the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 16 Dec 2020
| 16 Dec 2020
INSPIRE standards as a framework for artificial intelligence applications: a landslide example
Gioachino Roberti
Jacob McGregor
Sharon Lam
David Bigelow
Blake Boyko
Chris Ahern
Victoria Wang
Bryan Barnhart
Clinton Smyth
David Poole
Stephen Richard
This study presents a landslide susceptibility map using an artificial intelligence (AI) approach based on standards set by the INSPIRE (Infrastructure for Spatial Information in the European Community) framework. INSPIRE is a European Union spatial data infrastructure (SDI) initiative to standardize spatial data across borders to ensure interoperability for management of cross-border infrastructure and environmental issues. However, despite the theoretical effectiveness of the SDI, few real-world applications make use of INSPIRE standards. In this study, we show how INSPIRE standards enhance the interoperability of geospatial data and enable deeper knowledge development for their interpretation and explainability in AI applications. We designed an ontology of landslides, embedded with INSPIRE vocabularies, and then aligned geology, stream network, and land cover datasets covering the Veneto region of Italy to the standards. INSPIRE was formally extended to include an extensive landslide type code list, a landslide size code list, and the concept of landslide susceptibility to describe map application inputs and outputs. Using the terms in the ontology, we defined conceptual scientific models of areas likely to generate different types of landslides as well as map polygons representing the land surface. Both landslide models and map polygons were encoded as semantic networks and, by qualitative probabilistic comparison between the two, a similarity score was assigned. The score was then used as a proxy for landslide susceptibility and displayed in a web map application. The use of INSPIRE-standardized vocabularies in ontologies that express scientific models promotes the adoption of the standards across the European Union and globally. Further, this application facilitates the explanation of the generated results. We conclude that public and private organizations, within and outside the European Union, can enhance the value of their data by making them INSPIRE-compliant for use in AI applications.
- Article
(3865 KB) - Full-text XML
- BibTeX
- EndNote





1.1 INSPIRE
Data accessibility and interoperability are key for multinational cross-border applications and fundamental for economic development (European Parliament and the Council, 2007). Different countries have different languages and data standards, hindering infrastructure planning, disaster risk reduction initiatives, and effective legislative implementation. To overcome these challenges, the European Union initiated INSPIRE (Infrastructure for Spatial Information in the European Community; Directive 2007/2/EC; European Parliament and the Council, 2007). INSPIRE is structured in 34 spatial data themes organized in three annexes. The themes span administrative (e.g. street addresses) and environmental domains (e.g. geology), and all EU countries are mandated by law to have implemented the data framework by 2021 (European Parliament and the Council, 2014). Each theme defines a data model and has adopted a set of vocabularies to populate interoperable datasets based on that data model. EU countries are aligning and serving INSPIRE data at a slow pace, and currently relatively few INSPIRE-compliant datasets are available across Europe (Cho and Crompvoets, 2019). Conferences and competitions are currently being organized to promote its implementation and to show the potential impact of real-world applications built on INSPIRE datasets (European Commission, 2019). This project was first presented at one of these conferences, the Inspire Helsinki 2019 data challenge under the “Let's make the most out of INSPIRE!” topic, where the project won first prize.
1.2 Artificial intelligence
Artificial intelligence (AI) studies “the synthesis and analysis of computational agents that act intelligently” (Poole and Mackworth, 2017). Part of acting intelligently is building models of the world that make predictions. Probabilistic predictions are the most useful ones for subsequent decision making and can be learned from data (Pearl, 1988). All models are based on human knowledge and data (observations of the world). For some problem domains, society has collected an overwhelming number of data, and still, useful human knowledge of the domain can be very vague. Machine learning has made great progress recently for such cases, particularly with deep learning (Goodfellow et al., 2016). However, for domains with relatively limited data but that are still very large in volume, human knowledge (which may be represented in computers through the use of ontologies) can complement the data to make useful predictions (Pearl, 1988). Many environmental problems do not have enough data (e.g. lack of extensive landslide databases) to be solved by deep learning but do have enough data to generate useful products when combined with human expertise (expressed in ontologies; Poole and Mackworth, 2017). The term artificial intelligence is commonly used to indicate only the machine learning part of the field, especially in the landslide literature (e.g. Dieu and Gjermundsen, 2020). In this paper we use the term “AI” in its broader connotation, which also includes the ontological method used in this paper. See below for the description of the method and definition of ontologies.
1.3 The need for standards, ontologies, and taxonomies
Consistent, well-defined vocabularies and data standards are essential in computer science applications, especially in AI. For data to have meaning and to combine multiple datasets, vocabularies must be consistent and clearly defined. Deep learning techniques require meanings for the inputs and the outputs, but the internal representations do not have well-defined meanings, making the models very opaque (Marcus, 2018). Other representations, such as logical and probabilistic representations, support internal reasoning using symbols with well-defined meanings, which lend themselves to use in explanations (Marcus and Davis, 2019).
Ontologies are “a specification of the meanings of the symbols in an information system” (Poole and Mackworth, 2017). In particular, an ontology defines the vocabulary for individuals and relationships within a knowledge domain. Individuals may be concrete entities (e.g. a rock) or abstract concepts (e.g. numbers); relationships are properties that describe how individuals are connected. Typical examples of relationships include “is-a-kind-of”, “is-part-of”, “is-superclass-of”, “has-some-property”; the ontology also defines axioms controlling the use of the vocabulary for logical and thematic consistency (Poole and Mackworth, 2017). Given these axioms, the vocabulary can be unambiguously interpreted according to the rules of symbolic logic, and implicit relationships between entities or instances of those entities can be inferred.
Vocabularies can be Aristotelian taxonomies, which are logically consistent and multi-hierarchical. Aristotelian taxonomies are constructed by defining concepts from their relation to a more general parent concept (genus) and using differentiating properties (differentia) to distinguish concepts within the same genus (Aristotle, 350). For example, “slides in soil” and “slides in rock” share the same parent concept “slides”, and they are differentiated by the property dealing with the material type, “soil” and “rock”, which make them uniquely identifiable. Taxonomies based on Aristotelian definitions support multi-hierarchical knowledge networks and can be used by computers to make logical inferences (Poole et al., 2009; Smith, 2003). The term “multi-hierarchical” implies that there is more than one way to move through a taxonomy to arrive at a particular node or term. For example, the landslide taxonomy can be arranged based on different properties. If the landslide types are firstly arranged based on the type of movement and then based on the type of material, one path within the taxonomy would be landslide > slides > slides in rock and slides in soil. Alternatively, if the landslide types are arranged first based on the material type and then on the movement type, the path of the taxonomy would be landslide > landslides in rock > slides in rock and flows in rock. Both paths are valid, but they reach the same concept in different ways. The natural hazard classification code list extension for landslides presented in this paper was prepared using the open-access Aristotelian Class Editor (ACE) software (Minerva Intelligence, 2019d). Knowledge stored in a domain-specific ontology (e.g. geohazards) can be accessed by computers, allowing for data investigation through various AI techniques, including probabilistic matching between semantic networks, the technique used in this study.
Significant progress has been made in the development of taxonomies for geoscience information interchange by the International Union of Geological Sciences (IUGS ) Commission for the Management and Application of Geoscience Information (CGI) Geoscience Terminology Working Group, which produced the GeoSciML standard along with the Open Geospatial Consortium (OGC; CGI, 2003). However, ontology applications in earth sciences are scarce. Notable exceptions are in economic geology (Smyth et al., 2007), geohazards (Jackson Jr et al., 2008), and disaster risk reduction domains (Phengsuwan et al., 2019; Sermet and Demir, 2019). The INSPIRE framework, through its standardized vocabularies (code lists), provides a necessary foundation upon which AI applications with explainable output can be constructed. INSPIRE application examples in landslide studies include the LAND-deFeND Italian landslide database structure (Napolitano et al., 2018) and a deep learning algorithm to map landslide susceptibility (Hajimoradlou et al., 2020). In the implementation of deep learning by Hajimoradlou et al. (2020), training features were labelled with INSPIRE-compliant semantics to enable reproducibility of the experiment by other researchers.
In this study, we present an AI-based landslide susceptibility application using a natural hazard ontology. We do so by building from the ontology created by Jackson Jr et al. (2008) and by embedding INSPIRE code lists wherever possible as well as aligning input and output data to the INSPIRE data standards.
1.4 Landslide susceptibility and hazard
Landslide susceptibility is defined as the relative spatial probability of occurrence for a landslide based on the intrinsic properties of a site (SafeLand, 2011). The concept of susceptibility differs from hazard in that the temporal probability of occurrence, the triggering factors, and the magnitude of the event are not considered in the definition of a susceptibility map (SafeLand, 2011; Van Den Eeckhaut and Hervás, 2012). To produce landslide susceptibility maps, three approaches are usually applied: statistical, physical, and expert-based (SafeLand, 2011). Statistical methods rely on the analysis of landslide databases and their relation to landscape properties (see review by Reichenbach et al., 2018), physical methods calculate the limit equilibrium between failure-resisting and failure-driving forces in slopes (e.g. Baum et al., 2008), and expert-based methods rely on expert opinion and the assumption that influencing factors are known and are specified in the models (Dai et al., 2002). The AI approach used in this study is an example of the expert-based approach as the models follow rules that represent the reasoning process of a landslide expert, providing semi-quantitative susceptibility maps.
Figure 1 outlines the methodological workflow followed in this study to produce explainable landslide susceptibility assessments in the Veneto region of Italy. We extended INSPIRE (Sect. 2.1); we constructed an ontology (Sect. 2.2); and we defined expert models (Sect. 2.2.1) and instances, represented by mapping polygons (Sect. 2.2.2). We then compared the similarity of models and instances to produce a matching score, which is used as a susceptibility indicator (Sect. 2.2.3). Finally, the results are delivered in an interactive web map (Sect. 2.2.4).
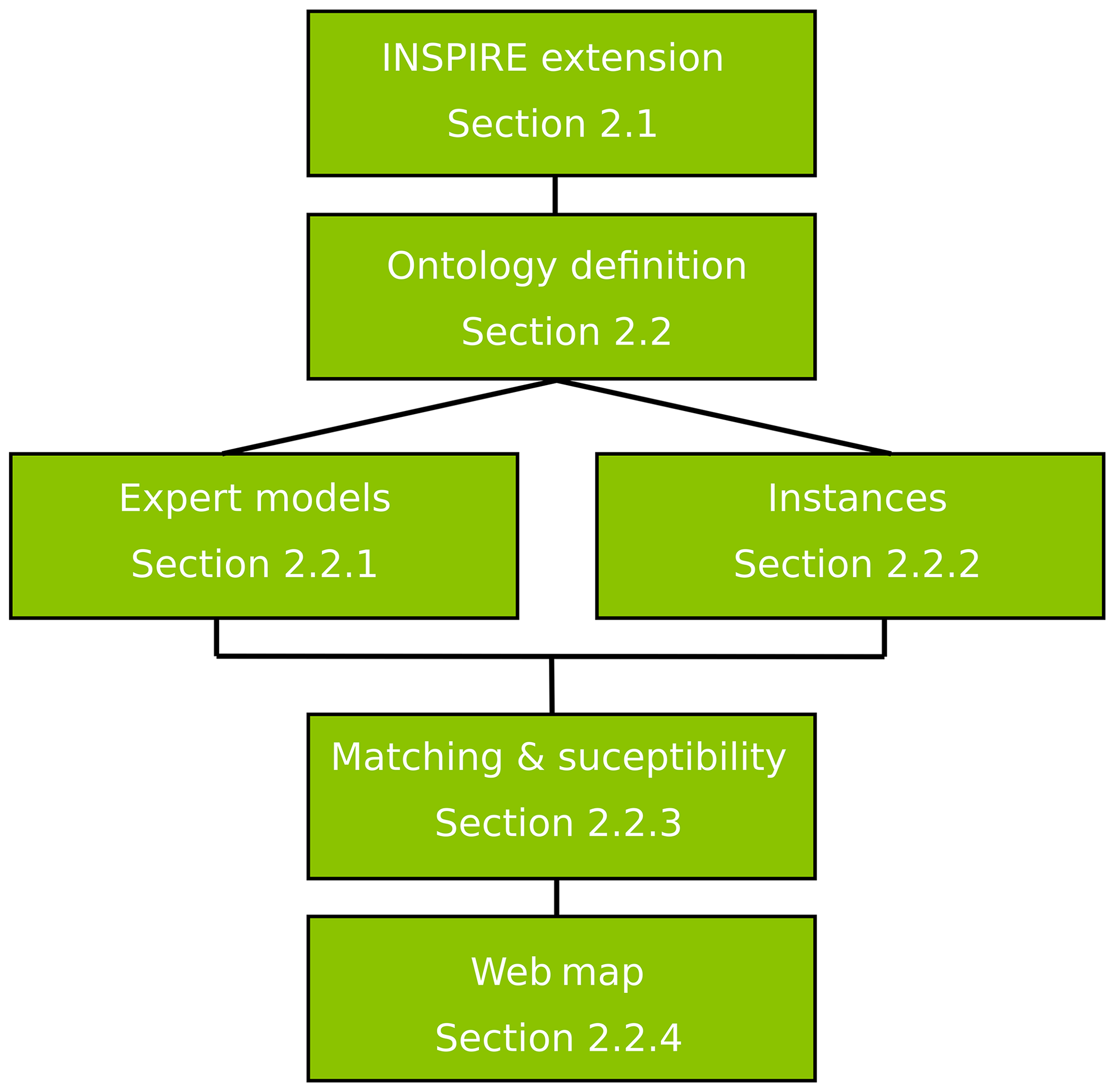
Figure 1The workflow followed in this study and corresponding method sections. We extended INSPIRE, defined an ontology, expert models and mapping instances. We compared models and instances to deliver a susceptibility map which is available online.
