the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 03 May 2023
| 03 May 2023
Probabilistic and machine learning methods for uncertainty quantification in power outage prediction due to extreme events
Prateek Arora
Luis Ceferino
Strong hurricane winds damage power grids and cause cascading power failures. Statistical and machine learning models have been proposed to predict the extent of power disruptions due to hurricanes. Existing outage models use inputs including power system information, environmental parameters, and demographic parameters. This paper reviews the existing power outage models, highlighting their strengths and limitations. Existing models were developed and validated with data from a few utility companies and regions, limiting the extent of their applicability across geographies and hurricane events. Instead, we train and validate these existing outage models using power outages from multiple regions and hurricanes, including hurricanes Harvey (2017), Michael (2018), and Isaias (2020), in 1910 US cities. The dataset includes outages from 39 utility companies in Texas, 5 in Florida, 5 in New Jersey, and 11 in New York. We discuss the limited ability of state-of-the-art machine learning models to (1) make bounded outage predictions, (2) extrapolate predictions to high winds, and (3) account for physics-informed outage uncertainties at low and high winds. For example, we observe that existing models can predict outages higher than the number of customers (in 19.8 % of cities with an average overprediction ratio of 5.2) and cannot capture well the outage variance for high winds, especially above 70 m s−1. Our findings suggest that further developments are needed for power outage models for proper representation of hurricane-induced outages.
- Article
(4493 KB) - Full-text XML
-
Supplement
(2572 KB) - BibTeX
- EndNote





Hurricanes can cause significant damage to the power distribution systems, resulting in large power failures and losses of billions of US dollars (Smith, 2020). Strong winds from hurricanes can destroy the exposed overhead distribution lines in a power grid and cause cascading power failures. For example, Hurricane Isaias (2020) damaged old power infrastructure and caused more than 2 million power outages across the US. More than a million outages occurred in New Jersey (https://www.nytimes.com/2020/08/04/nyregion/isaias-ny.html, last access: 21 September 2022) even though Hurricane Isaias had transitioned to a tropical storm when it hit New Jersey, reducing its sustained winds to 25 m s−1 (Latto et al., 2021). To address this issue, the US Department of Energy (DOE) has prioritized investing in enhancing power infrastructure resilience (National Academies of Sciences, Engineering, and Medicine, 2017). The Senate of the US passed the Grid Research Security Research and Development Act (2020) with a budget of 573 million US dollars to be spent from 2020–2025 to improve grid security to withstand shocks and rapidly recover from disruptions (Congress.gov, 2020).
Hurricane-induced power interruptions can cause billions of dollars in losses and long-lasting impacts on vulnerable communities. The power outages caused by storms can last for several hours to weeks and even months (https://www.reuters.com/business/environment/, last access: 16 February, 2023). Large-scale power blackouts show the vulnerability of the power grid to hurricanes, e.g., (1) 8.1 million homes lost power during Superstorm Sandy (2012) (Sheppard and DiSavino, 2012), (2) 1.7 million consumers in the southeast United States lost power in the aftermath of Hurricane Michael (2018) (EIA.GOV, 2018), and (3) Hurricane Ida (2021) was responsible for 1.2 million electrical outages (AJOT, 2021). Critical infrastructure systems such as hospitals and fire departments are especially vulnerable since they need to have the power restored within a few hours after a power outage to respond to the disaster (Ceferino et al., 2018, 2020).
Utilities must first assess the vulnerabilities in their power system infrastructure to enhance their resilience to hurricanes. Researchers have developed machine learning models to help utilities evaluate their vulnerabilities to predicting the extent of power outages from hurricanes. These outage models use inputs including hurricane winds, power systems, environmental information, and demographic information. Outage prediction models can assist utilities in planning and placing their resources before and during an extreme event for an emergency response to rapidly recover the failed power distribution systems (Arab et al., 2016). These models can also inform about the existing vulnerabilities, so utilities can also plan for grid hardening before a hurricane damages the power grid (Ouyang and Dueñas-Osorio, 2014).
Liu et al. (2005) developed a negative binomial generalized linear model (GLM) to predict the power outages in North and South Carolina. This model used hurricane parameters such as maximum wind speeds and duration of wind speeds over 20 m s−1; environmental parameters including land cover, tree type, soil drainage properties, and precipitation; and utility information on the number of transformers and customers. The model included only a specific utility, which limited the use of the outage model in other regions. The model also included a storm indicator, making the model not applicable to hurricanes with different characteristics than the ones in the training data. Liu et al. (2007) also presented an accelerated failure time model to estimate the power outage duration. Next, Liu et al. (2008) investigated the spatial correlation of power outages through spatial generalized linear mixed models (GLMMs) but did not observe any significant improvements in power outage prediction.
Han et al. (2009b) also developed a negative binomial GLM to predict outages in the Gulf Coast based on extensive information on hurricane parameters, additional environmental indicators (e.g., precipitation, soil moisture, tree type, land cover), and system information (e.g., number of poles, number of transformers). This model did not include any specific utility and storm indicators and instead used only generalizable features (e.g., wind speed, precipitation) to make the model applicable to any hurricanes. Han et al. (2009a) also developed generalized additive models (GAMs) with the same input features as GLMs. GAMs showed an improved accuracy over GLMs in power outage predictions because GAMs can effectively model the highly non-linear behavior of outages and the input parameters; e.g., precipitation and soil moisture can have non-linear effects on power outages (Han et al., 2009a).
Guikema et al. (2010) and Quiring et al. (2011) used decision tree models, classification and regression trees (CART), and Bayesian additive decision trees (BART), with additional topological and soil parameters, to better capture the variability of power outages. Decision trees provide a flexible way to represent the non-linear relation between input parameters and outages. More recently, researchers developed decision trees-based machine learning methods, which are robust to outliers and noise, called random forest (Breiman, 2001), to predict power outages caused by storms. Random forest regression is an extension of decision tree methods for regression. A series of parallel decision trees are fit in the random forest regression method to capture non-linearity and achieve high predictive accuracy. Nateghi et al. (2014) calibrated a random forest model to outage data from the Gulf Coast. Nateghi et al. (2014) used six input parameters to capture the damaging effects of trees on power lines. These six input parameters included 3 s gust wind speed, duration of strong winds, soil moisture at different depths, the number of customers served, and tree-trimming practices used to predict outages. Later, Guikema et al. (2014) used only publicly available data to develop a hurricane outage prediction model, independent of utility-specific input parameters, with random forest regression using 3 s gust wind speed, strong winds, and the number of customers served.
Maderia (2015) improved accuracy in power outage predictions with random forest models by including information on tree species. Tonn et al. (2016) used quantile regression forests (Li and Peng, 2011) to predict power outages at different confidence intervals. Guikema et al. (2014) and McRoberts et al. (2018) developed a two-stage zero-inflated power outage prediction model to better account for zero outages. The first stage of such a model is classification to predict outages or no outages. The second stage is the random forest regression to predict the count of outages on the point classified as having an outage. Wanik et al. (2017) used a random forest model with lidar-derived tree height data to predict power outages. Shashaani et al. (2018) developed a three-stage power outage prediction model to improve the accuracy of power outage predictions further. The first stage of the model is a binary classification to predict the location of outages; the second intermediate stage is the clustering of outage locations into a low, moderate, and large number of outages to address high right-skewness of non-zero outage data points; and the third stage is the prediction of the number of outages.
Previously, researchers have used more complex power outage prediction models, namely neural networks, kernel methods such as support vector machines, and other tree-ensemble methods, such as AdaBoost, which can model non-linear relationships between input parameters and outages (Xie et al., 2020). Kankanala et al. (2014) employed AdaBoost to predict weather-related power outages. Kankanala et al. (2014) trained a separate model for each city for daily use, and they did not cover extreme weather outages. Eskandarpour et al. (2018) and Eskandarpour and Khodaei (2018) used power grid component-level data with support vector machines. Rudin et al. (2012) ranked the power grid components (feeder failures, cables, joints, terminators, and transformers) based on their vulnerability to extreme weather events. Haseltine and Eman (2017) used a neural network to predict the failure of the power grid components for pre-storm planning. Such models will require specialized high-resolution power grid component-level data for each city, which are not accessible given the data protocols of utility companies. Sun et al. (2018) used Twitter (https://twitter.com; last access: 13 January 2023) data to predict real-time outages. Jaech et al. (2018) used repair log data employing natural processing with a recurrent neural network to predict real-time outage durations. However, tweets (https://twitter.com; last access: 13 January 2023) and repair logs were available after the hurricane made an impact on the city. Thus, leveraging repair logs is not possible to predict outages for pre-event planning ahead of a storm. Hence, data availability limits the applicability of these methods at a large scale for power outage predictions from extreme events.
GLM (Liu et al., 2005), GAM (Han et al., 2009a), and random-forest-based power outage prediction models (Guikema et al., 2014; McRoberts et al., 2018; Shashaani et al., 2018) provide outage predictions at a coarser level compared to predictions at component. However, these models are mostly based on open-source, publicly available data and can be generalized at a larger scale to the coastal cities in the United States. Hurricane-caused outages are mostly at the transmission level, which is responsible for city-wide outages (Brown, 2002) (https://poweroutage.us/faq, last access: 13 January 2023) rather than the customer meter level. So, predicting city-wide outages can still guide utilities to arrange for crews and emergency backup power ahead of a storm. Hence, for this paper, we focus on GLM, GAM, and random-forest-based power outage prediction models. As the power outage data are generally not made publicly available by the utilities, the previous models are primarily calibrated to data from a few regions. For example, Liu et al. (2005, 2007, 2008) developed the outage prediction model for North and South Carolina. Guikema et al. (2014), Nateghi et al. (2014), and Shashaani et al. (2018) developed the outage prediction models for the Gulf Coast. This paper addresses this gap by calibrating and validating existing models to extensive outage data from New Jersey, New York, Florida, and Texas at the city level. Thus, we investigate the generalized behavior of power outage models across the United States and focus on publicly available input variables to make our calibrated models widely applicable.
In this paper, Sect. 2 describes the input features, data sources, and data preprocessing used in the model development for power outage prediction. Section 3 explains the selection of important and uncorrelated input features for model development. GLM, GAM, and random forest power outage models are described in Sects. 4, 5, and 6, respectively. Section 7 describes the results for calibrated models and compares performance with the previous models in the literature. Section 8 highlights the limitations of existing state-of-the-art power outage prediction models to (1) make bounded outage predictions, (2) extrapolate for high winds, and (3) account for physics-informed uncertainties at low and high winds. Section 9 summarizes the findings of this paper.
We acquired power outage data from PowerOutage (https://poweroutage.us/, last access: 21 September 2022), an organization that tracks and records outages from utilities at the city level across the US. The automatic outage reporting points of utilities could be hindered during hurricanes, which could result in errors in outage counts (https://poweroutage.us/faq, last access: 13 January 2023). However, PowerOutage (https://poweroutage.us/, last access: 21 September 2022) regularly gets updates from utilities to keep the outage count close to actual outages. The data covered the power outages for Hurricane Isaias (2020) for 11 utilities in New York and 5 in New Jersey, for Hurricane Michael (2018) for 5 utilities in Florida, and for Hurricane Harvey (2017) for 39 utilities in Texas. Our dataset has about 3.6 million outages in total. Figure 1 shows outages caused by Hurricane Isaias in New Jersey in 2020. Figures S1, S2, and S3 in the Supplement present power outages across New York due to Isaias, Florida due to Michael, and Texas due to Harvey, respectively.
Previously, Liu et al. (2005) developed an outage model at zip code levels and smaller 1 km × 1 km grid cells. However, the final selected model was zip code level, as the aggregation of input parameters at the 1 km × 1 km grid level led to more errors in outage predictions. Since then, outage models have been developed at coarser grids. For example, Han et al. (2009b, a), Guikema et al. (2010), Quiring et al. (2011), and Nateghi et al. (2014) developed the models for 2.5 km × 3.7 km grid cells. Tonn et al. (2016) developed outage models at the zip code level, McRoberts et al. (2018) predicted outages at the resolution of census tracts, and Shashaani et al. (2018) predicted outages at 5 km × 5 km grid cells.
We calibrated outage models at the city level resolution, comparable to the most recent models by McRoberts et al. (2018) and Shashaani et al. (2018). A model with finer resolution could be developed, provided there are higher-resolution power outage data and input parameters. Here, we used data with reported outages for 1910 cities in New York, New Jersey, Texas, and Florida. Following the previous literature, we use the covariates listed in Table 1. We obtained model inputs at the city level across all covariates. Further description of the availability, resolution, and methods to obtain each variable at the city level is provided in the subsequent subsections. We also discuss the uncertainties in data that could inherently influence the accuracy of power outage predictions. The total number of data points available is 1910 (cities). The dataset has been divided into train and test datasets with a ratio of 80:20.
2.1 Response variable
We focused on two response variables: the number of outages which are equivalent to the number of customers without power in a city and the fraction of customers without power. GLM and GAM use Poisson and negative binomial distributions to assess the count of outages as they model discrete and non-negative variables. Random forests can model the fraction of households without power in a city, which is important to compare impact levels across cities.
