the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 02 Jul 2020
| 02 Jul 2020
Spatial seismic hazard variation and adaptive sampling of portfolio location uncertainty in probabilistic seismic risk analysis
Christoph Scheingraber
Martin Käser
Probabilistic seismic risk analysis is widely used in the insurance industry to model the likelihood and severity of losses to insured portfolios by earthquake events. The available ground motion data – especially for strong and infrequent earthquakes – are often limited to a few decades, resulting in incomplete earthquake catalogues and related uncertainties and assumptions. The situation is further aggravated by the sometimes poor data quality with regard to insured portfolios. For example, due to geocoding issues of address information, risk items are often only known to be located within an administrative geographical zone, but precise coordinates remain unknown to the modeler.
We analyze spatial seismic hazard and loss rate variation inside administrative geographical zones in western Indonesia. We find that the variation in hazard can vary strongly between different zones. The spatial variation in loss rate displays a similar pattern as the variation in hazard, without depending on the return period.
In a recent work, we introduced a framework for stochastic treatment of portfolio location uncertainty. This results in the necessity to simulate ground motion on a high number of sampled geographical coordinates, which typically dominates the computational effort in probabilistic seismic risk analysis. We therefore propose a novel sampling scheme to improve the efficiency of stochastic portfolio location uncertainty treatment. Depending on risk item properties and measures of spatial loss rate variation, the scheme dynamically adapts the location sample size individually for insured risk items. We analyze the convergence and variance reduction of the scheme empirically. The results show that the scheme can improve the efficiency of the estimation of loss frequency curves and may thereby help to spread the treatment and communication of uncertainty in probabilistic seismic risk analysis.
- Article
(3561 KB) - Full-text XML
- BibTeX
- EndNote





Seismic risk analysis is widely used in academia and industry to model the possible consequences of future earthquake events, but it is often limited by the availability of reliable earthquake event ground motion data over a longer period of time, resulting in the necessity for many assumptions and a wide range of deep uncertainties (Goda and Ren, 2010). The treatment and communication of uncertainties is highly important for informed decision making and a holistic view of risk (Tesfamariam et al., 2010; Cox, 2012; Bier and Lin, 2013). In the insurance industry, probabilistic seismic risk analysis (PSRA) is the means of choice to model the likelihood and severity of losses to insured portfolios due to earthquakes. In this context precise exposure locations are often unknown, which can have a significant impact on scenario loss, as well as on loss frequency curves (Bal et al., 2010; Scheingraber and Käser, 2019).
For PSRA in the insurance industry, uncertainty is usually taken into account by means of Monte Carlo (MC) simulation (e.g., Pagani et al., 2014; Tyagunov et al., 2014; Foulser-Piggott et al., 2020). This is a computationally intensive process, because the error convergence of MC is relatively slow and a high-dimensional loss integral needs to be evaluated with a sufficient sample size. In PSRA, the hazard component typically dominates the overall model run time. As a result, stochastic treatment of portfolio location uncertainty can be particularly challenging – ground motion needs to be simulated on a large number of sampled risk locations. On the other hand, a fast model run time is a key requirement for underwriting purposes in the insurance industry. Methods or sampling schemes to improve the error convergence of MC simulation are known as variance reduction techniques. MC simulation is ubiquitous in many areas of science and engineering, and a wide variety of sampling schemes exist. Some well-known ideas are common random numbers and control variates (Yang and Nelson, 1991); importance, stratified, and hypercube sampling; quasi-Monte Carlo simulation (QMC) using low-discrepancy sequences; and adaptive sampling. The error convergence of different sampling schemes has been investigated for many different types of integrals and application areas (Hess et al., 2006; dos Santos and Beck, 2015). Some work has already been performed on variance reduction for probabilistic seismic hazard analysis (PSHA) and PSRA in the form of importance sampling, e.g., preferentially sampling the tails of the magnitude and site ground motion probability distributions (Jayaram and Baker, 2010; Eads et al., 2013). However, to our knowledge so far no study has specifically investigated variance reduction for location uncertainty in PSRA in a modern risk assessment framework. Building on a framework proposed in a recent study, in the present paper we describe a novel variance reduction scheme specifically designed to increase the computational efficiency of stochastic treatment of portfolio location uncertainty in PSRA.
The remainder of this paper is structured as follows. We outline the most important theoretical background in Sect. 2. Using a seismic risk model of western Indonesia, in Sect. 3 we explore spatial hazard and loss rate variation inside administrative zones. Based on this, in Sect. 4 we propose an adaptive location uncertainty sampling scheme and investigate its performance using several test cases in Sect. 5. In Sect. 6, we give some recommendations on how to apply the results in practice and conclude with possible future improvements.
2.1 Seismic hazard and risk analysis
Seismic hazard is modeled in both academia and industry using a variety of different methods. Deterministic seismic hazard assessment traditionally aims at identifying the “maximum creditable earthquake” that represents the largest seismic hazard to a particular site. This approach is often used to estimate the so-called “design earthquake ground motion” for earthquake engineering purposes (e.g., Mualchin, 2011; Tsapanos et al., 2011). Another approach is to employ extreme value statistics to assess the probability of rare events, e.g., earthquakes that are more severe than those historically observed (e.g., Papadopoulou-Vrynioti et al., 2013; Pavlou et al., 2013). In this study we use PSRA. Below, we briefly outline the underlying theory and give reasons why this approach is well-suited for the purposes of the insurance industry.
PSRA is based on the method of probabilistic seismic hazard analysis (PSHA; Cornell, 1968; Senior Seismic Hazard Committee, 1997), which relies on a number of assumptions outlined in the following. In PSHA, the exceedance rate λ of ground motion level y0 at a site r0 is expressed by the hazard integral
with ν(m,r)dmdr the seismic rate density which describes the spatiotemporal distribution of seismic activity, the conditional probability of exceeding ground motion y0 at site r0 given a rupture of magnitude m at source location r, and V the spatial integration volume containing all sources which can cause relevant ground motion at r0. Assuming that the occurrence of earthquake events is a temporal Poisson process, the probability of at least one exceedance of y0 within time interval t0 is given by
where is the mean annual recurrence rate. Classical PSHA relies on quadrature integration; i.e., a deterministic algorithm is used to solve Eq. (1). A historically important software implementation that is still popular and useful for educational purposes is SEISRISK III (Bender and Perkins, 1987). Classical PSHA has its limits however, since the treatment of advanced topics, such as complex source geometries or spatial ground motion correlation, is often intricate and sometimes impossible. The approach is not well-suited to be extended to assess the risk of building damage and monetary loss to spatially distributed insurance portfolios.
For PSRA in the insurance industry, event-based MC simulation is commonly used today, since this approach is well-suited to numerically solve high-dimensional integrals as required for large-scale risk analyses of insured portfolios with many uncertainties. In this approach, stochastic simulation is performed to obtain a set of stochastic ground motion fields and to then compute the probability that a loss level ι0 is exceeded as
where is the loss probability density function for a portfolio Θ given the ith ground motion field . Summing up the contribution of all ne events yields the total loss exceedance probability. A probable maximum loss (PML) curve, showing loss against mean return period T (with ), can be obtained from the loss exceedance probability curve (Eq. 3) using a first-order Taylor approximation of Eq. (2):
Here, t0 is the period of interest (time interval), which is 1 year for most reinsurance contracts.
For more details on PSHA and PSRA, we refer to the comprehensive textbook of McGuire (2004).
2.2 Portfolio location uncertainty
Perhaps surprisingly, in the insurance industry, portfolios frequently lack precise coordinate-based location information. Obtaining this information is often not possible, e.g., because geocoding engines are not used systematically or can not reliably obtain coordinates from the policy address of the insured risk. Especially for large treaty portfolios with thousands or millions of risks, it apparently is simply too much effort for the primary insurer or the insurance broker to obtain and provide this information. Unfortunately, this is also not uncommon for smaller portfolios consisting only of a few hundred high-value risks. However, administrative zones, such as postal codes, can easily be obtained from the insurance policy.
Exposure uncertainty has previously been identified as an important area of research (Crowley, 2014), and we already introduced a framework for stochastic treatment of location uncertainty in a recent paper (Scheingraber and Käser, 2019). In our framework, locations of risk items without precise coordinate location information are sampled with replacement from a weighted irregular grid inside their corresponding administrative zone. The grid weights are used to preferentially sample locations in areas of assumed high insurance density, e.g., based on population density or on commercial and industrial inventory data depending on the type of risk (Dobson et al., 2000). An example of such a weighted grid is shown in Fig. 1.
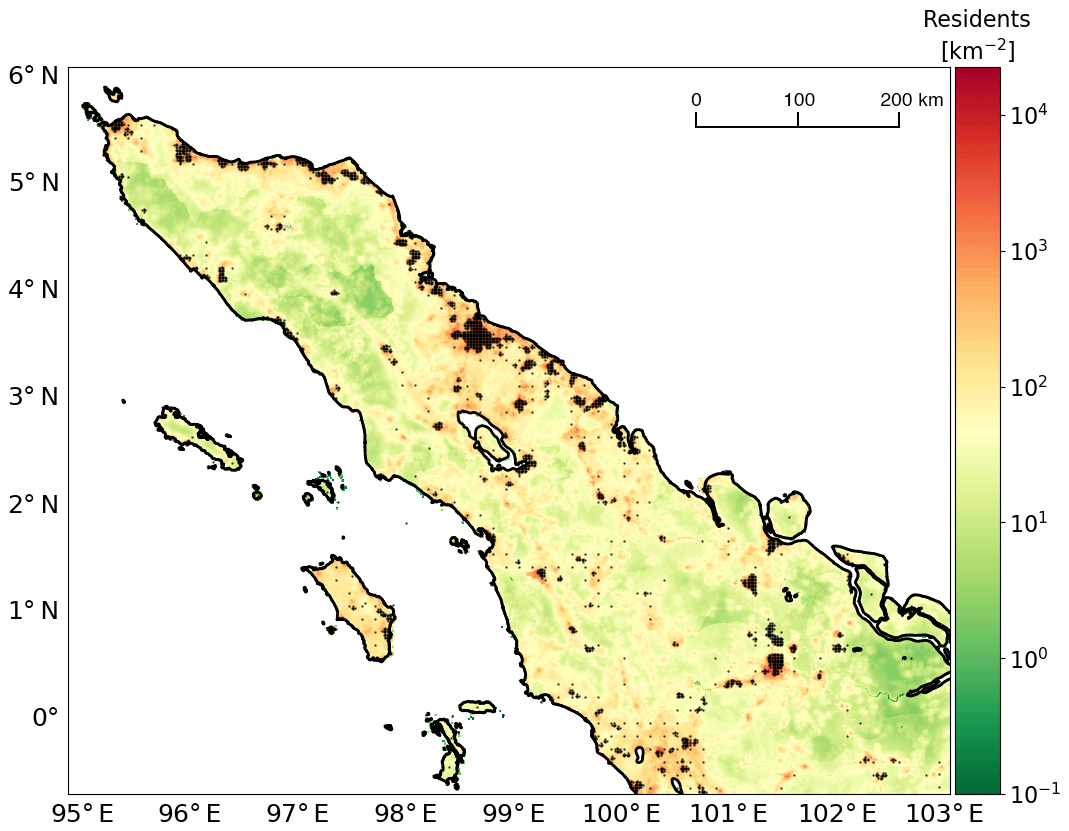
Figure 1An example of a weighted grid used as an insurance density proxy for the location uncertainty framework. The map shows northern Sumatra. Color indicates population density (residents per square kilometer) as a proxy for insured exposure density. Black markers depict grid points of the weighted grid. The population data in this plot are based on a free dataset (Gaughan et al., 2015).
In MC simulation, the choice of a pseudo-random number generator is of particular importance. In this study we use MRG32K3a, a combined multiple recursive generator which efficiently generates random number sequences with low memory requirements and excellent statistical properties (L'Ecuyer, 1999). MRG32K3a supports up to 1.8×1019 statistically independent substreams. Each substream has a period1 of 7.6×1022. These properties make MRG32K3a well-suited for a large-scale parallel MC simulation of seismic risk.
