the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 08 Nov 2018
| 08 Nov 2018
Quantification of extremal dependence in spatial natural hazard footprints: independence of windstorm gust speeds and its impact on aggregate losses
Laura C. Dawkins
David B. Stephenson
Natural hazards, such as European windstorms, have widespread effects that result in insured losses at multiple locations throughout a continent. Multivariate extreme-value statistical models for such environmental phenomena must therefore accommodate very high dimensional spatial data, as well as correctly representing dependence in the extremes to ensure accurate estimation of these losses. Ideally one would employ a flexible model, able to characterise all forms of extremal dependence. However, such models are restricted to a few dozen dimensions, hence an a priori diagnostic approach must be used to identify the dominant form of extremal dependence.
Here, we present various approaches for exploring the dominant extremal dependence class in very high dimensional spatial hazard fields: tail dependency measures, copula fits, and conceptual loss distributions. These approaches are illustrated by application to a data set of high-dimensional historical European windstorm footprints (6103 spatial maps of 3-day maximum gust speeds at 14 872 locations). We find there is little evidence of asymptotic extremal dependency in windstorm footprints. Furthermore, empirical extremal properties and conceptual losses are shown to be well reproduced using Gaussian copulas but not by extremally dependent models such as Gumbel copulas. It is conjectured that the lack of asymptotic dependence is a generic property of turbulent flows. These results open up the possibility of using geostatistical Gaussian process models for fast simulation of windstorm hazard fields.
- Article
(8581 KB) - Full-text XML
-
Supplement
(11734 KB) - BibTeX
- EndNote





Multivariate statistical models are increasingly used to explore the spatial characteristics of natural hazard footprints and quantify potential aggregate losses. For example, such models for European windstorms are used by academics and (re)insurers to create catalogues of possible events, explore loss potentials, and benchmark synthetic events from atmospheric models (Bonazzi et al., 2012; Youngman and Stephenson, 2016).
Natural hazards, such as European windstorms, have widespread effects, often causing insured losses at many locations throughout a continent. Therefore, statistical models for such hazards must accommodate very high dimensional data in order to represent the full hazard domain. Moreover, since natural hazards are rare events in the tail of the distribution, these statistical models must also correctly represent the dependence in the extremes to ensure valid inference and, hence, a realistic representation of the hazard's aggregate losses.
When modelling multivariate extremes, variables can be described as being either asymptotically dependent, where large values of the variables tend to occur simultaneously, or asymptotically independent, where the largest values rarely occur together (Coles et al., 1999). As noted by Wadsworth et al. (2017), examples of modelling joint extremes often assume asymptotic dependence in order to accommodate asymptotically justified extreme-value max-stable models, which can potentially lead to overestimation of the joint occurrences of extremes. The assumption of asymptotic dependence is common in the field of natural hazard research. Coles and Walshaw (1994) used a max-stable model for the dependence in maximum wind speeds in different directions, Blanchet et al. (2009) to model snow fall in the Swiss Alps, Huser and Davison (2013) to model extreme rainfall, and Bonazzi et al. (2012) to model windstorm hazard fields at pairs of locations in Europe. Indeed, Bonazzi et al. (2012) simply base this modelling assumption on being “in line with many examples found in the literature”. However, it is important to question this assumption of asymptotic dependence.
Two approaches are used for exploring, and correctly representing, extremal asymptotic dependence. Either one can estimate the dependence by fitting a suitably flexible extreme-value model capable of representing dependence and independence, or alternatively one can perform diagnostic tests to identify the dependence class, i.e. whether or not extremal dependence is present.
There is a growing literature in the area of flexible models for extremal dependence, originating from the bivariate tail model of Ledford and Tawn (1996). Wadsworth and Tawn (2012) developed a spatial model, involving inverted max-stable and max-stable models, able to incorporate both forms of extremal dependence. This model, however, requires the estimation of a large number of parameters and is only able to transition between dependence classes at a boundary point of the parameter space. Following this, Wadsworth et al. (2017) explored more flexible transitions between extremal dependence classes and developed a model able to represent a wider variety of dependence structures, although limited to the bivariate case. Huser et al. (2017) went on to develop a flexible extension of the Wadsworth et al. (2017) model using Gaussian scale mixtures, in which the two asymptotic dependence regimes are smoothly blended. As noted by Huser and Wadsworth (2018), however, this model either makes the transition between dependence class at a boundary point of the parameter space (as in Wadsworth and Tawn, 2012) or is inflexible in its representation of the asymptotic independence structure. Most recently, Huser and Wadsworth (2018) presented a flexible model able to provide a smooth transition between both extremal dependence classes using only a small number of parameters.
While these models provide advantages in terms of flexibility and are growing in their applicability to higher dimensions, none are computationally feasible yet for very high dimensional data sets (Huser and Wadsworth, 2018). For example, max-stable models for asymptotic dependence are limited in application to a few dozen variables due to the computational demand of existing fitting methods (de Fondeville and Davison, 2018). Hence, as noted by Huser and Wadsworth (2018), with the exception of the specific high-dimensional peaks-over-threshold model of de Fondeville and Davison (2018), truly high-dimensional inference for spatial extreme-value models has yet to be achieved.
Therefore, when aiming to model very high dimensional data, the alternative, a priori identification approach must be taken. Several studies have developed and/or employed diagnostic measures to identify the form of extremal dependence between variables. Ledford and Tawn (1996, 1997) developed a bivariate tail model in which one of the parameters, named the coefficient of tail dependence, is used within a diagnostic approach to help identify the bivariate extremal dependence class. Coles et al. (1999) introduced two extremal dependence coefficients, χ(p) and , characterising the conditional probability of a pair of locations exceeding the same high quantile threshold 1−p, for which the asymptotic limit (as p→0) provides a diagnostic of bivariate extremal dependence. Bortot et al. (2000) used pairwise scatter plots and empirical estimates of χ(p) and to diagnose the form of extremal dependence present in a three-dimensional data set of sea surge, wave height, and wave period in South West England. They found evidence for asymptotic independence and hence developed a multivariate Gaussian tail model for their data, derived from the joint tail of a multivariate Gaussian distribution with margins based on univariate extreme-value distributions. Similarly, Eastoe et al. (2013) applied the coefficient of tail dependence, the χ and measures, and the conditional extremes model of Heffernan and Tawn (2004) to estimate the form of extremal dependence in 3 hourly sea surface elevation maxima at 15 locations, identifying, in general, asymptotic dependence. Similarly, more recently, Kereszturi et al. (2015) employed the coefficient of tail dependence and χ and measures within a comprehensive theoretical framework to assess extremal dependence of North Sea storm severity along four strips of 14 locations within the North Sea.
In all of the above examples these diagnostic approaches are applied to a relatively small number of locations. Here we present an approach for systematically exploring the dominant form of extremal dependence within a high-dimensional natural hazard data set. Specifically, we demonstrate this approach using a large (6103 events) and very high dimensional data set (14 872 locations) of climate-model-generated European windstorm footprints.
We introduce the bivariate diagnostic measures of Ledford and Tawn (1996) and Coles (2001) in the context of our approach by initially using them to explore the bivariate extremal dependence in two pairs of locations within the European domain (London–Amsterdam and London–Madrid) and subsequently present an approach for systematically applying the same diagnostics throughout the high-dimensional domain. We use the simple extremal dependence measures of Ledford and Tawn (1996) and Coles (2001) as they are quick to compute and can therefore be calculated for many thousands of pairs of locations, which is important when exploring very high dimensional data.
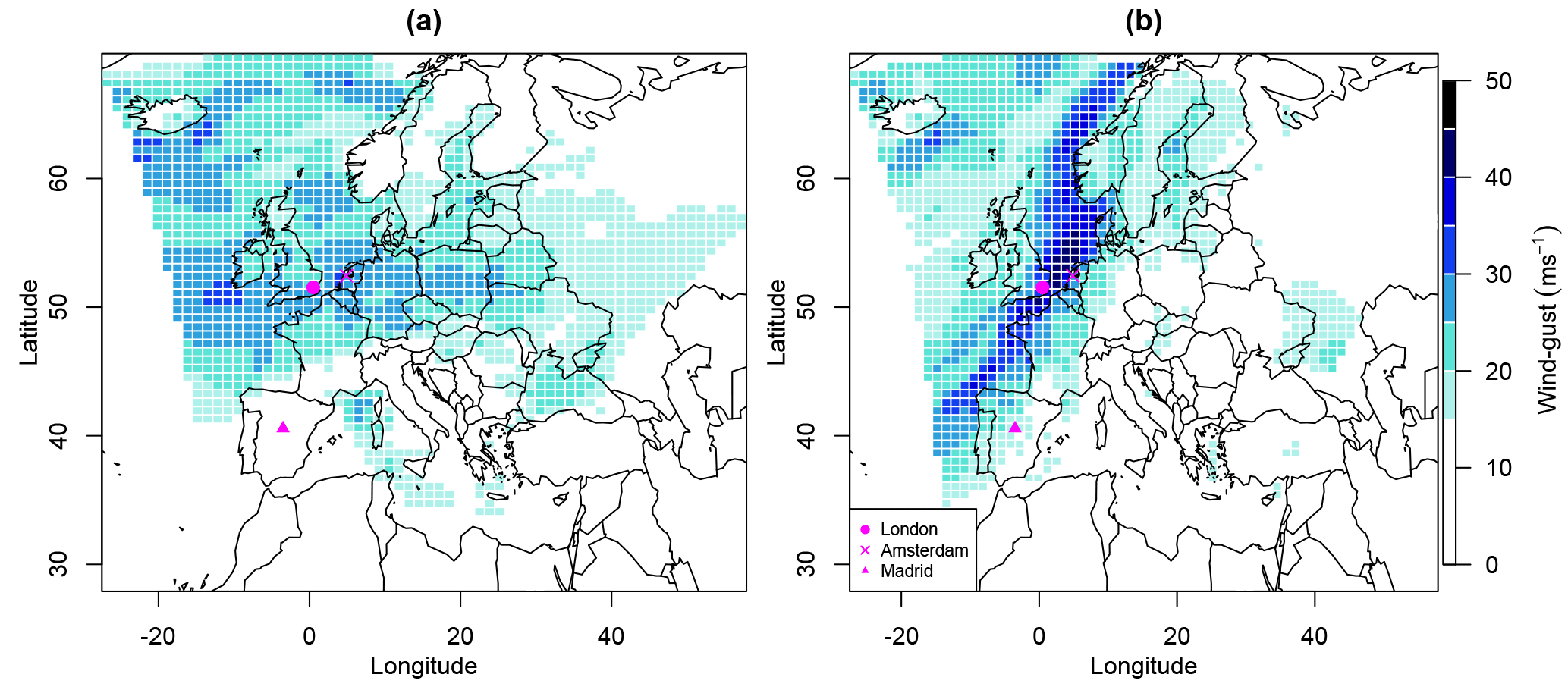
Figure 1Hazard footprints for windstorms (a) Kyrill and (b) the Great Storm of October 1987, with the location of the cities of London, Amsterdam, and Madrid indicated.