2.1 INSPIRE extension
Technical guideline documents outline the data structure for each theme within the INSPIRE directive, its encoding rules, its metadata standards, and some of its use cases. Data structures are formally represented using Unified Modeling Language (UML), modelling thematic entities as feature types, defining properties for each feature type, and characterizing relationships between feature types. Where applicable, standardized vocabularies are adopted for property value ranges. INSPIRE themes can be understood as an ontology (See Sect. 2.2 below) by defining various entities and the relationships between them.
INSPIRE data models are implemented as Geography Markup Language (GML) application schemas (https://inspire.ec.europa.eu/XML-Schemas/Data-Specifications/2892, last access: 26 October 2020) and serialized using Extensible Markup Language (XML). This enables data distribution provided as Open Geospatial Consortium (OGC)-compliant web services. Geospatial features are located using vector-based spatial data. Feature properties have value types (e.g. geometry for vector datasets); properties whose value ranges are controlled vocabularies have values implemented as code lists. Code lists incorporate vocabularies developed outside of INSPIRE (e.g. IUGS CGI rock type taxonomy). Some code lists within INSPIRE are not extensible, some are extensible with narrower values, and some allow additional values at any level. Code list values, definitions, and hierarchical structures are stored in the INSPIRE registry (https://inspire.ec.europa.eu/codelist, last access: 26 October 2020), making them accessible to and reusable by anyone. INSPIRE schemas can also be extended to include additional concepts and/or feature types. For this project, we worked with four INSPIRE themes: Geology, Land Cover, Hydrography, and Natural Risk Zones. The Natural Risk Zone application schema was not fully adequate for this application as it lacked the “landslide susceptibility” concept and “landslide type” code lists (Tomas et al., 2015). We addressed this issue by formally extending the Natural Risk Zone schema and the natural hazard code list.
2.2 Ontologically grounded probabilistic matching
The method used to produce INSPIRE-based landslide susceptibility maps, uses qualitative probabilistic reasoning that incorporates expert knowledge, making qualitative predictions based on comparisons between models and instances (e.g. Sharma et al., 2010; Smyth et al., 2007; Poole and Smyth, 2005; Smyth and Poole, 2004). A model is a set of rules defined a priori by an expert, based on the scientific literature, making use of the entities and properties defined in the ontology. These models aim to represent expert conceptualized descriptions of a given phenomenon or entity (e.g. landslide susceptibility). The properties used in a model description are concepts stored in the ontology, along with frequency terms (e.g. soil slide – has slope – moderately steep – always). Frequency terms used in this study are “always”, “usually”, “sometimes”, “rarely”, and “never”. These terms were chosen as they express experience-based judgements that geoscience practitioners may use in field assessments. The term “never” allows the system to explicitly deal with negation (e.g. soil slide – has surficial material – bedrock – never). The properties and the frequency terms are encoded in semantic triple format (W3C Working Group, 2014), and the resulting model is a semantic network. Semantic networks are a graph representation of knowledge, where nodes are concepts, and edges are the semantic relation between concepts (Shapiro, 1992); see Fig. 2 for example. Real-world areas on the ground (map units – more generally referred to as “instances”) are also described by semantic networks using the same properties stored in the ontology, but triples are accompanied by Boolean qualifiers to represent presence or absence of a specific property (e.g. polygon – has slope – steep – present). Comparisons, referred to as matches, between instances and models are possible because models and instances all use the same structured terminology, as controlled by the ontology.
Similarity scores are awarded based on the type of match between instance and model properties, the semantic distance in the taxonomy of compared property values, and the model property frequency term (Fig. 2). Match types include “exact”, “a kind of (AKO) exact”, and “possible”. An exact match indicates that the property value term used in the model is present in the instance (in Fig. 2a), in which case a full score is awarded for this component of the compared semantic networks. An AKO exact match indicates that the property value term found in the instance is a kind of the property value term found in the model (in Fig. 2b), in which case a full score is also awarded. A “possible” match occurs when the property value term in the instance is broader than the property value term in the model, based on the defined taxonomies, in which case the score is divided by the semantic distance between the two terms. For example, “forest” is a more specific type of “forest and semi-natural areas” (in Fig. 2c) and results in the score being divided by 2. The score is lower because the instance is only possibly the kind of value that the model is looking for.
In this study, an exact match or an AKO exact match of a property with frequency “always” scores 10 000, “usually” scores 9000, “sometimes” scores 1000, “rarely” scores “100”, and “never” scores −10 000; unmatched attributes are awarded −10 points. These scores are an arbitrary representation of the degree of surprise that uses order-of-magnitude numbers to distinguish qualitative measures. For an extensive review of the probabilistic comparison method, see Smyth and Poole (2004), Poole and Smyth (2005), Smyth et al. (2007), and Sharma et al. (2010). This approach has been applied in economic geology to generate mineral deposit exploration targets (Smyth et al., 2007) and in geohazard mapping to produce landslide susceptibility maps (Jackson Jr et al., 2008).
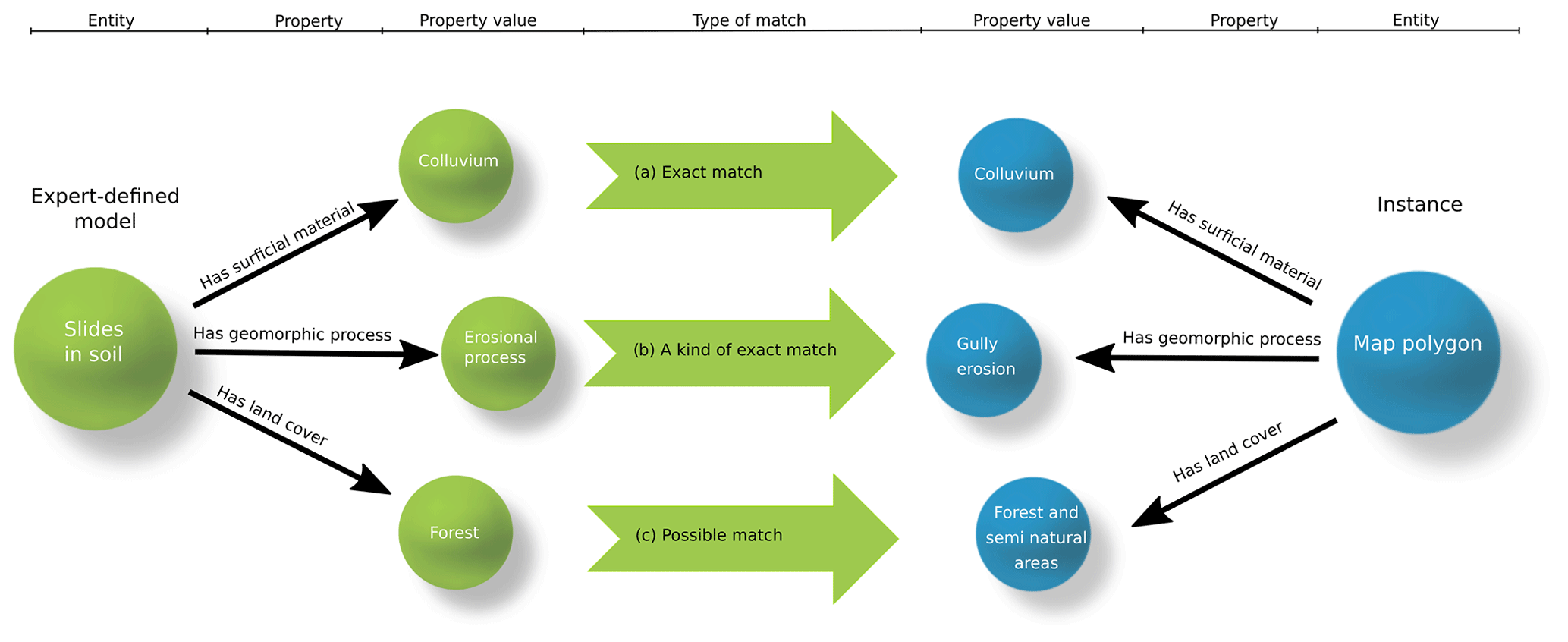
Figure 2Graphical representation of the matching process between expert-defined models and map polygon instances. Panel (a) is an example of an exact match between the property value “colluvium”; (b) is an example of a kind of (AKO) exact match because “gully erosion” is a more specific kind of “erosional process”. The model is looking for an “erosional process” and found a “gully erosion”; (c) is an example of a possible exact match because “forest and semi-natural areas” is a broader concept of “forest”. The model is looking for “forest”, but we do not know whether the instance is a “forest”. We only know that the instance is “forest and semi-natural areas”. The vocabulary and the hierarchy are controlled by the ontology. Note that frequency terms for model properties are not shown in this figure.
2.2.1 Landslide models
This paper presents an AI expert-based landslide susceptibility map for three different landslide types: debris flows, slides in soil, and slides in rock for the Veneto region of Italy. These three landslide types are conceptualizations of landslide models defined using knowledge recorded in the scientific literature. These landslide models are intended to be proof of concept of models that can be used in the semantic approach proposed in this paper. In particular, some of the properties used in the models are drafted from literature analysis of logging-related landslides in British Columbia, Canada (Jackson Jr, 2019). Here we briefly summarize the models; detailed explanations of each property–value–frequency combination are provided in Appendix C.
The “Debris Flow” model describes the channels that may generate a debris flow. Debris flows are flow-like landslides generated when saturated sediments move down a steep channel. They can be originated when a slide in soil intersects a flowing body of water or when saturated bed sediments are mobilized and begin flowing downstream. Debris flows are usually triggered by intense and persistent rainfall (Hungr et al., 2014). To visualize the Debris Flow model, see the table in Appendix C or navigate to https://italy.minervageo.com/debris-flow-model/ (last access: 26 October 2020).
The “Slides in Rock” model describes slopes that may generate slides in rock. Slides in rock form when steep rock slopes and cliffs fail under the influence of gravity and are commonly triggered by intense rainfall or earthquakes. Slides in rock are usually very fast, and the failure can occur along planar, curved, and/or multiple surfaces. This model represents the collective class of landslides that have as material “rock” and as movement type “slide”, including rotational, planar, compound, wedge, and irregular slides in rock (Hungr et al., 2014). Given the regional scale of this study, we do not have the data resolution to determine the possible failure plane geometry. For example, we cannot identify slopes more susceptible to planar rock slides than to rotational rock slides. To visualize the Slides in Rock model, see the table in Appendix C or navigate to https://italy.minervageo.com/the-roberti-slides-in-rock-model/ (last access: 26 October 2020).