2.3 Evaluation of the proposed sampling scheme
2.3.1 Standard error
Given that MC simulation is a stochastic method, there are no strict error bounds for statistics of interest obtained from a sample of finite size n. The error is therefore usually estimated using the standard deviation of the sampling distribution of the respective statistic, which is referred to as its standard error (ESE). If the sampling distribution is known (e.g., normal), standard errors can often be obtained using a simple closed-form expression (Harding et al., 2014). For the statistics estimated in this study, e.g., PML at a specific return period, we can however not make a valid distribution assumption when taking location uncertainty into account. We therefore use repeated simulation to evaluate the performance of the proposed sampling scheme. The standard error can then be estimated as
where denotes a set of estimations of a statistic obtained from R repeated simulations and Var(⋅) the variance operator. The corresponding relative standard error ERSE can be obtained by dividing ESE by the estimated statistic. To estimate confidence intervals of standard errors, we use bootstrapping with the bias-corrected accelerated percentile method (Efron, 1979; Efron and Tibshirani, 1986).
2.3.2 Bias and convergence plots
The bias of an estimator is defined as
where , x2, …, xn) is the estimator depending on n members of the sample and 𝔼θ its expected value. Taking into account that deriving the bias analytically is infeasible for a complex numerical simulation such as the one performed by our framework, we use simple MC2 with a large sample size as empirical reference and approximation for θ. In addition, we use convergence plots, which are a simple yet powerful method to monitor and verify the results (Robert and Casella, 2004). The values estimated using simple MC and the adaptive variance reduction scheme are plotted against increasing sample size n.
2.3.3 Variance reduction, convergence order, and speedup
To quantify the performance of the proposed scheme at a particular sample size n, we use the following well-known definition of variance reduction (VR):
where σ2MC is the variance using simple MC and the variance using the proposed location sampling scheme (MacKay, 2005; Juneja and Kalra, 2009).
To describe the asymptotic error behavior for growing n, we use the big O notation (𝒪; Landau, 1909; Knuth, 1976). For example, the error convergence order of simple MC is always 𝒪(n−0.5), independent of the dimensionality of the integrand (Papageorgiou, 2003).
To compare the real run time required by simple MC and the proposed scheme to reach a specific relative standard error level εRSE, we use the speedup S defined as
where tMC is the run time required by simple MC and tLSS the run time required by the proposed location sampling scheme.
2.4 Generation of synthetic portfolios
In this work, we use synthetic portfolios in western Indonesia modeled after real-world counterparts in terms of spatial distribution of risk items, as well as value distribution among risk items.
2.4.1 Value distribution
The total sum insured (TSI) is kept constant for all portfolios:
However, the TSI is distributed among a varying number of risk items (portfolio size). For this study, we use portfolio sizes nr of 1, 10, 20, 50, 100, 1000, and 10 000 risk items.
The value distribution observed in many real residential portfolios can be approximated well by a randomly perturbed flat value distribution:
VIflat,i (“value insured”) is the value assigned to the ith risk item, and nr denotes the number of risk items. Xi is a uniform random number in the interval [1−p, 1+p], where p is a perturbation factor controlling the variation in insured values among individual risk items in the portfolio. For this study, we set p to 0.2. This value corresponds to the characteristics we observe in many real residential portfolios and is in accordance with the assumption of a relatively flat value distribution, which is commonly made when modeling the value distribution of residential building stock (e.g., Kleist et al., 2006; Okada et al., 2011).
Equation (11) normalizes the nr randomly perturbed insured values to ensure .
2.4.2 Geographical distribution
For each portfolio size, we created a set of six portfolios with an increasing fraction of unknown coordinates: 0 %, 20 %, 40 %, 60 %, 80 %, and 100 % of the risk items have unknown coordinates and are only known on the basis of their administrative zone (Indonesian provinces, or regencies and cities; see Sect. 3).
The geographical distribution of the exposure locations follows the weighted irregular grid described in Sect. 2.2. For each portfolio size, a portfolio with 0 % unknown coordinates is initially created by choosing exposure locations from the irregular grid according to the grid point weights. For the other portfolios with the same number of risk items but a higher fraction of unknown coordinates, coordinate-based location information is then removed stepwise from the initial portfolio. In each step, 20 % of the risk items are randomly selected for the removal of coordinates until all risk items have unknown coordinates.
3.1 Hazard model
For this study, we use a custom seismic risk model. Our model is based on the Southeast Asia hazard model by Petersen et al. (2007) of the United States Geological Survey (USGS), which was the most recent, reliable, and publicly available model when we created our risk model. Site conditions or soil classes are based on topographic slope (Wald and Allen, 2007) but have been refined locally to consider areas of soft soil, such as river beds. The geometry of the Sumatra subduction zone has been improved over the original USGS model. It is a complex representation of the fault geometry based on the Slab 1.0 model (Hayes et al., 2012), which provides three-dimensional data of the subduction. To generate finite geometry patches for individual events on the complex fault, we use a rupture floating mechanism similar to the implementation of OpenQuake (Pagani et al., 2014), a free and open-source seismic hazard and risk software developed as part of the Global Earthquake Model initiative (Crowley et al., 2013).
In order to reduce the computational effort of the hazard model, we have simplified the logic tree of the ground motion model for all tectonic region types. This allowed us to thoroughly analyze the performance of the proposed sampling scheme for a larger set of insurance portfolios and sampling scheme parameters, while retaining overall accordance with the hazard of the original model. Table 1 gives an overview of the selected ground motion models and their weights.
Boore and Atkinson (2008)Campbell and Bozorgnia (2008)Chiou and Youngs (2008)Toro et al. (1997)Zhao et al. (2006)Youngs et al. (1997)Atkinson and Boore (2003)Table 1Ground motion models and corresponding weights used by the hazard model for different tectonic region types.
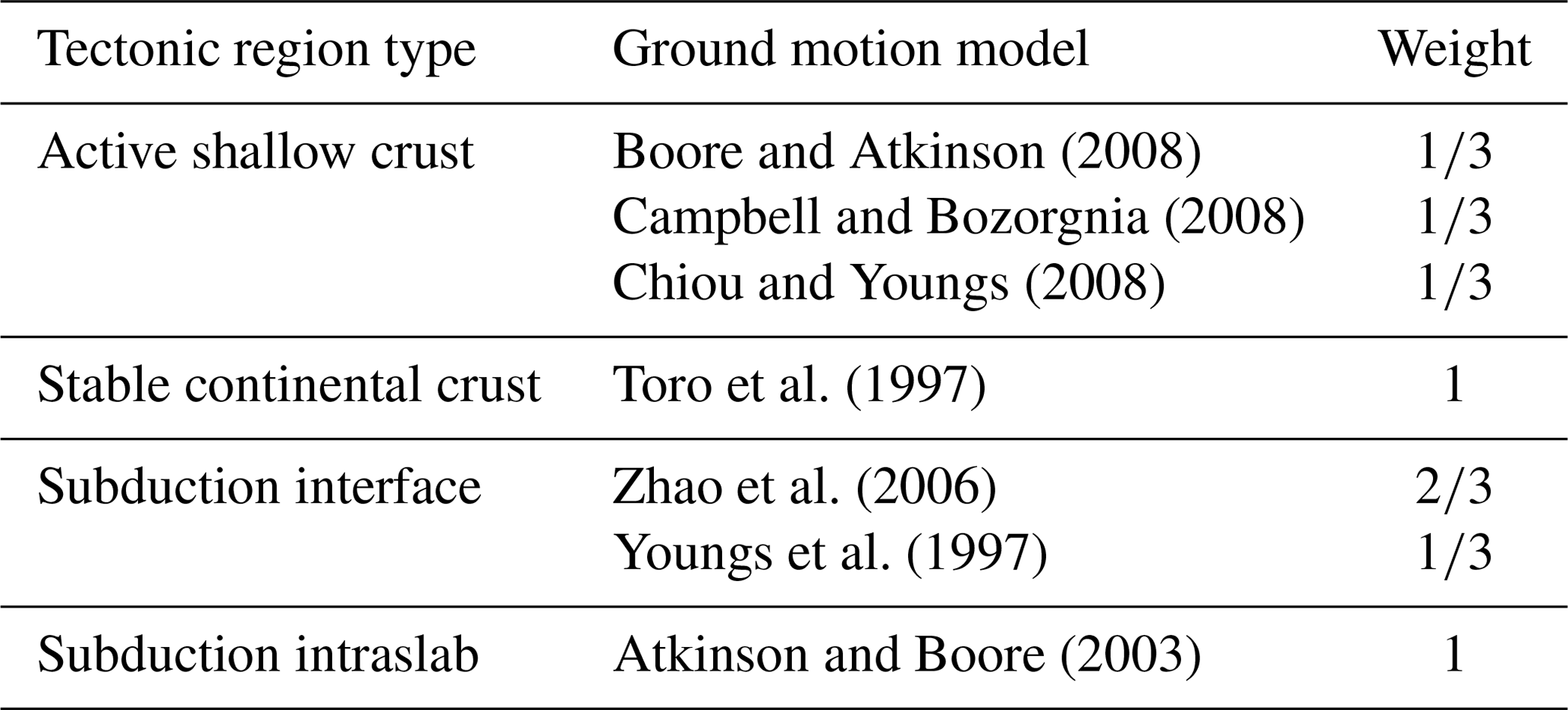
Figure 2 shows the resulting seismic hazard map for an exceedance probability of 10 % in 50 years. Assuming a temporal Poisson distribution, this probability equals an average return period of 475 years, which is used for most seismic hazard maps and by the engineering community for the design of building codes. The depicted area is comprised of the islands of Sumatra, Java, and Kalimantan (the Indonesian sector on the island of Borneo). The hazard results of our model are in general agreement with results obtained using the original USGS Southeast Asia model (Petersen et al., 2007) or third-party implementations, such as by the Global Earthquake Model (GEM) initiative evaluated using the OpenQuake engine3. Slight differences are caused by the inclusion of site conditions, a simplified ground motion model logic tree, different source parameterization, improved subduction geometry representation, and slightly modified seismicity rates based on the latest ISC-GEM Global Instrumental Earthquake Catalogue (Storchak et al., 2013) and Global Historical Earthquake Catalogue4.
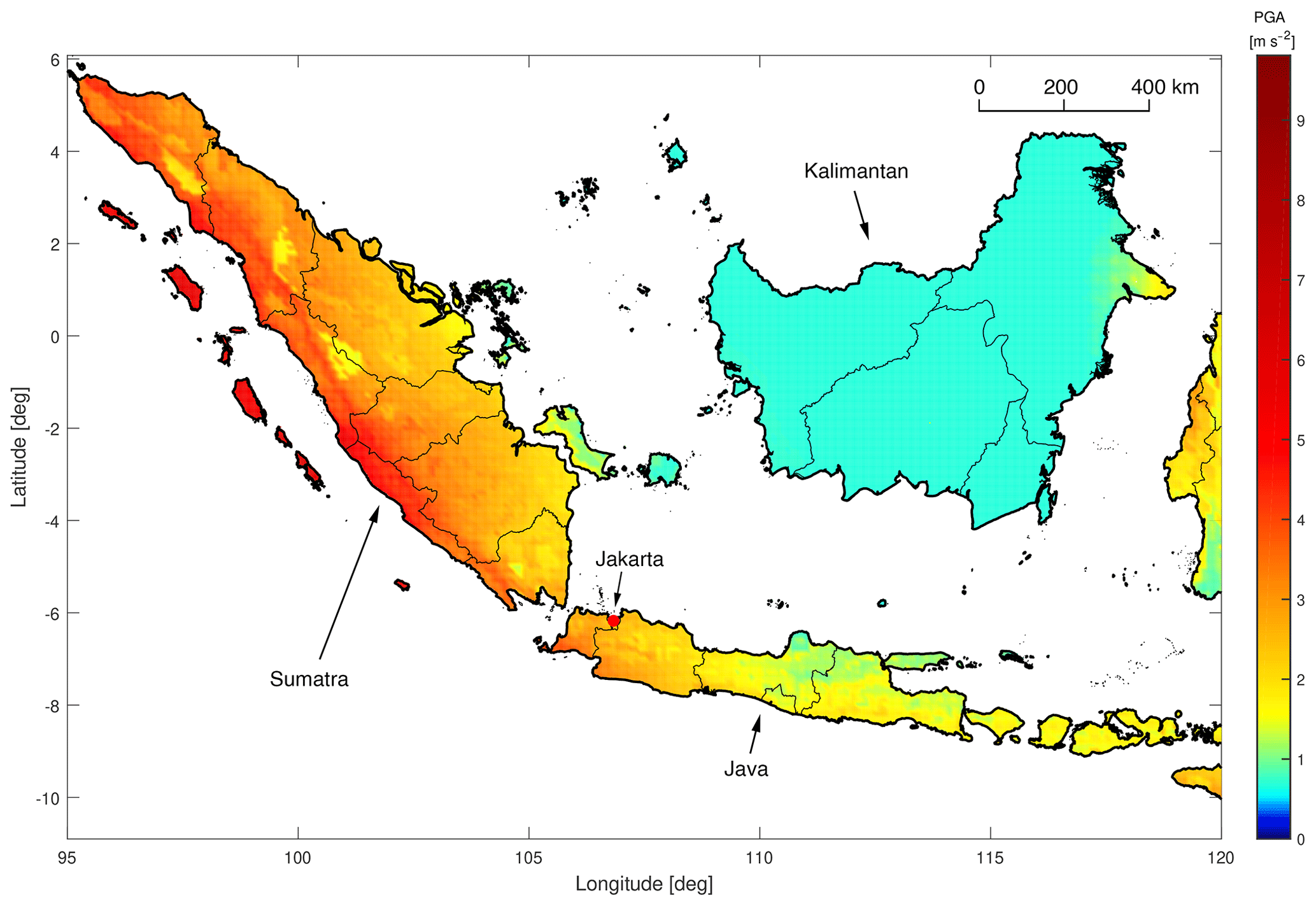
Figure 2Seismic hazard in western Indonesia, as obtained using our hazard model. Color shows the level of peak ground acceleration (PGA, m s−2) that is predicted to be exceeded at an average return period of 475 years.
