the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 04 Jan 2019
| 04 Jan 2019
A stochastic event-based approach for flood estimation in catchments with mixed rainfall and snowmelt flood regimes
Valeriya Filipova
Deborah Lawrence
Thomas Skaugen
The estimation of extreme floods is associated with high uncertainty, in part due to the limited length of streamflow records. Traditionally, statistical flood frequency analysis and an event-based model (PQRUT) using a single design storm have been applied in Norway. We here propose a stochastic PQRUT model, as an extension of the standard application of the event-based PQRUT model, by considering different combinations of initial conditions, rainfall and snowmelt, from which a distribution of flood peaks can be constructed. The stochastic PQRUT was applied for 20 small- and medium-sized catchments in Norway and the results give good fits to observed peak-over-threshold (POT) series. A sensitivity analysis of the method indicates (a) that the soil saturation level is less important than the rainfall input and the parameters of the PQRUT model for flood peaks with return periods higher than 100 years and (b) that excluding the snow routine can change the seasonality of the flood peaks. Estimates for the 100- and 1000-year return level based on the stochastic PQRUT model are compared with results for (a) statistical frequency analysis and (b) a standard implementation of the event-based PQRUT method. The differences in flood estimates between the stochastic PQRUT and the statistical flood frequency analysis are within 50 % in most catchments. However, the differences between the stochastic PQRUT and the standard implementation of the PQRUT model are much higher, especially in catchments with a snowmelt flood regime.
- Article
(2882 KB) - Full-text XML
- BibTeX
- EndNote





The estimation of low-probability floods is required for the design of high-risk structures such as dams, bridges and levees. For example, floods with a 100-year return period are sometimes required for the design of levees and the design and safety evaluation of high-risk dams requires the estimation of flood hydrographs for the 1000-year return period and, in some cases, floods with magnitudes of up to the probable maximum flood (PMF). An overview of design flood standards for reservoir engineering in different countries is provided in Ren et al. (2017). Flood mapping also usually requires input hydrographs for flood events with return periods of up to 1000 years. Methods for estimating these floods can be generally classified into three groups: (1) statistical flood frequency analysis, (2) the single design event simulation approach and (3) derived flood frequency simulation methods.
At gauged sites, statistical flood frequency analysis involves fitting a distribution function to the annual maxima (AMAX) or peak-over-threshold (POT) flood events and calculating the quantile of interest. When return periods that are longer than the observed record length are needed, the process requires extrapolation of the fitted statistical distribution. This introduces a high degree of uncertainty due to the number of limited observations relative to the estimated quantile (Katz et al., 2002). Significant progress has been made in methods for reducing this uncertainty by incorporating historic or paleo-flood data (Parkes and Demeritt, 2016), where available. Another way to “extend” the hydrological record in order to reduce the uncertainty is to combine data series from several different gauges by identifying pooling groups or hydrologically similar regions, where this is possible. It has been found, however, that the identification of such hydrological regions can be difficult in practice (Nyeko-Ogiramoi et al., 2012). The application of statistical flood frequency analysis in ungauged basins is also problematic. As the physical processes in the catchments are usually not directly considered in the analysis, estimating the flood quantiles in ungauged basins using regression or geostatistical methods can produce average RMSNE (root mean square normalized error) values of between 27 % and 70 % (Salinas et al., 2013), or even higher for the 100-year return period. In addition, the complete hydrograph is often needed in practice. Although multivariate analysis of flood events (e.g. flood peaks, volumes and durations) can be used to generate hydrographs for specific return periods, the methods are not easily applied (Gräler et al., 2013).
The second method for extreme flood estimation is the design event approach in which single realizations of initial conditions and precipitation are used as input in an event-based hydrological model. Another feature of the approach is that, when event-based models are used, a critical duration defined as the duration of the storm that results in the highest peak flow needs to be included. Two advantages of this method over statistical flood frequency analysis are that rainfall records are often widely available (e.g in the form of gridded datasets) and that the event hydrograph is generated in addition to the magnitude of the flood peak. This approach has been traditionally used due to its simplicity (Kjeldsen, 2007; Wilson et al., 2011). However, its application often involves the assumption that the simulated flood event has the same return period as the rainfall used as input in the hydrological model. This assumption is not realistic and, depending on the initial conditions, the return period of the rainfall and the corresponding runoff can differ by orders of magnitude (Salazar et al., 2017). A reason for this is that flood events are often caused by a combination of factors, such as a high degree of soil saturation in the catchment, heavy rainfall and seasonal snowmelt. A joint probability distribution, therefore, needs to be considered if one is to fully describe the relationship between the return period of rainfall and of runoff.
The third possible approach is the derived flood frequency method in which the distribution function of peak flows is derived from the distribution of other random variables such as rainfall depth and duration and different soil moisture states. Although a statistical distribution of flow values or their plotting positions is used to calculate the required quantiles, as in conventional flood frequency analysis, a hydrological model can be used to simulate an unlimited number of discharge values under differing conditions, thus extending and enhancing the observed discharge record. Under very stringent assumptions, the derived distribution can actually be solved analytically by using a simple rainfall-runoff model (e.g. a unit hydrograph), assuming independence between rainfall intensity and duration and considering only a few initial soil moisture states. However, because of these simplifying assumptions, the method can produce poor results (Loukas, 2002). For this reason, methods based on simulation techniques are most often used, and these range from continuous simulations to event-based simulations with Monte Carlo methods.
In the continuous-simulation approach, a stochastic weather generator is used to simulate long synthetic series of rainfall and temperature, which serve as input in a continuous rainfall-runoff model. The resulting long series of simulated discharge is then used to estimate the required return periods, usually using plotting positions (Calver and Lamb, 1995; Camici et al., 2011; Haberlandt and Radtke, 2014). A disadvantage of these methods is that they are computationally demanding, as long continuous periods need to be simulated to estimate the extreme quantiles. Several newer methods, therefore, use a continuous weather generator coupled with an event-based hydrological model. For example, the hybrid-CE (causative event) method uses a continuous rainfall-runoff simulation to determine the inputs to an event-based model (Li et al., 2014). Another disadvantage, however, of continuous-simulation models is that stochastic weather generators require the estimation of a large number of parameters (Beven and Hall, 2014; Onof et al., 2000). In addition, models such as the modified Bartlett–Lewis rectangular pulse model have limited capacity to simulate extreme rainfall depths, which can lead to an underestimation of runoff (Kim et al., 2017). In order to avoid the limitations of continuous weather generators, the semi-continuous method SCHADEX (Paquet et al., 2013) uses a probabilistic model for centred rainfall events (multi-exponential weather-pattern-based distribution; Garavaglia et al., 2010), identified as over threshold values that are larger than the adjacent rainfall values. Using this approach, millions of synthetic rainfall events can be generated, assigned a probability estimated from the MEWP (multi-exponential weather pattern) model and inserted directly into the historic precipitation series to replace observed rainfall events. In this manner, the SCHADEX method is similar to the hybrid-CE methods because a long-term hydrological simulation is used to characterize observed hydrological conditions and synthetic events are only inserted into the precipitation record for periods selected from the observed record. Despite the many advantages of the hybrid-CE and SCHADEX methods over continuous-simulation methods, they nevertheless require sufficient data for the calibration of the hydrological model, for the modelling of the extreme precipitation distribution and for ensuring that an exhaustive range of initial hydrological conditions are sampled during the simulations.
Another method for derived flood frequency analysis is the joint probability approach (Loukas, 2002; Muzik, 1993; Rahman et al., 2002; Svensson et al., 2013). In this approach, the Monte Carlo simulation is used to generate a large set of initial conditions and meteorological variables, which serve as input to an event-based hydrological model. This approach requires that the important variables are first identified and any correlations between the variables are quantified. Most often, the random variables that are considered are related to properties of the rainfall (intensity, duration, frequency) and to the soil moisture deficit. Some of these methods, such as the Stochastic Event Flood Model (SEFM, Schaefer and Barker, 2002), similarly to SCHADEX, require the use of a simulation based on a historical period to generate data series of state variables from which the random variables are sampled. Although the contribution of snowmelt can be important in some areas, it is rarely incorporated as it requires the generation of a temperature sequence for the event that is consistent with the rainfall sequence used and a snow water equivalent (SWE) as an initial condition. The assumption of a fixed rate of snowmelt which is based on typical temperatures, as is often used in Norway for the single-event-based design method, can introduce a bias in the estimates. The joint probability of both rainfall and snowmelt needs to be considered to obtain a probability-neutral value (Nathan and Bowles, 1997). One of the few methods that incorporates snowmelt is the SEFM, which has been applied in several USBR (US Bureau of Reclamation) studies and uses the semi-distributed HEC-1 hydrological model (Schaefer and Barker, 2002). Considering that, most often, simple event-based hydrological models are used (e.g. unit hydrograph), the joint probability approach is particularly advantageous in ungauged catchments or data-poor catchments, where the use of parsimonious models is preferred.
Even though methods for derived flood frequency analysis are becoming more commonly used in practice as they can provide better estimates of the high flood quantiles (e.g. Australian Rainfall and Runoff 2016, Ball, 2015; and the SCHADEX method), this kind of method has not yet been established in Norway. The purpose of this study is hence to develop a derived flood frequency method using a stochastic event-based approach to estimate design floods, including those with a significant contribution from snowmelt. In this way, the results for any return period can be derived, taking into account the probability of a range of possible initial conditions. A sensitivity analysis is then performed to understand the uncertainty in the stochastic PQRUT model and establish the relative roles of several factors, including the rainfall model, snowmelt, the initial soil moisture parameters of the model and the length of the simulation. The results are then compared with results from an event-based modelling method based on a single design precipitation sequence and assumed initial conditions and with statistical flood frequency analysis of the observed annual maximum series for a set of catchments in Norway for the 100- and 1000-year return periods.
The stochastic event-based model proposed here involves the generation of several hydrometeorological variables: precipitation depth and sequence, the temperature sequence during the precipitation event, the initial discharge, and the antecedent soil moisture conditions and snow water equivalent. A simple three-parameter flood model PQRUT (Andersen et al., 1983) is used to simulate the streamflow hydrograph for a set of randomly selected conditions based on these hydrometeorological variables. After this procedure is completed 100 000 times for each season, the results are combined and a flood frequency curve is constructed from all of the simulations using their plotting positions. As the method requires initial values for soil moisture and snow water equivalent, i.e variables which generally cannot be sampled directly from climatological data and which depend on the sequence of precipitation and temperature over longer periods, the distance distribution dynamics (DDD) hydrological model (Skaugen and Onof, 2014) was calibrated and run for a historical period to produce a distribution of possible values for testing the approach. The method (also shown in Fig. 1) can be outlined in summary form as follows:
-
Extract flood events for a given catchment and identify the critical storm duration.
For each season the following steps apply.
-
Aggregate the precipitation data to match the critical duration for the catchment.
-
Extract POT precipitation events and fit a generalized Pareto (GP) distribution.
-
Fit probability distributions for the initial discharge, soil moisture deficit and SWE values for the season.
-
Generate precipitation depth from the fitted GP distribution.
-
Disaggregate the precipitation depth to a 1 h time step by matching the dates of the identified POT flood events (from step 3) to the data series of precipitation with an hourly timestep.
-
Sample a temperature sequence by matching the dates of the identified POT flood events (from step 1) to the data series of temperature with an hourly timestep.
-
Sample initial conditions for snow water equivalent, soil moisture deficit and initial discharge from their distributions (step 5), accounting for co-variation using a multivariate normal distribution.
-
Simulate streamflow values using the calibrated PQRUT model for the sample event.
-
Repeat steps 5–9 100 000 times.
-
Estimate the annual exceedance probability from the total of 400 000 (i.e. 100 000 for each season) samples using plotting positions.