The “Slides in Soil” model describes slopes that may generate slides in soil. Slides in soil are downslope movements of soil under the influence of gravity, commonly triggered by intense rainfall or earthquakes. They can be slow or fast, and the failure can occur along one or many planar or curved surfaces (Hungr et al., 2014). With slides in soil, we refer to the collective class representing all landslides that have as material “soil” and as movement type “slide”, including rotational, planar, and compound clay, silt, sand, gravel, and debris slides. Given the regional scale of this study, we do not have the data resolution to determine the possible failure plane geometry and the specific kind of soil that is involved in the failure. To visualize the Slides in Soil model, see the table in Appendix C or navigate to https://italy.minervageo.com/slides-in-soil/ (last access: 26 October 2020).
In the presence of higher-resolution information such as rock bedding orientation or shear geometry and stratigraphy in soil masses, susceptibility to specific kinds of rock slides (e.g. planar vs rotational) or different kinds of slides in soil (e.g. clay compound slide vs. clay planar slide) may be mapped.
2.2.2 Map polygon instances
The definition of the mapping unit is a critical step in any landslide susceptibility mapping application, and there are many different approaches to subdividing the area of interest to identify areas susceptible to slides in soil or rock (see review by Guzzetti et al., 1999). For this study, we used slope units, which are a geomorphic representation of single slopes bounded by drainage and divide lines (Guzzetti et al., 1999), as mapping units. We used the r.slopeunits software to automate the slope unit delineation (Alvioli et al., 2016, 2020). We used stream line vector shape files provided by the Veneto Regional Government, buffered by a distance of 5 m as mapping units to map debris flow susceptibility. In total, the region of Veneto was subdivided into 93 262 polygons, of which 9302 are stream buffer polygons, and 83 960 are slope unit polygons.
We used a spatial overlay analysis to aggregate data describing the physical properties of the mapping units. The analysis aggregated the properties from all features that intersect the mapping units. For each property in an input layer, an aggregation type is specified as either (a) list, whereby all of the intersecting properties are concatenated into the mapping unit (e.g. multiple rock types), or (b) Boolean evaluation, which checks whether or not the mapping unit was intersected by a specific input feature (e.g. a fault).
The properties describing each mapping unit polygon were converted into semantic networks, one network for each polygon. This conversion allows for semantic reasoning to compare and rank, based on similarity, the mapping units (hereon instances) against the expert-defined landslide models to evaluate landslide susceptibility.
2.2.3 Matching, susceptibility, and run-out
The similarity score between a given model and instance is used as a proxy of landslide susceptibility. A high similarity score between an instance and a landslide susceptibility model signals a high susceptibility to that type of landslide. We deliver the similarity score between models and instances as susceptibility on the output maps.
After the susceptibility assessment, a first-order estimate of hazard is provided by calculating the likely extent of landslide run-out for the most susceptible (99.9th percentile score, i.e. top 1 in 1000) instances for each model. Various physical methods have been developed to calculate potential landslide run-out given the physical properties of the material and the topography (see review by McDougall, 2016). To compute the potential run-out extents, we applied the r.avaflow code (Mergili et al., 2017), which is an open-source software package implementing the two-phase debris flow model developed by Pudasaini (2012). Physical model parameters for “Slides in Rock” are inferred from the back-calculations of the recent Mt. Joffre landslide, in British Columbia, Canada (Friele et al., 2020); “Slides in Soil” and “Debris Flow” parameters use the default r.avaflow parameters for those landslide types (Table 1).
Various landslide size classes were simulated for each map instance, ranging from class 4 to class 6 (Jakob, 2005). Classes 4 to 6 were chosen to provide a preliminary hazard assessment, where a class 4 event may have an approximate return interval of hundreds of years, and class 6 events are very unlikely and extreme events with return intervals on the order of thousands of years (Jakob, 2005).
Table 1R.avaflow parameters for slides in soil, slides in rock, and debris flow run-out calculations.

2.2.4 Web map
This study’s landslide susceptibility maps and hypothetical landslide run-outs for slides in soil, slides in rock, and debris flows are delivered as an interactive web map based on OpenLayers (MetaCarta, 2005) and React (Facebook, 2013). Input layers are hosted through a GeoServer (The Open Planning Project, 2001) with a PostGIS (Refraction Researtch, 2001) back-end database. INSPIRE-aligned layers are hosted on Hale Connect (WeTransform, 2014), a platform used to host and serve INSPIRE-compliant data.
3.1 INSPIRE Natural Risk Zone extension
To develop an INSPIRE-compliant AI application to map landslide susceptibility, we needed to extend the INSPIRE Natural Risk Zone theme to include the concept of landslide susceptibility and the specific code list dealing with landslide terminology. The INSPIRE extensions developed in this project are documented and stored in the Minerva Re3gistry (Minerva Intelligence, 2019a), a version 1.3.1 of the INSPIRE registry based on the Re3gistry software (ISA, 2016). The registry service is packaged within a collection of Docker (Hykes, 2013) containers and hosted on a local server.
The Natural Risk Zone core (NZ-core) schema extension, which includes the Natural Risk Zone Susceptibility feature type, was based on SafeLand recommendations (SafeLand, 2011). The Natural Hazard classification code list was extended (Minerva Intelligence, 2019b) to include a classification of various landslide types using the updated Varnes landslide classification (Hungr et al., 2014), which is a landslide classification widely adopted within the scientific community, and a new code list of landslide size classes (Minerva Intelligence, 2019c) based on Jakob (2005). The landslide size code list contains 10 landslide size classes based on landslide volume and descriptions of approximate damage potential.
3.1.1 Code list extension
The Natural Hazard classification code list extension for landslides considers material type and failure movement, splitting the tree first on type of movement and then on type of material following Hungr et al. (2014) (Fig. 3). Other properties, such as water content, depth of failure, rate of movement, loading state, channelized state, and failure plane geometry (see Appendix B), are used to describe the individual landslide types as the unique combination of these properties allows for unambiguous classification in an Aristotelian taxonomy. We used these properties because, even if not shown in the final taxonomic tree, they are explicitly applied in the wordy description of landslide types by Hungr et al. (2014).
The formal extension registration process via the INSPIRE registry software does not enable the representation of such multi-hierarchical classifications. Because of this we had to work with a single tree hierarchy and consequently chose to first divide the classes based on type of failure followed by a division based on the type of movement (Fig. 3).
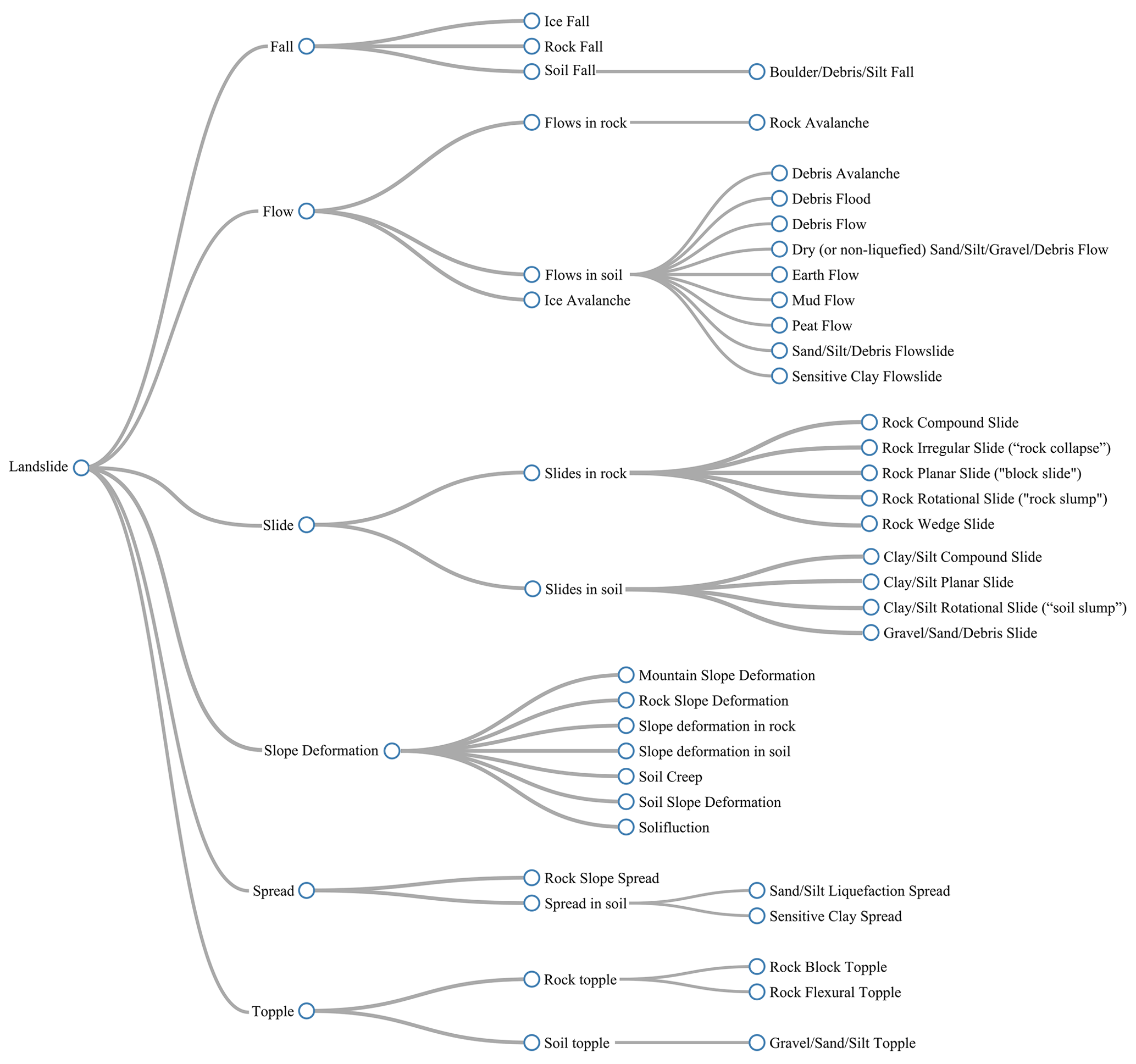
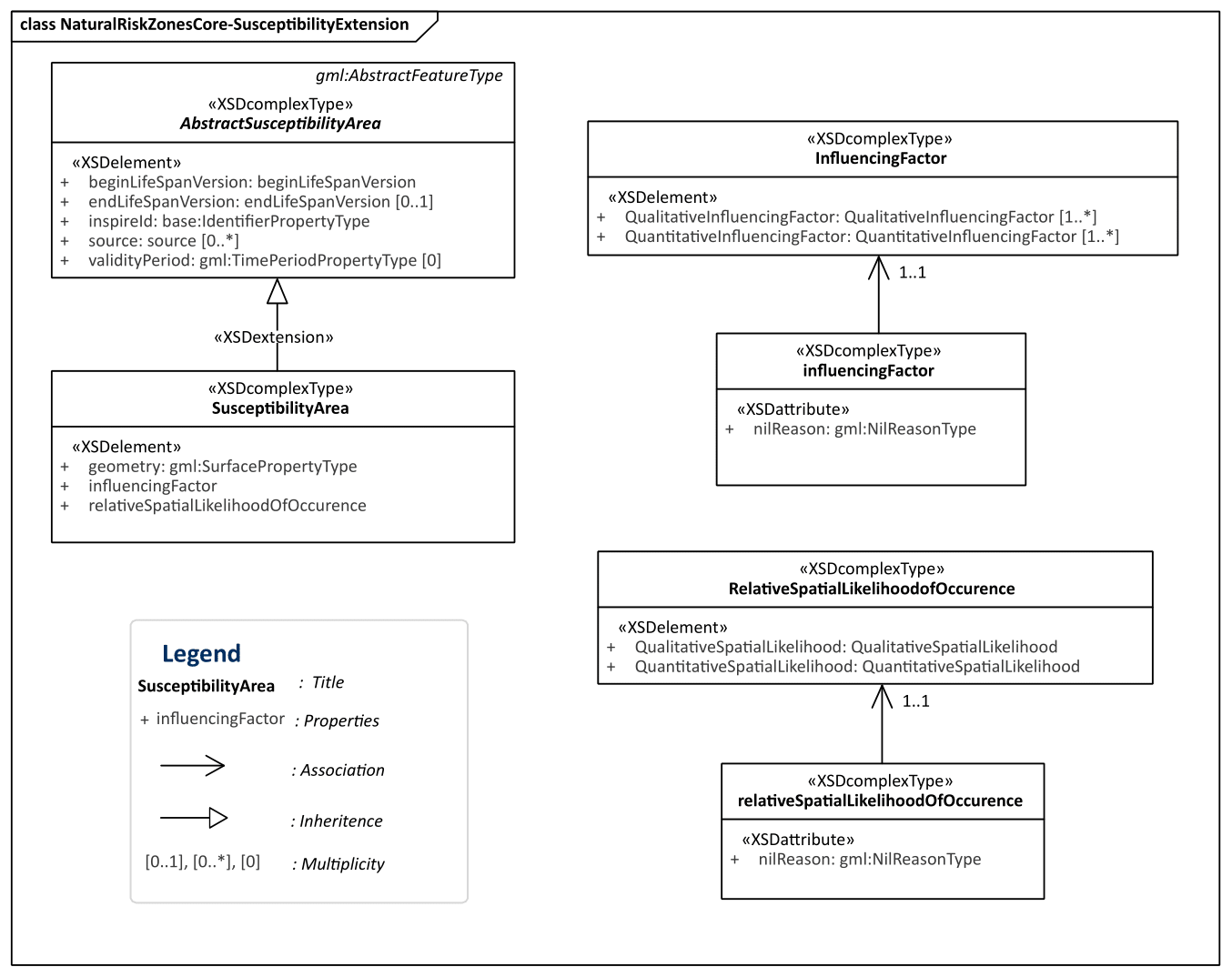
Figure 4UML diagram showing Natural Risk Zone Susceptibility schema extension of the Natural Risk Zone core schema.