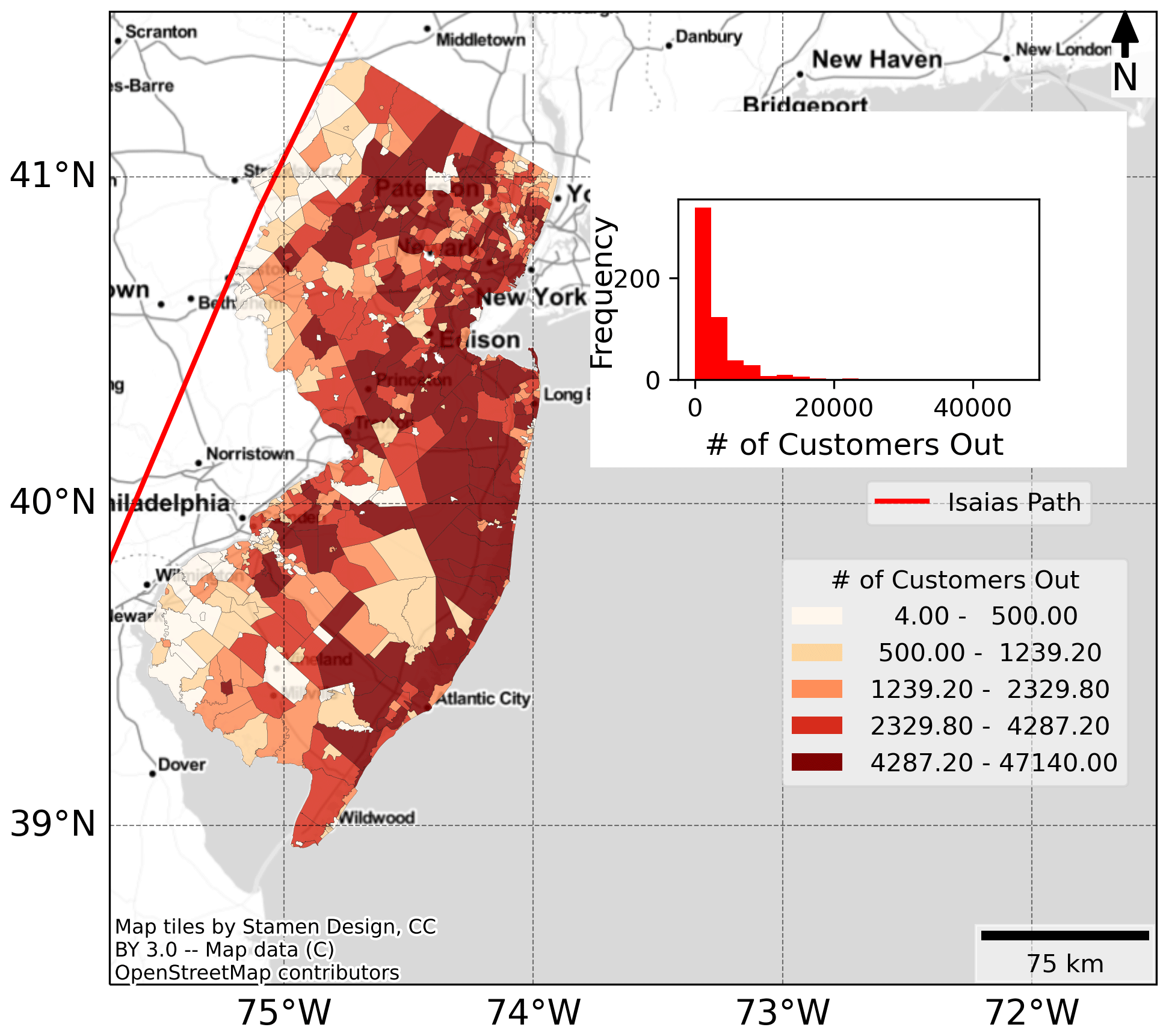
Figure 1Power outages in aftermaths of Hurricane Isaias (2021) in New Jersey at the city level. © OpenStreetMap.
2.2 Hurricane parameters
The hurricane parameters considered for this study are 3 s gust wind speed and duration of strong winds over 20 m s−1, as in previous research (Liu et al., 2005; Han et al., 2009b, a; Guikema et al., 2010, 2014; Shashaani et al., 2018). The overhead distribution system is the most vulnerable component of a power grid to high hurricane winds (National Academies of Sciences, Engineering, and Medicine, 2017). The distribution lines and poles are often close to trees and do not have considerable setbacks. The uprooting of trees due to strong winds often propagates damage to distribution lines. The poles are designed to sustain wind speeds of around 20 m s−1 (IEEE, 2007). Thus, winds above 20 m s−1 can cause substantial damage to the electric poles. The 3 s gust wind speed and duration of strong winds for the three hurricanes in the dataset were calculated based on a complete wind profile model for tropical cyclones by Chavas et al. (2015). We determined the wind speed for each city at its centroid. Figure 2 illustrates the variation of 3 s wind gusts in New Jersey during Hurricane Isaias. However, wind speed is an important factor causing outages, and any approximation in wind speed estimates could lead to errors in outage predictions. We provide detailed information in Sect. S1 in the Supplement to demonstrate that wind speeds at the city centroid can be a reasonable estimate in determining the city-wide outages.
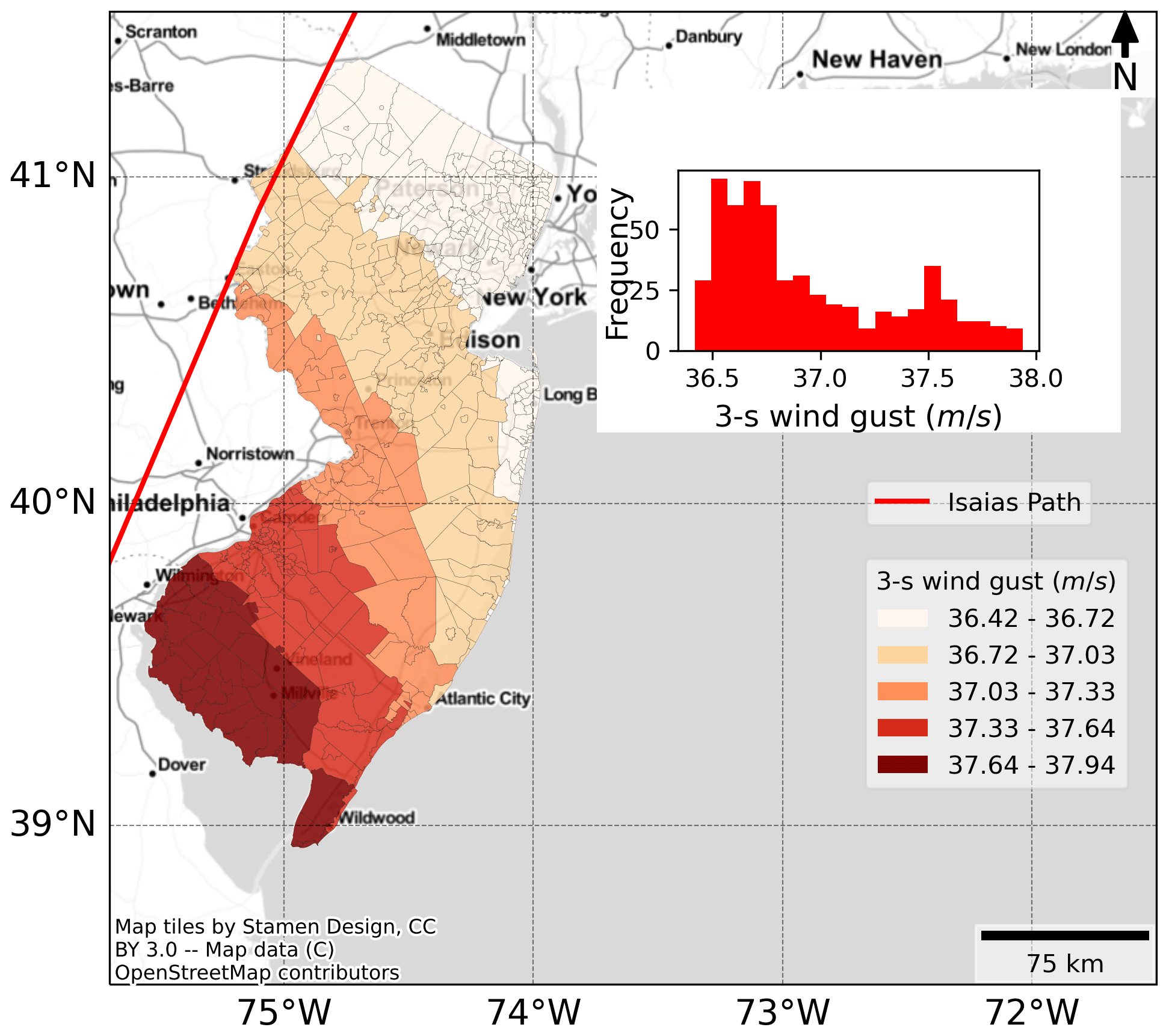
Figure 2Distribution of 3 s wind gust at the city level (mean: 36.95 m s−1, standard deviation: 0.41 m s−1) across New Jersey before the arrival of Hurricane Isaias. © OpenStreetMap.
2.3 Land cover data
Power grid patterns vary for different land use classes, resulting in different outage mechanisms. For example, rural areas can suffer larger power outages since they have radial grid patterns where component failures can propagate more than in cities with gridded patterns (Petersen, 1982). We obtained National Land Cover Data (NLCD) available from the Multi-Resolution Land Characteristics Consortium, which is maintained by the United States Geographical Survey (USGS) (https://www.mrlc.gov/viewer/, last access: 21 September 2022). National Land Cover Data have inaccuracies in the thematic pixel classification (Wickham et al., 2021) that could introduce uncertainties in the land cover type. However, evaluating the effect of the inaccuracies in the thematic pixel classification on power outages is not within the scope of this paper. NLCD are available in raster format with a resolution of 30 m × 30 m. USGS has classified the original land cover data into 20 different classes. We have reclassified the NLCD into nine classes to match previous power outage models. The nine different major classes of land cover data are developed area, water area, barren land, forest area, scrub area, grasslands, pasture land, cultivated cropland, and wetlands. We utilized the spatial analyst in ArcGIS (a tool for geographic information systems) (ESRI, 2019) to clip the 30 m × 30 m land cover raster for each city. We used zonal analysis within ArcGIS to determine the percentage of area covered by the nine major land cover classes.
2.4 Precipitation and soil moisture data
Precipitation and soil moisture have been extensively used in power outage models, e.g., Han et al. (2009b), Nateghi et al. (2014), and McRoberts et al. (2018). These parameters have non-linear effects on power outages, as deviations below and above standard values can result in more outages. The poles and overhead distribution lines in the vicinity of trees are susceptible to falling trees due to strong hurricane winds. The wet soil conditions from high precipitation and soil moisture increase the likelihood of trees and electric poles uprooting from strong hurricane winds (Han et al., 2009b; Nateghi et al., 2014). Also, persistent drought conditions, e.g., low precipitation in the months before a hurricane, can weaken the roots of trees because of gaps in the soil layer, making trees more susceptible to strong winds (McRoberts et al., 2018).
Precipitation and soil moisture data are available from the variable infiltration capacity (VIC) model from the National Land Data Assimilation System Phase 2 (NLDAS2) (Xia et al., 2012; Xia, 2012). However, the limited temporal resolution of parameters required for computing soil moisture and precipitation could introduce errors in the final estimates of these variables (Wei et al., 2013). The limitations of the variable infiltration capacity (VIC) model from the National Land Data Assimilation System Phase 2 (NLDAS2) (Xia et al., 2012; Xia, 2012) to get soil moisture and precipitation are beyond the scope of this study. Precipitation and soil moisture have been recorded each hour since 1979 with a resolution of 0.125∘ × 0.125∘. We used nearest-neighbor interpolation to obtain soil moisture and precipitation at the city centroid by taking the value available at the nearest point.
Soil moisture from NLDAS2 is available for three depths: 0–10, 10–40, and 40–100 cm. We calculated daily soil moisture for these depths by taking the average hourly readings. Soil moisture can vary at different geographical locations due to different soil types in different regions. We first normalized soil moisture to compute deviations from average values by computing percentiles. We fit Pearson type III distributions to the daily time series of soil moisture for all three layers to normalize the soil moisture across different geographies. We use maximum likelihood estimates (MLEs) to compute the parameters for Pearson type III distribution (Hosking and Wallis, 1997). Then, we evaluate the soil moisture percentile. We denote the soil moisture percentiles for three layers of soil at 0–10, 10–40, and 40–100 cm depth as CDF1, CDF2, and CDF3, respectively.
Precipitation data are represented in the form of the standard precipitation index (SPI) (Wu et al., 2007; Guttman, 1998; Casey, 2016). SPI for the months before the storm's impact can also be used as a proxy for the dryness and wetness of the soil. For the current study, we calculated SPI for durations of 1, 3, 6, and 12 months by adding hourly time series data for precipitation. The following are three steps to compute SPI. First, we fit the Pearson type III distributions to the time series of precipitation using MLE. Second, we compute the percentile from the Pearson type III distribution. Third, we take the inverse of the calculated percentile using a standard normal distribution to get the SPI for each duration. Figure 3 illustrates the variation of SPI 1 month in New Jersey before the arrival of Hurricane Isaias.
We also included the expected precipitation after the hurricane makes landfall for the next 7 d, as heavy rain can lead to flooding resulting in clustered outages (McRoberts et al., 2018). The soil moisture percentiles and SPI values are obtained from the day before the hurricane impacts the power systems. This starting time allows for outage predictions to give an early warning to the utilities and community members and take precautionary steps before strong hurricane winds hit the area.