On the island of Sumatra, the effect of the Sumatra fault zone is clearly visible and seismic hazard is high. The seismic hazard of Java is highest in the western area of the island, around the city of Jakarta. The hazard levels decrease towards the east. On Kalimantan, there are no known or modeled seismic crustal faults. Therefore, only a low level of spatially homogenous distributed gridded seismicity is used in this area, resulting in low hazard.
The hazard model and results are described in more detail in a recent paper (Scheingraber and Käser, 2019).
3.2 Spatial seismic hazard variation
For this analysis, we compute seismic hazard on a regular grid using a resolution of 0.3∘. We investigate the coefficient of variation (CV) of hazard inside administrative geographical zones for different levels of resolution, corresponding to provinces and regencies or cities in Indonesia. The CV is defined as
where σ is the standard deviation and μ the mean.
3.2.1 Dependence on resolution level of geographical zones
Figure 3 shows the CV of peak ground acceleration with an exceedance probability of 10 % in 50 years per province in Indonesia. There is a noticeable decrease in the CV from west to east. The subduction modeled by the complex fault and the Sumatra fault zone (SFZ) results in the highest CV on Sumatra (most values of about 0.2–0.3). The CV is also relatively high on Java (around 0.15). The CV is the lowest in Kalimantan (<0.1) due to the absence of any known or modeled crustal faults. As only gridded seismicity is used in this area, the hazard variation is very small. Furthermore, zones with a large extent perpendicular to the SFZ show a larger CV than zones with a smaller extent along the direction of the steepest hazard gradient. An example of this is the provinces of Jambi and Bengkulu in Fig. 3. Arguably, location uncertainty is more important in Jambi than in Bengkulu.
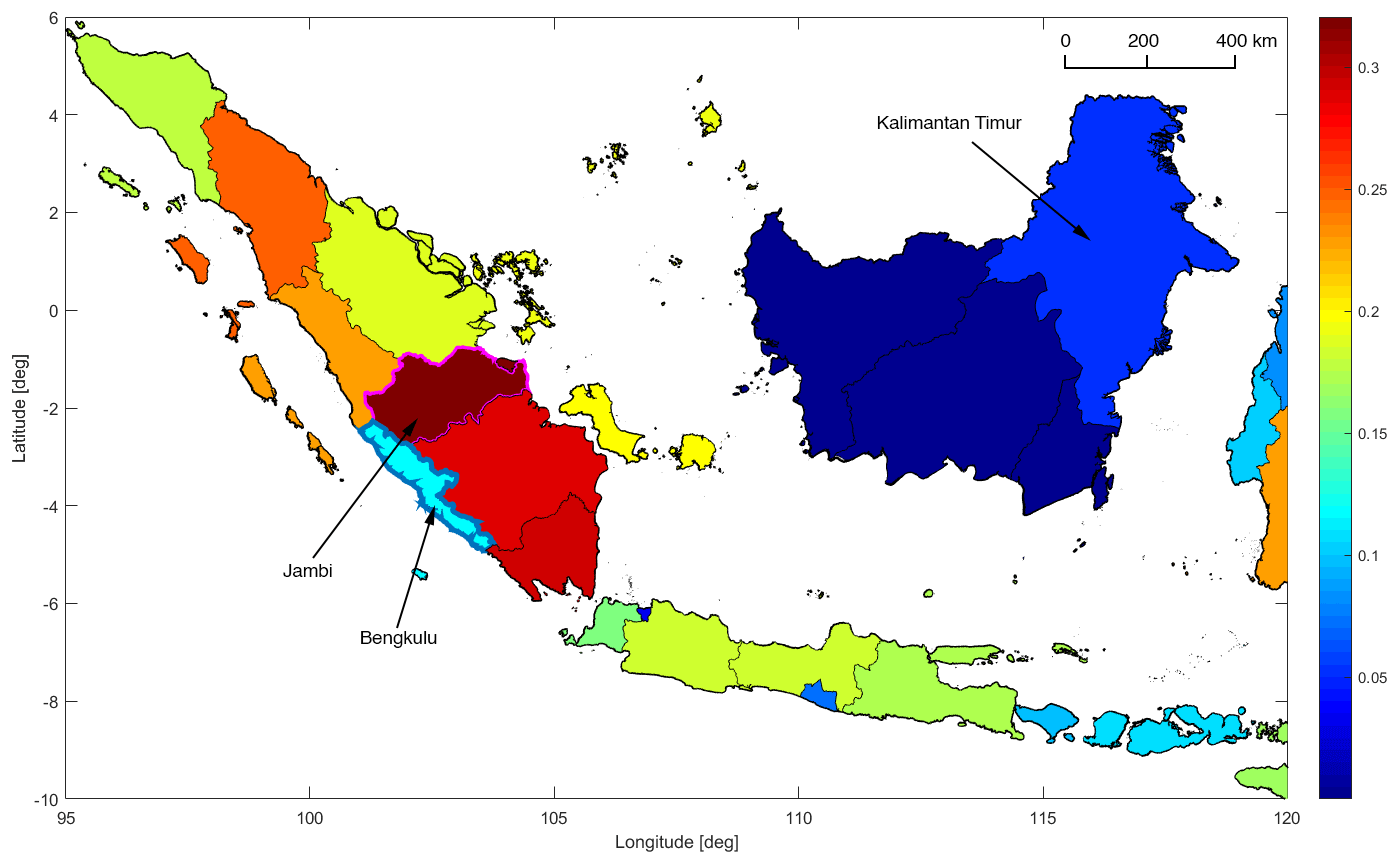
Figure 3Coefficient of variation (CV) of peak ground acceleration (PGA) with an exceedance probability of 10 % in 50 years inside provinces in western Indonesia. Color denotes the CV. Note how the CV is higher in provinces that have a large extent perpendicular to the Sumatra fault zone, such as Jambi (outlined in pink color), than in provinces with a small extent in that direction, such as Bengkulu (outlined in blue).
Figure 4 shows the CV per regency or city for the same exceedance probability.
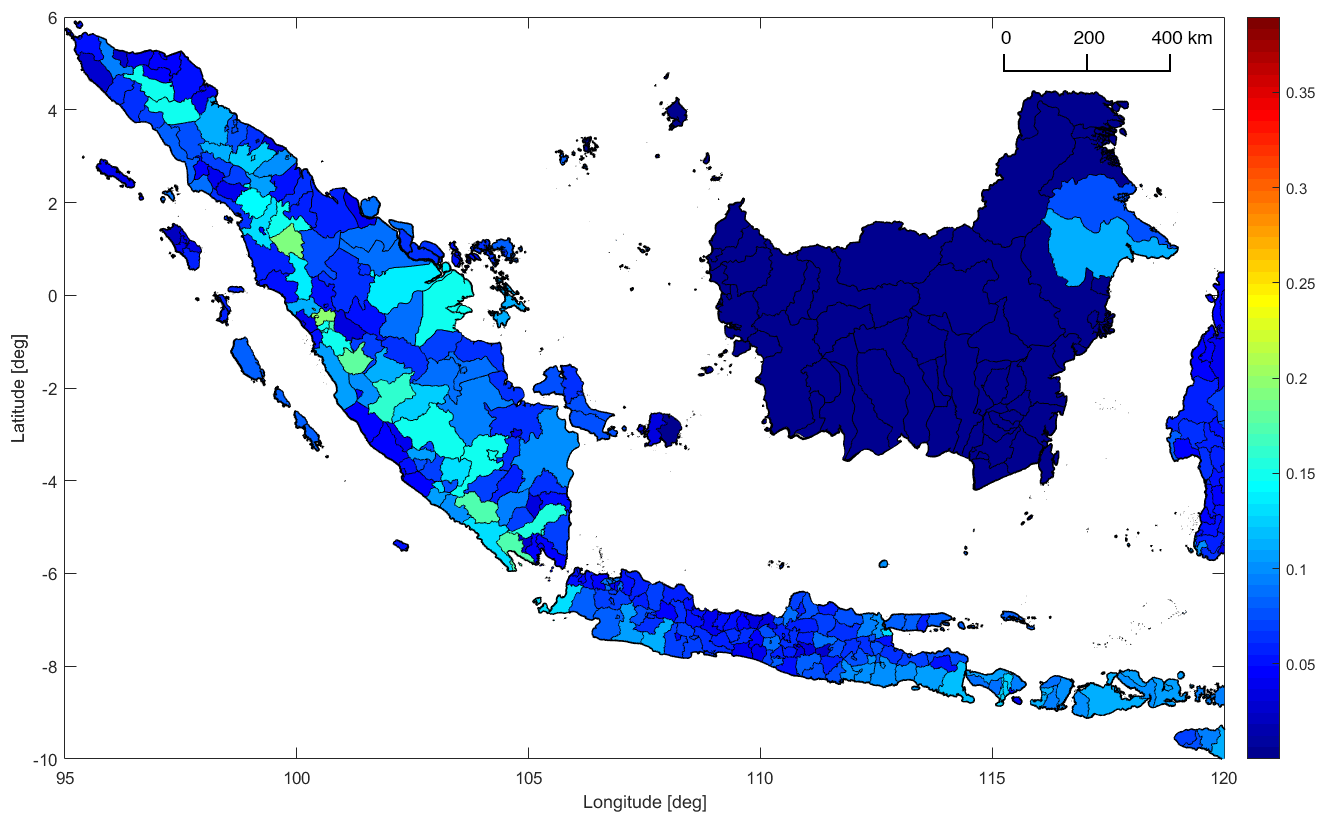
Figure 4Coefficient of variation (CV) of peak ground acceleration (PGA) with an exceedance probability of 10 % in 50 years inside regencies and cities in western Indonesia. Color denotes the CV. At this geographical resolution the CV is lower than for provinces (see Fig. 3), and the influence of individual seismotectonic features, such as the Sumatra fault zone, becomes apparent.
Due to the smaller spatial extent of the administrative zones, the CV is in general lower at this more granular resolution of administrative geographical zones. Another observation is that the influence of individual seismotectonic features emerges; the CV is higher in the vicinity of modeled faults. While the Sumatra subduction only has a weak influence, the SFZ has a pronounced effect. Near the SFZ, the CV has values of about 0.1–0.2. Perpendicular to the SFZ, the CV quickly drops below 0.1.
In general, the CV is highest in zones close to modeled faults of shallow depths, as they result in a higher spatial hazard gradient compared to areas where hazard is dominated by rather regularly distributed gridded seismicity. A reasonable assumption is that location uncertainty can be particularly high in such zones.