3.1.2 Schema extension: susceptibility
The INSPIRE Natural Risk Zone schema includes hazard and risk feature types, but the concept of susceptibility as a feature type is missing. To overcome this problem, we extended the INSPIRE Natural Risk Zone core XML schema, adding a Natural Risk Zone Susceptibility schema (Minerva Intelligence, 2019e). The Natural Risk Zone Susceptibility schema includes abstract susceptibility area and susceptibility area feature types (Fig. 4). The susceptibility area feature type is modelled following the structure of the hazard area and risk zone feature types in the INSPIRE Natural Risk Zone core schema. Susceptibility area has three elements: Geometry, Influencing Factor, and Relative Spatial Likelihood of Occurrence (Fig. 4). Geometry, as with all INSPIRE vector datasets, is the geometric representation of the extent of the feature on the earth's surface as a spatial feature. Influencing Factors are defined as the intrinsic, preparatory variables which make an area susceptible to a hazard (SafeLand, 2011). Influencing Factors are unbounded in multiplicity (i.e. can be as many as needed) and can be defined qualitatively or quantitatively. Qualitative Influencing Factors are expressed as a string, while quantitative Influencing Factors are expressed as GML:MeasureType (Fig. 4). Whether defined quantitatively or qualitatively, the Influencing Factor can also define a DataSetType attribute, such as slope or air quality. Influencing Factors are used in the calculation of Relative Spatial Likelihood of Occurrence, which is an element that can be quantitatively or qualitatively defined (Fig. 4). The Relative Spatial Likelihood of Occurrence refers to values that represent the spatial probability of occurrence of a specific hazard type given the influencing factors present in the area (SafeLand, 2011). The Influencing Factor element allows end users of susceptibility area datasets to understand which known conditions of the specific area led to the resultant susceptibility.
3.2 Landslide susceptibility mapping in Veneto
3.2.1 Input data
For this study, we used open-access datasets from the Veneto Region Geoportal and other sources (Table 2 and 3). Aligning all input datasets was beyond the scope of this project. We did, however, want to show the value of INSPIRE-aligned data and therefore aligned stream network, CORINE Land Cover, bedrock geology, and the Italian Landslide Inventory (IFFI; Table 2) to INSPIRE using Hale Studio (WeTransform, 2008). Figure 5 shows how different tools in Hale Studio are used to align properties from the source dataset to the target dataset. For example, the field “eta” – “age” in Italian – of the original Veneto dataset was directly mapped to four different INSPIRE fields: the olderNamedAge.href and title and the youngerNamedAge.href and title. Note that olderNamedAge.href and youngerNamedAge.href are hyperlinks to the code list value ID, and the title is the actual code list term from the GeochronologicEraValue code list. This alignment is done with many classification methods, including Groovy scripts, formatted strings, and assign-alignment tools. For further explanation on term alignments, refer to the documentation of Hale Studio (WeTransform, 2008). Datasets used that were not compliant with INSPIRE include lakes, watersheds, permafrost, fire, slope angle, faults, soil, roads, and railways (Table 3).
(Hungr et al., 2014) (Gruber, 2012)
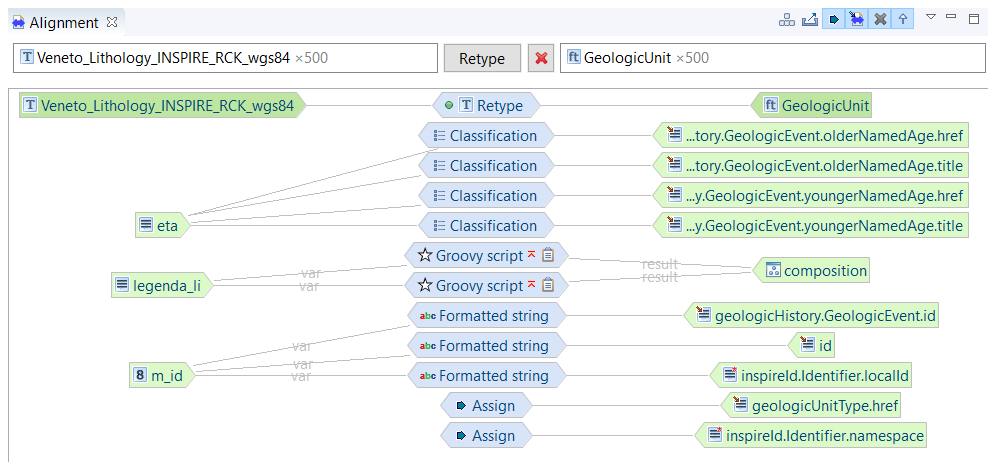
Figure 5Visualization of INSPIRE data alignment within Hale Studio. The left side shows the source Veneto Lithology shape file, the right side shows the target GeologicUnit feature type within the INSPIRE Geology schema, and the centre shows the classification method used to align the data.
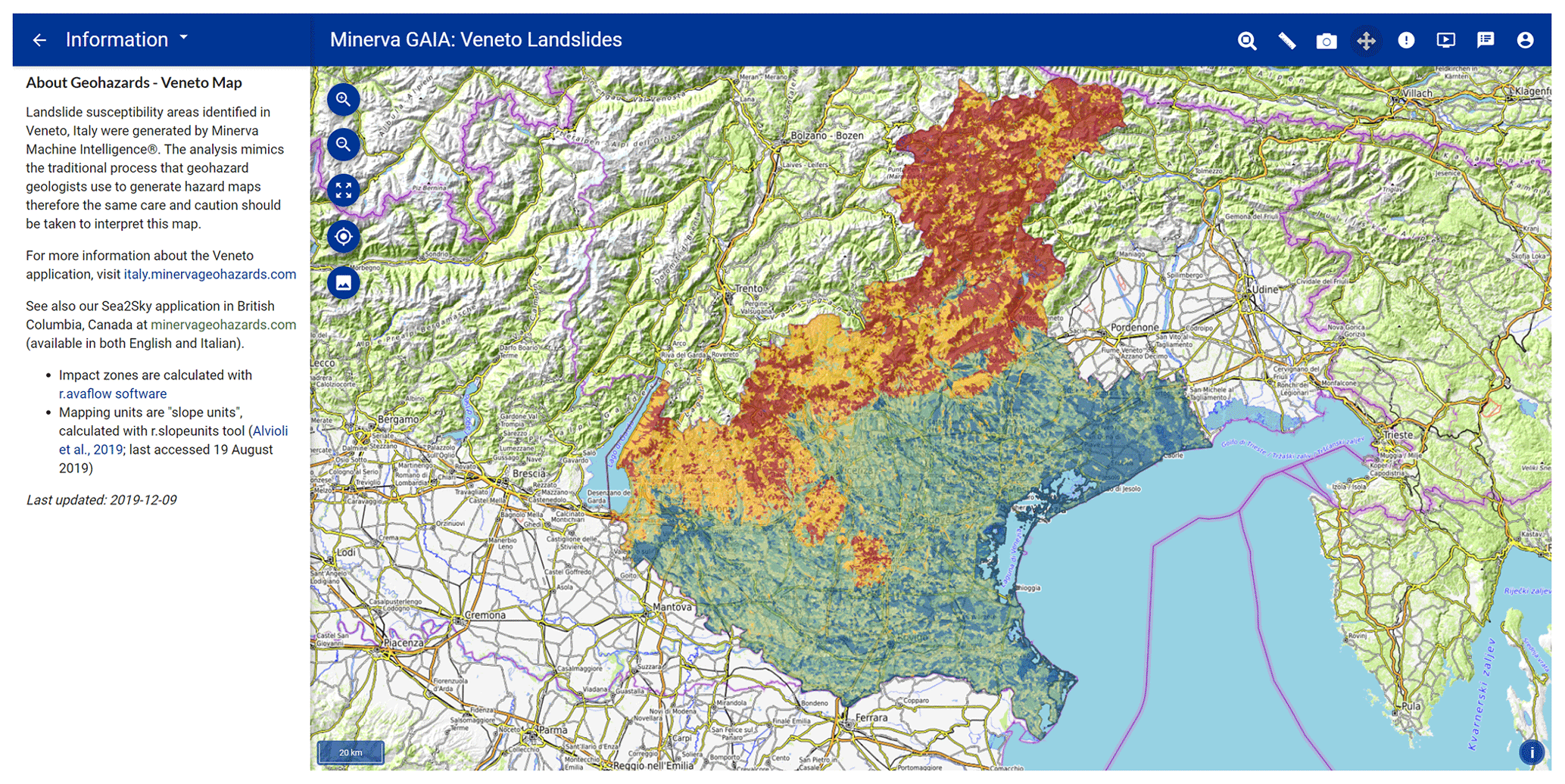
Figure 6Web map interface showing susceptibility to slides in soil in Veneto, Italy. Colours range from blue (0–20 score percentile) to dark green (20–40 score percentile), light green (40–60 score percentile), yellow (60–80 score percentile), red (80–99.9 score percentile), and purple (99.9–100 score percentile). Base map credit: © OpenTopoMap (CC-BY-SA).
3.2.2 Web map
The 83 960 slope units and 9302 stream buffer instances (Fig. 6) were encoded with the available data, then transformed from vector files into semantic network format. Then, each polygon was matched against the expert-based Slides in Soil, Slides in Rock, and Debris Flow models and colour-coded according to matching-score percentile to portray landslide susceptibility (Fig. 6). The left-side panel of the web map shows the landslide model layers, the reference layers, and different base maps (Fig. 7). By clicking on a polygon (instance), a pop-up window opens (Fig. 7): this window contains the name and hyperlink to the INSPIRE registry code list definition of the landslide type investigated, the attributes that are present in the mapping unit (e.g. bedrock lithology, erosional process, etc.), the instance percentile rank and total match score, the hyperlink to the comparison of the instance against other landslide models (e.g. the Slides in Rock model), and (only for the 99.9th percentile score, top 1 in 1000) buttons to turn on the display of landslide run-out for different landslide classes as well as the hyperlink to the match report.