In addition, we contribute a further diagnostic, relevant for natural hazard modelling, by presenting an approach for exploring the impact of extremal dependence misspecification on conceptual aggregate hazard loss estimation. We use the Gaussian and Gumbel copula models, representing asymptotic independence and dependence respectively, to model pairs of locations, and quantify the discrepancy between modelled and observed joint conceptual losses. This approach is introduced for one central location, paired with all other locations in the high-dimensional domain, and then extended to systematically explore the full domain. The approaches presented in this paper can be used to explore extremal dependence and develop appropriate multivariate statistical models for other high-dimensional natural hazard data sets.
Section 2 describes the windstorm hazard data set used throughout this paper. Section 3 introduces and applies the extremal dependence diagnostics of Ledford and Tawn (1996) and Coles et al. (1999), initially to two pairs of locations and then to systematically explore the high-dimensional data domain. Section 4 demonstrates how extremal dependence influences conceptual aggregate losses. Section 5 presents ideas from turbulence theory for why wind gust speeds are likely to be asymptotically independent, and, finally, Sect. 6 concludes.
The windstorm footprint data set used in this study is the same as that used in Dawkins et al. (2016) and an extended version of the data set used in Roberts et al. (2014), consisting of the 6103 high-resolution model-generated windstorm footprints, for windstorm events that occurred within the European domain during the 35 extended winters (October–March) 1979/1980–2013/2014 (kindly provided by Jessica J. Standen and Julia F. Lockwood at the Met Office).
The windstorm footprint is defined as the maximum 3 s wind gust speed (in metres per second) at grid points in the region 35 to 70∘ N in latitude and 15∘ W to 25∘ E in longitude and over a 72 h period centred on the time at which the maximum 925 hPa wind speed occurred over land. The 925 hPa wind speed is taken from ERA-Interim reanalysis (Dee et al., 2011). The 3 s wind gust speed has a robust relationship with storm damage (Klawa and Ulbrich, 2003) and is commonly used in catastrophe models for risk quantification (Roberts et al., 2014). A 72 h windstorm duration is commonly used in the insurance industry (Haylock, 2011) and is thought to capture the most damaging phase of the windstorm (Roberts et al., 2014).
These 6103 historical windstorm events have been identified using the objective tracking approach of Hodges (1995), and the associated footprints are created by dynamically downscaling ERA-Interim reanalysis to a horizontal resolution of 25 km using the Met Office Unified Model (MetUM). As described by Roberts et al. (2014), the wind gust speeds are calculated from wind speeds in the MetUM model, based on a simple gust parameterisation, , where U10 m is the wind speed at 10 m altitude and σ is the standard deviation of the horizontal wind, estimated from the friction velocity using the similarity relation of Panofsky et al. (1977). The roughness constant C is determined from the universal turbulence spectra and is larger over rough terrain.
The MetUM-generated footprints for Kyrill (17–19 January 2007) and the Great Storm of October 1987 (15–17 October 1987) are shown in Fig. 1. The variability in the intensity and location of extreme, damaging winds in these footprints demonstrates the potential importance of correctly modelling the spatial dependence between locations for realistically representing joint losses.
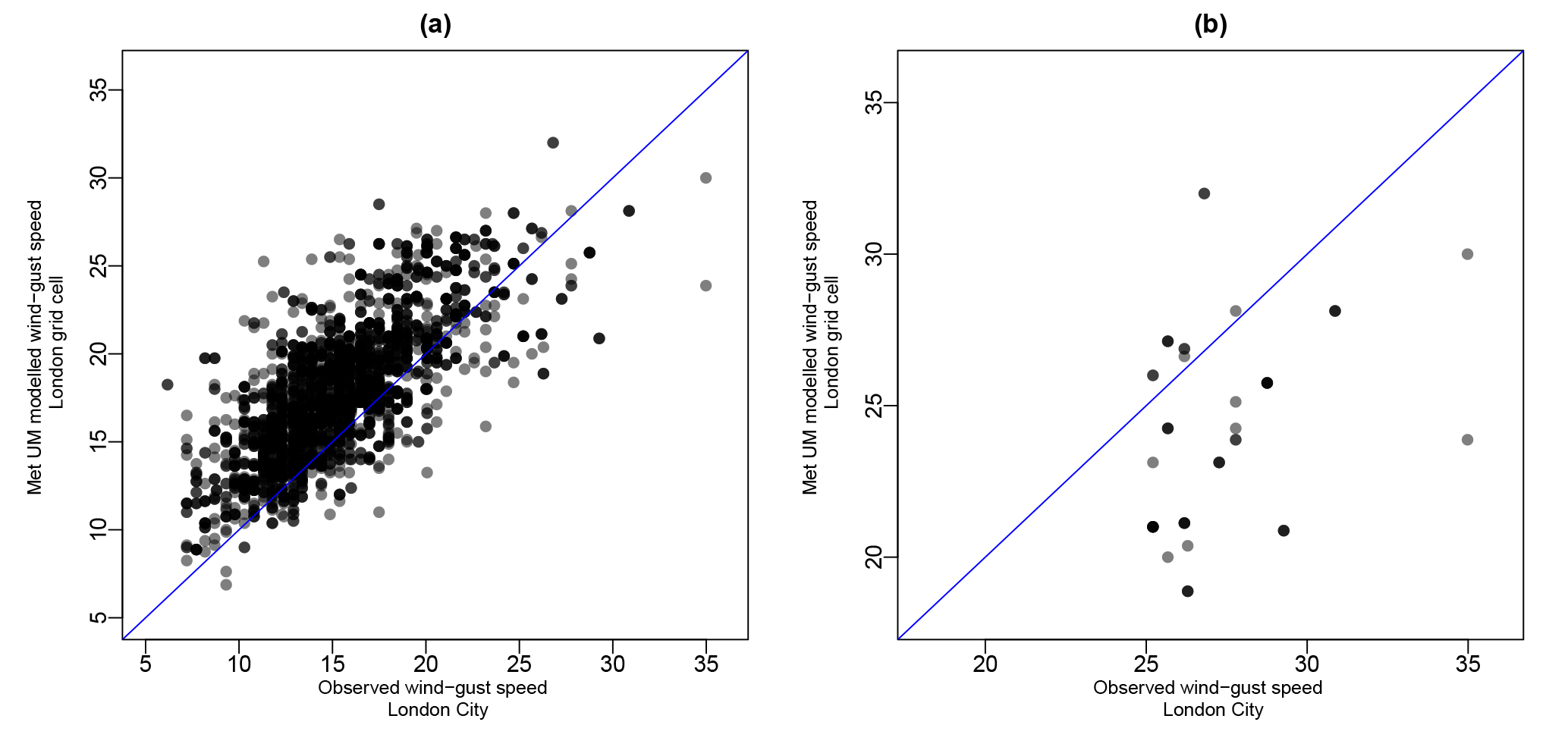
Figure 2(a) The relationship between MetUM windstorm footprint wind gust speeds in the London grid cell and the corresponding observed wind gust speeds at the London City Airport weather station within the Global Summary of the Day data set, and (b) the same relationship for the 50 most extreme windstorm events at the London City Airport weather station. In both plots the line y=x has been added for reference (blue).
Using model-generated windstorm footprints for representing historical storms has benefit in terms of spatial and temporal coverage; however these estimated maximum wind gust speeds will differ from those observed at nearby weather stations. For example, as noted by Roberts et al. (2014), several alternative methods for parameterising wind gust speeds are available (see Sheridan, 2011, for a review), which can lead to large differences in estimated gusts (10–20 m s−1). The validity of simplistic gust parameterisation stated above was evaluated by Roberts et al. (2014), who found an overestimation in the effect of surface roughness at stations greater than ∼500 m altitude, leading to an underestimation in MetUM-modelled extreme winds in these locations. In addition, Roberts et al. (2014) identified a slight underestimation in extreme wind gust speeds greater than ∼25 m s−1. This was found to be due to a number of mechanisms, including the underestimation of convective effects and strong pressure gradients, leading to the underdevelopment of fast-moving storms (Roberts et al., 2014).
To explore the possible discrepancy in the MetUM wind gust speed data relevant for this study, we extract daily maximum observed wind gust speed recorded at the London City Airport weather station (the station located within the London grid cell used throughout this study) from the Global Summary of the Day (GSOD) data repository and, for each of the 6103 windstorm events in our data set, find the maximum hourly observed gust in the 3-day period centred on the same date as in the MetUM-generated footprints. A comparison of the observed and MetUM-modelled footprint wind gusts in London is presented in Fig. 2a, indicating a general overestimation in modelled wind gust speeds below 25 m−1 and a slight underestimation for wind gust speeds above 25 m−1, reflecting the findings of Roberts et al. (2014). Figure 2b presents this same relationship for the 50 most extreme events in the observed data set, highlighting this underestimation of modelled extreme wind gust speeds. Indeed, the root-mean-squared difference between the observed and modelled footprint wind gust speeds for these 50 extreme events is 4.57 m s−1, which provides an estimate of the uncertainty in representing observed extreme windstorm gust speeds.
This discrepancy in model-generated wind gust speeds could lead to differences in results, namely the identification of the extremal dependence class between locations. To explore this possibility, we repeat the empirical analysis in Sect. 3 (Fig. 4) for GSOD data at London City Airport and Amsterdam Airport Schiphol, shown in Fig. S1 in the Supplement. We find that for this pair of locations the weather station and MetUM data have very similar relationships in the extremes, with the weather station data being slightly less dependent, therefore not changing the conclusions of this study.