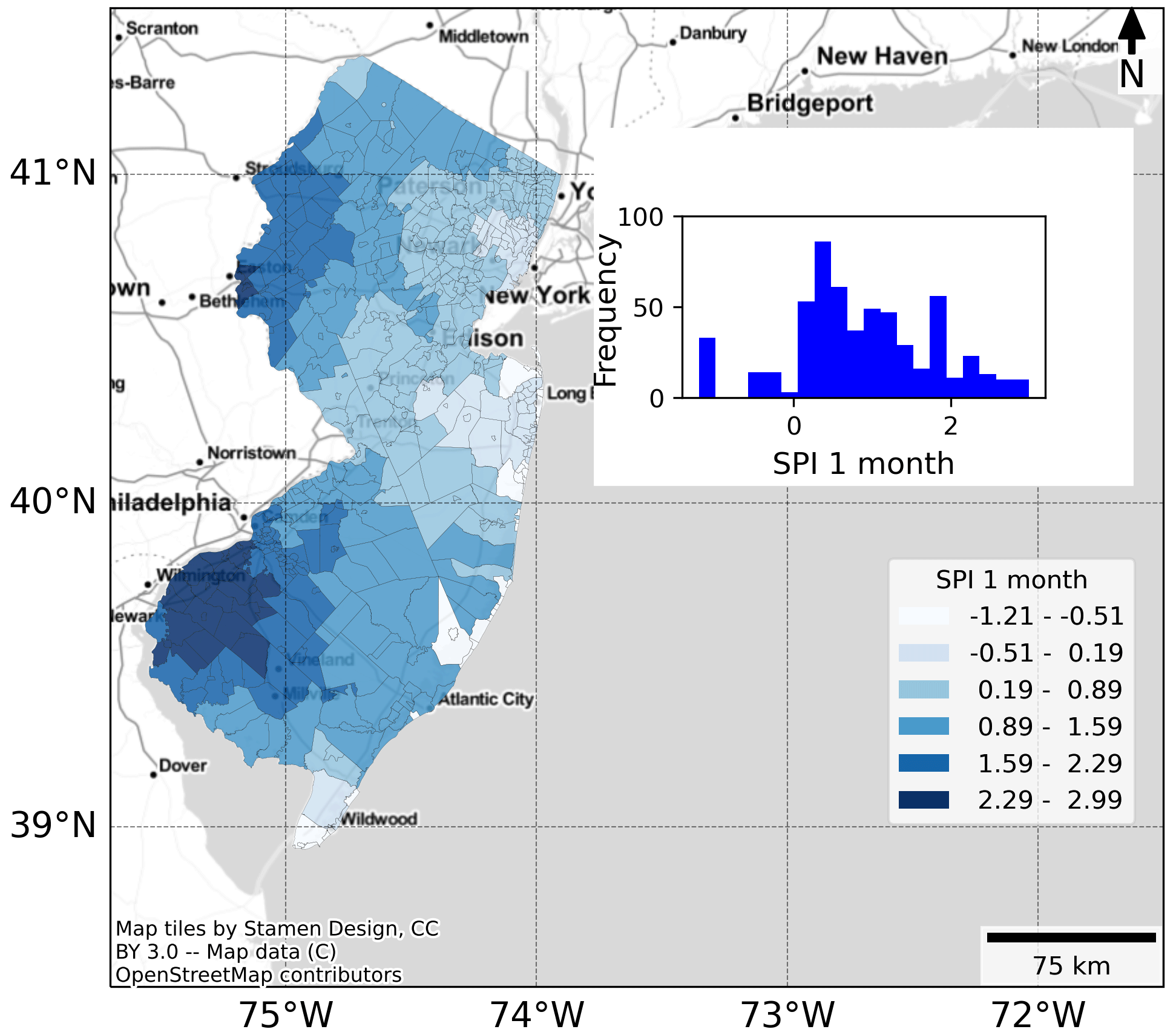
Figure 3Distribution of SPI 1 month (mean: 0.88, standard deviation: 0.93) across cities in New Jersey before the arrival of Hurricane Isaias. © OpenStreetMap.
2.5 Root zone depth
The effective root zone depth is defined as the depth of the soil from which plants and trees can effectively extract water and nutrients for growth (http://www.wood-database.com, last access: 21 September 2022). The more effective the root zone depth for trees, the less likely they will fail from strong hurricane winds (McRoberts et al., 2018). We add root zone depth as an input parameter for outage predictions because it could indicate the hazard from falling trees to the power lines. Root zone data are available from the United States Department of Agriculture (USDA) under Gridded Soil Survey Geographic (, ) at 30 m × 30 m resolution as raster data. The root zone depth at the city level is calculated as the average of the root zone in a city using the spatial analytic tool in ArcGIS. Given the resolution of available outage data at the city scale, we were not able to consider the variations in root zone depth, which limits the ability of the power outage model to consider the variation of tree root strength within a city.
2.6 Percentage treed area
USDA created National Insect and Disaster Risk Maps (Krist et al., 2014) in 2012, with the area covered by trees at 240 m × 240 m as raster data. The raster tree data are used to calculate the percent of the area covered by trees at the city level using the spatial analytic tool in ArcGIS (ESRI, 2019). Figure 4 illustrates the distribution of percent treed area in New Jersey.

Figure 4Distribution of percent treed area (mean: 73.45 %, standard deviation: 23.04 %) across cities in New Jersey. © OpenStreetMap.
2.7 Elevation
Previously, researchers have found that hurricane wind speeds (and thus damages) vary with surface topography (Chapman, 2000; Miller et al., 2013; Guikema et al., 2010; Quiring et al., 2011; McRoberts et al., 2018). Additionally, varying elevations could also introduce variations in precipitations (Napoli et al., 2019) and wind speeds (Chapman, 2000; Miller et al., 2013) within a city. Thus, we use the median and mean elevation at the city centroid, using nearest-neighbor interpolation, as topographic variables to capture the changes in elevations across the cities. We obtained these parameters from the digital elevation model (DEM) at a 30 arcsec resolution scale developed by USGS as part of the DEM: Global Multi-resolution Terrain Elevation Data (GMTED2010) (Danielson and Gesh, 2011). Note that the resolution of available outage data at the city level limit our ability to account for the varying elevations within a city. Future studies with high-resolution outage data might account for the variations in elevation within a city.
2.8 Density data
Demographics data are available from the American Community Survey (ACS) (https://www.census.gov/programs-surveys/acs, last access: 21 September 2022). The ACS collects different demographic data for each US census tract. The ACS started data collection in 2010, and we have considered data from 2019. We obtained the population density as it indicates the number of distribution poles and system components exposed to winds (Brown, 2002).
Table 1Parameters to build the power outage prediction models: all variables are rescaled at the city level. Parameters are grouped into categories separated by horizontal lines. We selected one variable from each category of each group to minimize correlation across parameters.

1 Chavas et al. (2015). 2 https://www.mrlc.gov/viewer/, last access: 21 September 2022. 3 Xia et al. (2012). 4 Xia (2012). 5 (). 6 Krist et al. (2014). 7 Danielson and Gesh (2011). 8 https://www.census.gov/programs-surveys/acs (last access: 21 September 2022). 9 Liu et al. (2005). 10 Liu et al. (2008). 11 Han et al. (2009b). 12 Han et al. (2009a). 13 Nateghi et al. (2014). 14 Guikema et al. (2010). 15 McRoberts et al. (2018). 16 Shashaani et al. (2018). 17 Wanik et al. (2017). 18 Wanik et al. (2015). 19 Variables finally selected for model development after performing feature selection.
Machine learning models with high-dimensional input data can be hard to train, especially when datasets are sparse, as in the case of infrastructure failures. Input features can be correlated, leading to higher generalization errors. This means the machine learning model can fit well the training data, i.e., with small errors. However, we might observe significant errors after testing the model with additional data. Also, correlated features can lead to a flawed understanding of the relation between input and predicted outages (Verleysen and François, 2005).
Feature selection, also called variable selection, is an essential step in machine learning model development to select relevant variables and discard redundant and highly correlated ones (Cai et al., 2018). We performed the feature selection for outage prediction in two steps. First, we performed a forward selection with a linear regression (Kohavi and John, 1997) for an initial rank on feature importance (Fig. 5). A linear model might not be the best model to forecast power outages. However, it can provide initial insights into the dependence of an input feature on outages. We started with a set of empty features and added features one by one. At each step, we selected the variable that led to the largest increase in the R2. Our results show that, as expected, wind speed and duration of strong winds affect the power outages most. We found that precipitation and soil moisture are important for outage prediction, even for linear regression, suggesting that their relevance could be even higher for non-linear regressions. We also found that population density is critical for outage prediction, which could be explained by a positive correlation between density and the density of transformers, as described in Liu et al. (2007).
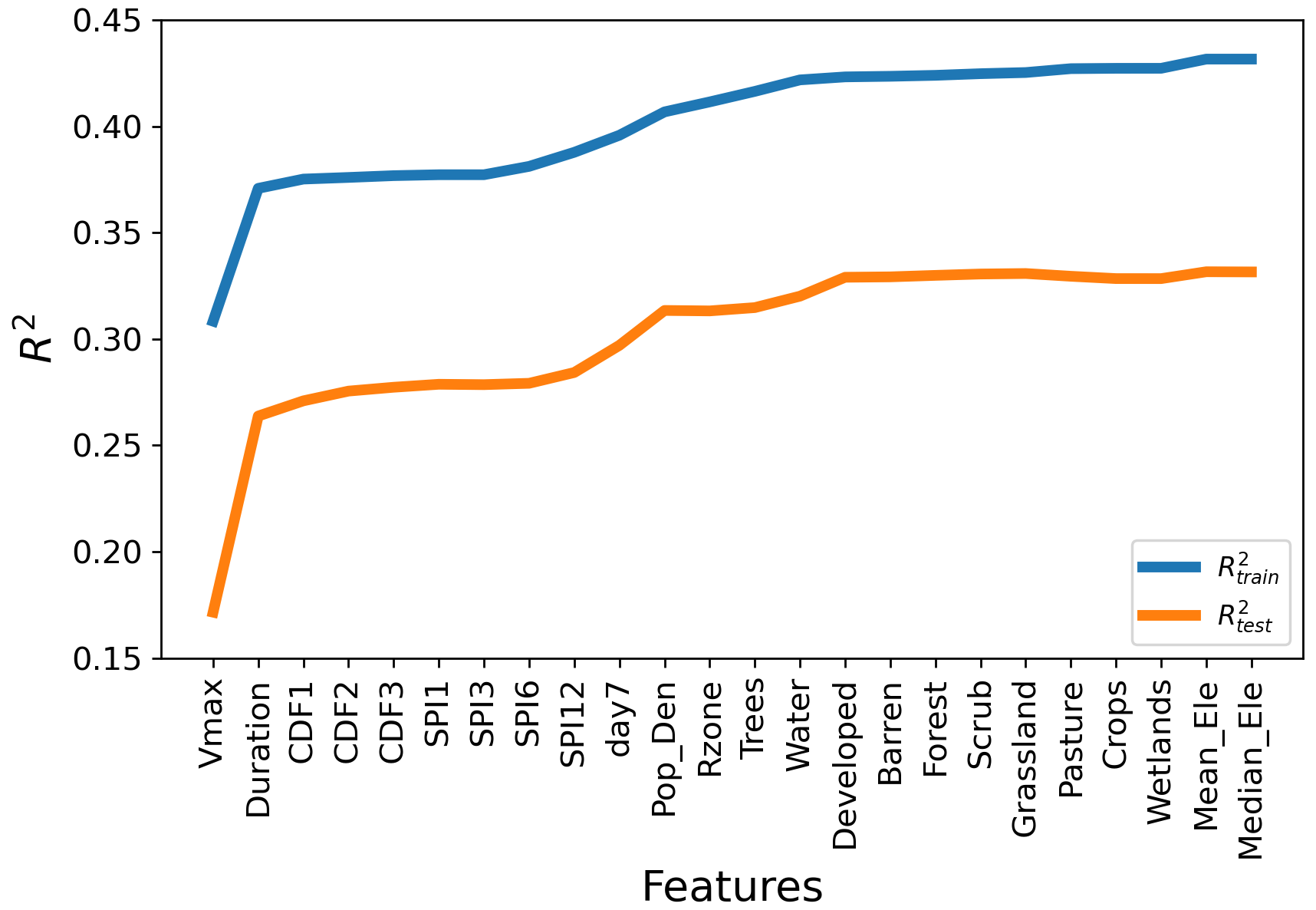
Figure 5Forward selection: selection of important input parameters based on importance to explain the variability in outage predictions. Feature descriptions are shown in Table 1.
In the second stage, we analyzed the correlations between the input parameters. Figure S4 shows the correlation coefficients for each pair of variables. We found that input features within the same category in Table 1 are highly correlated. For example, the maximum wind speed and duration of strong winds, which are at the top of the ranking in forward selection (Fig. 5), have a correlation coefficient of 0.89 (Fig. S4). Hence, we kept only maximum wind speed as an input feature since it is better ranked than the duration of strong winds in the forward selection. We conducted a similar analysis for the different categories listed in Table 1 to select the input variable with the strongest predictive power. Due to their lower importance in our results, we did not include parameters from the elevation and land cover categories, as they contribute less than 1 % to R2. Finally, we selected the following seven variables that will be used throughout the paper:
-
3 s gust wind speed
-
7 d precipitation
-
standard precipitation index 6 months
-
soil moisture first layer
-
population density
-
percent treed area
-
root zone depth.
Generalized linear models (GLMs) are a generalization of ordinary linear regression. GLMs allow us to use a flexible link function to relate a linear model (of the input variables) to the response variable (Dunn and Smyth, 2018). Unlike ordinary linear regressions, GLMs do not assume homoscedasticity, i.e., when the variance of the response variable is constant across the values of the input variables. The assumption of homoscedasticity fails for the number of customers without power since this output variable has positive counts, and when damage to power infrastructure is negligible (e.g., little storm), the variable's variance (and mean) should change and approach zero (Dunn and Smyth, 2018).
In addition, GLMs can utilize multiple statistical models to represent the data instead of the only normal distribution as in ordinary linear regressions. Outages have a lower bound of zero counts that normal distributions cannot capture. Thus, previous researchers have used the following distributions to represent outages with GLMs.
4.1 Poisson GLMs
Poisson regression models, a category of GLMs, are applicable for positive count data where observations are independent. Outages are modeled as a Poisson random variable:
where y is the number of outages in a city. The Poisson distribution is described by the parameter μ, the mean number of outages in a city. A log link connects the parameter μ to the input variables, which assures that μ is greater than zero.
where β is learned from the historical outages from extreme events, often through maximum likelihood estimation (MLE). MLE finds the value of β that maximizes the probability of observing the data. Readers can refer to Dunn and Smyth (2018) for more information on MLE estimates for GLMs. We use glm package in R studio (https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/glm, last access: 21 September 2022) to fit the Poisson GLM to our power outage data.