The match report is a detailed table showing the results from the model instance semantic matching, ensuring the explainability of the results. Each line corresponds to a property–value–frequency term (e.g. has slope – moderately steep – always) comparison between the model and the instance, how they match (with a hyperlink to textual explanation on how the score was awarded), the numerical score value (see Table 4 for example), a textual explanation on why that attribute was chosen, and the original data value (Table 5). An “advice” button opening textual advice expressing which of the instance's unmatched attributes may change the score is available. This advice is a sort of data advice: it invites the user to check in the field or in some other databases if, for example, a fault is present in that specific instance.
Table 4Simplified match report table showing instance 117309 compared to the Slides in Soil model. The match report is accessible online by clicking https://spot.italy.minervageohazards.com/match_results?if_id=34434&t_id=117309 (last access: 26 October 2020).

Table 5Simplified match report table showing the comment for the model property “has erosional process” matching the instance property “gully erosion”. The full match report is accessible online at https://spot.italy.minervageohazards.com/match_results?if_id=34434&t_id=117309 (last access: 26 October 2020).


Figure 7Screen capture of the web map showing layer list, information pop-up window, map legend, and landslide run-out. Base map credit: © OpenTopoMap (CC-BY-SA).
4.1 INSPIRE as a framework for explainable AI
Across society, the use of numerous complex and non-standardized earth science taxonomies results in interoperability limitations, which hinder the widespread implementation of explainable AI solutions to natural-hazard-related problems. This is evident in the landslide domain, where data layers for landslide susceptibility analysis, ranging from landslide databases (Van Den Eeckhaut et al., 2013) to geomorphology maps, vary across regions and countries. Consequently, despite the wealth of scientific literature on landslides in general and landslide susceptibility in particular (Reichenbach et al., 2018), broad-scale operational landslide hazard management systems are scarce (Guzzetti et al., 2020), resulting in significant human and economic losses (Froude and Petley, 2018).
INSPIRE partially addresses this problem by providing standardized data structures for data hosting and standard terminology to use within those structures. This study illustrates that, once INSPIRE-compliant, European data can be subjected to analytical methods that can be applied for practical application to multiple other equivalent INSPIRE-compliant datasets. For example, the same landslide-focused ontology that uses terminology and knowledge models based on INSPIRE code lists used in this project has been applied in south-western British Columbia, Canada (Minerva Intelligence, 2019f).
By maintaining carefully curated standards, INSPIRE can play a critical role in AI applications that seek to be “explainable” (Gilpin et al., 2019). Its code lists can be mapped into ontology properties, enabling machines to make inferences of semantic and hierarchic relations based on data. The explainability in the application presented in this study is provided in the form of a comprehensive match report, which can be opened via an information pop-up for each instance. The match report provides the user with complete access to the logic that drives the AI reasoning engine, allowing interrogation of the results displayed on the map. By embedding explanations in a user-friendly interface, ontologically based AI can improve the understanding of complex geospatial problems by decision makers, insurance companies, and the general public.
Public and private organizations, within and outside the European Union, can significantly enhance the value of the data they collect and publish by using INSPIRE-compliant standards not only in natural hazard mapping but also in other domains. A comparative study of regional spatial data infrastructure (SDI) in the context of INSPIRE implementation (Craglia and Campagna, 2010) showed that inefficient data access and use at the European level results in annual economic losses in the EUR 100–200 million range. The same study shows that the regional SDI of Lombardy, Italy, allowed savings of EUR 3 million per year to companies working in environmental impact assessments (EIAs) and strategic environmental assessments (SEAs). Savings in the same order of magnitude can be expected by adopting INSPIRE standards in the domain of geological-hazard assessment.
4.2 INSPIRE extension and limitations
INSPIRE-compliant datasets are still rare across European countries in general and in Italy in particular (Cetl et al., 2017; Mijić and Bartha, 2018; Cho and Crompvoets, 2019). Consequently, we were unable to identify a jurisdiction in Europe with INSPIRE-compliant datasets for all the inputs necessary for this study. Therefore, instead of using already-compliant data, a region optimal for demonstrating the interrelationship between INSPIRE and explainable AI was chosen, and some of the data for that region was made INSPIRE-compliant. In doing so, the study provides both a case study of dealing with non-INSPIRE-compliant data and an illustration of the rewards achievable by making a coherent set of data INSPIRE-compliant.
The code lists and application schemas in the INSPIRE Natural Risk Zone theme lacked the level of detail necessary for this application. This is understandable as, given the broad scope of the directive, schemas lack the necessary granularity for specific applications. INSPIRE is intended to be used as an overarching umbrella under which domain-specific applications can find their place by extending it where necessary. The Natural Risk Zone theme (Tomas et al., 2015) and the extension presented in this work are an example of using this extension facility. Within the Natural Risk Zone theme, the Natural Hazard category value code list includes geological and hydrological hazards, including “flood” and “landslide”, but the different subclasses of floods and landslides are not specified. For this kind of landslide susceptibility assessment, the clear definition of landslide types, landslide size classes, and susceptibility was fundamental. For example, a debris flow, which moves rapidly (metres per second), and an earth flow, which may move slowly (metres per year), present entirely different hazards; they can both destroy property, but it is unlikely for an earth flow to result in fatalities, while the opposite can be said of debris flows (Hungr et al., 2014). The definition of landslide sizes is also important: a size class 1 debris flow has a smaller impact area than a size class 6 event, but, by having a higher frequency, it may result in greater losses (Jakob, 2005).
From a data structure perspective, INSPIRE code lists cannot currently host multi-hierarchical taxonomies. This limits the nature of reasoning that can be brought to bear on them. We understand the technical difficulties in handling multi-hierarchical taxonomies but hope that future versions of the registry software will be able to handle these complex knowledge representations.
The INSPIRE Natural Risk Zone theme also lacks the definition of susceptibility as a concept and feature type. The term susceptibility is not implemented as a feature type because for most hazards (e.g. floods and earthquakes), the concept is embedded within the concept of hazard likelihood (Tomas et al., 2015). This does not apply in the landslide domain, where susceptibility and hazard are distinct concepts (e.g. Van Den Eeckhaut and Hervás, 2012). In this study, we implemented the susceptibility feature type. Although we applied this feature type in the landslide domain, it will be useful for other natural hazard applications, when the spatial likelihood of hazard occurrence must be expressed separately from the general concept of hazard likelihood.
The extensibility of INSPIRE allows for domain-specific applications, like the approach presented in this paper, to fit within the INSPIRE framework. However, problems may also arise from the fact that INSPIRE is extensible. Extensibility allows greater precision in terminology and schema for a specific application, but this allows different public and private institutions to implement separate and eventually incompatible extensions. For example, another landslide classification may be implemented by another institution: this implementation may not be interoperable with the one presented in this study but will have the same INSPIRE compliance, leading to two conflicting standards. Much work remains at the level of thematic clusters to implement as many standardized vocabularies and schemas as possible. Our extension is open and free, and we hope that other entities will adopt it for other landslide applications.
4.3 Ontological probabilistic matching for landslide susceptibility mapping
The semantic AI system applied in this study aimed to replicate the reasoning with uncertainties typical of geological assessments, applying the terminology that geological and geotechnical professionals use in their daily practice (Smyth et al., 2007). Since they are based on expert-defined models, the landslide susceptibility maps produced in this study are comparable to qualitative heuristic assessments (SafeLand, 2011). The choice of using a qualitative method for landslide susceptibility assessment is in contrast with recent recommendations for the application of quantitative methods (Corominas et al., 2014). However, in current professional geological assessments and geomorphological mapping applications, expert judgement is still widely applied (e.g. Association of Professional Engineers and Geoscientists of British Columbia, 2010; Guzzetti et al., 2012), and quantitative (statistically and physically based) methods rely on data that are not always available or are of unknown quality. For example, landslide databases necessary for statistically based susceptibility mapping are often incomplete, inaccurate, and geographically limited (Guzzetti et al., 2012). Further, the geotechnical parameters necessary for running physical models are usually approximated to carry out regional-scale studies (e.g. Mergili et al., 2014).
The semantic AI system applied in this study can be used in cases of data scarcity and, if coupled with numerical methods, can improve the explainability of predictions. For example, by embedding the ontology concepts related to statistical parameters (e.g. receiving operating curves, confidence intervals) or physical parameters (e.g. friction angles, viscosity), it will be possible for the numerical outputs of quantitative methods to be explained in natural language, helping to reduce the gap between scientists and decision makers (Newman et al., 2017).
The main goal of this paper is not to present the semantic matching approach but to show an example of how to modify INSPIRE to make it possible to use for landslide-specific applications. By suggesting these landslide-specific schema and code list extensions, we lay the foundation for INSPIRE-compliant landslide susceptibility studies. Other organizations can build on top of these extensions, and future landslide susceptibility applications can be compared as they formally refer to the same data structure and semantics. Note that we neither force any specific data and modelling variable selection nor modelling approach for a landslide susceptibility, hazard, or risk calculation. Such an effort is beyond the scope of this paper and, to some extent, has already been addressed by the SafeLand project (e.g. SafeLand, 2011); rather, we provide the data structure and semantics to store and share whichever method has been chosen by the modeller. For example, data selection for calculation of landslide susceptibility is encompassed in the schema structure under “Influencing Factor”, which is “unbounded in multiplicity and can be defined qualitatively or quantitatively”, leaving a broad range of possibilities to the modeller. Regarding the data quality, it is discussed in the Natural Risk Zone schema, and it refers to ISO standards (INSPIRE Thematic Working Group Natural Risk Zones, 2013). However, we recognize that specific code lists (semantics) dealing with data quality and model uncertainty are missing. We hope that the INSPIRE thematic group will address this point.
This study presents an AI method, based on semantic network comparison, to produce landslide susceptibility maps using an ontology and standardized taxonomies within the framework provided by the INSPIRE Natural Risk Zone theme. This method does not need an accurate landslide inventory to make predictions as it uses qualitative probabilistic reasoning that incorporates expert knowledge. We produced susceptibility maps for debris flow, slides in soil, and slides in rock for the province of Veneto, Italy. To produce the maps for specific landslide types, we extended the Natural Risk Zone theme to encompass both the concept of susceptibility and the different types of landslides. In particular, we registered a landslide classification extension of the Natural Hazard category code list, a landslide size class code list, and susceptibility area and abstract susceptibility area feature type schema extensions. After defining the extension, we aligned key input layers (geology, streams, and land cover) to INSPIRE and, by using an ontologically grounded probabilistic matching algorithm, we produced the landslide susceptibility layers. The processing outputs were mapped to the Natural Risk Zone Susceptibility schema extension. Then, potential impact zones of landslides for multiple landslide size classes were physically modelled for a subset of the instances with the highest susceptibility scores. Finally, the results were presented in a user-friendly interface, embedding plain-language explanations on how the score was assigned and advising on how to improve the matching.
We have demonstrated the value of INSPIRE compliance by showing how it enhances information and knowledge interoperability and allows for explainability in AI applications by standardized interrogation of their inputs and outputs. Ontologies provide the formal structure for INSPIRE code lists to run algorithms similar to that applied here. The maps can explain the scientific results that they portray, and consequently improve the understanding of complex geospatial problems not only by domain experts but also by decision makers and other non-specialized interested parties.