As a motivating example, the bivariate dependence in windstorm footprint wind gust speeds for London paired with Amsterdam and Madrid is presented in Fig. 3a and c respectively. These three locations are shown in Fig. 1, and these two pairings are chosen because of their contrasting separation distances and hence degrees of dependence (as shown in Fig. S2). These scatter plots show a greater degree of dependence between London and Amsterdam compared to London and Madrid. Indeed, multiple windstorms have losses occurring in London and Amsterdam at the same time, where loss is associated with wind gust speeds exceeding the 0.99th quantile at a given location, characterised by the top right-hand corner of each plot in Fig. 3. However, does this level of dependence between London and Amsterdam necessarily suggest asymptotic dependence?
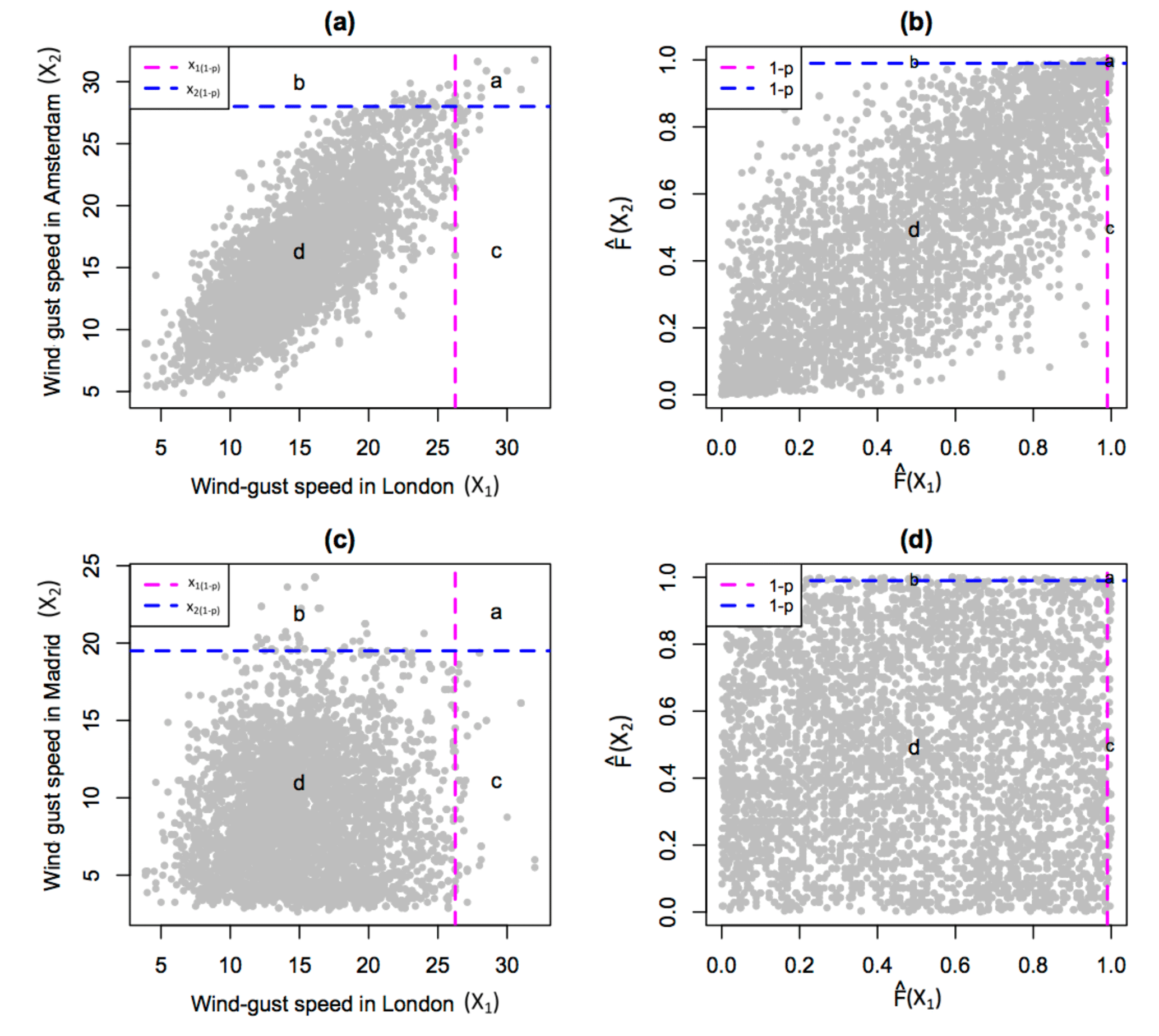
Figure 3Scatter plot comparing historical windstorm footprint wind gust speeds (m s−1) in London with those in (a) Amsterdam and (c) Madrid, and empirical copula plots for London paired with (b) Amsterdam and (d) Madrid. Dashed lines show the 0.99th quantile of wind gust speed at each location, and labels a–d represent the number of points in each section of each plot, related to being above or below these high quantile thresholds.
The wind gust speeds at any two locations can be represented by the n×2 pair of random variables (X1, X2), where n=6103 is the number of observations at each location. The joint distribution Pr(X1≤x1, X2≤x2) is determined by the marginal distributions of each variable (i.e. and ) and their joint dependence. It can be shown that Pr(X1≤x1, , , where is a bivariate function known as a copula (Nelson, 2006). In other words, the marginal distributions can be factored out by using the respective cumulative distribution functions to transform the variables into variables (, ) that have uniform distributions over the interval [0, 1]. A simple way to do this is to use the empirical cumulative distribution function (). This empirical copula approach simply amounts to considering the respective ranks of the X1 and X2 values divided by the sample size as shown in Fig. 3b and d.
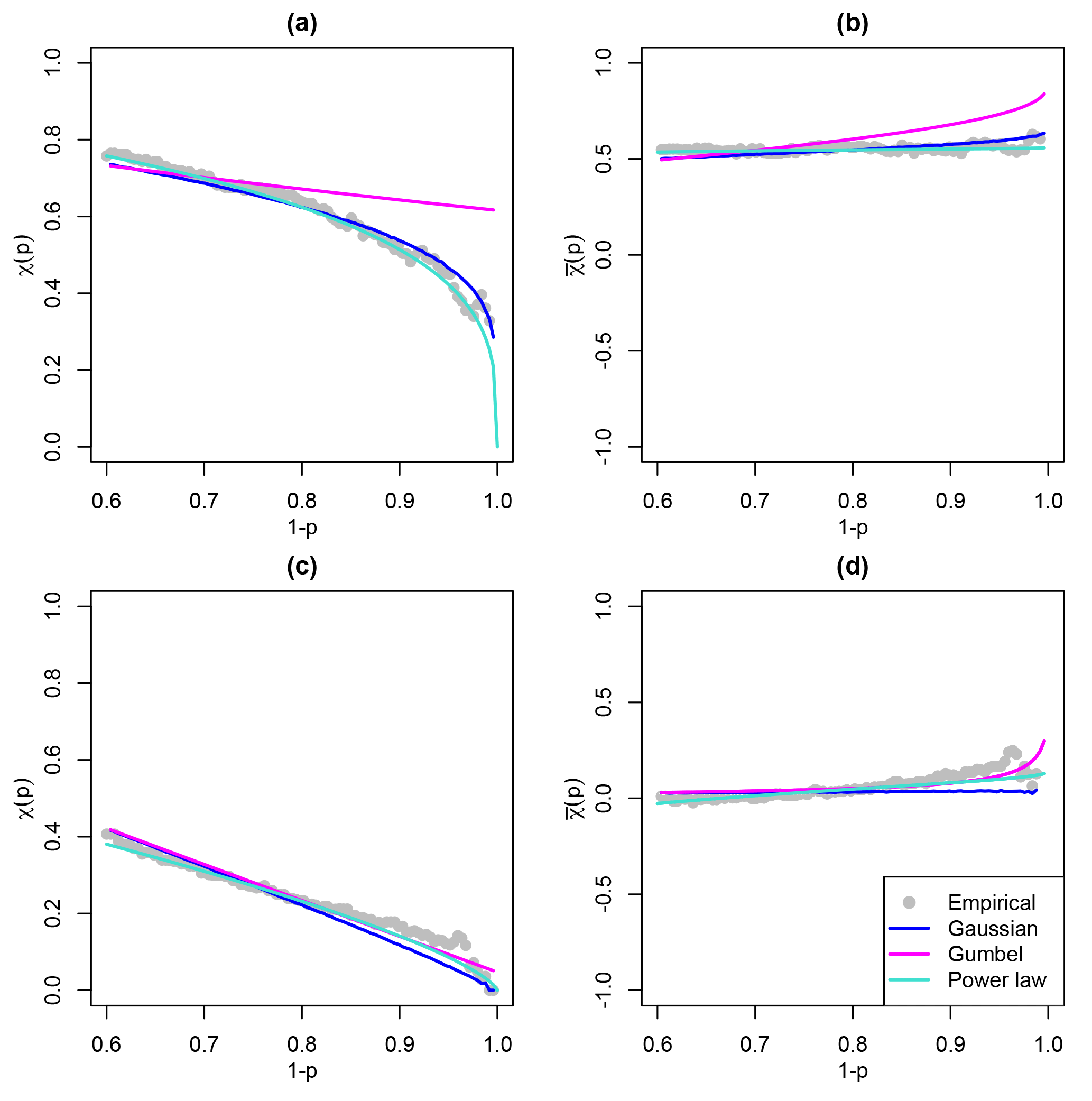
Figure 4Extremal dependence measure χ(p), for , for windstorm footprint wind gust speeds in London paired with (a) Amsterdam and (c) Madrid, and dependence measure , for , for windstorm footprint wind gust speeds in London paired with (b) Amsterdam and (d) Madrid, calculated empirically and based on the Gaussian, Gumbel, and power law bivariate dependence functions, as defined in Table A1.