The variance in a Poisson distribution is equal to the mean, i.e., Var(y)=μ. Thus, the variance grows as μ increases. However, previous research has found that outage variance from historical data is significantly bigger than the mean (Liu et al., 2005; Han et al., 2009b, a), a phenomenon that is known as overdispersion in Poisson regressions (Dunn and Smyth, 2018). Overdispersion may arise from the interdependence of output variables, especially when they happen in clusters (Dunn and Smyth, 2018). Poisson distributions represent counts of events, e.g., customers without power, that are independent (Liu et al., 2007). In contrast, multiple outages in the city can happen due to the failure of the same power grid components (Liu et al., 2005; Han et al., 2009b). Thus, outage counts are not independent.
4.2 Negative binomial GLMs
Negative binomial GLM is a hierarchical model which can account for overdispersion effects in power outage count predictions (Dunn and Smyth, 2018). Negative binomial GLMs are based on a Poisson–gamma mixture distribution; i.e., the outage count y is distributed as a Poisson random variable
where μ is a factor that when multiplied by τ equals the mean of the Poisson distribution. τ is an additional random variable to account for extra variance, with a mean equal to 1 and distributed as gamma
where k is the overdispersion parameter and Γ() is the gamma function; thus, the variance of τ equals k. After marginalizing the random variable τ,
which is equivalent to a negative binomial distribution with a variance of μ+kμ2. This variance is higher than the one in the Poisson GLM with one term that is proportional to μ2. Thus, negative binomial GLMs account for significantly higher variances. μ is parameterized as in Eq. (2). Then, β and k are estimated through MLE using the glm package in R studio (https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/glm, last access: 21 September 2022).
4.3 Zero-inflated GLMs
Researchers have also developed zero-inflation outage prediction models to improve statistical performance for unbalanced data, e.g., when there are a lot of data points with no outages (McRoberts et al., 2018; Shashaani et al., 2018). The zero-inflation model has two levels of predictions (McRoberts et al., 2018; Shashaani et al., 2018). The first level can be a logistic regression or a decision tree model to check if there is at least one power outage (Hall, 2000). The first level model predicts “0” in case of no outages and “1” in case of at least one outage. The second level is the regression model predicting the number of outages for cases where the prediction was “1” at the first level. In this paper, we do not fit zero-inflated models, as our data are balanced; i.e., we observe at least one outage in each city.
GLM models assume a linear relationship between the logarithm of the mean number of outages and input parameters (Eq. 2). However, previous research has shown that they have non-linear relationships (Han et al., 2009a), which can be modeled with non-parametric extensions of GLMs (Yee, 2012). Generalized additive models (GAMs) capture non-linear relationships using smoothing functions
where μ is the mean outages for a city, xj∈X is the individual input parameter, β0 is the intercept, and fj(xj) are the smoothing functions for each input parameter. Some examples of smoothing functions are regression splines, B splines, and P splines. Splines of any order could be used to fit GAMs, but accuracy increases negligibly after the quartic degree (Yee, 2012). Thus, we used quartic-order polynomials for all input variables except for maximum wind speeds. For this variable, we reduced the order of the polynomial to 1 to always obtain a monotonically increasing relationship between winds and outages, as we would expect from the structural behavior of infrastructure against extreme loads. We used MLE to estimate GAMs' parameters through iteratively reweighted least squares (IRLS) (Wood, 2017) using the MGCV library in R studio. Poisson GAM assumes the Poisson distribution on the number of outages as described in Eq. (1), with link function equal to Eq. (6). Similarly, negative binomial GAMs assume the Poisson–gamma distribution mixture for the number of outages as mentioned in Eq. (5), with link function equal to Eq. (6).
Random forest regressions (Breiman, 2001) are non-parametric ensembles of decision trees that do not assume any underlying probability distribution for the decision variable. Tree-based methods are easy to build and powerful machine learning tools. Decision trees split at each node based on some criteria involving the value of a particular input variable. For regression trees, binary splits at each node are performed for each variable (Fig. 6) (Hastie et al., 2001). The split with the largest reduction of squared errors is selected at each step. The splitting stops once there is no performance gain for the regression analysis. For the prediction, the decision tree will point to a final leaf node based on the criterion for the splitting of feature space, and the output for the decision tree is the average of the predicted variable,
where Lm is the final leaf node (Fig. 6).
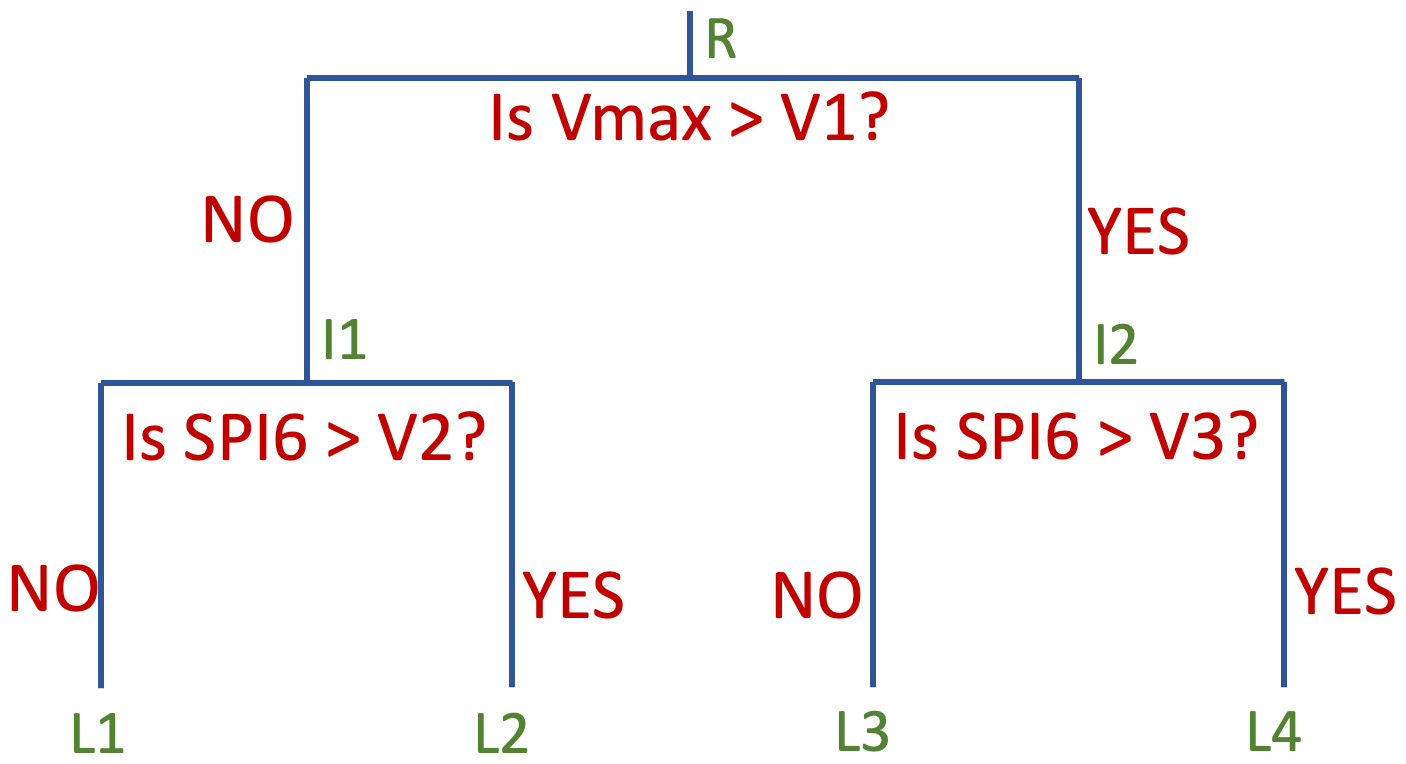
Figure 6Example of a simple decision tree with two input features, maximum wind speed (Vmax) and precipitation (SPI6), to predict outages. The split at the root node (R) is done with Vmax. Thus, if the wind speed value is greater than the value V1, the points will belong to the right interior node (I2), otherwise they belong to the left node. Similarly, interior nodes are further divided into leaf nodes L1, L2, L3, and L4 using values of SPI6.
Random forests “grow” a large number of parallel decision trees and bag new samples for each decision tree (Breiman, 2001). Bagging involves drawing new training points with replacements to fit each decision tree with a random selection of features. The final output is the average of outputs from each decision tree modeled in parallel. The random selection of features results in the development of uncorrelated trees, reducing the variance in predictions (Hastie et al., 2001).
Random forest models can generally capture the non-linear between the input parameters and output predictions. However, a random forest is not easily interpretable, as it is based on multiple decision trees. In this paper, we use the sci-kit learn module in Python to fit the random forest model. We also use the GridSearchCV module in Python (Pedregosa et al., 2011) to tune for the parameters and select the model with the least error on out-of-bag samples.
In this section, we discuss the statistical performance of different outage models by first training the models on training data and then comparing the R2 metrics on hold-out test data. We use different R2 metrics since traditional ones, like the coefficient of determination, have many limitations for counting variables, as discussed in the Appendix. We also compare the performance of developed models for our generalized data covering the southeast, southwest, and northeast regions in the US, with the results from previous models applied to a particular region.
7.1 Generalized linear models
We trained Poisson and negative binomial GLMs to predict the outage counts. The predictions are based on the seven input features mentioned in the feature selection section. All the input features are significant at a p value of . We compared the statistical performance of the Poisson and negative binomial GLMs (Table 2). We have a total of 1528 training data points with seven input variables and one additional slope constant. Thus, the residual degree of freedom for each model is 1520.
Table 2Statistical performance measurements for generalized linear models.

The high value of residual deviance, relative to the degree of freedom, in the Poisson GLM shows large overdispersion (Liu et al., 2005; Han et al., 2009b; Dunn and Smyth, 2018). Thus, using this new outage dataset, we confirm that the variance in historical outages largely exceeds the mean value. A negative binomial GLM has a low residual deviance value compared to the Poisson model and is more similar to the degrees of freedom, indicating that a negative binomial GLM can handle overdispersion in power outage predictions more satisfactorily.
in Table 2 is a measure of the deviance explained by the fitted model compared to the null model. The null model predicts the average of observed outages () for all the cities irrespective of the input parameters. quantifies the amount of overdispersion explained by the additional variability introduced as a parameter in Eqs. (4) and (5) for the negative binomial fitted model. The is higher for the negative binomial GLM, also suggesting the negative binomial's better statistical performance. The for the negative binomial GLM is 0.69, which means the model can capture 69 % of variability by considering the additional level of uncertainty in the form of Poisson–gamma mixture given by Eq. (5) for outage counts. The reported value of for the negative binomial GLM in this paper is comparable to the values presented by Han et al. (2009b), i.e., ∼0.8. However, we observe a lower value of compared to previous literature, i.e., ∼ 0.6. The lower value of may be due to the use of fewer parameters, e.g., 7 in this study versus 20 in Han et al. (2009a), as always increases with more predictors. For example, we get a value of 0.48 for when all the input variables in Table 1 are included, but we considered fewer parameters to avoid correlated features and enhance the generalization of these models. We may also get a lower value of because we have a generalized dataset covering different regions in the US, and previous models were applied to data from smaller regions.
7.2 Generalized additive models
We also trained the Poisson and negative binomial GAMs. Like for GLMs, GAMs are trained with the seven input features mentioned before. All the input features are significant at a p value of for both models. Like for GLMs, the residual degrees of freedom for each model is 1520.
Table 3Statistical performance measurements for generalized additive models

The residual deviance for Poisson GAM (Table 3) is ∼ 38 % less than the one in Poisson GLM (Table 2), which is a minimal improvement to overcome the large overdispersion, as the deviance is still significantly higher than the degrees of freedom. However, shows a more significant performance improvement as its value increases to 0.53 for Poisson GAM (Table 3) over a value of 0.20 for Poisson GLM (Table 2).
The negative binomial GAM has a low value of residual deviance, which indicates that the negative binomial GAM can handle overdispersion. Additionally, non-linear shapes from spline functions (Eq. 6) for GAMs improve the outage predictions. The for the negative binomial GAM improves significantly to a value of 0.62 (Table 3) over the 0.29 in the negative binomial GLM (Table 2). The observed value of 0.99 for is similar to the one reported by Han et al. (2009a) in their GAM model development for power outage predictions. The for GAMs is not available in the previous literature, so further comparisons with previous work could not be made.