This study also illustrates that, in their current state of development, the INSPIRE standards are not sufficiently expressive to support complex landslide susceptibility mapping. We provided an example of how INSPIRE’s extension capabilities may be implemented to add the required expressivity. Through its Re3gistry register, this extension framework ensures that the expressivity extensions are documented and available to all interested parties for reuse. In doing so, it sets the context for the ongoing refinement of standards by the INSPIRE thematic committees.
| Term | Description |
| Code list | A dataset specifying terms for populating INSPIRE properties that require controlled vocabulary. |
| CLC | CORINE Land Cover, a classification system for land cover based on vegetation and land use. |
| Feature type | A data type representing a thematic entity in a domain of interest, typically with some geospatial location |
| specified by vector-based spatial data. | |
| IFFI | Italian Landslide Inventory. |
| Instance | A data item that represents an individual, specific real-world entity; for this application an instance is |
| a spatial feature, either a slope unit polygon or a stream buffer polygon. | |
| Model | A conceptualization of the entities, properties, and relationships in some domain of interest, |
| in this case landslides. Three landslide models were used in this project: | |
| Debris Flow, Slides in Soil, and Slides in Rock. | |
| Ontology | A formal representation of a conceptualization of the entities, properties, relationships, and rules |
| describing the relation between the entities in some domain of interest. | |
| Semantic network | A graph network of arcs and nodes that represent concepts in a domain of interest. |
| Schema | A representation of a data model describing the structure of a data theme. |
| Slope unit | A map unit polygon that is derived from the digital elevation model, |
| defined by hydrologic drainage and divide lines. | |
| Taxonomy | Hierarchical classification scheme based on shared characteristics between entities. |
| Triple | A semantic triple is a subject–object–predicate expression that asserts a fact, |
| and it is the basic unit of a semantic network. |
Table B1Properties used for the definition of the Aristotelian taxonomy of landslides.
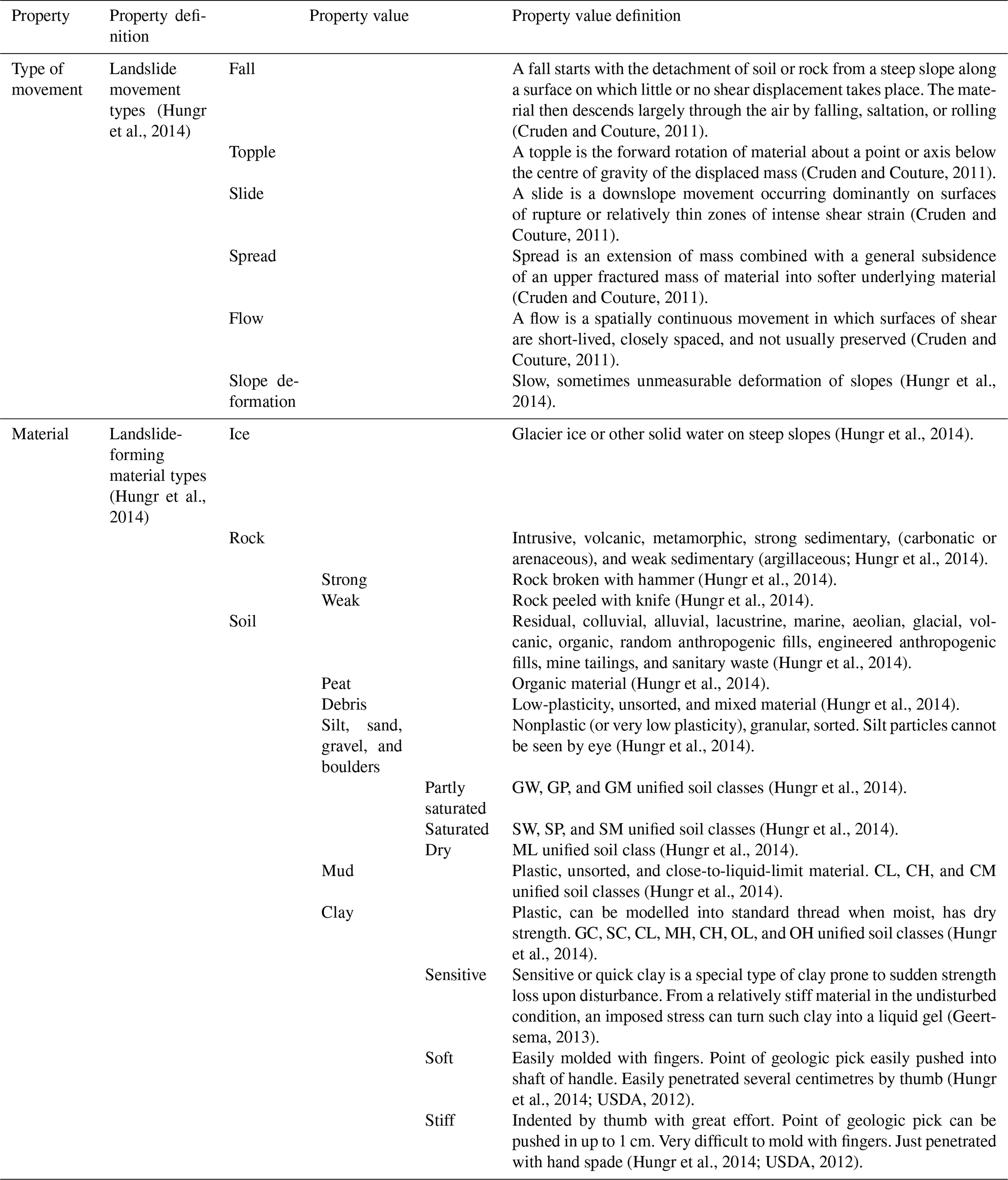
Table C1Debris flow model (https://italy.minervageo.com/debris-flow-model/, last access: 26 October 2020) .
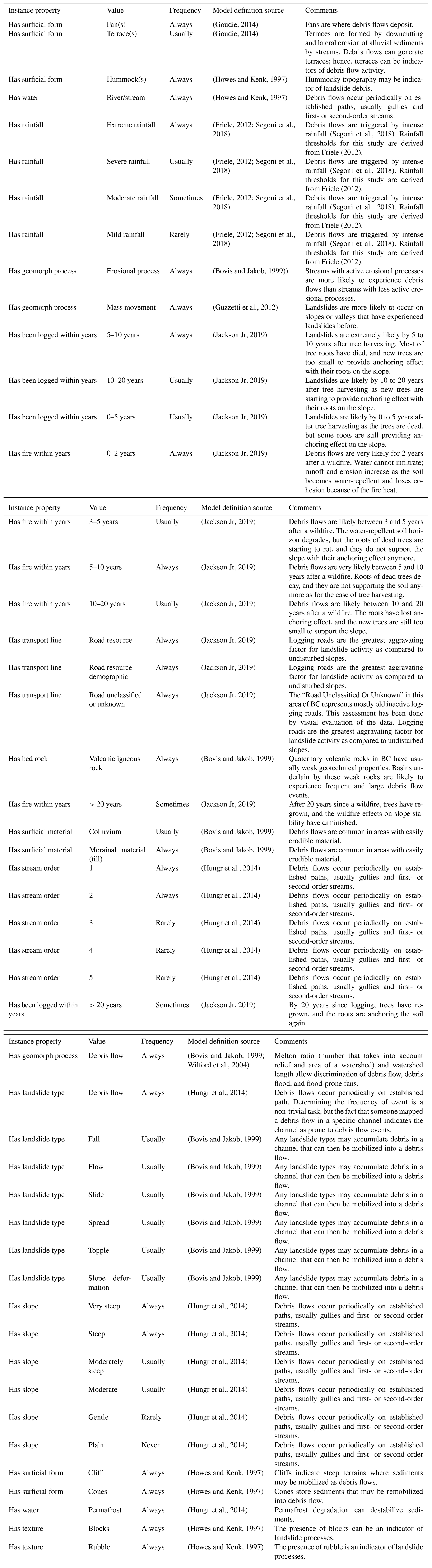
Table C2Slides in rock model https://italy.minervageo.com/the-roberti-slides-in-rock-model/ (last access: 26 October 2020).
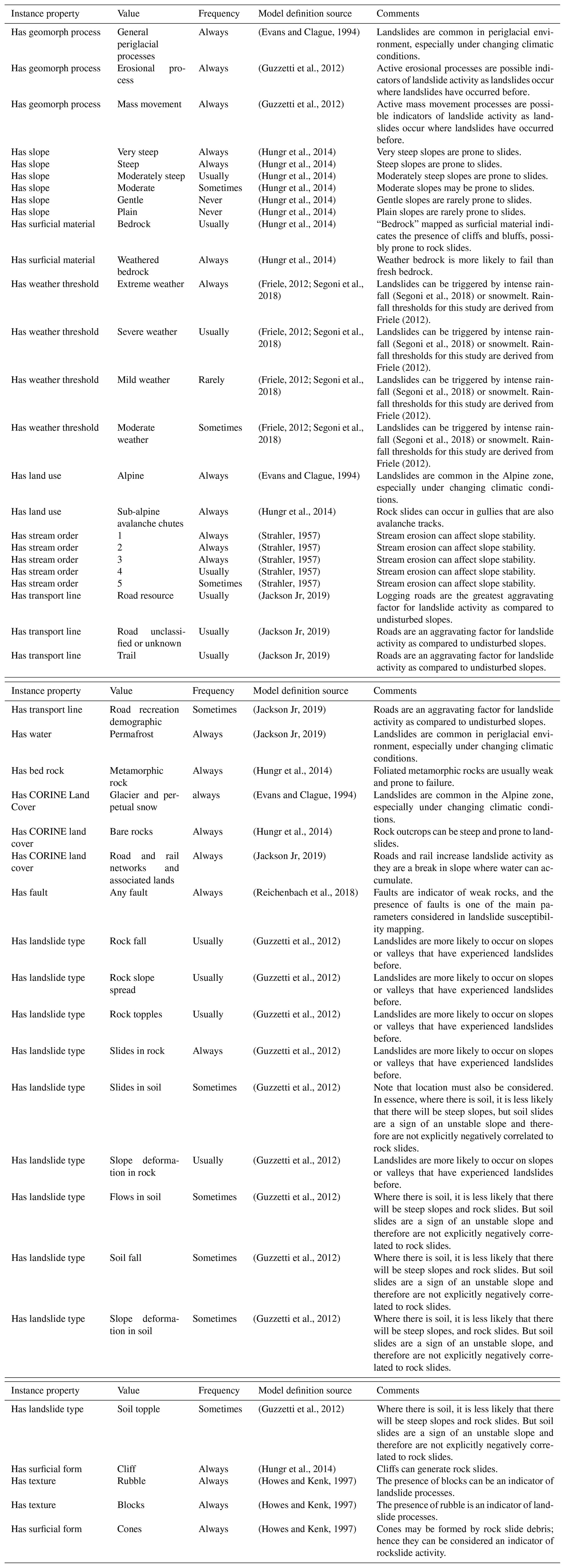
Table C3Slides in soil model https://italy.minervageo.com/slides-in-soil/ (last access: 26 October 2020).
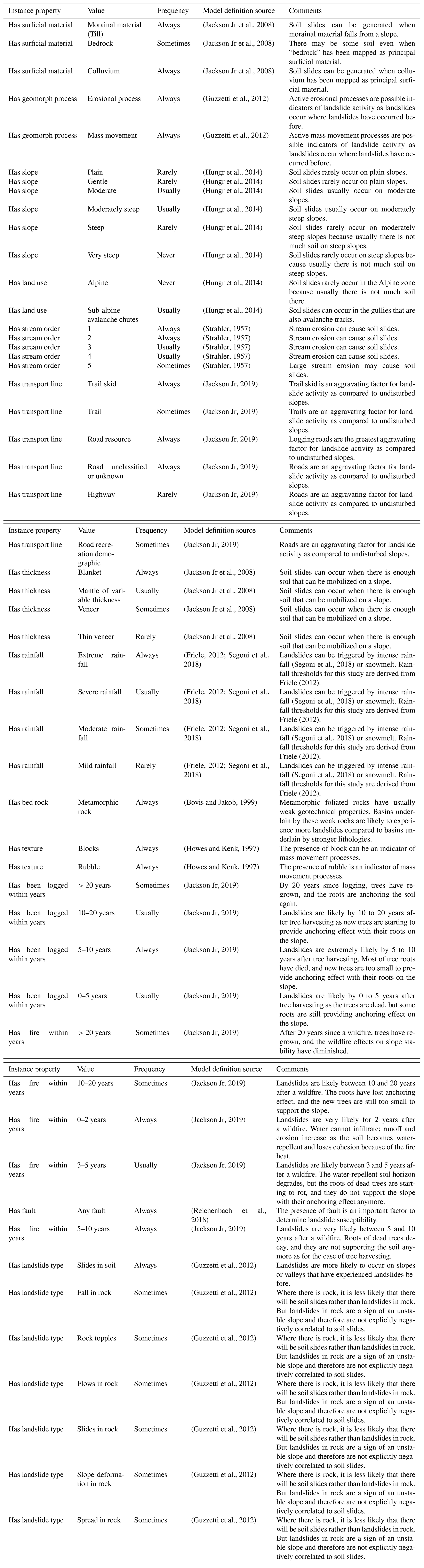
-
The web application is available at https://map.italy.minervageohazards.com/ (Minerva Intelligence, 2019g).