3.1 Diagnostic measures
The degree of conditional dependence between X1 and X2 at a specified high quantile threshold, 1−p, can be explored, based on the empirical copula, using the extremal dependence measures, χ(p) and , introduced by Coles et al. (1999). The asymptotic limit of these measures, as p→0, can then be used to classify the class of bivariate extremal dependence between X1 and X2 as either asymptotically dependent or asymptotically independent. These measures are defined as
where x1(1−p) and x2(1−p) are the (1−p)th quantiles of X1 and X2 respectively, for all , and
where for all . Hence, if , , and the pair (X, Y) are said to be asymptotically dependent, with strength χ(0). If instead χ(0)=0, and hence , the pair are said to be asymptotically independent, and the non-vanishing measure represents the strength of this non-asymptotic dependence.
As an initial exploration of bivariate extremal dependence class between variables, these conditional probability measures can be calculated empirically over a range of quantile thresholds, as shown in Fig. 4 for windstorm footprint wind gust speeds in London paired with Amsterdam and Madrid. These empirical estimates are calculated as functions of the counts (a–d) in Fig. 3, as defined in Table A1. Based on these empirical estimates, for both pairs of locations, χ(p)→0 and as p→0, suggesting asymptotic independence.
However, here and as in all data sets of environmental phenomena, the rarity of very extreme events makes it impossible to empirically quantify the asymptotic limits χ(0) and , necessary for extremal dependence class identification. To overcome this, Ledford and Tawn (1996) developed a bivariate tail model, able to characterise both classes of extremal dependence, which when fit to a bivariate random variable can be used to predict the asymptotic limit of the conditional probability measures and hence give an estimate of the class of extremal dependence, based on the sub-asymptotic evidence in the data and the assumption that the model can be extrapolated to asymptotic levels.
As in Ledford and Tawn (1996), let Z1 and Z2 denote X1 and X2 transformed to Fréchet margins respectively; that is, . Then the joint survivor function for Z1 and Z2 above some large quantile threshold z1−p takes the form
where , is a constant and ℒ(z1−p) is a slowly varying function as p→0. Based on this power law model, as shown by Coles et al. (1999),
Hence, the parameter η, named the coefficient of tail dependence by Ledford and Tawn (1996), characterises the nature of the extremal dependence. When η=1, ) and ; hence the pair (X, Y) are asymptotically dependent on degree ℒ(z1−p). Alternatively, if η<1, χ(0)=0 and , and the pair are asymptotically independent with non-asymptotic dependence of degree 2η−1.
For a given pair, e.g. wind gust speeds in London and Amsterdam, the Ledford and Tawn (1996) model is fit to the joint survivor function along the diagonal, equivalent to the univariate distribution of T=min{Z1, Z2}, known as the structure variable, which has length n. Using the stable two-parameter Poisson process representation of T presented by Ferro (2007), who employed the Ledford and Tawn (1996) model for the verification of extreme weather forecasts, the exceedance of T above a high threshold w has the form
with location parameter α and scale parameter , equivalent to η in Eq. (3), estimated by maximum likelihood (Ferro, 2007).
Fitting this model to the pairs London–Amsterdam and London–Madrid requires the specification of the high threshold, w, above which the Poission process model is fit. As discussed by Ferro (2007), this threshold selection is a trade-off between being low enough that enough data are retained to ensure model precision, but high enough that the extreme-value theory that motivates the model provides accurate estimates. In a similar way to choosing the appropriate threshold when fitting a generalised Pareto distribution (see Coles, 2001), empirical diagnostic plots can be used to inform this selection. These include parameter stability plots, in which the estimated model parameters and mean excess should be constant above the chosen high threshold, and quality of fit plots, in which the transformed excesses, , should be exponentially distributed if an appropriately high threshold has been chosen (see Ferro, 2007, for more details).
Here, the 85 % quantile of the structural variable T is selected, based on these diagnostic plots (example for London–Amsterdam is presented in Fig. S3). This choice is similar to the 0.88 % and 0.9 % thresholds selected in the applications of Ferro (2007) and Ledford and Tawn (1996) respectively. Based on this choice of w, for London–Amsterdam and for London–Madrid, indicating asymptotic independence for both pairs of locations. This is further demonstrated in Fig. 4, which shows how the Ledford and Tawn (1996) model, referred to as the power law model, calculated as in Table A1, represents the conditional dependence measures χ(p) and as p→0, for London–Amsterdam and London–Madrid.
In addition, as a comparison (included in Fig. 4), alternative parametric bivariate dependence models known as the Gaussian and Gumbel copulas are used to model the pair (X1, X2) to give further indication of the extremal dependence class present.
The Gumbel bivariate copula model characterises asymptotic dependence with
the degree of dependence quantified by parameter r. For each pair of
locations, this parameter is estimated via maximum likelihood using the
copula R package. The Gaussian bivariate model characterises
asymptotic independence with dependence parameter ρ, here represented by
the Spearman's rank correlation coefficient. Both models are fit to the full
bivariate data pair, as presented in Fig. 3. For the Gumbel model
the data are transformed to uniform margins using the empirical distribution
function. The same transformation is made for the Gaussian model, followed by
a transformation to Gaussian margins using the standard normal distribution
function. The parametric forms of χ(p) and for these two
opposing models are shown in Table A1. In Fig. 4, the
Gumbel model is calculated as in Table A1; however, since the
closed-form definition for the Gaussian model in Table A1 only
holds for the limit p→0, for this model χ(p) and
are estimated as the median of 1000 parametric bootstrap simulations from the
associated bivariate normal distribution.
For both pairs of locations in Fig. 4, all three parametric bivariate dependence models indicate asymptotic independence. The power law model estimates χ(0)=0 and , the Gaussian model matches closely with the empirical estimates and the power law model, and the Gumbel model overestimates the conditional probability of joint extremes.
As a final diagnostic, analogous to that used by Ledford and Tawn (1996, 1997), the coefficient of tail dependence is estimated for a range of high thresholds, w, to explore the sensitivity of the parameter estimate to this choice. As in Ledford and Tawn (1996, 1997), here this diagnostic observes the proportion of time η=1 is within the profile likelihood confidence interval for η, when estimated using w in the interval of the 0.5–1 quantile of T. The pair (X1, X2) are said to be asymptotically dependent if η=1 is contained within these confidence intervals for a majority of the range of w and asymptotically independent otherwise. This exploration is presented for London paired with Amsterdam and Madrid in Fig. 5, providing further evidence of asymptotic independence for both pairs, based on this criterion.
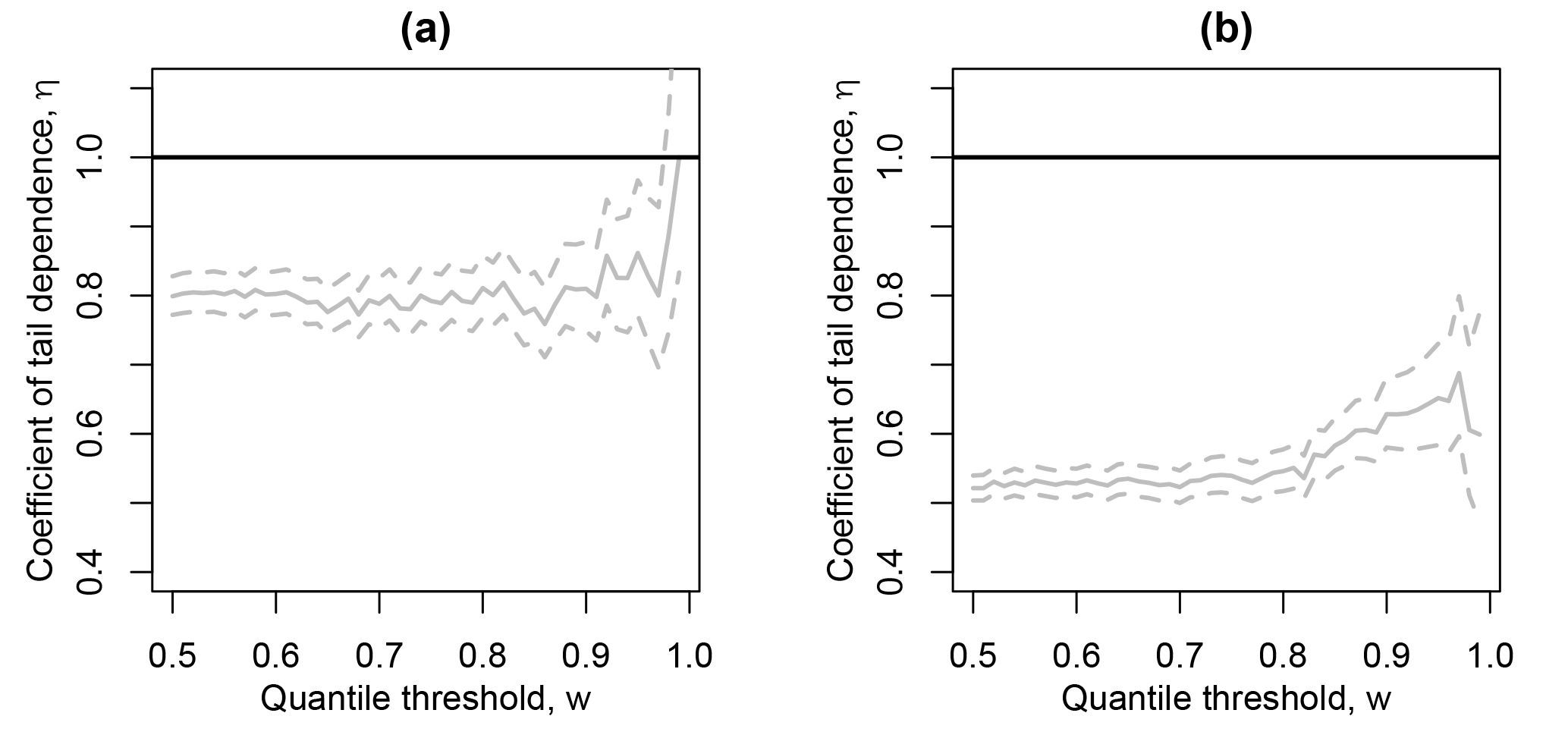
3.2 Extension to high dimensions
We now demonstrate a way of extending the quick-to-calculate coefficient of tail dependence diagnostic approach to systematically explore the dominant extremal dependence class across locations in a high-dimensional hazard field.