7.3 Random forest
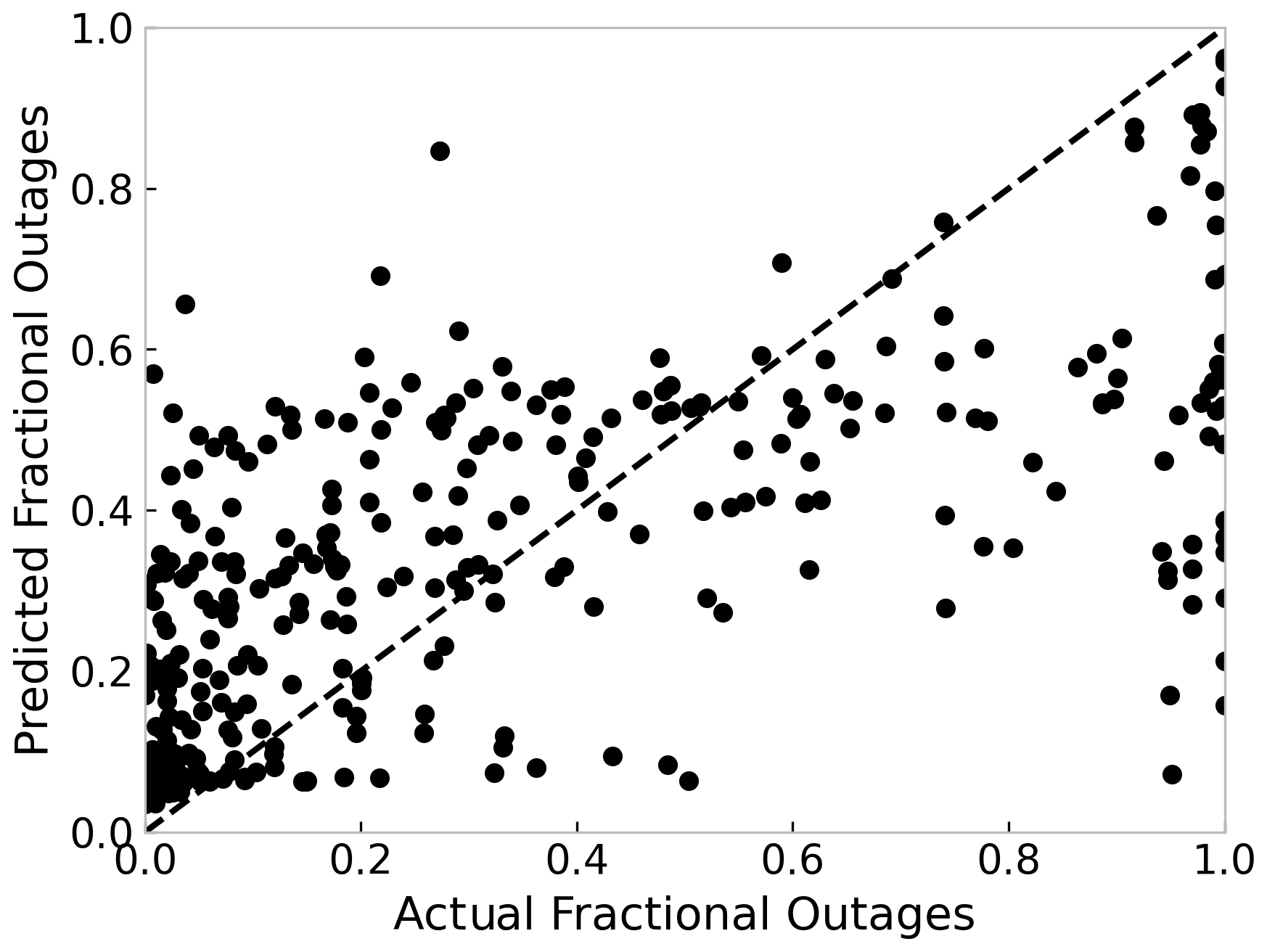
We calibrated the random forest model to predict the fraction of customers without power. We performed the hyperparameter tuning using the GridSearch tool in Python (Pedregosa et al., 2011) with cross-validation to select the best input parameters for the random forest. The hyperparameter tuning resulted in a mean cross-validation R2 of 0.52. However, we obtained a training R2 of 0.84 when fitting the random forest with the tuned hyperparameters on the training data. The high training R2 compared to cross-validation R2 represents potential overfitting in the random forest model. We further tuned the model parameters by reducing the maximum depth. We obtained a cross-validation R2 of 0.48 and training R2 of 0.63. Finally, we obtained an R2 of 0.48 on the hold-out test. The number of randomly grown trees in the selected random forest model is 500. Figure 7 shows the predicted fractional outages against the observed outages using a tuned random forest (RF). RF does not generalize well to the outages due to Hurricane Isaias, which had low wind speeds (∼36 m s−1) in New Jersey but still caused outages to 60 % of consumers in 213 cities (out of 565) in New Jersey. This effect is visible in Fig. 7, where RF underestimated the fractional outages for severely affected cities in New Jersey.
The R2 for the random forest model cannot be compared to different R2 statistics calculated for GLM and GAM models, as the output for random forest (fraction of outages) differs from GLM and GAM models (outage counts). Also, we cannot calculate and statistics for random forest as there is no underlying probability distribution assumed for random forest predictions.
We present the variable importance in the random forest model in Fig. 8. We calculated the variable importance by training a base model with all the input features and a permuted model resulting from training different random forests and removing one feature at a time from the base model. We ranked importance by finding the variable that leads to the largest difference in the mean squared error between the base (full) model and the permuted (reduced) model. We present the normalized importance factors in decreasing order of importance (Fig. 8).
We found that maximum wind speed is the most important parameter in the random forest model (Fig. 8), which coincides with our findings from a simple linear regression in Fig. 5. Precipitation is the second most important variable, with a relative importance of 0.33, as trees can more easily be torn out from wetter soil. Population density is the third most important variable in outage predictions since it is a proxy for cities’ density of transformers exposed to winds.

Figure 8Random forest variable importance in decreasing order of importance. All importance factors are normalized by the highest value, i.e., the factor for Vmax.
Random forest and negative binomial GAMs show superior performance in predicting the power outages caused by a hurricane. MSE (mean squared error) (Wallach and Goffinet, 1989) has been used to compare the performance difference statistic models, given as
where y is the predicted value, is the observed value, and n is the total number of observations. Thus, we report MSE on both negative binomial GAM and RF models to compare the performance of these models. We rescale the negative binomial GAM predictions by the total number of customers to compare the MSE values of negative binomial GAM and RF models at the same scale as fractional outages. MSE for the negative binomial GAM is 45.13, and MSE for RF is 0.06. Researchers should be careful in making the direct comparison for MSE values of the fraction-based RF model and the count-based negative binomial GAM model, as these models are optimized for a different set of response variables. The high MSE for the negative binomial arises from overestimating outages, which we discuss next.
Different machine learning models discussed in previous sections can predict power outages for a hurricane-stricken city. Here, we discuss the limitations of state-of-the-art machine learning models for power outage predictions.
8.1 GLM and GAM's predictions are unbounded
GLM and GAM regressions can predict the mean number of outages in the city. The models have a lower bound of zero as both Poisson and negative binomial distributions predict the count of outages. However, there is no upper bound on the predicted number of outages. Hence, GLM or GAM models can predict more outages than the number of customers, resulting in an overestimation of power outages.
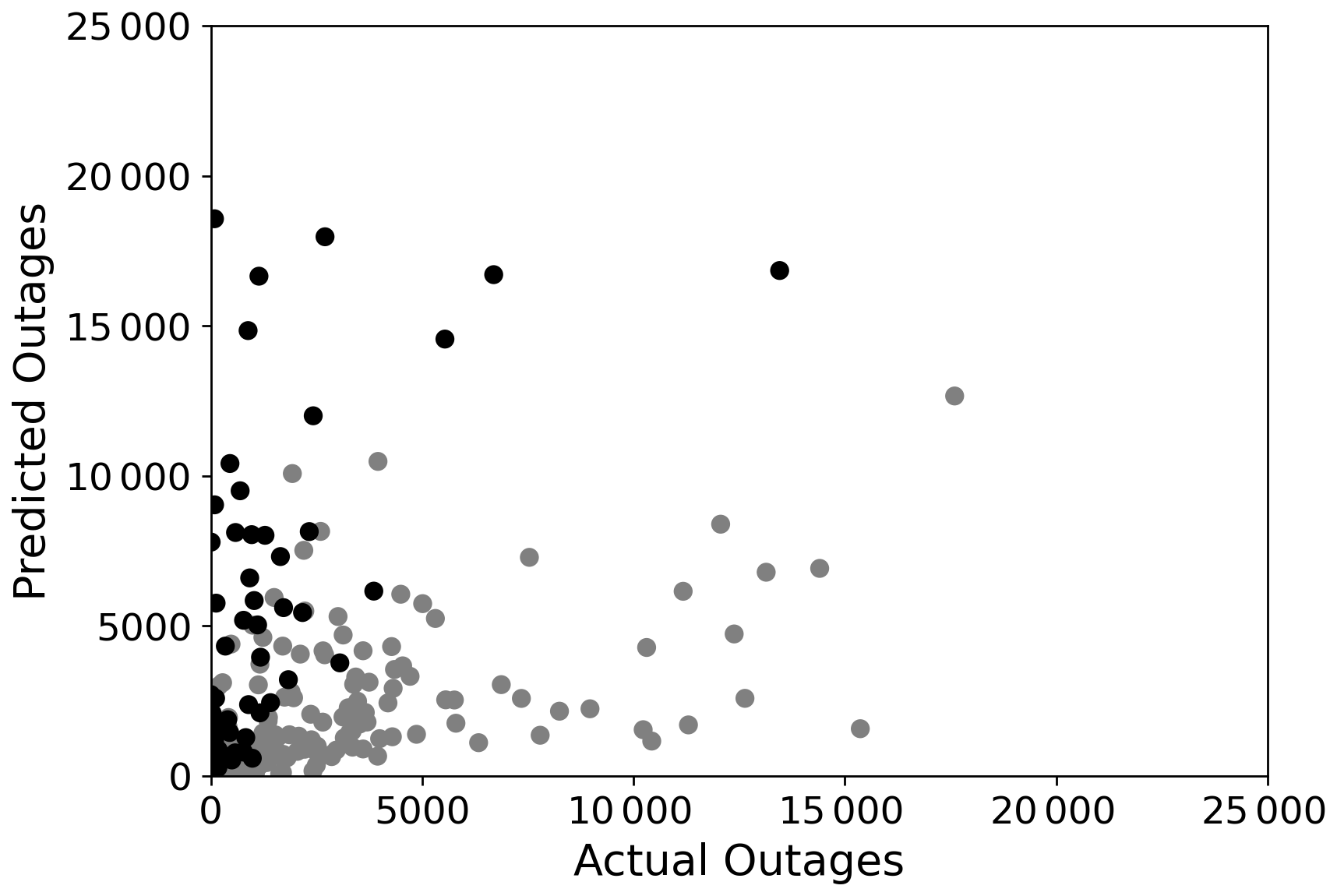
Figure 9Outage predictions on 20 % holdout test data using the negative binomial GAM outage model. Black dots represent the cities with predicted outages larger than the number of customers. Grey dots represent the cities with predicted outages less than or equal to number of customers.
For illustration, we present the power outage predictions on 20 % hold-out test data for the negative binomial GAM (Fig. 9). For 76 cities out of 382 (19.8 %) in test data, predicted outages are more than the number of customers, and the overestimation can be significant. For example, the model predicted outages as high as 16 times those of Rockleigh, New Jersey, customers. The average ratio of predicted outages over the number of customers in the cities that experienced overestimation was 5.2. The cities that experienced overestimation had smaller populations, with an average of 5962; e.g., Rockleigh had only 106 customers. In contrast, cities without overestimation had an average population of 30 058. Modelers could impose an upper bound on the predictions using the total number of customers as the maximum possible outage. However, this adjustment would violate the assumptions in the Poisson–gamma mixture model (Eq. 5) and GAM link function (Eq. 6).
8.2 Random forest's lack of extrapolability for high winds
Random forest predictions are an average value of the outages in the training data (Eq. 7). Thus, unlike GLMs, random forest predictions are bounded by the minimum and maximum values of power outages in training data. Based on simple physics, one would expect more damage and more outages from higher wind speeds. In order to understand the influence of wind speeds on the power outages in the random forest regression, we plotted the partial dependence of the fraction of customers without power against wind speed. The partial dependence, g(xj) (Hastie et al., 2001; Nateghi et al., 2014), of the input variable xj is given by
where N is the total number of observations, xic are the variables other than xj, and is outage prediction (Eq. 7) for the ith data point. To plot the partial dependence, we varied xj (wind for this case) and kept xic (input parameters other than wind speed) constant. We estimated outages by averaging all observations in training data plotted against the xj (wind speed).
For this assessment, we trained the random forest model on a reduced dataset, with only New York and New Jersey, and on a complete dataset, including Florida and Texas. We present the partial dependence of wind speed in Fig. 10, also including the distribution of wind speeds in the training data. Hurricanes of category 3 or higher bring wind speeds above 40 m s−1 that can significantly damage electric poles (Bjarnadottir et al., 2013). However, they are significantly less observed in inland cities, especially in the northern United States, as storms often weaken in their transition to higher latitudes and after leaving the ocean. For example, only tropical storms with wind speeds of less than 33 m s−1 have impacted New York City for the past 20 years (https://coast.noaa.gov/hurricanes/#map, last access: 21 September 2022). For example, Superstorm Sandy (2012) transitioned to a tropical storm before impacting New York City (https://coast.noaa.gov/hurricanes/#map, last access: 21 September 2022). As per ASCE 7–10 wind hazard maps (https://hazards.atcouncil.org/, last access: 21 September 2022), a wind speed of 43 m s−1 has a return period of 100 years for New York City. Thus, it is very unlikely, and evident from Fig. 10, to get outage data in New York and New Jersey for winds above 43 m s−1.