-
The schema extension is available at https://github.com/minervaintelligence/INSPIRE-NZ-Susceptibility (Minerva Intelligence, 2019e).
-
The code list extension is available at http://minerva.codes/registry (Minerva Intelligence, 2019a, b, c).
-
Data from the Italian National geoportal are available under “Attribution-NonCommercial-ShareAlike 3.0 Italy (CC BY-NC-SA 3.0 IT)” license (Ministero dell'Ambiente e della Tutela del Territorio e del Mare, 2017).
-
Data from the Veneto Geoportal are available under the “Italian Open Data License 2.0” (Regione del Veneto, 2020).
-
CORINE Land Cover data are available under EEA standard reuse policy: reuse of content on the EEA website for commercial or non-commercial purposes is permitted free of charge, provided that the source is acknowledged (Feranec et al., 2016).
-
The Tinitaly digital elevation model (DEM) is available upon request by sending an email to simone.tarquini@ingv.it with the subject of TINITALY DEM. Terms and conditions of use: data are provided for research purposes only. Data are provided solely to the person named on this application form and should not be given to third parties. Third parties who might need access to the same dataset are required to fill out their own application forms. Data from INGV are available under “Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)” (Tarquini et al., 2007).
-
The permafrost data are available under “Attribution 3.0 Unported (CC BY 3.0)” licence (Gruber, 2012).
-
GR, JM, CS, and DP wrote the paper.
-
GR conceptually designed the susceptibility schema, landslide extension, and the expert-based landslide models and expanded the geohazard ontology.
-
JM implemented the INSPIRE schema and code list extension and designed the web map application.
-
DP and CS designed the qualitative probabilistic method used to calculate susceptibility.
-
SL and BB implemented and maintain the web map.
-
VW implemented and maintained the geohazard ontology.
-
BB and CA implemented the qualitative probabilistic algorithm.
-
SR supported the semantic implementations and edited the manuscript.
-
DB helped in the redaction of the manuscript as well as reviewed the landslide models and the code list extensions.
The authors declare that they have no conflict of interest
This project was first presented at the Helsinki 2019 INSPIRE data challenge and won the first prize. The authors would like to acknowledge the conference organizer committee including the National Land Survey of Finland, the Ministry of Agriculture, and the Joint Research Centre of the European Commission and Spatineo. The authors would also like to acknowledge Massimiliano Alvioli et al. for the availability of the r.slopeunit code, Martin Mergili and Shiva Pudasaini for the r.avaflow code, and WeTransform GmbH for the Hale Connect and Hale Studio software licences. We would also like to thank the reviewers Ivan Marchesini and Omar F. Althuwaynee for constructive feedback on the manuscript.
This research was funded by Minerva Intelligence Inc.
This paper was edited by Filippo Catani and reviewed by Ivan Marchesini and Omar F. Althuwaynee.
Alvioli, M., Marchesini, I., Reichenbach, P., Rossi, M., Ardizzone, F., Fiorucci, F., and Guzzetti, F.: Automatic delineation of geomorphological slope units with r.slopeunits v1.0 and their optimization for landslide susceptibility modeling, Geosci. Model Dev., 9, 3975–3991, https://doi.org/10.5194/gmd-9-3975-2016, 2016. a
Alvioli, M., Guzzetti, F., and Marchesini, I.: Parameter-free delineation of slope units and terrain subdivision of Italy, Geomorphology, 358, 107124, https://doi.org/10.1016/j.geomorph.2020.107124, 2020. a
Aristotle: The Categories, 350 BCE. a
Association of Professional Engineers and Geoscientists of British Columbia: Guidelines for Legislated Landslide Assessments for proposed residencial development in BC, EGBC, Burnaby, British Columbia, Canada, Tech. Rep. May, 2010. a
Baum, R. L., Savage, W. Z., and Jonathan W., G.: Trigrs – A Fortran Program for Transient Rainfall Infiltration and Grid-Based Regional Slope-Stability Analysis, Version 2.0, USGS, Denver, Colorado, United States, Tech. rep., 2008. a
Bovis, M. and Jakob, M.: The role of debris supply conditions in predicting debris flow activity, Earth Surf. Proc. Land., 24, 1039–1054, 1999. a, b, c, d, e, f, g, h, i, j, k, l
Cetl, V., Nunes De Lima, V., Tomas, R., Lutz, M., D'eugenio, J., Nagy, A., and Robbrecht, J.: Summary Report on Status of implementation of the INSPIRE Directive in EU, https://doi.org/10.2760/162895, 2017. a
CGI: GeoSciML, available at: http://www.geosciml.org/ (last access: 26 October 2020), 2003. a
Cho, G. and Crompvoets, J.: The INSPIRE directive: some observations on the legal framework and implementation, Surv. Rev., 51, 310–317, https://doi.org/10.1080/00396265.2018.1454686, 2019. a, b
Corominas, J., van Westen, C., Frattini, P., Cascini, L., Malet, J. P., Fotopoulou, S., Catani, F., Van Den Eeckhaut, M., Mavrouli, O., Agliardi, F., Pitilakis, K., Winter, M. G., Pastor, M., Ferlisi, S., Tofani, V., Hervás, J., and Smith, J. T.: Recommendations for the quantitative analysis of landslide risk, B. Eng. Geol. Environ., 73, 209–263, https://doi.org/10.1007/s10064-013-0538-8, 2014. a
Craglia, M. and Campagna, M.: Advanced Regional SDI in Europe: Comparative cost-benefit evaluation and impact assessment perspectives, International Journal of Spatial Data Infrastructures Research, 5, 145–167, https://doi.org/10.2902/1725-0463.2010.05.art6, 2010. a
Cruden, D. M. and Couture, R.: The Working Classification of Landslides: material matters, Pan-Am CGS Geotechnical Conference, Toronto, Ontario, Canada, p. 7, 2011. a, b, c, d, e
Dai, F. C., Lee, C. F., and Ngai, Y. Y.: Landslide risk assessment and management: An overview, Eng. Geol., 64, 65–87, https://doi.org/10.1016/S0013-7952(01)00093-X, 2002. a
Dieu, T. B. and Gjermundsen, E. F.: Advance Geospatial Artificial Intelligence for Landslide Modeling, Prediction and Management, ISPRS Int. Geo.-Inf., Special Issue, available at: https://www.mdpi.com/journal/ijgi/special_issues/AI_landslide?listby=type&view=abstract (last access: October 2020), 2020. a
European Commission: INSPIRE Helsinki 2019, available at: https://www.inspire-helsinki-2019.fi/ (last access: October 2020), 2019. a
European Parliament and the Council: Directive 2007/2/EC of the European Parliament and of the council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE), Official Journal of the European Union, 50, 1–14, 2007. a, b
European Parliament and the Council: Commission Regulation (EU) No 1312/2014 of 10 December 2014 amending Regulation (EU) No 1089/2010 implementing Directive 2007/2/EC of the European Parliament and of the Council as regards interoperability of spatial data services, Official Journal of the European Union, 53, 13–34, https://doi.org/10.3000/17252555.L_2010.323.eng, 2014. a
Evans, S. G. and Clague, J. J.: Recent climatic change and catastrophic geomorphic processes in mountain environments, Geomorphology, 10, 107–128, https://doi.org/10.1016/0169-555X(94)90011-6, 1994. a, b, c
Facebook: React, available at: https://reactjs.org/ (last access: 26 October 2020), 2013. a
Feranec, J., Soukup, T., Hazeu, G., and Jaffrain, G. (Eds.): European Landscape Dynamics, Boca Raton, CRC Press, https://doi.org/10.1201/9781315372860, 2016. a
Friele, P., Millard, T. H., Mitchell, A., Allstadt, K. E., Menounos, B., Geertsema, M., and Clague, J. J.: Observations on the May 2019 Joffre Peak landslides, British Columbia, Landslides, 17, 913–930, https://doi.org/10.1007/s10346-019-01332-2, 2020. a
Friele, P. A.: Volcanic Landslide Risk Management, Lillooet River Valley, BC: Start of north and south FSRs to Meager Confluence, Meager Creek and Upper Lillooet River, Metro Vancouver Squamish District Ministry of Forests, Lands and Natural Resource Operations, Vancouver, British Columbia, Canada, Tech. rep., 2012. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x
Froude, M. J. and Petley, D. N.: Global fatal landslide occurrence from 2004 to 2016, Nat. Hazards Earth Syst. Sci., 18, 2161–2181, https://doi.org/10.5194/nhess-18-2161-2018, 2018. a
Geertsema, M.: Quick Clay, Springer Netherlands, Dordrecht, 803–804, in: Encyclopedia of Natural Hazards, 2013 edn., edited by: Bobrowsky, P. T., https://doi.org/10.1007/978-1-4020-4399-4_282, 2013. a
Gilpin, L. H., Bau, D., Yuan, B. Z., Bajwa, A., Specter, M., and Kagal, L.: Explaining explanations: An overview of interpretability of machine learning, Proceedings – 2018 IEEE 5th International Conference on Data Science and Advanced Analytics, Turin, Italy, DSAA 2018, 80–89, https://doi.org/10.1109/DSAA.2018.00018, 2019. a
Goodfellow, I., Bengio, Y., and Aaron, C.: Deep Learning, MIT press, Cambridge, Massachusetts, United States, 2016. a
Goudie, A.: Alphabetical Glossary of Geomorphology, IAG Publ., p. 84, http://www.geomorph.org/wp-content/uploads/2015/06/GLOSSARY_OF_GEOMORPHOLOGY1.pdf (last access: 26 October 2020), 2014. a, b
Gruber, S.: Derivation and analysis of a high-resolution estimate of global permafrost zonation, The Cryosphere, 6, 221–233, https://doi.org/10.5194/tc-6-221-2012, 2012. a, b
Guzzetti, F., Carrara, A., Cardinali, M., and Reichenbach, P.: Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy, Geomorphology, 13, 1995, https://doi.org/10.1016/S0169-555X(99)00078-1, 1999. a, b
Guzzetti, F., Mondini, A. C., Cardinali, M., Fiorucci, F., Santangelo, M., and Chang, K. T.: Landslide inventory maps: New tools for an old problem, Earth.-Sci. Rev., 112, 42–66, https://doi.org/10.1016/j.earscirev.2012.02.001, 2012. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x
Guzzetti, F., Gariano, S. L., Peruccacci, S., Brunetti, M. T., Marchesini, I., Rossi, M., and Melillo, M.: Geographical landslide early warning systems, Earth-Sci. Rev., 200, 102973, https://doi.org/10.1016/j.earscirev.2019.102973, 2020. a
Hajimoradlou, A., Roberti, G., and Poole, D.: Predicting Landslides Using Locally Aligned Convolutional Neural Networks, in: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, {IJCAI-20}, edited by: Bessiere, C., International Joint Conferences on Artificial Intelligence Organization, Yokohama, Japan, 2020. a, b
Howes, D. E. and Kenk, E.: Terrain Classification System for British Columbia, Tech. Rep. Version 2, Fisheries Branch Ministry of Environment and Surveys and Resource Mapping Branch Ministry of Crown Lands Province of British Columbia, Victoria, British Columbia, Canada, 1997. a, b, c, d, e, f, g, h, i, j, k