We first take a stratified (based on the distribution of locations over longitude and latitude) sample of 100 locations within the European domain. One such sample is shown in Fig. 6a. Since the extremal dependence is likely to decrease with increasing separation distance (Wadsworth and Tawn, 2012) and we hope to understand if asymptotic independence is dominant and hence present at small separation distances, for each of these 100 locations, we estimate the coefficient of tail dependence, η (and the associated 95 % profile likelihood confidence interval), when paired with the 100 nearest locations within the full domain. Figure 6b demonstrates how the 100 nearest locations are geographically distributed for one such sampled location in our windstorm footprint data set. For each pairing, the coefficient of tail dependence is calculated using w as the 0.9 quantile threshold of the structure variable, found to ensure stable estimates of η using diagnostic plots as in Fig. 6c. The estimated η parameters and confidence intervals for these 100×100 pairs of locations are plotted against separation distance to explore how, throughout the domain, η varies at small separation distances and changes with increasing separation distance, shown in Fig. 6d. The parameter estimate related to the pair of locations in pink and blue in Fig. 6b is shown in pink. This method is repeated many times with 10 such repetitions shown in Fig. S4, showing very similar results.
Figure 6d shows that for small separation distances (<180 km) a proportion of pairs of locations have coefficient of tail dependence parameters, η, close to 1, with η=1 within the confidence interval indicating asymptotic dependence. Within the range (0–50 km) 69 % of pairs of locations exhibit this behaviour; however this proportion reduces rapidly as separation distance increases, to 30 % for locations separated by (50–100 km), 13 % for locations separated by (100–150 km), and 3 % for locations separated by (150–200 km). Hence, while there is evidence of asymptotic dependence for some locations in close proximity, even at very small separation distances (50 km) a larger proportion of locations exhibit asymptotic independence. Indeed, here and in Fig. S4, beyond a separation distance of approximately 200 km the coefficient of tail dependence parameter estimates drop well below 1, indicating asymptotic independence. Therefore, since separation distances within the domain extend to up to 3500 km, we conclude that asymptotic independence is the dominant extremal dependence structure across the spatial domain.
It is important to consider the validity of representing even this small proportion of asymptotically dependent pairs of locations incorrectly as asymptotically independent. To explore this, Bortot et al. (2000) carried out a simulation study in which they fit the Gaussian, Ledford and Tawn (1996), and Gumbel models to bivariate data simulated from three parent populations with different classes of extremal dependence. They concluded that, for asymptotically independent parent populations the Gaussian copula is able to provide accurate inferences for tail probability estimates, outperforming the Gumbel copula model. Indeed, even for asymptotically dependent parent populations, the estimation error of the Gaussian copula model was deemed to be acceptably small (Bortot et al., 2000). This suggests that, when data dimensionality prohibits the use of flexible extremal dependence models (e.g. Huser and Wadsworth, 2018) and asymptotic independence is found to be the dominant extremal dependence structure across the spatial domain, using an asymptotically independent model, such as the Gaussian tail model, is preferable over using a model for asymptotic dependence.
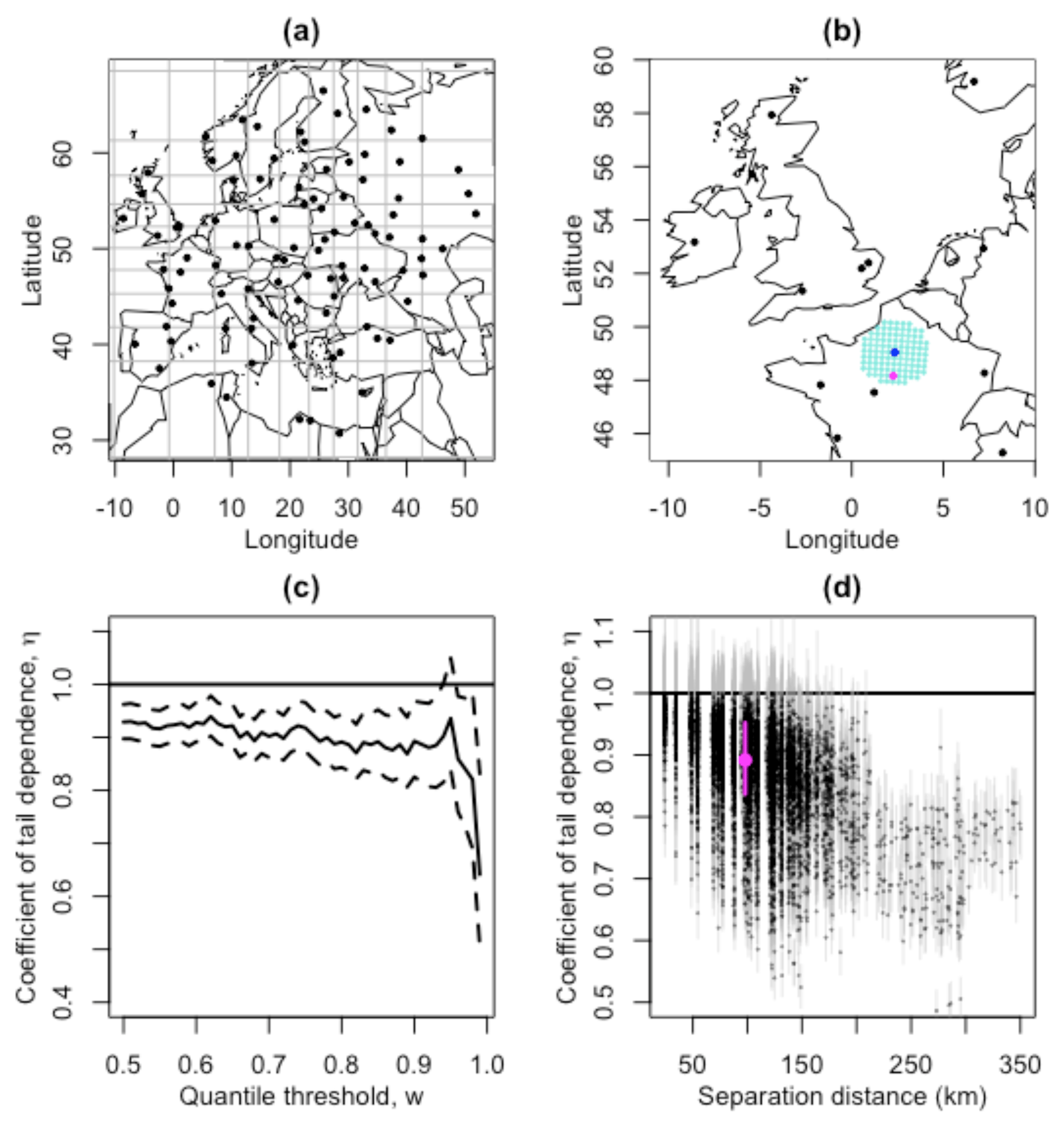
Figure 6(a) A stratified (based on the distribution of locations over longitude and latitude) sample of locations within the European domain, with stratified grid shown in grey; (b) a demonstration of the 100 nearest locations (turquoise) to one of these sampled locations (blue), with one such point selected at random (pink); (c) the coefficient of tail dependence diagnostic plot (as in Fig. 5) for wind gusts at the blue location paired with the pink location; (d) the coefficient of tail dependence (estimated using w as the 90 % quantile threshold of the structure variable) and 95 % profile likelihood confidence intervals, for each of the 100 sampled locations paired with their 100 nearest locations in the full domain, plotted against separation distance in kilometres, with the estimate based on the pair of locations in (b) and (c) added in pink.
We now contribute a natural hazard loss perspective for exploring the dominant extremal dependence class, providing further justification of the selected dependence model. We define a conceptual hazard loss function and explore the impact of misspecifying the extremal dependence class on aggregate hazard loss estimation, using the Gaussian and Gumbel copula models previously introduced. We present this approach initially based on one central location (London) and then demonstrate how this can be extended to systematically explore a high-dimensional hazard field.
Similar to other natural hazard perils, in the absence of confidential insurance industry exposure and vulnerability information, it has become common in the literature to define conceptual windstorm event loss as a function of the footprint wind gust speeds over the spatial domain (see Dawkins et al., 2016, for a review). While these conceptual windstorm loss functions vary in the detail of their composition, it is generally possible to express these loss functions as special cases of the generic loss function:
where are the m locations in the spatial domain; V is a vulnerability function representing the damage caused by the hazard; ej represents exposure at location j (e.g. population density); u(Xj) quantifies a high threshold of the wind gust speed above which losses occur; and 𝟙(x) is an indicator function such that 𝟙(x)=1 if x is true and 𝟙(x)=0 otherwise. For example, in the widely used and rigorously validated conceptual loss function of Klawa and Ulbrich (2003), , u(X)=x0.98 (the 0.98th quantile of X), and ej is the population density at location j, whereas Cusack (2013) used a loss function in which , u(X)=x0.99 (the 0.99th quantile of X), and ej=1 for all j. See Table 2.1 in Dawkins (2016) for a summary of previously published conceptual loss functions in terms of the components of Eq. (5).
More recently, Roberts et al. (2014) presented an exploration of the success of a number of these conceptual windstorm loss functions in representing insured loss throughout the European domain, based on the same data set as in this study, with the aim of developing a method for selecting extreme storms for the eXtreme WindStorms (XWS) catalogue. While there is much published work on the existence of a relationship between loss severity and the magnitude of the wind, in particular the cubed excess wind as used in the loss functions of Klawa and Ulbrich (2003) and Cusack (2013), Roberts et al. (2014) found that a conceptual loss function representing just the area in which the windstorm footprint exceeds a high loss threshold (i.e. V(Xj)=1 and ej=1 for all j in Eq. 5) to be more successful at characterising a subset of extreme windstorms known to have caused large insured losses. It should be noted, however, that this exploration did not include population density within the Klawa and Ulbrich (2003) loss function and was therefore not a direct comparison of this measure. In addition, an alternative subjectively selected subset of extreme storms may have given an alternative result. The success of this simplistic loss function could also be due to its relative insensitivity to errors in components of the loss estimate not well represented by the climate-model-generated footprints and may not perform as well if applied to wind gust observations.