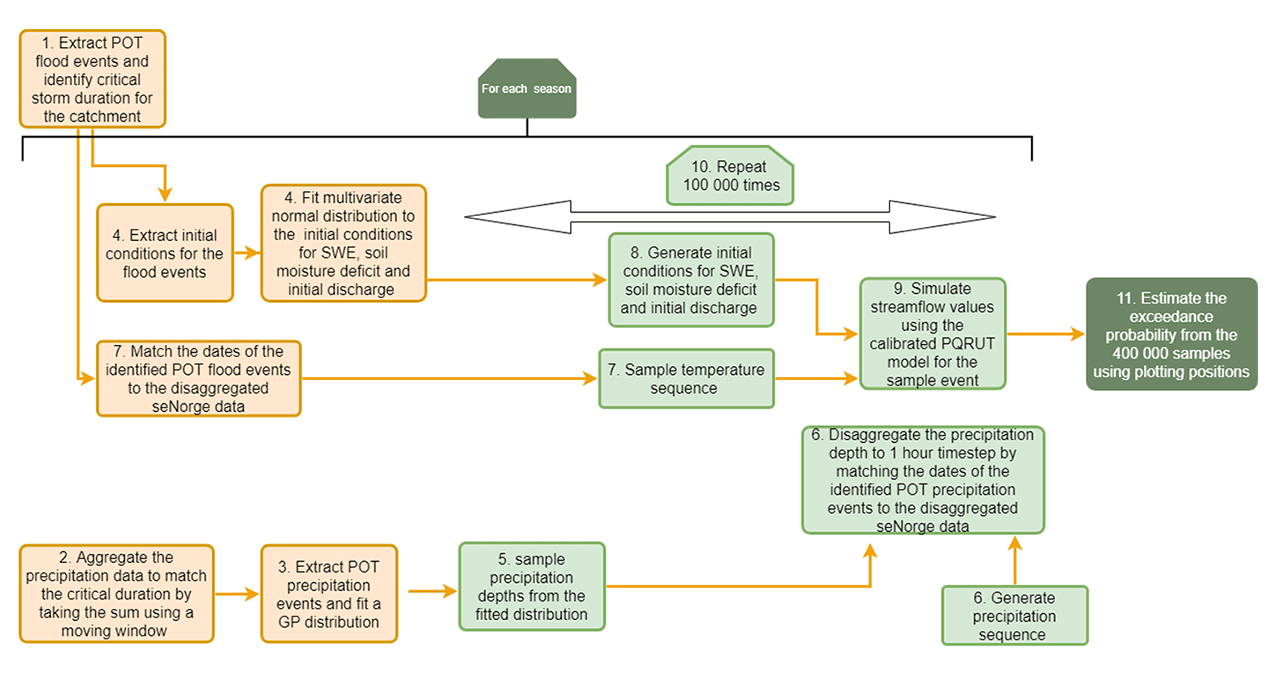
The study area and data requirements for the proposed method are described in Sect. 2.1, while Sect. 2.2 describes the method for determining the critical duration, and Sect. 2.3 and 2.4 describe the generation of antecedent conditions and meteorological data series. The hydrological model is presented in Sect. 2.5, the method for constructing the flood frequency curve is outlined in Sect. 2.6 and the sensitivity analysis is presented in Sect. 2.7.
2.1 Study area and data requirements
2.1.1 Catchment selection and available streamflow data
The study area in Norway, consisting of a dataset of 20 catchments located throughout the whole country, is shown in Fig. 2. All catchments have at least 10 years of hourly discharge data, and in all cases the length of the daily flow record is considerably longer than 10 years. All selected catchments are members of the Norwegian Benchmark dataset (Fleig et al., 2013), which ensures that the data series are unaffected by significant streamflow regulation and have discharge data of sufficiently high quality suitable for the analyses of flood statistics. The catchment size was restricted to small- and medium-sized catchments (maximum area is 854 km2), as the structure of the three-parameter PQRUT model does not take into account the longer-term storage processes which can contribute to delaying the runoff response during storm events. Previous applications of PQRUT in Norway indicate that this shortcoming is most problematic for larger catchments. Discharge datasets with both daily and hourly time steps were obtained from the national archive of streamflow data held by NVE (https://www.nve.no/, last access: 21 December 2018). The catchments were delineated and their geomorphological properties were extracted using the NEVINA tool NVE (2015), except for Q, which was calculated using the available streamflow data, and P, which was calculated using available gridded data (further details are given in Sect. 2.1.2 below). In order to illustrate the application of the method, we have selected three catchments which can be considered representative for different flood regimes in Norway: Krinsvatn in western Norway, Øvrevatn in northern Norway and Hørte in southern Norway (Fig. 2).
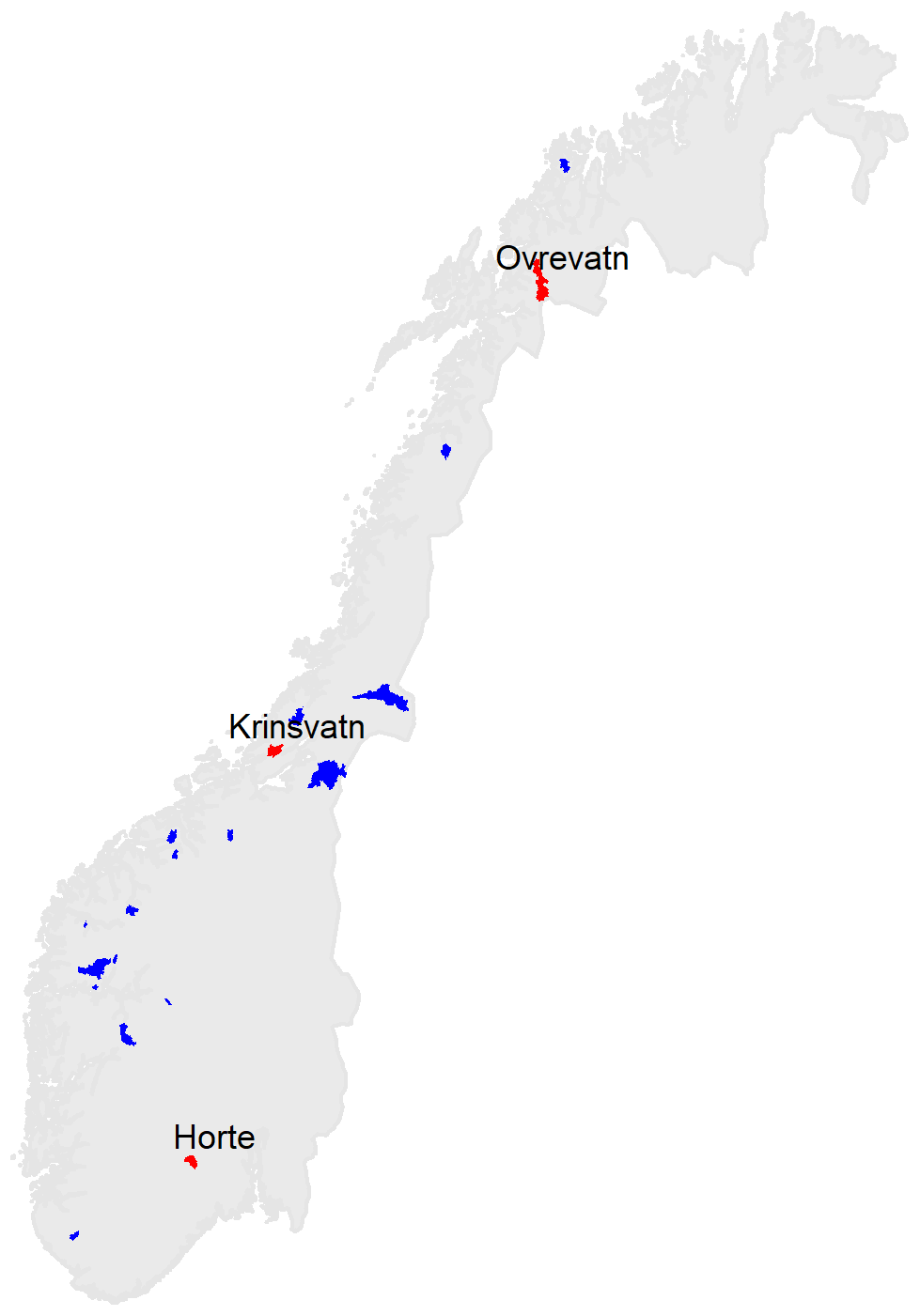
Figure 2Location of the selected catchments. The catchments Hørte, Øvrevatn and Krinsvatn, for which we show the method in more detail, are plotted in red.
Table 1Properties for the selected catchments, including catchment area (Area), mean annual streamflow (Q), mean annual precipitation (P), mean elevation (Hm50), percent forest (For), percent marsh (M), percent sparse vegetation over the treeline (B), catchment steepness (Hl), effective lake percent (Lk) and mean annual temperature (Temp).

Table 1 summarizes the climatological and geomorphological properties of these three catchments, including area (A in km2), mean annual runoff (Q in mm yr−1), mean annual precipitation (P in mm yr−1), mean elevation (Hm50), percentage of forest-covered area (For), percentage of marsh-covered area (M), percentage of area with sparse vegetation above the treeline (B), effective lake percentage (Lk), catchment steepness (Hl) and the mean annual temperature in the catchment (Temp). The effective lake percent (Lk) is used to describe the ability of water bodies to attenuate peak flows such that lake areas which are closer to the catchment outlet have a higher weight than those near the catchment divide. It is calculated as , where ai is the area of lake i, Ai is the catchment area upstream of lake i and A is the total catchment area. The dominant land cover for Krinsvatn and Øvrevatn is sparse vegetation over the treeline, while the land cover for Hørte is mainly forest. The effective lake percentage Lk is insignificant for Hørte and Øvrevatn, but for Krinsvatn, the Lk is higher and the area covered by marsh, M, is 9 %. The catchment steepness (Hl) (defined as (, where L is the catchment length and Hm25 and Hm75 are the 25th and 75th percentiles of the catchment elevation) is highest for Hørte (18.7 m km−1) and lowest for Krinsvatn (5.4 m km−1). The catchment Krinsvatn, being located near the western coast of Norway, has a much higher mean annual precipitation (P), i.e. an average of 2354 mm yr−1, in comparison with Hørte (1261 mm yr−1) and Øvrevatn (1558 mm yr−1). The dominant flood regime for Krinsvatn is primarily rainfall-driven high flows, as the catchment is located in a coastal area and is characterized by high precipitation values and an average annual temperature of around 4 ∘C. The highest observed floods, however, also have a contribution from snowmelt. The season of the AMAX flood is the winter period, i.e. December–February, although high flows can occur throughout the year. Hørte has a mixed flood regime with most of the AMAX flood events in the period of September–November, but in some years annual flood events occur in the period of March–May and are associated with rainfall events during the snowmelt season. Øvrevatn has a predominantly snowmelt flood regime with most AMAX flood events occurring in the period of June–August, due to the lower temperatures in the region such that precipitation falls as snow during much of the year.
2.1.2 Available meteorological data
Data for temperature and precipitation with daily time resolution were obtained from seNorge.no (last access: 21 December 2018). This dataset is derived by interpolating station data on a 1 km2 grid and is corrected for wind losses and elevation (Mohr, 2008). In addition, meteorological data with a sub-daily time step are needed for calibrating the PQRUT model, as many of the catchments have fast response times. For this, precipitation and temperature data with a 3 h resolution, representing a disaggregation of the 24 h gridded seNorge.no data using the High-Resolution Limited-Area Model (HIRLAM) hindcast series (Vormoor and Skaugen, 2013), were used. The HIRLAM atmospheric model for northern Europe has a 0.1∘ resolution (around 10 km2), and we used a temporal distribution of 3 h. The HIRLAM dataset was first downscaled to match the spatial resolution of the seNorge data, and the precipitation of the HIRLAM data was rescaled to match the 24 h seNorge data (Vormoor and Skaugen, 2013). Then, these rescaled values were used to disaggregate the seNorge data to a 3 h time resolution. The method was validated against 3 h observations, and the correlation of the method was found to be higher than that obtained by simply dividing the seNorge data into eight equal 3-hourly values (Vormoor and Skaugen, 2013). These datasets were further disaggregated to a 1 h time step by dividing the 3-hourly values into three equal parts to match the time resolution of the streamflow data.