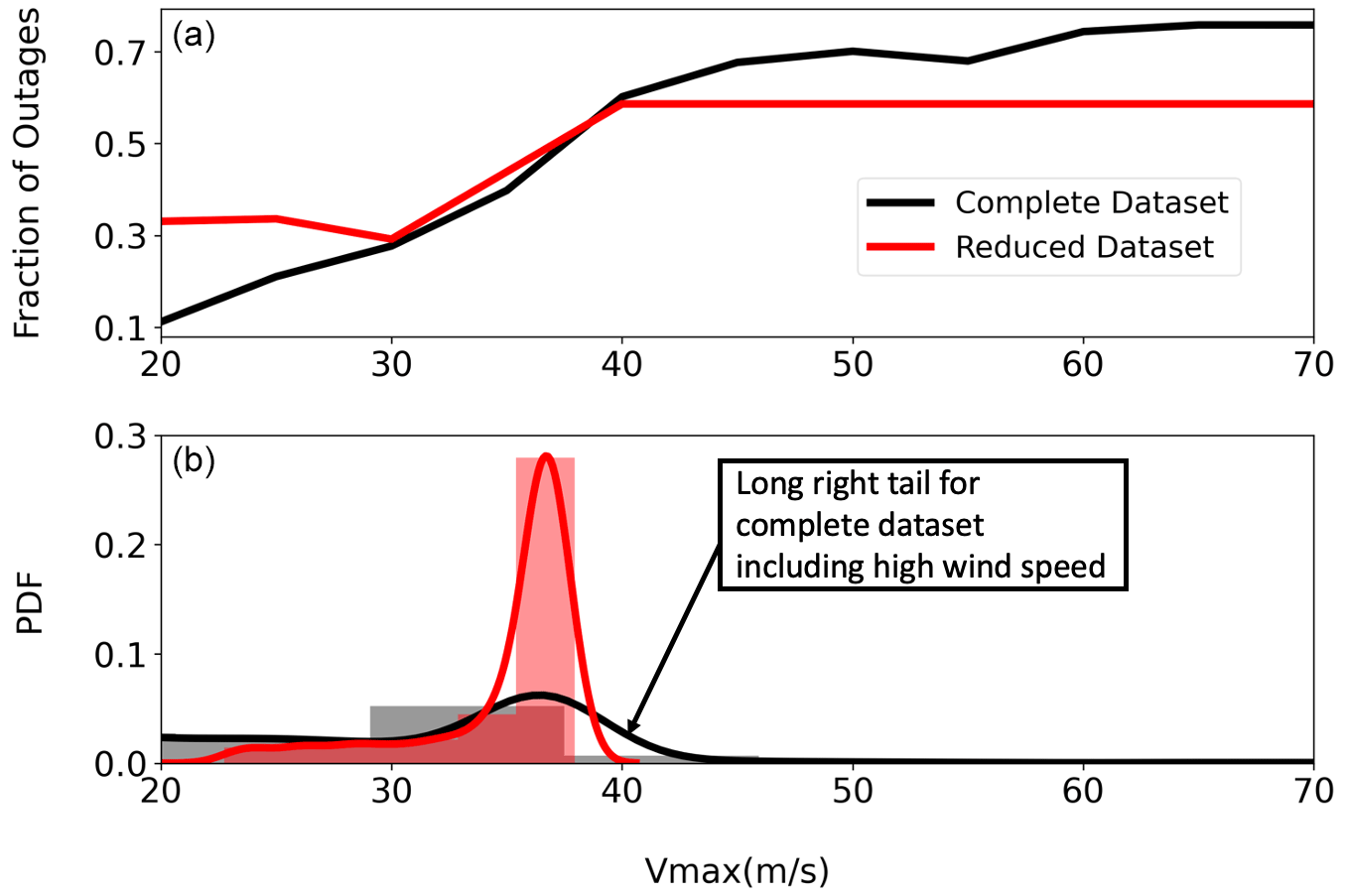
Figure 10(a) Partial dependence of wind speed on power outages. (b) Distribution of wind speed in the complete and reduced dataset. The random forest model does not extrapolate for the wind speeds and outages not in the range of training data.
These limited outage datasets have strong implications for the validity and extrapolability of outage models based on random forest regressions. Under the reduced dataset, i.e., with only New Jersey and New York, outage predictions increase as the wind speed increases from 20 to 40 m s−1. However, the fraction of outages reached a maximum of 0.58 at wind speeds of 40 m s−1 and does not increase with higher wind speeds. The random forest model cannot extrapolate for the higher winds, which limits the capability of random forest to make outage predictions for large hurricanes.
Under the complete dataset, results improve by including outages in Florida and Texas. These states experience higher winds; e.g., their 100-year return-period winds are ∼70 m s−1 in contrast to the 43 m s−1 in New York (https://hazards.atcouncil.org/, last access: 21 September 2022). The reduced dataset (with only New York and New Jersey) did not have any data points with wind speeds above 40 m s−1. In contrast, the complete dataset (including Florida and Texas) had 88 cities (4.6 % of data points) with winds greater than 40 m s−1 and 29 cities (1.5 % of data points) with winds above 70 m s−1. With the complete dataset, the random forest predictions reach a maximum value of 0.76 for winds of 75 m s−1. While these results show improvement, they also show that the data are still insufficient to make the random forest model follow the physics of infrastructure failure and extrapolate predictions for high winds causing outages close to 100 %.
8.3 Lack of physics-based variance shapes
In catastrophic storms, we expect large outages with higher certainty, e.g., Hurricane Ida (2021) in Louisiana (Elamrouss, 2021) and Tropical Storm Fiona (2022) in Puerto Rico (Rivera et al., 2022), close to 100 %. Structural models for power poles estimate failure probabilities close to 95 % for winds of 70 m s−1 (Ouyang and Dueñas-Osorio, 2014; Bjarnadottir et al., 2013). Thus, the physics of infrastructure failure suggests that variance in outages should be smaller for catastrophic winds. To evaluate if existing models follow these principles from the physics of power infrastructure failure, we quantified the variance in predictions for Jersey City by varying the wind speed and keeping the other input variables unchanged (Fig. 11).
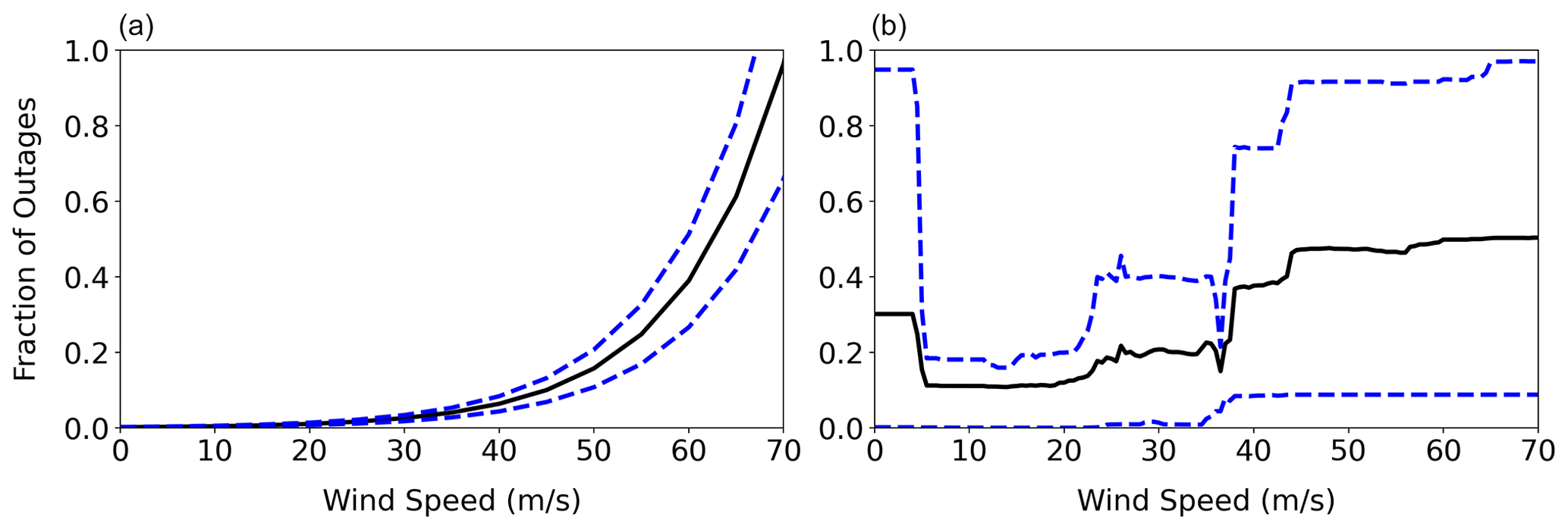
Figure 11Prediction ranges of power outage as a function of wind speed for (a) the negative binomial GAM and (b) random forest. For GAM, mean and standard deviations are based on Eq. (5). For random forest, we use quantile random forest to determine percentiles and assume normal distribution to find comparable intervals of the mean plus and minus the standard deviation. Black lines indicate the mean outage predictions. Blue dashed lines indicate the 1 standard deviation interval for outage predictions.
As discussed previously, negative binomial GAMs capture the variability of outages better than Poisson models. Thus, we focus on the former models and estimate the variance according to Eq. (5). Figure 11a shows the mean and 1 standard deviation interval for outage predictions with varying wind speeds. We normalized the GAM's predictions to show fractions and compare them to the random forest model. GAM's predictions go beyond 1, as discussed previously, but we truncated the y axis at 1 for comparison purposes. The linear relationship in the link function ensures that the variance (function of the square of mean outages from Eq. 5) grows with wind speed. For example, for a wind of 40 m s−1, we have a standard deviation of 0.02, and for a wind of 70 m s−1, we have a standard deviation that is 15 times higher with a value of 0.3. Thus, the variance shows higher values as the predicted outage fraction approaches to 1. In fact, the variance is also unbounded in the negative binomial GAM and goes to infinity.
The random forest model can only predict the mean number of outages. Thus, it cannot evaluate variances. However, the quantile regression forest (QRF) (Meinshausen, 2006) can predict the outages at different confidence intervals, and we use it to quantify variance. The QRF uses the recorded observation at the leaf node to predict confidence intervals. These intervals are fully data-driven, as random forests do not assume any underlying probability distribution on predicted outages (Ahsanullah et al., 2014). We presented random forest prediction intervals in Fig. 11b. The random forests had a standard deviation of 0.45 for high winds (>70 m s−1), departing from the expected value of zero for catastrophic winds. Additional data could improve these random forest variance estimates. However, as mentioned earlier, infrastructure failure data are sparse.
Moreover, structural models predict no damage to power infrastructure at wind speeds lower than 10 m s−1 (IEEE, 2007; Bjarnadottir et al., 2013). Thus, we expect outage predictions closer to 0 with a higher degree of certainty. Negative binomial (and Poisson) GAMs handle this case well, as the variance is zero when the mean outage is zero (Eqs. 1 and 5). In contrast, we found that random forests had a standard deviation of 0.66 for zero wind speeds, showing that they also have limitations to represent physics-informed variance at low wind speeds.
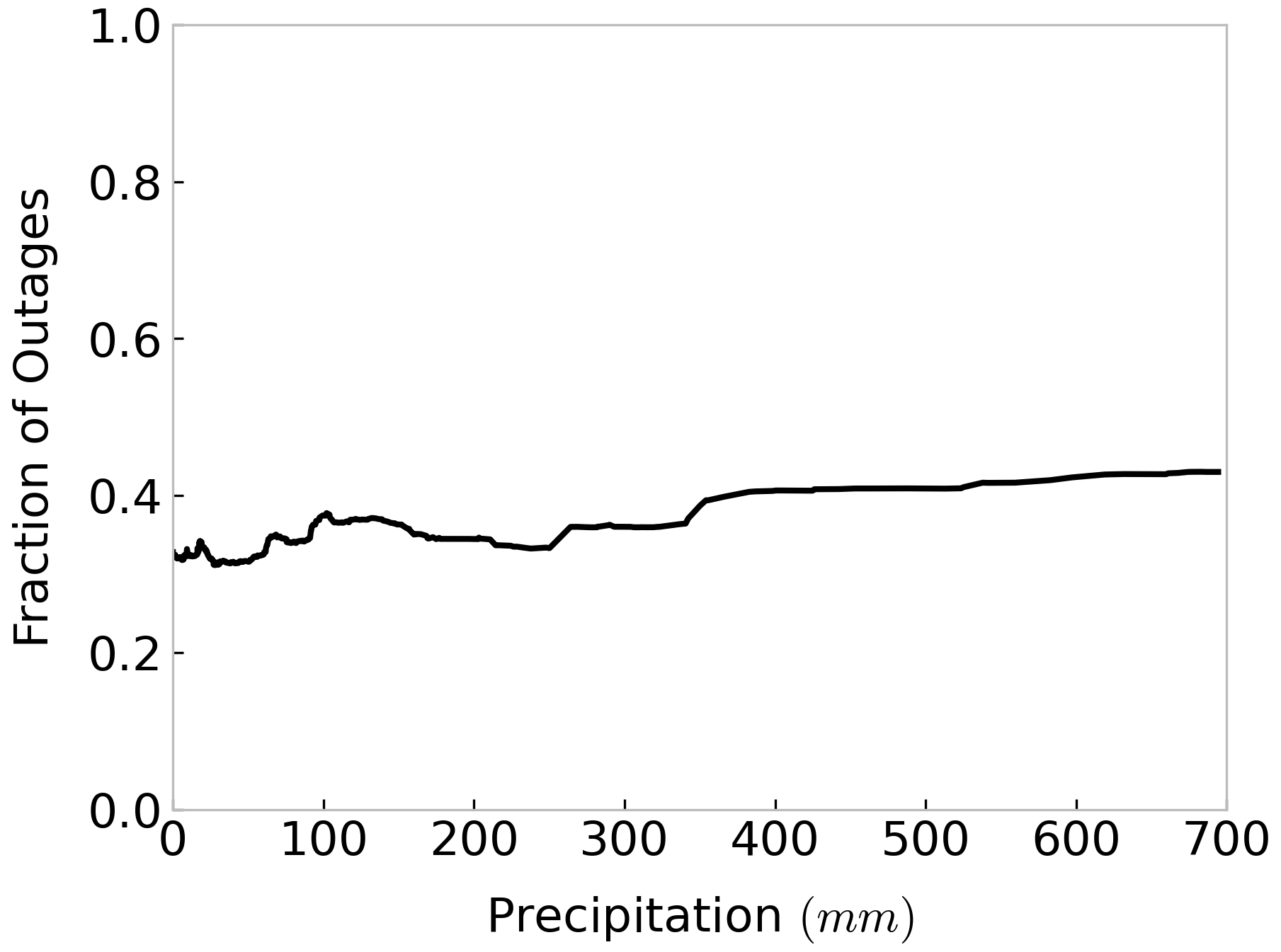
As standard deviation is high for outages with the variation of winds, and precipitation is the second most important variable in the RF model per Fig. 8, we explore the relationship between outage fraction and precipitation, based on Eq. (9), to understand the non-linearity in outages. We show the partial dependence plot of precipitation in Fig. 12. The partial dependence plot of precipitation (Fig. 12) shows non-linearity with an increase in the fraction of outages from 0.3 to 0.4 over the range of observed precipitation for the historical storms. However, we can observe from Fig. 12, similar to Fig. 11, that precipitation also explains limited variability in the outages in this case. Also, at zero wind speed and zero precipitation RF model predicts non-zero outages.