3.2.2 Dependence on return period
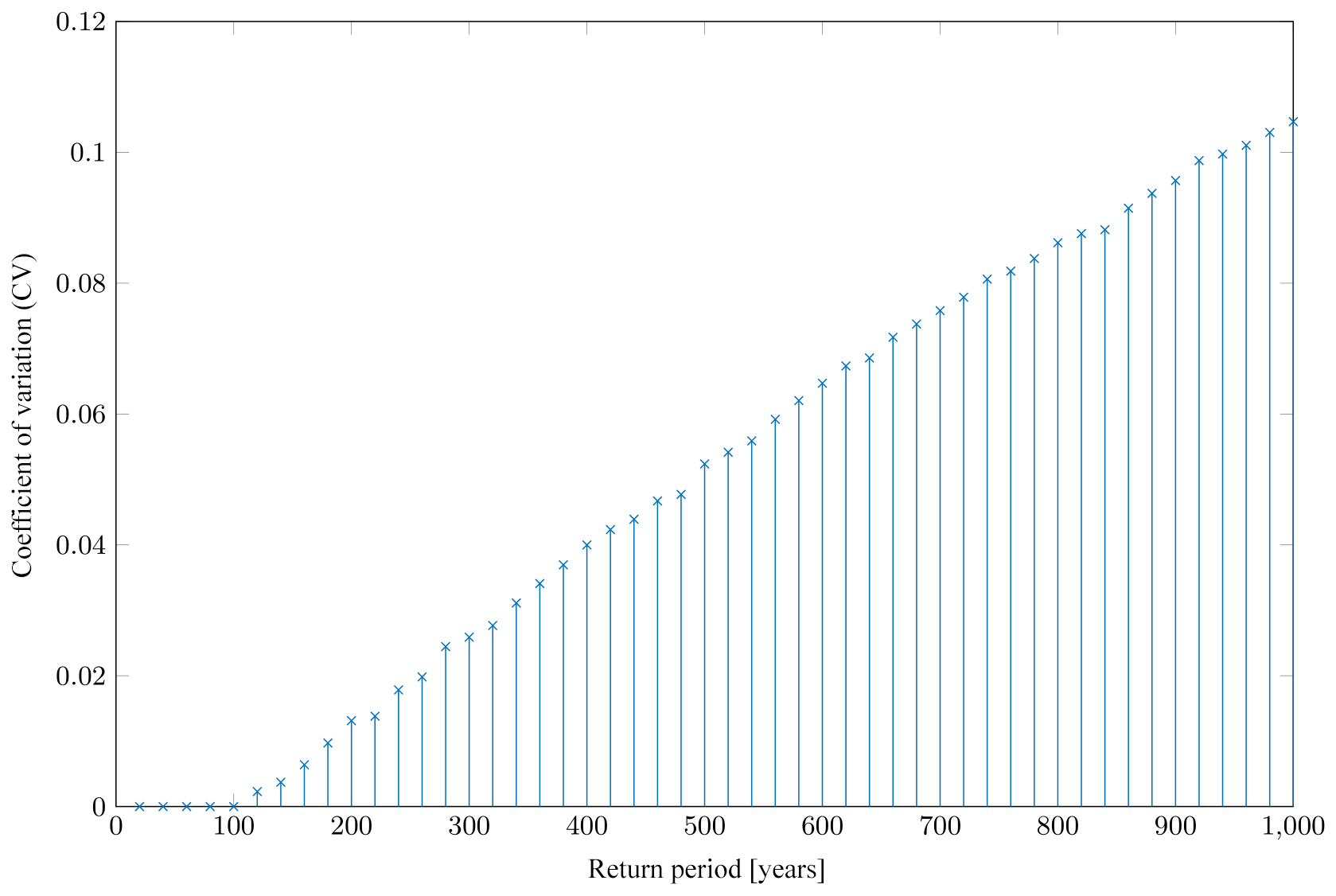
Analysis of the CV across different return periods for individual zones revealed a similar pattern for most administrative zones. The CV is small for short return periods and reaches a relatively stable level above a certain return period. An example of this behavior is shown in Fig. 5 for the province of Jambi. However, the CV does not show this pattern in all administrative zones. For some zones, especially at the level of regencies and cities, we could not determine a range of return periods for which the CV is roughly constant, as for example in the province of Kalimantan Timur shown in Fig. 6.

Figure 5Coefficient of variation (CV) of ground motion predicted to be exceeded at various return periods for the Jambi province (see Fig. 3). The CV remains quite stable over a large range of return periods.
3.3 Loss rate variation
The variability of the CV over return periods for certain zones makes it difficult to choose a general return period suitable for assessing the spatial variation in hazard inside a zone. To avoid the subjectivity introduced by a manual decision process for a suitable return period, we use the CV of the loss rate per zone, as it considers all return periods. Figure 7 shows the CV of the loss rate for Indonesian provinces. The overall pattern agrees with the pattern of the spatial hazard variation in Fig. 3, but the range of values is much higher, from about 0.1 to 0.9.
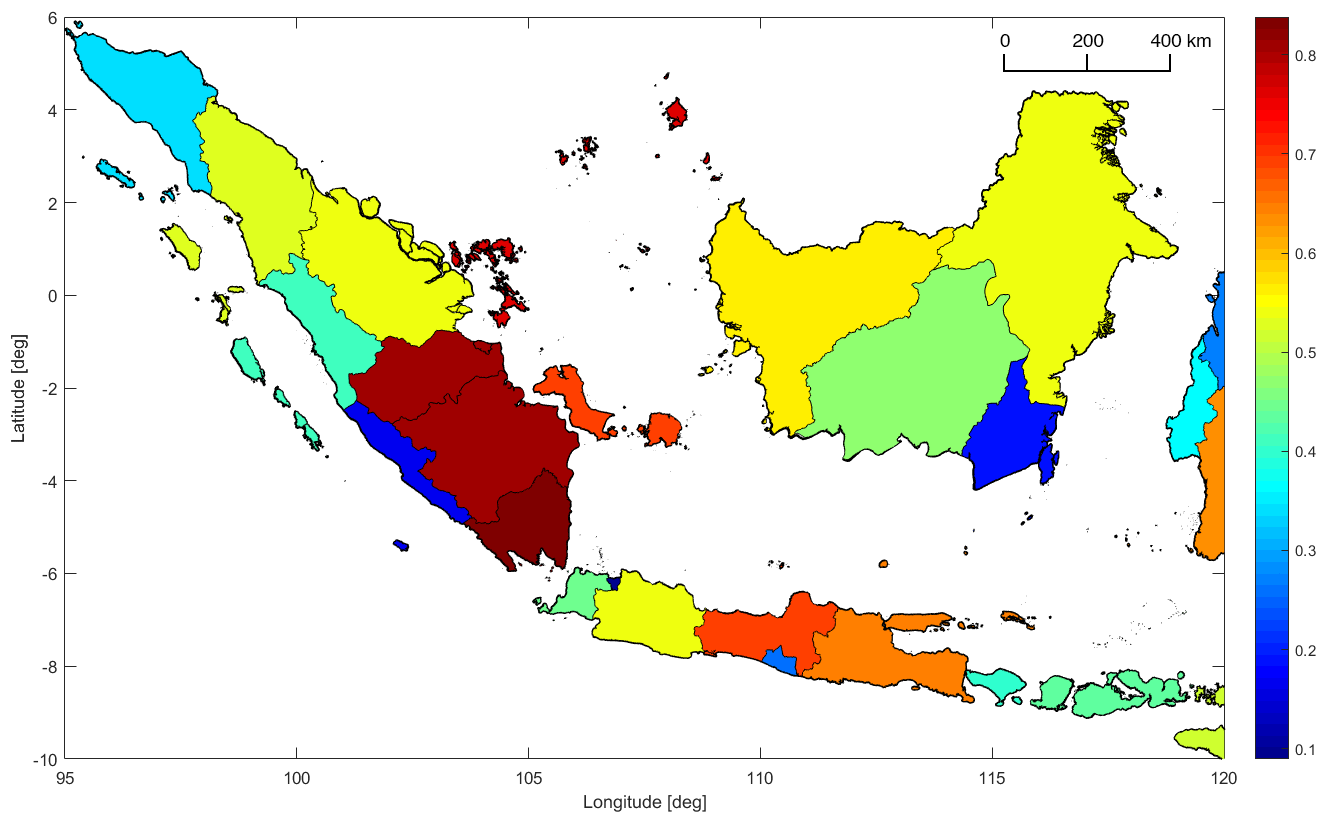
Figure 7Coefficient of variation (CV) of the loss rate inside provinces in western Indonesia. Color denotes the CV.
To increase efficiency, in our framework ground motion is jointly simulated on all unique locations of all sampled location sets. Since the computation of hazard dominates the overall run time of PSRA, it is worthwhile to explore possibilities to distribute the number of locations at which hazard is computed in a smart way among risk items. To this end, we introduce three sampling criteria to determine the location sample size individually per risk item. A large location sample size is used for risk items for which all three criterions indicate that location uncertainty has a strong influence. If any of the three criteria predict that the location uncertainty has a lesser effect, a smaller sample size is used. In this way, more computational effort is invested where it is important, and a better estimation of the PML curve associated with a lower variance is obtained for a given number of used hazard locations. To not add noticeable overhead to the calculation, a key requirement is that all criteria can be evaluated very efficiently. To keep the computational overhead small, another design goal is that the framework is adaptive in a sense that it depends directly on properties of the portfolio and a precalculated hazard variability (see Sect. 3) but does not require on-the-fly integral presampling, such as the one used by certain general purpose adaptive variance reduction schemes (Press and Farrar, 1990; Jadach, 2003).
4.1 Risk location index mapping table
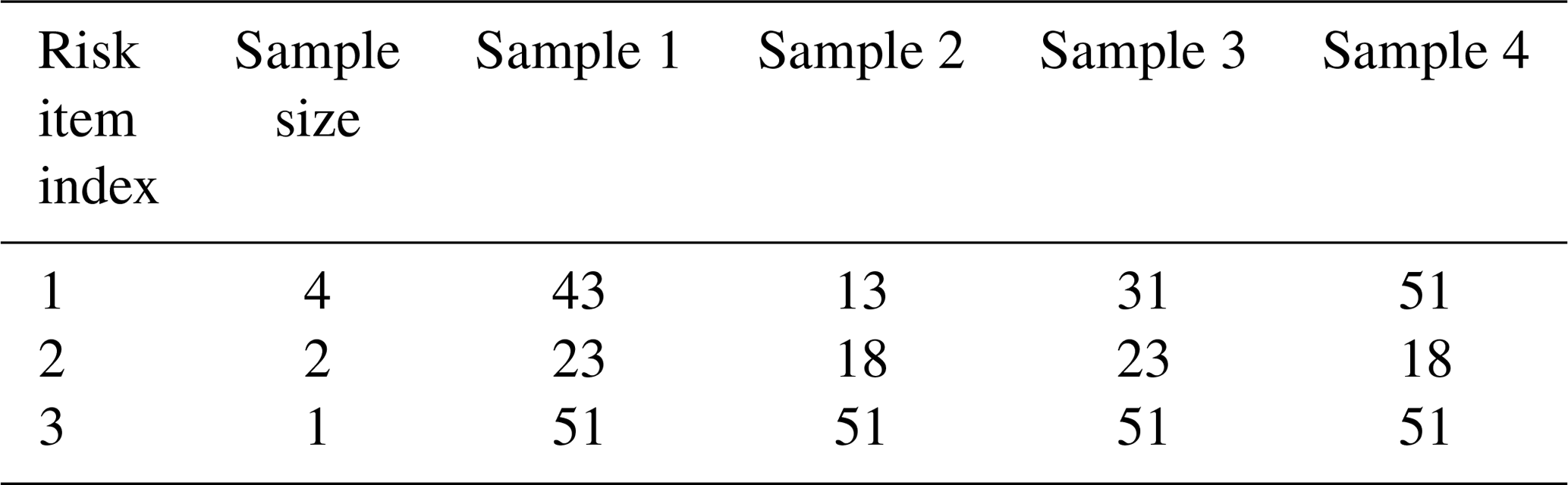
We store an array containing all unique geographical locations at which ground motion is simulated and another array with the sampled location indices per risk item. Table 2 illustrates the concept. Each column of the table corresponds to a location set representing a valid realization of location uncertainty for the entire portfolio. To combine unequal sample sizes for risk items without introducing bias due to overemphasis of a subset of a sample, we restrict the sample size to powers of 2. The full sample can then be repeated in the mapping table.
Table 2Risk location index mapping table. Rows correspond to individual risk items, showing sampled grid point indices. Each column represents a possible spatial distribution of the portfolio. Risk item 1 has the maximum location sample size of nmax=4, but risk items 2 and 3 only have a sample size of 2 and 1, respectively.