2.1.3 Initial conditions
The stochastic PQRUT method requires time series of soil moisture deficit, SWE and initial discharge. These data series are used to construct probability distribution functions for generating initial conditions for the event-based simulations. Sources of these data can be for example remotely sensed data (see, for example, the review provided in Brocca et al., 2017) or gridded hydrological models. In this study, the DDD hydrological model was used to simulate these data series. The DDD model is a conceptual model that includes snow, soil moisture and runoff response routines and is calibrated for individual catchments using a parsimonious set of model parameters. The snowmelt routine of the DDD model uses a temperature-index method and accounts for snow storage and melting for each of 10 equal area elevation zones. The soil moisture routine is based on one dynamic storage reservoir, in which we find both the saturated and the unsaturated zones, having capacities which vary in time. The flow percolates to the saturated zone if the water content in the unsaturated zone exceeds 0.3 of its capacity. The response routine includes routing of the water in the saturated zone using a convolution of unit hydrographs based on the distribution of distances to the nearest river channel within the catchment and from the distribution of distances within the river channel.
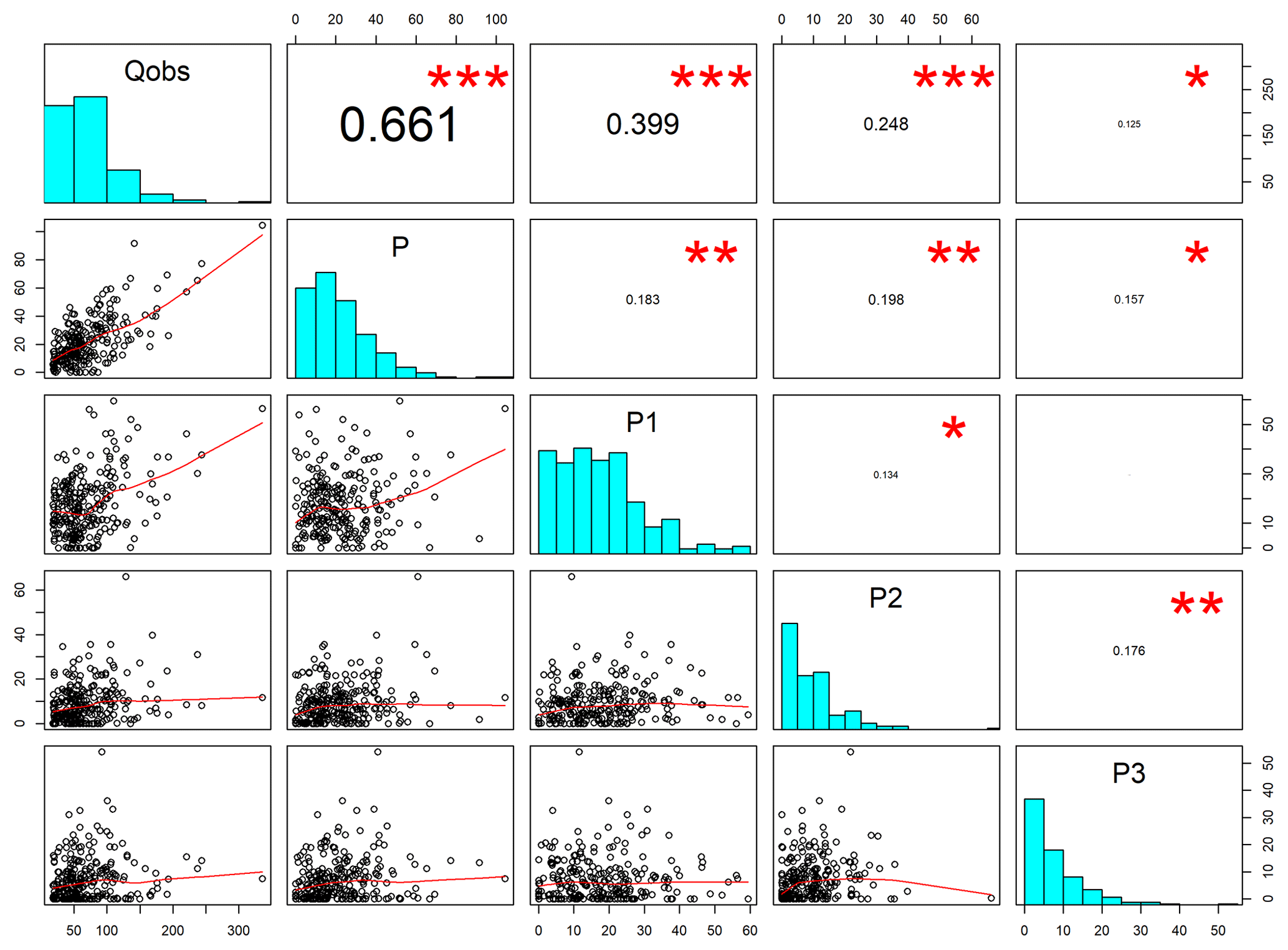
Figure 3Diagram representing the process used to establish the critical duration for Krinsvatn. The stars represent the degree of significant correlation between Qobs and P on the day of the peak and −1, −2 and −3 days before the peak at p=0.01. The critical duration is set in this case to 2 days because the correlation between Qobs and P and P1 is greater than 0.25.
2.2 Critical duration
When simulating flood response with an event-based model, it is important to specify the so-called critical duration (Meynink and Cordery, 1976) to ensure that the flood peak is correctly modelled. The critical duration is an important quantity which effectively links the duration and the intensity of precipitation events of a given probability. To determine the critical duration, flood events from the daily time series over a quantile threshold (in this case, 0.9) were extracted. The POT flood events were considered independent if they were separated by at least 7 days of values below the threshold. The day with the maximum peak value of streamflow was then identified for each event. The peak values were tested for correlations with the precipitation on the day of the peak flow and on days −1, −2 and −3 before the peak. The critical duration was determined as the number of days in which the correlation between the precipitation and the streamflow was higher than 0.25. This threshold value was selected because it gave realistic durations for the catchments in the study area. As an alternative approach, the critical duration was also set to equal the number of days for which the correlation was significant at p=0.01. This method resulted, however, in very long durations in some cases. A possible reason for this is that, if there are only a few observations, even relatively low Pearson correlation coefficients can produce statistically significant p values. In some catchments (mostly those having a snowmelt flood regime), no significant correlation was found between discharge and precipitation, and in this case the critical duration was determined by considering only flood events in the September–November (SON) season, in which most events are caused by rainfall (in this case, during the autumn). If the critical duration was more than 1 day, the precipitation was aggregated to the critical duration by applying a moving window to the data series. For Hørte and Øvrevatn, the critical duration was found to be 24 h, and for Krinsvatn it was found to be 48 h (Fig. 3).
2.3 Precipitation and temperature sequence generation
In addition to the critical duration of the event, the sequence of the input data must be generated for the stochastic simulation. Snowmelt can be important in the catchments considered in this study, so both the sequence of precipitation and temperature must be considered. In order to account for seasonality, the meteorological data series were first split into standard seasons: DJF, MAM, JJA and SON. In this way, we ensure that more homogeneous samples are used to fit the statistical distributions. Precipitation events over a threshold (POT events) were identified in the precipitation data series and a generalized Pareto distribution was fitted to the series of selected events. In order to choose a threshold value for event selection, two criteria were used: (1) the threshold must be higher than the 0.93 quantile and (2) the number of selected events must be between two and three per season. Although other methods for threshold selection exist, such as the use of mean life residual plots, the described method is much simpler to apply and gives acceptable results (Coles, 2001). The selected threshold varied between the 0.93 and 0.99 quantiles, depending on the season and catchment. In addition, the exponential distribution is often fitted to POT events, as it can give more robust results than the GP distribution. Figure 4 shows the return levels calculated from the GP and exponential distributions and the empirical return levels and demonstrates that it is appropriate to use these models. In this case, we have preferred to use the GP distribution due to the inclusion of the shape parameter for describing the behaviour of the highest quantiles. An exponential distribution, however, could also be used, as could a compound weather-pattern-based distribution such as the MEWP distribution (Blanchet et al., 2015; Garavaglia et al., 2010). In addition, a temperature sequence with a 1 h time resolution was identified from the disaggregated seNorge data, introduced in Sect. 2.1.2, and extracted for each POT event. The precipitation depths were generated (for 100 000 events) from the fitted GP distribution for each season. Storm hyetographs were used to disaggregate the precipitation values as follows: a storm hyetograph was first sampled from the extracted hyetographs for the selected POT precipitation events (by matching the dates of the selected POT precipitation events to the disaggregated seNorge data series), taking into account seasonality, and the ratios between the 1 h and the total precipitation for the event were calculated according to
where Phsim is the simulated 1 h precipitation intensity, Pdsim is the simulated daily intensity and Pi is the 1 h disaggregated seNorge intensity. The calculated ratios were then used to rescale the simulated values.

Figure 4Return level plots for the fitted generalized Pareto (GP) and exponential (EXP) distributions for peak-over-threshold precipitation events with duration equal to the critical duration (GP, red; EXP, green) for the three selected catchments.
2.4 Antecedent snow water equivalent, streamflow and soil moisture deficit conditions
In order to determine the underlying distributions for various antecedent conditions, the relevant quantities were extracted from simulations based on the DDD hydrological model of Skaugen and Onof (2014). The model was calibrated for the selected catchments at a daily timestep using a Markov chain Monte Carlo (MCMC) routine (Soetaert and Petzoldt, 2010). Outputs from DDD model runs were used to extract values for the initial streamflow, snow water equivalent (SWE) and soil moisture deficit, at the onset of the previously selected seasonal flood POT events. It is important to note that simulated values for the soil moisture deficit are used. However, as described in Skaugen and Onof (2014), the model provides realistic values in comparison with measured groundwater levels. The POT event series used for this is the same as that used for identifying the critical duration (described in Sect. 2.2).
After extracting the initial conditions, the correlation between the variables was tested for each season for each catchment. As the correlation between the variables is in most cases significant, the variables were jointly simulated using a truncated multivariate normal distribution. In order to achieve normality for the marginal distributions, the SWE and the discharge were log-transformed. In the spring and summer, the SWE is often very low or 0 in some catchments. If the proportion of non-zero values, p, was greater than 0.3 (around 15 observations), the values were simulated using a mixed distribution as
where G1 represents the multivariate normal distribution with discharge, soil moisture deficit and SWE as variables (denoted as x1) and G2 represents the bivariate normal distribution for the discharge and soil moisture (given as x2). The probability p for switching between the trivariate and bivariate distributions is based on the historical data for SWE higher than 0. In addition, because the initial conditions are not expected to include extreme values, the values of the initial conditions were truncated to be between the minimum and maximum of the observed ranges. The correlation between the observed and simulated variables is shown in Fig. 5 for the Krinsvatn catchment, and although the distribution of simulated values exhibits a very good resemblance to that of the observed values, there is not a perfect correspondence between the two. A reason for this may be that the variables (even after log transformation) do not exactly follow a normal distribution. We considered using copulas for the correlation structure of the initial conditions (Hao and Singh, 2016). However, as the data are limited in number (around 50 observations per season), these were much more difficult to fit. Similarly, nonparametric methods such as kernel density estimation were deemed to not be feasible due to the limited number of observations. Therefore, the multivariate normal distribution was chosen as the best alternative for modelling the joint dependency between the variables comprising the initial conditions for the stochastic modelling.