In this study we propose a similar threshold exceedance conceptual loss function to that used in Roberts et al. (2014) and Dawkins et al. (2016). Roberts et al. (2014) used an exceedance threshold of 25 m s−1, while Dawkins et al. (2016) used a threshold of 20 m s−1, as is commonly used by German insurance companies (Klawa and Ulbrich, 2003). Here, similar to Klawa and Ulbrich (2003) and Cusack (2013), we propose a locally varying wind gust speed quantile threshold, accounting for local adaptation to varying wind intensity. We find that the 0.99th quantile of windstorm footprint wind gust speed is in excess of the commonly used 20 m s−1 loss threshold for most land locations in Europe, with a higher loss threshold used in regions where stronger winds occur (as shown in Fig. S5).
Since, for a given storm event at any pair of locations, e1V(X1) and e2V(X2) in Eq. (5) are constants, this equation can be simplified to
where and . In our case , and u(X1)=x1(0.99) and u(X2)=x2(0.99), the 0.99th quantiles of X1 and X2 respectively. Therefore, while in this study we use just one conceptual loss function in which the magnitude of the loss is always equal to 1, it is simple to adapt the following analysis to accommodate alternative loss functions in which the vulnerability function is not constant across locations.
The probability mass function of the bivariate conceptual loss function can easily be obtained in terms of the extremal dependence coefficient, χ(p), by considering the joint probability of (X1, X2) in each of the quadrants shown in Fig. 3:
The distribution of loss is completely determined by p (which is chosen here to be 0.01) and χ(p), and so χ(0.01) can be used to diagnose and explore the consequence of extremal dependence assumptions on loss estimation. It should be noted that the expected loss, 𝔼(L(X1, X2)), does not depend on χ(p). This is because the expectation of a sum is the sum of the expectations; hence expected total loss over two or more locations is simply the sum of the expected losses at each location and so is unaffected by the amount of dependency between sites.
To compare how well the Gaussian and Gumbel models represent our empirical bivariate conceptual loss function, we can therefore compare estimates for χ(p) and for our specified loss threshold p=0.01, calculated based on each model, with those calculated empirically (as in Table A1). We present the resulting difference in these estimates for London paired with all other land locations in the European domain in Fig. 7.
Figure 7 demonstrates how well the Gaussian model is able to represent empirical χ(0.01) throughout the domain. Conversely the Gumbel model can be seen to greatly overestimate χ(0.01) for all pairs of locations. The Gaussian model also well reproduces for locations not too distant from London, with this distance being greater in the west–east direction, reflecting the common path of storms over Europe (Hoskins and Hodges, 2002). The Gumbel model greatly overestimates for all locations except those in very close proximity to London.
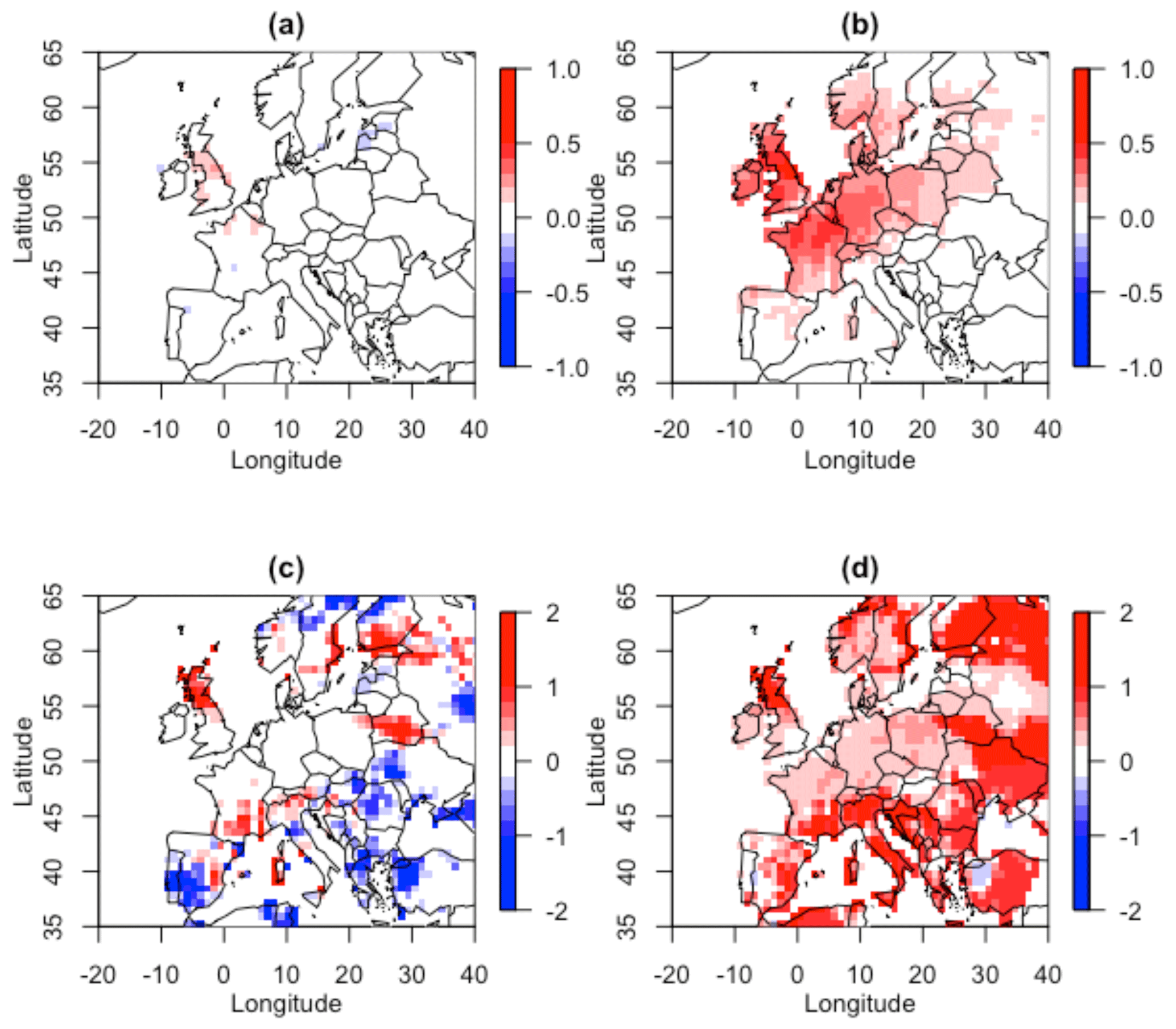
Figure 7The difference between empirical and modelled χ(0.01) for (a) the Gaussian model and (b) the Gumbel model, and the difference between empirical and modelled (0.01) for (c) the Gaussian model and (d) the Gumbel model, for London paired with all other locations over land.
As well as being relevant for representing the probability mass function of the bivariate conceptual loss function, χ(p) can also be shown to characterise the conditional expectation of joint loss:
The conditional first moment of the loss distribution in Eq. (7) can therefore be used to compare how well the different dependency models represent the size of the joint losses, rather than just their conditional probability of occurrence, since the expression includes and . Here, ; hence the conditional expectation of joint loss is equivalent to the conditional expectation of loss jointly occurring at both locations given a loss has occurred at one location.
Figure 8 presents a comparison of the distribution of the conditional expected joint loss for London paired with each land location in our European domain, given a loss has occurred in London, when calculated empirically and using the two opposing dependence models.
Figure 8 further illustrates the importance of correctly specifying extremal dependence class when representing loss. When a conceptual loss occurs in London, the Gumbel dependence model overestimates the expected conditional joint loss with other European land locations, while, conversely, the Gaussian model provides a very good estimate of the empirical expected conditional joint loss distribution.
Extension to high dimensions
We extend the analysis in Fig. 7 to systematically explore the high-dimensional domain by fitting both the Gaussian and Gumbel models to a stratified sample of 100 locations paired with each of the other 99 locations and, for each pair, plot the difference between empirical and modelled χ(0.01) against their separation distance, shown in Fig. 9.
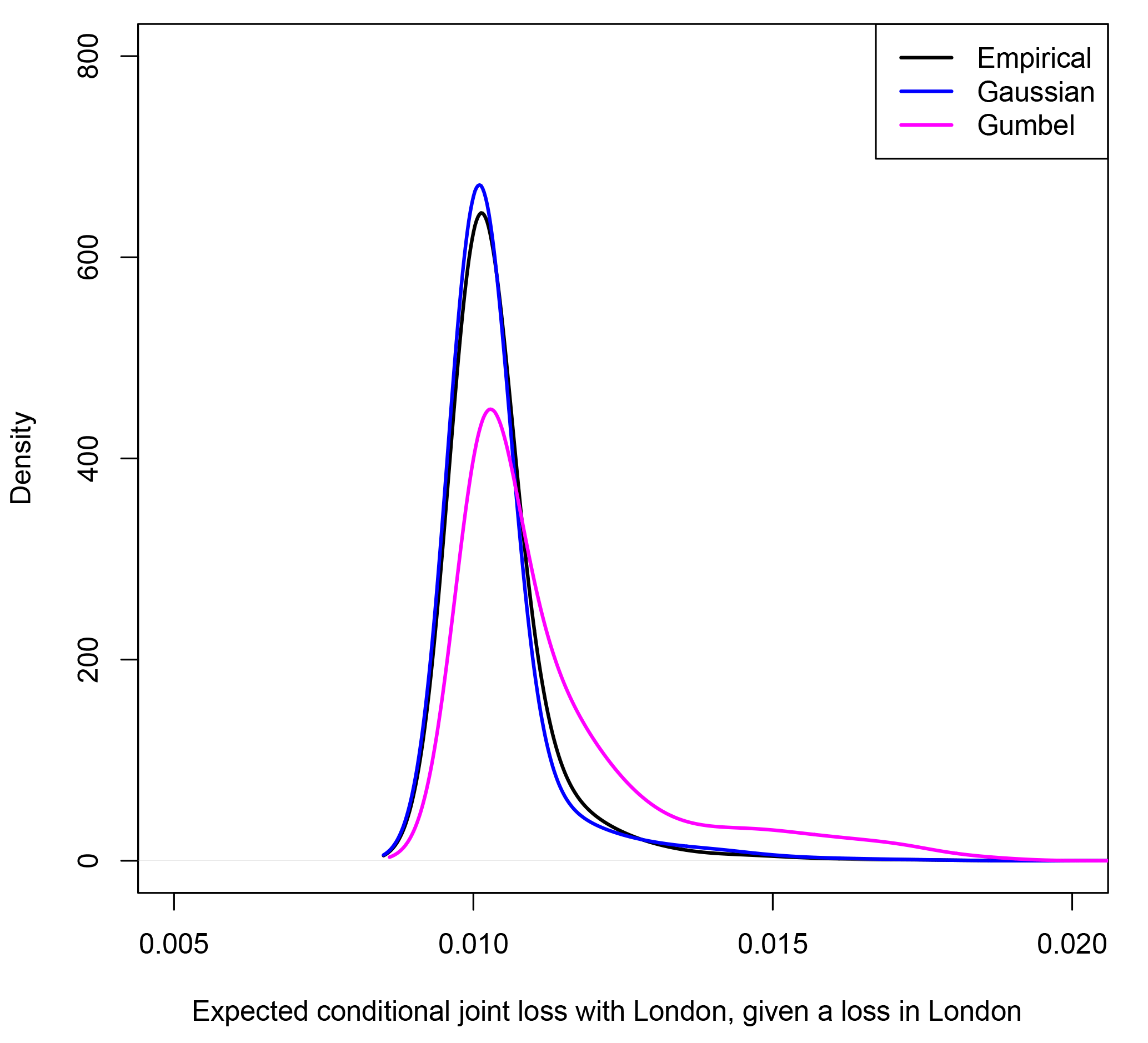
Figure 8For all land locations in the European domain, the conditional expected joint loss with London, given a loss has occurred in London (Eq. 7), calculated empirically and using the Gaussian and Gumbel copula models.