4.2 Criterion I: coefficient of variation of loss rate
The first criterion is based on the CV of loss rate within a zone (see Sect. 3), hereafter denoted by CVz. The values of CVz can be precomputed for all administrative geographical zones, and therefore the evaluation of this criterion can be implemented in a very efficient manner.
The number of samples nL due to criterion I is defined piecewise.
Here, tl and tu are the lower and upper threshold values. nmax represents the maximum used sample size. We round up to the next higher power of 2 to obtain the final nL. The criterion is shown in Fig. 8 for the example tl=0.1, tu=0.4, and nmax=16. In our final implementation, tl and tu are chosen adaptively as empirical quantiles of the CV distribution (CV0.4 for tl and CV0.6 for tu, i.e., the 40 % and 60 % percentiles) of the loss rate of all administrative zones of a model (see Sect. 3), which was found to be a reasonable choice for our test cases with the aid of an extensive parameter study (see Sect. 5.1).

Figure 8Criterion I: number of samples per zone depending on coefficient of variation. The discrete realization of the criterion (limited to powers of 2) is shown in blue, while the red line represents the theoretical linear behavior.
4.3 Criterion II: number of risk items
The second criterion involves two steps. The first step defines a maximum sample size for the entire portfolio depending on the total number of risk items nr in the portfolio and a threshold tp as
which is then used to obtain a maximum sample size per zone, depending on the number of risk items in a zone nz and a threshold tz:
We round up to the next higher power of 2 to obtain the final nR. Figures 9 and 10 illustrate this criterion for tp=10 000, tz=100, and nmax=16. In this study, tp is chosen to be 10 000, and tz is set adaptively to equal the number of grid points of the weighted location uncertainty sampling grid (see Sect. 2.2) inside each administrative zone. The design of this criterion is based on the results of a previous study, in which we systematically investigated the effect of location uncertainty and loss aggregation due to spatial clustering of risk items for a large range of different portfolios. It was found that location uncertainty typically has a neglectable effect for very large portfolios and a roughly flat value distribution (Scheingraber and Käser, 2019).
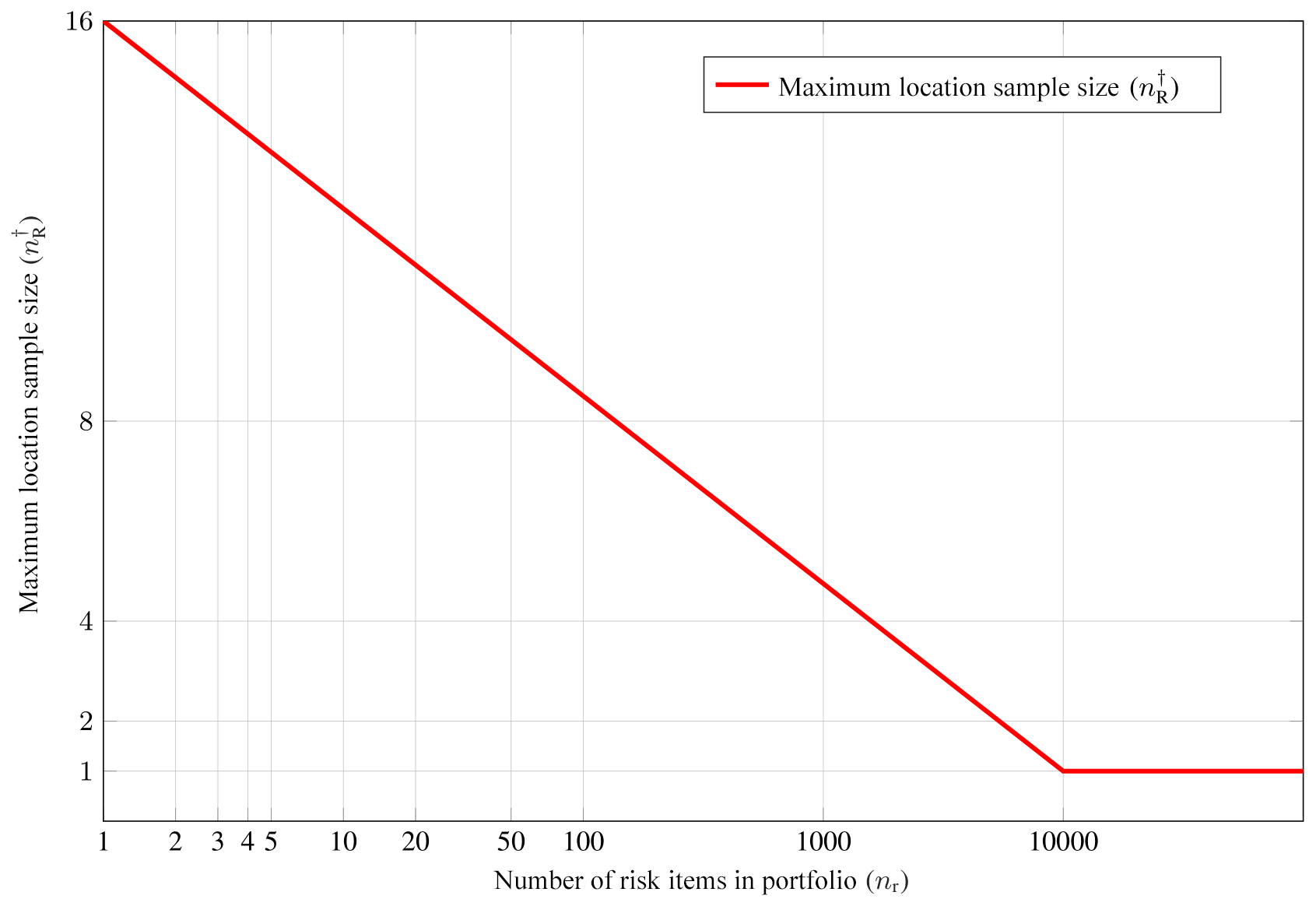
Figure 9Criterion II.a: number of samples per zone depending on the number of risk items in the portfolio. Note that we do not round up to the next higher power of 2, since this plot illustrates Eq. (14), which is an intermediate step.
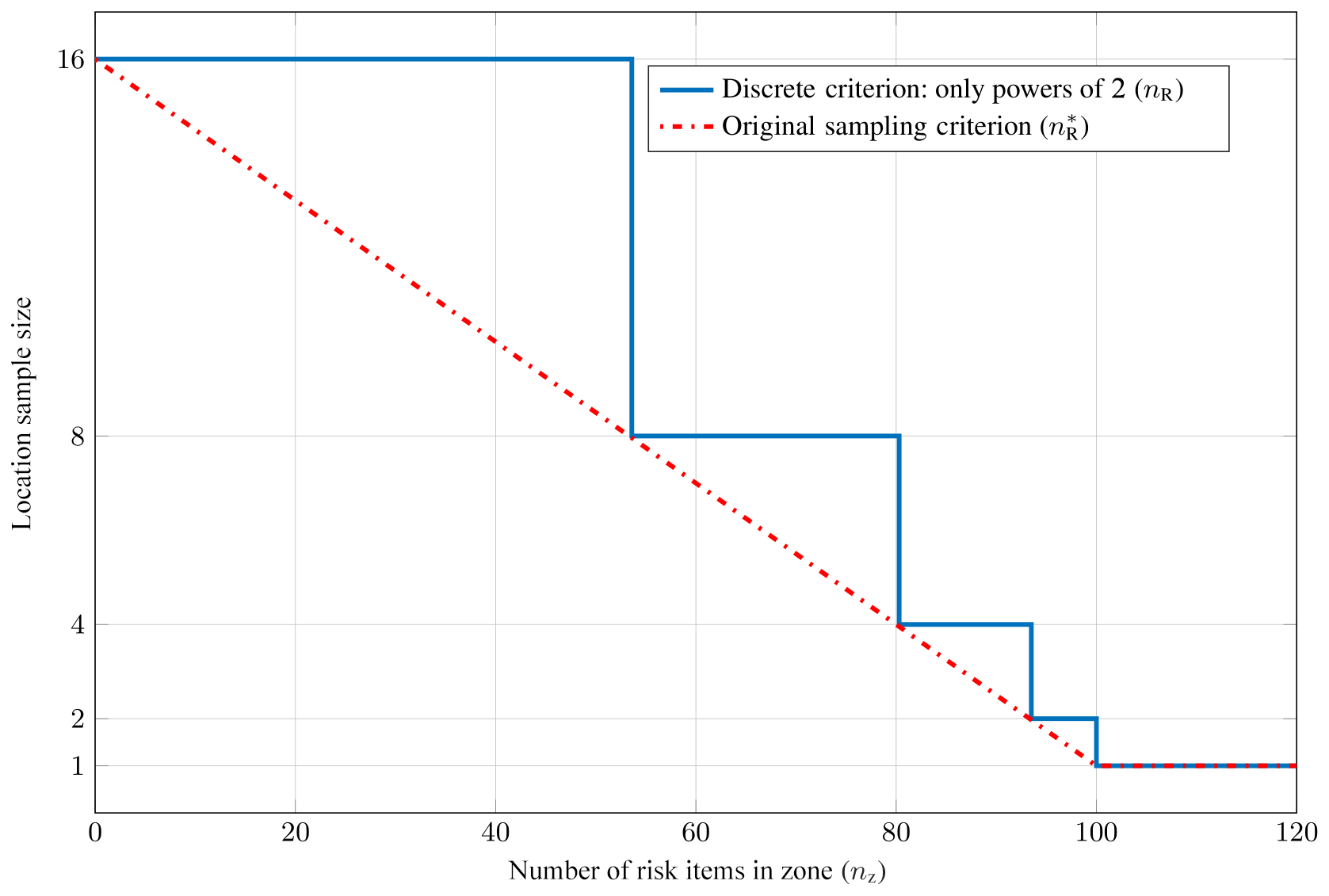
Figure 10Criterion II.b: maximum number of samples per zone depending on the number of risk items in an administrative zone. The discrete realization of the criterion (limited to powers of 2) is shown in blue, while the red line represents the theoretical linear behavior.
4.4 Criterion III: value distribution
The third criterion depends on the relative insured values of risk items (“sum insured”, SI). Risk items are sorted with respect to their SI, and the index of their sorted order Ir is used along with a threshold index ti to determine the maximum sample size per risk item:
We round up to the next higher power of 2 to obtain the final nV. Figure 11 illustrates this criterion for ti=6 and nmax=16. In this study, for ti we adaptively set the index of the first risk item which has a SI higher than the mean of all risk items.

Figure 11Criterion III: number of samples per zone depending on the insured values of the risk items. The discrete realization of the criterion (limited to powers of 2) is shown in blue, while the red line represents the theoretical linear behavior.
4.5 Combination of criteria
The final sample size for a specific risk item is then given by the minimum of the three criteria:
The rationale behind this decision is that any of the criteria can separately predict that a particular risk item has a low impact on loss uncertainty. For example, if a risk item with an unknown coordinate has a low insured value, it has a relatively low impact on loss uncertainty, even if the variation in hazard or loss rate within the corresponding administrative zone is high, and thus a small location uncertainty sample size can be used. Vice versa, the impact of location uncertainty is limited if a risk item with an unknown coordinate has a high insured value but the hazard within the corresponding administrative zone is relatively flat. Furthermore, loss uncertainty is also limited if a portfolio contains a very high number of total risk items or the number of risk items belonging to an administrative zone is high compared to the number of grid points within this zone.
In this section, the variance reduction and speedup obtained with the proposed adaptive location uncertainty sampling scheme are analyzed using the western Indonesia hazard model described in Sect. 3.1 in conjunction with a vulnerability model for regional building stock composition. To this end, loss frequency curves are computed for the synthetic portfolios described in Sect. 2.4 with simple MC as well as the adaptive scheme. The convergence and relative standard errors are evaluated against the number of unique hazard locations used for the loss calculation by either approach, and the associated required run time is compared.
5.1 Spatial variation parameter study
We first analyze the performance of the adaptive sampling scheme for different values of the lower (tl) and upper (tu) threshold parameters for the spatial variation in loss rate in an administrative zone in comparison to simple sampling. In simple MC, all risk items get the same location uncertainty sample size nmax and there is no restriction to powers of 2. For this parameter, we use values of nmax=32, 64, 96, 128, 160, 192, 224, and 256 in order to obtain a smooth curve with a high number of support points.