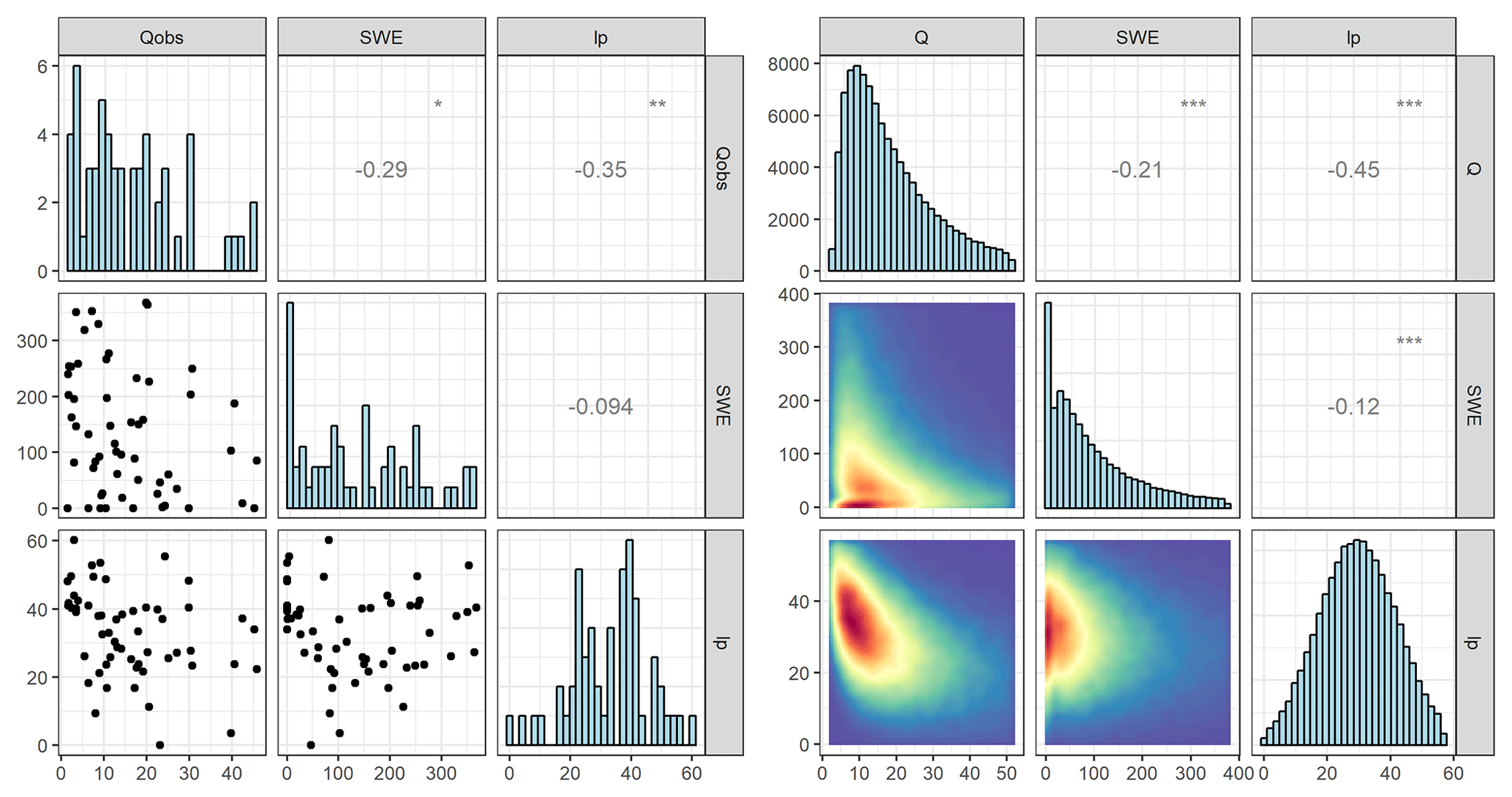
Figure 5Correlation scatterplots for initial conditions (snow water equivalent, SWE, in mm; soil moisture deficit, lp, in mm; initial discharge, Qobs, in m3 s−1) for the Krinsvatn catchment for POT events (flood events over the 0.9 quantile, 57 observations). Scatterplots for observed quantities are shown on the left and simulated on the right (based on 100 000 simulations). The stars represent the degree of significant correlation.
2.5 PQRUT model
The PQRUT (P, precipitation; Q, discharge; and RUT, routing) model was used to simulate the streamflow for the selected storm events. The PQRUT model is a simple, event-based, three-parameter model (Fig. 6) which is used for various applications, including estimating design floods and safety check floods for dams in Norway (Wilson et al., 2011). In practical applications, a design precipitation sequence of a given return period is routed through the PQRUT model, usually under the assumption of full catchment saturation. For this reason, only the hydrograph response is simulated, and there is no simulation of subsurface and other storage components, such as are found in more complex conceptual hydrological models. Of the three model parameters, K1 corresponds to the fast hydrograph response of the catchment, and the parameter K2 is the slower or delayed hydrograph response. The parameter Trt is the threshold above which K1 becomes active.
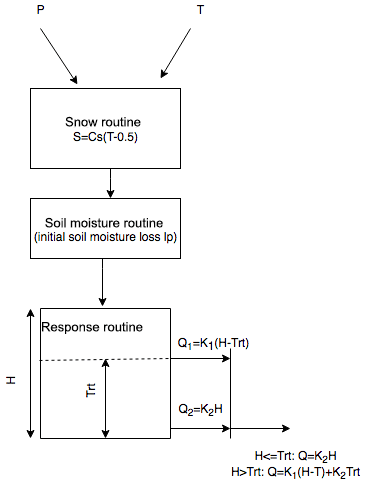
The PQRUT model was calibrated for the 45 highest flood events for each catchment by using the DDS (dynamically dimensioned search) optimization routine (Tolson and Shoemaker, 2007) and the Kling–Gupta efficiency (KGE) criterion (Gupta et al., 2009) as the objective function. An additional variable, the soil deficit, lp, was introduced to account for initial losses to the soil zone. The reason for this is that, even though fully saturated conditions are assumed when the model is used to estimate PMF or other extreme floods with low probabilities, the model needs to account for initial losses when actual (more frequent) events are simulated during the calibration process. This procedure is described in more detail in Filipova et al. (2016). In addition, regional values can be used in ungauged or poorly gauged catchments (Andersen et al., 1983; Filipova et al., 2016).
For the work presented here, the value of lp was set to the initial soil moisture deficit, estimated using DDD. This variable functions as an initial loss to the system, such that the input to the reservoir model is 0 until the value of lp is exceeded by the cumulative input rainfall. In order to model flood events involving snowmelt, a simple temperature-index snow melting rate was used:
where S is the snow melting rate in mm h−1, Cs is a coefficient accounting for the relation between temperature and snowmelt properties, and TL is the temperature threshold for snowmelt (here fixed at 0 ∘C). Regional values for the Cs parameters as a function of catchment properties, based on the ranges given in Midttømme and Pettersson (2011), were applied. In addition, the temperature threshold between rain and snow was set to TX=0.5 ∘C, which is typically used in Norway (Skaugen, 1998).
2.6 Flood frequency curves
Seasonal and annual flood frequency curves were constructed by extracting the peak discharge for each event and estimating the plotting positions of the points using the Gringorten plotting position formula:
where Pe is the exceedance probability of the peak, m is the rank (sorted in decreasing order) of the peak value, N is the number of years and k is the number of events per year. The number of events per year, k, was set to be equal to the average number of extracted POT storm (precipitation) events per year. These simulated events were compared with the POT flood events extracted from the observations (Fig. 7). After calculating the probability of the simulated events using Eq. (4), the initial conditions and seasonality for a return period of interest can be extracted. For example, the events with return periods between 90 and 110 years were extracted (representing around 80 events), and the hydrological conditions for those events were identified (Table 2). The results show that there is a large variation in the total precipitation depths and initial conditions that can produce flood events of a given magnitude and this is the reason why it is difficult to assign initial conditions in event-based models. However, it is still useful to extract the distribution of these values in order to ensure that the ranges are reasonable and the catchment processes are properly simulated. For example, the average snowmelt is negative (i.e. there is snow accumulation) for Krinsvatn, which means that in most cases snowmelt does not contribute to extreme floods. This is reasonable as the catchment is located in western Norway, where the climate is warmer (the mean temperature is around 4 ∘C) and the mean elevation is low. The average snowmelt contribution for Øvrevatn is much higher as this catchment has a predominantly snowmelt flood regime. The soil moisture deficit for the three catchments is larger than 0, even though floods with relatively long return periods (i.e. between 90 and 100 years) are being sampled here. The seasonality of the simulated values is consistent with the seasonality of the observed annual maxima (Table 1).
Table 2Precipitation (48 h duration is used for Krinsvatn) and initial conditions for Q100; range corresponds to 5 and 95 percentile. For the seasonality, the actual fraction of the simulated events is given in brackets.

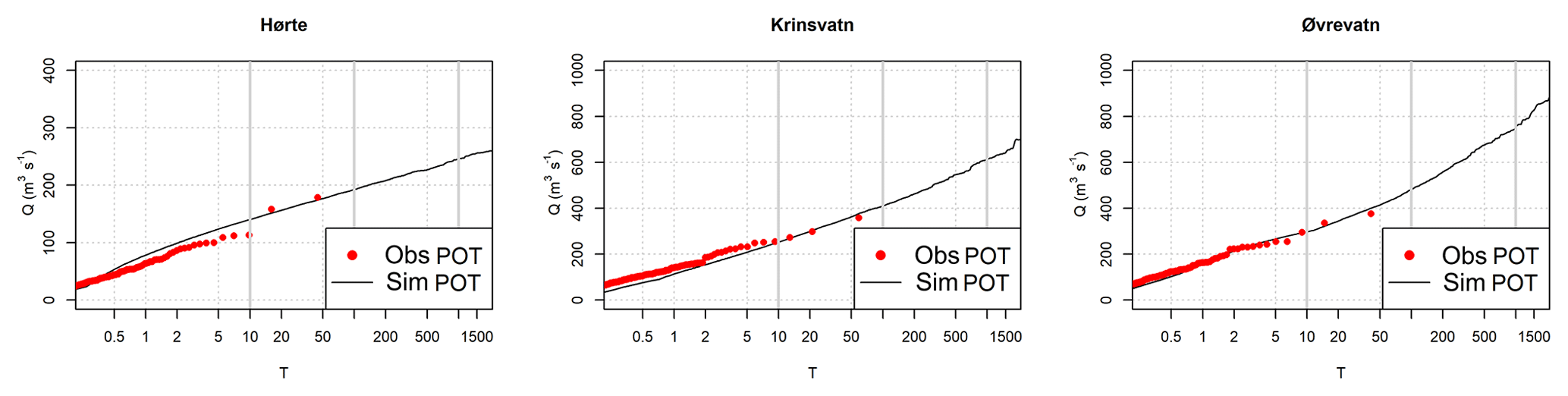
Figure 7Comparison between the observed and simulated flood frequency curves of peak discharge for Hørte, Krinsvatn and Øvrevatn.

Figure 8Sensitivity analysis of the stochastic PQRUT for the following variables: (a) the rainfall model; (b) the effect of the simulation length and the parameters of the hydrological model; (c) the initial discharge values, snowmelt conditions and catchment saturation; and (d) the random seed used for the simulations. Detailed information on the set-up is given in Table 3.