Hungr, O., Leroueil, S., and Picarelli, L.: The Varnes classification of landslide types, an update, Landslides, 11, 167–194, https://doi.org/10.1007/s10346-013-0436-y, 2014. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, aa, ab, ac, ad, ae, af, ag, ah, ai, aj, ak, al, am, an, ao, ap, aq, ar, as, at, au, av, aw, ax, ay, az, ba, bb, bc, bd, be, bf, bg
Hykes, S.: Docker, available at: https://www.docker.com/ (last access: 26 October 2020), 2013. a
INSPIRE Thematic Working Group Natural Risk Zones: D2.8.III.12 Data Specification on Natural Risk Zones – Technical Guidelines, Tech. Rep. March 2007, European Commission Joint Research Centre, Ispra, Italy, 2013. a
ISA: Re3gistry software 1.3, available at: https://ec.europa.eu/isa2/solutions/re3gistry_en (last access: 26 October 2020), 2016. a
Jackson Jr, L., Smyth, C., and Poole, D.: Hazardmatch: an application of artificial intelligence to landslide susceptibility mapping, Howe Sound Area, Bristish Columbia, 4th Canadian Conference on Geohazards: From Causes to Management, Quebec, Canada, p. 594, 2008. a, b, c, d, e, f, g, h, i, j
Jackson Jr, L. E.: Recommendation for adding logging, logging road, wildfire, and morphometric parameters to the soil-slide model, Tech. rep., available at: https://italy.minervageo.com/wp-content/uploads/2020/07/Minerva_Jackson2019.pdf (last access: 26 October 2020), 2019. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z, aa, ab, ac, ad, ae, af, ag, ah
Jakob, M.: A size classification for debris flows, Eng. Geol., 79, 151–161, https://doi.org/10.1016/j.enggeo.2005.01.006, 2005. a, b, c, d
Marcus, G.: Deep Learning: A Critical Appraisal, 1–27, arxiv [preprint], arxiv:1801.00631, 2018. a
Marcus, G. and Davis, E.: Rebooting AI: Building Artificial Intelligence We Can Trust, Knopf Doubleday Publishing Group, New York, NY, United States, 2019. a
McDougall, S.: 2014 Canadian Geotechnical Colloquium: Landslide runout analysis – current practice and challenges, Can. Geotech. J., 54, 605–620, https://doi.org/10.1139/cgj-2016-0104, 2016. a
Mergili, M., Marchesini, I., Alvioli, M., Metz, M., Schneider-Muntau, B., Rossi, M., and Guzzetti, F.: A strategy for GIS-based 3-D slope stability modelling over large areas, Geosci. Model Dev., 7, 2969–2982, https://doi.org/10.5194/gmd-7-2969-2014, 2014. a
Mergili, M., Fischer, J.-T., Krenn, J., and Pudasaini, S. P.: r.avaflow v1, an advanced open-source computational framework for the propagation and interaction of two-phase mass flows, Geosci. Model Dev., 10, 553–569, https://doi.org/10.5194/gmd-10-553-2017, 2017. a
MetaCarta: OpensLayer, available at: https://openlayers.org/ (last access: 26 October 2020), 2005. a
Mijić, N. and Bartha, G.: Infrastructure for Spatial Information in European Community (INSPIRE) Through the Time from 2007. Until 2017, Springer, Cham, 60, 34–42, https://doi.org/10.1007/978-3-030-02577-9_5, 2018. a
Minerva Intelligence: Minerva INSPIRE registry, available at: http://minerva.codes/registry (last access: 26 October 2020), 2019a. a, b
Minerva Intelligence: Natural Hazard Category Landslide Extension, available at: http://minerva.codes/codelist/NaturalHazardCategoryLandslideExtension (last access: 26 October 2020), 2019b. a, b
Minerva Intelligence: Landslide Size Class, available at: http://minerva.codes/codelist/LandslideSizeClass (last access: 26 October 2020), 2019c. a, b
Minerva Intelligence: Aristotelean Class Editor – ACE, available at: https://ace.minervaintelligence.com/ (last access: 26 October 2020), 2019d. a
Minerva Intelligence: INSPIRE Natural Risk Zone Schema Extension for Susceptibility Area, available at: https://github.com/minervaintelligence/INSPIRE-NZ-Susceptibility (last access: 26 October 2020), 2019e. a, b
Minerva Intelligence: Sea to Sky hazards, available at: https://www.minervageohazards.com/ (last access: 26 October 2020), 2019f. a
Minerva Intelligence: Minerva GAIA: Veneto Landslides, available at: https://map.italy.minervageohazards.com/ (last access: October 2020), 2019g. a
Ministero dell'Ambiente e della Tutela del Territorio e del Mare: Geoportale Nazionale, available at: http://www.pcn.minambiente.it/mattm/ (last access: 26 October 2020), 2017. a
Napolitano, E., Marchesini, I., Salvati, P., Donnini, M., Bianchi, C., and Guzzetti, F.: LAND-deFeND – An innovative database structure for landslides and floods and their consequences, J. Environ. Manage., 207, 203–218, https://doi.org/10.1016/j.jenvman.2017.11.022, 2018. a
Newman, J. P., Maier, H. R., Riddell, G. A., Zecchin, A. C., Daniell, J. E., Schaefer, A. M., van Delden, H., Khazai, B., O'Flaherty, M. J., and Newland, C. P.: Review of literature on decision support systems for natural hazard risk reduction: Current status and future research directions, Environ. Modell. Softw., 96, 378–409, https://doi.org/10.1016/j.envsoft.2017.06.042, 2017. a
Pearl, J.: Probabilistic reasoning in intelligent systems: networks of plausible inference, Morgan Kaufmann, San Francisco, California, United States, 1988. a, b
Phengsuwan, J., Shah, T., James, P., Thakker, D., Barr, S., and Ranjan, R.: Ontology-based discovery of time-series data sources for landslide early warning system, Computing, 102, 745–763, https://doi.org/10.1007/s00607-019-00730-7, 2019. a
Poole, D. and Mackworth, A.: Artificial Intelligence: foundations of computational agents, Cambridge University Press, UK, second edn., 2017. a, b, c, d
Poole, D. and Smyth, C.: Type Uncertainty in Ontologically-Grounded Qualitative Probabilistic Matching, in: Symbolic and Quantitative Approaches to Reasoning with Uncertainty, edited by: Godo, L., 763–774, Springer Berlin Heidelberg, Berlin, Heidelberg, 2005. a, b
Poole, D., Smyth, C., and Sharma, R.: Ontology Design for Scientific Theories That Make Probabilistic Predictions, IEEE Intell. Syst., 24, 27–36, 2009. a
Pudasaini, S. P.: A general two-phase debris flow model, J. Geophys. Res.-Earth, 117, 1–28, https://doi.org/10.1029/2011JF002186, 2012. a
Refraction Researtch: PostGIS, available at: https://postgis.net/ (last access: 26 October 2020), 2001. a
Regione del Veneto: Geoportale, available at: https://idt2.regione.veneto.it/, last access: 26 October 2020. a
Reichenbach, P., Rossi, M., Malamud, B. D., Mihir, M., and Guzzetti, F.: A review of statistically-based landslide susceptibility models, Earth-Sci. Rev., 180, 60–91, https://doi.org/10.1016/j.earscirev.2018.03.001, 2018. a, b, c, d
SafeLand: Recommended procedures for validating landslide hazard and risk models and maps, Living with landslide risk in Europe: Assessment, effects of global change, and risk management strategies, NGI, Oslo, Norway, p. 162, 2011. a, b, c, d, e, f, g, h
Segoni, S., Tofani, V., Rosi, A., Catani, F., and Casagli, N.: Combination of Rainfall Thresholds and Susceptibility Maps for Dynamic Landslide Hazard Assessment at Regional Scale, Front. Earth Sci., 6, p. 85, https://doi.org/10.3389/feart.2018.00085, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x
Sermet, Y. and Demir, I.: Towards an information centric flood ontology for information management and communication, Earth Sci. Inform., 12, 541–551, https://doi.org/10.1007/s12145-019-00398-9, 2019. a
Shapiro, S. C.: Encyclopedia of Artificial Intelligence, John Wiley & Sons, Inc., New York, USA, 2nd edn., 1992. a
Sharma, R., Poole, D., and Smyth, C.: A framework for ontologically-grounded probabilistic matching, Int. J. Approx. Reason, 51, 240–262, https://doi.org/10.1016/j.ijar.2009.05.007, 2010. a, b
Smith, B.: Ontology, in: Blackwell Guide to the Philosophy of Computing and Information, edited by: Floridi, L., chap. 11, 155–166, Blackwell, Oxford, 2003. a
Smyth, C. and Poole, D.: Qualitative Probabilistic Matching with Hierarchical Descriptions, {KR} 2004: Principles of Knowledge Representation and Reasoning, AAAI Press, San Jose, California, United States, 479–486, 2004. a, b
Smyth, C., Poole, D., and Sharma, R.: Semantic e-Science and Geology, Association for the Advancement of Artificial Intelligence, Semantic e-Science AAAI Workshop, 22–26 July, Vancouver, British Columbia, Canada, 2007. a, b, c, d, e
Strahler, A. N.: Quantitative Analysis of Watershed Geomorphology, Eos, Transactions American Geophysical Union, 38, 913–920, https://doi.org/10.1029/TR038i006p00913,1957. a, b, c, d, e, f, g, h, i, j
Tarquini, S., Isola, I., Favalli, M., and Battistini, A.: TINITALY, a digital elevation model of Italy with a 10 m-cell size (Version 1.0), Data set, Istituto Nazionale di Geofisica e Vulcanologia (INGV), https://doi.org/10.13127/TINITALY/1.0, 2007. a
The Open Planning Project: Geoserver, available at: http://geoserver.org/ (last access: 26 October 2020), 2001. a
Tomas, R., Harrison, M., Barredo, J. I., Thomas, F., Llorente Isidro, M., Pfeiffer, M., and Čerba, O.: Towards a cross-domain interoperable framework for natural hazards and disaster risk reduction information, Nat. Hazards, 78, 1545–1563, https://doi.org/10.1007/s11069-015-1786-7, 2015. a, b, c
USDA: Chapter 3 Engineering Classification of Earth Materials, Part 631 National Engineering Handbook, Washington DC, United States, p. 35, 2012. a, b
Van Den Eeckhaut, M. and Hervás, J.: State of the art of national landslide databases in Europe and their potential for assessing landslide susceptibility, hazard and risk, Geomorphology, 139-140, 545–558, https://doi.org/10.1016/j.geomorph.2011.12.006, 2012. a, b
Van Den Eeckhaut, M., Hervas, J., and Montanarella, L.: Landslide Databases in Europe: Analysis and Recommendations for Interoperability and Harmonisation, in: Landslide Science and Practice, edited by: Margottini, C., Canuti, P., and Sassa, K., vol. 1, 243–247, Springer, Berlin, Heidelberg, https://doi.org/10.1007/978-3-642-31325-7_4, 2013. a
W3C Working Group: RDF 1.1 Primer, available at: https://www.w3.org/TR/rdf11-primer (last access: 26 October 2020), 2014. a
WeTransform: Hale Studio, available at: https://www.wetransform.to/products/halestudio/ (last access: 26 October 2020), 2008. a, b
WeTransform: Hale Connect, available at: https://www.wetransform.to/products/haleconnect/ (last access: 26 October 2020), 2014. a
Wilford, D. J., Sakals, M. E., Innes, J. L., Sidle, R. C., and Bergerud, W. A.: Recognition of debris flow, debris flood and flood hazard through watershed morphometrics, Landslides, 1, 61–66, https://doi.org/10.1007/s10346-003-0002-0, 2004. a
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Dictionary of terms
- Appendix B: Properties used for the landslide classification
- Appendix C: Landslide models
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Methods
- Results
- Discussion
- Conclusions
- Appendix A: Dictionary of terms
- Appendix B: Properties used for the landslide classification
- Appendix C: Landslide models
- Data availability
- Author contributions
- Competing interests
- Acknowledgements
- Financial support
- Review statement
- References