For the adaptive variance reduction scheme, the sample size is restricted to powers of 2 and is determined for each risk item individually – potentially smaller than the maximum allowed location uncertainty sample size nmax (see Sect. 4 and Table 2). Since the sample size varies between risk items, for a meaningful comparison with simple MC it is necessary to use a measure of the total effort spent for the treatment of location uncertainty of all risk items. We use the total number of unique hazard locations (nhazard) and the run time spent for the computation of hazard (thazard). While for simple MC all risk items get the maximum sample size nmax, the adaptive location sampling scheme reduces the sample size for risk items for which location uncertainty likely has a smaller influence. This means that the adaptive location sampling scheme results in a smaller nhazard than simple MC for the same portfolio and nmax. Therefore, in order to obtain comparable values for nhazard, a larger maximum sample size nmax has to be employed for the adaptive scheme than for simple MC. Here, we use nmax=2i with i=5, 6, …, 8.
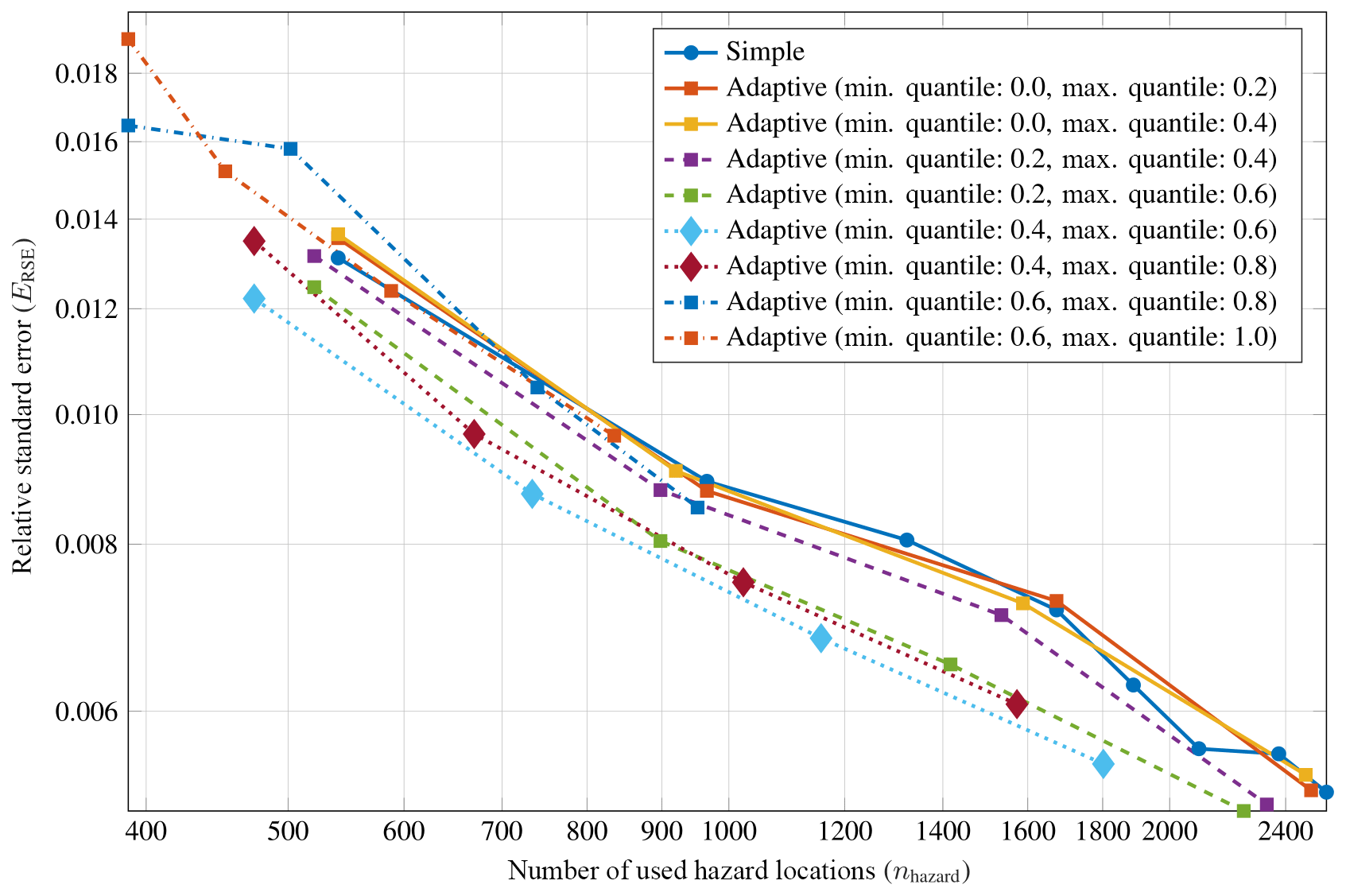
Figure 12Results of a systematic parameter study with the goal of finding good values for the lower threshold (tl) and upper threshold (tu) parameters of criterion I of the adaptive location uncertainty sampling scheme (see Sect. 4), based on the distribution of the coefficient of variation (CV) of loss rate in administrative zones. This shows a logarithmic plot of relative standard error (ERSE) of probable maximum loss (PML) at a return period of 100 years against the number of used hazard locations (nhazard) for a portfolio of 20 risk items with 100 % unknown coordinates. Color indicates different combinations for the threshold parameters tl and tu. Quantiles of the CV distribution around in combination with work best.
For each sample size, the spatial variation threshold parameters are varied over the distribution of CV values, picking quantiles in constant steps of 0.2. The lower threshold tl is varied from CV0.0 to CV0.8, and the upper threshold tu is varied from CV0.2 to CV1.0. For each combination of tl and tu, R=20 repeated simulations were performed for each sample size to estimate the respective relative standard error ERSE.
In general, for our test cases the scheme works well around in combination with . For example, for a portfolio of 20 risk items and 100 % unknown coordinates, Fig. 12 shows a logarithmic plot of the relative standard error ERSE of PML at a return period of 100 years against the number of used hazard locations nhazard for some combinations of tl and tu. The error curves for all combinations of tl and tu have the same slope as the curve for simple MC and thus the same convergence order of 𝒪(n−0.5). For certain combinations, the error curve is below the curve for simple MC, meaning that in these cases the scheme successfully reduces the variance of the estimation and therefore the associated standard error.
For the final implementation, we used tl=CV0.4 and tu=CV0.6, which performed best in this parametric study.
5.2 Performance of the final implementation
We now evaluate the performance of the final implementation of the adaptive scheme, checking if it results in any unwanted systematic bias and investigating variance reduction and speedup for the calculation of PML for different portfolios.
5.2.1 Convergence and bias
Figures 13 and 14 show convergence plots of PML at a 100-year return period against the number of used hazard locations nhazard for portfolios with nr=10 and nr=100 risk items, respectively. Panels (a) depict the results for portfolios with 60 % unknown coordinates, and panels (b) show the results for portfolios with 100 % unknown coordinates. Simple sampling is shown in blue, and the adaptive scheme is shown in red. For all portfolios, the sample size n was varied as n=2i with i=3, 4, …, 9. For each sample size and both sampling schemes, R=20 repeated simulations are shown as semitransparent circles, with solid lines highlighting one individual repetition.

Figure 13Convergence plots showing relative probable maximum loss (PML) at a return period of 100 years against the number of used hazard locations nhazard for portfolios of nr=10 risk items with 60 % (a) and 100 % (b) unknown coordinates using simple MC (shown in blue) as well as the adaptive scheme (shown in red). Semitransparent circles depict R=20 repeated simulations for each sample size, and solid lines highlight one repetition. The transparently shaded background shows the entire range for each sampling scheme. The plots show that the adaptive scheme scatters less and converges faster to the same result than simple sampling.
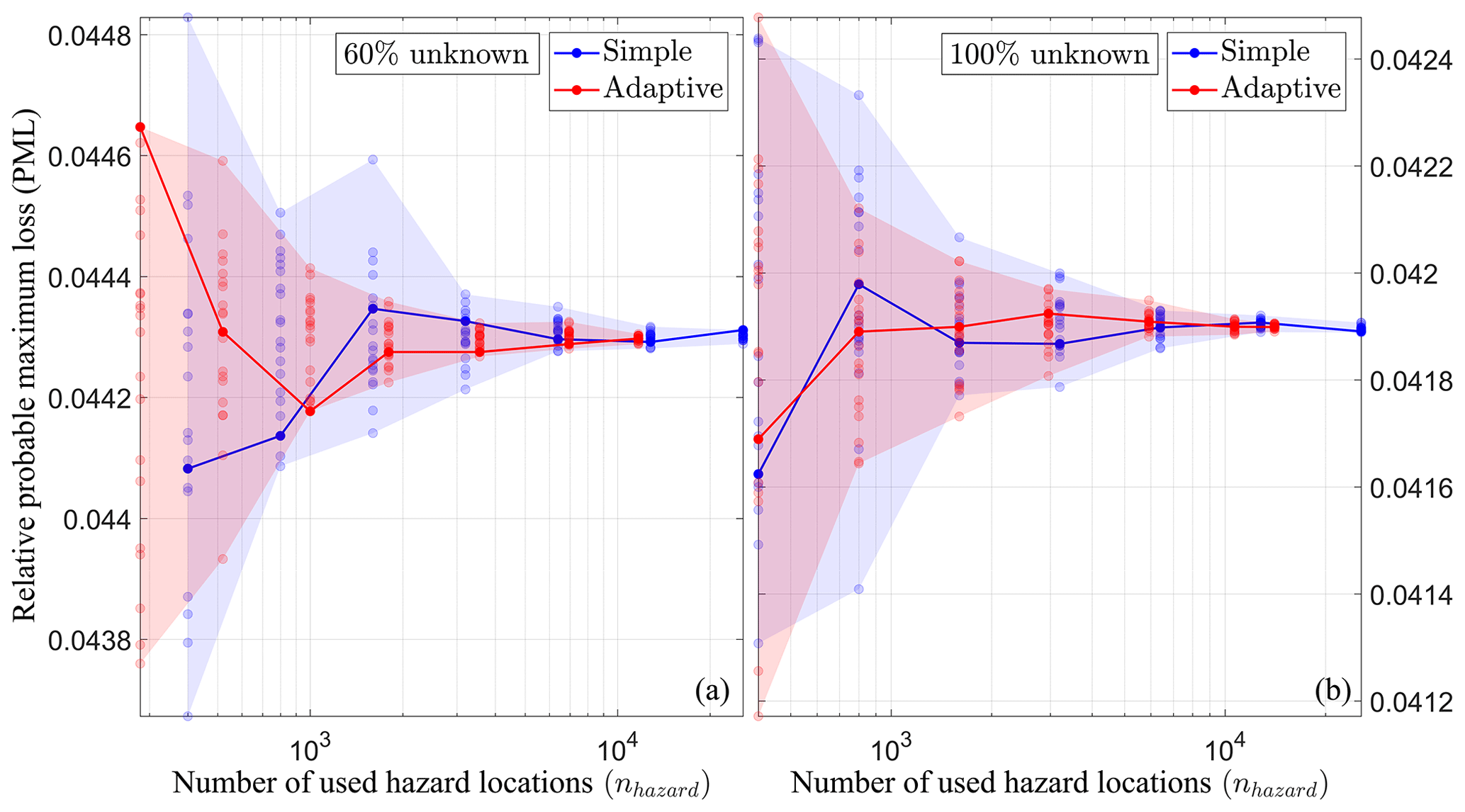
Figure 14Convergence plots showing relative probable maximum loss (PML) at a return period of 100 years against the number of used hazard locations nhazard for portfolios of nr=100 risk items with 60 % (a) and 100 % (b) unknown coordinates using simple MC (shown in blue) as well as the adaptive scheme (shown in red). Semitransparent circles depict R=20 repeated simulations for each sample size, and solid lines highlight one repetition. The transparently shaded background shows the entire range for each sampling scheme. The plots show that the adaptive scheme scatters less and converges faster to the same result than simple sampling.
The results show that empirically the adaptive scheme converges to the same result as simple MC for our test cases, meaning that the scheme does not result in any systematic bias. It is also apparent that for a given number of used hazard locations nhazard, the relative PML values obtained with the adaptive scheme scatter less than those estimated with simple MC.