2.7 Sensitivity analysis
A sensitivity analysis was performed for the three test catchments, Hørte, Øvrevatn and Krinsvatn, in order to determine the relative importance of the initial conditions, precipitation, the parameters of PQRUT, the effect of the random seed and length of the simulation on the flood frequency curve. To test the sensitivity of the model, we have used several different model runs and calculated the percentage difference of each of these model runs relative to the standard model set-up, as shown in Fig. 8. More detailed information on the set-up is given in Table 3. As these catchments are located in different regions and exhibit different climatic and geomorphic characteristics, we hypothesize that the flood frequency curve will be sensitive to different parameters and hydrological states, as well as local climate and catchment characteristics. The results are summarized in Table 4.
Table 4Percent difference between the model runs of the sensitivity analysis to the calibrated model.
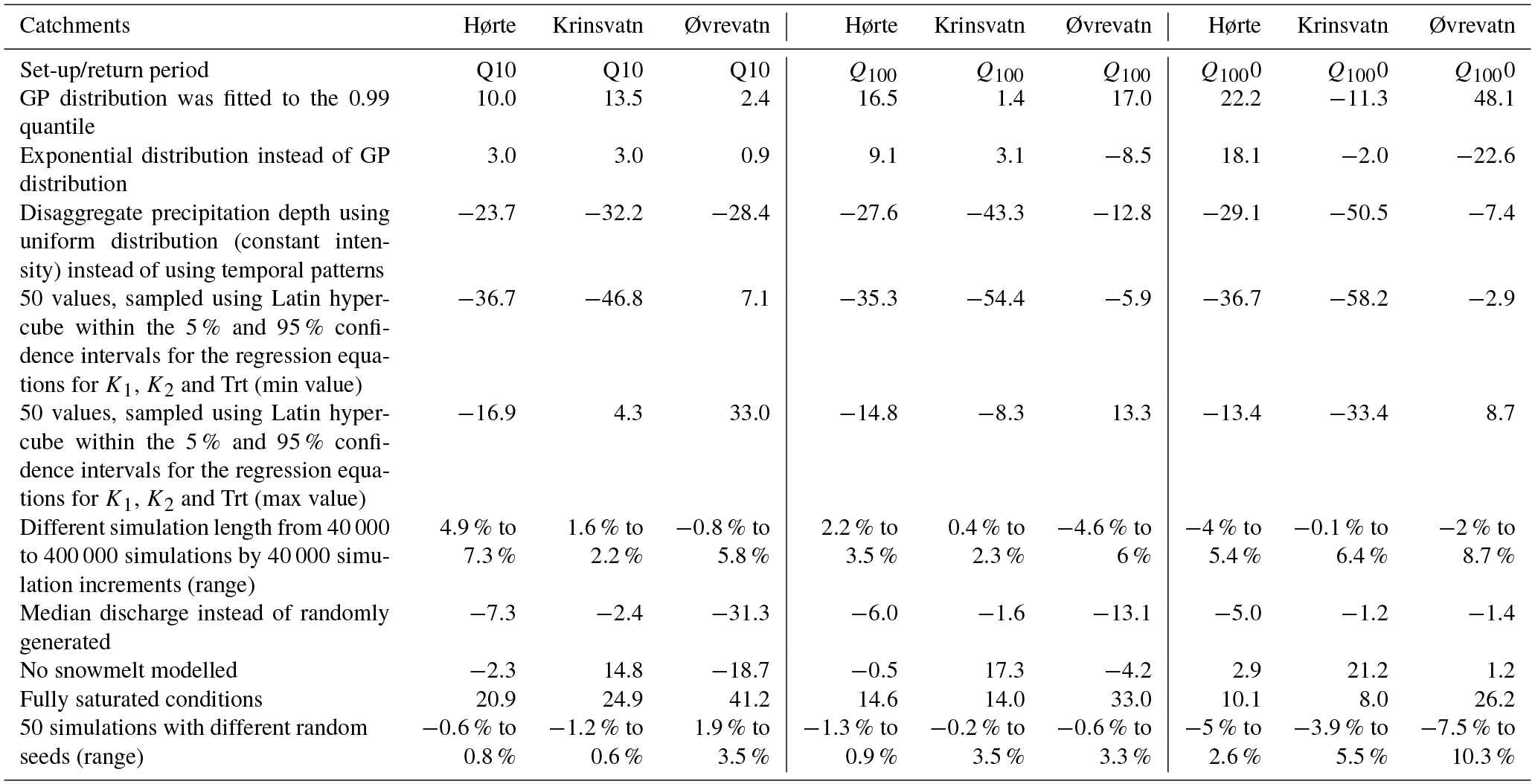
The results for the sensitivity to the rainfall model are presented in Fig. 8a. The results show that the temporal patterns of the rainfall input have a large impact (up to 50 %) on the flood frequency curve for Hørte and Krinsvatn, as these catchments have a predominantly rainfall-dominated flood regime. The impact is very little for Øvrevatn. A high sensitivity to the shape of the hyetograph was also found in Alfieri et al. (2008). Their study shows that using rectangular hyetograph results in a significant underestimation of the flood peak while the Chicago hyetograph (e.g. Chow et al., 1988), where the peak is in the middle of the event, resulted in overestimation. In addition, Øvrevatn and Hørte showed sensitivity (around 20 %) to the choice of the statistical distribution for modelling precipitation. This means that the uncertainty in fitting the rainfall model can propagate to the final results of the stochastic PQRUT, and therefore it is important to ensure that the choice of distribution and parameters is carefully considered. A high sensitivity to the parameters of the rainfall model was also described by Svensson et al. (2013), who tested the sensitivity of a stochastic event-based model applied to four small-to-medium-sized catchments in the UK. Both Hørte and Krinsvatn showed relatively lower sensitivity to the threshold value for the GP distribution, compared to Øvrevatn.
In addition, all catchments are very sensitive to the parameters of the PQRUT model (Fig. 8b) and there is large uncertainty in these values. Because of the higher sensitivity to the calibration of the rainfall-runoff model, a conclusion can be made that, in practice, if streamflow data are available it is important that they are used for calibrating the PQRUT model rather than relying on regionalized parameter values.
Considering the effect of the initial conditions (Fig. 8c), using fully saturated conditions results in the slight overestimation of flood values for all catchments, as expected, and the impact is higher at lower return periods. In addition, Øvrevatn shows a higher sensitivity (around 26 % for Q1000) to the initial soil moisture conditions than the other two catchments. A reason for this is that, for Øvrevatn, higher soil moisture conditions are associated with higher rainfall quantiles. For example, the ratio of the maximum soil moisture to the mean rainfall is 65 % while for Hørte and Krinsvatn it is much less, i.e 33 % and 26 %, respectively. The initial discharge value does not seem to have a large impact on any of the catchments. If no snow component (no snowmelt and no snow accumulation) is used, there is not much difference in the results for Øvrevatn and Hørte, but the seasonality of the flood events is changed. For example, the season when the Q1000 is simulated for Øvrevatn is SON instead of JJA when most of the AMAX values are observed. Due to this change of seasonality, the precipitation values that produce Q1000 are accordingly higher (the median is around 15 % higher). The soil moisture deficit, as expected, is also somewhat higher and shows much more spread, with values up to 45 mm. In addition, Krinsvatn shows a high sensitivity to the snowmelt component (21 % higher) and also a step change in the frequency curve, even though the soil moisture deficit is higher. This can also be explained by the fact that the snowmelt contribution is negative (i.e. there is snow accumulation), as can also be seen in Table 2. Other studies have also shown that the soil saturation level is not as important as the parameters of the hydrological model. For example, Brigode et al. (2014) tested the sensitivity of the SCHADEX model using a block bootstrap method. In each of these experiments, different sub-periods selected from the observation record were used in turn to calibrate the rainfall model, the hydrological model and to determine the sensitivity to the soil saturation level. The results showed that, for extreme floods (1000-year return period), the model is sensitive to the calibration of the rainfall and the hydrological models, but not so much to the initial conditions.
The stochastic PQRUT model shows some sensitivity to the random seeds (Fig. 8d), especially for higher return periods. This is expected as the higher quantiles are calculated using a smaller sample of simulated events. Similarly, the effect of the simulation length has a larger impact on the higher quantiles (e.g. Q1000). However, the length of the simulation will depend on the required return level, as shorter simulation length can be acceptable for lower return periods, e.g. Q100.
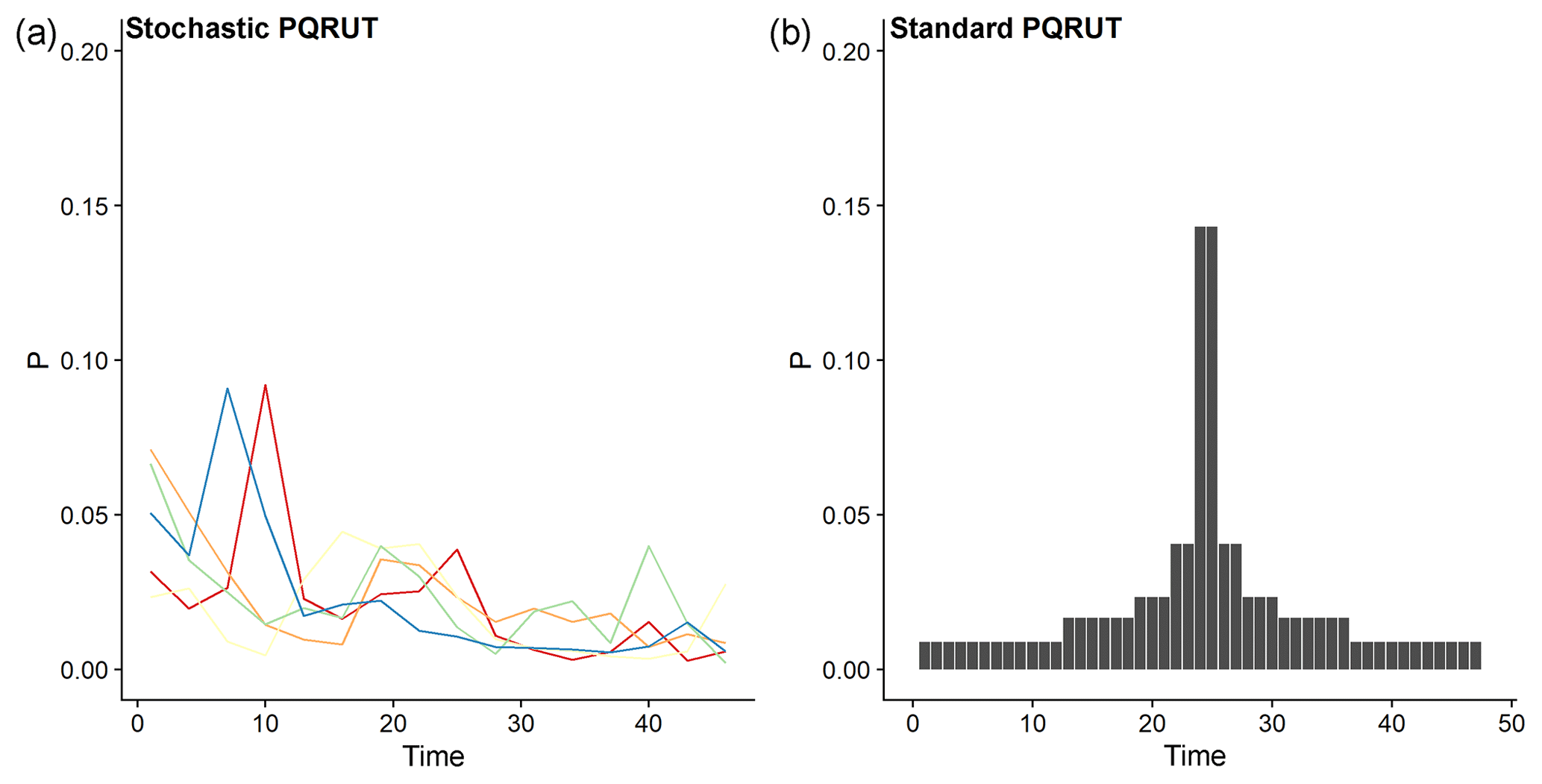
Figure 9An example of storm patterns (only five are shown here) used for the simulated events in the stochastic PQRUT model (a) and the storm pattern typically used with the standard PQRUT model (b). P represents the ratio of the hourly precipitation to the total precipitation depth for the event.