Figure 9The difference between empirical and modelled χ(0.01) for a stratified sample of 100 locations paired with each of the other 99 locations, plotted against separation distance for (a) the Gaussian model and (b) the Gumbel model.

Figure 10For a stratified sample of 100 locations within the windstorm footprint domain, the difference between modelled and empirical relative frequencies of binned ranges of expected conditional joint loss for (a) the Gaussian model and (b) the Gumbel model.
This domain-wide comparison indicates that, while the Gaussian model slightly over- and underestimates empirical χ(0.01) at small separation distances, this model consistently outperforms the Gumbel model, which overestimates χ(0.01) for all separation distances, even very small ones. This indicates, as in Fig. 6, that a majority of nearby locations do not exhibit asymptotic dependence as they are not well represented by the Gumbel model, further supporting the diagnosed dominance of extremal independence throughout the European domain.
Finally, we extend the analysis in Fig. 8 to systematically explore the high-dimensional domain by replacing London as the location of origin, with each location within a stratified sample of 100 locations. For each of these 100 locations, Fig. 10 presents the difference between modelled and empirical relative frequencies of binned ranges of conditional expected joint loss, separately for the Gaussian and Gumbel models, i.e. representing the difference between the modelled and empirical density plots in Fig. 8, but for 100 locations rather than one. Figure 10b identifies that the discrepancy between the empirical and Gumbel estimates of conditional expected joint loss shown in Fig. 8 is consistent throughout the domain, with lower values being under-represented and higher values over-represented by the Gumbel model. In a similar way, Fig. 10a shows that the Gaussian model performs equally well for these 100 locations, with much smaller discrepancy compared to the Gumbel model, as found in Fig. 8.
In this windstorm footprint application, we found that, while the Gumbel model is able to represent some pairs of locations at very small separation distances, where asymptotic dependence is suggested by the coefficient of tail dependence, this model greatly misrepresents the joint-tail behaviour and hence the conditional probability of joint loss for a majority of pairs and separation distances. Conversely, the Gaussian model is able to represent the joint-tail behaviour relevant for loss estimation for locations within close proximity to each other, as well as further apart.
As previously mentioned, alternative windstorm loss thresholds have been implemented in other studies, for example the 0.98th quantile in Klawa and Ulbrich (2003), and the fixed thresholds of 20ms−1 in Bonazzi et al. (2012) and Dawkins et al. (2016) and 25 m s−1 in Lamb and Frydendahl (1991) and Roberts et al. (2014). An exploration of the effect of the choice of loss threshold and, indeed loss function, on how the opposing dependence models represent joint losses would be an extremely interesting area of further investigation but is beyond the scope of this study. Dawkins (2016) goes some way in addressing this by presenting a comparison for the 0.98th quantile and 25 m s−1 fixed loss thresholds in the same form as Fig. 7. Dawkins (2016) found that the overall suitability of the opposing models remained the same for both thresholds, although the discrepancy of the Gumbel model was slightly smaller for the lower, 0.98th quantile loss threshold. This was thought to be because modelled exceedances further from the upper limit of the joint distribution were less sensitive to a misspecification of the extremal dependence characteristic in the Gumbel model.
It is of interest to ask whether there might be fundamental fluid dynamical reasons for why extreme wind gust speeds should be asymptotically independent at different spatial locations. One approach to answering this question is to consider extremal dependence in turbulent flows. The atmospheric flow in storm track regions is highly chaotic and irregular and is therefore turbulent rather than smoothly varying laminar flow (see Held, 1999, and references therein). Furthermore, over short enough spatial distances, the horizontal flow in a storm may be considered to be stationary in space and directionally invariant, in other words, homogeneous isotropic turbulence.
It is useful to first consider the more tractable problem of dependency in simultaneous wind speeds rather than maximum wind speeds over a given time period. The dependency between maximum gust speeds over 3 days will not generally be less than the dependency between simultaneous wind gust speeds because maximum wind gusts for a storm do not occur at the same time at different locations. However, for locations that are close to one another, maximum gust speeds for fast-moving extreme storms will occur within a short time window (e.g. within around 3 h or less for extreme storms over the UK), and so simultaneous results become more relevant.
As originally proposed by Von Kármán (1937), turbulent wind fields can be efficiently and realistically simulated using stochastic processes (Mann, 1998). This approach is widely used for many applications such as testing loads on new aircraft designs. The basic assumption in homogeneous turbulence is that the Cartesian velocity components are independent Gaussian processes, each with a prescribed spatial covariance function. In the special case of isotropic turbulence, the spatial covariance functions are identical for each velocity component. Hence, for two-dimensional windstorm gusts, the wind gust speed at spatial location j is given by , where uj and vj are independent Gaussian processes having identical covariance functions.
The distribution of each velocity component is expected, by the central limit theorem, to be close to normally distributed since the net displacement of a particle in turbulence is the result of many irregular smaller displacements. The distribution of each component has zero skewness due to the symmetry of the fluid equations (negative deviations are as likely as positive ones) but can have slightly more kurtosis (i.e. fatter tails) than the normal distribution due to intermittency in the flow. Measurements of velocity components in the atmospheric surface layer reveal that the distributions are near to Gaussian (e.g. Chu et al., 1996).
So what can be deduced about the extremal dependence class of wind speeds from such turbulence models? Firstly, as shown in example 5.32 of McNeil et al. (2005), since the individual velocity components are bivariate normal, the individual velocity components are asymptotically independent at different locations; e.g. u1 and u2 are asymptotically independent when locations j=1 and j=2 differ, and likewise for v1 and v2. Furthermore, it can be shown that the square of each velocity component is also asymptotically independent (see Appendix).
The squared wind speeds at pairs of locations are sums of two such independent components, (, , ), and so it would be counter-intuitive if somehow these sums were not also asymptotically independent. Unfortunately proof of asymptotic independence between (, ) (and hence (X1, X2)) remains elusive. Nevertheless, the conjecture can be explored using numerical simulation.

Figure 11Simulation of wind speeds at two sites having highly correlated velocities (see main text for details): (a) scatter plot of squared wind speeds at the two sites (1000 points randomly sampled out of the million); (b) joint versus marginal exceedance probabilities (on logarithmic axes). The dot shows an example obtained by counting the fraction of points in the upper right and the right-hand quadrants of (a). The curve has a steeper slope than the dashed line (equal probabilities denoting complete dependence), suggesting asymptotic independence.
By simulating velocities from bivariate normal distributions, we have found no evidence of extremal dependence in wind speeds even when each velocity component is highly correlated. Figure 11 shows an example obtained by simulating a million wind speeds at two locations where the u and v velocity components are independent standard normal variates each with correlation of 0.9 between locations (i.e. the correlation between u1 and u2 is 0.9). The squared wind speeds at each location are chi-squared distributed with 2∘ of freedom but are not independent: there is positive association clearly visible in Fig. 11a. To assess extremal dependence, Fig. 11b shows how the joint exceedance probability, , , and the marginal exceedance probability, , behave as threshold t2 is varied. As the threshold is increased, the joint probability drops to zero faster than the marginal exceedance probability (the curve in Fig. 11b is steeper than the dashed line), which suggests that the ratio, the conditional probability of exceedance, equivalent to χ in Eq. (1), will tend to zero in the asymptotic limit.
This study has demonstrated how to use the extremal dependence diagnostics of Coles et al. (1999) and Ledford and Tawn (1996) along with the Gaussian and Gumbel copula models to explore and identify the dominant extremal dependence class in a very high dimensional natural hazard field. Furthermore, we have explicitly shown how extremal dependency determines conceptual aggregate loss functions and have revealed how sensitive the aggregate loss distribution is to misspecification of extremal dependency.
These methods present strong evidence for asymptotic independence in windstorm footprint hazard fields, contrary to what has been assumed in previous studies such as Bonazzi et al. (2012). The misspecification of this extremal dependency (e.g. by using a Gumbel copula) has been shown to lead to severe overestimation of the aggregate losses. Stochastic turbulence theory suggests that asymptotic independence of wind speeds is a generic property of turbulent flows as seen in windstorm footprints. These results provide justification that simulated windstorm hazard fields can be represented by a Gaussian geostatistical model (Dawkins, 2016; Youngman and Stephenson, 2016).
The windstorm footprint data set used in this paper is not available, but 50 of the 6103 storms can be accessed in the XWS catalogue at http://www.europeanwindstorms.org/ (European Wind Storms, 2018).
Table A1Empirical and parametric forms for extremal dependence measures χ(p) and .