This paper summarized existing power outage prediction models, (a) GLMs and (b) GAMs based on Poisson and negative binomial distributions and (c) random forest regressions. Power outages depend on several factors, including hurricane, environmental, and demographic conditions. To examine the existing models, we used power outage data with a total of 3.6 million outages for Hurricane Isaias (2020) in New York and New Jersey states, Hurricane Harvey (2017) in Texas, and Hurricane Michael (2018) in Florida. We combined the outages from these states to develop a generalized power outage model across different regions, improving previous efforts that only calibrated outage models to a particular region or utility companies in the US. We conducted a feature selection to avoid multi-collinearity among input variables and calibrated the state-of-the-art outage models using seven input parameters: 3 s wind gust speed, 7 d precipitation after the storm, standard precipitation index for 6 months before the storm, soil moisture for a depth between 0 and 10 cm, population density, the percent area covered by trees, and trees' root zone depth.
First, we found that Poisson regressions are unsuitable for modeling outages, as historical outages have larger variances than the mean, resulting in overdispersion. The overdispersion was evident by the large residual deviances of 6 038 042 and 3 565 948 for the Poisson GLM and GAM, respectively, for 1520 degrees of freedom. We found that negative binomial regressions account for these larger variances better than Poisson regressions since we obtained residual deviances of 2078 and 1813 for GLM and GAM, respectively. We also showed that GAMs could better model the non-linear behavior of predictors compared to GLMs since and significantly increased to 0.62 and 0.99, respectively, compared to values of 0.29 and 0.69 in negative binomial GLMs. We demonstrated that the random forest could also capture this non-linear behavior, as we found a value of 0.48 for the R2 in the cross-validation.
However, each model has its own merits and demerits in predicting outages. Poisson and negative binomial estimates are unbounded and can overestimate power outages. For example, the negative binomial regression predicted more outages than the number of customers for 19.8 % of cities in the test data, with an overprediction ratio of 5.2 for predicted outages compared to the actual number of customers. Random forest predictions are hard to calibrate for extreme winds, as outage data are limited. As a result, we found that they could not be extrapolated for high winds since we only had 1.5 % observations with wind speeds greater than 70 m s−1. The negative binomial GAM failed to account for low uncertainty in outage predictions at high winds, as we observed that instead the standard deviation in predictions grew 15 times with increasing wind speed from 40 to 70 m s−1. We found that random forest also fails to account for low uncertainty at low winds. Overestimated power outages could result in prioritizing a less affected city, placing more resources on that city than required. Limited mobility of crews during a disaster can lead to prolonged outages, delaying the restoration effects (National Academies of Sciences, Engineering, and Medicine, 2017). In general, erroneous power outage estimates with high uncertainty can result in the non-optimal placement of resources, as optimal resource allocation algorithms will use predicted outages (Brown, 2002).
We suggest beta (Ferrari and Cribari-Neto, 2010) and binomial regressions (Dunn and Smyth, 2018) to model power outages in future research. While testing their performance fell outside this paper's scope, beta and binomial distribution can help overcome existing limitations due to their fundamental properties. For example, beta and binomial regressions are upper-bounded, unlike negative binomial GLM and GAM regressions. Thus, beta or binomial GAMs can model the fraction of outages in a city, i.e., directly in the case of beta since it goes from 0 to 1, or after normalizing the total number of outages by the maximum number of customers in the case of the binomial regressions. Also, beta and binomial GAMs can extrapolate outages for the extreme (low and high) values of winds since they can model monotonically increasing outages as a function of environmental parameters. Finally, beta and binomial GAMs have variances closer to zero at outage fraction observation values of 0 and 1, better representing the physics or power infrastructure failures.
The R2 parameter, a goodness-of-fit measure, is used to compare and select among different models. The goodness-of-fit measure can quantify how good predictions are by the fitted model on unseen or test data.
The R2 parameter mentioned in Eq. (A1) represents the amount of variability explained by the fitted compared model to the null model. The null model predicts the average of observed outages () for all the cities irrespective of the input parameters. In the Eq. (A1), TSS is the residual sum of squares, defined by the sum of squares of the difference between the true value of the response variable and average of true values of response variable.
RSS is the total sum of squares, defined by the sum of squares of the difference between the true value of the response variable and the predicted value of the response variable from the fitted model.
A1 parameter
We quantify overdispersion by calculating if the residual deviance is larger than the degrees of freedom. Degrees of freedom is defined as the number of data points in the training data minus the number of input parameters. We estimate
where LL(sat) is the maximum achievable log-likelihood for the saturated model, and LL(fit) is the log-likelihood for the fitted model. Simplified versions of Eq. (A4) to calculate deviance for different distributions are given below.
-
Poisson. Residual deviance (Cameron and Windmeijer, 1996) for the ith observation for Poisson GLM and GAM is
where yi are are the observed and predicted outages for ith city. Deviance for the model is the sum of the square of the residual deviance for each observation.
-
Negative binomial. Residual deviance for the ith observation for a negative binomial GLM is
and deviance for the fitted model is estimated by Eq. (A6).
For GLMs and GAMs, a pseudo-R2, denoted as (Cameron and Windmeijer, 1996), is also defined to compare the statistical performance based on model deviance. Similar to the definition of R2, measures the reduction in deviance of the fitted model when compared with the null model. The value of is given by
D(y,yi) is the deviance for the fitted model already defined in Eq. (A4). For a null model, predictions will always be (average of observed outages in training data). is the deviance for a null model, which can be obtained by replacing LL(fit) in Eq. (A4) with LL(null).
The value of will increase after adding more predictors, as more predictors will always explain more variability in outage counts, decreasing the residual deviance. Also, the value of is bounded from 0 to 1, and a value closer to 1 will indicate a good fit of the model (Cameron and Windmeijer, 1996).
A2 parameter
is defined to measure the reduction in overdispersion for the fitted model negative binomial regression models when compared to the null model (Liu et al., 2005; Han et al., 2009b).
k is the overdispersion factor (Eq. 5) for the fitted model, and k0 is the overdispersion factor (Eq. 5) for the null model. Models with low overdispersion will have a low value of k. The will be closer to 1 for a model with less overdispersion.
Power outage data are available from PowerOutage (https://poweroutage.us/, last access: 21 September 2022; PowerOutage.us, 2023). The data on Land Cover are available from the Multi-Resolution Land Characteristics Consortium (https://www.mrlc.gov/viewer/, last access: 21 September, 2022; MRLC, 2023). Precipitation and soil moisture data are available from the National Land Data Assimilation System Phase 2 (Xia et al., 2012; Xia, 2012). The soil data are available from Soil Survey Staff. The percent tree data are available from National Insect and Disaster Risk Maps (Krist et al., 2014). Elevation data are obtained from USGS (Danielson and Gesh, 2011). Additional analyses are available from the authors upon reasonable request.
The supplement related to this article is available online at: https://doi.org/10.5194/nhess-23-1665-2023-supplement.
PA reviewed the existing models for power outage predictions during hurricanes, under LC's supervision. PA and LC collected and curated the data for outages and input parameters and fitted the power outage models for predicting outages. PA drafted the paper with contributions and revisions from LC.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the special issue “Advances in machine learning for natural hazards risk assessment”. It is not associated with a conference.
We acknowledge the financial support by the NYU Tandon School of Engineering Fellowship. Additionally, this research was also supported by the Coalition for Disaster Resilient Infrastructure Fellowship Grant 210924669. The authors are grateful for their generous support.
This research has been supported by the NYU Tandon School of Engineering Fellowship. This research has been additionally supported by the Coalition for Disaster Resilient Infrastructure Fellowship (grant no. 201924669).
This paper was edited by Vitor Silva and reviewed by two anonymous referees.
Ahsanullah, M., Kibria, B. M. G., and Shakil, M.: Normal Distribution, 7–50, https://link.springer.com/chapter/10.2991/978-94-6239-061-4_2 (last access: 21 September 2022), 2014. a
AJOT: Hurricane Ida caused at least 1.2 million electricity customers to lose power | AJOT.COM, https://ajot.com/news/hurricane-ida-caused-at-least-1.2-million-electricity-customers-to-lose-power (last access: 21 September, 2022), 2021. a
Arab, A., Khodaei, A., Khator, S. K., and Han, Z.: Electric Power Grid Restoration Considering Disaster Economics, IEEE Access, 4, 639–649, https://doi.org/10.1109/ACCESS.2016.2523545, 2016. a
Bjarnadottir, S., Li, Y., and Stewart, M. G.: Hurricane Risk Assessment of Power Distribution Poles Considering Impacts of a Changing Climate, J. Infrastruct. Sys., 19, 12–24, https://doi.org/10.1061/(asce)is.1943-555x.0000108, 2013. a, b, c
Breiman, L.: Random forests, Mach. Learn., 45, 5–32, 2001. a, b, c
Brown, R. E.: Electric Power Distribution Reliability, https://doi.org/10.1201/9780849375682), 2002. a, b, c
Cai, J., Luo, J., Wang, S., and Yang, S.: Feature selection in machine learning: A new perspective, Neurocomputing, 300, 70–79, https://doi.org/10.1016/j.neucom.2017.11.077, 2018. a
Cameron, A. C. and Windmeijer, F. A.: R-squared measures for count data regression models with applications to health-care utilization, J. Bus. Econ. Stat., 14, 209–220, https://doi.org/10.1080/07350015.1996.10524648, 1996. a, b, c
Casey, S.: The United States, The Ashgate Research Companion to the Korean War, 49–60 pp., https://doi.org/10.1007/978-1-349-08679-5_5, 2016. a
Ceferino, L., Kiremidjian, A., and Deierlein, G.: Regional Multiseverity Casualty Estimation Due to Building Damage following a Mw 8.8 Earthquake Scenario in Lima, Peru, Earthq. Spectra, 34, 1739–1761, https://doi.org/10.1193/080617EQS154M, 2018. a
Ceferino, L., Mitrani-Reiser, J., Kiremidjian, A., Deierlein, G., and Bambarén, C.: Effective plans for hospital system response to earthquake emergencies, Nat. Commun., 11, 1–12, https://doi.org/10.1038/s41467-020-18072-w, 2020. a
Chapman, L.: Assessing topographic exposure, Meteorol. Appl., 7, 335–340, https://doi.org/10.1017/S1350482700001729, 2000. a, b
Chavas, D. R., Lin, N., and Emanuel, K.: A model for the complete radial structure of the tropical cyclone wind field. Part I: Comparison with observed structure, J. Atmos. Sci., 72, 3647–3662, https://doi.org/10.1175/JAS-D-15-0014.1, 2015. a, b
Congress.gov: H.R.5760 – 116th Congress (2019-2020): Grid Security Research and Development Act | Congress.gov | Library of Congress, https://www.congress.gov/bill/116th-congress/house-bill/5760 (last access: 21 September 2022), 2020. a
Danielson, J. and Gesh, D.: Global multi-resolution terrain elevation data 2010 (GMTED2010): U.S. Geological Survey Open-File Report 2011–1073, https://www.usgs.gov/publications/global-multi-resolution-terrain-elevation-data-2010-gmted2010 (last access: last access: 21 September 2022), 2011. a, b
Dunn, P. K. and Smyth, G. K.: Generalized Linear Models With Examples in R, https://link.springer.com/book/10.1007/978-1-4419-0118-7 (last access: last access: 21 September 2022), 2018. a, b, c, d, e, f, g, h
EIA.GOV: U.S. Energy Information Administration – EIA – Independent Statistics and Analysis, https://www.eia.gov/todayinenergy/detail.php?id=37332 (last access: last access: 21 September 2022), 2018. a
Elamrouss, A.: 75% of power outages reported in Louisiana after Hurricane Ida have been restored, governor says | CNN, https://www.cnn.com/2021/09/09/us/hurricane-ida-aftermath-louisiana-thursday/index.html (last access: last access: 21 September 2022), 2021. a
Eskandarpour, R. and Khodaei, A.: Leveraging accuracy-uncertainty tradeoff in SVM to achieve highly accurate outage predictions, IEEE T. Power Syst., 33, 1139–1141, https://doi.org/10.1109/TPWRS.2017.2759061, 2018. a