3.1 Implementation of the methods and results
The results of the stochastic PQRUT method for the 100- and 1000-year return level were compared with the results for statistical flood frequency analysis and with the standard implementation of the event-based PQRUT method (in which full saturation and snow melting rates are assumed a priori) for the 20 test catchments described in Sect. 2.1. For the statistical flood frequency analysis, the annual maximum series were extracted from the observed daily mean streamflow series. The generalized extreme value (GEV) distribution was fitted to the extracted values using the L-moments method and the return levels were estimated. In order to obtain instantaneous peak values, the return values were multiplied by empirical ratios, obtained from regression equations, as given in Midttømme and Pettersson (2011). The ratios can vary substantially from catchment to catchment, and in this study the values are from 1.02 to 1.82, depending on the area and the flood generation process (snowmelt or precipitation). Although much more sophisticated methods could be used to obtain statistically based return levels, the procedure used here is equivalent to that currently used in standard practice in design flood analysis in Norway. In addition, the length of the daily streamflow series justifies the use of at-site flood frequency analysis (Kobierska et al., 2017); the minimum length is 31 years, while the median is 65 years of data. However, it is expected that the uncertainty will be high when the fitted GEV distribution is extrapolated to a 1000-year return period. The 1000-year return period is used here, however, as it is required for dam safety analyses in Norway (e.g. Midttømme, et al., 2011; Table 1). More robust, but potentially less reliable, estimates could be obtained using a two-parameter Gumbel distribution, rather than a three-parameter GEV distribution (Kobierska et al., 2017). The standard implementation of PQRUT involves using a precipitation sequence that combines different intensities, obtained from growth curves based on the 5-year return period value fitted using a Gumbel distribution while the ratios between the different durations are derived from empirical distribution (Førland, 1992). The precipitation intensities were combined to form a single symmetrical storm profile with the highest intensity in the middle of the storm event whereas the storm profile is randomly sampled for the stochastic PQRUT model (Fig. 9). In the application reported here, the duration of the storm event was assumed to be the same as the critical duration used for the stochastic PQRUT model. The initial discharge values were similarly fixed to the seasonal mean values, as is common in standard practice. The snowmelt contribution for the 1000-year return period was, in this case, assumed to be 30 mm day−1 for all catchments, which corresponds to 70 % of the maximum snowmelt, estimated as 45 mm day−1 by using a temperature-index factor of 4.5 mm ∘C−1 day and 10 ∘C−1. The snowmelt contribution for the 100-year return period was assumed to be 21 mm day−1 for all catchments. In addition, fully saturated conditions were assumed for both the estimation of the 100- and 1000-year return periods. A similar implementation of PQRUT for the purposes of comparing different methods has also been described in Lawrence et al. (2014). The parameters of the PQRUT were estimated by using the regional equations derived in Andersen et al. (1983), as these are still used in standard practice.
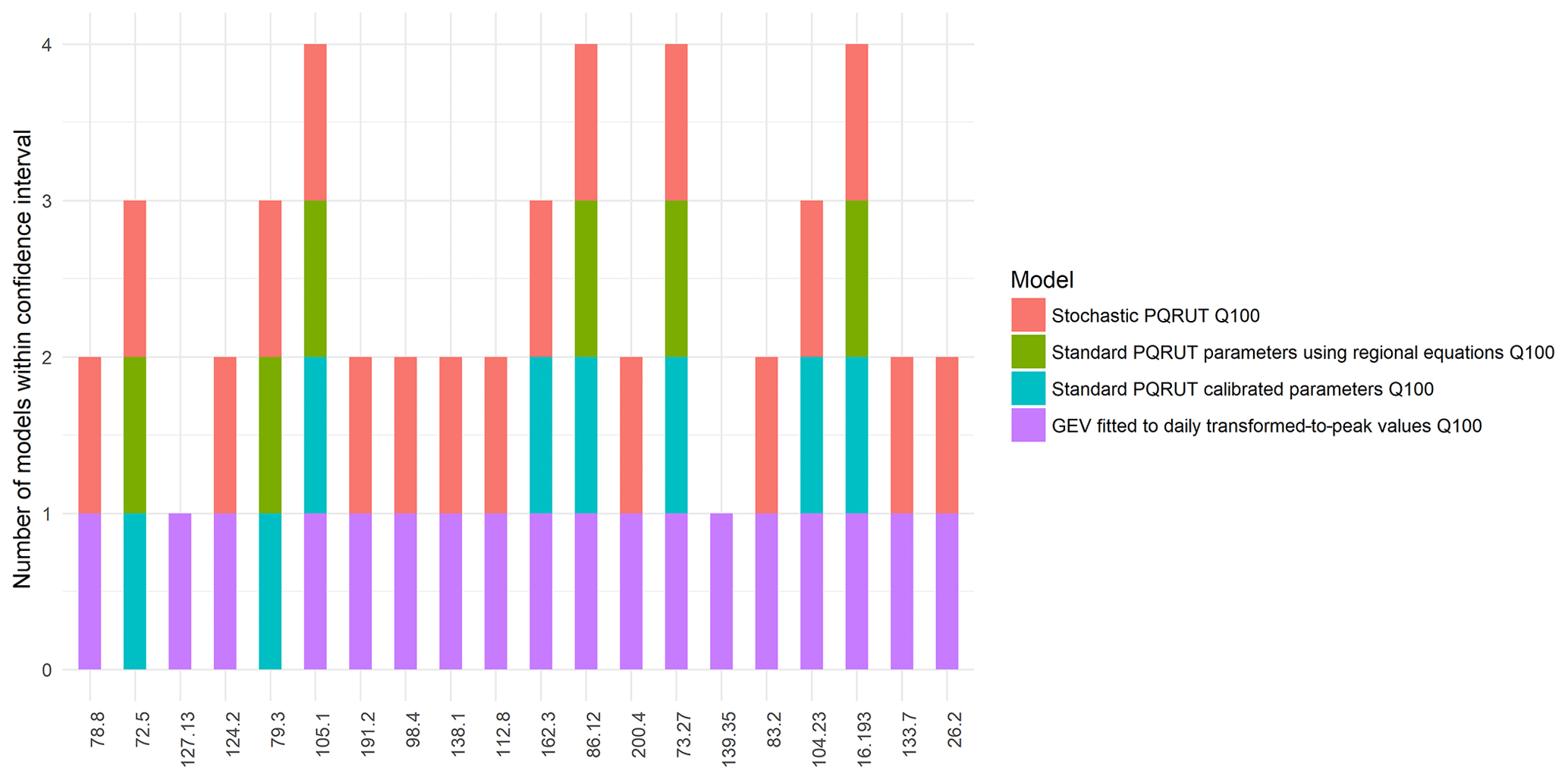
Figure 10Number of models giving estimates for Q100 within the confidence intervals of the GP distribution fitted to 1 h streamflow data.
The performance of the three models was validated by using two different tests. Test 1 assessed whether the estimated values for the 100-year return period are within the confidence intervals of a GP distribution fitted to the streamflow data with a 1 h time step. The stochastic PQRUT shows good agreement with the observations (Fig. 10), and for 18 of the 20 catchments, all the points of the derived flood frequency curve were inside the confidence intervals. As expected, for most of the catchments (16 out of 20) the return levels calculated using statistical flood frequency analysis based on the GEV distributions using daily values were within the confidence intervals. For the standard PQRUT model, the values of the 100-year return level were within the confidence interval for only six of the catchments when the regional equations for the PQRUT model were used and for only eight of the catchments when calibrated parameters were used. In test 2, the results of the flood frequency analysis and the stochastic PQRUT methods were compared, based on a quantile score (QS) suggested by Emmanuel Paquet (personal communication, 2018). This is given in Eq. (5):
In Eq. (5) the observed probabilities () are calculated using Gringorten positions for the peak AMAX series that were derived from the daily values. The modelled probabilities that correspond to the observed events are calculated by using the statistical flood frequency analysis and the stochastic PQRUT model, as described previously. The standard implementation of the event-based PQRUT model was not evaluated based on QS as initial conditions could not be assigned for low return periods. As this model is usually used to calculate high quantiles (Q100 or higher), fully saturated conditions are assumed for its implementation. The results for the quantile score show similar performance, and the median is approximately 0.65 for both methods. However, the results vary between catchments as shown in Fig. 11. Although it is difficult to evaluate the performance of the models when the data series are relatively short, based on the results of test 1 we can conclude that the performance of the standard PQRUT model is poorer than the performance of the statistical flood frequency analysis and the stochastic PQRUT model for the selected catchments, while the results of test 2 indicate that both the GEV distribution and the stochastic PQRUT provide similar fits to observed quantiles.
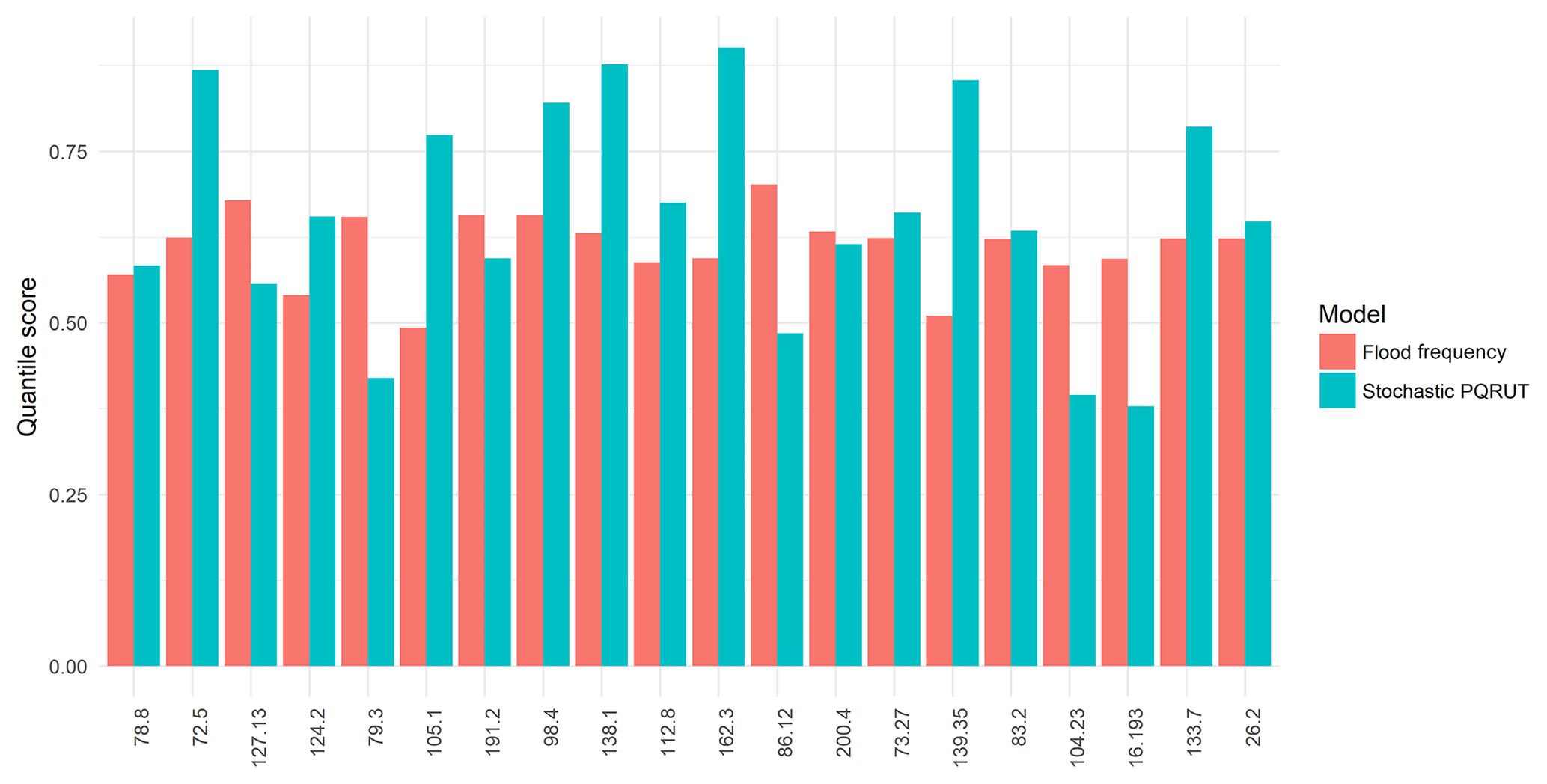
Figure 11Quantile score (Eq. 5) for estimates based on statistical flood frequency analysis using a GEV distribution (red) and on the stochastic PQRUT model (blue).