5.2.2 Variance reduction and speedup
For the same portfolios, as analyzed in the previous section, Fig. 15 shows logarithmic plots of the relative standard error ERSE obtained from R=20 repeated simulations against the number of used hazard locations nhazard. Vertical bars depict upper 95 % confidence intervals estimated using bootstrapping with 1000 resamples. Simple MC is again shown in blue, and the variance reduction sampling scheme is shown in red. While the observed error convergence order of the adaptive scheme remains the same as for simple MC (i.e., 𝒪(n−0.5); compare Sect. 5.1), the error curves are below those for simple MC for all portfolios.
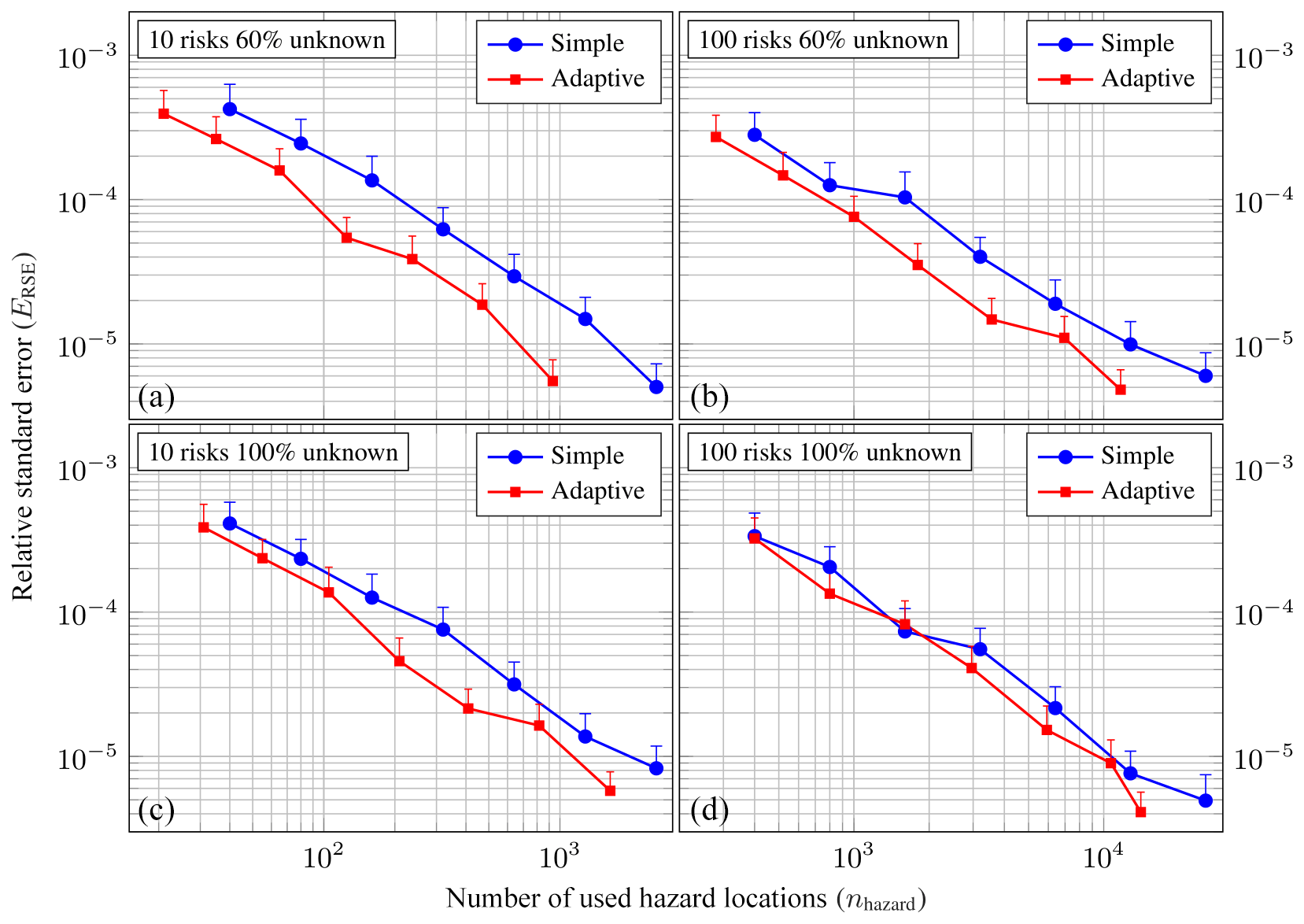
Figure 15Logarithmic plot of relative standard errors ERSE of probable maximum loss (PML) at a return period of 100 years against the total number of used hazard locations nhazard for different portfolios with nr=10 (a, c) and nr=100 (b, d) risk items and 60 % (a, b) and 100% (c, d) unknown coordinates. Simple MC is shown in blue, and the adaptive variance reduction scheme is shown in red. All ERSE values have been obtained from R=20 repeated simulations; vertical error bars depict upper 95 % confidence intervals estimated using bootstrapping with 1000 resamples.
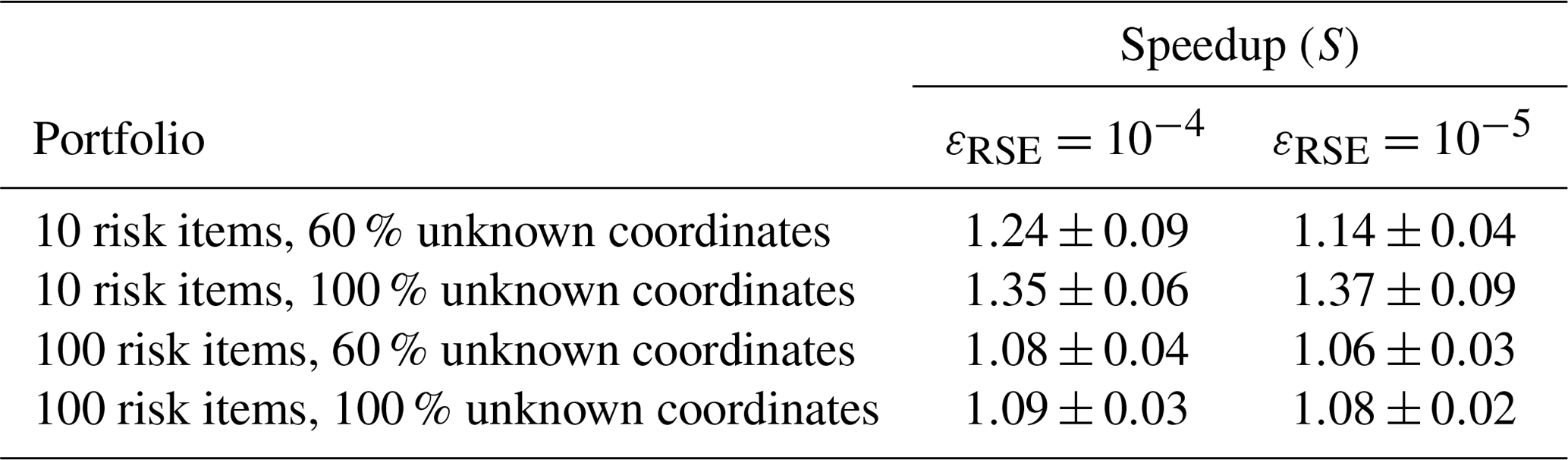
Table 3Mean run time speedup and standard errors (S±ESE) of the hazard computation achieved by the adaptive location uncertainty sampling scheme in comparison to simple sampling to obtain relative standard error levels of and , estimated from R=20 repeated simulations. Depending on the portfolio and εRSE, the mean speedup ranges from 6 % to 37 %.
The variance reduction quotient (VR, the ratio of the variances in the estimations obtained using simple MC to those of the adaptive scheme; see Eq. 7) varies between portfolios with different numbers of risk items and fractions of unknown coordinates but generally increases with growing nhazard. For example, for the portfolio with 10 risk items and 60 % unknown coordinates, VR is about 6.2 at nhazard=102 and increases to 13.2 at nhazard=103. For the portfolio with 10 risk items and 100% unknown coordinates, VR≈1.8 at nhazard=102 and 2.2 at nhazard=103. For the portfolios with 100 risk items, the situation is similar. For 60 % unknown coordinates, VR≈2.4 at nhazard=103 and 3.7 at nhazard=104. For 100 % unknown coordinates, VR≈1.7 at nhazard=103 and 3.0 at nhazard=104.
The obtained variance reduction partially leads to a speedup of the computational run time to reach a specific relative standard error level εRSE. Table 3 shows the speedup S of the scheme to reach relative standard error levels of and for the same portfolios. Depending on the portfolio, the scheme achieves a speedup between 8 % and 35 % to reach and between 6 % and 37 % to reach . Note that we obtained these speedup values using a highly optimized seismic hazard and risk analysis framework. We suspect that the scheme can result in a significantly higher speedup for less optimized code, especially if the hazard simulation is not vectorized but contains a loop over locations.
Seismic risk assessment is associated with a large range of deep uncertainties. For example, the exact location of risks is often unknown due to geocoding issues of address information. In order to provide a holistic view of risk and to be able to communicate the effect of uncertainty effectively to decision makers, all model uncertainties need to be treated. Therefore, in this paper we propose a novel adaptive sampling strategy to efficiently treat this location uncertainty using a seismic hazard and risk model for western Indonesia. The adaptive scheme considers three criteria to decide how often an unknown risk coordinate has to be sampled within a known administrative zone: (1) the loss rate variation within the zone, (2) the number of risks within the zone, and (3) the individual value of the risk. As the variation in hazard can vary quite strongly not only between different administrative geographical zones but also between different return periods, we use the spatial variation in loss rate which displays a similar pattern as the variation in hazard but is independent of the return period. Furthermore, the total number of risks in the corresponding administrative zone and the value (importance) of the risk with respect to the entire portfolio are considered by the adaptive scheme.
We investigated the performance of the scheme for a large range of sample sizes using different synthetic portfolios of different levels of unknown risk locations. We have found that the scheme successfully reduces the expected error; i.e., it reaches the same error levels as simple Monte Carlo with fewer samples of potential risk locations. This results in lower memory requirements and a moderate but appreciable run time speedup to reach a desired level of reliability when computing loss frequency curves – a critical measure of risk in the insurance industry. The scheme helps to obtain a holistic view of risk including the associated uncertainties and could also be applied to other natural hazards, such as probabilistic wind and flood models. This should help to avoid blind trust in probabilistic risk assessment.
While the proposed scheme already successfully reduces the variance of loss frequency curve estimations, future improvements in the treatment of uncertainty in PSRA are conceivable and necessary. The effect of modeling assumptions and the often poor data quality need to be investigated further. The computation might become yet more efficient by the application of variance reduction techniques to other uncertainties, for example in the ground motion and vulnerability models. Moreover, it would be essential to investigate the relative importance of location uncertainty in comparison to these other uncertainty types.
The hazard model used for this work is based on the publicly available United States Geological Survey (USGS) Southeast Asia seismic hazard model by Petersen et al. (2007), as described in Sect. 3.1. The seismic risk model and analysis software used for this work is proprietary and not publicly available.
CS implemented the location uncertainty sampling schema, analyzed the seismic hazard variation and sampling schema performance, and wrote the paper. MK conceptualized the sampling methodology, provided guidance for the analysis and for writing the paper, and revised the paper.
This work has been supported by a scholarship provided by Munich Re to the first author, who has worked on the project in the course of his doctoral studies at Ludwig Maximilian University of Munich. The second author works as senior seismic risk modeler at Munich Re and is a professor at Ludwig Maximilian University of Munich. Munich Re sells reinsurance products and services based on PSHA and PSRA and therefore has a high interest in modeling the inherent uncertainties within these methods, but they did not influence the results of this study in any way.
This work was supported by a scholarship provided to the first author by Munich Re. We thank the reviewers for their insightful comments, which helped to considerably improve the original manuscript.
This paper was edited by Filippos Vallianatos and reviewed by Gerasimos Papadopoulos, Robert J. Geller, and two anonymous referees.