Eskandarpour, R., Khodaei, A., Paaso, A., and Abdullah, N. M.: Artificial Intelligence Assisted Power Grid Hardening in Response to Extreme Weather Events, Cornell University, https://doi.org/10.48550/arxiv.1810.02866, 2018. a
ESRI: ArcGIS Desktop: Release 10.8, Tech. rep., Environmental Systems Research Institute, Relands, CA, https://www.arcgis.com/index.html (last access: 21 September 2022), 2019. a, b
Ferrari, S. L. and Cribari-Neto, F.: Beta Regression for Modelling Rates and Proportions, 31, 799–815, https://doi.org/10.1080/0266476042000214501, 2010. a
Guikema, S. D., Quiring, S. M., and Han, S. R.: Prestorm Estimation of Hurricane Damage to Electric Power Distribution Systems, Risk Anal., 30, 1744–1752, https://doi.org/10.1111/j.1539-6924.2010.01510.x, 2010. a, b, c, d, e
Guikema, S. D., Nateghi, R., Quiring, S. M., Staid, A., Reilly, A. C., and Gao, M.: Predicting Hurricane Power Outages to Support Storm Response Planning, IEEE Access, 2, 1364–1373, https://doi.org/10.1109/ACCESS.2014.2365716, 2014. a, b, c, d, e
Guttman, N. B.: Comparing the palmer drought index and the standardized precipitation index, J. Am. Water Resour. As., 34, 113–121, https://doi.org/10.1111/j.1752-1688.1998.tb05964.x, 1998. a
Hall, D. B.: Zero-Inflated Poisson and Binomial Regression with Random Effects: A Case Study, Biometrics, 56, 1030–1039, https://doi.org/10.1111/J.0006-341X.2000.01030.X, 2000. a
Han, S. R., Guikema, S. D., and Quiring, S. M.: Improving the predictive accuracy of hurricane power outage forecasts using generalized additive models, Risk Anal., 29, 1443–1453, https://doi.org/10.1111/j.1539-6924.2009.01280.x, 2009a. a, b, c, d, e, f, g, h, i, j
Han, S. R., Guikema, S. D., Quiring, S. M., Lee, K. H., Rosowsky, D., and Davidson, R. A.: Estimating the spatial distribution of power outages during hurricanes in the Gulf coast region, Reliab. Eng. Syst. Safe., 94, 199–210, https://doi.org/10.1016/j.ress.2008.02.018, 2009b. a, b, c, d, e, f, g, h, i, j, k
Haseltine, C. and Eman, E. E. S.: Prediction of power grid failure using neural network learning, Proceedings – 16th IEEE International Conference on Machine Learning and Applications, ICMLA 2017, 2017–December, 505–510, https://doi.org/10.1109/ICMLA.2017.0-111, 2017. a
Hastie, T., Tibshirani, R., and Friedman, J.: Springer Series in Statistics The Elements of Statistical Learning Data Mining, Inference, and Prediction, https://link.springer.com/book/10.1007/978-0-387-84858-7 (last access: 21 September 2022), 2001. a, b, c
Hosking, J. R. M. and Wallis, J. R.: Regional Frequency Analysis: An Approach Based on L-Moments, Cambridge University Press, 191–209, https://doi.org/10.1017/CBO9780511529443, 1997. a
IEEE: National Electrical Safety Code, ANSI/IEEE Standard C2-2007, 552, https://law.resource.org/pub/us/cfr/ibr/004/ieee.c2.2007.pdf (last access: 21 September 2022), 2007. a, b
Jaech, A., Zhang, B., Ostendorf, M., and Kirschen, D. S.: Real-Time Prediction of the Duration of Distribution System Outages, http://arxiv.org/abs/1804.01189 (last access: 20 January 2023), 2018. a
Kankanala, P., Das, S., and Pahwa, A.: Adaboost+: An ensemble learning approach for estimating weather-related outages in distribution systems, IEEE T. Power Syst., 29, 359–367, https://doi.org/10.1109/TPWRS.2013.2281137, 2014. a, b
Kohavi, R. and John, G. H.: Wrappers for feature subset selection, Artif. Intell., 97, 273–324, https://doi.org/10.1016/S0004-3702(97)00043-X, 1997. a
Krist Jr., F. J., Ellenwood, J. R., Woods, M. E., Mcmahan, A. J., Cowardin, J. P., Ryerson, D. E., Sapio, F. J., Zweifler, M. O., and Romero, S. A.: 2013–2027 National Insect and Disease Forest Risk Assessment, 87–92, https://doi.org/10.2737/SRS-GTR-209, 2014. a, b
Latto, A., Hagen, A., and Berg, R.: National Hurricane Center Tropical Cyclone Report. Hurricane Isaias, 1–32 pp., https://www.nhc.noaa.gov/data/tcr/AL092020_Isaias.pdf (last access: 21 September 2022), 2021. a
Li, R. and Peng, L.: Quantile Regression for Left-Truncated Semicompeting Risks Data, Biometrics, 67, 701–710, https://doi.org/10.1111/j.1541-0420.2010.01521.x, 2011. a
Liu, H., Davidson, R. A., Rosowsky, D. V., and Stedinger, J. R.: Negative Binomial Regression of Electric Power Outages in Hurricanes, J. Infrastruct. Syst., 11, 258–267, https://doi.org/10.1061/(asce)1076-0342(2005)11:4(258), 2005. a, b, c, d, e, f, g, h, i, j
Liu, H., Davidson, R. A., and Apanasovich, T. V.: Statistical forecasting of electric power restoration times in hurricanes and ice storms, IEEE Trans. Power Syst., 22, 2270–2279, https://doi.org/10.1109/TPWRS.2007.907587, 2007. a, b, c, d
Liu, H., Davidson, R. A., and Apanasovich, T. V.: Spatial generalized linear mixed models of electric power outages due to hurricanes and ice storms, Reliab. Eng. Syst. Safe., 93, 897–912, https://doi.org/10.1016/j.ress.2007.03.038, 2008. a, b, c
Maderia, C. M.: Importance of Tree Species and Precipitation for Modeling Hurricane-induced Power Outages, https://oaktrust.library.tamu.edu/handle/1969.1/155728 (last access: 21 September 2022), 2015. a
McRoberts, D. B., Quiring, S. M., and Guikema, S. D.: Improving Hurricane Power Outage Prediction Models Through the Inclusion of Local Environmental Factors, Risk Anal., 38, 2722–2737, https://doi.org/10.1111/risa.12728, 2018. a, b, c, d, e, f, g, h, i, j, k, l
Meinshausen, N.: Quantile Regression Forests, J. Mach. Learn. Res., 7, 983–999, 2006. a
Miller, C., Gibbons, M., Beatty, K., and Boissonnade, A.: Topographic speed-up effects and observed roof damage on Bermuda following Hurricane Fabian (2003), Weather Forecast., 28, 159–174, https://doi.org/10.1175/WAF-D-12-00050.1, 2013. a, b
MRLC: All NLCD Land Cover 2019 CONUS Land Cover, MRLC [data set], https://www.mrlc.gov/viewer/ (last access: 21 September, 2022), 2023. a
Napoli, A., Crespi, A., Ragone, F., Maugeri, M., and Pasquero, C.: Variability of orographic enhancement of precipitation in the Alpine region, Sci. Rep., 9, 13352, https://doi.org/10.1038/S41598-019-49974-5, 2019. a
Nateghi, R., Guikema, S., and Quiring, S. M.: Power Outage Estimation for Tropical Cyclones: Improved Accuracy with Simpler Models, Risk Anal., 34, 1069–1078, https://doi.org/10.1111/risa.12131, 2014. a, b, c, d, e, f, g, h
National Academies of Sciences, Engineering, and Medicine: Enhancing the Resilience of the Nation's Electricity System, Enhancing the Resilience of the Nation's Electricity System, The National Academies Press, 170 pp., https://doi.org/10.17226/24836, 2017. a, b, c
Ouyang, M. and Dueñas-Osorio, L.: Multi-dimensional hurricane resilience assessment of electric power systems, Struct. Saf., 48, 15–24, https://doi.org/10.1016/j.strusafe.2014.01.001, 2014. a, b
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E.: Scikit-learn: Machine Learning in {P}ython, J. Mach. Learn. Res., 12, 2825–2830, 2011. a, b
Petersen, H. C.: Electricity Consumption in Rural Vs. Urban Areas, Western J. Agr. Econ., 07, 13–18, http://econpapers.repec.org/RePEc:ags:wjagec:32417 (last access: 21 September 2022), 1982. a
PowerOutage.us: Electric customers without power, PowerOutage.us [data set], https://poweroutage.us/ (last access: 21 September 2022), 2023. a
Quiring, S. M., Zhu, L., and Guikema, S. D.: Importance of soil and elevation characteristics for modeling hurricane-induced power outages, Nat. Hazards, 58, 365–390, https://doi.org/10.1007/s11069-010-9672-9, 2011. a, b, c
Rivera, I., Mckay, R., and Disavino, S.: Puerto Rico power grid no match for Fiona; residents unsurprised | Reuters, https://www.reuters.com/business/environment (last access: 21 September 2022), 2022. a
Rudin, C., Waltz, D., Anderson, R., Boulanger, A., Salleb-Aouissi, A., Chow, M., Dutta, H., Gross, P., Huang, B., Ierome, S., Isaac, D. F., Kressner, A., Passonneau, R. J., Radeva, A., and Wu, L.: Machine learning for the New York City power grid, IEEE T. Pattern Anal., 34, 328–345, https://doi.org/10.1109/TPAMI.2011.108, 2012. a
Shashaani, S., Guikema, S. D., Zhai, C., Pino, J. V., and Quiring, S. M.: Multi-Stage Prediction for Zero-Inflated Hurricane Induced Power Outages, IEEE Access, 6, 62432–62449, https://doi.org/10.1109/ACCESS.2018.2877078, 2018. a, b, c, d, e, f, g, h, i
Sheppard, D. and DiSavino, S.: Superstorm Sandy cuts power to 8.1 million homes | Reuters, https://www.reuters.com/article/us-storm-sandy-powercuts (last access: 21 September 2022), 2012. a
Smith, A. B.: U.S. Billion-dollar Weather and Climate Disasters, 1980–present (NCEI Accession 0209268), National Centers for Environmental Information, https://doi.org/10.25921/STKW-7W73, 2020. a
Soil Survey Staff: Gridded Soil Survey Geographic Database (gSSURGO) | Ag Data Commons, https://data.nal.usda.gov/dataset/gridded-soil-survey-geographic-database-gssurgo (last access: 21 September 2022). a, b
Sun, C. C., Hahn, A., and Liu, C. C.: Cyber security of a power grid: State-of-the-art, Int. J. Elec. Power, 99, 45–56, https://doi.org/10.1016/j.ijepes.2017.12.020, 2018. a
Tonn, G. L., Guikema, S. D., Ferreira, C. M., and Quiring, S. M.: Hurricane Isaac: A Longitudinal Analysis of Storm Characteristics and Power Outage Risk, Risk Anal., 36, 1936–1947, https://doi.org/10.1111/risa.12552, 2016. a, b
Verleysen, M. and François, D.: The curse of dimensionality in data mining and time series prediction, Lect. Notes Comput. Sci., 3512, 758–770, https://doi.org/10.1007/11494669_93, 2005. a
Wallach, D. and Goffinet, B.: Mean squared error of prediction as a criterion for evaluating and comparing system models, Ecol. Modell., 44, 299–306, https://doi.org/10.1016/0304-3800(89)90035-5, 1989. a
Wanik, D. W., Anagnostou, E. N., Hartman, B. M., Frediani, M. E., and Astitha, M.: Storm outage modeling for an electric distribution network in Northeastern USA, Nat. Hazards, 79, 1359–1384, https://doi.org/10.1007/s11069-015-1908-2, 2015. a
Wanik, D. W., Parent, J. R., Anagnostou, E. N., and Hartman, B. M.: Using vegetation management and LiDAR-derived tree height data to improve outage predictions for electric utilities, Electr. Pow. Syst. Res., 146, 236–245, https://doi.org/10.1016/j.epsr.2017.01.039, 2017. a, b
Wei, H., Xia, Y., Mitchell, K. E., and Ek, M. B.: Improvement of the Noah land surface model for warm season processes: Evaluation of water and energy flux simulation, Hydrol. Process., 27, 297–303, https://doi.org/10.1002/HYP.9214, 2013. a
Wickham, J., Stehman, S. V., Sorenson, D. G., Gass, L., and Dewitz, J. A.: Thematic accuracy assessment of the NLCD 2016 land cover for the conterminous United States, Remote Sens. Environ., 257, https://doi.org/10.1016/J.RSE.2021.112357, 2021. a
Wood, S. N.: Generalized additive models: An introduction with R, second edition, Generalized Additive Models: An Introduction with R, Second Edition, 1–476 pp., https://doi.org/10.1201/9781315370279/GENERALIZED-ADDITIVE-MODELS-SIMON-WOOD, 2017. a
Wu, H., Svoboda, M. D., Hayes, M. J., Wilhite, D. A., and Wen, F.: Appropriate application of the Standardized Precipitation Index in arid locations and dry seasons, Int. J. Climatol., 27, 65–79, https://doi.org/10.1002/joc.1371, 2007. a
Xia, Y., Mitchell, K., Ek, M., Sheffield, J., Cosgrove, B., Wood, E., Luo, L., Alonge, C., Wei, H., Meng, J., Livneh, B., Lettenmaier, D., Koren, V., Duan, Q., Mo, K., Fan, Y., and Mocko, D.: NCEP/EMC (2014), NLDAS VIC Land Surface Model L4 Hourly 0.125 × 0.125 degree V002, edited by: Mocko, D., NASA/GSFC/HSL, Greenbelt, Maryland, USA, Goddard Earth Sciences Data and Information Services Center (GES DISC), https://doi.org/10.5067/ELBDAPAKNGJ9, 2012. a, b, c
Xia, Y., Mitchell, K., Ek, M., Sheffield, J., Cosgrove, B., Wood, E., Luo, L., Alonge, C., Wei, H., Meng, J., Livneh, B., Lettenmaier, D., Koren, V., Duan, Q., Mo, K., Fan, Y., and Mocko, D.: Continental-scale water and energy flux analysis and validation for the North American Land Data Assimilation System project phase 2 (NLDAS-2): 1. Intercomparison and application of model products, J. Geophys. Res.-Atmos., 117, 3109, https://doi.org/10.1029/2011JD016048, 2012. a, b, c
Xie, J., Alvarez-Fernandez, I., and Sun, W.: A review of machine learning applications in power system resilience, IEEE Pow. Ener. Soc. Ge., 2020–August, https://doi.org/10.1109/PESGM41954.2020.9282137, 2020. a
Yee, T. W.: Package “VGAM” (Vector generalized linear and additive models), http://www.springer.com/series/692 (last access: 21 September 2022), 2012. a, b
- Abstract
- Introduction
- Data description
- Model development: feature selection
- Generalized linear models
- Generalized additive models
- Random forests
- Application of existing models
- Limitations of state-of-the-art outage models
- Conclusions and future research
- Appendix A: R2 parameter
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement
- Abstract
- Introduction
- Data description
- Model development: feature selection
- Generalized linear models
- Generalized additive models
- Random forests
- Application of existing models
- Limitations of state-of-the-art outage models
- Conclusions and future research
- Appendix A: R2 parameter
- Code and data availability
- Author contributions
- Competing interests
- Disclaimer
- Special issue statement
- Acknowledgements
- Financial support
- Review statement
- References
- Supplement