Figure 12Box plots showing the distribution of the differences (calculated by dividing the estimates by the average of all of the models) between the stochastic PQRUT, PQRUT and GEV for the 100- and 1000-year return level.
3.2 Discussion
A comparison of the stochastic PQRUT with the standard methods for flood estimation shows that there is a large difference between the results of the three methods for both Q100 and Q1000 (Figs. 12 and 13). The box plots (Fig. 12) show that the stochastic PQRUT method gives slightly lower results on average than the standard PQRUT model for Q100 and Q1000. This is probably due to assuming fully saturated conditions when applying the standard PQRUT for Q100, which might not be realistic for some catchments. For example, the results for the initial conditions for the three catchments, presented in Sect. 2.6, show that the soil moisture deficit is larger than 0 for Q100. Furthermore, the absolute differences between the two methods are larger in catchments with lower temperature (Fig. 12). This indicates that the performance of the standard PQRUT model is worse in catchments with a snowmelt flood regime, which may be either due to the difficulty in determining the snowmelt contribution or to the poorer performance of the regional parameters in catchments with a snowmelt flow regime. Although it shows a similar pattern, the standard PQRUT model, implemented using calibrated parameters, results in much less spread than the implementation using the regionalized parameters, when compared to both the GEV distribution and the stochastic PQRUT model. This means that the hydrological model can introduce a large amount of uncertainty, as also indicated by the sensitivity analysis described in Sect. 2.7 and previous results presented by Brigode et al. (2014).
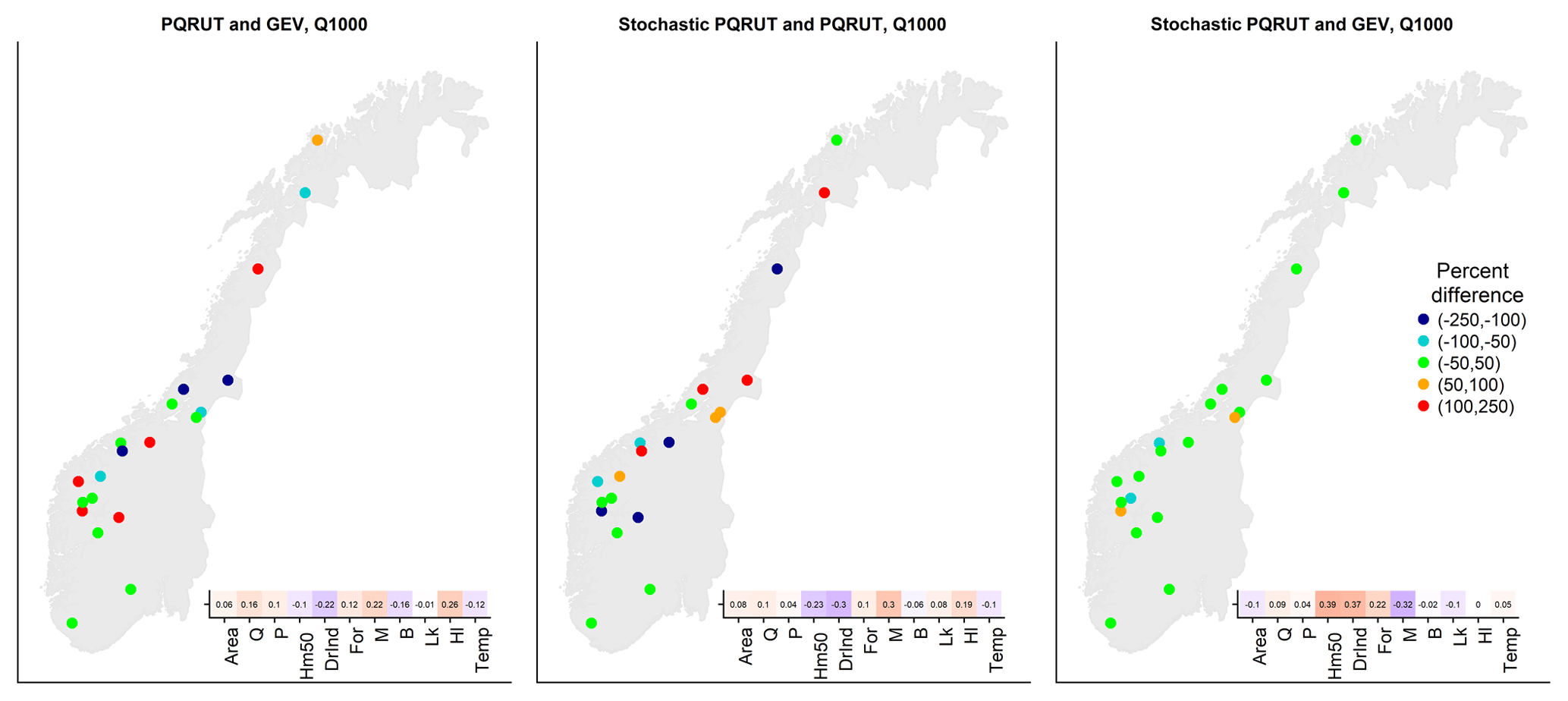
Figure 13Results of the comparison between stochastic PQRUT, PQRUT and GEV for the values of the 1000-year return level. The absolute differences (calculated by dividing the estimate by the average of all models) are correlated with catchment properties. Positive correlations are given by red and negative correlations by blue.
The differences between the stochastic PQRUT model and the GEV fits are much smaller than the differences between the standard PQRUT model and the GEV fits, even when calibrated parameters are used for the PQRUT modelling. The differences are larger (i.e. the stochastic PQRUT results are lower, as shown in Fig. 13) in western Norway, where P and Q are higher, and for steeper catchments, i.e. with a higher value of Hl. A reason for this might be that the empirical ratios that are used to convert daily to peak flows in these catchments are inaccurate and possibly too high. Similarly to the box plots, Fig. 13 also shows that the results of the stochastic PQRUT closely match the GEV distribution fits with differences within 50 % for most locations. There is no clear spatial pattern in the differences between estimates based on the GEV distribution and on the standard PQRUT model, except for the catchments in mid-Norway, i.e. Trøndelag (including catchment Krinsvatn), where the GEV distribution produces higher results. However, a much larger sample of catchments is needed to assess whether there is a spatial pattern in the performance of the methods.
In this article, we have presented a stochastic method for flood frequency analysis based on a Monte Carlo simulation to generate rainfall hyetographs and temperature series to drive a snowmelt estimation, along with the corresponding initial conditions. A simple rainfall-runoff model is used to simulate discharge, and plotting positions are used to calculate the final probabilities. In this way, we can generate thousands of flood events and base extreme flood estimates on the empirical distribution, instead of extrapolating a statistical distribution fitted to the observed events. The approach thereby gives significant insights into the various combinations of factors that can produce floods with long return periods in a given catchment, including combinations of factors that are not necessarily well represented in observed flow series. It is thus a very useful complement to statistical flood frequency analysis and can be particularly beneficial in catchments with shorter streamflow series compared to the precipitation record as well as in ungauged catchments.
In order to apply the method, we assume that the precipitation and temperature series are not significantly correlated with the initial conditions, which allows us to simulate them as independent variables. Although we have not performed a statistical analysis, the independence between the precipitation events and the initial conditions has been verified (Paquet et al., 2013). Due to the considerable seasonal variation in the initial conditions and in the rainfall distribution, seasonal distributions were used. In addition to obtaining more homogeneous samples, this allows for a check of the seasonality of the flood events, which can be of interest in catchments with a mixed flood regime. In this study, we have used a GP distribution to model the extreme precipitation. However, if only shorter precipitation data series are available, the exponential distribution or even regional frequency analysis methods may provide more robust results. A limitation of the method is that PQRUT can only be used for small- and medium-sized catchments, since its three parameters cannot take into account spatial variation in the snowmelt and soil saturation conditions within the catchment. However, for the catchments presented in this study (all with a catchment area under 850 km2), the model produces relatively good fits to the observed peaks, even though it uses a very limited number of parameters.
In this study, initial conditions based on simulations using a hydrological model (DDD) were used. This requires that this model is calibrated for each catchment. Considering the results of the sensitivity analysis, the quality of the initial conditions is not as important as that of the precipitation data for the estimation of extreme floods (with return periods higher than 100 years). This means that, if no other data are available, the output of the gridded hydrological model could be considered as a source of this input data. Alternatively, remotely sensed data can be used for soil moisture and the snow water equivalent while regional values for the initial discharge can be derived. This, for example, can be an option in ungauged basins.
The stochastic PQRUT model was applied to 20 catchments, located in different regions of Norway, and was compared with the results of statistical flood frequency analysis and the event-based PQRUT method, which is today used in standard practice. Due to the high uncertainty in estimating extreme floods, the application of the different methods produces differing results, as is often the case in practical applications. However, in this work we have shown that the stochastic PQRUT model gives estimates which generally are more similar to those obtained using a statistical flood frequency analysis based on the observed annual maximum series than are estimates obtained using a standard implementation of PQRUT. As it is not possible to test the reliability of estimates for the 500- or 1000-year flood (due to the length of the observed streamflow series relative to the return period of interest), the use of alternative methods for flood estimation, including stochastic simulations such as those presented here, is an essential component of flood estimation in practice.
The R package StochasticPQRUT (https://github.com/valeriyafilipova/StochasticPQRUT, last access: 21 December 2018) can be installed from github and contains sample data.
The authors declare that they have no conflict of interest.
This work has been supported by a PhD fellowship to Valeriya Filipova from
the University of Southeast Norway, Bø. Additional funds from the Energix FlomQ project supported by the
Norwegian Research Council and EnergiNorge have partially supported the
contributions of the co-authors to this work. The authors wish to thank
Emmanuel Paquet (EDF) for suggesting the use of a simple quantile score for
comparing the simulations with the observed higher quantiles and two
anonymous reviewers for their very detailed and helpful comments on the
manuscript.