Atkinson, G. M. and Boore, D. M.: Empirical ground-motion relations for subduction-zone earthquakes and their application to Cascadia and other regions, Bull. Seismol. Soc. Am., 93, 1703–1729, https://doi.org/10.1785/0120080108, 2003. a
Bal, I. E., Bommer, J. J., Stafford, P. J., Crowley, H., and Pinho, R.: The influence of geographical resolution of urban exposure data in an earthquake loss model for Istanbul, Earthq. Spectra, 26, 619–634, https://doi.org/10.1193/1.3459127, 2010. a
Bender, B. and Perkins, D. M.: SEISRISK III: a computer program for seismic hazard estimation, Bulletin, United States Geological Survey, Reston, Virgina, USA, 1772–1820, https://doi.org/10.3133/b1772, 1987. a
Bier, V. M. and Lin, S. W.: On the treatment of uncertainty and variability in making decisions about risk, Risk Anal., 33, 1899–1907, https://doi.org/10.1111/risa.12071, 2013. a
Boore, D. M. and Atkinson, G. M.: Ground-motion prediction equations for the average horizontal component of PGA, PGV, and 5 %-damped PSA at spectral periods between 0.01 s and 10.0 s, Earthq. Spectra, 24, 99–138, https://doi.org/10.1193/1.2830434, 2008. a
Campbell, K. W. and Bozorgnia, Y.: NGA ground motion model for the geometric mean horizontal component of PGA, PGV, PGD and 5 % damped linear elastic response spectra for periods ranging from 0.01 to 10 s, Earthq. Spectra, 24, 139–171, https://doi.org/10.1193/1.2857546, 2008. a
Chiou, B. S.-J. and Youngs, R. R.: An NGA model for the average horizontal component of peak ground motion and response spectra, Earthq. Spectra, 24, 173–215, https://doi.org/10.1193/1.2894832, 2008. a
Cornell, C. A.: Engineering seismic risk analysis, Bull. Seismol. Soc. Am., 58, 1583–1606, 1968. a
Cox, L. A.: Confronting deep uncertainties in risk analysis, Risk Anal., 32, 1607–1629, https://doi.org/10.1111/j.1539-6924.2012.01792.x, 2012. a
Crowley, H.: Earthquake Risk Assessment: Present Shortcomings and future directions, Geotech. Geolog. Earthq. Eng., 34, 515–532, https://doi.org/10.1007/978-3-319-07118-3_16, 2014. a
Crowley, H., Pinho, R., Pagani, M., and Keller, N.: Assessing global earthquake risks: the Global Earthquake Model (GEM) initiative, in: Handbook of Seismic Risk Analysis and Management of Civil Infrastructure Systems, Woodhead Publishing Limited, Sawston, Cambridge, UK, 815–838, https://doi.org/10.1533/9780857098986.5.815, 2013. a
Dobson, J. E., Bright, E. A., Coleman, P. R., Durfee, R. C., and Worley, B. A.: LandScan: a global population database for estimating populations at risk, Photogram. Eng. Remote Sens., 66, 849–857, 2000. a
dos Santos, K. and Beck, A.: A benchmark study on intelligent sampling techniques in Monte Carlo simulation, Lat. Am. J. Solids Struct., 12, 624–648, https://doi.org/10.1590/1679-78251245, 2015. a
Eads, L., Miranda, E., Krawinkler, H., and Lignos, D. G.: An efficient method for estimating the collapse risk of structures in seismic regions, Earthq. Eng. Struct. Dynam., 42, 25–41, https://doi.org/10.1002/eqe.2191, 2013. a
Efron, B.: Bootstrap methods: another look at the Jackknife, Ann. Stat., 7, 1–26, https://doi.org/10.1214/aos/1176344552, 1979. a
Efron, B. and Tibshirani, R.: Bootstrap methods for standard errors, confidence intervals, and other measures of statistical accuracy, Stat. Sci., 1, 54–75, 1986. a
Foulser-Piggott, R., Bowman, G., and Hughes, M.: A framework for understanding uncertainty in seismic risk assessment, Risk Anal., 40, 169–182, 2020. a
Gaughan, A. E., Stevens, F. R., Linard, C., Jia, P., and Tatem, A. J.: High resolution population distribution maps for Southeast Asia in 2010 and 2015, PLoS ONE, 8, e55882, https://doi.org/10.1371/journal.pone.0055882, 2015. a
Goda, K. and Ren, J.: Assessment of seismic loss dependence using copula, Risk Anal., 30, 1076–1091, https://doi.org/10.1111/j.1539-6924.2010.01408.x, 2010. a
Harding, B., Tremblay, C., and Cousineau, D.: Standard errors: A review and evaluation of standard error estimators using Monte Carlo simulations, Quant. Meth. Psychol., 10, 107–123, https://doi.org/10.20982/tqmp.10.2.p107, 2014. a
Hayes, G. P., Wald, D. J., and Johnson, R. L.: Slab1.0: A three-dimensional model of global subduction zone geometries, J. Geophys. Res., 117, B01302, https://doi.org/10.1029/2011JB008524, 2012. a
Hess, S., Train, K. E., and Polak, J. W.: On the use of a Modified Latin Hypercube Sampling (MLHS) method in the estimation of a mixed logit model for vehicle choice, Transport. Res. Pt. B, 40, 147–163, https://doi.org/10.1016/j.trb.2004.10.005, 2006. a
Jadach, S.: Foam: A general-purpose cellular Monte Carlo event generator, Comput. Phys. Commun., 152, 55–100, https://doi.org/10.1016/S0010-4655(02)00755-5, 2003. a
Jayaram, N. and Baker, J. W.: Efficient sampling and data reduction techniques for probabilistic seismic lifeline risk assessment, Earthq. Eng. Struct. Dynam., 39, 1109–1131, https://doi.org/10.1002/eqe.988, 2010. a
Juneja, S. and Kalra, H.: Variance reduction techniques for pricing American options using function approximations, J. Comput. Finance, 12, 79–101, https://doi.org/10.21314/JCF.2009.208, 2009. a
Kleist, L., Thieken, A. H., Köhler, P., Müller, M., Seifert, I., Borst, D., and Werner, U.: Estimation of the regional stock of residential buildings as a basis for a comparative risk assessment in Germany, Nat. Hazards Earth Syst. Sci., 6, 541–552, https://doi.org/10.5194/nhess-6-541-2006, 2006. a
Knuth, D. E.: Big Omicron and big Omega and big Theta, ACM SIGACT News, 8, 18–24, https://doi.org/10.1145/1008328.1008329, 1976. a
Landau, E.: Handbuch der Lehre von der Verteilung der Primzahlen, in: vol. 1, B. G. Teubner, Leipzig, 1909. a
L'Ecuyer, P.: Good parameters and implementations for combined multiple recursive random number generators, Operat. Res., 47, 159–164, https://doi.org/10.1287/opre.47.1.159, 1999. a
MacKay, D. J. C.: Information theory, inference, and learning algorithms, in: vol. 100, Cambridge University Press, Cambridge, https://doi.org/10.1198/jasa.2005.s54, 2005. a
McGuire, R. K.: Seismic hazard and risk analysis, 1st Edn., Earthquake Engineering Research Institute, Oakland, California, USA, 2004. a
Mualchin, L.: History of modern earthquake hazard mapping and assessment in California using a deterministic or scenario approach, Pure Appl. Geophys., 168, 383–407, 2011. a
Okada, T., McAneney, K. J., and Chen, K.: Estimating insured residential losses from large flood scenarios on the Tone River, Japan – a data integration approach, Nat. Hazards Earth Syst. Sci., 11, 3373–3382, https://doi.org/10.5194/nhess-11-3373-2011, 2011. a
Pagani, M., Monelli, D., Weatherill, G., Danciu, L., Crowley, H., Silva, V., Henshaw, P., Butler, L., Nastasi, M., Panzeri, L., Simionato, M., and Vigano, D.: OpenQuake engine: An open hazard (and risk) software for the Global Earthquake Model, Seismol. Res. Lett., 85, 692–702, https://doi.org/10.1785/0220130087, 2014. a, b
Papadopoulou-Vrynioti, K., Bathrellos, G. D., Skilodimou, H. D., Kaviris, G., and Makropoulos, K.: Karst collapse susceptibility mapping considering peak ground acceleration in a rapidly growing urban area, Eng. Geol., 158, 77–88, 2013. a
Papageorgiou, A.: Sufficient conditions for fast quasi-Monte Carlo convergence, J. Complex., 19, 332–351, https://doi.org/10.1016/S0885-064X(02)00004-3, 2003. a
Pavlou, K., Kaviris, G., Chousianitis, K., Drakatos, G., Kouskouna, V., and Makropoulos, K.: Seismic hazard assessment in Polyphyto Dam area (NW Greece) and its relation with the “unexpected” earthquake of 13 May 1995 (Ms=6.5, NW Greece), Nat. Hazards Earth Syst. Sci., 13, 141–149, https://doi.org/10.5194/nhess-13-141-2013, 2013. a
Petersen, M., Harmsen, S., Mueller, C., Haller, K., Dewey, J., Luco, N., Crone, A., Lidke, D., and Rukstales, K.: Documentation for the Southeast Asia seismic hazard maps, USGS Administrative Report, USGS, Reston, Virgina, USA, 2007. a, b, c
Press, W. and Farrar, G.: Recursive stratified sampling for multidimensional Monte Carlo integration, Comput. Phys., 4, 190–195, 1990. a
Robert, C. P. and Casella, G.: Monte Carlo statistical methods, in: Springer Texts in Statistics, Springer, New York, https://doi.org/10.1007/978-1-4757-4145-2, 2004. a
Scheingraber, C. and Käser, M.: The Impact of Portfolio Location Uncertainty on Probabilistic Seismic Risk Analysis, Risk Anal., 39, 695–712, https://doi.org/10.1111/risa.13176, 2019. a, b, c, d
Senior Seismic Hazard Committee: Recommendations for probabilistic seismic hazard analysis: Guidance on uncertainty and use of experts, NUREG/CR-6372, Livermore, California, USA, 1997. a
Storchak, D. A., Di Giacomo, D., Bondár, I., Engdahl, E. R., Harris, J., Lee, W. H. K., Villaseñor, A., and Bormann, P.: Public release of the ISC–GEM global instrumental earthquake catalogue (1900–2009), Seismol. Res. Lett., 84, 810–815, https://doi.org/10.1785/0220130034, 2013. a
Tesfamariam, S., Sadiq, R., and Najjaran, H.: Decision making under uncertainty – an example for seismic risk management, Risk Anal., 30, 78–94, https://doi.org/10.1111/j.1539-6924.2009.01331.x, 2010. a
Toro, G. R., Abrahamson, N. A., and Schneider, J. F.: Model of strong ground motions from earthquakes in Central and Eastern North America: best estimates and uncertainties, Seismol. Res. Lett., 68, 41–57, https://doi.org/10.1785/gssrl.68.1.41, 1997. a
Tsapanos, T. M., Koravos, G. C., Zygouri, V., Tsapanos, M. T., Kortsari, A. N., Kijko, A., and Kalogirou, E. E.: Deterministic seismic hazard analysis for the city of Corinth-central Greece, Balkan Geophys. Soc., 14, 1–14, 2011. a
Tyagunov, S., Pittore, M., Wieland, M., Parolai, S., Bindi, D., Fleming, K., and Zschau, J.: Uncertainty and sensitivity analyses in seismic risk assessments on the example of Cologne, Germany, Nat. Hazards Earth Syst. Sci., 14, 1625–1640, https://doi.org/10.5194/nhess-14-1625-2014, 2014. a
Wald, D. J. and Allen, T. I.: Topographic slope as a proxy for seismic site conditions and amplification, Bull. Seismol. Soc. Am., 97, 1379–1395, https://doi.org/10.1785/0120060267, 2007. a
Yang, W.-N. and Nelson, B. L.: Using common random numbers and control variates in multiple-comparison procedures, Operat. Res., 39, 583–591, 1991. a
Youngs, R. R., Chiou, S.-J., Silva, W. J., and Humphrey, J. R.: Strong ground motion attenuation relationships for subduction zone earthquakes, Seismol. Res. Lett., 68, 58–73, https://doi.org/10.1785/gssrl.68.1.58, 1997. a
Zhao, J. X., Zhang, J., Asano, A., Ohno, Y., Oouchi, T., Takahashi, T., Ogawa, H., Irikura, K., Thio, H. K., Somerville, P. G., and Fukushima, Y.: Attenuation relations of strong ground motion in Japan using site classification based on predominant period, Bull. Seismol. Soc. Am., 96, 898–913, https://doi.org/10.1785/0120050122, 2006. a
The period of a pseudo-random number generator refers to the minimum length of a generated sequence before the same random numbers are repeated cyclically.
For simple MC, the strong law of large numbers guarantees an almost certain convergence for n→∞.
See https://hazardwiki.openquake.org/sea2007_intro (last access: 1 July 2020) for results obtained using OpenQuake.
See http://www.emidius.eu/GEH/ (last access: 1 July 2020).