Assume the velocity components (u1, v1) and (u2, v2) at two separate locations in an isotropic turbulent flow can be represented as bivariate normally distributed vectors (u1, u2) and (v1, v2) that are independent and identically distributed with zero expectations.
The individual velocity components, (u1, u2) and (v1, v2), are both asymptotically independent because of each being bivariate normally distributed.
The squares of the individual velocity components, e.g. (, ), are also asymptotically independent. This is proven by rewriting the joint probability of exceedance:
which is obtained by noting that , and conditional probabilities and by symmetry of the bivariate normal distribution about (0, 0). Since the components are bivariate normal, and as t→∞, and so Pr(u12>t2, . Hence, the square of the velocity component is also asymptotically independent.
Perhaps rather counter-intuitively, the sum of two independent identically distributed asymptotically independent variables is not necessarily asymptotically independent. It, therefore, remains to be proven whether or not (, ) is asymptotically independent.
The supplement related to this article is available online at: https://doi.org/10.5194/nhess-18-2933-2018-supplement.
Sections 1–4 of this study were developed and written by LD, based on chap. 3 of her PhD thesis, supervised by DS. Section 5 was conceived and written by DS.
The authors declare that they have no conflict of interest.
Laura C. Dawkins was supported by the Natural Environment Research Council
(Consortium on Risk in the Environment: Diagnostics, Integration,
Benchmarking, Learning and Elicitation – CREDIBLE project; NE/J017043/1).
Edited by: Joaquim G. Pinto
Reviewed by: three anonymous referees
Blanchet, J., Marty, C., and Lehning, M.: Extreme value statistics of snowfall in the Swiss Alpine region, Water Resour. Res., 45, W05424, https://doi.org/10.1029/2009WR007916, 2009. a
Bonazzi, A., Cusack, S., Mitas, C., and Jewson, S.: The spatial structure of European wind storms as characterized by bivariate extreme-value Copulas, Nat. Hazards Earth Syst. Sci., 12, 1769–1782, https://doi.org/10.5194/nhess-12-1769-2012, 2012. a, b, c, d, e
Bortot, P., Coles, S., and Tawn, J.: The multivariate Gaussian tail model: an application to oceanographic data, Appl. Stat., 49, 31–49, 2000. a, b, c
Chu, C. R., Parlange, M. B., Katul, G. G., and Albertson, J. D.: Probability density functions of turbulent velocity and temperature in the atmospheric surface layer, Water Resour. Res., 32, 1681–1688, 1996. a
Coles, S. G.: An Introduction to Statistical Modeling of Extreme Values, Springer, London, 2001. a, b, c
Coles, S. G. and Walshaw, D.: Directional Modelling of Extreme Wind Speeds, J. Roy. Stat. Soc. C, 43, 139–157, 1994. a
Coles, S. G., Heffernan, J., and Tawn, J.: Dependence Measures for Extreme Value Analysis, Extremes, 2, 339–365, 1999. a, b, c, d, e, f, g, h
Cusack, S.: A 101 year record of windstorms in the Netherlands, Climatic Change, 116, 693–704, 2013. a, b, c
Dawkins, L. C.: Statistical modelling of European windstorm footprints to explore hazard characteristics and insured loss, PhD thesis, University of Exeter, College of Engineering Mathematics and Physical Sciences, Exeter, 2016. a, b, c, d
Dawkins, L. C., Stephenson, D. B., Lockwood, J. F., and Maisey, P. E.: The 21st century decline in damaging European windstorms, Nat. Hazards Earth Syst. Sci., 16, 1999–2007, https://doi.org/10.5194/nhess-16-1999-2016, 2016. a, b, c, d, e
de Fondeville, R. and Davison, A. C.: High-dimensional peaks-over-threshold inference, Biometrika, 0, 1–18, 2018. a, b
Dee, D., Uppala, S. M., Simmons, A. J., Berrisford, P., Poli, P., Kobayashi, S., Andrae, U., Balmaseda, M. A., Balsamo, G., Bauer, P., Bechtold, P., Beljaars, A. C. M., van de Berg, L., Bidlot, J., Bormann, N., Delsol, C., Dragani, R., Fuentes, M., Geer, A. J., Haimberger, L., Healy, S. B., Hersbach, H., Hólm, E. V., Isaksen, L., Kallberg, P., Kohler, M., Matricardi, M., McNally, A. P., Monge-Sanz, B. N., Morcrette, J. J., Park, B. K., Peubey, C., de Rosnay, P., Tavolato, C., Thepaut, J. N., and Vitart, F.: The ERA Interim reanalysis: configuration and performance of the data assimilation system, Q. J. Roy. Meteorol. Soc., 137, 553–597, 2011. a
Eastoe, E. F., Koukoulas, S., and Jonathan, P.: Statistical measures of extremal dependence illustrated using measured sea surface elevations from a neighbourhood of coastal locations, Ocean Eng., 62, 68–77, 2013. a
European Wind Storms: Extreme Wind Storms (XWS) Catalogue, available at: http://www.europeanwindstorms.org/, last access: 7 November 2018. a
Ferro, C. A. T.: A Probability Model for Veryfiying Deterministic Forecasts of Extreme Events, Weather Forecast., 22, 1089–1100, 2007. a, b, c, d, e
Haylock, M. R.: European extra-tropical storm damage risk from a multi-model ensemble of dynamically-downscaled global climate models, Nat. Hazards Earth Syst. Sci., 11, 2847–2857, https://doi.org/10.5194/nhess-11-2847-2011, 2011. a
Heffernan, J. E. and Tawn, J. A.: A conditional approach for multivariate extreme values, J. Roy. Stat. Soc. B, 66, 497–546, 2004. a
Held, I. M.: The macroturbulence of the troposphere, Tellus A, 51, 59–70, 1999. a
Hodges, K. I.: Feature Tracking on the Unit Sphere, Mon. Weather Rev., 123, 3458–3465, 1995. a
Hoskins, B. J. and Hodges, K. I.: New Perspectives on the Northern Hemisphere Winter Storm Tracks, J. Atmos. Sci., 59, 1041–1061, 2002. a
Huser, R. G. and Davison, A. C.: Space–time modelling of extreme events, J. Roy. Stat. Soc. B, 76, 439–461, 2013. a
Huser, R. G. and Wadsworth, J. L.: Modeling spatial processes with unknown extremal dependence class, J. Am. Stat. Assoc., in press, 2018. a, b, c, d, e
Huser, R. G., Opitz, T., and Thibaud, E.: Bridging asymptotic independence and dependence in spatial extremes using Gaussian scale mixtures, Spatial Stat., 21, 166–186, 2017. a
Kereszturi, M., Tawn, J., and Jonathan, P.: Assessing extremal dependence of North Sea storm severity, Ocean Eng., 118, 242–259, 2015. a
Klawa, M. and Ulbrich, U.: A model for the estimation of storm losses and the identification of severe winter storms in Germany, Nat. Hazards Earth Syst. Sci., 3, 725–732, https://doi.org/10.5194/nhess-3-725-2003, 2003. a, b, c, d, e, f, g
Lamb, H. and Frydendahl, J.: Historic Storms of the North Sea, British Isles and Northwest Europe, Cambridge University Press, Cambridge, 1991. a
Ledford, A. W. and Tawn, J. A.: Statistics for near independence in multivariate e xtreme values, Biometrika, 83, 169–187, 1996. a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p
Ledford, A. W. and Tawn, J. A.: Modelling Dependence within Joint Tail Regions, J. Roy. Stat. Soc., 59, 475–499, 1997. a, b, c
Mann, J.: Wind field simulation, Probabil. Eng. Mech., 13, 269–282, 1998. a
McNeil, A. J., Frey, R., and Embrechts, P.: Quantitative Risk Management: Concepts, Techniques, Tools, Princeton University Press, Princeton, 2005. a
Nelson, R. B.: An Introduction to Copulas, 2nd Edn., Springer, New York, 2006. a
Panofsky, H. A., Tennekes, H., Lenschow, D. H., and Wyngaard, J. C.: The characteristics of turbulent velocity components in the surface layer under convective conditions, Bound.-Lay. Meteorol., 11, 355–361, 1977. a
Roberts, J. F., Champion, A. J., Dawkins, L. C., Hodges, K. I., Shaffrey, L. C., Stephenson, D. B., Stringer, M. A., Thornton, H. E., and Youngman, B. D.: The XWS open access catalogue of extreme European windstorms from 1979 to 2012, Nat. Hazards Earth Syst. Sci., 14, 2487–2501, https://doi.org/10.5194/nhess-14-2487-2014, 2014. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Sheridan, P.: Review of techniques and research for gust forecasting and parameterisation: Forecasting Research Technical Report 570, Tech. rep., Met Office, Exeter, UK, 2011. a
Von Kármán, T.: The fundamentals of the statistical theory of turbulence, J. Aeronaut. Sci., 4, 131–138, 1937. a
Wadsworth, J. L. and Tawn, J. A.: Dependence modelling for spatial extremes, Biometrika, 99, 253–272, 2012. a, b, c
Wadsworth, J. L., Tawn, J. A., Davison, A. C., and Elton, D. M.: Modelling across extremal dependence classes, J. Roy. Stat. Soc. B, 79, 149–175, 2017. a, b, c
Youngman, B. D. and Stephenson, D. B.: A geostatistical extreme-value framework for fast simulation of natural hazard events, Proc. Math. Phys. Eng. Sci., 472, 20150855, https://doi.org/10.1098/rspa.2015.0855, 2016. a, b
- Abstract
- Introduction
- Data
- Extremal dependency
- A conceptual loss diagnostic approach
- Why are wind gust speeds asymptotically independent?
- Conclusion
- Data availability
- Appendix A
- Appendix B: Proof of independence in stochastic models of turbulent flows
- Author contributions
- Competing interests
- Acknowledgements
- References
- Supplement
- Abstract
- Introduction
- Data
- Extremal dependency
- A conceptual loss diagnostic approach
- Why are wind gust speeds asymptotically independent?
- Conclusion
- Data availability
- Appendix A
- Appendix B: Proof of independence in stochastic models of turbulent flows
- Author contributions
- Competing interests
- Acknowledgements
- References
- Supplement