Edited by: Bruno
Merz
Reviewed by: two anonymous referees
Alfieri, L., Laio, F., and Claps, P.: A simulation experiment for optimal design hyetograph selection, Hydrol. Process., 22, 813–820, https://doi.org/10.1002/hyp.6646, 2008. a
Andersen, J., Sælthun, N., Hjukse, T., and Roald, L.: Hydrologisk modell for flomberegning (Hydrological for flood estimation), Tech. rep., NVE, Oslo, 1983. a, b, c
Ball, J. E.: Australian Rainfall and Runoff: A Guide to Flood Estimation – Draft for Industry Comment 151205, Geoscience Australia, 2015. a
Beven, K. and Hall, J.: Applied Uncertainty Analysis for Flood Risk Management, edited by: Beven, K. and Hall, J., 684 pp., https://doi.org/10.1142/p588, 2014. a
Blanchet, J., Touati, J., Lawrence, D., Garavaglia, F., and Paquet, E.: Evaluation of a compound distribution based on weather pattern subsampling for extreme rainfall in Norway, Nat. Hazards Earth Syst. Sci., 15, 2653–2667, https://doi.org/10.5194/nhess-15-2653-2015, 2015. a
Brigode, P., Bernardara, P., Paquet, E., Gailhard, J., Garavaglia, F., Merz, R., Micovic, Z., Lawrence, D., and Ribstein, P.: Sensitivity analysis of SCHADEX extreme flood estimations to observed hydrometeorological variability, Water Resour. Res., 50, 353–370, https://doi.org/10.1002/2013WR013687, 2014. a, b
Brocca, L., Ciabatta, L., Massari, C., Camici, S., and Tarpanelli, A.: Soil moisture for hydrological applications: Open questions and new opportunities, Water, 9, 140, https://doi.org/10.3390/w9020140, 2017. a
Calver, A. and Lamb, R.: Flood frequency estimation using continuous rainfall-runoff modelling, Phys. Chem. Earth, 20, 479–483, https://doi.org/10.1016/S0079-1946(96)00010-9, 1995. a
Camici, S., Tarpanelli, A., Brocca, L., Melone, F., and Moramarco, T.: Design soil moisture estimation by comparing continuous and storm-based rainfall-runoff modeling, Water Resour. Res., 47, W05527, https://doi.org/10.1029/2010WR009298, 2011. a
Chow, V. T., Maidment, D. R., and Mays, L. W.: Applied Hydrology, 2nd ed., McGraw-Hill International Editions, 1988. a
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, 1st ed., Springer-Verlag, London, 2001. a
Filipova, V., Lawrence, D., and Klempe, H.: Regionalisation of the parameters of the rainfall–runoff model PQRUT, Hydrol. Res., 47, 748–766, 2016. a, b
Fleig, A. K., Andreassen, L. M., Barfod, E., Haga, J., Haugen, L. E., Hisdal, H., Melvold, K., and Saloranta, T.: Norwegian Hydrological Reference Dataset for Climate Change Studies, Tech. rep., Oslo, available at: http://publikasjoner.nve.no/rapport/2013/rapport2013_02.pdf (last access: 21 December 2018), 2013. a
Førland, E.: Manuel for beregning av påregnelige ekstreme nedbørverdier (Manuel for estimating probable extreme precipitation values), Tech. rep., DNMI, Oslo, 1992. a
Garavaglia, F., Gailhard, J., Paquet, E., Lang, M., Garçon, R., and Bernardara, P.: Introducing a rainfall compound distribution model based on weather patterns sub-sampling, Hydrol. Earth Syst. Sci., 14, 951–964, https://doi.org/10.5194/hess-14-951-2010, 2010. a, b
Gräler, B., van den Berg, M. J., Vandenberghe, S., Petroselli, A., Grimaldi, S., De Baets, B., and Verhoest, N. E. C.: Multivariate return periods in hydrology: a critical and practical review focusing on synthetic design hydrograph estimation, Hydrol. Earth Syst. Sci., 17, 1281–1296, https://doi.org/10.5194/hess-17-1281-2013, 2013. a
Gupta, H. V., Kling, H., Yilmaz, K. K., and Martinez, G. F.: Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling, J. Hydrol., 377, 80–91, https://doi.org/10.1016/j.jhydrol.2009.08.003, 2009. a
Haberlandt, U. and Radtke, I.: Hydrological model calibration for derived flood frequency analysis using stochastic rainfall and probability distributions of peak flows, Hydrol. Earth Syst. Sci., 18, 353–365, https://doi.org/10.5194/hess-18-353-2014, 2014. a
Hao, Z. and Singh, V. P.: Review of dependence modeling in hydrology and water resources, Prog. Phys. Geogr., 40, 549–578, https://doi.org/10.1177/0309133316632460, 2016. a
Katz, R. W., Parlange, M. B., and Naveau, P.: Statistics of extremes in hydrology, Adv. Water Resour., 25, 1287–1304, https://doi.org/10.1016/S0309-1708(02)00056-8, 2002. a
Kim, D., Cho, H., Onof, C., and Choi, M.: Let-It-Rain: a web application for stochastic point rainfall generation at ungaged basins and its applicability in runoff and flood modeling, Stoch. Env. Res. Risk A., 31, 1023–1043, https://doi.org/10.1007/s00477-016-1234-6, 2017. a
Kjeldsen, T. R.: The revitalised FSR/FEH rainfall-runoff method, Center of Ecology & Hydrology, 1–64, available at: http://nora.nerc.ac.uk/id/eprint/2637/1/KjeldsenFEHSR1finalreport.pdf (last access: 21 December 2018), 2007. a
Kobierska, F., Engeland, K., and Thorarinsdottir, T.: Evaluation of design flood estimates – a case study for Norway, Hydrol. Res., 49, 450–465, https://doi.org/10.2166/nh.2017.068, 2017. a, b
Lawrence, D., Paquet, E., Gailhard, J., and Fleig, A. K.: Stochastic semi-continuous simulation for extreme flood estimation in catchments with combined rainfall–snowmelt flood regimes, Nat. Hazards Earth Syst. Sci., 14, 1283–1298, https://doi.org/10.5194/nhess-14-1283-2014, 2014. a
Li, J., Thyer, M., Lambert, M., Kuczera, G., and Metcalfe, A.: An efficient causative event-based approach for deriving the annual flood frequency distribution, J. Hydrol., 510, 412–423, https://doi.org/10.1016/j.jhydrol.2013.12.035, 2014. a
Loukas, A.: Flood frequency estimation by a derived distribution procedure, J. Hydrol., 255, 69–89, https://doi.org/10.1016/S0022-1694(01)00505-4, 2002. a, b
Meynink, W. J. and Cordery, I.: Critical duration of rainfall for flood estimation, Water Resour. Res., 12, 1209–1214, https://doi.org/10.1029/WR012i006p01209, 1976. a
Midttømme, G. and Pettersson, L.: Retningslinjer for flomberegninger 2011, Tech. Rep. 4/2011, NVE, Oslo, available at: http://publikasjoner.nve.no/retningslinjer/2011/retningslinjer2011_04.pdf (last access: 21 December 2018), 2011. a, b
Mohr, M.: New Routines for Gridding of Temperature and Precipitation Observations for “seNorge. no”, Met. no Report, Oslo, 8, 2008, https://doi.org/10.1073/pnas.93.13.6830, 2008. a
Muzik, I.: Derived, physically based distribution of flood probabilities, Proceedings of the Yokohama Symposium, IAHS , Wallingford, 183–188, 1993. a
Nathan, R. J. and Bowles, D.: A Probability-Neutral Approach to the Estimation of Design Snowmelt Floods A Probability-Neutral Approach to the Estimation of Design Snowmelt Floods, Hydrology and Water Resources Symposium:Wai-Whenua, 125–130, 1997. a
NVE: NEVINA (Nedbørfelt-Vannføring-INdeks-Analyse) Lavvannsverktøy, available at: http://nevina.nve.no/ (last access: 21 December 2018), 2015. a
Nyeko-Ogiramoi, P., Willems, P., Mutua, F. M., and Moges, S. A.: An elusive search for regional flood frequency estimates in the River Nile basin, Hydrol. Earth Syst. Sci., 16, 3149–3163, https://doi.org/10.5194/hess-16-3149-2012, 2012. a
Onof, C., Chandler, R. E., Kakou, A., Northrop, P., Wheater, H. S., and Isham, V.: Rainfall modelling using Poisson-cluster processes: a review of developments, Stoch. Env. Res. Risk A., 14, 384–411, https://doi.org/10.1007/s004770000043, 2000. a
Paquet, E., Garavaglia, F., Garçon, R., and Gailhard, J.: The SCHADEX method: A semi-continuous rainfall-runoff simulation for extreme flood estimation, J. Hydrol., 495, 23–37, https://doi.org/10.1016/j.jhydrol.2013.04.045, 2013. a, b
Parkes, B. and Demeritt, D.: Defining the hundred year flood: A Bayesian approach for using historic data to reduce uncertainty in flood frequency estimates, J. Hydrol., 540, 1189–1208, https://doi.org/10.1016/j.jhydrol.2016.07.025, 2016. a
Rahman, A., Weinmann, P. E., Hoang, T. M. T., and Laurenson, E. M.: Monte Carlo simulation of flood frequency curves from rainfall, J. Hydrol., 256, 196–210, https://doi.org/10.1016/S0022-1694(01)00533-9, 2002. a
Ren, M., He, X., Kan, G., Wang, F., Zhang, H., Li, H., Cao, D., Wang, H., Sun, D., Jiang, X., Wang, G., and Zhang, Z.: A comparison of flood control standards for reservoir engineering for different countries, Water, 9, 152, https://doi.org/10.3390/w9030152, 2017. a
Salazar, S., Salinas, J. L., García-bartual, R., and Francés, F.: A flood frequency analysis framework to account flood-generating 60 factors in Western Mediterranean catchments, presented at 2017 STAHY, Warsaw, Poland, 21–22 September 2017. a
Salinas, J. L., Laaha, G., Rogger, M., Parajka, J., Viglione, A., Sivapalan, M., and Blöschl, G.: Comparative assessment of predictions in ungauged basins – Part 2: Flood and low flow studies, Hydrol. Earth Syst. Sci., 17, 2637–2652, https://doi.org/10.5194/hess-17-2637-2013, 2013. a
Schaefer, M. and Barker, B.: Stochastic Event Flood Model (SEFM), in: Mathematical models of small watershed hydrology and applications, edited by: Singh, V. P. and Frevert, D., chap. 20, 950, Water Resources Publications, Colorado, USA, 2002. a, b
Skaugen, T.: Studie av Skilltemperatur for snøved hjelp samlokalisert snøpute, nedbør og temperaturdata, Tech. rep., NVE, Oslo, 1998. a
Skaugen, T. and Onof, C.: A rainfall-runoff model parameterized from GIS and runoff data, Hydrol. Process., 28, 4529–4542, https://doi.org/10.1002/hyp.9968, 2014. a, b, c
Soetaert, K. and Petzoldt, T.: Inverse Modelling, Sensitivity and Monte Carlo Analysis in R Using Package FME, J. Stat. Softw., 33, 1–28, https://doi.org/10.18637/jss.v033.i03, 2010. a
Svensson, C., Kjeldsen, T. R., and Jones, D. A.: Flood frequency estimation using a joint probability approach within a Monte Carlo framework, Hydrolog. Sci. J., 58, 8–27, https://doi.org/10.1080/02626667.2012.746780, 2013. a, b
Tolson, B. A. and Shoemaker, C. A.: Dynamically dimensioned search algorithm for computationally efficient watershed model calibration, Water Resour. Res., 43, W01413, https://doi.org/10.1029/2005WR004723, 2007. a
Vormoor, K. and Skaugen, T.: Temporal Disaggregation of Daily Temperature and Precipitation Grid Data for Norway, J. Hydrometeorol., 14, 989–999, https://doi.org/10.1175/JHM-D-12-0139.1, 2013. a, b, c
Wilson, D., Fleig, A. K., Lawrence, D., Hisdal, H., Petterson, L. E., and Holmqvist, E.: A review of NVE's flood frequency estimation procedures, NVE Report, p. 52, 2011. a, b