disrupts the functioning of a community or society and causes human, material, and economic or environmental losses that exceed the community's or society's ability to cope using its resources. Though often caused by nature, disasters can have human origins.”
A study by Wang et al. (2020) suggests that Covid-19 could have been detected via social media weeks before the acknowledgment by official institutions.
A similar analysis is presented by Meek et al. (2014) for other kinds of crowdsourcing projects.
Crooks et al. (2013) refer to social media data as “ambient geographic information”, in contrast to “volunteered geographic information”.